14-深度学习的图生成模型
这里使用的这个模型和VAE,GAN等模型不一样,VAE,GAN一般有两个部分构成:encoder+Decoder或者generator+discriminator,两个部分分别做数据的表征和生成,这个模型只有一个部分,直接用来做数据的密度估计和采样。主要是生成过程计算量很大,可以看到,每次添加新的点,那么这个点要和其他所有已经存在的点做边RNN预测,但是这个可以优化,因为当前加入的节点并不是和所有
图机器学习(深度学习的图生成模型)
1. 前言
1. 图生成任务分为两种:
- 逼真的图形生成:生成与给定的一系列图相似的图
- 目标导向图生成:生成优化特定目标或约束的图(举例:生成/优化药物分子)
2. 图生成模型
从给定的数据中通过采样得到图 P d a t a ( G ) P_{data}(G) Pdata(G)(这里的data相当于所有的真实数据,是无穷无尽的,没法穷举,因此只能尽量多的采样来推测整体数据)
通过采样数据,从中可以学习到数据分布 P m o d e l ( G ) P_{model}(G) Pmodel(G),再利用 P m o d e l ( G ) P_{model}(G) Pmodel(G)来生成图

3.生成模型基础
要从一个点数据集 { x i } \{x_i\} {xi}中学习一个生成模型
P d a t a ( x ) P_{data}(x) Pdata(x)是真实数据分布,这个分布是真实存在但由于数据无穷性又无法直接学到,因此我们可以对其进行采样: x i ∼ P d a t a ( x ) x_i\sim P_{data}(x) xi∼Pdata(x)
P m o d e l ( x ; θ ) P_{model}(x;\theta) Pmodel(x;θ)是我们学习的模型, θ \theta θ是模型参数,可以根据模型来估计真实数据分布 P d a t a ( x ) P_{data}(x) Pdata(x)。这个过程类似人口普查,我们不可能完全统计所有人,但是我们可以通过采样某个小区域的人口,来推断整个区域的人口分布。
