超图结构熵增强的推荐预训练
本文介绍EPRHSE框架,本框架针对主流推荐模型受训练数据稀疏性、图结构利用率不足,且现有超图学习存在拓扑结构未充分挖掘、全局依赖难捕获、信息融合复杂抽象的难题,创新性地设计双预训练任务、超图结构熵优化方法与超图池化机制。团队通过双预训练任务构建辅助超图以缓解交互稀疏性、超图结构熵优化构建高维编码树实现用户 / 物品分层聚类、超图池化与解池层增强 HGCN 聚合高阶信息,突破推荐系统中数据稀疏与结
本文介绍来自北航彭浩教授团队的最新科研成果-EPRHSE框架,针对主流推荐模型(如GCN、HGNN等)受训练数据稀疏性、图结构利用率不足,且现有超图学习存在拓扑结构未充分挖掘、全局依赖难捕获、信息融合复杂抽象的难题,创新性地设计双预训练任务、超图结构熵优化方法与超图池化机制。团队通过双预训练任务构建辅助超图以缓解交互稀疏性、超图结构熵优化构建高维编码树实现用户 / 物品分层聚类、超图池化与解池层增强 HGCN 聚合高阶信息,突破推荐系统中数据稀疏与结构利用不充分的瓶颈,为推荐系统性能提升与冷启动场景稳定性保障提供高效方案,在 Steam、XMrec 系列等五个真实数据集上优于13个代表性推荐方法。

论文名称:Enhanced Pre-training for Recommendation via Hypergraph Structural Entropy
论文链接:https://penghao-bdsc.github.io/papers/EPRHSE@TOIS2025(final).pdf
代码链接:https://github.com/SELGroup/EPRHSE
1.动机
随着信息通信技术的快速发展,多平台同步传播相同内容的现象日益普遍,导致信息过载问题加剧——用户被海量可获取信息淹没,难以有效筛选并利用相关信息,还易因信息失控产生信息疲劳、心理冲突、压力与焦虑,最终影响生产效率与创新能力。在此背景下,推荐系统作为缓解信息过载的核心技术,已广泛应用于电商网站、视听平台、社交媒体等领域。其通过挖掘用户兴趣偏好、历史行为(购买、搜索、点击等)及物品评价数据,为用户推荐合适物品,核心在于从用户-物品交互历史与场景中提取物品特征、建模用户偏好[1],进而缓解信息过载[2]与信息茧房[3] 问题,降低用户在复杂大数据环境中的决策与交易成本,提升决策质量。
为实现精准推荐,研究人员先后提出多种方法,但均存在明显局限:早期内容过滤[4]与协同过滤[5]依赖用户或物品相似度,受限于评分、属性等低维特征及基础分类/排序算法[6],表达能力有限;矩阵分解[7]与逻辑回归[8]虽能通过学习社交网络中的latent特征提升稀疏数据处理能力,却在缺乏用户历史行为数据时无法有效推荐;图神经网络(GNN)[9]虽能捕捉用户-物品复杂拓扑结构以优化协同过滤,但其性能依赖大量历史交互数据,在冷启动场景中泛化性差[10]。此外,GNN仅关注pairwise(成对)交互,忽略数据中的复杂高阶关系;虽有研究将超图引入推荐系统并开发超图卷积网络模型[11],且形成 “预训练 + 超图 + 注意力” 研究范式(如UPRTH[12] 通过任务超图与TA层融合多任务信息),但现有超图相关模型仍面临三大关键挑战,难以充分发挥超图建模优势与预训练价值。
挑战 1:如何充分挖掘超图拓扑结构以释放高阶关系建模潜力?
超图的核心优势在于建模高阶关系(如多用户共享偏好、多物品互补关系),而现有超图学习研究未充分利用超图的拓扑结构——这一影响推荐有效性的关键因素。同时,现有研究明确指出,超图在建模高阶用户关系方面的潜力仍未被充分开发,且已有研究证实拓扑结构对信息检索、处理与决策过程具有显著影响。因此,如何有效学习超图拓扑结构,将其与用户-物品交互特征结合以精准建模高阶关系,仍是超图推荐领域的核心难题。
挑战 2:如何突破HGCN局部依赖限制以捕捉全局依赖与群体表示?
在模型架构层面,单纯采用超图卷积网络(HGCN)难以充分捕捉全局依赖关系。一方面,HGCN过度依赖局部高阶邻域结构,限制了其对全局网络中“社会影响扩散过程”的建模能力;另一方面,间接社会连接与历史用户-物品交互均对识别用户偏好群体至关重要,而现有HGCN无法同时捕捉 “直接邻居依赖” 与 “全局网络中的群体表示”。这导致模型难以挖掘用户/物品的群体级模式,进而影响推荐的准确性与泛化性。
挑战 3:如何简化信息融合过程以提升模型可解释性与可靠性?
现有“预训练+超图+注意力”范式的模型(如UPRTH),多依赖注意力机制或类似策略融合异质社会信息(如用户属性、物品关系),但该融合过程基于多样GCN架构,引入过度复杂性与抽象性,严重损害模型可解释性。例如,UPRTH通过TA层将辅助任务嵌入融合到主任务超边嵌入中,但物品图的超边嵌入(编码物品共享共购模式)与辅助任务的用户嵌入(捕捉用户年龄、职业等属性)在语义上并不等价,导致融合过程存在主观性,无法实现信息的合理、有效整合,进一步增加了模型优化难度。
为应对上述挑战,作者提出EPRHSE(基于超图结构熵的增强推荐预训练框架),通过创新双预训练任务、超图结构熵优化方法与超图池化机制,系统性解决超图拓扑利用不足、全局依赖缺失、信息融合复杂的问题,以提升推荐性能、稳定性与可解释性。其总体框架图如下图1所示。
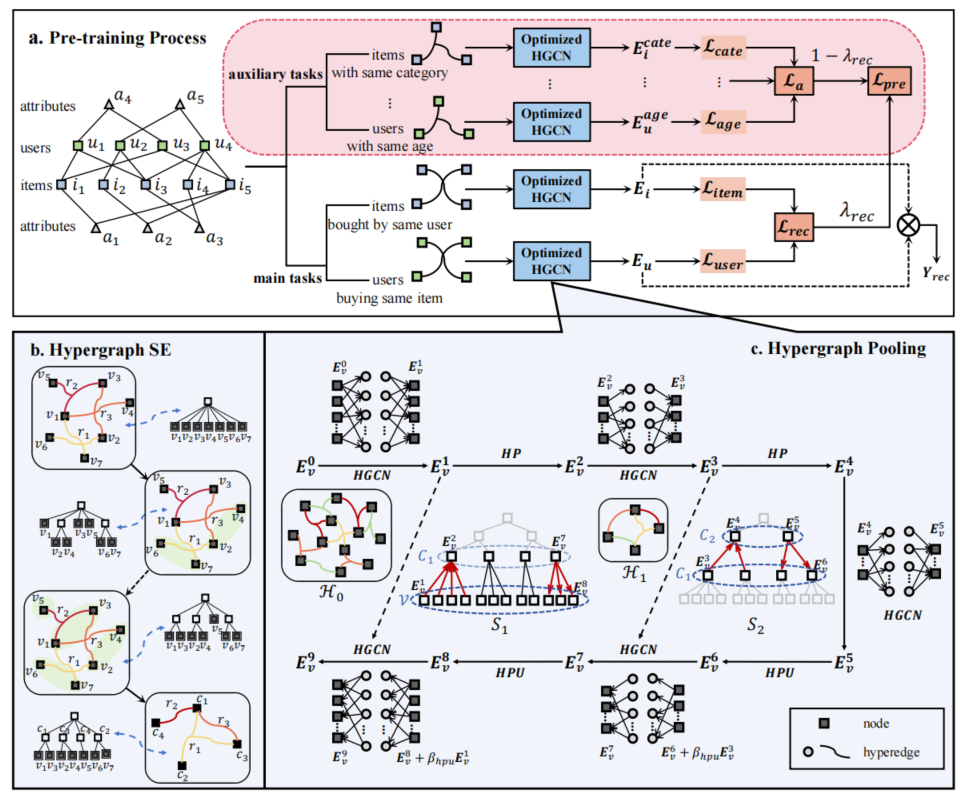
EPRHSE的核心是通过超图建模高阶关系+结构熵优化分层结构 + 池化聚合全局信息,编码推荐系统的拓扑结构,解决传统推荐模型训练数据稀疏、图结构利用不足、全局依赖难捕捉的问题,最终提升用户/物品嵌入质量与推荐性能。其目标是让模型既能捕捉用户-物品间的异质关系,又能挖掘超图的全局拓扑特征,同时避免复杂信息融合带来的可解释性问题。
2.预备知识
在本节中,介绍推荐任务的基本定义与概念、超图编码器的结构及信息聚合方法、结构信息理论在推荐框架中的应用、结构熵的基本概念、超图融合机制(TA 层)—— 该机制将在消融实验中添加至 EPRHSE 模型,以作进一步探讨。

2.1推荐任务
推荐任务旨在根据给定的用户 - 物品交互信息,为每个用户确定物品的最优排序。该信息包含两个独立的节点集合(用户集 𝑈 𝑈 U和物品集 𝐼 𝐼 I)以及用户 - 物品交互边 E u , i E_{u,i} Eu,i。因此,用于表示用户 - 物品交互关系的图可表示为 G = ( U , E u , i , I ) G=(U,E_{u,i},I) G=(U,Eu,i,I)。在针对某个用户的个性化推荐任务 T r e c T_{rec} Trec中,目标是在图 G G G中预测出该用户尚未交互过的物品列表 i 1 , i 2 , . . . , i m {i_1,i_2,...,i_m} i1,i2,...,im。物品排序越靠前,用户与这些物品发生交互的可能性就越高。
2.2超图编码器
超图由节点集 V \mathcal{V} V和超边集 E h y p e r \mathcal{E}_{hyper} Ehyper组成,记为 H = ( V , E h y p e r ) \mathcal{H}=(\mathcal{V},\mathcal{E}_{hyper}) H=(V,Ehyper)。与普通图不同,超图的超边可连接多个节点,代表一组节点间的关联,而非仅局限于成对节点间的关系。通常,超图中节点与超边的关系通过二部图矩阵 A G A_G AG来表征,具体记为 A G = ( a i , j ) ∈ { 0 , 1 } ∣ V ∣ × ∣ E h y p e r ∣ A_G=(a_{i,j}) \in {\{0,1\}}^{|\mathcal{V}|\times|\mathcal{E}_{hyper}|} AG=(ai,j)∈{0,1}∣V∣×∣Ehyper∣,其中 a i , j a_{i,j} ai,j表示节点 v i v_i vi与超边 e j e_j ej是否相连。
针对超图数据的表示学习,研究人员提出了超图神经网络。对于超图中的每个节点,超图卷积神经网络(Hypergraph Convolutional Neural Network, HGCN)编码器通过融合其相邻超边的信息,迭代更新该节点的表示;与之相对,超边的信息则通过融合其相邻节点的信息来表示。通过这种方式,信息可借助超边进行传递,从而学习到包含一跳邻居节点信息的表示,且该过程可通过堆叠多个编码器实现传播。本文模型中使用的超图编码器可表示为:
E v l + 1 = ( D e ) − 1 ⋅ A G ⋅ E e l = ( D e ) − 1 ⋅ A G ⋅ ( B v ) − 1 ⋅ A G ⊤ ⋅ E v l , ( 1 ) \mathbf{E_v^{l+1}=(D_e)^{-1}\cdot{A_G}\cdot{E_e^l}=(D_e)^{-1}\cdot{A_G}\cdot{(B_v)^{-1}}\cdot{{A_G}^{\top}}\cdot{E_v^l}},(1) Evl+1=(De)−1⋅AG⋅Eel=(De)−1⋅AG⋅(Bv)−1⋅AG⊤⋅Evl,(1)
其中, E v l \mathbf{E_v^l} Evl和 E v l + 1 \mathbf{E_v^{l+1}} Evl+1分别为超图编码器中节点集的输入嵌入表示和输出嵌入表示。 A G A_G AG为节点与超边的二部图矩阵, D e D_e De为超边的度矩阵, E e l \mathbf{E_e^l} Eel表示当前迭代中超边集的嵌入表示。通过点积运算,节点集的嵌入表示会更新为其相邻超边嵌入表示的加权和:一条超边连接的节点越多,其对每个节点的影响就越小。此外,超边集的嵌入表示 E e l \mathbf{E_e^l} Eel可通过运算 ( B v ) − 1 ⋅ A G ⊤ ⋅ E v l \mathbf{(B_v)^{-1}\cdot{{A_G}^{\top}}\cdot{E_v^l}} (Bv)−1⋅AG⊤⋅Evl得到,其中 B v B_v Bv为超图中节点的度矩阵。类似地,超边集的嵌入表示也会通过点积运算,更新为其相连节点嵌入表示的加权和:一个节点连接的超边越多,其对每条超边的影响就越小。
2.3结构信息理论
结构信息理论最初提出的目的是衡量图中包含的结构信息。具体而言,该理论旨在计算同构图 G = ( V , E ) \mathcal{G=(V,E)} G=(V,E)的结构熵,该熵反映了同构图在进行层次划分时的不确定性。在本文研究中,层次划分结果由一种称为编码树的树结构表示。下文将介绍无向图中的编码树与 k k k维结构熵。
编码树。
图 G \mathcal{G} G的编码树定义为一棵有根树 T \mathcal{T} T,其具有以下性质:
(1)对于编码树 T \mathcal{T} T中的每个节点 α \alpha α,存在图 G \mathcal{G} G中顶点集 V \mathcal{V} V的一个子集 T α T_{\alpha} Tα与之对应。
(2)编码树的根节点 λ \lambda λ对应的顶点子集 T λ = V T_{\lambda}=\mathcal{V} Tλ=V。
(3)节点 α \alpha α的子节点记为 α i \alpha_i αi,按 i i i递增顺序从左到右排列。子节点 α i \alpha_i αi的父节点记为 α i − = α \alpha_i^-=\alpha αi−=α。
(4)若节点 α \alpha α有 L L L个子节点,则各子节点对应的顶点子集 T α i T_{\alpha_i} Tαi互不相交,且 T α = ∪ T α i T_{\alpha}=\cup{T_{\alpha_i}} Tα=∪Tαi。
(5)树中的每个叶子节点 v v v对应图 G \mathcal{G} G顶点集 V \mathcal{V} V中的一个单独顶点。
k k k维编码树的高度为 k k k(根节点高度为 0)。直观来看,编码树体现了图顶点的层次化社区划分:父节点对应一个大社区,子节点则是该大社区下的小社区。
结构熵。
由编码树 T \mathcal{T} T确定的同构图 G \mathcal{G} G,其结构信息定义为:
H T ( G ) = − ∑ α ∈ T , α ≠ λ g α v o l ( G ) log v o l ( α ) v o l ( α − ) , ( 2 ) H^\mathcal{T}(\mathcal{G}) = -\sum_{\alpha \in \mathcal{T}, \alpha \neq \lambda} \frac{g_\alpha}{vol(\mathcal{G})} \log \frac{{vol}(\alpha)}{{vol}(\alpha^-)},(2) HT(G)=−α∈T,α=λ∑vol(G)gαlogvol(α−)vol(α),(2)
其中, v o l ( G ) vol(\mathcal{G}) vol(G)表示图 G \mathcal{G} G中所有顶点的度数之和。 v o l ( α ) {vol}(\alpha) vol(α)为子集 T α T_\alpha Tα的体积,等于顶点子集 T α T_\alpha Tα中所有顶点的度数之和。 g α g_\alpha gα表示从顶点子集 T α T_\alpha Tα到顶点子集 V / T α \mathcal{V}/T_\alpha V/Tα的所有边的权重之和,可理解为顶点子集 T α T_\alpha Tα外部顶点到 T α T_\alpha Tα内部顶点的所有边的权重总和,或所有割边的权重总和。 g α v o l ( G ) \frac{g_\alpha}{vol(\mathcal{G})} vol(G)gα表示随机游走进入 T α T_\alpha Tα的概率。
图 G \mathcal{G} G的结构熵 H ( G ) H(\mathcal{G}) H(G)是 H T ( G ) H^\mathcal{T}(\mathcal{G}) HT(G)的最小值(即对编码树 H ( T ) H(\mathcal{T}) H(T)取极小化后的结果)。设 T k \mathcal{T}_k Tk为高度不大于 k k k的编码树,则图 G \mathcal{G} G的 k k k维结构熵定义如下:
H k ( G ) = min ( H T k ( G ) ) , ( 3 ) H_k(\mathcal{G}) = \min(H^{\mathcal{T}_k}(\mathcal{G})),(3) Hk(G)=min(HTk(G)),(3)
此外,一维结构熵具有特殊性,因其一层编码树中仅包含根节点与叶节点。在一维编码树下,图 G \mathcal{G} G中的所有顶点均属于一个大社区 λ \lambda λ;该社区划分方式具有唯一性,因此一维结构熵可直接表示为:
H 1 ( G ) = − ∑ i = 1 n d i v o l ( G ) log d i v o l ( G ) , ( 4 ) H_1(\mathcal{G}) = -\sum_{i=1}^{n} \frac{d_i}{{vol}(\mathcal{G})} \log \frac{d_i}{{vol}(\mathcal{G})},(4) H1(G)=−i=1∑nvol(G)dilogvol(G)di,(4)
其中, d i d_i di是图 G \mathcal{G} G中与顶点 v i v_i vi相连的所有边的权重之和,被称为顶点 v i v_i vi的度。一维结构熵用于衡量未经过分层处理的图 G \mathcal{G} G的不确定性。
2.4超图融合机制(TA 层)
本节将介绍一种超图融合机制,该机制与UPRTH中的TA层类似,但并非本文所提模型的组成部分,而是作为后续讨论与实验中用于对比分析的一种变体。该方法认为,在融合过程中,每个辅助任务对推荐收益的影响程度不同;因此,其设计目的是自适应地学习辅助任务与主任务之间的相关程度。这一过渡层会为每个辅助任务分配相应的注意力,通过一轮超图卷积网络(HGCN)将从辅助任务中学习到的嵌入融合到主任务嵌入中,从而实现有效的知识迁移。
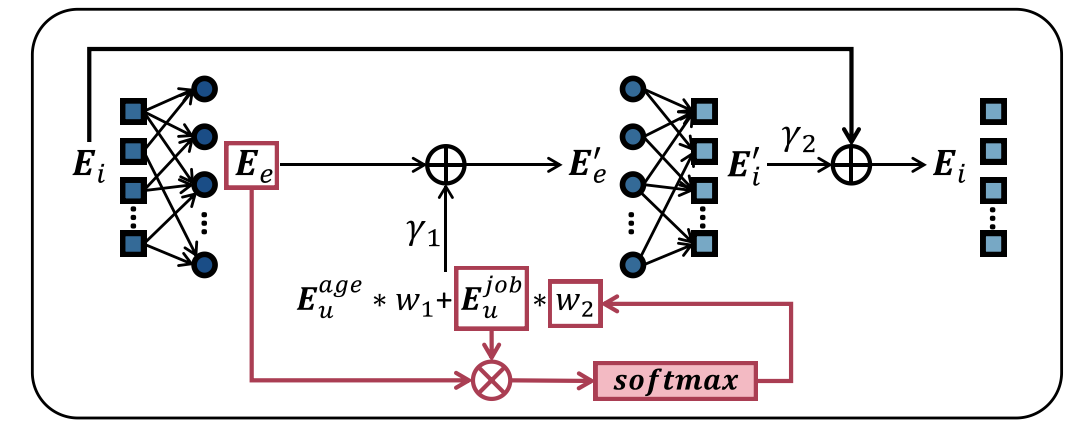
为便于说明,以主任务超图“同一用户购买的物品”为例,作者将从主任务中学习到的物品节点嵌入表示为 E i \mathbf{E_i} Ei。如图3所示,通过HGCN中的节点表示聚合,初始超边嵌入可表示为 E e \mathbf{E_e} Ee。由于在该主任务超图中,超边代表“同一用户购买”,因此 E e \mathbf{E_e} Ee等价于用户购买行为初始嵌入的共性特征。随后,计算从辅助任务中学习到的用户特征 E u j o b ( E u a g e ) \mathbf{E_u^{job}(E_u^{age})} Eujob(Euage)与初始超边嵌入 E e \mathbf{E_e} Ee之间的注意力,生成辅助任务超边嵌入。以 E u j o b \mathbf{E_u^{job}} Eujob为例:
