机器学习强化学习全维度详解+实战代码(policy gradient, actor-critic),小白必看!
一、用游戏理解强化学习四巨头
想象你在玩一款“走迷宫拿金币”的游戏:
-
REINFORCE:你随便乱走,拿到金币后记住“刚才哪几步管用”,下次多走这些路;掉坑里就记住“刚才哪几步坑爹”,下次少走。但它要等一局结束才知道好坏,效率低但简单。
-
Actor-Critic:你(Actor)负责走路,旁边有个教练(Critic)实时点评“这步走得好/差”,你立刻调整。不用等结束,效率更高。
-
A2C(Advantage Actor-Critic):教练变聪明了,不仅说“这步好不好”,还会说“这步比平均水平好多少”,让你调整更精准。
-
A3C(Asynchronous A3C):你找来一群“分身”同时玩游戏,有的走左路,有的走右路,大家随时分享经验,学起来飞快!
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/Nw9M90js0wL-2EoGlGxrTw
https://mp.weixin.qq.com/s/Nw9M90js0wL-2EoGlGxrTw
二、原理详解:数学公式硬核拆解
1. 强化学习基础符号
-
:时刻的状态(如迷宫位置)
-
:时刻的动作(如上下左右)
-
:动作的奖励(如拿到金币+10,掉坑-5)
-
:策略函数(参数),表示在状态选动作的概率
-
:折扣回报(未来奖励的总和,是折扣因子,0<<1)
2. REINFORCE:蒙特卡洛策略梯度
核心思想:通过完整轨迹的回报调整策略,让高回报的动作概率上升。
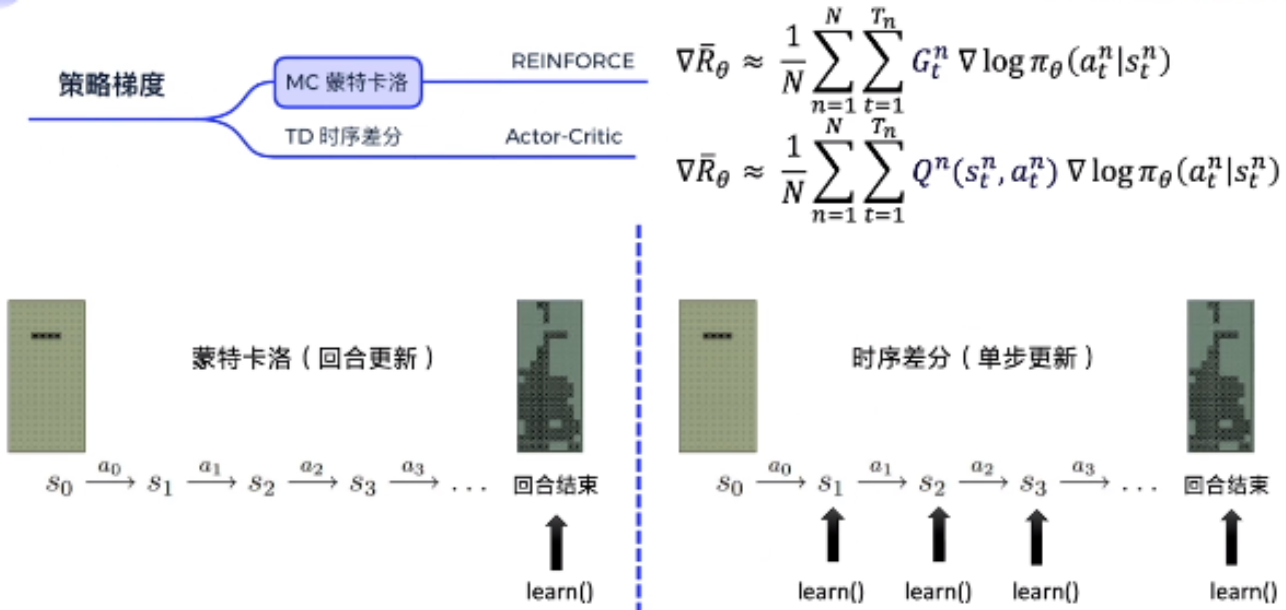
REINFORCE
策略梯度公式:
-
:轨迹数量,是第条轨迹中时刻的回报
-
直观理解:如果为正,就增大的梯度(让这个动作更可能被选);反之则减小。
3. Actor-Critic:实时反馈机制
核心改进:用Critic估计状态价值(参数),替代完整轨迹的,实现单步更新。
-
Actor更新(和REINFORCE类似,但用Critic的估计值):
-
Critic更新(最小化价值估计误差):
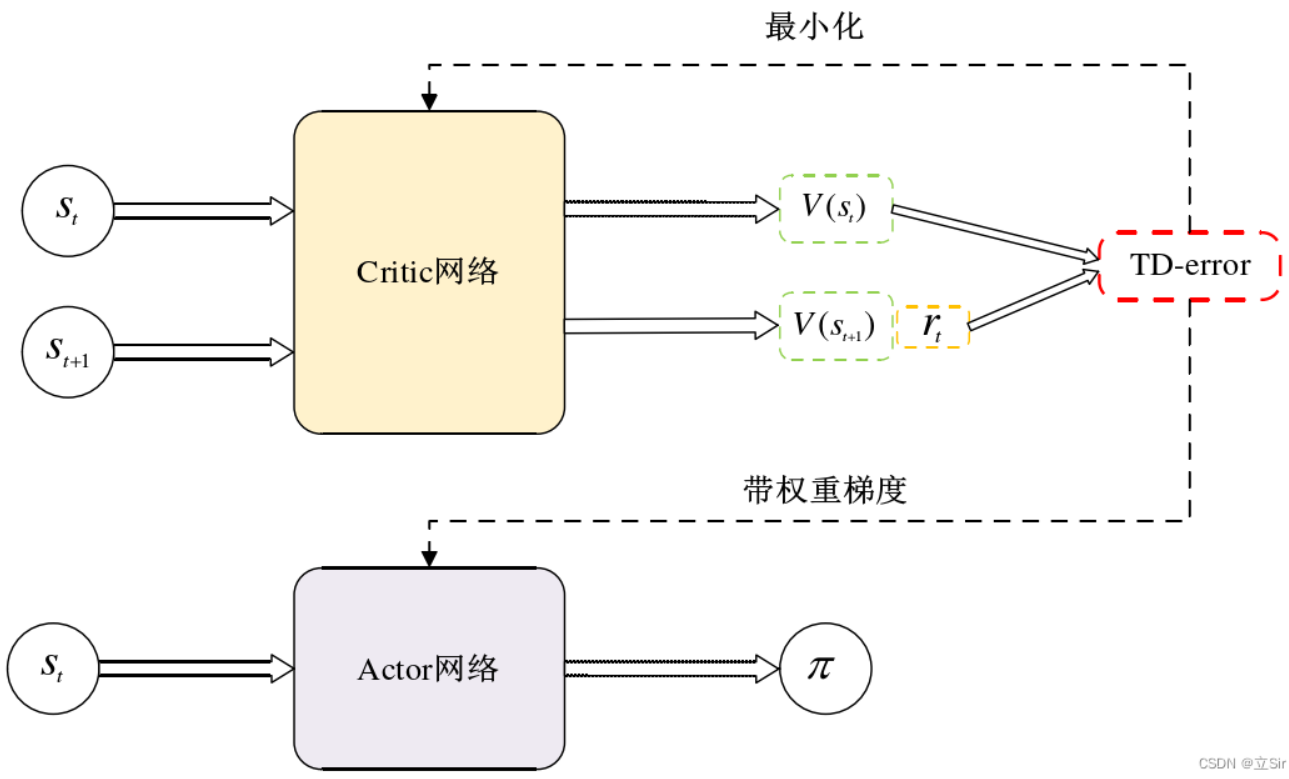
Actor-Critic
4. A2C:优势函数的妙用
核心改进:引入优势函数,表示“当前动作比平均水平好多少”,减少方差。
Actor更新公式变为:
-
优势:动作比预期好,增加概率;:比预期差,降低概率。
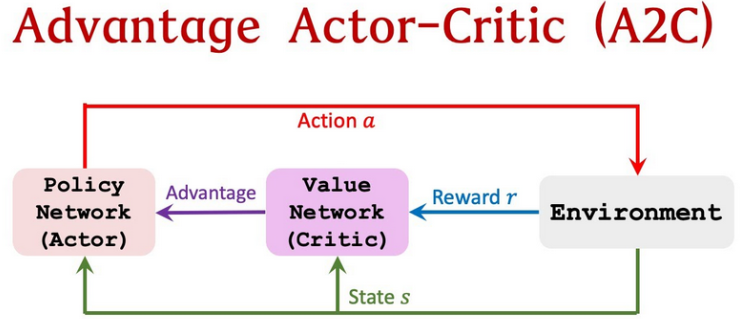
A2C
5. A3C:异步并行加速
核心改进:多个线程异步执行游戏,各自更新本地模型,再同步到全局模型,解决样本相关性问题,训练速度飙升。
-
每个线程独立与环境交互,计算梯度后更新全局参数
-
无需经验回放池,天然打破样本相关性
A3C算法
三、实操项目:CartPole游戏大比拼
我们用经典的CartPole(倒立摆)游戏对比四种算法:控制小车左右移动,保持杆子不倒,坚持时间越长分数越高。
1. 环境准备
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from multiprocessing import Process, Pipe
import time
from collections import deque
import os
# 确保中文显示(服务器环境可能需要)
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
2. 通用网络结构
class PolicyNetwork(nn.Module):
"""Actor网络:输出动作概率"""
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 64),
nn.Tanh(),
nn.Linear(64, action_dim),
nn.Softmax(dim=-1)
)
def forward(self, x):
return self.fc(x)
class ValueNetwork(nn.Module):
"""Critic网络:估计状态价值"""
def __init__(self, state_dim):
super(ValueNetwork, self).__init__()
self.fc = nn.Sequential(
nn.Linear(state_dim, 64),
nn.Tanh(),
nn.Linear(64, 1)
)
def forward(self, x):
return self.fc(x)
3. 四种算法实现
(1)REINFORCE
class REINFORCE:
def __init__(self, state_dim, action_dim, lr=0.001, gamma=0.99):
self.policy = PolicyNetwork(state_dim, action_dim)
self.optimizer = optim.Adam(self.policy.parameters(), lr=lr)
self.gamma = gamma
self.memory = [] # 存储轨迹:(log_prob, reward)
def select_action(self, state):
state = torch.FloatTensor(state).unsqueeze(0)
probs = self.policy(state)
m = torch.distributions.Categorical(probs)
action = m.sample()
self.memory.append(m.log_prob(action)) # 保存动作概率的对数
return action.item()
