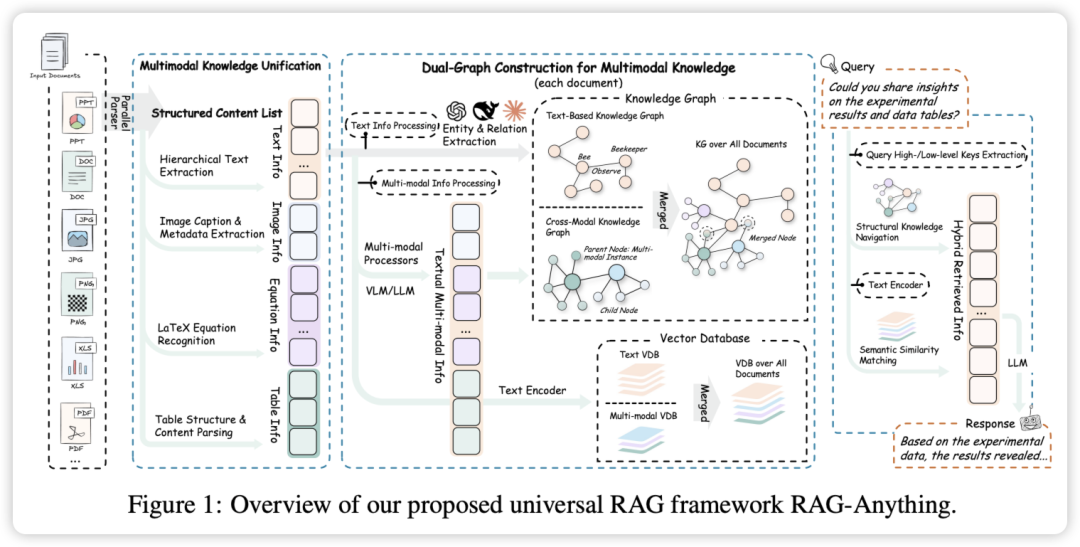
小白学大模型:RAG-Anything 统一多模态问答的RAG框架
RAG-Anything 建立了一种新的多模态知识访问范式,消除了现有系统中的架构碎片化,为处理复杂、真实的知识环境提供了全面的解决方案。
现有 RAG 框架几乎完全局限于文本内容。真实的知识库本质上是多模态的,包含文本、视觉元素(图表、图像)、结构化表格和数学表达式的丰富组合。
https://arxiv.org/pdf/2510.12323
https://github.com/HKUDS/RAG-Anything
RAG-Anything 建立了一种新的多模态知识访问范式,消除了现有系统中的架构碎片化,为处理复杂、真实的知识环境提供了全面的解决方案。RAG-Anything作出了如下改进:
- 统一的多模态表示:双图构建 (Dual-Graph Construction)
- 跨模态检索机制:跨模态混合检索 (Cross-Modal Hybrid Retrieval)
unsetunsetRAG-Anything 框架概述unsetunset
RAG-Anything 是一个统一的 RAG 框架,专门为解决现有系统仅限于文本的限制而设计,使 LLMs 能够利用来自图像、表格、公式和各种文本的异构多模态知识。
该框架由三个核心组件构成:
- 通用索引(Universal Indexing):用于多模态知识的统一表示。
- 跨模态自适应检索(Cross-Modal Adaptive Retrieval):结合结构导航和语义匹配。
- 知识增强的响应生成(Knowledge-Enhanced Response Generation):利用 VLM 进行信息合成。
1. 通用异构知识表示 (Universal Representation)