整个过程大概就是两个步骤:
- 学习到模型
- 模型生成图结构
4. 步骤一
学习到模型就是要使得 P m o d e l ( x ; θ ) P_{model}(x;\theta) Pmodel(x;θ)越接近 P d a t a ( x ) P_{data}(x) Pdata(x)越好,这里通常使用(对数)最大似然的方式来进行估计:
θ ∗ = a r g m a x E x ∼ P d a t a log P m o d e l ( x ∣ θ ) \theta ^*=arg\quad max\mathbb{E}_{x\sim P_{data}}\log P_{model}(x|\theta) θ∗=argmaxEx∼PdatalogPmodel(x∣θ)
找到最优化的参数 θ ∗ \theta ^* θ∗使得模型最有可能生成观测数据x
5. 步骤二
模型生成图结构就是从 P m o d e l ( x ; θ ) P_{model}(x;\theta) Pmodel(x;θ)采样数据,常用方法:
先从复杂分布中采样: z i ∼ N ( 0 , 1 ) z_i\sim N(0,1) zi∼N(0,1)
然后对采样结果 z i z_i zi通过 f ( ⋅ ) f(\cdot) f(⋅)(一般用DNN)进行变化: x i = f ( z i ; θ ) x_i=f(z_i;\theta) xi=f(zi;θ)得到的结果 x i x_i xi就是服从复杂分布的结果
6. 自回归模型
这里使用的这个模型和VAE,GAN等模型不一样,VAE,GAN一般有两个部分构成:encoder+Decoder或者generator+discriminator,两个部分分别做数据的表征和生成,这个模型只有一个部分,直接用来做数据的密度估计和采样。
模型类似语言模型,使用条件概率来表示联合概率:
P m o d e l ( x ; θ ) = ∏ t = 1 n P m o d e l ( x t ∣ x 1 , … … x t − 1 ; θ ) P_{model}(x;\theta)=\prod_{t=1}^nP_{model}(x_t|x_1,……x_{t-1};\theta) Pmodel(x;θ)=t=1∏nPmodel(xt∣x1,……xt−1;θ)
如果是语言模型,则是用前t-换个词 x t − 1 x_{t-1} xt−1预测第t个词 x t x_t xt,从而得到整个句子。这里的图模型, x t x_t xt代表第t个动作(添加节点和边)。
2. GraphRNN
GraphRNN: Generating Realistic Graphs with Deep Auto-regressive Models.
将生成图的过程看成一个序列,例如对于下面的图:
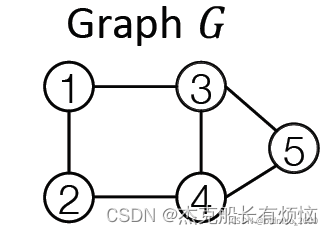
每个步骤记如下:
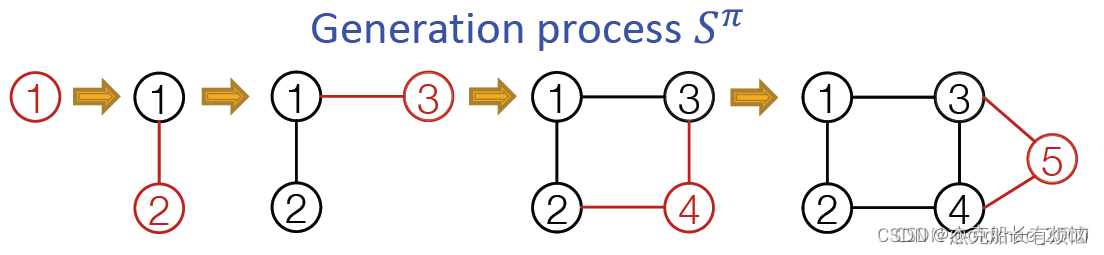
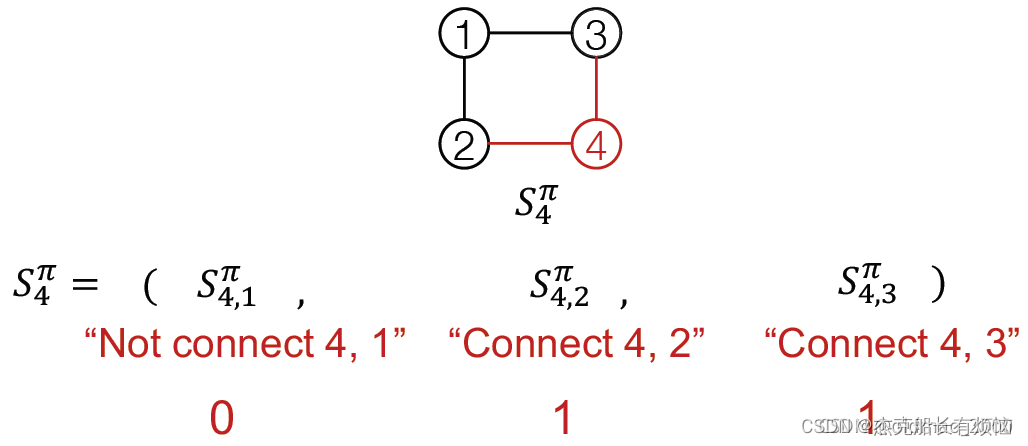
其中π是图G的节点序列(这个当然有必要,因为之前说图是无序的,不知道这里如果不一样生成的模型会不会相同),经过扩展可以将其对应到添加节点和边的动作序列: S π S^\pi Sπ
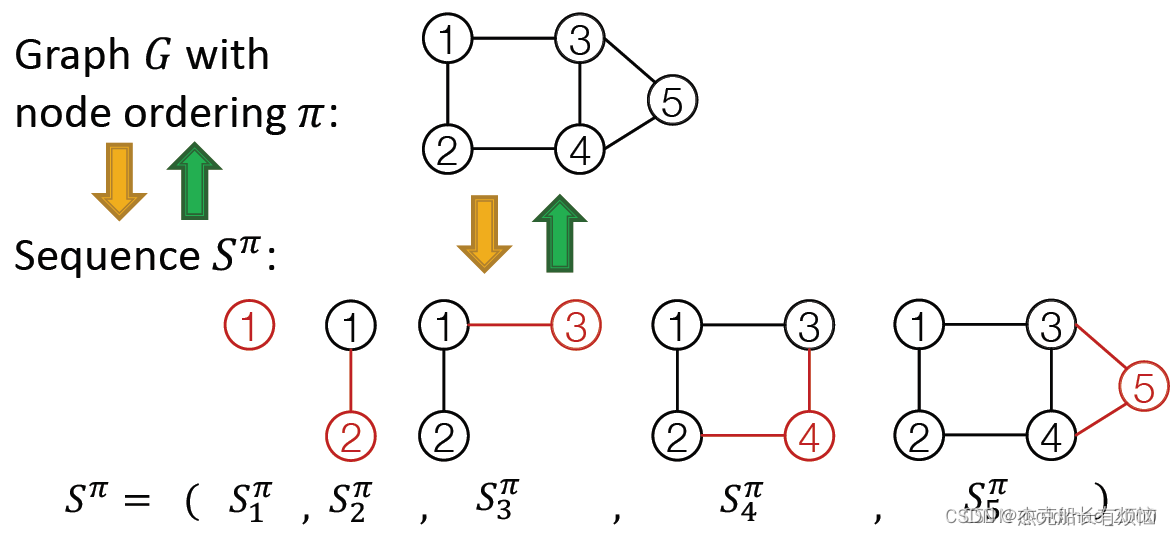
1. 图与序列的映射
由于动作包含两层意思:
Node-level:每次添加一个节点;
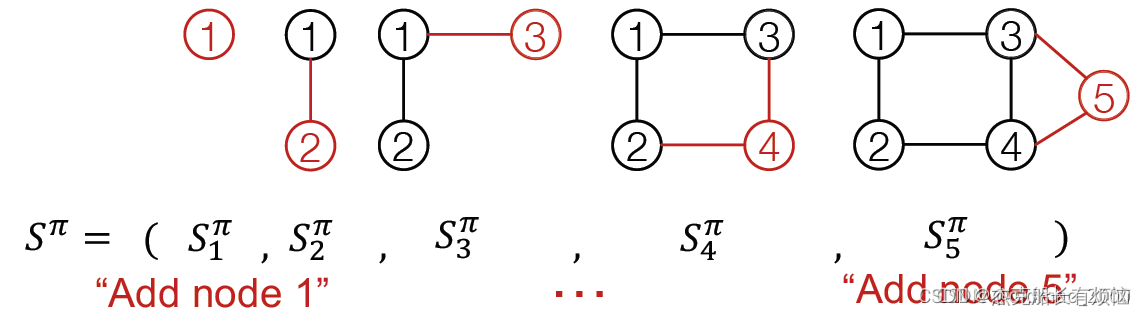
Edge-level:为新加节点与已存在的节点建立边(可以多条)
从邻接矩阵上来看,可以看到两个序列(实际上是序列的序列)关系如下: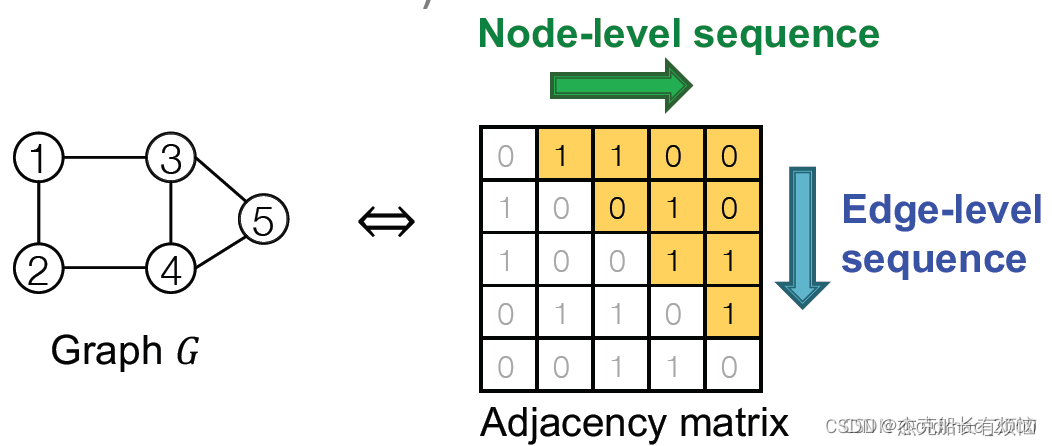
经过图到序列的转化后,就将图生成问题变成了序列生成问题,不过需要处理两个序列:
- 为新节点生成状态(节点级序列)
- 根据新节点的状态(边缘级序列)为新节点生成边缘
2. RNN
RNN是用来处理序列数据的。它接受输入序列,并更新它的隐状态。隐状态包含之前所有序列的信息,更新关键就是RNN Cells