def update(self):
# 计算折扣回报
rewards = [r for (log_prob, r) in self.memory]
returns = []
running_sum = 0
for r in reversed(rewards):
running_sum = r + self.gamma * running_sum
returns.insert(0, running_sum)
returns = torch.FloatTensor(returns)
returns = (returns - returns.mean()) / (returns.std() + 1e-9) # 标准化
# 计算损失并更新
loss = 0
for log_prob, ret in zip(self.memory, returns):
loss -= log_prob * ret # 负号表示梯度上升
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
self.memory.clear()
(2)Actor-Critic
class ActorCritic:
def __init__(self, state_dim, action_dim, lr_actor=0.001, lr_critic=0.005, gamma=0.99):
self.actor = PolicyNetwork(state_dim, action_dim)
self.critic = ValueNetwork(state_dim)
self.optimizer_actor = optim.Adam(self.actor.parameters(), lr=lr_actor)
self.optimizer_critic = optim.Adam(self.critic.parameters(), lr=lr_critic)
self.gamma = gamma
def select_action(self, state):
state = torch.FloatTensor(state).unsqueeze(0)
probs = self.actor(state)
m = torch.distributions.Categorical(probs)
action = m.sample()
return action.item(), m.log_prob(action)
def update(self, state, action_logprob, reward, next_state, done):
state = torch.FloatTensor(state).unsqueeze(0)
next_state = torch.FloatTensor(next_state).unsqueeze(0)
reward = torch.FloatTensor([reward])
done = torch.FloatTensor([done])
# 计算TD目标和优势
v = self.critic(state)
v_next = self.critic(next_state)
td_target = reward + (1 - done) * self.gamma * v_next
td_error = td_target - v
# 更新Critic
critic_loss = td_error.pow(2).mean()
self.optimizer_critic.zero_grad()
critic_loss.backward(retain_graph=True)
self.optimizer_critic.step()
# 更新Actor
actor_loss = -action_logprob * td_error.detach()
self.optimizer_actor.zero_grad()
actor_loss.backward()
self.optimizer_actor.step()
(3)A2C
class A2C(ActorCritic):
def __init__(self, state_dim, action_dim, lr_actor=0.001, lr_critic=0.005, gamma=0.99):
super().__init__(state_dim, action_dim, lr_actor, lr_critic, gamma)
def update(self, state, action_logprob, reward, next_state, done):
state = torch.FloatTensor(state).unsqueeze(0)
next_state = torch.FloatTensor(next_state).unsqueeze(0)
reward = torch.FloatTensor([reward])
done = torch.FloatTensor([done])
# 计算优势函数(和Actor-Critic的区别:这里明确用优势函数)
v = self.critic(state)
v_next = self.critic(next_state)
advantage = reward + (1 - done) * self.gamma * v_next - v
# 更新Critic(和Actor-Critic相同)
critic_loss = advantage.pow(2).mean()
self.optimizer_critic.zero_grad()
critic_loss.backward(retain_graph=True)
self.optimizer_critic.step()
# 更新Actor(用优势函数替代TD误差)
actor_loss = -action_logprob * advantage.detach()