w 2 = S o f t m a x ( d i a g ( E u j o b ⋅ ( E e ) ⊤ ) d ) , E e a = w 1 E u a g e + w 2 E u job , ( 5 ) w_2 ={Softmax}\left(\frac{{diag}(\mathbf{E_u^{job}} \cdot (\mathbf{E_e)}^\top)}{\sqrt{d}}\right), \mathbf{E_e^a} = \mathbf{w}_1 \mathbf{E_u^{age}} + \mathbf{w}_2 \mathbf{E_u^{\text{job}}},(5) w2=Softmax(ddiag(Eujob⋅(Ee)⊤)),Eea=w1Euage+w2Eujob,(5)
其中, E e a \mathbf{E_e^a} Eea表示辅助任务超边的嵌入,它是通过对所有辅助任务的用户特征进行注意力加权得到的。 E u j o b \mathbf{E_u^{job}} Eujob表示来自“相同职业用户”这一辅助任务的用户特征, E u a g e \mathbf{E_u^{age}} Euage表示来自“相同年龄用户”这一辅助任务的用户特征。 𝑑 𝑑 d表示特征维度。 w 1 {w_1} w1和 w 2 {w_2} w2是注意力对角矩阵,代表为每个辅助任务分配给用户的注意力。随后,通过加法运算将初始超边嵌入与辅助任务超边嵌入进行融合:
E e ′ = E e + γ 1 E e a = E e + γ 1 ( w 1 E u a g e + w 2 E u j o b ) , ( 6 ) \mathbf{E}_e^{'} = \mathbf{E_e }+ \gamma_1 \mathbf{E_e^a}= \mathbf{E_e} + \gamma_1 (\mathbf{w_1}\mathbf{E_u^{age}} + \mathbf{w_2}\mathbf{E_u^{job}}),(6) Ee′=Ee+γ1Eea=Ee+γ1(w1Euage+w2Eujob),(6)
其中, E e ′ \mathbf{E}_e^{'} Ee′表示融合后的超边嵌入, γ 1 \gamma_1 γ1表示融合超参数。最后,通过在超图卷积网络(HGCN)中聚合超边嵌入,将物品嵌入更新为 E i ′ \mathbf{E}_i^{'} Ei′,并利用融合超参数 γ 2 \gamma_2 γ2将其与原始物品嵌入 E i \mathbf{E_i} Ei进行融合:
E i = E i + γ 2 E i ′ , ( 7 ) \mathbf{E_i}= \mathbf{E_i}+ \gamma_2 \mathbf{E_i^{'}},(7) Ei=Ei+γ2Ei′,(7)
TA层包含两个超参数 γ 1 \gamma_1 γ1和 γ 2 \gamma_2 γ2,它们分别控制两步嵌入融合过程中的权重,一个用于超边,另一个用于节点。
3.所提模型
本节将介绍推荐框架EPRHSE的主要组成部分。本研究旨在学习更优的融合结构表示,以提升推荐系统性能。如上图1所介绍,EPRHSE包含三个关键模块:预训练过程、超图结构熵模块和超图池化模块。具体而言,预训练过程(3.1节)定义了两类辅助任务,阐述了模型完整的预训练与推荐流程,并利用优化后的超图卷积神经网络层,在不同超图中学习物品或用户节点的嵌入表示。随后,超图结构熵模块与超图池化模块共同阐述了如何从超图结构学习和全局信息捕捉的角度对HGCN进行优化。本研究首次将结构信息理论扩展到超图领域,提出了超图结构熵(3.2节):通过将节点-超边二部图转换为节点邻接矩阵,并传递超边信息来设计超图结构熵;随后在结构熵最小化原则的指导下,实现最优的高维社区划分。超图池化模块(3.3节)在超图编码器HGCN之后,分别添加了两个池化层和两个反池化层。通过对社区嵌入进行聚合与传递,将群体特征整合到节点嵌入中,以用于推荐任务。最后,整合所有模块对推荐任务进行优化(3.4节),并对模型的时间复杂度进行了详细分析(3.5节)。
3.1预训练流程
本小节将详细介绍整个预训练流程的分步方法。预训练的目标是从辅助任务和主任务中获取先验知识,为下游推荐模型构建更优的用户 / 物品嵌入表示。在整个预训练过程中,会学习两个嵌入矩阵,即物品嵌入矩阵 E i E_i Ei和用户嵌入矩阵 E u E_u Eu,其中矩阵的行分别表示物品和用户的嵌入表示。
超图构建。
首先为每个辅助任务构建超图,以统一处理各类辅助任务。这些辅助任务可能涉及用户和物品的特定属性(如年龄、职业、价格、类别等),也可能包含特定关系(如替代品关系、互补品关系等)。以用户的年龄属性为例,将用户表示为超图中的节点,通过超边连接同一年龄段内的用户群体。该步骤生成的超图如图1.a上半部分所示,记为 “同龄用户” 超图。
类似地,还可以构建其他辅助任务超图,例如 “同类物品” 超图、“同评分物品” 超图、“一起购买物品” 超图、“一起比较物品” 超图以及 “同职业用户” 超图。随后,为两个主任务构建超图:这两个超图分别以用户和物品为节点,基于用户与物品的直接交互关系构建,记为 “购买相同物品的用户” 超图和 “被相同用户购买的物品” 超图,如图1.a下半部分所示。
超图学习。
所有辅助任务超图和主任务超图均输入优化后的超图卷积神经网络(HGCN)层进行训练,生成物品节点和用户节点对应的嵌入表示。例如, E i E_i Ei表示主任务超图 “被相同用户购买的物品” 中物品节点的嵌入表示, E u E_u Eu表示主任务超图 “购买相同物品的用户” 中用户节点的嵌入表示 E i c a t e E_i^{cate} Eicate
表示辅助任务超图 “同类物品” 中物品节点的嵌入表示, E i a g e E_i^{age} Eiage
表示辅助任务超图 “同龄用户” 中用户节点的嵌入表示。该优化后的HGCN 整合了超图拓扑学习(详见3.2 小节)和全局关系捕捉(详见3.3小节)功能,是对原始HGCN的改进,后续章节将对此展开详细阐述。
预训练损失与推荐生成。
上述嵌入表示在预训练过程中被用作优化目标,且需为每个任务单独计算损失。所有辅助任务的损失被聚合形成辅助损失 L a \mathcal{L}_a La,所有主任务的损失被合并得到推荐损失 L r e c \mathcal{L}_{rec} Lrec损失进行加权组合得到。在推荐阶段,通过比较两个主任务的嵌入表示(即物品嵌入矩阵 E i E_i Ei和用户嵌入矩阵 E u E_u Eu)生成推荐序列。损失函数的详细计算方法将在3.4 小节中介绍。
3.2预训练流程
结构信息理论在图结构学习与聚类任务中展现出更强的适应性。然而,该方法仅适用于简单的同构图和多关系图。为解决超图上编码树构建与社区划分的难题,作者首先对超图二部图矩阵中的超边信息进行转换,构建节点邻接矩阵;随后为超图构建最优编码树,实现对节点社区的有效划分。
超图结构熵。
传统结构熵的定义已在2.3节中给出。在构建完主任务与辅助任务超图后,作者的目标是利用结构信息理论,将连接紧密的用户/物品划分到同一个社区。结构信息理论通过节点在图中沿连接边的随机游走,来衡量结构的不确定性。超图中的超边可连接多个节点,能够表达群体间的关系而非一对一关系,这是超图与同构图/多关系图最显著的区别。因此,将结构熵概念推广到超图的关键在于:在保留超图特性的前提下,将超图中的群体关系(即超边)转化为节点间抽象的一对一关系(即节点邻接矩阵)。作者对超图的二部图矩阵 A G A_G AG执行如下操作,得到节点邻接矩阵 A H A_\mathcal{H} AH:
A H = A G ⋅ ( D e ) − 1 ⋅ A G ⊤ = ( ∑ m = 1 ∣ E h y p e r ∣ a i , m ⋅ a j , m ⋅ 1 log 2 d e m ) , ( 8 ) A_{\mathcal{H}} = A_G \cdot (D_e)^{-1} \cdot A_G^\top = \left( \sum_{m=1}^{|\mathcal{E}_{hyper}|} a_{i, m} \cdot a_{j, m} \cdot \frac{1}{\log_2 d_e^m} \right),(8) AH=AG⋅(De)−1⋅AG⊤= m=1∑∣Ehyper∣ai,m⋅aj,m⋅log2dem1 ,(8)
其中, D e D_e De表示超边度矩阵(与公式1中的定义一致); d e m d_e^m dem表示第 m m m条超边的度; a i , m a_{i,m} ai,m表示节点 v i v_i vi与边 e m e_m em之间是否存在连接关系(与2.2节中的定义一致)。上述公式通过计算两个节点共享超边的加权和,为节点间的邻接关系赋值;而 ( D e ) − 1 (D_e)^{-1} (De)−1的作用是放大连接节点数量较少的超边的影响力。
得到超图节点的邻接矩阵后,可通过公式4计算超图结构熵。具体而言,所有节点的度可通过邻接矩阵对应的行和表示:
( d 1 , d 2 , . . . , d N ) ⊤ = ( A H − diag ( A H ) ) ⋅ 1 ∣ V ∣ , ( 9 ) (d_1, d_2, ..., d_N)^\top = \big(A_\mathcal{H} - \text{diag}(A_\mathcal{H})\big) \cdot 1_{|\mathcal{V}|},(9) (d1,d2,...,dN)⊤=(AH−diag(AH))⋅1∣V∣,(9)
其中, d i a g ( ⋅ ) diag(⋅) diag(⋅)表示取矩阵的对角元素; N N N为超图 H \mathcal{H} H中的节点数量; 1 ∣ V ∣ 1_{|\mathcal{V}|} 1∣V∣是长度为 ∣ V ∣ |\mathcal{V}| ∣V∣的全1列向量,即 ( 1 , 1 , . . . , 1 ) ⊤ (1,1,...,1)^\top (1,1,...,1)⊤。在上述公式的计算过程中,需移除节点自身与自身的邻接项。
优化编码树。
作者通过两次构建最优二维编码树,进而构建出最优三维编码树:在形成最优二维编码树后,将这些社区节点作为超图节点,再次构建二维编码树。二维编码树的构建过程如下:初始的一维编码树为最简单的两层结构,图中的叶子节点直接与根节点相连。通过合并算子(Merge operator) 对节点进行合并,并采用贪心搜索策略构建最优编码树。合并算子会将同一父节点下的两个子树合并为一个子树,在图中表现为两个小社区的合并。在最优编码树中,图结构的不确定性最小,节点处于平衡稳定状态,从而实现节点的最优划分。记 T m g ( α , β ) \mathcal{T}_{mg}(\alpha, \beta) Tmg(α,β)为编码树 T \mathcal{T} T执行合并操作 M g ( T ; α , β ) Mg(\mathcal{T};\alpha, \beta) Mg(T;α,β)后得到的编码树,超图 G h y p e r \mathcal{G}_{hyper} Ghyper在编码树 T m g ( α , β ) \mathcal{T}_{mg}(\alpha, \beta) Tmg(α,β)与原编码树 T \mathcal{T} T下的结构熵差值可表示为:
Δ H Mg ( T ; α , β ) = H T mg ( α , β ) ( H ; α ) + ∑ δ - = α H T mg ( α , β ) ( H ; δ ) − H T ( H ; α ) − H T ( H ; β ) − ∑ δ - = α or δ - = β H T ( H ; δ ) , ( 10 ) \Delta_\mathcal{H}^{\text{Mg}}(T; \alpha, \beta) = H^{\mathcal{T}_{\text{mg}}(\alpha, \beta)}(\mathcal{H}; \alpha) + \sum_{\delta^\text{-} = \alpha} H^{\mathcal{T}_{\text{mg}}(\alpha, \beta)}(\mathcal{H}; \delta) - H^{\mathcal{T}}(\mathcal{H}; \alpha) - H^{\mathcal{T}}(\mathcal{H}; \beta) - \sum_{\delta^\text{-} = \alpha \text{ or } \delta^\text{-} = \beta} H^{\mathcal{T}}(\mathcal{H}; \delta),(10) ΔHMg(T;α,β)=HTmg(α,β)(H;α)+δ-=α∑HTmg(α,β)(H;δ)−HT(H;α)−HT(H;β)−δ-=α or δ-=β∑HT(H;δ),(10)
其中, H T ( H ; α ) H^{\mathcal{T}}(\mathcal{H}; \alpha) HT(H;α)表示子树 α \alpha α的结构信息, H T ( H ; β ) H^{\mathcal{T}}(\mathcal{H}; \beta) HT(H;β)表示子树 β \beta β的结构信息, H T ( H ; δ ) H^{\mathcal{T}}(\mathcal{H}; \delta) HT(H;δ)表示 α \alpha α和 β \beta β的子树 δ \delta δ的结构信息; H T mg ( α , β ) ( H ; α ) H^{\mathcal{T}_{\text{mg}}(\alpha, \beta)}(\mathcal{H}; \alpha) HTmg(α,β)(H;α)表示将子树 β \beta β合并到 α \alpha α后,子树 α \alpha α的结构信息;同理, H T mg ( α , β ) ( H ; δ ) H^{\mathcal{T}_{\text{mg}}(\alpha, \beta)}(\mathcal{H}; \delta) HTmg(α,β)(H;δ)表示将子树 β \beta β合并到 α \alpha α后 δ \delta δ的结构信息。公式 10 计算了对节点 α \alpha α和 β \beta β执行合并算子前后,相关子树结构熵的变化量。若 Δ H Mg ( T ; α , β ) ≤ 0 \Delta_{\mathcal{H}}^{\text{Mg}}(T; \alpha, \beta) \leq 0 ΔHMg(T;α,β)≤0,则合并算子执行成功,记为 Mg ( T ; α , β ) ↓ \text{Mg}(\mathcal{T}; \alpha, \beta) \downarrow Mg(T;α,β)↓。
初始的一维编码树中,每个节点 v i v_i vi均形成一个独立社区。接下来,计算任意两个节点执行合并算子前后的结构熵差值,从结构熵下降最多的节点对中,选择不超过最大对数 Q Q Q的节点对执行合并算子;重复此过程,直到不存在可成功执行合并算子的节点对为止。每次迭代中 Q Q Q的取值由下式确定:
Q = c e i l ( ( n c u r − 1 ) × p ) , ( 11 ) Q=ceil((n_{cur}-1)\times p),(11) Q=ceil((ncur−1)×p),(11)
其中, n c u r n_{cur} ncur表示当前的社区/节点数量; p p p是控制合并算子并行操作速度的超参数,取值范围为0到1; c e i l ceil ceil为数学中的向上取整函数。最终的社区划分可通过矩阵 S 1 S_1 S1
将社区集合视为新的节点集合,可得到社区超图的二部图矩阵 A G ′ A'_G AG′:
A G ′ = S 1 ⊤ ⋅ A G , S 1 = ( s i , j ) ∈ { 0 , 1 } ∣ V ∣ × ∣ C 1 ∣ , ( 12 ) A_G' = S_1^\top \cdot A_G, \quad S_1 = (s_{i,j}) \in \{0, 1\}^{|\mathcal{V}| \times |C_1|},(12) AG′=S1⊤⋅AG,S1=(si,j)∈{0,1}∣V∣×∣C1∣,(12)
其中, C 1 C_1 C1为初步社区集合; s i , j s_{i,j} si,j表示节点 v i v_i vi是否属于社区 c 1 j c_1^j c1j; A G A_G AG为初始超图的二部图矩阵。如此得到的 A G ′ A'_G AG′表示社区间超边的连接关系,且会存在自环。
如算法1所述,通过重复执行公式 8-10 的计算的二维编码树构建算法,可得到具有更高层次社区划分的最终社区集合,至此完成三维最优编码树及对应社区划分的构建。

3.3超图池化
三维编码树成功学习到超图的拓扑结构,并将节点划分为两个层级化社区。本小节在此基础上,提出一种节点群体特征捕捉方法:在超图编码器后引入池化层与反池化层,以增强节点信息的扩散过程。
池化与反池化。
池化操作负责聚合低层级节点的嵌入信息,形成高层级社区的嵌入表示;与之相对,反池化操作则将已获取的高层级社区嵌入表示反向传播至低层级节点。这两种操作的数学表达式如下:
E c = S ⊤ ⋅ E v , ( 13 ) E_{c}=S^{\top} \cdot E_{v},(13) Ec=S⊤⋅Ev,(13)