RNN Cells
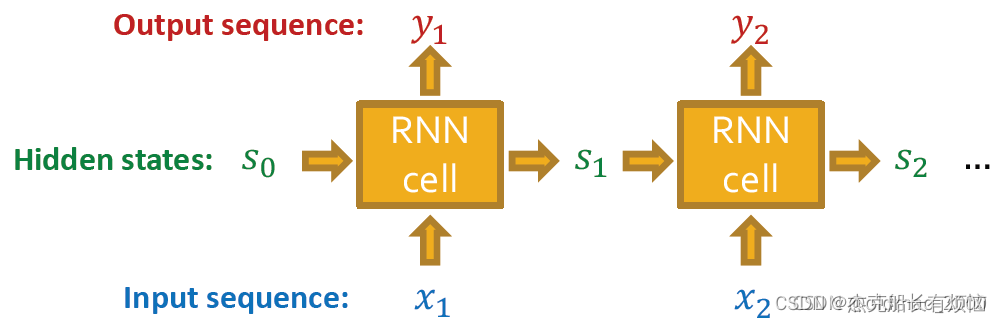
s t s_t st:RNN在第t步之后的状态
x t x_t xt:RNN在第t步的输入
y t y_t yt:RNN在第t步的输出
RNN cell保持三个可训练参数:𝑊 , 𝑈 , 𝑉
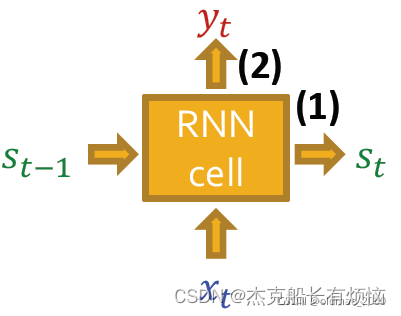
- 更新隐藏层状态:
s t = σ ( W ⋅ x t + U ⋅ s t − 1 ) s_t=\sigma(W\cdot x_t+U\cdot s_{t-1}) st=σ(W⋅xt+U⋅st−1)
- 预测输出:
y t = V ⋅ s t y_t=V\cdot s_t yt=V⋅st
3. GraphRNN
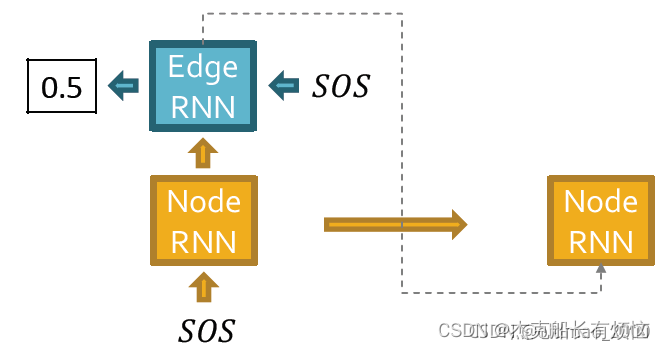
GraphRNN包含节点RNN和边RNN,节点RNN生成的状态会作为输入,输入到边RNN,边RNN将以序列方式对新节点是否连接已有节点进行预测。
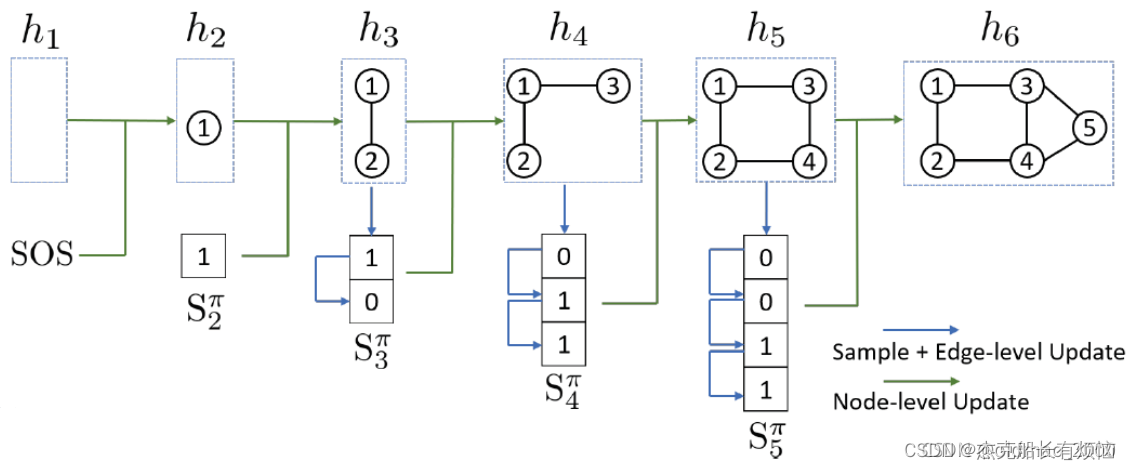
节点RNN是横向,边RNN是纵向。
对于原始的RNN模型,他每次的输出要作为下一个时刻的输入,开始信号是start of sequence token (SOS),终止信号是end of sequence token (EOS),如果输出EOS=0,则RNN继续生成;如果过输出EOS=1,则RNN停止生成。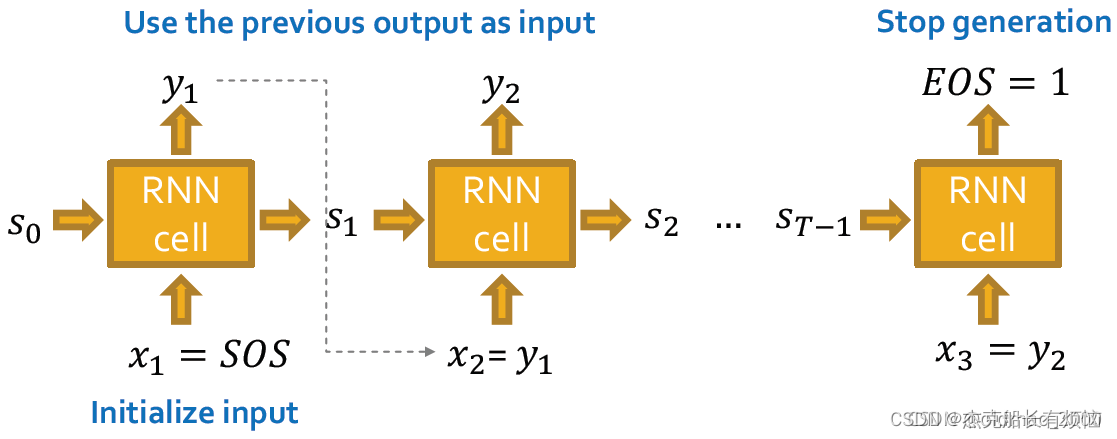
但是这里的输出是不是概率,因此我们想要把原始RNN做第一个修改就是让输出是一个概率,并让生成边的方式是从概率中进行丢硬币决定。
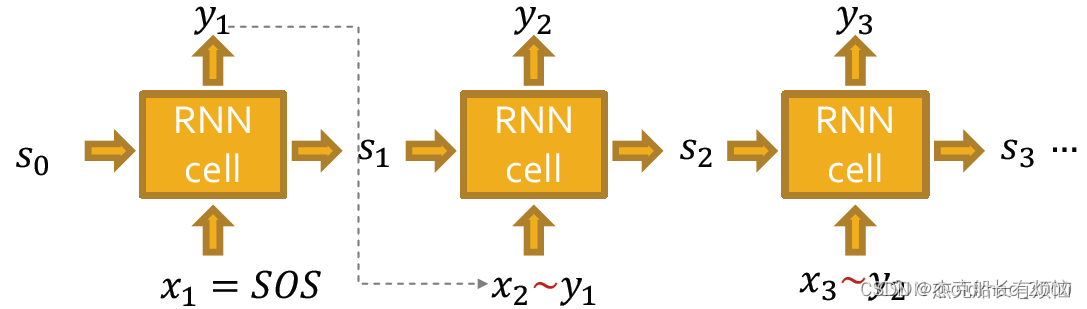
1. 训练
这里使用Teacher Forcing来辅助训练,上面说了原始RNN吃的去前一个时间步的输出和隐状态,但是这样不好,因为训练迭代过程初始阶段,RNN预测能力非常弱,几乎不能给出好的结果。如果某一个cell产生了垃圾结果,必然会影响后面所有cell的学习。也就是说会导致学习速度变慢,难以收敛。