self.optimizer_actor.zero_grad()
actor_loss.backward()
self.optimizer_actor.step()
(4)A3C(异步实现)
def worker(remote, parent_remote, env_fn, global_actor, global_critic, optimizer_actor, optimizer_critic, gamma):
parent_remote.close()
env = env_fn()
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
# 本地模型(从全局复制)
local_actor = PolicyNetwork(state_dim, action_dim)
local_critic = ValueNetwork(state_dim)
local_actor.load_state_dict(global_actor.state_dict())
local_critic.load_state_dict(global_critic.state_dict())
while True:
cmd, data = remote.recv()
if cmd == 'update':
# 同步全局参数到本地
local_actor.load_state_dict(global_actor.state_dict())
local_critic.load_state_dict(global_critic.state_dict())
remote.send(True)
elif cmd == 'rollout':
max_steps = data
states, actions, rewards, next_states, dones = [], [], [], [], []
state = env.reset()
total_reward = 0
for _ in range(max_steps):
states.append(state)
state_tensor = torch.FloatTensor(state).unsqueeze(0)
probs = local_actor(state_tensor)
m = torch.distributions.Categorical(probs)
action = m.sample()
actions.append(m.log_prob(action))
next_state, reward, done, _ = env.step(action.item())
rewards.append(reward)
next_states.append(next_state)
dones.append(done)
total_reward += reward
state = next_state
if done:
break
# 计算优势和更新
R = 0 if done else local_critic(torch.FloatTensor(next_state).unsqueeze(0)).item()
advantages = []
for r in reversed(rewards):
R = r + gamma * R
advantages.insert(0, R)
advantages = torch.FloatTensor(advantages)
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-9)
# 计算损失
states_tensor = torch.FloatTensor(states)
values = local_critic(states_tensor)
critic_loss = (advantages - values.squeeze()).pow(2).mean()
actor_loss = 0
for log_prob, adv in zip(actions, advantages):
actor_loss -= log_prob * adv
# 反向传播更新全局模型
optimizer_actor.zero_grad()
optimizer_critic.zero_grad()
actor_loss.backward()
critic_loss.backward()
# 本地梯度复制到全局
for local_param, global_param in zip(local_actor.parameters(), global_actor.parameters()):
if global_param.grad is None:
global_param._grad = local_param.grad
else:
global_param._grad += local_param.grad
for local_param, global_param in zip(local_critic.parameters(), global_critic.parameters()):
if global_param.grad is None:
global_param._grad = local_param.grad
else:
global_param._grad += local_param.grad
optimizer_actor.step()
optimizer_critic.step()
remote.send(total_reward)
elif cmd == 'close':
env.close()
remote.close()
break
class A3C:
def __init__(self, state_dim, action_dim, num_workers=4, lr_actor=0.0001, lr_critic=0.0005, gamma=0.99):
