私有化部署DeepSeek + RAGFlow,技术小白也能轻松学会_私有化部署deepseek ragflow
本文分享了在无GPU的本地电脑上部署DeepSeek R1大模型与RAGFlow的实践过程。作者使用AMD Ryzen 5 5600G处理器、16GB内存的Windows 11环境,通过虚拟机运行CentOS 7.9和Docker完成部署。步骤包括:安装Ollama并下载DeepSeek模型(7B和1.5B版本)、配置RAGFlow完整版(含Embedding模型)、解决Elasticsearch
这期内容分享下在我们个人本地电脑私有化部署 DeepSeek R1 + RAGFlow,也想观察下在没有GPU的机器上跑起来体验如何?
这期分享全程操作的干货内容,言简意赅,不要怕学不会,现在部署大模型已经很简单了。照着我说的一步步做,一定能成功!

① 我本地的环境
AMD Ryzen 5 5600G 3.90 GHz
16.0 GB (15.4 GB 可用)
1TB固态
没有独显(哈哈)
Windows 11 专业版
本地虚拟机
CentOS Linux release 7.9.2009 (Core)
安装好 Docker,这个不会可以问AI,Linux几行命令就搞定
以上环境相信大部分朋友都具备。
② 下载和安装ollama
# 下载地址
https://ollama.com/download/windows
# 配置下环境变量
# ollama 默认只允许本地访问,不配置的话我们虚拟机不能和本地ollama连接
OLLAMA_HOST 0.0.0.0:11434
# 模型下载位置,推荐配置下
OLLAMA_MODELS D://models/xxx
# 傻瓜式下一步安装,安装后最好重启下电脑
③ 下载 DeepSeek 模型
# 这里推荐下载7b,大概4G,要一会儿
ollama run deepseek-r1:7b
