python爬虫天猫商品数据及分析(1)
·
目的
获取目标商品的商品数据(店铺名称,店铺链接,商品名,价格,销量,省份)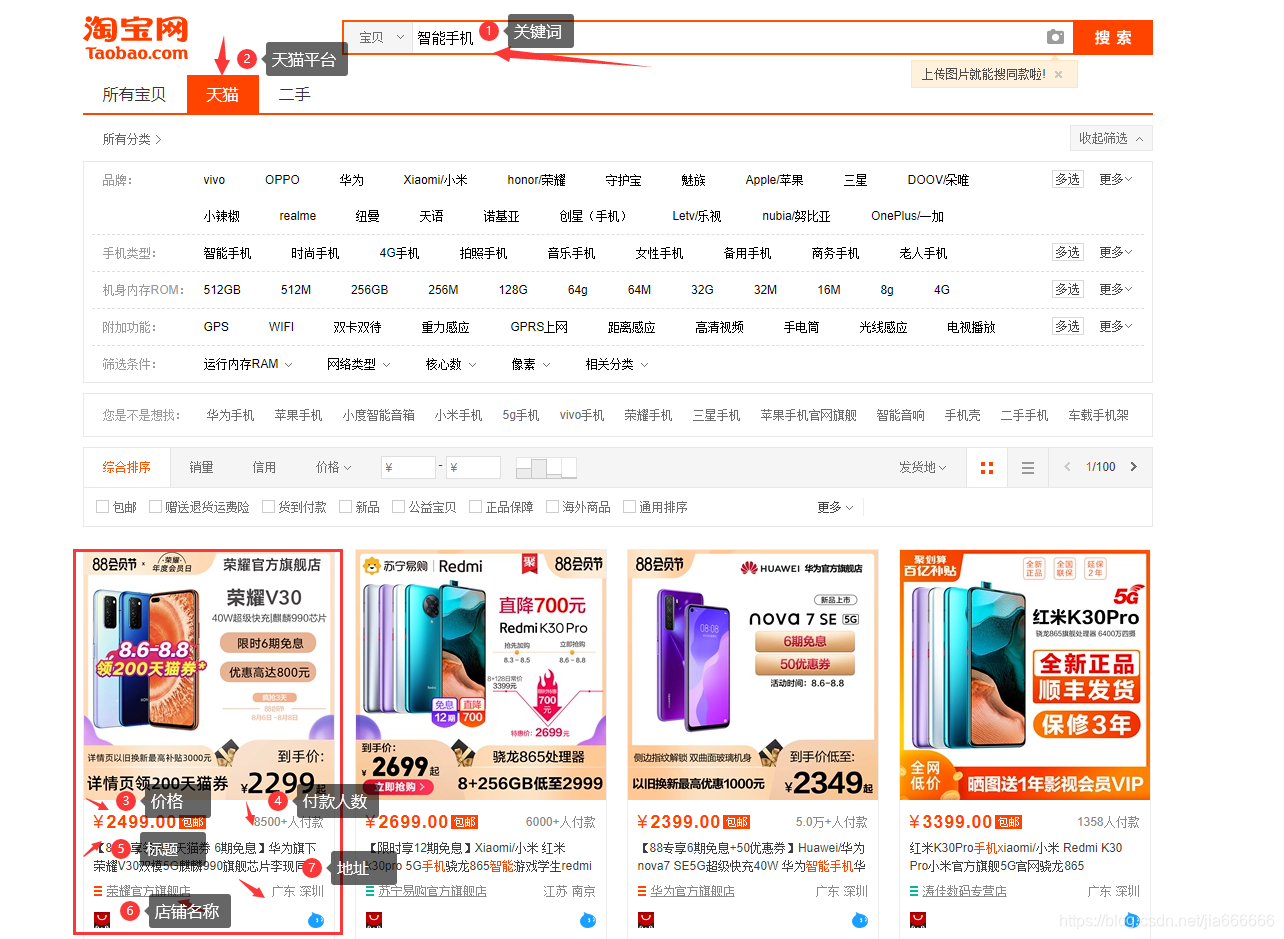
实现
程序会自动化控制谷歌浏览器,打开定义的淘宝首页,自动输入定义的关键词,点击搜索按钮
注意!!这时,界面会跳转到登陆界面,程序预留20s时间用于淘宝二维码扫码登陆,建议提前准备好扫码操作
完成扫码操作后,后续程序会自动点击天猫平台,然后完成不停的翻页操作,直至最后一页结束运行。
后台会进行网页信息的解析,从中提取出(店铺名称,店铺链接,商品名,价格,销量,省份)写入本地文件。用于后面的数据分析及可视化操作。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
__title__ = ''
__author__ = 'jia666666'
__time__ = '2020/8/06'
"""
import re,time
from pyquery import PyQuery as pq
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
#TODO 1 界面可视
browser=webdriver.Chrome()
#TODO 2 界面不可视,后台运行
# browser=webdriver.PhantomJS()
# browser.set_window_size(1400,900)
wait=WebDriverWait(browser, 10)
def search(kyes):
print('正在搜索')
try:
#获取淘宝主页
browser.get('https://taobao.com')
#找到搜素框
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
#找到搜素按钮
submit=wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
#输入搜索内容
input.send_keys(keys)
#点击搜索按钮
submit.click()
# #获取总的页数
# total= wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total")))
time.sleep(20)
#browser.find_element_by_id('#tabFilterMall').click()
browser.find_element_by_link_text('天猫').click()
print('点击天猫成功')
#店铺名称,店铺链接,商品名,价格,销量,省份
n = '../file/CSV/' + keys + '-all.csv'
with open(n, 'a+', encoding='utf-8') as f:
productlist = '店铺名称' + ',' + '店铺链接' + ',' + '商品名' + ',' + '价格' + ',' + '销量' + ',' + '省份' + '\n'
f.write(productlist)
# 获取总的页数
# total = wait.until(
# EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total")))
#淘宝搜索页面默认含有100页商品
total=100
#TODO 获取产品信息,执行函数
get_profucts()
#返回页数信息
return total
#判断超时
except Exception as e:
print(e)
#重新执行
#return search()
def next_page(page_number):
#提示信息