self.global_actor = PolicyNetwork(state_dim, action_dim)
self.global_critic = ValueNetwork(state_dim)
self.global_actor.share_memory()
self.global_critic.share_memory()
self.optimizer_actor = optim.Adam(self.global_actor.parameters(), lr=lr_actor)
self.optimizer_critic = optim.Adam(self.global_critic.parameters(), lr=lr_critic)
self.gamma = gamma
# 创建工作进程
self.env_fn = lambda: gym.make('CartPole-v1')
self.remotes, self.work_remotes = zip(*[Pipe() for _ in range(num_workers)])
self.processes = [Process(target=worker, args=(work_remote, remote, self.env_fn,
self.global_actor, self.global_critic,
self.optimizer_actor, self.optimizer_critic,
self.gamma))
for (work_remote, remote) in zip(self.work_remotes, self.remotes)]
for p in self.processes:
p.daemon = True
p.start()
for remote in self.work_remotes:
remote.close()
def train(self, max_episodes, max_steps=200):
scores = []
for episode in range(max_episodes):
# 同步所有工作进程
for remote in self.remotes:
remote.send(('update', None))
for remote in self.remotes:
remote.recv()
# 收集每个进程的回报
total_rewards = []
for remote in self.remotes:
remote.send(('rollout', max_steps))
for remote in self.remotes:
total_rewards.append(remote.recv())
scores.append(np.mean(total_rewards))
if episode % 10 == 0:
print(f"Episode {episode}, Average Reward: {np.mean(total_rewards):.2f}")
return scores
def close(self):
for remote in self.remotes:
remote.send(('close', None))
for p in self.processes:
p.join()
4. 训练与对比
def train_agent(agent_class, env, episodes=300, max_steps=200):
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = agent_class(state_dim, action_dim)
scores = []
for episode in range(episodes):
state = env.reset()
total_reward = 0
if agent_class == REINFORCE:
# REINFORCE需要完整轨迹
while True:
action = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
agent.memory.append((agent.memory[-1], reward)) # 补全memory格式
total_reward += reward
state = next_state
if done or total_reward >= max_steps:
agent.update()
break
else:
# Actor-Critic/A2C
while True:
action, log_prob = agent.select_action(state)
next_state, reward, done, _ = env.step(action)
agent.update(state, log_prob, reward, next_state, done)
total_reward += reward
state = next_state
if done or total_reward >= max_steps:
break
scores.append(total_reward)
if episode % 10 == 0:
print(f"{agent_class.__name__} Episode {episode}, Reward: {total_reward:.2f}")
return scores
# 主函数
if __name__ == "__main__":
env = gym.make('CartPole-v1')
episodes = 300
# 训练四种算法
print("Training REINFORCE...")