Teacher Forcing不使用上一个时刻的输出作为下一个时刻的输入,而是直接使用训练数据ground truth【1】的对应上一项作为下一个时刻的输入。
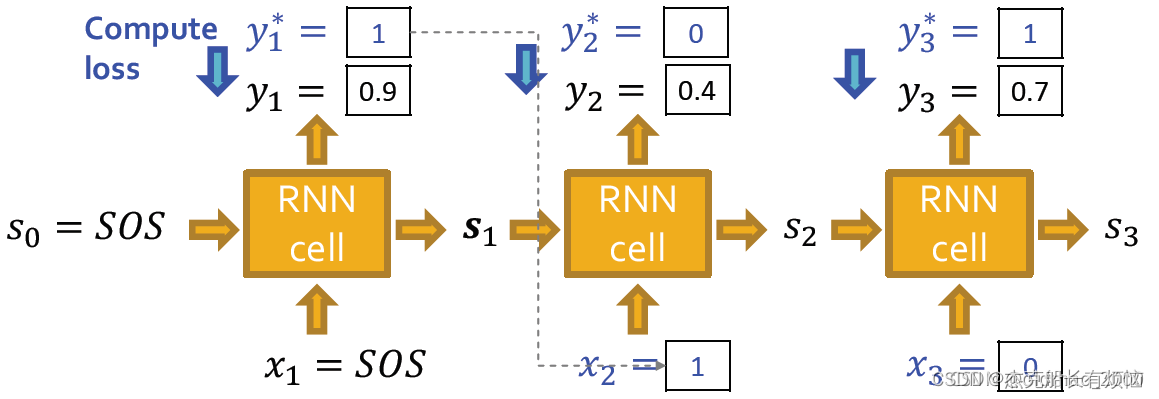
注意看图中 y ∗ = x t + 1 y^*=x_{t+1} y∗=xt+1
当然这个技巧有缺点,就是训练过程中抄答案,测试的时候性能可能会掉。使用Binary cross entropy做损失函数,第一个时间步的损失可以写为:
L = − [ y 1 ∗ log ( y 1 ) + ( 1 − y 1 ∗ ) log ( 1 − y 1 ) ] L=-[y^*_1\log(y_1)+(1-y^*_1)\log(1-y_1)] L=−[y1∗log(y1)+(1−y1∗)log(1−y1)]
2. 测试
每个时间步的输出 y t y_t yt是一个标量,并服从伯努利分布:
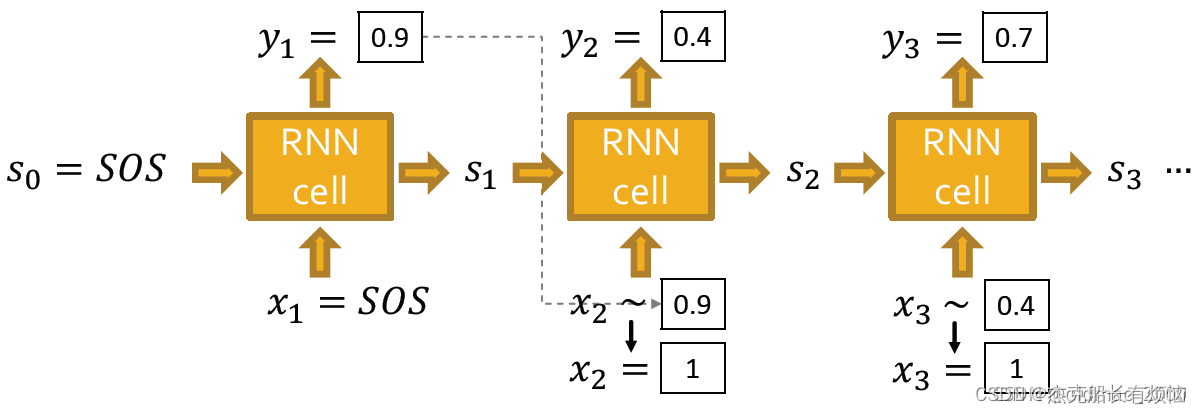
注意这里每个时间步的输出要进行采样在丢进下一个时间步里面,例如:
上图中的 x 2 ∼ 0.9 x_2\sim0.9 x2∼0.9表示 x 2 x_2 x2有0.9的概率为1(有边),0.1的概率没有边,最后采样出来得到 x 2 = 1 x_2=1 x2=1,然后再进入RNN cell。
3. 训练实例
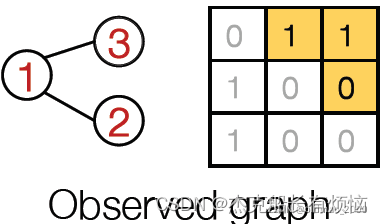
假设观测到的图结构:
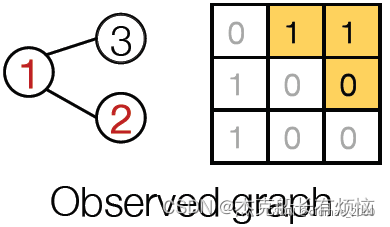
假设1号是初始节点,先加2号
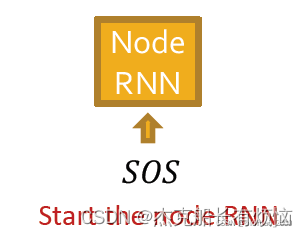
然后边RNN预测2号节点是否连接1号节点
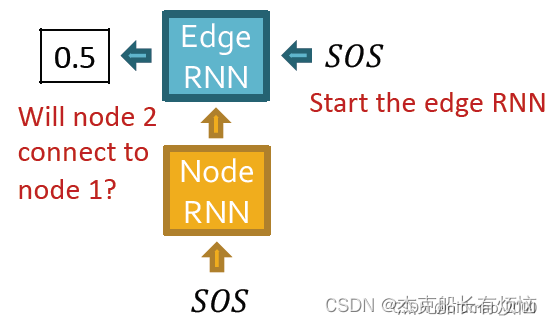
更新节点RNN(吃边RNN的隐状态+上一个节点的输出)