传统方法只是将文档解析为文本段落,而 RAG-Anything 引入了多模态知识统一 (Multimodal Knowledge Unification) 过程。
- 原子知识单元分解: 将原始输入分解为原子内容单元 ,其中 是模态类型(如 text, image, table, equation), 是相应的内容。
- 结构和语义完整性: 确保非文本元素(如图表、公式)与其标题、周围定义保持结构上的关联。
- 专业解析器: 使用专门的解析器处理不同内容类型(例如,LaTeX 公式识别、表格结构解析),以保证高保真提取。
RAG-Anything 采用双图策略来整合结构和语义信息:
| 图类型 | 目的 | 关键机制 |
|---|---|---|
| 跨模态知识图 (Cross-Modal KG) | 将非文本模态(图像、表格、公式)与其上下文环境可靠地关联起来。 | 1. 利用 VLM/LLM 为非文本单元生成详细描述 () 和实体摘要 ()。 |
| 2. 以非文本单元为锚点 (),构建图结构,包含belongs_to等边,实现模态特定性关联。 | ||
| 基于文本的知识图 (Text-based KG) | 捕获文本中的显式知识和语义连接。 | 遵循传统的 NER/RE 方法,直接从纯文本内容中提取实体和关系。 |
2. 跨模态混合检索 (Cross-Modal Hybrid Retrieval)
检索阶段结合了结构和语义两种互补机制,克服了传统 RAG 仅依赖单一模态语义匹配的限制:
机制一:结构化知识导航 (Structural Knowledge Navigation)
- 目标: 捕捉显式关系和多跳推理模式,特别是跨模态的连接。
- 方法: 从用户查询中识别关键词和实体,在统一知识图 上进行精确实体匹配,并进行策略性的邻域扩展(在指定跳数内)。
- 结果: 得到候选集 ,提供高层语义连接和结构性上下文。
机制二:语义相似性匹配 (Semantic Similarity Matching)