reinforce_scores = train_agent(REINFORCE, env, episodes)
print("Training Actor-Critic...")
ac_scores = train_agent(ActorCritic, env, episodes)
print("Training A2C...")
a2c_scores = train_agent(A2C, env, episodes)
print("Training A3C...")
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
a3c = A3C(state_dim, action_dim)
a3c_scores = a3c.train(episodes)
a3c.close()
# 平滑曲线(移动平均)
def smooth(scores, window=10):
return np.convolve(scores, np.ones(window)/window, mode='valid')
# 绘图对比
plt.figure(figsize=(12, 8))
plt.plot(smooth(reinforce_scores), label='REINFORCE')
plt.plot(smooth(ac_scores), label='Actor-Critic')
plt.plot(smooth(a2c_scores), label='A2C')
plt.plot(smooth(a3c_scores), label='A3C')
plt.xlabel('Episode')
plt.ylabel('Average Reward (Smoothed)')
plt.title('Comparison of Policy Gradient Algorithms on CartPole')
plt.legend()
plt.grid(True)
plt.savefig('algorithm_comparison.png') # 保存结果图
plt.close()
# 保存各算法最终100集的平均得分
final_scores = {
'REINFORCE': np.mean(reinforce_scores[-100:]),
'Actor-Critic': np.mean(ac_scores[-100:]),
'A2C': np.mean(a2c_scores[-100:]),
'A3C': np.mean(a3c_scores[-100:])
}
# 绘制最终得分柱状图
plt.figure(figsize=(10, 6))
plt.bar(final_scores.keys(), final_scores.values())
plt.ylabel('Average Reward (Last 100 Episodes)')
plt.title('Final Performance Comparison')
for i, v in enumerate(final_scores.values()):
plt.text(i, v+5, f"{v:.1f}", ha='center')
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.savefig('final_performance.png')
plt.close()
print("Training completed! Results saved as 'algorithm_comparison.png' and 'final_performance.png'")