# 如果就是学习下步骤,也可以下1.5b,快
ollama run deepseek-r1:1.5b
# 我2模型个都下了,下的过程中,可能到最后会很慢
# 不要怕,直接Ctrl + C结束
# 再执行下载,他有断点续传,再下就发现很快
# 跑起来就直接进对话指令了,类似如下
C:\Users\sailen>ollama run deepseek-r1:7b
>>> Send a message (/? for help)
# 可以输入点内容测试下速度,例如:介绍下你自己
# 由于我没GPU,7b回答的时候有点慢,但勉强能推理
# 1.5b的速度很快了,但是问了几个问题
# 说实话很拉胯,不能用,只剩快,哈哈
>>> 介绍下你自己
<think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
</think>
您好!我是由中国的深度求索(DeepSeek)公司开发的智能助手DeepSeek-R1。如您有任何任何问题,我会尽我所能为您提供帮助。
# 输入 /bye,可以退出 对话
# 再输入 ollama list 查看本地下载的模型
>>> /bye
C:\Users\sailen>ollama list
NAME ID SIZE MODIFIED
deepseek-r1:7b 0a8c26691023 4.7 GB 4 days ago
deepseek-r1:1.5b a42b25d8c10a 1.1 GB 4 days ago
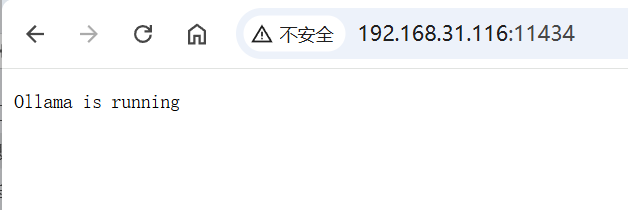
# 此时,浏览器里用你的内网IP访问下11434
http://192.168.31.116:11434/
# 看看 显示 Ollama is running 即可
④ 下载、部署RagFlow