- 目标: 识别缺乏显式结构连接的语义相关知识。
- 方法: 在所有组件(块、实体、关系)的嵌入表 上,使用查询嵌入 进行密集向量相似性搜索。
- 结果: 返回按余弦相似度排名的 top-k 语义相似块 。
融合与排序 (Fusion and Ranking)
- 将两个机制的候选集合并:。
- 应用多信号融合评分 (Multi-Signal Fusion Scoring),整合结构重要性、语义相似度得分以及查询推断的模态偏好,以生成最终的排名结果 。
3. 从检索到合成 (From Retrieval to Synthesis)
- 构建文本上下文: 将检索到的所有组件(实体摘要、关系描述、块内容)的文本表示连接起来,并加入模态类型和层级来源的分隔符,作为 LLM 的输入。
- 恢复视觉内容: 对于多模态块,进行解引用 (dereferencing) 以恢复原始的**视觉内容 **。
- 联合条件生成: 响应由视觉-语言模型 (VLM) 联合生成,模型同时以查询 、组装的文本上下文 和解引用的视觉内容 为条件:
unsetunset实验设置与评估unsetunset
所有方法均使用 GPT-4o-mini 作为生成骨干 LLM;使用 text-embedding-3-large 嵌入模型和 bge-reranker-v2-m3 重排序模型。
- GPT-4o-mini: 强大的多模态 LLM,具有 128K Token 上下文窗口,可直接处理长文档,作为强基线。
- LightRAG: 一种图增强的 RAG 系统,但仅限于文本处理。
- MMGraphRAG: 一种多模态检索框架,构建统一知识图,但对表格和公式处理不够完善。
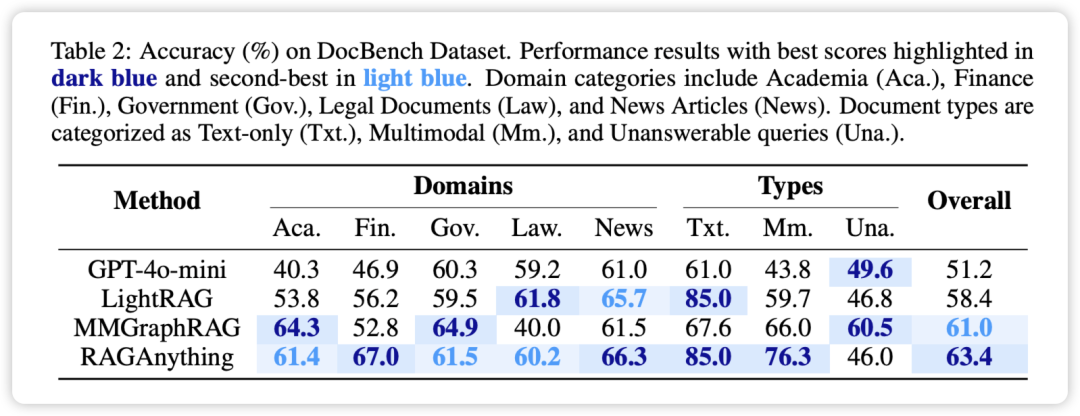