E c = S ⋅ E c , ( 14 ) E_{c}=S \cdot E_{c},(14) Ec=S⋅Ec,(14)
其中,公式13为池化操作,公式14为反池化操作;S为社区划分矩阵(与3.2 小节中的定义一致); E c E_c Ec和 E v E_v Ev分别表示社区集合与节点集合的嵌入表示。
超图池化的编码器-解码器结构。
在超图池化编码器(Hypergraph Pooling Encoder, HP)中,采用两个向上抽象模块,每个模块由1个HGCN层和1个池化层构成;在超图反池化解码器(Hypergraph Unpooling Decoder, HPU)中,采用两个向下反馈模块,每个模块由1个反池化层和1个HGCN层构成。此外,还在编码器与解码器之间插入1个HGCN层,以促进最高层级社区的信息扩散。为同时捕捉全局社区表示与直接邻居依赖关系,解码器中的HGCN层不直接使用反池化层的输出,而是通过加权的方式,融合对应编码器中HGCN层的输出与反池化层的输出。这种编码器-解码器跳跃连接操作(skip-connection operation)能够将高层级社区信息嵌入到低层级节点的嵌入表示中;若缺少该操作,每个底层节点最终接收到的社区嵌入反馈差异会极小。超图池化的详细流程如算法2所示。

具体而言,如图1所示,针对初始超图 H 0 \mathcal{H}_0 H0,首先随机初始化一个节点嵌入矩阵 E v 0 E_v^0 Ev0;经过HGCN层一轮信息传播后,得到相同维度的嵌入矩阵 E v 1 E_v^1 Ev1。随后,基于3.2小节中编码树上的社区划分矩阵 S 1 S_1 S1,执行嵌入池化以向上抽象,得到维度为 ∣ C 1 ∣ × d |C_1| \times d ∣C1∣×d的初步社区嵌入矩阵 E v 2 E_v^2 Ev2;节点聚合后更新得到的超图即为社区超图 H 1 \mathcal{H}_1 H1。经过第二轮 HGCN 信息传播,得到维度为 ∣ C 1 ∣ × d |C_1| \times d ∣C1∣×d的嵌入矩阵 E v 3 E_v^3 Ev3;接着,基于3.2小节中的社区划分矩阵 S 2 S_2 S2,对初步社区执行池化以进一步向上抽象,得到维度为 ∣ C 2 ∣ × d |C_2| \times d ∣C2∣×d的最终社区嵌入矩阵 E v 4 E_v^4 Ev4,此时编码器的工作完成。初步社区聚合后更新得到的超图为最终社区超图 H 2 \mathcal{H}_2 H2,经过一轮HGCN信息传播,得到维度为 ∣ C 2 ∣ × d |C_2| \times d ∣C2∣×d的嵌入矩阵 E v 5 E_v^5 Ev5。随后启动解码器工作:首先基于社区划分矩阵 S 2 S_2 S2执行最终社区反池化,得到维度为 ∣ C 1 ∣ × d |C_1| \times d ∣C1∣×d的初步社区嵌入矩阵 E v 6 E_v^6 Ev6;将 E v 6 E_v^6 Ev6与编码器对应层级的初步社区嵌入矩阵 β h p u E v 3 \beta_{hpu}E_v^3 βhpuEv3进行加权融合后,输入HGCN层,经过一轮传播得到维度为 ∣ C 1 ∣ × d |C_1| \times d ∣C1∣×d的嵌入矩阵 E v 7 E_v^7 Ev7。下一步,基于社区划分矩阵 S 1 S_1 S1执行初步社区反池化,得到维度为 ∣ V ∣ × d |V| \times d ∣V∣×d的节点嵌入矩阵 E v 8 E_v^8 Ev8;最后,将 E v 8 E_v^8 Ev8与编码器中的节点嵌入矩阵 β h p u E v 3 \beta_{hpu}E_v^3 βhpuEv3加权融合,输入HGCN层,得到维度为 ∣ V ∣ × d |\mathcal{V}| \times d ∣V∣×d的最终节点嵌入矩阵 E v 9 E_v^9 Ev9。本质上,上述池化与反池化过程旨在获取节点的高层级社区嵌入 E v 8 E_v^8 Ev8。对于原始超图 H 0 \mathcal{H}_0 H0而言,这相当于执行两轮超图编码:
1)初始节点嵌入 E v 0 E_v^0 Ev0经过一轮HGCN传播,得到包含直接邻居依赖关系的新节点嵌入 E v 1 E_v^1 Ev1;
2)新节点嵌入 E v 1 E_v^1 Ev1与对应高层级社区嵌入 E v 8 E_v^8 Ev8加权融合后,经过第二轮 HGCN 传播,最终得到同时包含直接邻居依赖关系与全局群体表示的节点嵌入 E v 9 E_v^9 Ev9。
3.4推荐与优化
EPRHSE中的完整推荐流程如算法3所示。该流程首先为主要任务和辅助任务构建超图;随后,针对每个超图,利用超图结构熵(算法1)构建三维编码树,对节点社区进行层级划分;基于这些社区-节点映射关系,执行超图池化与反池化操作(算法2),以增强超图编码器的聚合过程。作者根据任务类型的不同开展预训练优化,具体流程如下:

主任务(推荐任务)优化。
对于主任务(即推荐任务),通过内积计算用户 - 物品对的排序分数 Y r e c Y_{rec} Yrec,公式如下:
Y r e c = E u ⋅ E i ⊤ , ( 15 ) Y_{rec} = \mathbf{E_u} \cdot \mathbf{E_i}^\top,(15) Yrec=Eu⋅Ei⊤,(15)
其中, E u \mathbf{E_u} Eu和 E i \mathbf{E_i} Ei分别表示由主要任务的优化超图卷积神经网络(HGCN)层输出的用户嵌入矩阵和物品嵌入矩阵; Y r e c Y_{rec} Yrec为维度为 ∣ U ∣ × ∣ I ∣ ∣U∣×∣I∣ ∣U∣×∣I∣的分数矩阵,矩阵中每个元素 y r e c ( u , i ) y_{rec}(u,i) yrec(u,i)表示用户 u u u对物品 i i i的推荐可能性。作者采用对齐损失(alignment loss) 对推荐任务进行优化,损失函数公式如下:
L r e c = 1 ∣ D r e c ∣ ∑ ( u , i ) ∈ D r e c ∥ e u − e i ∥ 2 2 + λ Θ ⋅ ∥ Θ ∥ 2 2 , ( 16 ) \mathcal{L}_{rec} = \frac{1}{|\mathcal{D}_{rec}|} \sum_{(u,i) \in \mathcal{D}_{rec}} \left\| \mathbf{e_u} - \mathbf{e_i} \right\|_2^2 + \lambda_\Theta \cdot \left\| \Theta \right\|_2^2,(16) Lrec=∣Drec∣1(u,i)∈Drec∑∥eu−ei∥22+λΘ⋅∥Θ∥22,(16)
其中, D r e c \mathcal{D}_{rec} Drec表示训练集中的用户 - 物品交互对集合; e u \mathbf{e_u} eu和 e i \mathbf{e_i} ei分别表示用户 u u u和物品 i i i的嵌入向量; Θ \Theta Θ表示 EPRHSE 中所有可训练参数(包括初始用户嵌入和初始物品嵌入,即 Θ = { E u ∪ E i } \Theta = \{ \mathbf{E_u} \cup \mathbf{E_i} \} Θ={Eu∪Ei}为正则化超参数,用于对模型参数进行正则化,避免过拟合。
辅助任务优化。
以 “同类物品”这一辅助任务为例:由于超边表示关系或属性,作者将该关系(或属性)超边的嵌入与对应物品(或用户)节点的嵌入进行内积运算,得到预测分数,公式如下:
Y c a t e = E i ⋅ E e c a t e ⊤ , ( 17 ) Y_{cate} = \mathbf{E_i} \cdot {\mathbf{E_e^{cate}}}^{\top},(17) Ycate=Ei⋅Eecate⊤,(17)
其中, E e c a t e \mathbf{E_e^{cate}} Eecate表示辅助任务 “同类物品” 的特定超边嵌入, E i \mathbf{E_i} Ei表示该任务相关的物品节点嵌入; Y c a t e Y_{cate} Ycate为分数矩阵,矩阵中每个元素表示物品节点 i i i与属性超边 e e e之间的关联可能性。
随后,作者采用贝叶斯个性化排序损失(Bayesian Personalized Ranking, BPR 损失)对辅助任务进行优化,损失函数公式如下:
L c a t e = ∑ ( i , e , e ′ ) ∈ D c a t e − log σ ( y c a t e ( i , e ) − y c a t e ( i , e ′ ) ) , ( 18 ) \mathcal{L}_{cate} = \sum_{(i,e,e') \in \mathcal{D}_{cate}} -\log \sigma(y_{cate}(i,e) - y_{cate}(i,e')),(18) Lcate=(i,e,e′)∈Dcate∑−logσ(ycate(i,e)−ycate(i,e′)),(18)
其中, D c a t e \mathcal{D}_{cate} Dcate表示辅助任务 “同类物品” 训练集中的节点 - 超边交互对集合,每个物品节点 i i i均连接一个正例属性超边 e e e和一个负例属性超边 e ′ e' e′; y c a t e ( i , e ) y_{cate}(i,e) ycate(i,e)和 y c a t e ( i , e ′ ) y_{cate}(i,e') ycate(i,e′)分别表示物品节点 i i i与正例、负例属性超边的预测分数; σ \sigma σ表示Sigmoid函数,定义为 σ ( x ) = 1 1 + exp ( − x ) \sigma(x) = \frac{1}{1+\exp(-x)} σ(x)=1+exp(−x)1,用于将分数差值映射到 0-1 区间,以衡量排序的置信度。
最终,结合推荐主任务和辅助任务对预训练过程进行联合优化,总预训练损失公式如下:
L p r e = λ r e c ⋅ L r e c + ( 1 − λ r e c ) ⋅ L a L a = L c a t e + ⋯ + L a g e s , ( 19 ) \begin{align*} \mathcal{L}_{pre} &= \lambda_{rec} \cdot \mathcal{L}_{rec} + (1 - \lambda_{rec}) \cdot \mathcal{L}_{a} \\ \mathcal{L}_{a} &= \mathcal{L}_{cate} + \cdots + \mathcal{L}_{ages} \end{align*},(19) LpreLa=λrec⋅Lrec+(1−λrec)⋅La=Lcate+⋯+Lages,(19)
其中, λ r e c \lambda_{rec} λrec为平衡主任务与辅助任务损失的系数; L a \mathcal{L}_{a} La为所有辅助任务的辅助损失之和(例如 “同类物品” 任务的 L c a t e \mathcal{L}_{cate} Lcate、“同龄用户” 任务的 L a g e s \mathcal{L}_{ages} Lages等)。在微调阶段,仅保留预训练阶段的主任务:优化过程中仅聚合用户 - 物品超图和物品 - 用户超图的优化超图编码器信息,损失计算方式与预训练阶段的 L r e c \mathcal{L}_{rec} Lrec部分保持一致。
3.5时间复杂度分析
超图结构熵。
EPRHSE 中的增强型 HGCN 通过超图结构熵进行扩展。构建一棵三维超图结构熵编码树的时间复杂度为 O ( ∣ ∣ A H ∣ ∣ 0 ⋅ ( 1 + log ∣ V ∣ ) O(||A_\mathcal{H}||_0 \cdot (1 +\log |\mathcal{V}|) O(∣∣AH∣∣0⋅(1+log∣V∣),其中 A H A_\mathcal{H} AH是通过公式8计算得到的初始超图邻接矩阵, V \mathcal{V} V是超图中的节点集合。 ∣ ∣ ⋅ ∣ ∣ 0 ||⋅||_0 ∣∣⋅∣∣0表示零范数,即矩阵中非零元素的数量。具体来说,每轮并行率为p的合并(Merge)操作中,尝试合并的节点对数量为 ∣ ∣ A H ∣ ∣ 0 ||A_\mathcal{H}||_0 ∣∣AH∣∣0时,完成所有合并操作所需的最大轮数为 log 1 − p 1 − p ∣ V ∣ − 1 \log_{1-p} \frac{1-p}{|\mathcal{V}|-1} log1−p∣V∣−11−p间复杂度为 O ( ∣ ∣ A H ∣ ∣ 0 ) ⋅ log 1 − p 1 − p ∣ V ∣ − 1 O(||A_\mathcal{H}||_0) \cdot \log_{1-p} \frac{1-p}{|\mathcal{V}|-1} O(∣∣AH∣∣0)⋅log1−p∣V∣−11−p,该公式可进一步简化为 O ( ∣ ∣ A H ∣ ∣ 0 ⋅ ( 1 + log ∣ V ∣ ) O(||A_\mathcal{H}||_0 \cdot (1 +\log |\mathcal{V}|) O(∣∣AH∣∣0⋅(1+log∣V∣)。类似地,在二维编码树基础上增加一层(构建更高维度编码树)的时间复杂度为 O ( ∣ ∣ A H ′ ∣ ∣ 0 ⋅ ( 1 + log ∣ C 1 ∣ ) O(||A_\mathcal{H}'||_0 \cdot (1 +\log |C_1|) O(∣∣AH′∣∣0⋅(1+log∣C1∣)是前一棵二维编码树中的社区节点集合, A H ′ A_\mathcal{H}' AH′是通过公式12和公式8更新后得到的超图邻接矩阵。由此可知,构建一棵三维编码树的时间复杂度为 O ( ∣ ∣ A H ∣ ∣ 0 ⋅ ( 1 + log ∣ V ∣ ) + ∣ ∣ A H ′ ∣ ∣ 0 ⋅ ( 1 + log ∣ C 1 ∣ ) ) O(||A_\mathcal{H}||_0 \cdot (1 +\log |\mathcal{V}|)+||A_\mathcal{H}'||_0 \cdot (1 +\log |C_1|)) O(∣∣AH∣∣0⋅(1+log∣V∣)+∣∣AH′∣∣0⋅(1+log∣C1∣)),该式可简化为 O ( ∣ ∣ A H ∣ ∣ 0 ⋅ ( 1 + log ∣ V ) O(||A_\mathcal{H}||_0 \cdot (1 +\log |\mathcal{V}) O(∣∣AH∣∣0⋅(1+log∣V)。在本文提出的 EPRHSE 模型中,需要为用户 - 物品(user-item)、物品 - 类别(i-cate)和物品 - 评分(i-rate)三类任务分别构建三维编码树。因此,模型额外增加的时间复杂度为 O ( ∥ A H u ∥ 0 ⋅ ( 1 + log ∣ U ∣ ) + ( ∥ A H c a t e ∥ 0 + ∥ A H r a t e ∥ 0 ) ⋅ ( 1 + log ∣ I ∣ ) ) O \big( \|\mathbf{A}^u_\mathcal{H}\|_0 \cdot (1 + \log |U|) + (\|\mathbf{A}^{cate}_\mathcal{H}\|_0 + \|\mathbf{A}^{rate}_\mathcal{H}\|_0) \cdot (1 + \log |I|) \big) O(∥AHu∥0⋅(1+log∣U∣)+(∥AHcate∥0+∥AHrate∥0)⋅(1+log∣I∣)),其中 A H u \mathbf{A}^u_\mathcal{H} AHu、 A H c a t e \mathbf{A}^{cate}_\mathcal{H} AHcate和 A H r a t e \mathbf{A}^{rate}_\mathcal{H} AHrate分别表示三类任务对应的超图邻接矩阵 U U U为用户集合, I I I为物品集合。
优化后的HGCN与预训练的时间复杂度。
HGCN 单层的时间复杂度为 O ( ∣ V 2 ∣ ⋅ d + n n z ( A G ) ) O(|\mathcal{V}^2| \cdot d+nnz(A_G)) O(∣V2∣⋅d+nnz(AG)),其中 V \mathcal{V} V表示超图中的节点数量, A G A_G AG表示超图的二部图矩阵, d d d为嵌入维度, n n z ( ⋅ ) nnz(⋅) nnz(⋅)表示矩阵中非零元素的个数。当 A G A_G AG为稀疏矩阵时,HGCN的时间复杂度可近似为 O ( ∣ V 2 ∣ ⋅ d ) O(|\mathcal{V}^2| \cdot d) O(∣V2∣⋅d)。超图池化编码器(Hypergraph Pooling encoder, HP)或超图反池化解码器(Hypergraph Unpooling decoder, HPU)的时间复杂度为