远程连接虚拟机,准备下载RagFlow
# 先下下ragflow源码
git clone https://github.com/infiniflow/ragflow.git
# 修改下环境变量文件
# 目的:下载RagFlow完整版,含Embedding模型
# 不然你本地还需要部署一个Embedding模型
cd ragflow
vi docker/.env
# 注释轻量版本
# RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim
# 打开完整版本
RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0
# cd ragflow
# 准备跑吧,拉镜像需要点时间哈,完整版9多G
docker compose -f docker/docker-compose.yml up -d
# 最好配置下Docker国内代理
vi /etc/docker/daemon.json
# 配置内容:
{
"registry-mirrors": ["https://docker.1ms.run"]
}
# 下载过程中可能提示连接失败,多重新尝试几次即可
# 另外,我遇到一个问题,跑完后,一个es容器没下载成功
# 一开始不清楚原因,用docker logs 看了下ragflow-server容器的日志
# 发现一直在连 es,无法连接
# 找了下解决方案:
https://github.com/infiniflow/ragflow/issues/4038
# 还是一个open状态的问题,看最后那个大佬的内容
I was able to solve it by moving in the folder /docker and doing docker compose down then docker compose up and elastic search installed itself
# 于是,执行下
docker compose down
docker compose up
# 嘿嘿,就检测到es的容器没下载成功,然后一顿下载
# 完事后,再重启下ragflow-server容器
# 观察下日志,好了
# 浏览器访问下试试
http://192.168.31.101/
⑤注册账号、登录
没啥好说的,输入邮箱,名称,密码就可以了
⑥ 配置模型提供商
我英文水平一般,先切换到中文,哈哈
点击头像,找到左侧模型提供商
找到ollama,点击添加模型
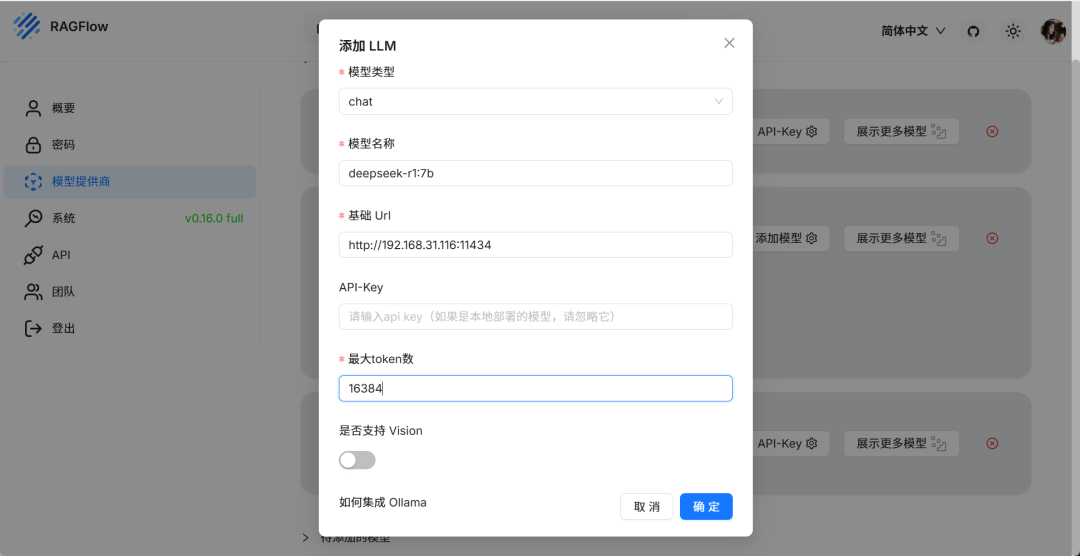
参考我这图上面配置就行,一看就懂哈。
点击确认,可能要转一下下,然后就看到列表上有Ollama了
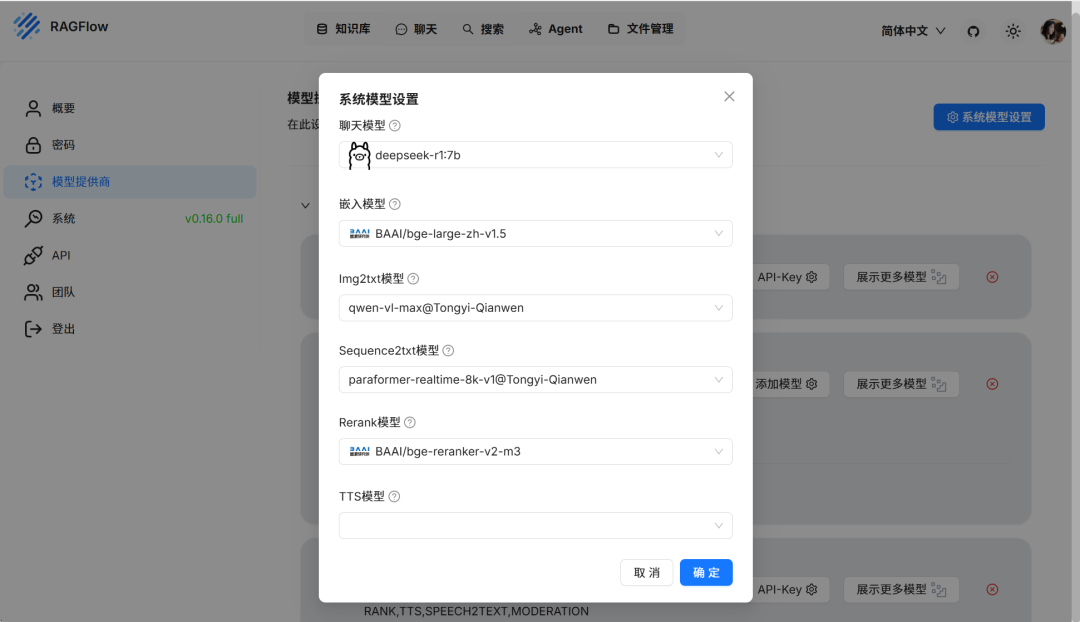
⑦ 系统模型设置
再点击系统模型设置,参考我这样配置就行
⑧ 创建知识库
输入名称,选择语言,选择嵌入模型
解析方法没啥特殊的,就选General就行
其它的不懂就默认,先别管
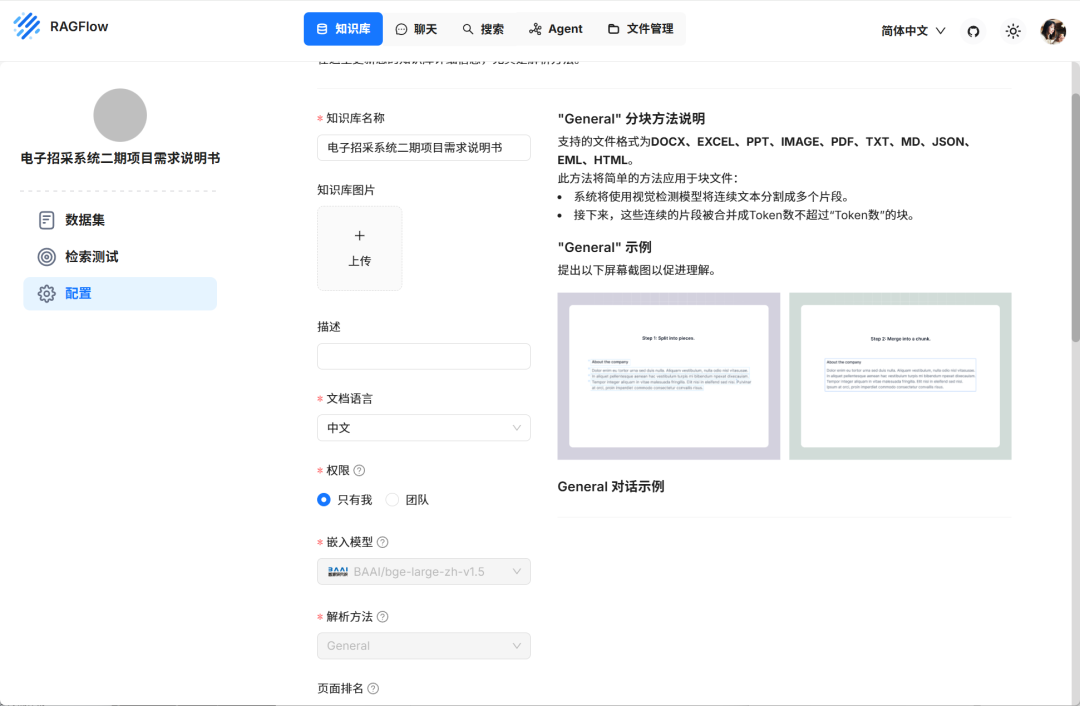
然后新增一个你本地的文档
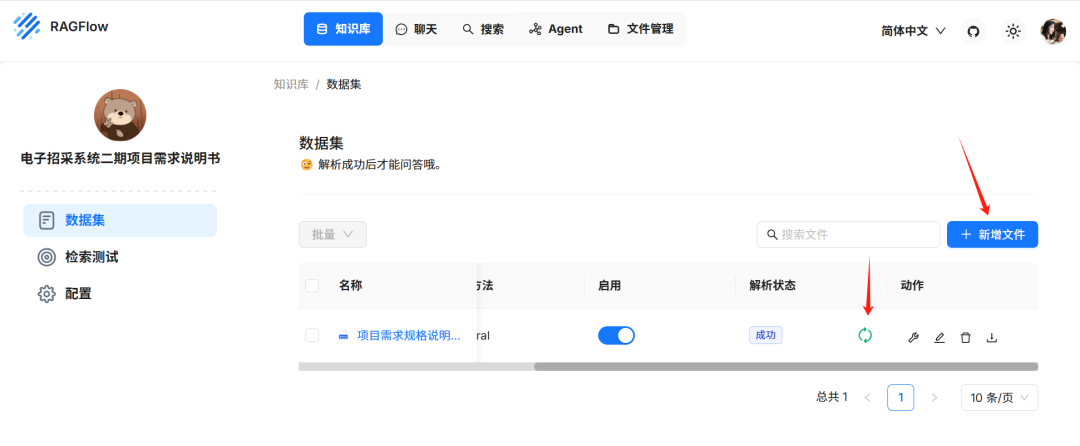
传上来后,点击下执行下解析,可能需要几分钟
解析状态显示 成功 就好了
由于没有GPU加持,向量化过程全靠CPU算
我这个文档 28M,12核CPU全部接近 跑满状态,大概跑了5分钟
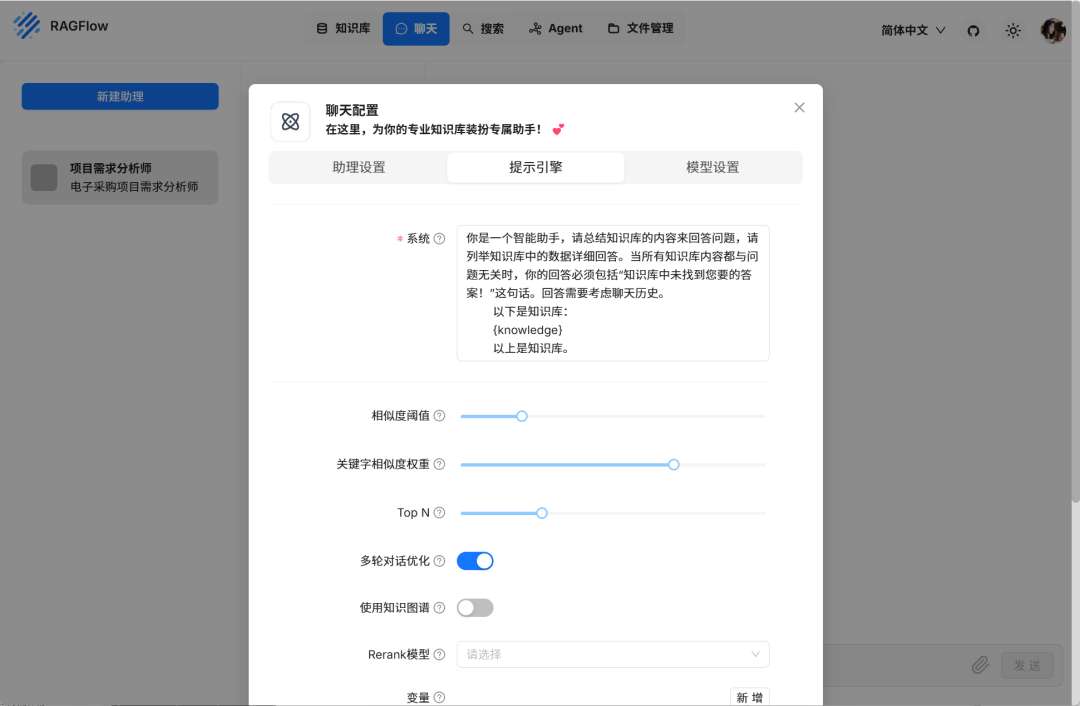
⑨ 新建助理,创建聊天
在助理设置里,就填写个名字,愿意的话就改下开场白,最重要吧下面的知识库选为你自己刚刚刚刚创建的
切换到提示引擎们可以按你的需求改下提示词其它也不用动
