python数据处理----整理数据
为什么要整理数据对于这种“宽”数据,在展示方面来说没有什么问题,但是数据分析的时候我们需要“长”数据,这时候就需要整理数据整理成我们想要的样子。melt函数把字段拆分成数据id_vars参数:保留哪个字段(可以保留多个字段)var_name参数:为其余转换的字段起别名value_name参数:为值的那一列起别名pew_long = pd.melt(pew,id_vars='religion',va
·
为什么要整理数据
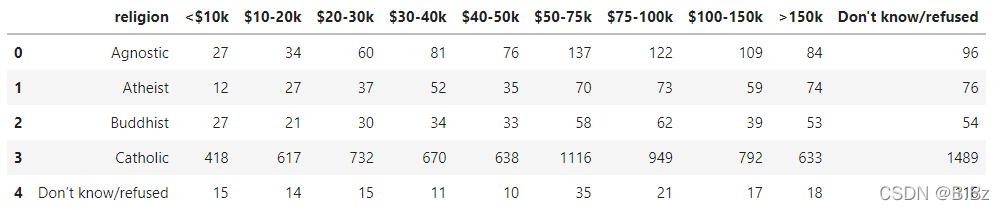
对于这种“宽”数据,在展示方面来说没有什么问题,但是数据分析的时候我们需要“长”数据,这时候就需要整理数据整理成我们想要的样子。
melt( )函数
把字段拆分成数据
- id_vars参数:保留哪个字段(
可以保留多个字段) - var_name参数:为其余转换的字段起别名
- value_name参数:为值的那一列起别名
pew_long = pd.melt(pew,id_vars='religion',var_name='income',value_name='count')
print(pew_long)

保留多个列
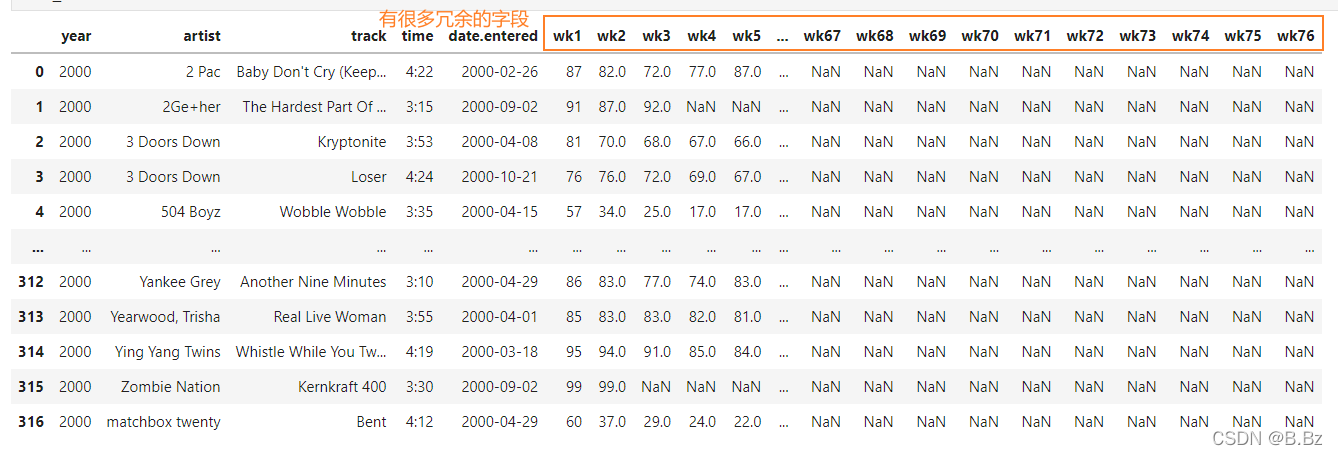
# 保留除了冗余的字段外其他的字段
bill_long = bill_board.melt(id_vars=['year','artist','track','time','date.entered'],var_name="周期",value_name="周排行")
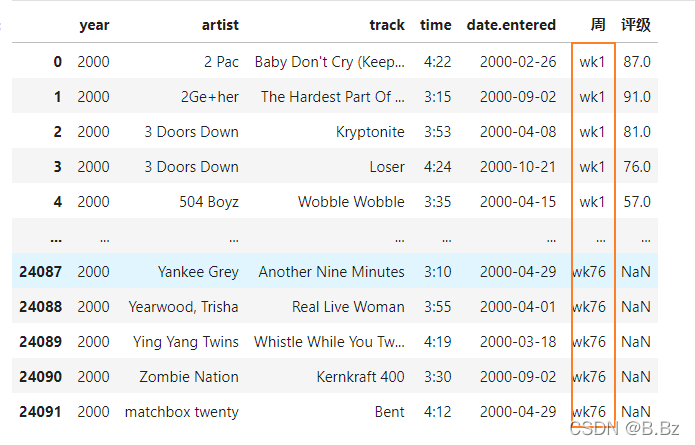
drop_duplicates( )函数
根据列名删除重复数据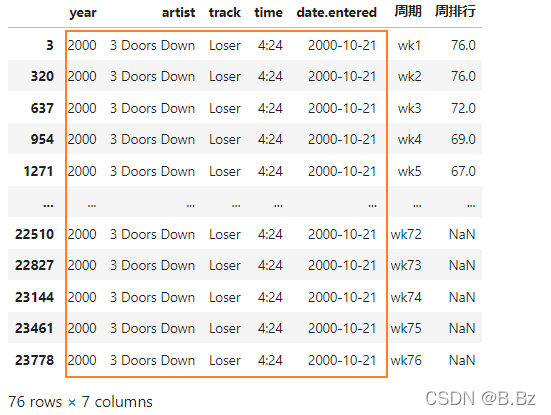
根据歌手查看数据发现很多同一首歌相同的数据,这时候需要去除冗余数据:
bill_long.drop_duplicates(subset=['year','artist','track','time','date.entered'],keep='first',inplace=True)
subset参数:要进行去重的列名,默认Nonekeep可选参数:first保留第一次出现重复行,删除后面的重复last删除重复项,保留最后一个重复的数据False删除所有重复的数据
inplace参数: 布尔值,默认False,为True时直接修改原数据,False时修改完的数据返回一个副本
stack( )函数
原数据:
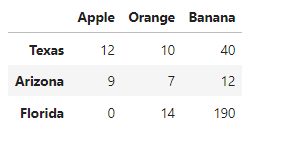
stack()方法整理数据
state_fruit_tidy = state_fruit.stack()
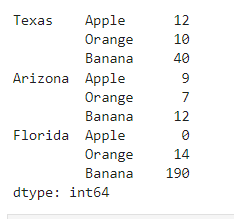
重置索引转换为DataFrame对象并修改列索引:
state_fruit_tidy = state_fruit.stack().reset_index()
state_fruit_tidy.columns = ['state', 'fruit', 'weight']
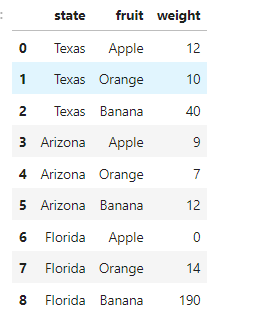
wide_to_long( )函数
原数据:

- 从上面数据中可以看出,列名中包含了数字 1,2,3 如果想把这部分信息提取到列当中,可以使用wide_to_long函数
使用wide_to_long函数时,要求 1,2,3 这样的顺序信息在列名的最后,并用分隔符隔开
-
使用自定义函数先整理数据为wide_to_lang()需要的数据格式:
wide_to_lang()函数需要数据格式 列名\分隔符\数字#创建一个自定义函数,用来改变列名。将数字放到列名的最后 def change_col_name(col_name): # 每一次传入列表 把_name替换为空 前三个数据符合格式 col_name = col_name.replace('_name', '') if 'facebook' in col_name: # 处理后三个列名 fb_idx = col_name.find('facebook') col_name = col_name[:5] + col_name[fb_idx - 1:] + col_name[5:fb_idx-1] return col_name actor2 = actor.rename(columns=change_col_name) actor2.head()

- 使用wide_to_lang()函数
stubnames参数:提取以指定字符串开头的列(可传入字符串和列表)i参数:当作索引的列(可传入字符串和列表)j参数: 提取开头后剩余的部分,在此指定列名(传入字符串)sep参数: 指定分隔符 ,默认" "(传入字符串)
# 列名列表
stubs = ['actor', 'actor_facebook_likes']
actor2_tidy = pd.wide_to_long(actor2,
stubnames=stubs,
i=['movie_title'],
j='actor_num',
sep='_').reset_index()
print(actor2_tidy)
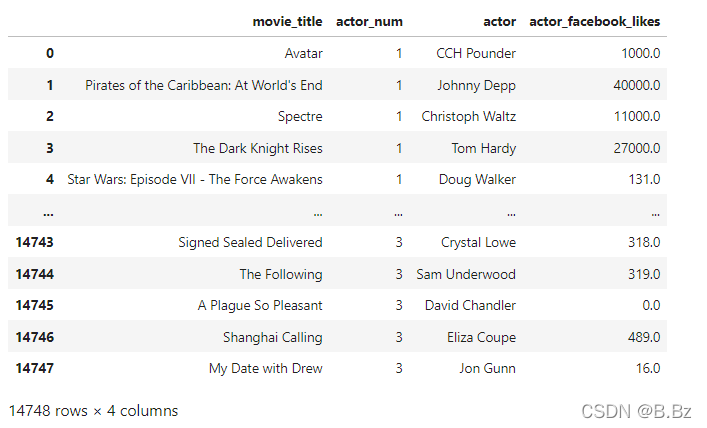
小结
| 方法 | 特点 |
|---|---|
| melt | 指定数据列,将指定的列变成长数据 |
| stack | 返回一个具有多层级索引的数据,配合reset_index()重置索引可实现宽数据变成长数据 |
| wide_to_lang | 处理列名带数字后缀的宽数据 |

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)