O ( ∣ C ∣ ⋅ ∣ V ∣ ⋅ d ) O(|C| \cdot |\mathcal{V}| \cdot d) O(∣C∣⋅∣V∣⋅d),其中 ∣ C ∣ ∣C∣ ∣C∣为社区数量。因此,优化后HGCN的时间复杂度为 O ( 2 ⋅ ∣ V ∣ 2 ⋅ d + 2 ⋅ ∣ C 1 ∣ ⋅ ∣ V ∣ ⋅ d + 2 ⋅ ∣ C 1 ∣ 2 ⋅ d + 2 ⋅ ∣ C 1 ∣ ⋅ ∣ C 2 ∣ ⋅ d + ∣ C 2 ∣ 2 ⋅ d ) O(2 \cdot |\mathcal{V}|^2 \cdot d + 2 \cdot |C_1| \cdot |\mathcal{V}| \cdot d + 2 \cdot |C_1|^2 \cdot d + 2 \cdot |C_1| \cdot |C_2| \cdot d + |C_2|^2 \cdot d) O(2⋅∣V∣2⋅d+2⋅∣C1∣⋅∣V∣⋅d+2⋅∣C1∣2⋅d+2⋅∣C1∣⋅∣C2∣⋅d+∣C2∣2⋅d),其中 ∣ C 1 ∣ |C_1| ∣C1∣和 ∣ C 2 ∣ |C_2| ∣C2∣分别表示两层社区划分中的社区数量。由于 ∣ C 1 ∣ |C_1| ∣C1∣和 ∣ C 2 ∣ |C_2| ∣C2∣通常远小于 ∣ V ∣ ∣V∣ ∣V∣,优化后 HGCN 的时间复杂度可简化为 O ( 2 ⋅ ∣ V ∣ 2 ⋅ d ) O(2 \cdot |\mathcal{V}|^2 \cdot d) O(2⋅∣V∣2⋅d)。由于超图结构熵可预先计算,且在预训练过程中无需重复参与计算,因此模型整体的时间复杂度仅需考虑所有任务对应的优化后 HGCN 的时间开销。该时间复杂度可近似表示为 O ( 2 ⋅ ∣ U ∣ 2 ⋅ d ) + O ( ∣ I ∣ 2 ⋅ d ) + O ( 2 ⋅ ∣ I ∣ 2 ⋅ d ) + O ( 2 ⋅ ∣ I ∣ 2 ⋅ d ) + O ( ∣ U ∣ 2 ⋅ d ) + O ( ∣ U ∣ 2 ⋅ d ) , O(2 \cdot |U|^2 \cdot d) + O(|I|^2 \cdot d) + O(2 \cdot |I|^2 \cdot d) + O(2 \cdot |I|^2 \cdot d) + O(|U|^2 \cdot d) + O(|U|^2 \cdot d), O(2⋅∣U∣2⋅d)+O(∣I∣2⋅d)+O(2⋅∣I∣2⋅d)+O(2⋅∣I∣2⋅d)+O(∣U∣2⋅d)+O(∣U∣2⋅d),,其中各项分别对应两类主任务和四类辅助任务的时间开销。对常数项进行简化后,整体时间复杂度可进一步表示为 O ( ∣ U ∣ 2 ⋅ d + ∣ I ∣ 2 ⋅ d ) O(|U|^2 \cdot d + |I|^2 \cdot d) O(∣U∣2⋅d+∣I∣2⋅d),
其中 ∣ U ∣ ∣U∣ ∣U∣为用户数量, ∣ I ∣ ∣I∣ ∣I∣为物品数量。
3.6空间复杂度分析
本节将从三个维度分析所提框架 EPRHSE 的空间复杂度:超图结构熵(算法 1)、超图池化与反池化(算法 2),以及整体预训练与优化流程(算法3)。
超图结构熵的空间复杂度。
由公式8推导得到的邻接矩阵 A H A_\mathcal{H} AH包含非零元素,存储种稀疏结构需要 O ( n n z ( A H ) ) O(nnz(A_\mathcal{H})) O(nnz(AH))的内存空间,其中 n n z ( ⋅ ) nnz(⋅) nnz(⋅)表示矩阵中非零元素的个数。在编码树构建过程中,会生成候选节点对 L o p L_{op} Lop。最坏情况下,候选节点对的数量可达 O ( V ) 2 O(\mathcal{V})^2 O(V)2;但通过超参数 p p p控制并行合并后,每轮仅保留 Q = O ( ( 1 − p ) ∣ V ∣ ) Q=O((1−p)∣\mathcal{V}∣) Q=O((1−p)∣V∣)个节点对,因此实际峰值内存占用可简化为 O ( n n z ∣ A H ∣ + Q ) O(nnz∣A_\mathcal{H}∣+Q) O(nnz∣AH∣+Q)。综上,超图结构熵模块的空间复杂度为 O ( n n z ∣ A H ∣ + ∣ V ∣ ) O(nnz∣A_\mathcal{H}∣+|\mathcal{V}|) O(nnz∣AH∣+∣V∣)。
超图池化与反池化的空间复杂度。
在算法2(超图池化与反池化)中,主要内存开销来自节点嵌入与社区嵌入的存储。每一层需存储三类嵌入:节点嵌入(尺寸为 ∣ V ∣ × d ∣\mathcal{V}∣×d ∣V∣×d, d d d为嵌入维度),第一层社区嵌入(尺寸为 ∣ C 1 ∣ × d ∣C_1∣×d ∣C1∣×d, ∣ C 1 ∣ ∣C_1∣ ∣C1∣为第一层社区数量)、第二层社区嵌入(尺寸为 ∣ C 2 ∣ × d ∣C_2∣×d ∣C2∣×d, ∣ C 2 ∣ ∣C_2∣ ∣C2∣为第二层社区数量);同时需存储超图的二部图矩阵 A G 0 A^0_\mathcal{G} AG0, A G 1 A^1_\mathcal{G} AG1和 A G 2 A^2_\mathcal{G} AG2。由于 ∣ C 1 ∣ ∣C_1∣ ∣C1∣和 ∣ C 2 ∣C_2 ∣C2通常远小于 ∣ V ∣ ∣\mathcal{V}∣ ∣V∣,超图池化与反池化模块的最坏空间复杂度可简化为 O ( ∣ V ⋅ d + n n z ( A G ) ) O(∣\mathcal{V} \cdot d + nnz(A_\mathcal{G})) O(∣V⋅d+nnz(AG))。
推荐与优化流程的空间复杂度。
在预训练与微调阶段(算法 3),需为主任务与辅助任务构建编码树并学习嵌入。具体内存开销如下:(1)超图结构熵相关内存为 O ( n n z ( A H u ) + n n z ( A H c a t e ) + n n z ( A H r a t e ) + ∣ U ∣ + ∣ I ∣ ) O(nnz(A_\mathcal{H}^u) + nnz(A_\mathcal{H}^{cate}) + nnz(A_\mathcal{H}^{rate}) + |U| + |I|) O(nnz(AHu)+nnz(AHcate)+nnz(AHrate)+∣U∣+∣I∣)。(2)超图池化与反池化相关内存为 O ( ∣ U ∣ d + nnz ( A G u ) ) + O ( ∣ I ∣ d + nnz ( A G i ) ) + O ( ∣ U ∣ d + nnz ( A G a g e ) ) + O ( ∣ U ∣ d + nnz ( A G j o b ) ) + O ( ∣ I ∣ d + nnz ( A G c a t e ) ) + O ( ∣ I ∣ d + nnz ( A G r a t e ) ) O(|U| d + \text{nnz}(A^u_\mathcal{G})) + O(|I| d + \text{nnz}(A^i_\mathcal{G})) + O(|U| d + \text{nnz}(A^{age}_\mathcal{G})) + O(|U| d + \text{nnz}(A^{job}_\mathcal{G})) + O(|I| d + \text{nnz}(A^{cate}_\mathcal{G})) +O(|I| d + \text{nnz}(A^{rate}_\mathcal{G})) O(∣U∣d+nnz(AGu))+O(∣I∣d+nnz(AGi))+O(∣U∣d+nnz(AGage))+O(∣U∣d+nnz(AGjob))+O(∣I∣d+nnz(AGcate))+O(∣I∣d+nnz(AGrate))。但由于所有任务采用顺序优化策略,同一时间内存中仅需保留单个任务的嵌入与邻接结构,因此实际峰值内存由两类主任务主导,即 O ( ∣ U ∣ d + nnz ( A G u ) ) + O ( ∣ I ∣ d + nnz ( A G i ) ) O(|U| d + \text{nnz}(A^u_\mathcal{G})) + O(|I| d + \text{nnz}(A^i_\mathcal{G})) O(∣U∣d+nnz(AGu))+O(∣I∣d+nnz(AGi))。综上,推荐与优化流程的总内存需求可表示为 O ( ( ∣ U ∣ + ∣ I ∣ ) d + nnz ( A G u ) + nnz ( A G i ) + nnz ( A H u ) + nnz ( A H c a t e ) + nnz ( A H r a t e ) ) O\big( (|U| + |I|) d + \text{nnz}(A^u_\mathcal{G}) + \text{nnz}(A^i_\mathcal{G}) + \text{nnz}(A^u_\mathcal{H}) + \text{nnz}(A^{cate}_\mathcal{H}) + \text{nnz}(A^{rate}_\mathcal{H}) \big) O((∣U∣+∣I∣)d+nnz(AGu)+nnz(AGi)+nnz(AHu)+nnz(AHcate)+nnz(AHrate)),最坏情况下可进一步简化为 O ( ∣ U ∣ ∣ I ∣ + ∣ U ∣ 2 + ∣ I ∣ 2 ) O(|U||I|+|U|^2+|I|^2) O(∣U∣∣I∣+∣U∣2+∣I∣2)。
在实际应用中,内存消耗主要由超图结构熵计算主导。由于超图的社区划分仅由输入图结构决定,且在训练轮次间保持不变,因此可在 CPU 上预先计算社区划分结果并存储,从而缓解 GPU 内存压力;训练时,可根据需求将预计算的社区结构高效加载至 GPU。该策略能显著降低 GPU 内存占用,使模型可扩展至大规模图数据场景。
4.实验设置
在本节中,介绍实验的基本设置,包括有关数据集(4.1节)、基线(4.2节)、EPRHSE的变化(4.3节)以及评估指标的计算(4.4节)的详细信息。
4.1数据集
作者在五个真实世界数据集上进行了实验,分别是Steam、XMrec-CN、XMrec-MX、XMrec-AU和XMrec-BR。其中,Steam数据集包含用户在Steam在线游戏商店的交易记录。在辅助任务中,使用了“相同类别物品”(i-cate)、“相同评分物品”(i-rate)、“相同年龄用户”(u-age)和“相同职业用户”(u-job)这几项。
XMarket数据集是一个从亚马逊获取的公开大规模数据集,作者在实验中使用了其中来自中国、墨西哥、澳大利亚和巴西的数据。对于这四个数据集的辅助任务,使用了“相同类别物品”(i-cate)、“相同评分物品”(i-rate)和“一起购买的物品”(i-bT)。此外,在XMrec-MX数据集中,将“一起比较的物品”(i-cpr)之间的替代关系预测为同构边;由于其他三个数据集不支持该类数据,因此没有此类辅助任务。
除辅助任务外,作者还定义了两个直接体现推荐本质的主任务:
- 用户-物品任务(“购买相同物品的用户”):该任务对有共同购买行为的用户之间的相似性进行建模,从而捕捉用户侧的集体偏好模式;
- 物品-用户任务(“同一用户购买的物品”):该任务对同一用户共同消费的物品之间的相似性进行建模,从而捕捉物品侧的替代或互补关系。
这两个任务对应表5中的“用户-物品”和“物品-用户”条目,共同构成了基础预测目标,而辅助任务则提供了额外的异构图社交信息和属性信息。对于每个用户,作者选取一组用户-物品交互数据用于预训练和微调,其余的用户-物品交互数据则用于用户数据微调测试。
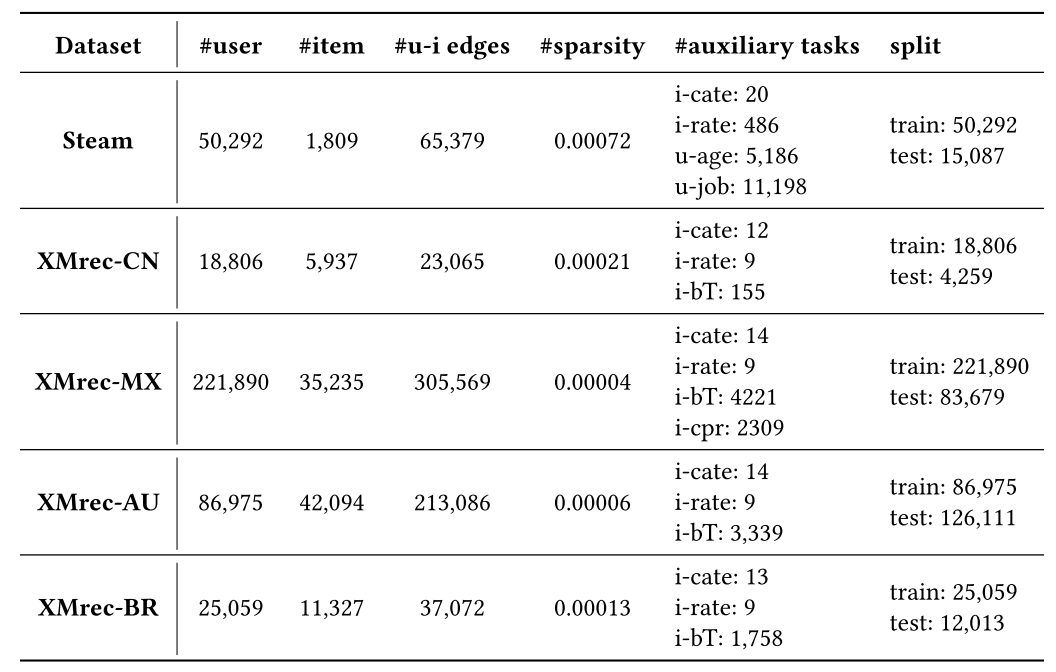
五个数据集的统计信息如表1所示。其中,“#user”(用户数)、“#item”(物品数)、“#u-i edges”(用户-物品交互边数)和“split”(数据划分)列分别对应数据集中的用户数量、物品数量、用户-物品交互次数以及训练集与测试集的用户数量。“#sparsity”(稀疏度)列表示用户-物品交互的稀疏程度。“#auxiliary tasks”(辅助任务数)列标明了每个数据集所使用的辅助任务类型。对于每个辅助任务,都会构建一个对应的超图,其中每个属性或关系均被建模为一条超边;因此,该列中报告的数值(“hyperedges number”,超边数)对应所构建超图中的超边总数。
作者仅对社区聚合特征相对明显的任务采用增强型HGCN编码器,具体指“购买相同物品的用户”这一主任务以及i-cate(相同类别物品)、i-rate(相同评分物品)这两个辅助任务。而对于i-bT(一起购买的物品)、i-cpr(一起比较的物品)、u-age(相同年龄用户)、u-job(相同职业用户)这类社区聚合特征不明显的辅助任务,保留原始HGCN编码器,具体的社区聚合情况可参见表5。
4.2基线
为验证EPRHSE的有效性,作者对基于图的推荐模型在使用和未使用EPRHSE预训练的用户与物品嵌入时的性能进行了对比,涉及的模型包括LightGCN、DirectAU、UltraGCN、HGNN、HCCF和DHCF。作者还与预训练基准模型进行了对比,包括GCC、SGL、AttriMask和UPRTH。除预训练模型外,作者还进一步纳入了当前最先进的图对比学习基准模型。这类模型借助多种数据增强策略开展对比学习,从而解决推荐任务中的数据稀疏性问题,典型方法包括NCL、XSimGCL和LightGCL。因篇幅原因,以上所提基线详细情况请查看原文章。
4.3 变体模型
为验证部分模块的有效性,并证明在不使用超图融合机制的情况下也能取得良好效果,作者构建了若干变体模型,并通过消融实验将其与EPRHSE进行对比。
- EPRHSE+TA𝑎𝑡𝑡(见5.2.2节):该模型是EPRHSE的一种变体,引入了2.4节所述的TA层,通过注意力机制将从辅助任务中得到的节点表示整合到主任务中。
- EPRHSE+TA𝑠𝑢𝑚(见5.2.2节):该模型是EPRHSE的一种变体,同样纳入了TA层,其核心是将辅助任务的嵌入直接与主任务的超边相加。
- EPRHSE+TA𝑐𝑜𝑛𝑐𝑎𝑡(见5.2.2节):该模型是EPRHSE的一种变体,包含TA层,具体做法是将辅助任务的嵌入进行拼接,再通过线性层融合到主任务的超边中。
- EPRHSE_w/o_auxiliary(见5.4节):该模型是EPRHSE的一种变体,移除了所有辅助任务,包括i-cate(相同类别物品)、i-rate(相同评分物品)、i-bT(一起购买的物品)、i-cpr(一起比较的物品)、u-age(相同年龄用户)和u-job(相同职业用户)。
4.4评估指标
作者通过在微调阶段对所有未交互用户的测试物品进行排序,来评估该推荐框架。评估指标采用𝑅𝑎𝑐𝑎𝑙𝑙@{10,20}(召回率@{10,20})和𝑁𝐷𝐶𝐺@{10,20}(归一化折损累积增益@{10,20}),在后续表格中,将其简记为R@10、R@20、N@10和N@20。其中,Recall@K(K值召回率)表示在推荐列表Top-K物品中,预测正确的物品数量占应推荐物品总数量的比例:
R e c a l l @ K = T P @ K T P @ K + F N @ K , ( 20 ) Recall@K=\frac{TP@K}{TP@K+FN@K},(20) Recall@K=TP@K+FN@KTP@K,(20)
其中, T P @ K TP@K TP@K表示推荐前 K K K个物品时的真阳性数量, F N @ K FN@K FN@K表示推荐前 K K K个物品时的假阴性数量。NDCG即归一化折损累积增益(Normalized Discounted Cumulative Gain),该指标会考虑推荐物品的排序顺序:
N D C G @ K = D C G @ K I D C G @ K , D C G @ K = ∑ i = 1 K y r e c ( . , i ) log 2 ( i + 1 ) , I D C G @ K = ∑ i = 1 min { K , ∣ Y ∣ } 1 log 2 ( i + 1 ) . ( 21 ) NDCG@K=\frac{DCG@K}{IDCG@K}, DCG@K = \sum_{i=1}^{K} \frac{y_{rec}(.,i)}{\log_2(i+1)}, IDCG@K = \sum_{i=1}^{\min\{K,|Y|\}} \frac{1}{\log_2(i+1)}.(21) NDCG@K=IDCG@KDCG@K,DCG@K=i=1∑Klog2(i+1)yrec(.,i),IDCG@K=i=1∑min{K,∣Y∣}log2(i+1)1.(21)
其中, Y r e c Y_{rec} Yrec是通过公式15计算得到的用户与物品之间的评分矩阵, y r e c ( , i ) y_{rec}(,i) yrec(,i)是 Y r e c Y_{rec} Yrec中的一个元素,代表物品 𝑖 𝑖 i对某一用户的相关性得分。 Y Y Y是某一用户的真实推荐物品列表。
折损累积增益(DCG,Discounted Cumulative Gain)是一种对预测排序中排名更靠前的物品增加增益、对排名更靠后的物品折损增益的指标。理想折损累积增益(IDCG)则代表物品排序达到最优状态时的折损累积增益(DCG)。
5.实验结果与讨论
5.1整体性能
本节通过多项实验对EPRHSE的性能进行评估,主要围绕以下问题展开解答:
- Q1(5.1节):在不同数据集上,EPRHSE与13个基准模型相比表现如何?此外,EPRHSE的预训练架构在算法有效性方面,相较于最新的基准模型具有哪些优势?