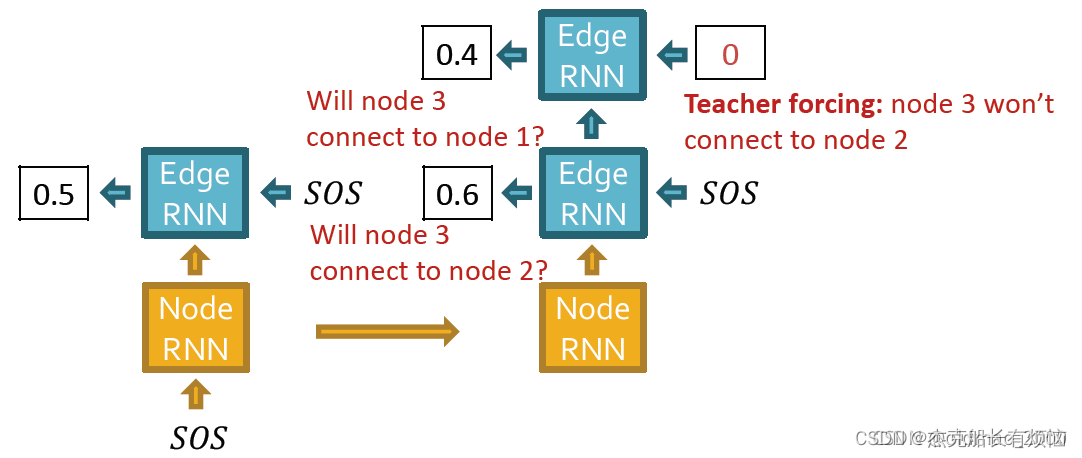
然后边RNN预测3号节点是否连接1号和2号节点
继续更新节点RNN:
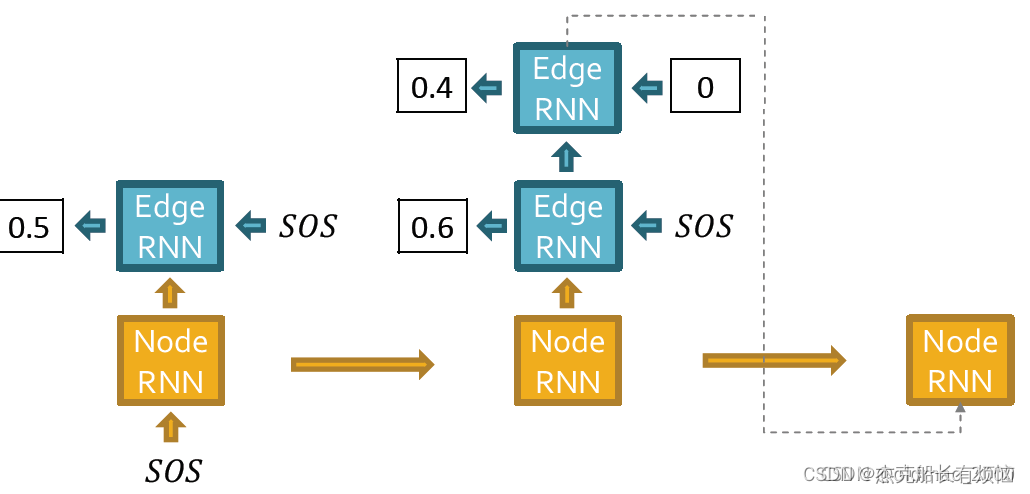
由于这个节点不会连接其他所有节点,因此迭代停止: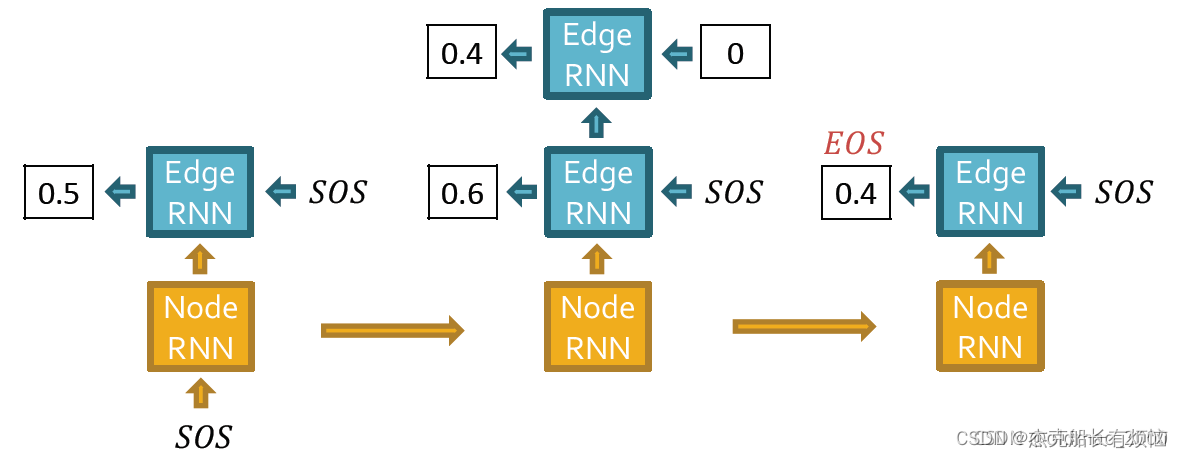
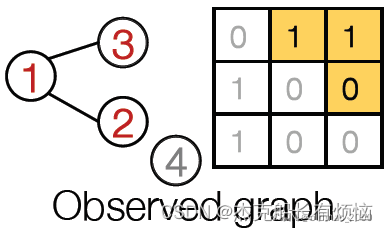
每一次边预测结果要和真实结果(红色)做交叉熵计算:
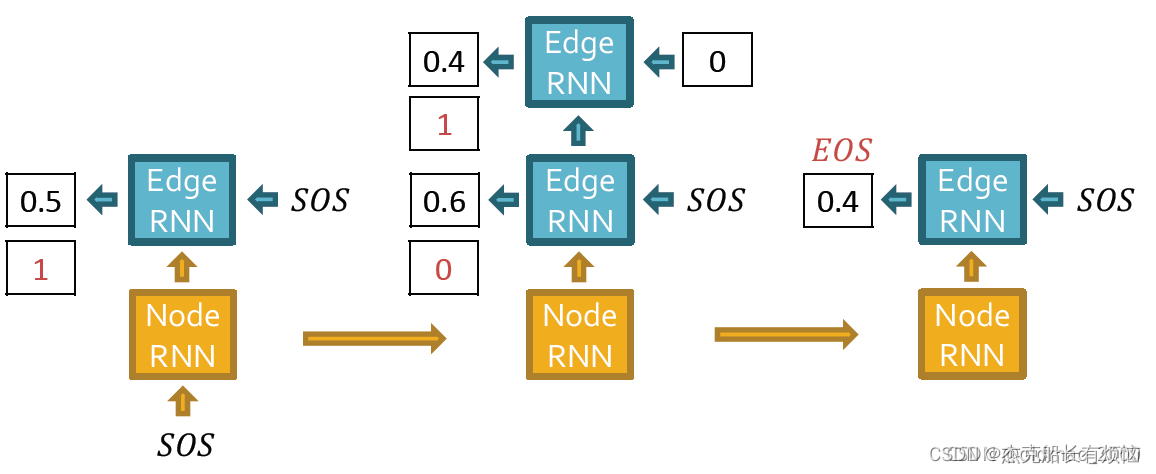
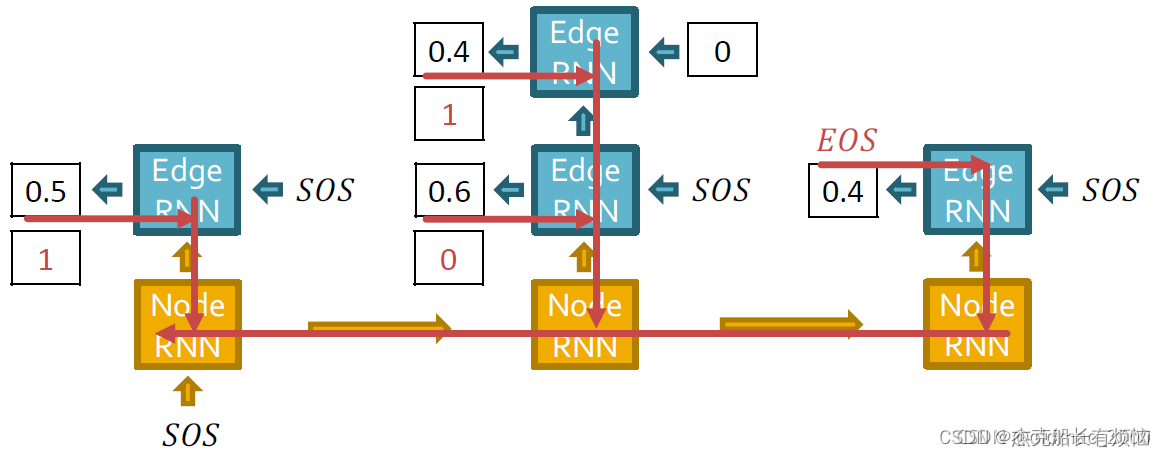
Backprop through time(BTT)方向:
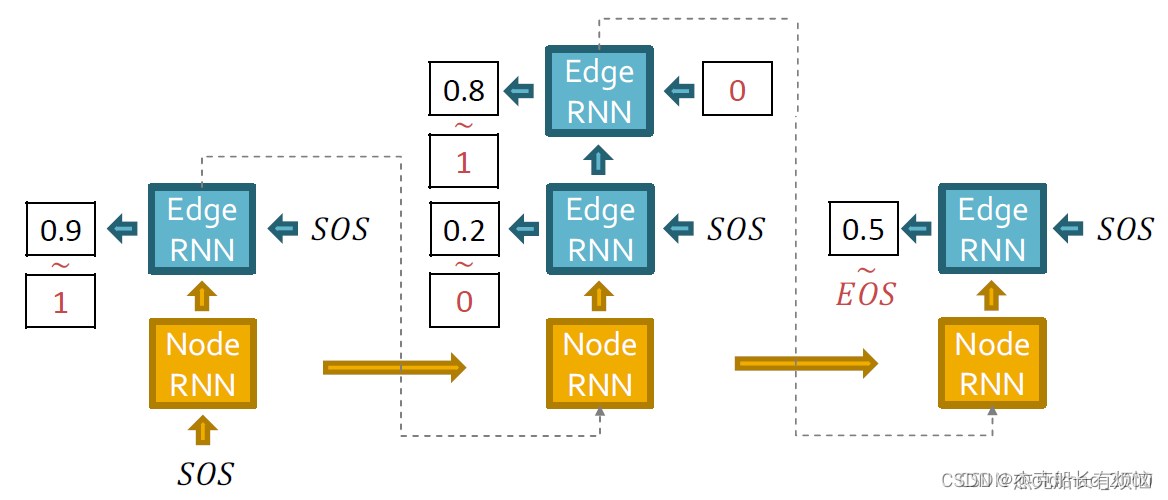
4. 测试例子
将预测出来的概率做边的采样,注意看红色的 ∼ {\color{Red} \sim} ∼,采样结果丢下个时间步的节点RNN
4. 问题及解决方法
主要是生成过程计算量很大,可以看到,每次添加新的点,那么这个点要和其他所有已经存在的点做边RNN预测,但是这个可以优化,因为当前加入的节点并不是和所有节点相连。
考虑BFS(广度遍历)遍历,例如:

这里可以看到节点4没有连接节点1,因为节点1的BFS遍历已经完毕,因此节点5以及后面的节点不会连接到节点1,因此只需要记录前面两个时间步即可。这样可以明显减少边RNN的工作步骤:
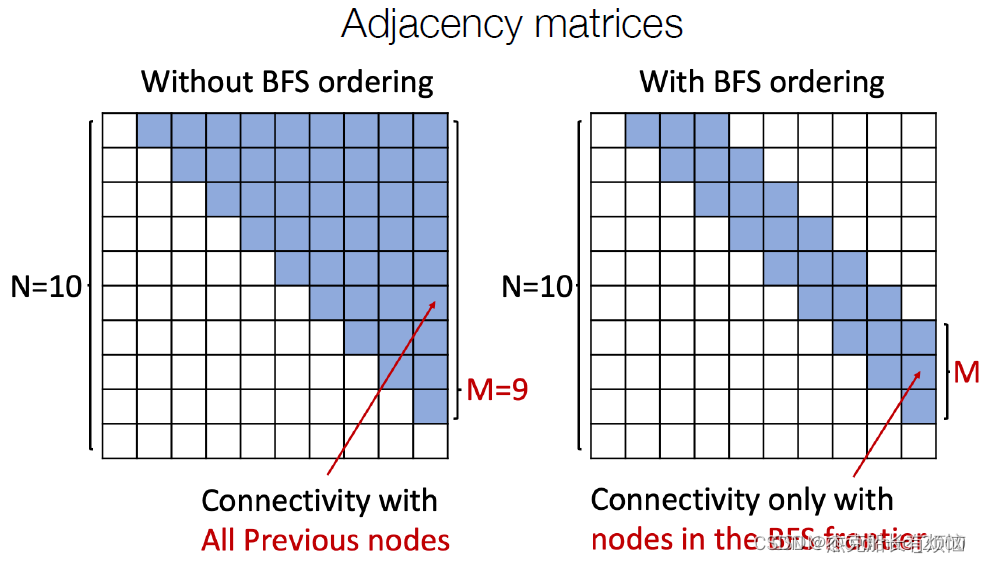
上图中右边M = 3,这里应该是图中节点最大度值。
例如:
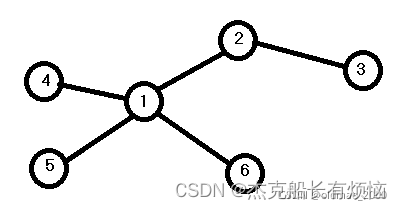
这个图最大度为1,按顺序的邻接矩阵为:
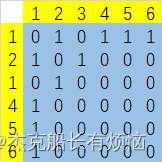
如果从1号节点开始BFS:
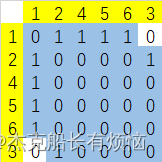