RAG-Anything 将文本、图像、表格和公式视为一等实体进行处理,而 LightRAG 仅处理文本,MMGraphRAG 缺乏对表格和公式结构信息的处理。RAG-Anything 通过双图构建策略保留了所有模态的结构关系。
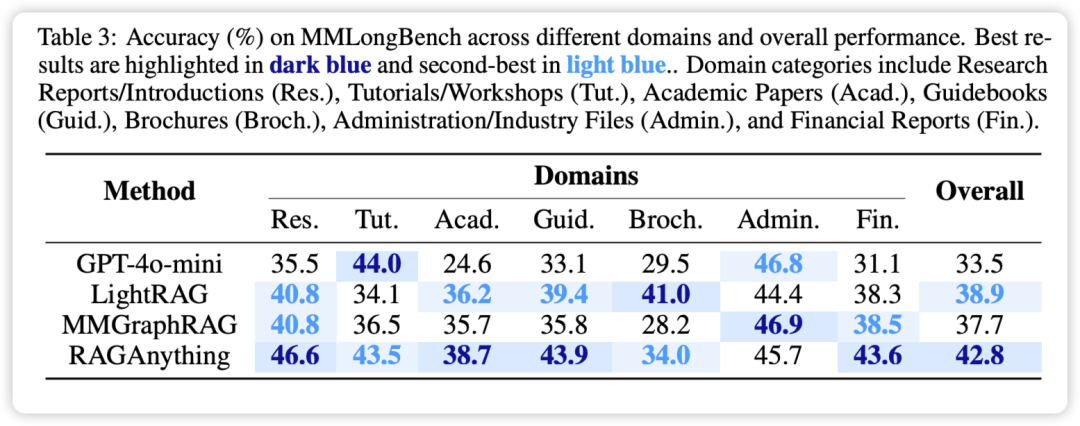
RAG-Anything 优势构建视觉布局图**,节点包含面板、轴标题、图例和标题,边编码了层级关系。这引导检索器精确聚焦到**风格空间面板**,避免了混淆,得到了正确答案。
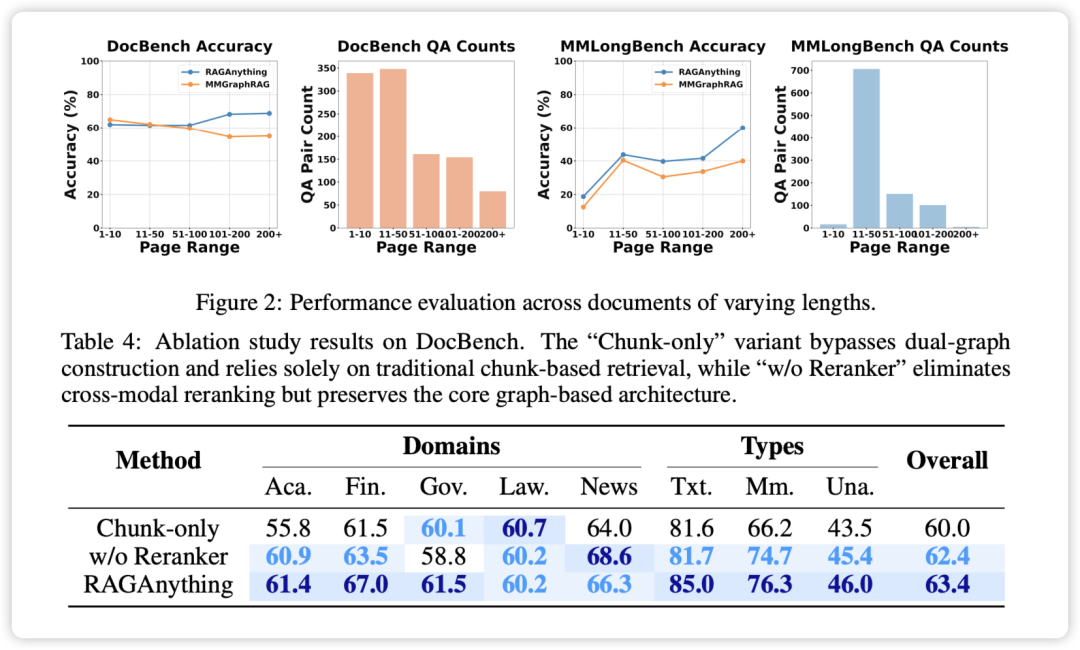
RAG-Anything 将表格转换为结构化图,节点包含行标题、列标题(年份)、数据单元格和单位,边捕获了 行-列-单元格 的关系。这使得系统能够精确导航到“Wages and salaries”行和“2020”列的交集单元格,确保了准确的数值提取。


unsetunsetRAG-Anything 代码解析unsetunset
使用的外部工具
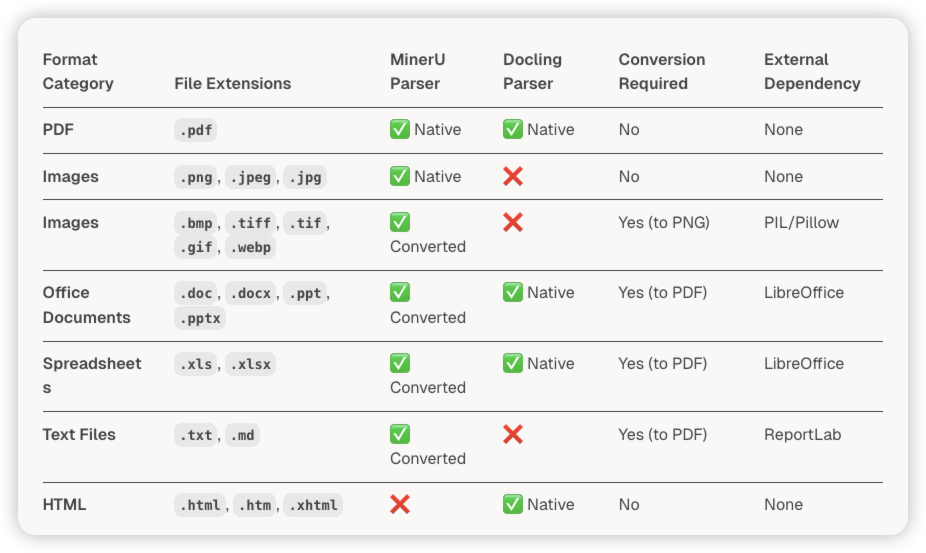
- MinerU 是 RAG-Anything 的主要文档解析引擎,负责从 PDF 和图像文档中高保真提取文本、图像、表格和公式。
- LibreOffice 是处理 Office 文件(
.doc,.docx,.ppt,.pptx,.xls,.xlsx)的关键。 - Pillow(Python Imaging Library)用于处理 MinerU 原生不支持的非标准图像格式。
- Docling: 作为 MinerU 的替代解析器,可以通过配置
PARSER环境变量或RAGAnythingConfig.parser来启用。
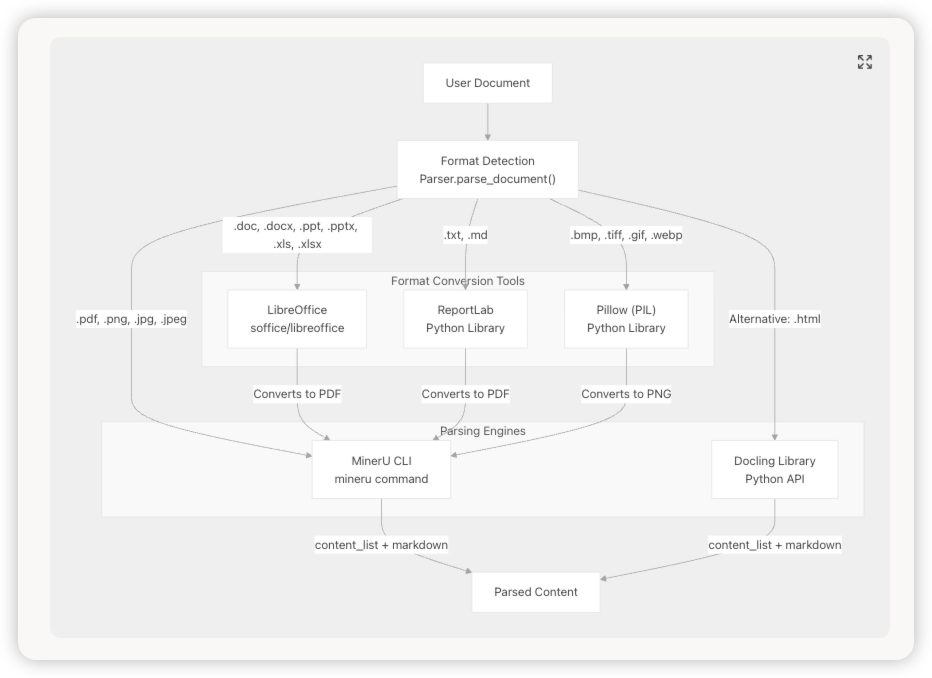
文档处理过程
文档解析 (Document Parsing) 处理文件格式、应用格式特定的转换(例如,Office 文件转 PDF),然后调用核心解析器(如 MinerU 或 Docling)提取内容。