- Q2(5.2节):超图池化层对整体性能有何贡献?此外,引入超图融合机制(TA层)后,模型性能会发生怎样的变化?
- Q3(5.3节):四个关键超参数(预训练学习率𝑙𝑟𝑝𝑟𝑒、微调学习率𝑙𝑟、推荐权重𝜆𝑟𝑒𝑐、正则化参数𝜆Θ)对EPRHSE的性能及稳定性有何影响?
- Q4(5.4节):在冷启动场景下,EPRHSE与预训练基准模型相比表现如何?EPRHSE中哪一部分起到了关键作用?
- Q5(5.5节):不同基准模型与EPRHSE的效率如何?EPRHSE在运算方面具有哪些优势?
- Q6(5.6节):可视化结果如何体现通过结构熵形成的层级社区?不同模型学习到的嵌入在可视化时呈现出怎样的特征?’
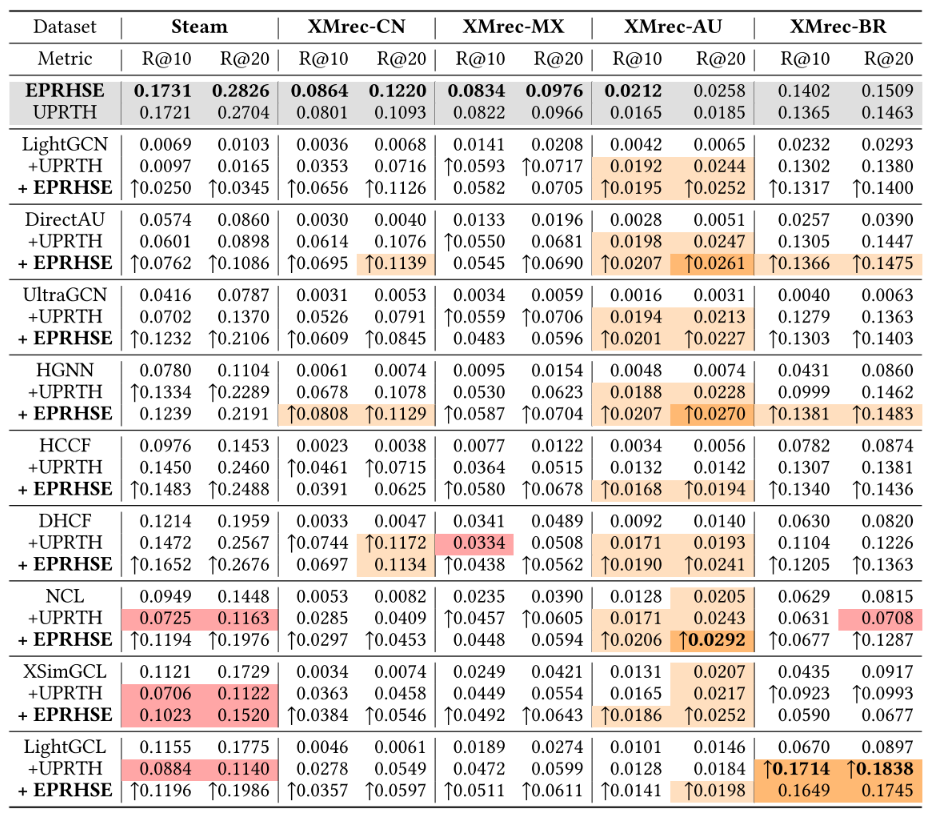
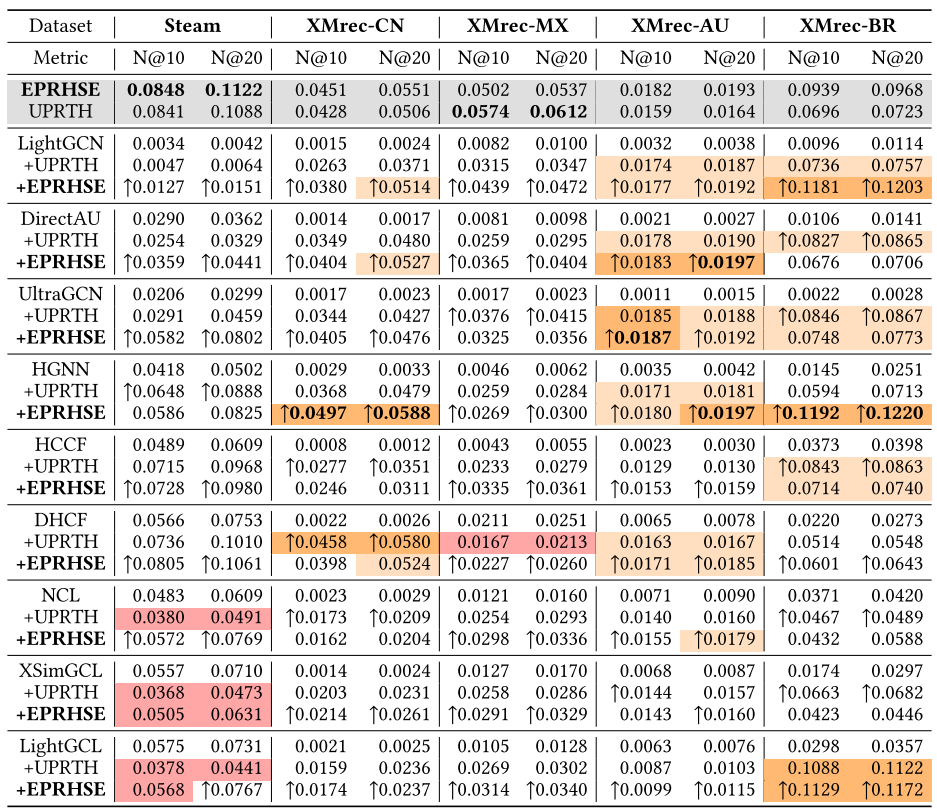
表2. 不同方法在五个数据集上的Recall@10(10值召回率)、Recall@20(20值召回率)、NDCG@10(10值归一化折损累积增益)和NDCG@20(20值归一化折损累积增益)对比。最优结果以粗体标注,次优结果以下划线标注。 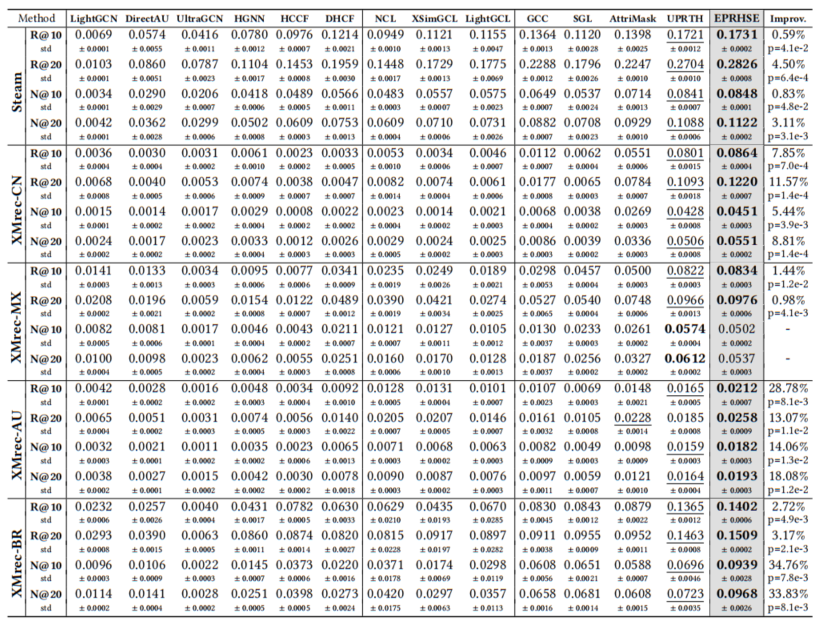
表2展示了EPRHSE与13个基准模型在五个数据集上的整体结果。前六列对应无预训练的基准模型,接下来三列对应图对比学习基准模型,再之后四列对应基于预训练的基准模型,其后呈现的是EPRHSE的结果。最后一列(Improv.)报告了本模型相较于性能最佳基准模型的提升百分比,以及通过t检验得到的p值。此外,每行结果下方均以较小字体标注了标准差(std)。从这些结果中,得出以下结论:
(1)总体而言,融合了拓扑结构与全局依赖关系的EPRHSE模型,在五个数据集上均取得了最佳推荐性能。具体来看,除XMrec-MX数据集上的NDCG@10和NDCG@20为次优结果外,其余所有指标均为最优,且相较于性能最佳的基准模型均有不同程度提升。此外,18个p值均小于0.05,其中9个小于0.005,这表明EPRHSE的性能优势具有统计显著性。作者认为,这些提升得益于EPRHSE中超图结构熵的运用——该机制在预训练阶段融合了拓扑结构与全局依赖关系,使学习到的嵌入能更好地捕捉用户与物品的特征。此外,作者在5.2.1节对超图池化层进行了消融实验,结果证实,设置适当数量的超图结构熵池化层有助于提升推荐性能,这表明从超图学习与模型架构角度优化推荐性能的思路是有效的。
(2)在基准模型中,经预训练或图对比学习(GCL)增强的模型,性能普遍优于基础模型。在预训练基准模型子集内,采用辅助任务的模型(如GCC、AttriMask、UPRTH)比未纳入辅助任务的SGL表现更优;在基础模型中,以HGCN为编码器的模型(HGNN、HCCF、DHCF),性能优于仅依赖LightGCN的模型(LightGCN、DirectAU)。这一结果凸显了在用户-物品交互稀疏的场景下,推荐系统采用“辅助任务预训练”与“图对比学习”的重要性——二者能在信息有限的情况下实现数据增强。此外,作者提出的的EPRHSE通过融入超图结构熵对HGCN进行改进,克服了其无法捕捉全局依赖关系的缺陷,从而实现了更优的推荐性能。
(3)相较于Recall@10和NDCG@10,EPRHSE在Recall@20和NDCG@20上的提升更为显著,且这一效果在Steam和XMrec-CN数据集上尤为突出。这表明EPRHSE在提升推荐列表中排名较后物品的相关性方面效果显著,进而有助于增强推荐稳定性,确保相关推荐不仅局限于排名靠前的物品。
将预训练模型与非预训练模型直接对比,本质上可能存在不公平性。为确保对比的公平性,作者将EPRHSE的预训练流程应用于6个基础基准模型和3个图对比学习(GCL)模型,将EPRHSE生成的预训练嵌入作为这些模型的初始嵌入。此外,为验证本模型预训练架构的有效性,作者还对性能最佳的基准模型(UPRTH)执行了相同操作。结果分别如表3和表4所示。两张表格均表明,EPRHSE生成的预训练嵌入显著提升了几乎所有模型的性能,且相比性能最佳的基准模型UPRTH,其提升效果更显著、更稳定。唯一的例外是在Steam数据集上对XSimGCL和LightGCL的实验——在这两个实验中,EPRHSE未带来性能增益。与之相反,UPRTH在4个基准模型(DHCF、NCL、XSimGCL、LightGCL)上均出现了性能下降。此外,许多模型在结合EPRHSE进行预训练后,甚至超越了性能最佳的基准模型UPRTH,部分情况下还超过了EPRHSE本身。例如,经EPRHSE预训练后,HGNN在XMrec-CN、XMrec-AU和XMrec-BR数据集上的NDCG得分高于EPRHSE,创下了新的最优结果(state-of-the-art)。这些发现充分体现了EPRHSE强大的泛化能力,使其能够适配多种下游模型,并在数据稀疏场景中展现出卓越的性能优势。
5.2消融研究
本节针对超图池化层(见5.2.1节,对应编码树的维度)开展消融实验,并探究在EPRHSE中引入TA层(见5.2.2节)所产生的影响。这些实验旨在验证各组件的作用及有效性。
5.2.1 超图池化层
为验证EPRHSE中超图池化层的层数设置是否合理,作者采用3.2节所述方法构建更高维度的编码树,并相应增加EPRHSE中的池化层与反池化层数量。实验结果如图4和图5所示,其中每个含双y轴的子图均展示了某一数据集下,不同层数对应的Top-10(前10)和Top-20(前20)推荐性能。
在图4中,对应左侧y轴的蓝色柱状图代表Recall@20(20值召回率),对应右侧y轴的红色折线图代表Recall@10(10值召回率);在图5中,对应左侧y轴的紫色柱状图代表NDCG@20(20值归一化折损累积增益),对应右侧y轴的红色折线图代表NDCG@10(10值归一化折损累积增益)。对于不同层级(如“𝐿𝑎𝑦𝑒𝑟𝑖”),其含义为EPRHSE构建(i+1)维编码树,形成含i层社区的结构,以用于池化与反池化操作。
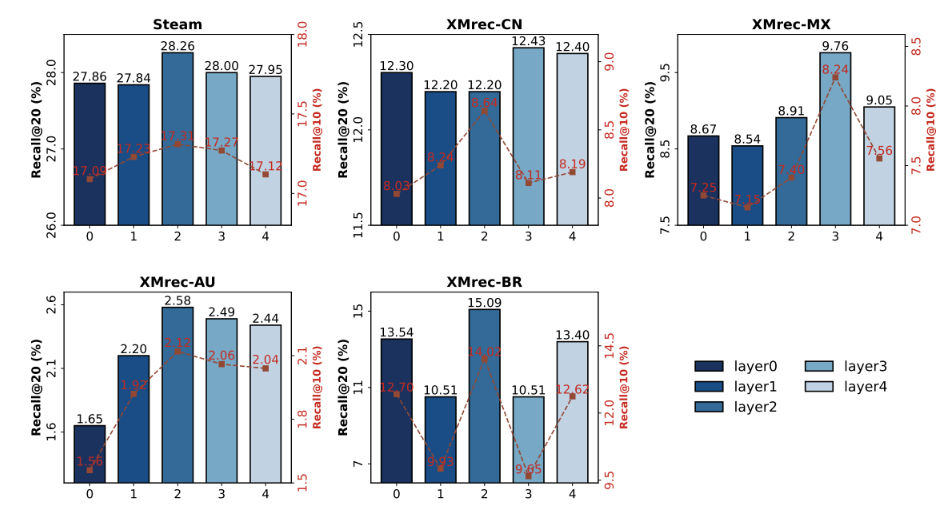
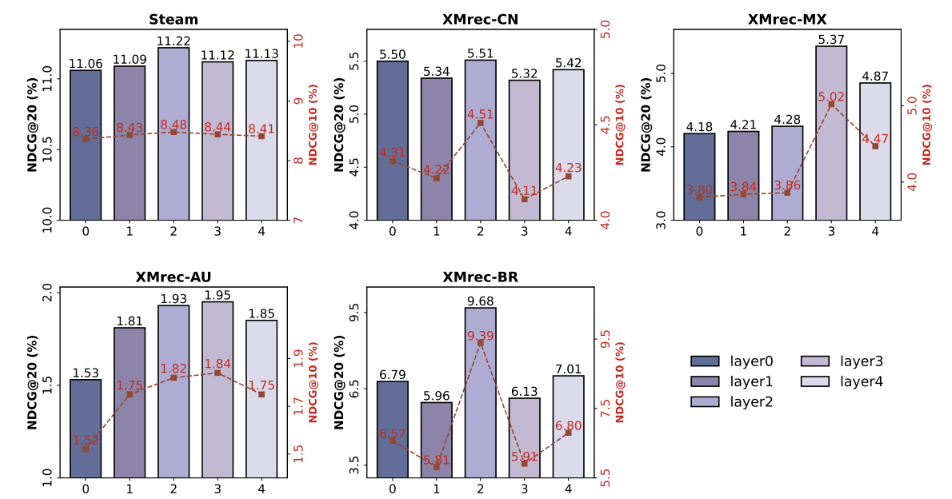