从2号节点开始BFS
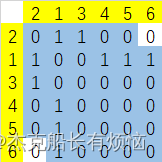
可以看到这个解决方案无论从哪个节点开始做BFS,最后的M=4不变,但是对于度较大的图效果不怎么好,如果是完全图,那么效果为0。
5. 效果
主要是看生成的图与训练的图相似度如何。
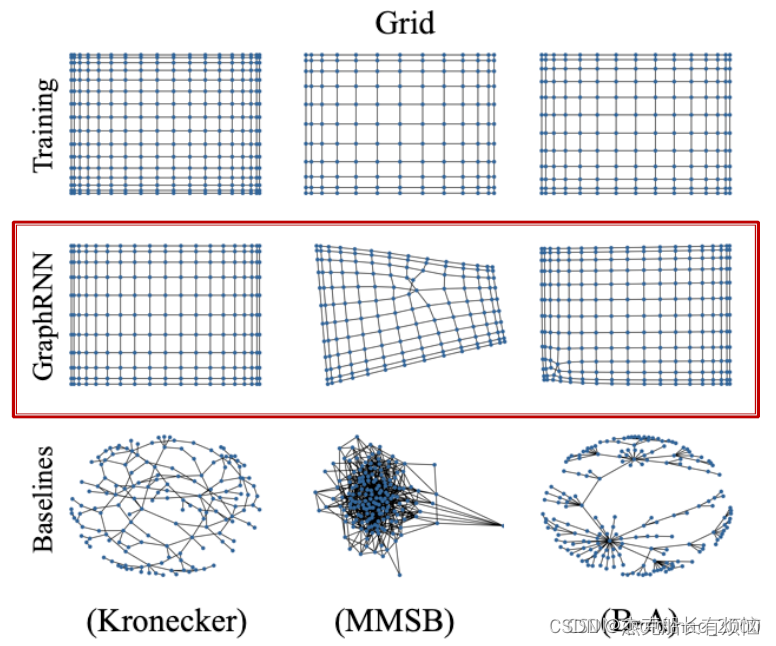
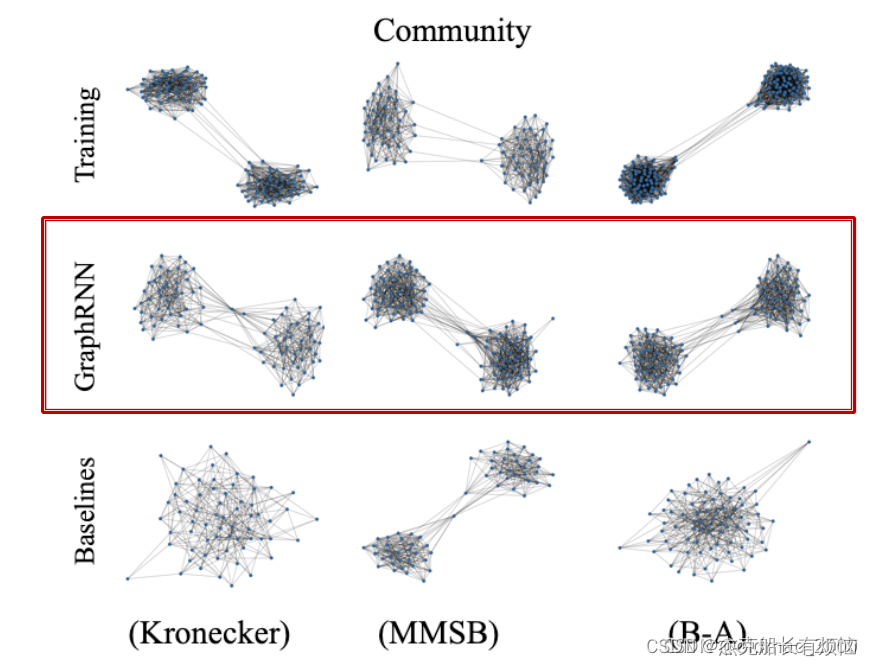
GraphRNN无论在生成非常规的网格图或是社区图上效果都不错,尤其是前者,传统方法基本都不行,在社区图的效果上MMSB是专门为社区图设计的,效果也还不错。
属性统计相似度:
-
earth mover distance (EMD)
用于比较两个分布之间的相似性。在直觉上就是衡量需要将一种分布编程另一种分布所需要移动的最小“泥土量”(面积)。 -
maximum mean discrepancy (MMD)
基于元素相似性,比较集合相似性:使用L2距离,对每个元素用EMD计算距离,然后用L2距离计算MMD。
3. 深度图生成模型的应用(药物)
这种生成任务就是goal-directed graph generation:
- 优化一个特定目标得分(high scores),如药物相似性
- 遵从内蕴规则(valid),如化学有效性规则
- 从示例中学习(realistic),如模仿分子图数据集
1和2是难点。为了解决他们,这里引入RL【1】成结果(给出positive or negative reward)。
【1】RL强化学习

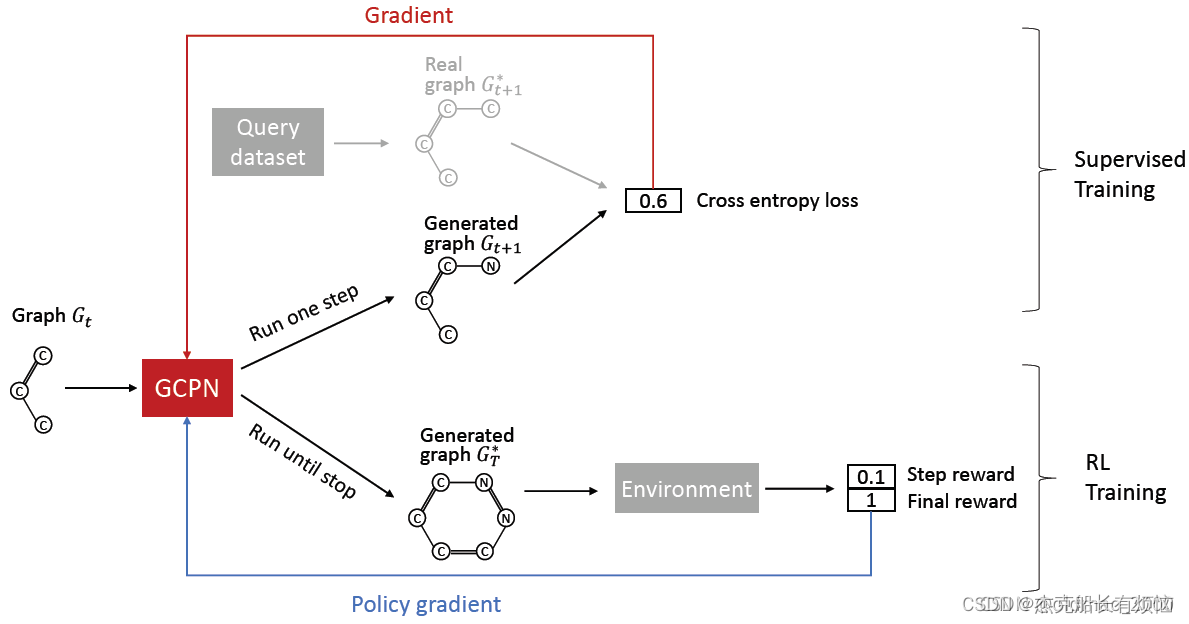
1. GCPN
图卷积策略网络(GCPN)结合图表示 + RL,包含三个部分
- 图神经网络捕获图结构信息
- 强化学习指导导向预期目标的图生成过程
- 有监督训练模拟给定数据集的样例
| 模型 | GCPN | GraphRNN |
|---|---|---|