print('正在翻页',page_number)
try:
#定位到页码输入框
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")))
#定位到确定按钮
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
#页码框情况
input.clear()
#输入页码
input.send_keys(page_number)
#点击确定翻页
submit.click()
#判断高亮当前页码,确保是否成功加载
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > ul > li.item.active > span"),str(page_number)))
#TODO 执行函数,获取该页所有的产品信息
get_profucts()
#超时重新加载
except TimeoutException:
next_page(page_number)
def get_profucts():
#等待,确保产品列表加载完成
#print('deafda')
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#mainsrp-itemlist .m-itemlist .items .item')))
#print('112')
#获取网页源码
html=browser.page_source
#PyQuery解析
doc=pq(html)
#信息提取
#print(doc)
items=doc('#mainsrp-itemlist .items .item').items()
#print(list(items[0]))
#保存数据
# n = time.strftime("%Y-%m-%d") +"bak.CSV"
n='../file/CSV/'+keys+'-all.csv'
fw = open(n, 'a+', encoding='utf-8')
for item in items:
fw.write(item.find('.shop').text() + ',' +
item.find('.pic a').attr('href') + ',' +
item.find('.title').text().replace(' ', '').replace(',','') + ',' +
item.find('.price').text().strip().replace('¥', '').replace('.00', '') + ',' +
item.find('.deal-cnt').text()[:-3].replace('.', '').replace('万', '000').replace('+', '') + ',' +
item.find('.location').text().split(' ')[0] +
'\n')
def main(keys):
try:
#开始搜索
total=search(keys)
# print(total)
# #总页数提取
# total= int(re.compile('(\d+)').search(total).group(1))
#循环遍历所有页数
for i in range(2,101):
#print(i)
next_page(i)
print('信息写入完成,可以查看文件.')
# 浏览器关闭
browser.close()
except Exception:
print('错误了,请检查')
finally:
pass
if __name__ == '__main__':
keys='智能手机'
main(keys)
本地文件写入


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)