我们观察到,随着超图池化层层数的增加,Recall@{10,20}(10/20值召回率)和NDCG@{10,20}(10/20值归一化折损累积增益)均呈现先提升后下降的趋势。除以下情况外:XMrec-CN数据集上的Recall@20、XMrec-AU数据集上的NDCG@10与NDCG@20,以及XMrec-MX数据集上的Recall@10、Recall@20、NDCG@10与NDCG@20在𝐿𝑎𝑦𝑒𝑟3(3层)时达到峰值;其余所有数据集上的指标均在𝐿𝑎𝑦𝑒𝑟2(2层)时达到峰值,这也是EPRHSE中所讨论的模型最优配置。
这一现象可能与编码树中的社区数量相关。因此,作者在表5中报告了每个数据集下各任务的节点数量,以及经过若干层超图结构熵划分后得到的社区数量。由表5可见,从𝐿𝑎𝑦𝑒𝑟0(0层)到𝐿𝑎𝑦𝑒𝑟1(1层),节点出现显著聚合;而从𝐿𝑎𝑦𝑒𝑟1到𝐿𝑎𝑦𝑒𝑟2,仅有少量节点聚合形成社区;即便到了𝐿𝑎𝑦𝑒𝑟3和𝐿𝑎𝑦𝑒𝑟4,也未形成新的社区。这表明,三层编码树(对应𝐿𝑎𝑦𝑒𝑟2)已足够学习到充足的层级结构,从而捕捉全局结构信息——这一现象与图4和图5所示结果一致。
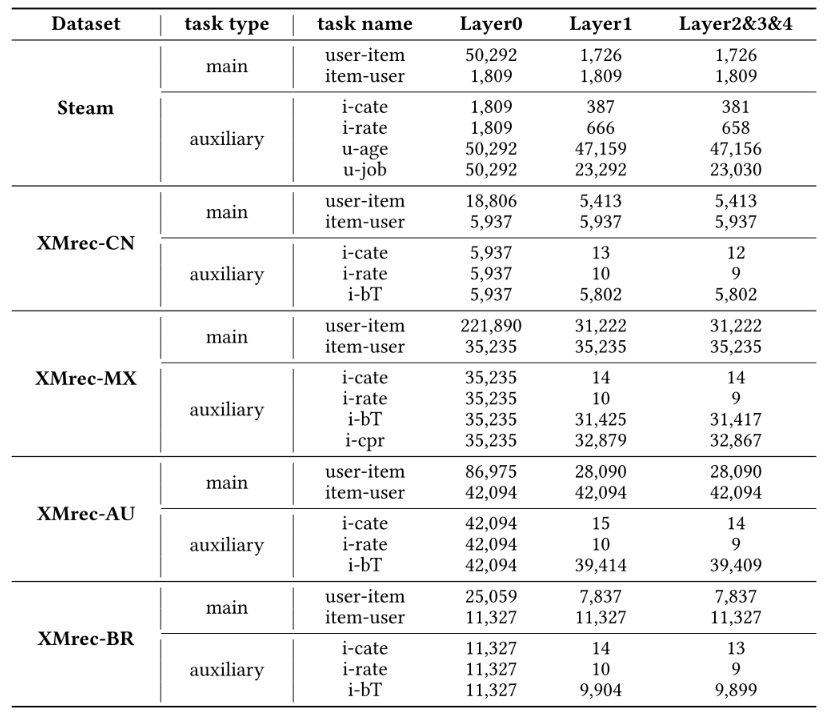
在从𝐿𝑎𝑦𝑒𝑟0到𝐿𝑎𝑦𝑒𝑟2的过程中,模型利用层级化全局结构更新物品与用户的嵌入,显著提升了推荐性能;但𝐿𝑎𝑦𝑒𝑟3和𝐿𝑎𝑦𝑒𝑟4并未挖掘出更深层次的全局依赖关系,且基于𝐿𝑎𝑦𝑒𝑟2进行的重复池化与反池化操作,导致嵌入出现过拟合,最终使得推荐性能下降。
5.2.2 TA层
作者将EPRHSE与TA层中采用不同聚合方式的模型,以及性能最佳的基准模型UPRTH进行了对比。三种聚合方式对应的变体模型分别记为 EPRHSE + TA a t t \text{EPRHSE}+\text{TA}_{att} EPRHSE+TAatt、 EPRHSE + TA 𝑠 𝑢 𝑚 \text{EPRHSE}+\text{TA}_{𝑠𝑢𝑚} EPRHSE+TAsum和 EPRHSE + TA 𝑐 𝑜 𝑛 𝑐 𝑎 𝑡 \text{EPRHSE}+\text{TA}_{𝑐𝑜𝑛𝑐𝑎𝑡} EPRHSE+TAconcat。
如表6所示,实验结果表明:未采用超图融合机制的EPRHSE整体表现最优。具体来看, EPRHSE + TA a t t \text{EPRHSE}+\text{TA}_{att} EPRHSE+TAatt在20个场景中有11个取得最优或次优结果, EPRHSE + TA 𝑠 𝑢 𝑚 \text{EPRHSE}+\text{TA}_{𝑠𝑢𝑚} EPRHSE+TAsum在20个场景中有10个取得最优或次优结果, EPRHSE + TA 𝑐 𝑜 𝑛 𝑐 𝑎 𝑡 \text{EPRHSE}+\text{TA}_{𝑐𝑜𝑛𝑐𝑎𝑡} EPRHSE+TAconcat在20个场景中有8个取得最优或次优结果。作者推测,出现这一现象的原因可能是:EPRHSE的图编码器在一定程度上利用了拓扑结构与全局依赖关系,弥补了不同聚合方式带来的影响,从而降低了超图融合机制的重要性。鉴于TA层带来的性能提升有限,且会增加模型复杂度,因此作者在EPRHSE中决定不采用超图融合机制。
5.3超参数敏感性
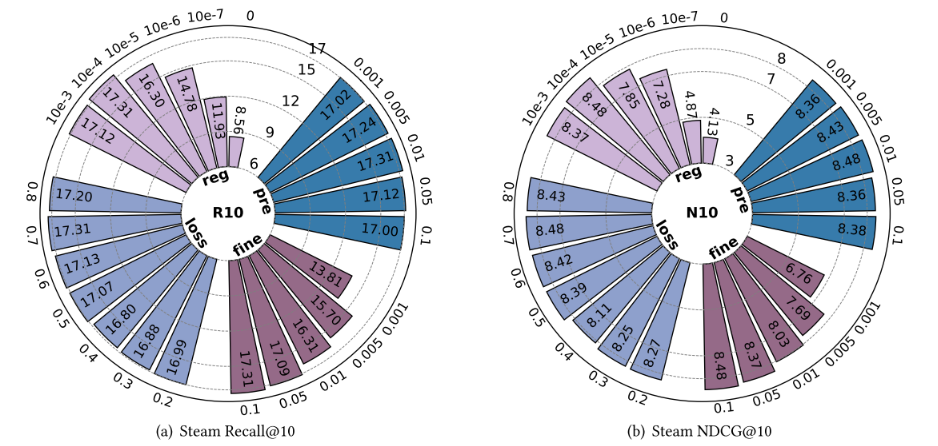
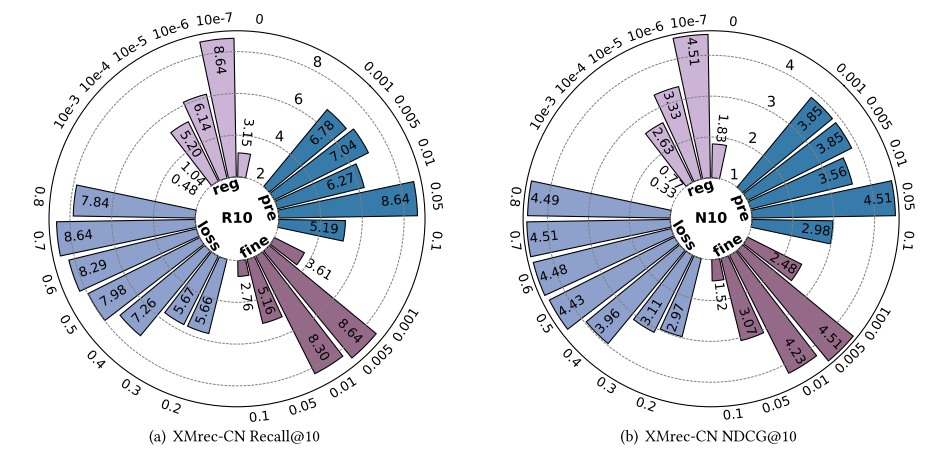
本节针对EPRHSE的四个关键超参数开展敏感性分析,分别是:预训练学习率(𝑝𝑟𝑒_𝑙𝑟)、微调学习率( 𝑙 𝑟 𝑙𝑟 lr)、推荐任务在聚合损失中的权重(Font metrics not found for font: .)以及正则化权重( λ Θ \lambda_{\Theta} λΘ)。图6至图10展示了不同超参数设置下,EPRHSE在五个数据集上的实验结果。左侧子图呈现Recall@10(10值召回率)结果,右侧子图呈现NDCG@10(10值归一化折损累积增益)结果。每个环形柱状图包含四种颜色,分别代表“固定其他超参数、仅调整某一个超参数”的实验设置;外环数值表示超参数的具体取值,内环柱状图的数值则对应相应的测试结果。
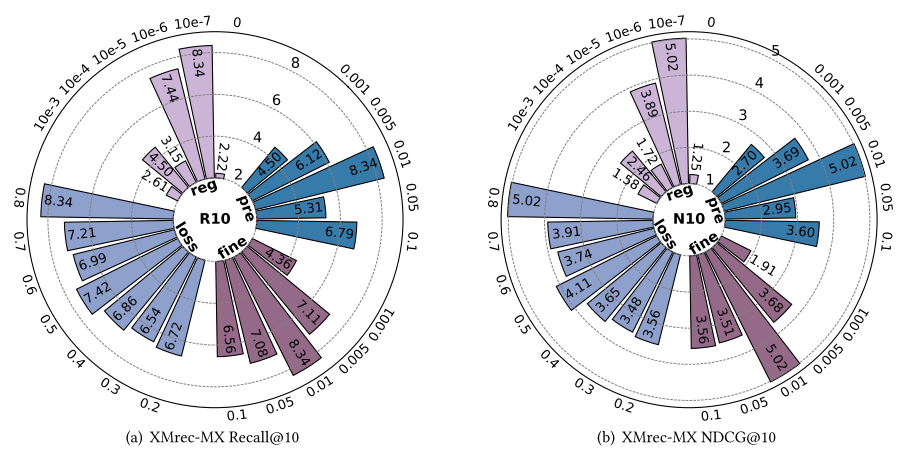
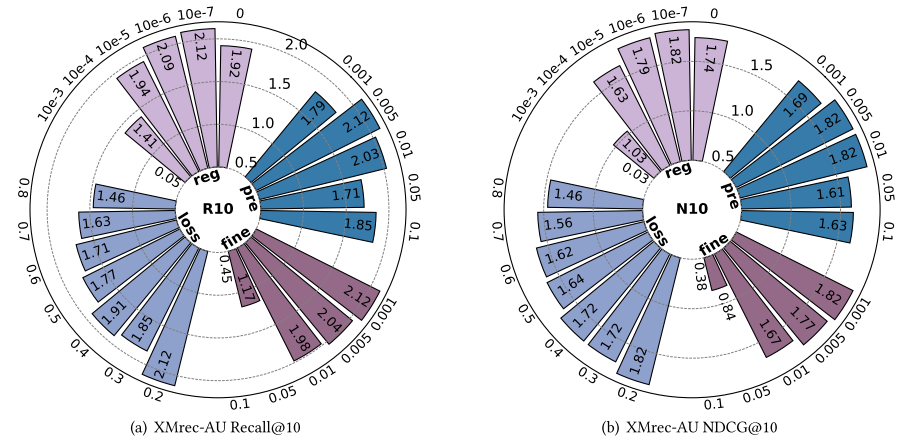
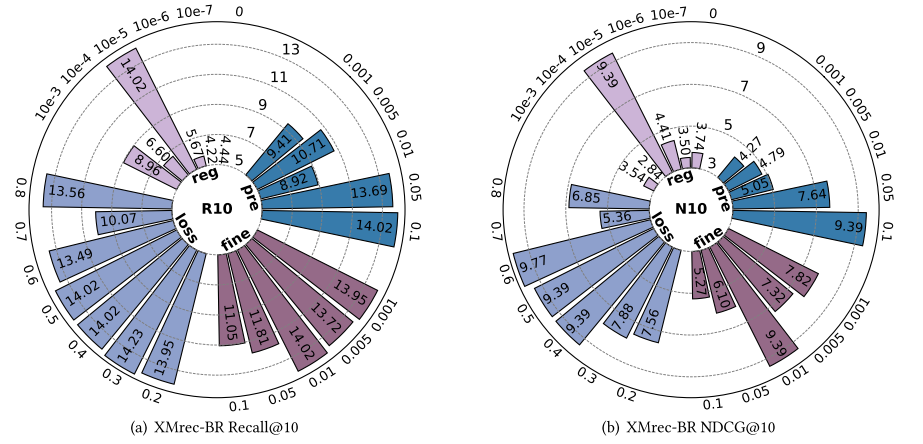
5.3.1 预训练学习率𝑝𝑟𝑒_𝑙𝑟
针对预训练学习率𝑝𝑟𝑒_𝑙𝑟,作者将其取值范围设为{0.001, 0.005, 0.01, 0.05, 0.1}并开展重复实验。如图6至图10所示,𝑝𝑟𝑒_𝑙𝑟的最优取值具有数据集依赖性:该参数对Steam数据集的影响最小,而在其余四个数据集上均存在最优取值或最优取值范围。
- 在XMrec-CN数据集上,0.05是召回率(Recall)和归一化折损累积增益(NDCG)的共同最优选择,其他取值会导致推荐性能大幅下降;
- 在XMrec-MX数据集上,0.01为最优取值,取值过大或过小均会使性能显著降低;
- 在XMrec-AU数据集上,0.005为最优选择,但NDCG对𝑝𝑟𝑒_𝑙𝑟变化的鲁棒性优于Recall——在0.001至0.01的范围内,NDCG性能保持稳定;
- 类似地,在XMrec-BR数据集上,0.1为最优取值,但Recall对𝑝𝑟𝑒_𝑙𝑟变化的鲁棒性优于NDCG——在0.05和0.1两个取值下,Recall均表现良好。
5.3.2 微调学习率𝑙𝑟
针对微调学习率𝑙𝑟,作者将其取值范围设为{0.001, 0.005, 0.01, 0.05, 0.1}并开展重复实验。总体而言,选择中间值的学习率通常对EPRHSE的推荐性能有利,但最优取值仍具有数据集依赖性。
- 如图6所示,Steam数据集上𝑙𝑟与推荐性能呈正相关关系:学习率越高,性能越好,不过整体波动幅度相对较小;
- 如图7所示,XMrec-CN数据集在𝑙𝑟=0.01和𝑙𝑟=0.005时性能稳定,在其他设置下性能则大幅下降;
- 如图8所示,XMrec-MX数据集在𝑙𝑟=0.01时取得最佳性能;
- 如图9和图10所示,XMrec-AU和XMrec-BR数据集上𝑙𝑟与推荐性能呈负相关关系:学习率越低,结果越好。不过,XMrec-BR数据集的NDCG@10(10值归一化折损累积增益)在𝑙𝑟=0.01时表现尤为突出。
5.3.3 推荐任务权重Font metrics not found for font: .