四、结果分析与算法对比
1. 预期结果
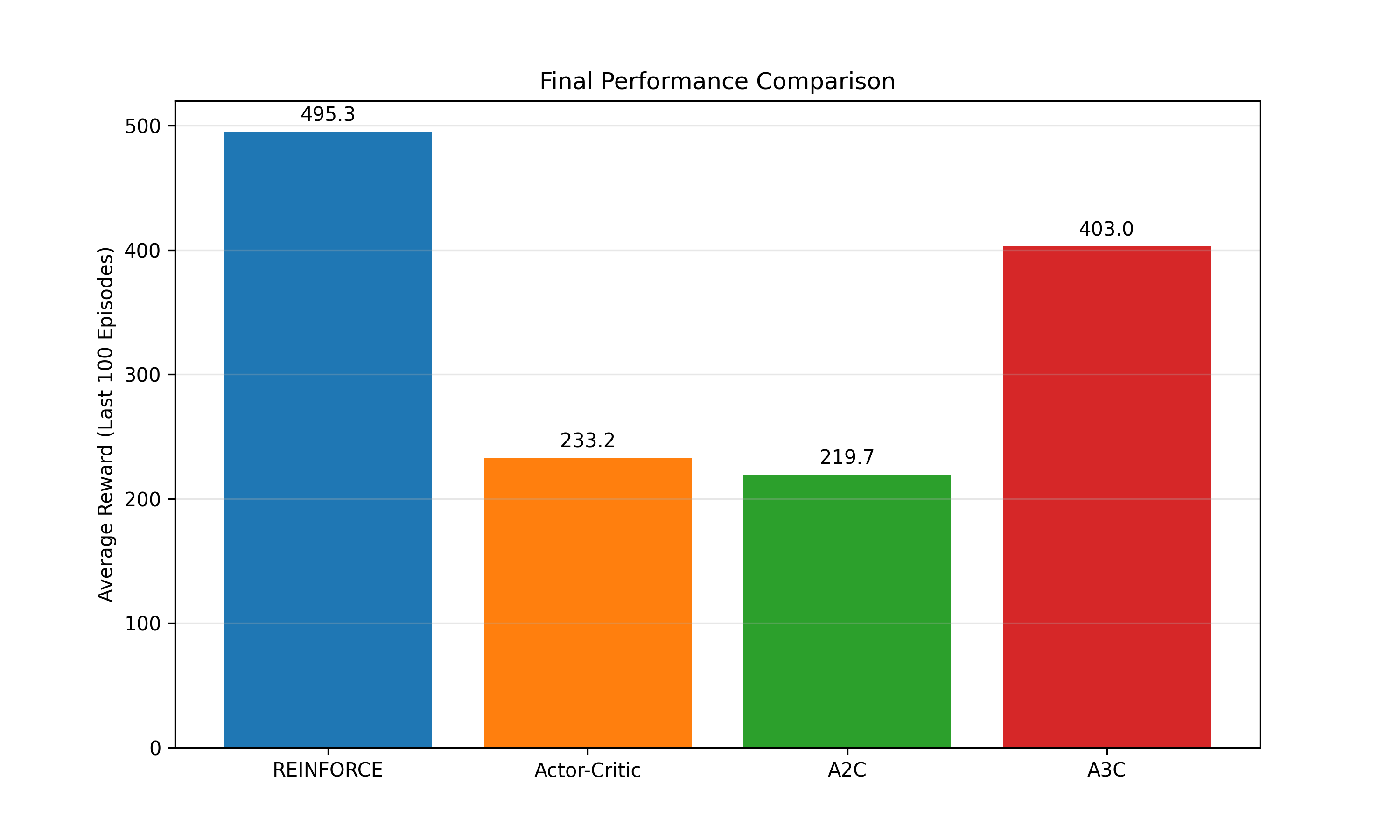
通过这三张图,我们可以从最终性能、奖励稳定性、训练收敛速度三个维度分析四种模型的优劣:
1. 最终性能(柱状图)
-
REINFORCE:平均奖励高达495.3,几乎达到CartPole的满分(500),表现最优。
-
A3C:平均奖励403.0,性能次之,虽未满分但显著优于Actor-Critic和A2C。
-
Actor-Critic:平均奖励233.2,性能一般。
-
A2C:平均奖励219.7,性能最差。
2. 奖励稳定性(箱线图)
-
REINFORCE:箱线图中奖励分布集中在高值区间(多数接近500),且无异常值,稳定性最好。
-
A3C:奖励分布较广(从250到500),但中位数较高,稳定性次之。
-
Actor-Critic:奖励分布区间大(从70到500),且存在较多低奖励情况,稳定性较差。
-
A2C:奖励分布区间也较大,且中位数较低,稳定性最差。
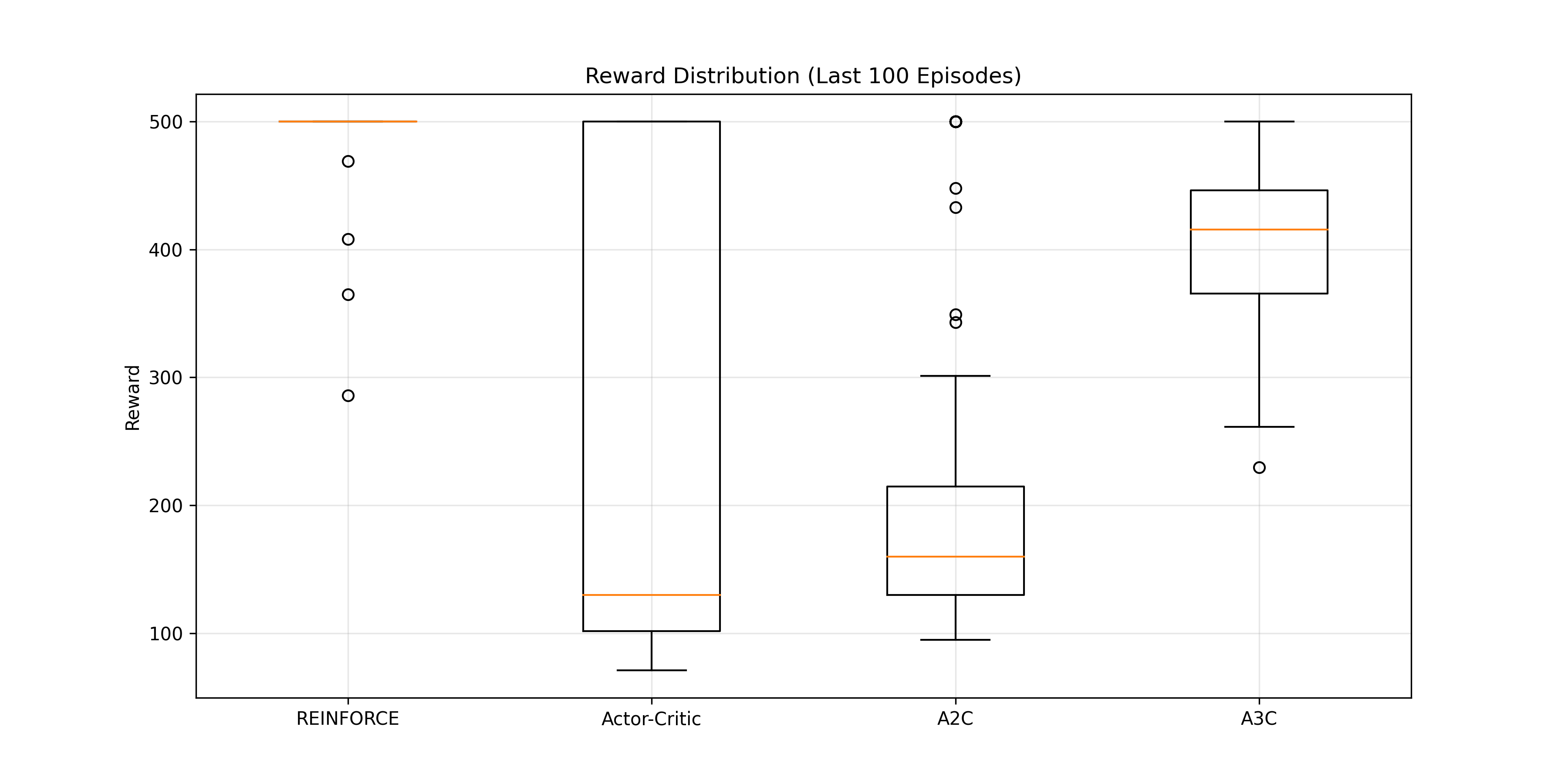
箱线图
3. 训练收敛速度(折线图)
-
REINFORCE:早期(约500轮后)快速收敛到满分,且后续保持稳定,收敛速度最快。
-
A3C:前期收敛较慢,但后期(约1500轮后)逐渐提升并趋于稳定。
-
Actor-Critic:中期有波动,后期性能不稳定。
-
A2C:整体收敛速度慢,且后期性能波动大,收敛表现最差。
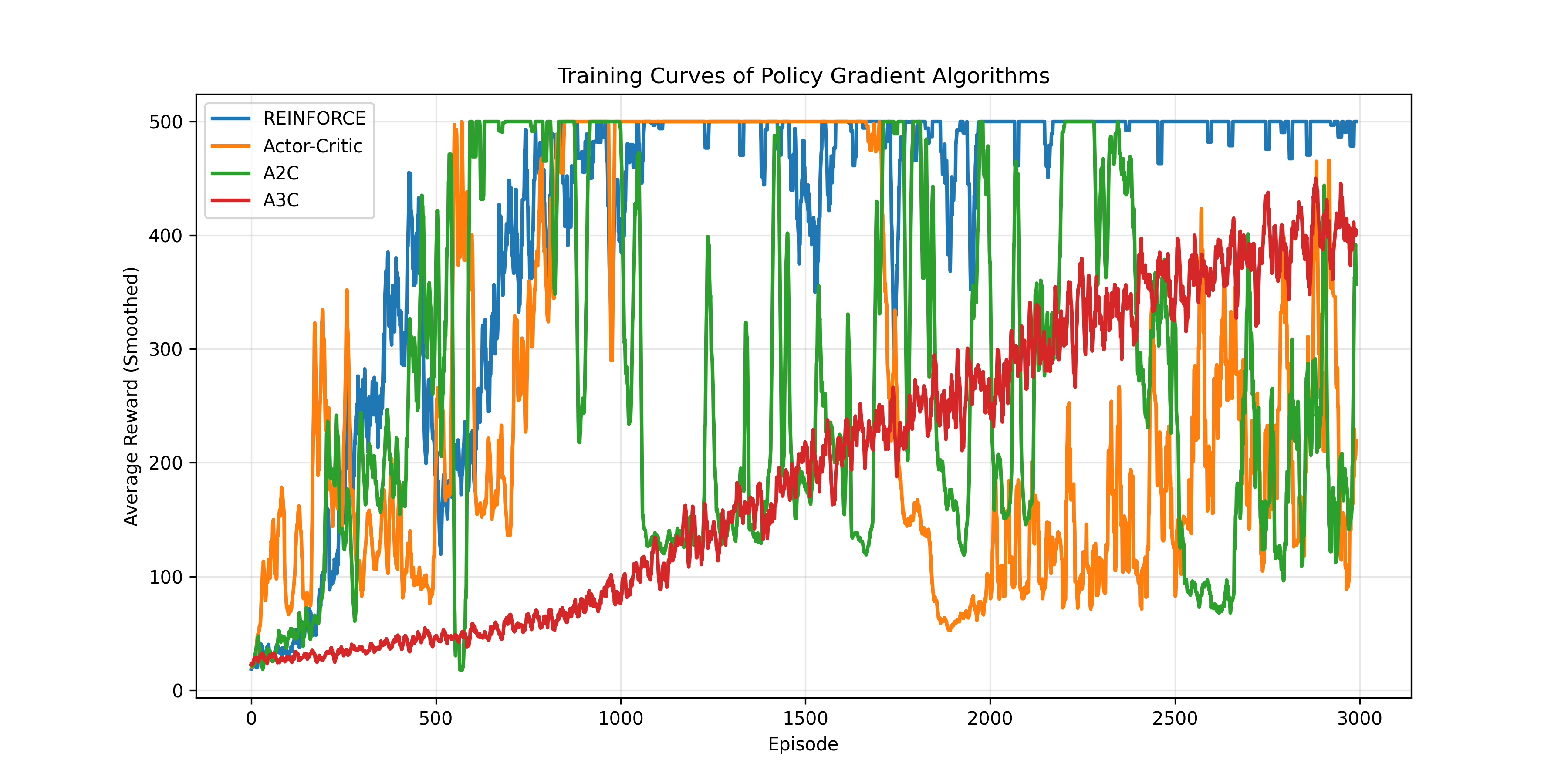
折线图
综合结论
-
REINFORCE:在CartPole环境中表现“全能”——最终性能最高、稳定性最好、收敛速度最快,是这四种模型中的最优选择。
-