内容理解与处理 (Content Understanding & Processing) 将内容明确区分为纯文本内容和多模态元素(图像、表格、公式等)。
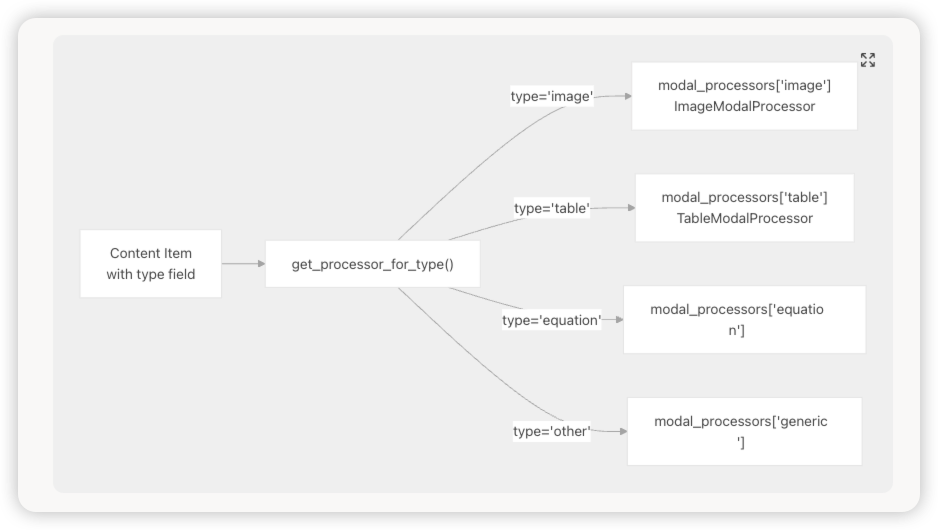
多模态分析引擎 (Multimodal Analysis Engine) 对 每个多模态项目(如图像、表格)都由相应的处理器并发处理。例如,图像可能需要 VLM 来生成详细描述,表格可能需要结构化解析。
知识图谱构建 (Knowledge Graph Construction) 从文本和多模态内容的增强描述中,提取实体和它们之间的关系。
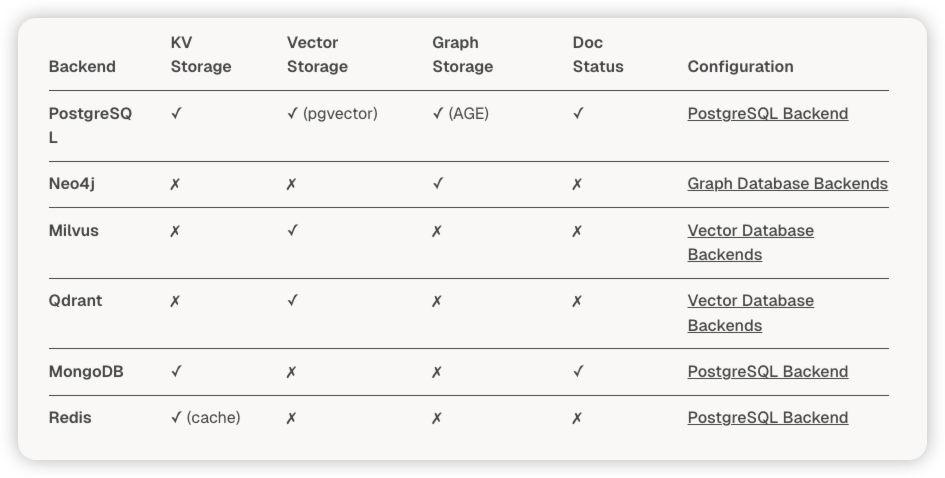
将处理后的内容合并到 LightRAG 的存储系统中。这包括将分块的嵌入存储到向量数据库(VDB),并将实体和关系存储到图数据库(KG)。
知识图谱构建与检索
调用 LightRAG 的 extract_entities 函数,对多模态分块进行批量实体和关系提取。这个过程利用 LLM 根据分块的增强描述来识别语义实体和关系。
- 节点 (Node) 结构: 提取的节点包含
entity_name、entity_type、description和一个指向其原始分块 ID 的source_id。 - 边 (Edge) 结构: 提取的边包含
src_id、tgt_id、关系描述 (description)、关键词 (keywords) 和一个权重 (weight),用于表示关系的强度。
知识图谱的数据被分散存储在多个 LightRAG 后端,以优化不同的检索需求:
| 存储位置 | 存储内容 | 用途 |
|---|---|---|
chunk_entity_relation_graph |
节点(实体)和边(关系) | 图遍历 和结构化检索的来源。 |