针对损失函数中推荐任务的权重Font metrics not found for font: .,作者将其取值范围设为{0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8}并开展重复实验。在大多数主任务损失权重范围内,预训练阶段的推荐性能保持相对稳定且良好。具体来看:
- Steam数据集几乎不受该权重变化的影响;
- 对于XMrec-CN和XMrec-MX数据集,权重较小时推荐性能会下降,但当权重超过约0.5后,性能趋于稳定并保持在较高水平;
- 反之,对于XMrec-AU和XMrec-BR数据集,权重过大(尤其是超过0.6时)会导致推荐性能大幅下降,而在其余范围内,性能仍保持相对良好。
5.3.4 正则化权重 λ Θ \lambda_{\Theta} λΘ
针对正则化权重 λ Θ \lambda_{\Theta} λΘ,作者将其取值范围设为{10e-3, 10e-4, 10e-5, 10e-6, 10e-7, 0}并开展重复实验。研究发现,正则化权重的选择对不同数据集具有独特且显著的影响,每个数据集均呈现出明确的“偏好”取值。
- 对于图6中的Steam数据集,10e-4是最优选择:取值过大会导致性能小幅下降,取值过小则会使性能大幅下滑;
- 对于图7至图9中的XMrec-CN、XMrec-MX和XMrec-AU数据集,10e-7是最优选择。尽管该取值极小,但至关重要——将其设为0会导致推荐性能显著下降;
- 对于图10中的XMrec-BR数据集,10e-5是最佳选择:取值略大或略小,均会导致推荐性能近乎完全损失。
5.4冷启动
EPRHSE 在预训练过程中融入了涉及属性和关系的辅助任务,使其能够解决冷启动问题。为验证这一点,作者隐藏了不同比例用户的所有相关用户 - 物品交互数据,随后重新运行模型。作者将EPRHSE的结果与一个移除了所有辅助任务的变体模型(命名为EPRHSE_w/o_auxiliary)以及四个预训练基准模型(GCC、SGL、AttriMask、UPRTH)进行了对比。实验结果如图11所示,其中红色曲线代表 EPRHSE。每一行对应一个特定数据集的结果,从左到右四列分别代表 Recall@10(前10项召回率)、Recall@20(前20 项召回率)、NDCG@10(前10项归一化折损累积增益)和 NDCG@20(前20 项归一化折损累积增益)。选取五个比例点 {0.1, 0.2, 0.3, 0.4, 0.5} 开展实验,这些比例点代表无历史交互数据的用户占比,也可理解为孤立节点的比例。作者的发现如下:
(1)总体而言,EPRHSE(红色曲线)在冷启动场景下保持了优异的性能,这要归功于辅助任务的作用。值得注意的是,在 XMrec-AU 数据集上,随着冷启动用户比例的增加,Recall@10、Recall@20以及NDCG@10、NDCG@20 均呈现出明显的上升趋势,甚至超过了未隐藏用户 - 物品交互信息场景下的性能。在XMrec-BR数据集上,EPRHSE并未显著优于性能最佳的基准模型 UPRTH,尤其是在冷启动用户比例为20%时;但其整体性能保持稳定,未受归纳比例(即冷启动用户比例)变化的显著影响。当所有辅助任务被移除后(绿色曲线),EPRHSE_w/o_auxiliary 的推荐性能相较于 EPRHSE 和 UPRTH 均大幅下降,但仍与其他基准模型的性能相当。
(2)在Steam数据集上,EPRHSE及其变体模型 EPRHSE_w/o_auxiliary 基本不受冷启动用户比例的影响,均实现了优异的推荐性能。相比之下,AttriMask和UPRTH虽呈现出轻微的下降趋势,但波动幅度很小。这表明,对于Steam数据集而言,融入超图结构熵池化模块为提升性能带来的增益,比添加辅助任务更为显著。
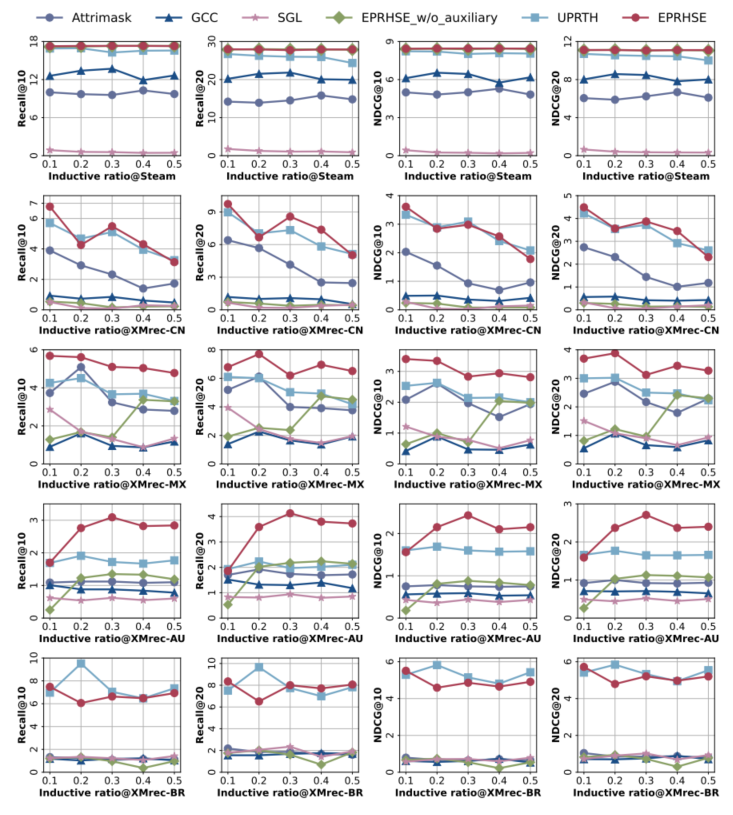
5.5时间分析
作者通过测量 EPRHSE 与其他模型的平均运行时间来评估模型效率。为确保公平性,将所有预训练模型的预训练轮次(epoch)设为 800,微调轮次设为 200;对于无预训练过程的模型,其总训练轮次设为 1000。对于 EPRHSE,还额外记录了为 “用户 - 物品”“物品 - 类别” 和 “物品 - 评分” 任务构建三维编码树所需的运行时间 —— 该过程可视为数据准备阶段的一部分,不包含在前面提到的模型运行时间内。
如表7所示,XMrec-MX和XMrec-AU数据集的 “编码树” 构建在CPU上执行,原因是服务器的GPU内存不足以处理这两个大规模数据集。由于EPRHSE 的编码器中新增了池化层(pooling layer)和反池化层(unpooling layer),与HGNN、AttriMask、UPRTH 等其他基于HGCN(超图卷积网络)的模型相比,EPRHSE 在每个轮次中需要进行更广泛的信息聚合,因此运行时间有所增加。但总体而言,运行时间的增加仍处于可接受范围内。
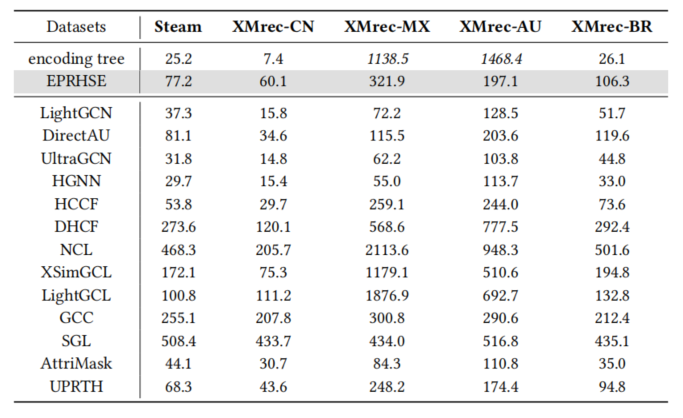
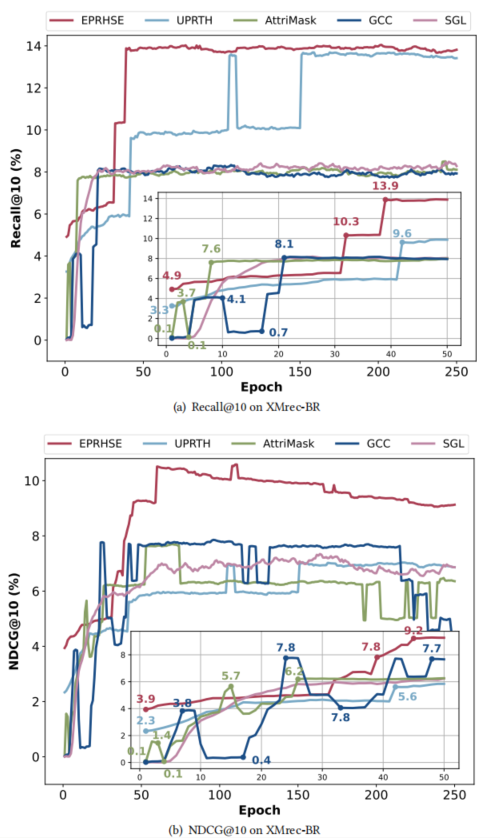
与所有基准模型相比,EPRHSE的运行时间处于中等水平:其速度慢于LightGCN、DirectAU、UltraGCN、HGNN、HCCF、AttriMask 和 UPRTH,但快于 DHCF、NCL、XSimGCL、LightGCL、GCC 和 SGL。此外,EPRHSE 的性能优于所有基准模型。作者认为,为提升推荐性能而牺牲部分计算时间是值得的权衡。
对模型运行时间的分析不仅需考虑每轮训练的执行时间,还需关注模型的收敛速度。因此,对比了包含 EPRHSE 在内的5个预训练模型的微调曲线,以进一步探究这一问题。图12展示了在 XMrec-BR数据集上,经过250 轮微调后,模型在Recall@10(前10项召回率)和NDCG@10(前10项归一化折损累积增益)指标上的性能变化;图中的插图放大了前 50 轮的结果,以便更细致地观察关键数据。作者的主要发现如下:
(1)总体而言,EPRHSE 收敛速度快,且能保持长期稳定性。相比之下,UPRTH 的收敛速度最慢,且在训练后期出现显著的性能下降。尽管 GCC、SGL 和 AttriMask 能较快达到性能峰值,但其整体性能仍处于较低水平。例如,GCC 的 NDCG@10 在训练后半段出现剧烈波动。
(2)在微调初期,EPRHSE、UPRTH 和 SGL 呈现出明显的性能上升趋势;而 GCC 和 AttriMask 则呈现 “螺旋式上升” 特征,训练过程中性能起伏剧烈。以 GCC 为例,其 Recall@10 在第 10 轮时初步上升至 4.1,但随后骤降至约 0.7,直至第 21 轮左右才恢复至 8.1。
(3)EPRHSE 的初始性能(微调开始时)最高,这印证了预训练的有效性。具体而言,预训练结束后,EPRHSE 的 Recall@10 立即达到 4.9,NDCG@10 达到3.9;而 SGL、GCC 和 AttriMask 此时的指标仅为 0.1 左右,UPRTH 的 Recall@10 和 NDCG@10 也仅为 3.3 和 2.3。
5.6图与嵌入的可视化
5.6.1 图可视化
本节以Steam数据集为对象,对基于超图结构熵的层级化社区划分结果进行可视化,重点关注三类任务:“物品-类别(item-cate)”“物品-评分(item-rate)”和“用户-物品(user-item)”。
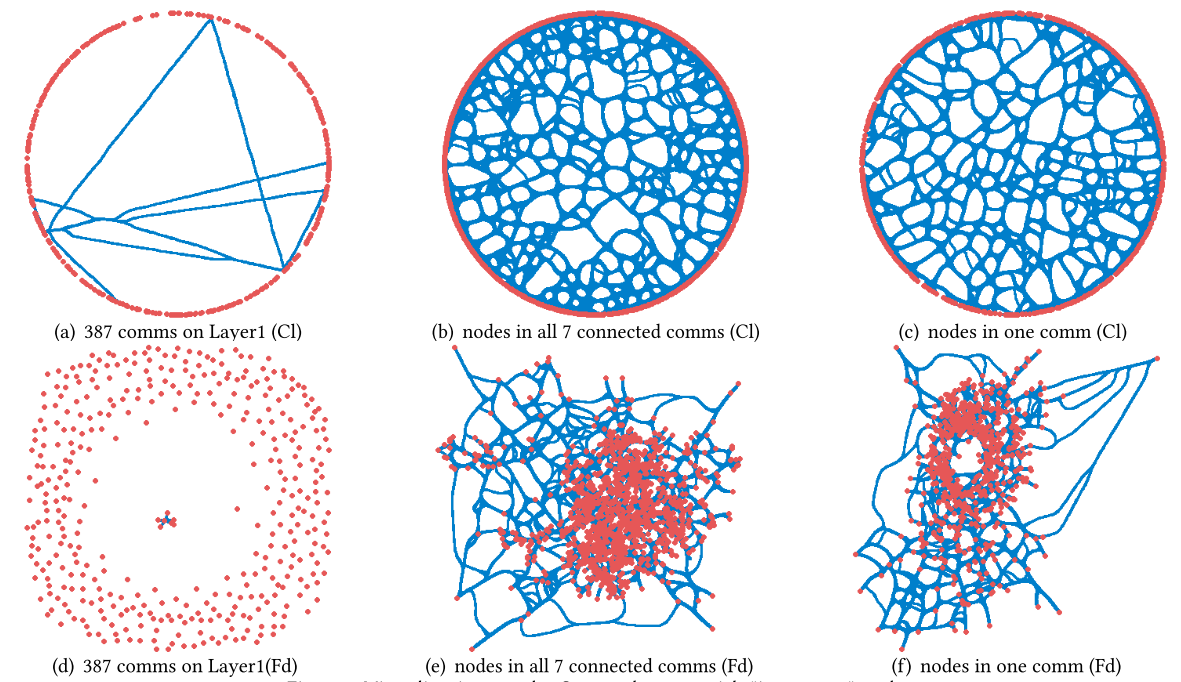
如图13所示,呈现了“物品-类别”任务的可视化结果:第一行子图采用“环形(Circular)”布局方式生成,第二行子图则采用“力导向(Force-directed)”布局方式生成。
- 图13(a)展示了经超图结构熵一级划分后得到的387个社区间的连接关系,每个节点代表一个社区,对应表5中的1层(Layer 1);
- 图13(b)展示了图13(a)中7个连通社区内所有物品的社区内连接关系,每个节点代表一个独立物品;
- 图13©是图13(a)中单个社区的放大视图,呈现了该社区内物品间的内部结构,可视为图13(b)的局部放大;
- 图13(d)、图13(e)、图13(f)分别与图13(a)、图13(b)、图13©内容一致,仅采用“力导向”布局策略绘制。
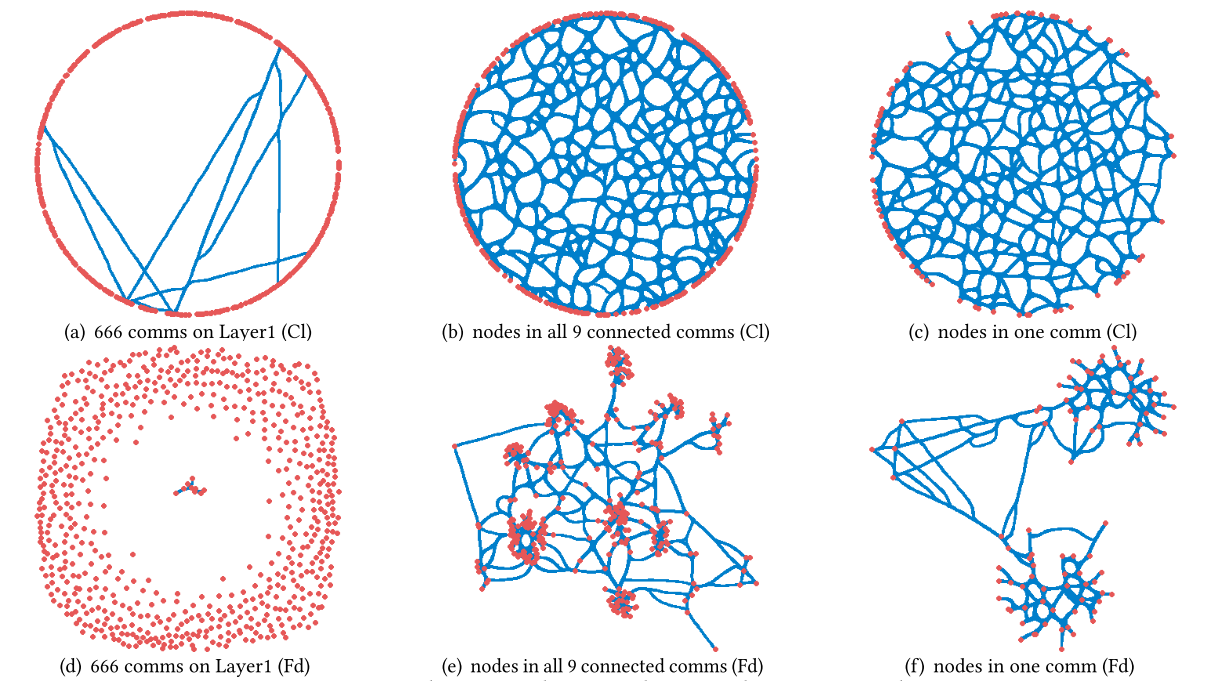
图14呈现了“物品-评分”任务的可视化结果,其构建方法与图13一致,故不展开详述。图15呈现了“用户-物品”任务的可视化结果。由表5可知,1层(Layer 1)共生成1726个社区,数量过多难以直接可视化。为提升清晰度,作者选取5个连通社区中的用户节点,分别在图15(a)和图15©中进行可视化;同时,对其中一个社区进行放大,生成图15(b)和图15(d)。
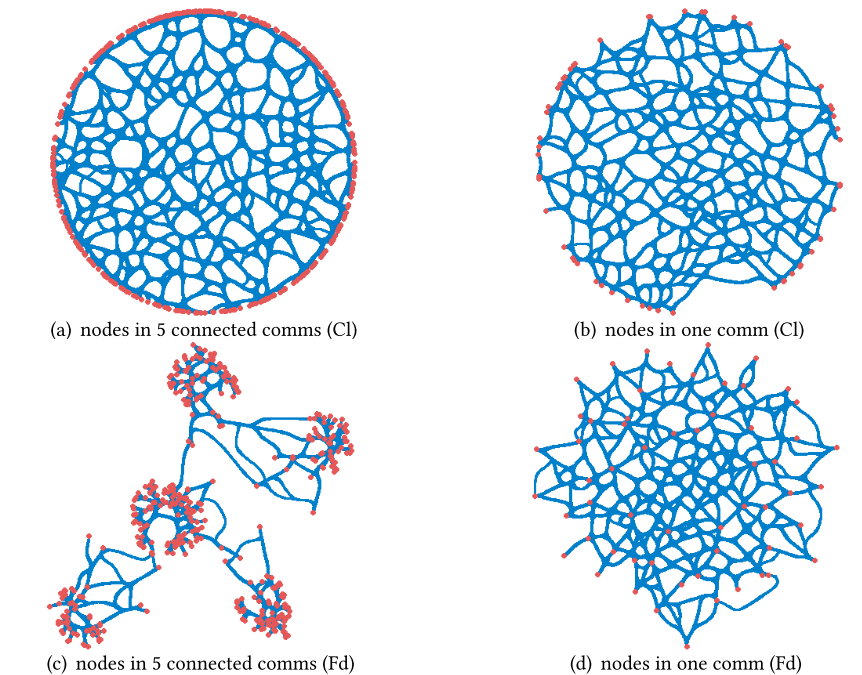
上述三组可视化结果也直观验证了超图结构熵在层级化社区划分中的有效性:它能成功将连接紧密的节点归为一组,这为后续学习用户与物品的组级表示提供了便利,最终对推荐性能产生积极作用。
5.6.2 嵌入可视化