| 生成方式 | 模仿给定训练数据集以序列方式生成图结构。 | 模仿给定训练数据集以序列方式生成图结构。 |
| 预测方式 | GNN 获取表征 | RNN |
| 是否能针对某个目标生成图 | RL辅助,可以 | 不可以 |
| 表达能力 | GNN表达能力强 | RNN表达能力比GNN弱 |
| 计算复杂度 | 慢,每一次生成一个节点,要和所有已存在节点进行是否有边判断,但是分子结构较小,无所谓 | BFS优化后比较快 |
2. GCPN概览

(a).插入节点
(bc).使用GNN预测节点之间的边
(d).检查分子有效性chemical validity
(ef).计算reward【2】
这里的reward有两种:
步骤奖励:学会采取有效行动
§ 在每一步中,为有效行动分配小的正奖励最终奖励:优化期望的属性
§ 最后,为高期望的属性分配积极的奖励
3. GCPN的训练
第一部分监督学习,这个步骤和前面的GraphRNN相似
第二部分是强化学习
整个反向传播也是分为两个部分:
4. 结果
在logP和QED这些医药上要优化的指标上都表现很好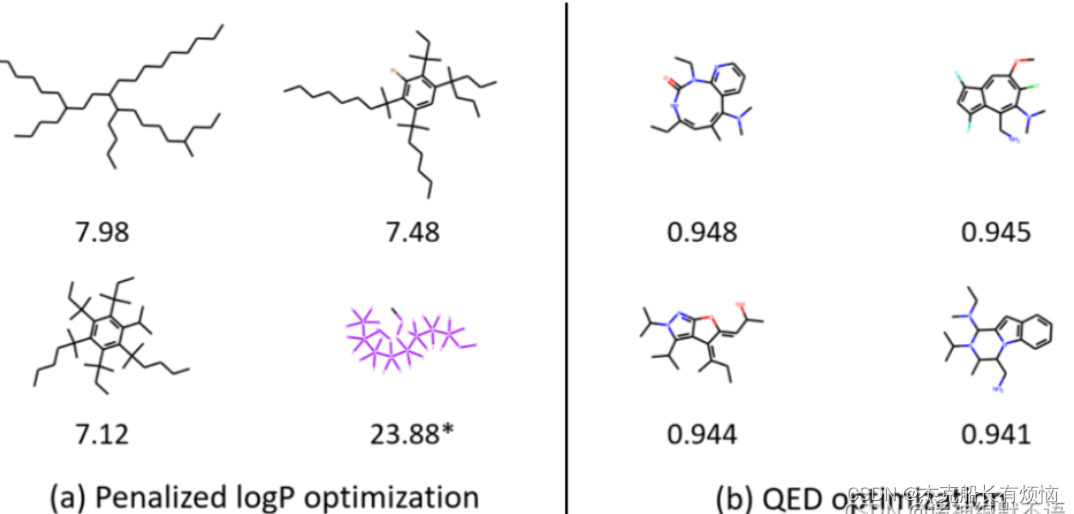
constrained optimization / complete任务:编辑给定分子,在几步之后就能达到高属性得分(如在以logP作为罚项的基础上,提升辛醇的可溶性)
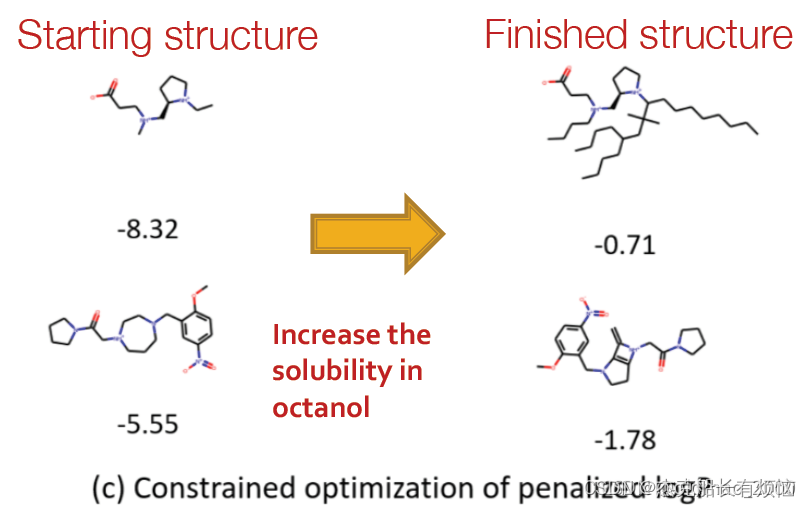
4.本章小结
- 复杂图可以用深度学习通过sequential generation成功生成。
- 图生成决策的每一步都基于hidden state。
hidden state可以是隐式的向量表示(因为RNN的中间过程都在hidden state里面,所以说是隐式的),由RNN解码;也可以是显式的中间生成图,由GCN解码。 - 可以实现的任务包括模仿给定的图数据集和往给定目标优化图
达到高属性得分(如在以logP作为罚项的基础上,提升辛醇的可溶性)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)