entities_vdb |
实体描述的嵌入 | 用于实体名称的向量相似性搜索。 |
relationships_vdb |
关系描述的嵌入 | 用于关系类型的向量相似性搜索。 |
full_entities |
文档 ID 关联的所有实体列表 | 用于文档级实体跟踪和去重。 |
混合检索机制
RAG-Anything 利用知识图谱启用跨模态混合检索,支持复杂的问答任务。检索策略战略性地结合了向量相似性搜索和图遍历:
- 结构化知识导航: 利用图遍历来探索实体之间的显式关系(包括
belongs_to)和多跳推理路径。 - 语义相似性匹配: 利用
chunks_vdb和entities_vdb进行密集的向量搜索,捕获隐式语义联系。
检索结果通过一个模态感知的融合评分机制进行排序,不同的关系类型被赋予不同的权重,例如:
belongs_to关系:权重 10.0(最高优先级)。- 跨模态关系:权重 5.0-8.0(中高优先级)。
- 模态内关系:权重 3.0-5.0(标准优先级)。
查询系统架构
RAG-Anything 通过继承 QueryMixin,提供了三种核心查询方法来满足不同的用户需求。
- 纯文本查询 (
aquery/query) 用于文本驱动的检索。** 直接在 LightRAG 知识库上执行搜索。 - VLM 增强查询 (VLM-Enhanced Query) 在检索到上下文中包含图像时,会自动利用视觉语言模型 (VLM) 进行深入的视觉分析。
- 带明确内容的多模态查询 (
aquery_with_multimodal) 允许用户将特定的多模态内容(例如一张待分析的图像、一张用户提供的表格或一个公式)作为查询的一部分,临时集成到知识图谱中。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献187条内容
已为社区贡献187条内容

所有评论(0)