作者对比了EPRHSE、UPRTH和AttriMask三种模型在五个数据集上学到的嵌入分布,并采用t-SNE(t分布随机邻域嵌入)进行二维可视化。如图16至图20所示,第一行的三个子图对应预训练后得到的嵌入,第二行的三个子图对应最终嵌入;其中橙色节点代表用户,蓝色节点代表物品。得出以下观察结果:
1. 预训练阶段的嵌入特征
EPRHSE预训练得到的嵌入相比另外两种模型,呈现出更明显的层级化社区结构:具体表现为包含不同规模的社区、节点分布相对分散、社区间距离存在差异。这一特征符合预期——预训练阶段的目标正是融合不同任务的信息,为用户和物品构建具有代表性的嵌入。
- 反观UPRTH的嵌入,其社区内部往往过度聚集,可能导致个体信息丢失或模型过拟合,这一现象很可能与TA层的融合机制有关;
- 而AttriMask的嵌入则表现为用户与物品嵌入过度分散:要么形成密集簇,要么成为孤立点,最终呈现出极端的分布状态。
2. 最终嵌入特征
EPRHSE的最终嵌入不仅保留了预训练阶段建立的层级化社区结构,还在组级层面实现了用户与物品嵌入的对齐。这种对齐机制为Top-k组级推荐提供了便利,也解释了为何EPRHSE在@20(即Recall@20、NDCG@20)指标上能取得更优性能。
- 相比之下,UPRTH和AttriMask的最终嵌入要么仍过度紧凑(形成单一密集簇),要么呈现出过度离散的状态,仅能实现用户与物品间点对点的对齐——这两种情况均对推荐任务不利。
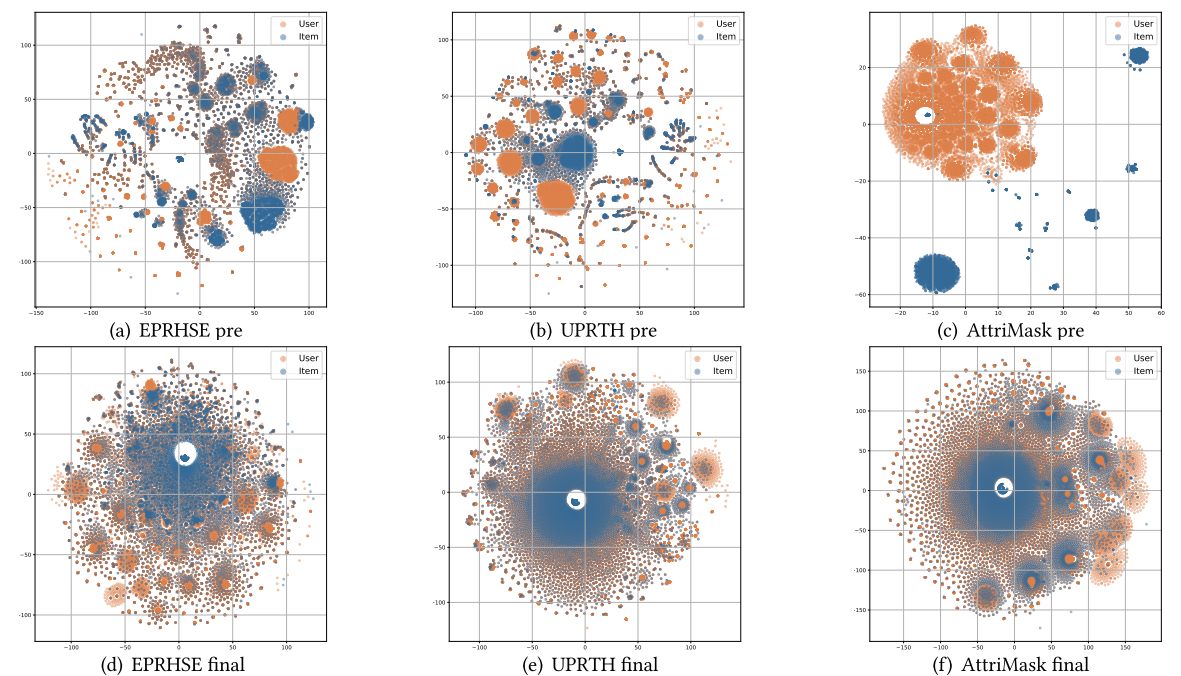
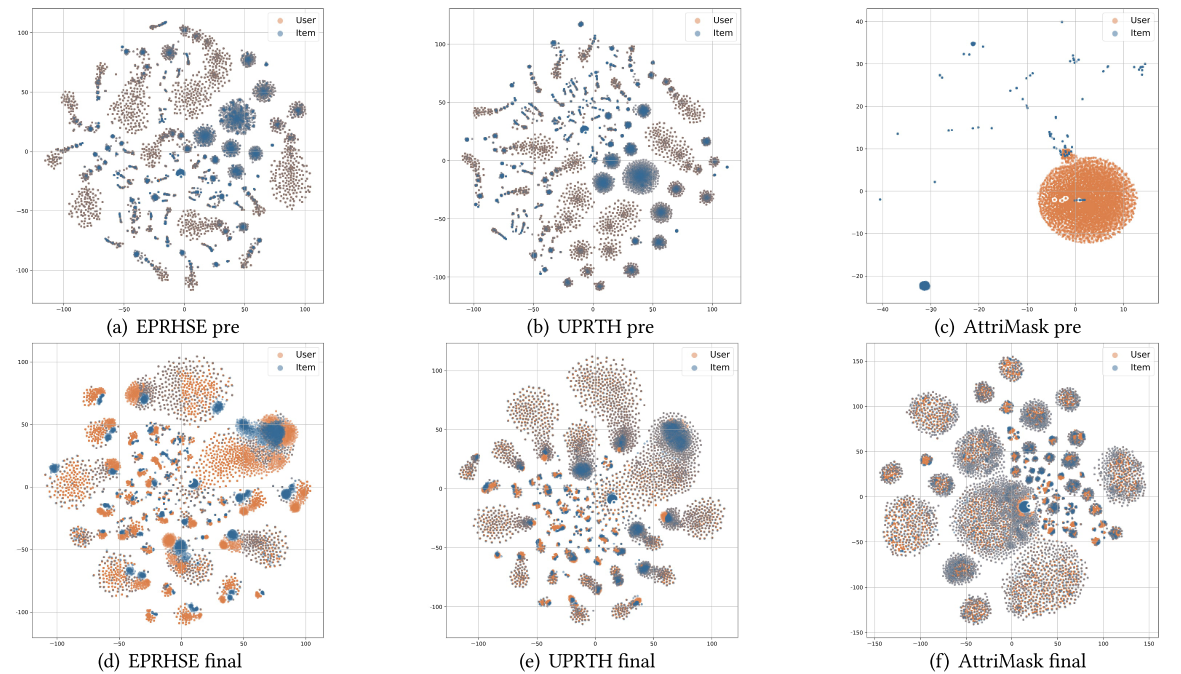
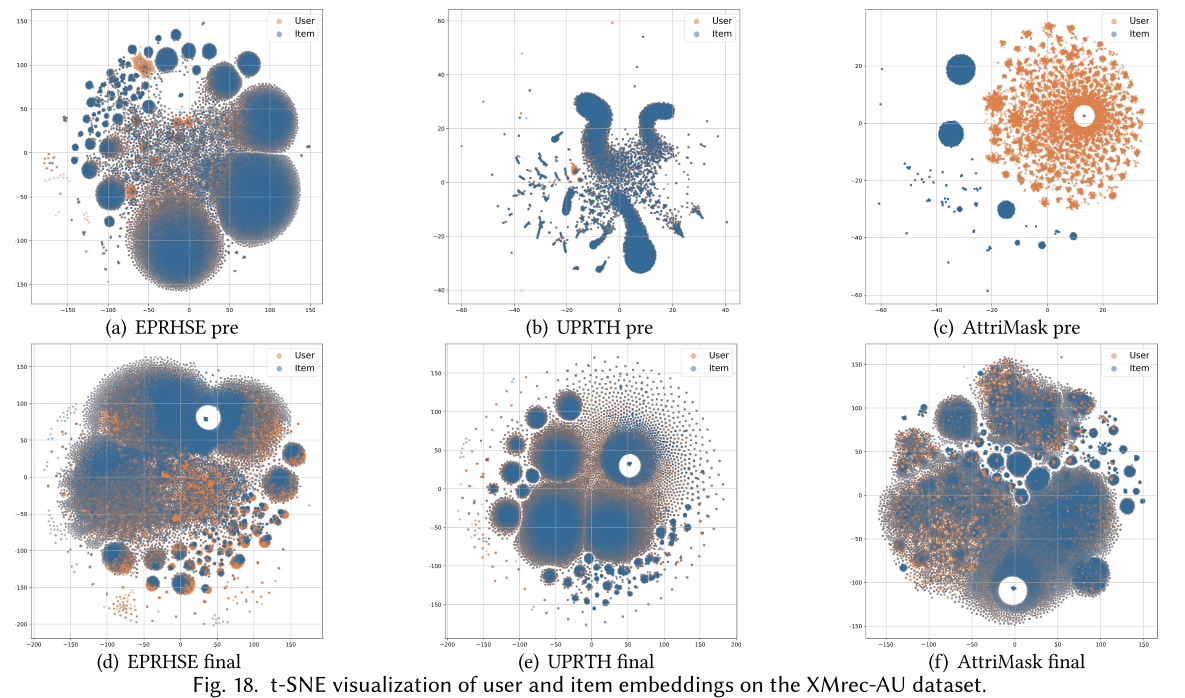
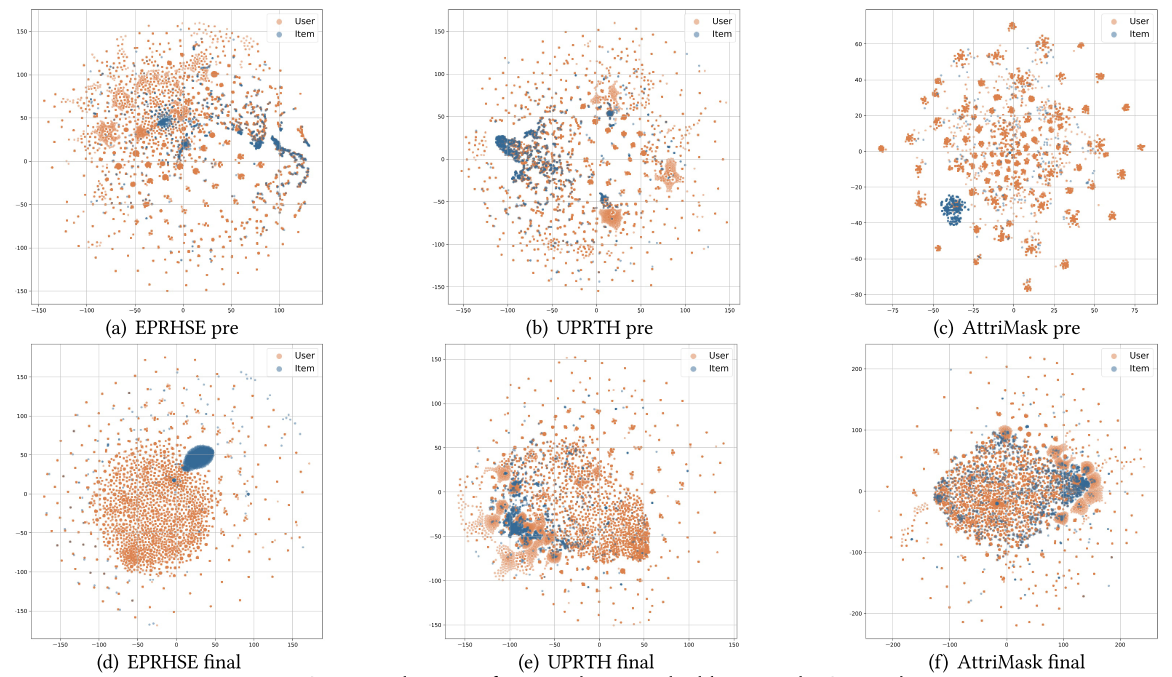
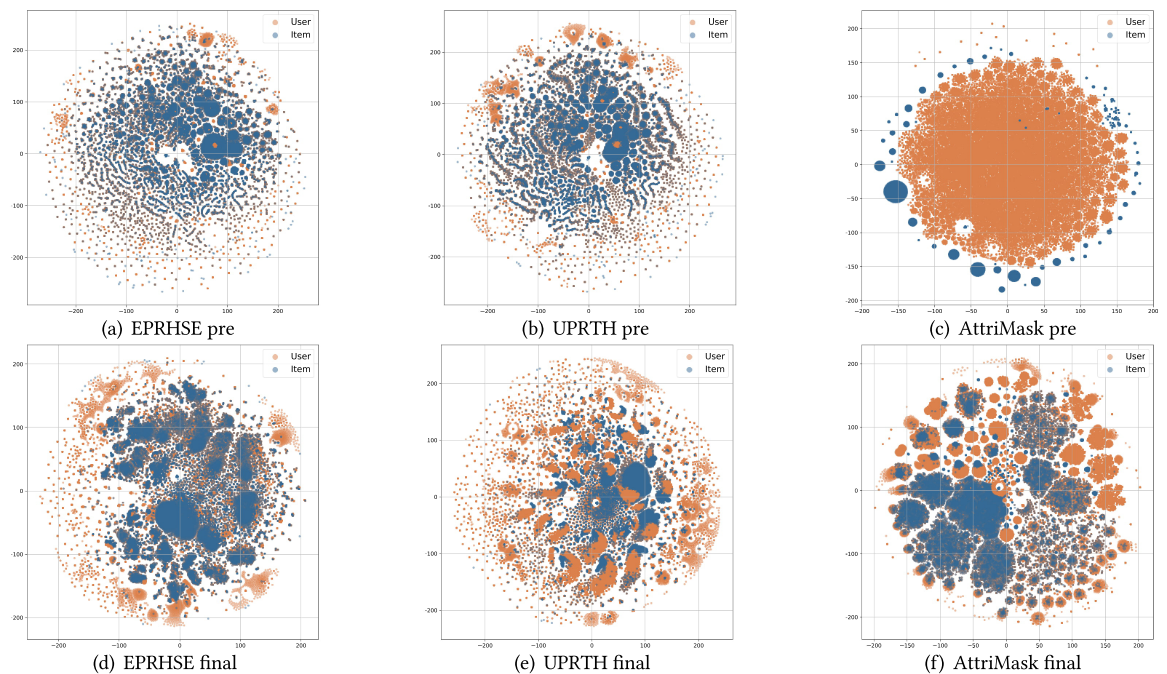
基于上述观察结果,作者总结出嵌入分布应具备的理想特性:优质嵌入需形成能反映组级特征的层级化社区,同时避免节点过度融合导致个体特有信息丢失;在每个社区内部,节点不应过度聚集——簇内相似度过高会产生冗余;最后,用户与物品嵌入的对齐应在组级层面实现,而非一对一层面,因为一对一对齐同样可能引入过多冗余。
6 结论
本文研究了一种基于超图结构熵的新型增强型推荐预训练框架。所提出的 EPRHSE(基于超图结构熵的增强型推荐预训练框架)能够对推荐系统的拓扑结构进行编码。通过构建融合辅助任务的预训练框架,有效捕捉了用户(物品)间的异质关系,并解决了用户 - 物品交互稀疏性问题。此外,通过将结构信息理论融入超图学习,作者在构建高维编码树的过程中实现了用户(物品)的层级社区划分,充分挖掘了超图内部的拓扑结构。超图池化技术不仅为模型架构优化提供了指导,还支持全局依赖关系的提取,进而增强了对社交扩散过程的模拟效果,提升了节点嵌入质量。实验结果表明,在 Recall(召回率)和 NDCG(归一化折损累积增益)指标上,EPRHSE 的性能均优于基准模型,且在冷启动场景下展现出较强的稳定性和优异性能。本研究证实了结构信息理论在超图学习中的应用潜力,或将为超图结构熵领域开辟新的研究方向。未来,作者计划从结构视角探索其他超图学习方法,并将超图学习扩展到更多研究领域。
篇幅原因,我们在本文中省略了诸多细节,更多细节可以在论文中找到。感谢阅读!
参考文献
[1]Walid Krichene and Steffen Rendle.On sampled metrics for item recommendation. In Proceedings of the ACM SIGKDD international conference on knowledge discovery & data mining, 2020.
[2]Muhammad Aljukhadar, Sylvain Senecal, and Charles-Etienne Daoust. Information overload and usage of recommendations.In Proceedings of the ACM RecSys 2010 Workshop on User-Centric Evaluation of Recommender Systems and Their Interfaces (UCERSTI),Barcelona, Spain, 2010.
[3]Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, and Tat-Seng Chua. On softmax direct preference optimization for recommendation. Advances in Neural Information Processing Systems 37 (2024), 2024.
[4]Sherrie YX Komiak and Izak Benbasat. The effects of personalization and familiarity on trust and adoption of recommendation agents. MIS quarterly (2006), 2006.
[5]Abhinandan S Das, Mayur Datar, Ashutosh Garg, and Shyam Rajaram. Google news personalization: scalable online collaborative filtering. In Proceedings of the 16th international conference on World Wide Web, 2007.
[6]Chumki Basu, Haym Hirsh, William Cohen, et al. Recommendation as classification: Using social and content-based information in recommendation. In Proceedings of the AAAI Conference, 1998.
[7]Mohsen Jamali and Martin Ester. A matrix factorization technique with trust propagation for recommendation in social networks.In Proceedings of the fourth ACM conference on Recommender systems, 2010.
[8]Denis Parra, Alexandros Karatzoglou, Xavier Amatriain, Idil Yavuz, et al.Implicit feedback recommendation via implicit-to-explicit ordinal logistic regression mapping. Proceedings of the CARS-2011 5 (2011), 2011.
[9]Jingyuan Chen, Hanwang Zhang, Xiangnan He, Liqiang Nie, Wei Liu, and Tat-Seng Chua. Attentive collaborative filtering:Multimedia recommendation with item-and component-level attention. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, 2017.
[10]Shristi Shakya Khanal, PWC Prasad, Abeer Alsadoon, and Angelika Maag.A systematic review: machine learning based recommendation systems for e-learning. Education and Information Technologies 25, 4 (2020), 2020.
[11]Bilal Khan, Jia Wu, Jian Yang, and Xiaoxiao Ma.Heterogeneous hypergraph neural network for social recommendation using attention network. ACM Transactions on Recommender Systems (2023), 2023.
[12]Mingdai Yang, Zhiwei Liu, Liangwei Yang, Xiaolong Liu, Chen Wang, Hao Peng, and Philip S Yu.Unified Pretraining for Recommendation via Task Hypergraphs. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, 2024.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)