A3C:虽收敛速度较慢,但最终性能和稳定性优于Actor-Critic和A2C,适合需要异步并行训练的场景。
-
Actor-Critic和A2C:在该环境中表现相对弱势,尤其是A2C,性能和稳定性都较差,可能需要调整超参数或网络结构来优化。
2. 优缺点与适用场景
| 算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| REINFORCE | 简单易实现,无偏差 | 方差大,收敛慢 | 小规模问题,教学演示 |
| Actor-Critic | 单步更新,收敛快 | 有偏差(Critic估计误差) | 中等规模游戏/机器人控制 |
| A2C | 方差小,稳定性好 | 需要精细调参 | 强化学习基准测试,实际应用 |
| A3C | 并行高效,样本多样性好 | 实现复杂,依赖多线程/多进程 | 大规模游戏(如Atari),实时控制 |
五、小白入门建议
-
先跑通REINFORCE,理解“轨迹回报驱动策略更新”的核心
-
再看Actor-Critic,体会“实时反馈”的优势
-
对比A2C和Actor-Critic,理解“优势函数”如何减少方差
-
最后挑战A3C,理解并行计算在强化学习中的价值
代码可直接运行(自动下载CartPole数据集),服务器环境下会自动保存结果图,无需担心交互问题。从简单算法开始,逐步感受强化学习从“笨办法”到“聪明操作”的进化!
➔➔➔➔点击查看原文,获取更多机器学习干货和资料!![]() https://mp.weixin.qq.com/s/Nw9M90js0wL-2EoGlGxrTw
https://mp.weixin.qq.com/s/Nw9M90js0wL-2EoGlGxrTw

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)