切换到模型设置,选择 ollama 图标里的 DeepSeek 7b就好了
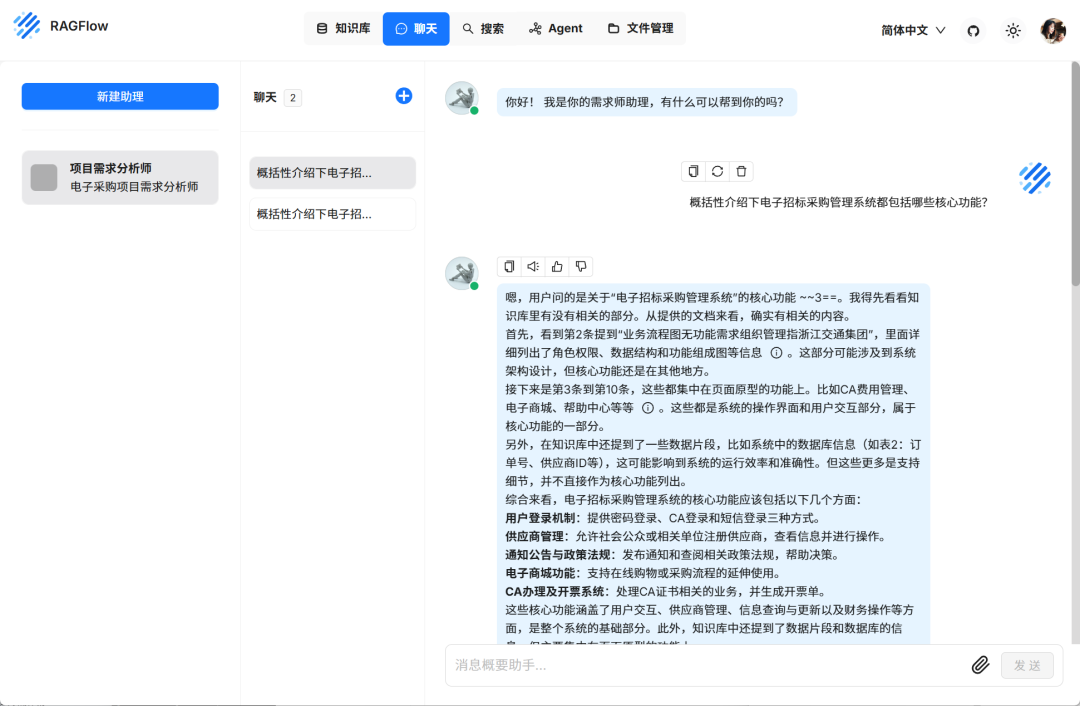
然后就愉快地聊天吧!
看完后是不是觉得简单吧?RagFlow 与 Docker 把很多技术细节给你屏蔽了,不用关心需要部署数据库、Redis、ES、minio啥啥的,模型相关的一些参数配置也都是给你默认配置了,上手很容易,缩一缩,这都2025年了,搭建一个完全私有化的RAG系统也没那么难。
实际上RAGFlow有很多细节支持你配置和自定义,需要你花点时间去测试和研究。
还提供了丰富的API,供你业务系统调用,多爽~~~
这些内容后面有空,我会继续写几篇文章逐一介绍,敬请关注!
实际运行情况
现实很残酷,你知道我得到上面那个推理结果代价有多大吧?
内存99%,磁盘100%,CPU从持续一段时间100%,到后面稳在35%左右
然后,大概每隔1分钟,响应2句话,等啊等
我开的其它应用有的就报错了,然后闪退,然后就是鼠标键盘都不好使了
大概半小时,结果出来了,但系统已经瘫痪了
本来想截屏的,卡住没反应了
最终,想按各种快捷键杀进程都没反应,强制按主机电源键关机重启……
反正是玩一下嘛,还是挺好玩的哈哈,感兴趣可以看下我的视频号里的内容
智享视界8
我重启后不敢用 7b 模型了,改用了1.5b 进行推理,不会还会死掉
速度快了不少,但结果也不是太准确了……
好了,大家玩的时候,还是先玩下1.5b吧,玩 7b+ 的有 GPU 可以放心玩哈!!!
都看到这里了,点个关注吧,我后面还会细讲 RagFlow 产品相关的深入使用哦!
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 5
5 0
0- 0



 已为社区贡献129条内容
已为社区贡献129条内容

{kind=link}
所有评论(0)