迁移学习 transfer learning
本文从入门级讲述了迁移学习的原理及基本实现方法
本文会持续更新~
1 零次学习
零次学习(zero-shot learning,本文简称ZSL)是迁移学习中一个研究分支,此外还有一次学习,它们所使适用的假设条件是不一样的,但是目的都差不多:根据已有的信息,用特殊的方式训练模型,使模型具有推断已有信息以外的能力。
下图概括了迁移学习中的ZSL问题: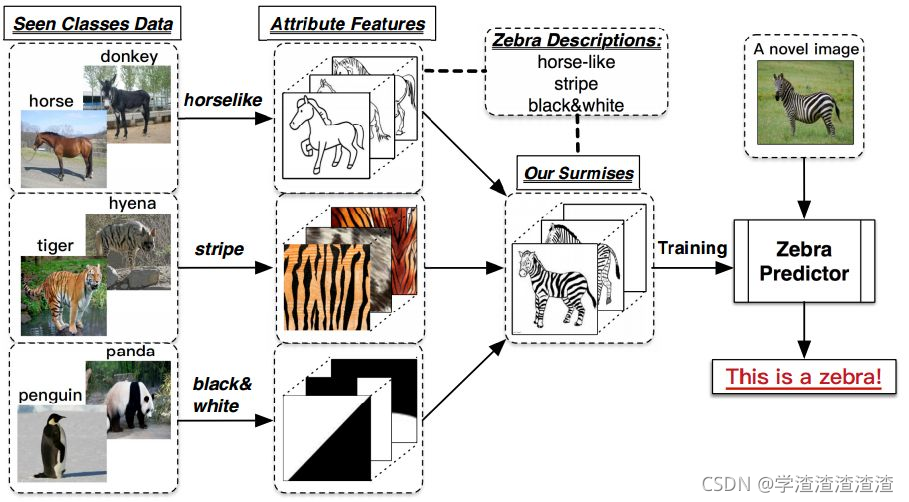
我有一些关于马、驴、老虎、鬣狗、企鹅、熊猫的图片作为训练数据,并且给一个描述:模型训练阶段没有遇见的新物种斑马具有 马的身材、条纹、黑白颜色 这三种特点,我们的任务是训练一个模型使得它能够判断图片中的动物是否为斑马?
ZSL就是希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。这样的能力听上去很具有吸引力,那么到底是怎么实现的呢?
我们假设:
(1)训练集数据 XtrainX_{train}Xtrain 及其标签 YtrainY_{train}Ytrain ,包含了模型需要学习的类别(马、老虎和熊猫),这里和传统的监督学习中的定义一致;
(2)测试集数据 XtestX_{test}Xtest及其标签YtestY_{test}Ytest ,包含了模型需要辨识的类别(斑马)。
(3)训练集类别的描述 AtrainA_{train}Atrain ,以及测试集类别的描述 AtestA_{test}Atest ;我们将每一个类别 yi∈Yy_i \in Yyi∈Y ,都表示成一个语义向量 ai∈Aa_i \in Aai∈A的形式,而这个语义向量的每一个维度都表示一种高级的属性,比如“黑白色”、“有尾巴”、“有羽毛”等等,当这个类别包含这种属性时,那在其维度上被设置为非零值。对于一个数据集来说,语义向量的维度是固定的,它包含了能够较充分描述数据集中类别的属性。
在ZSL中,我们希望利用 XtrainX_{train}Xtrain 和 YtrainY_{train}Ytrain 来训练模型,而模型能够具有识别 XtestX_{test}Xtest 的能力,因此模型需要知道所有类别的描述 AtrainA_{train}Atrain 和 AtestA_{test}Atest 。ZSL这样的设置其实就是上文中小暗识别斑马的过程中,爸爸为他提供的条件。
下图概括了ZSL做了什么: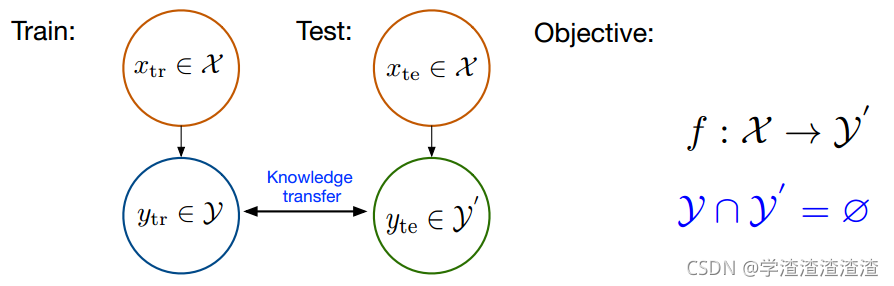
实现ZSL功能似乎需要解决两个部分的问题:第一个问题是获取合适的类别描述 AAA;第二个问题是建立一个合适的分类模型。目前大部分工作都集中在第二个问题上,而第一个问题的研究进展比较缓慢。
2 实现算法
ZSL的算法有很多,本文仅介绍最简单的算法。我们面对的是一个图片分类问题,即对测试集的样本 XtestX_{test}Xtest 进行分类,而我们分类时需要借助类别的描述 AtestA_{test}Atest,由于每一个类别 y∈Yy \in Yy∈Y ,都对应一个语义向量 ai∈Aa_{i} \in Aai∈A ,因此我们现在可以忘掉 Y,直接使用 AAA 。我们把 FFF(利用深度网络提取的图片特征,比如GoogleNet提取为1024维)称为特征空间(visual feature space),所以 Ftrain和FtestF_{train}和F_{test}Ftrain和Ftest 分别是对 XtrainX_{train}Xtrain 和 XtestX_{test}Xtest 提取得到的特征向量,把类别的语义表示为 AAA ,称为语义空间。我们要做的,其实就是建立特征空间与语义空间之间的映射。
对于分类,我们能想到的最简单的形式就是岭回归(ridge regression)(类似单层DNN),俗称均方误差加范数约束,具体形式为:
min∥FtrainW−Atrain∥2+ηΩ(W)min \Vert F_{train}W - A_{train} \Vert ^2 + \eta \Omega(W)min∥FtrainW−Atrain∥2+ηΩ(W)
其中,WWW 为模型参数, Ω()\Omega()Ω() 通常为2范数约束, η\etaη 为超参,对 WWW 求导,并让导为0,即可求出 WWW 的值(即最优WWW)。测试时,利用 WWW 将 f∈Ftestf \in F_{test}f∈Ftest 投影到语义空间中,并在该空间中寻找到离它最近的 ai∈Atesta_i \in A_{test}ai∈Atest ,则样本的类别为aia_iai所对应的标签yi∈Ytrainy_i \in Y_{train}yi∈Ytrain 。
我们使用AwA数据集,图片事先利用GoogleNet提取了特征(1024维),在测试集上可以得到59.1%的准确率。
这样一个岭回归之所以有效,是因为训练集类别语义 $ A_{train}$ 与测试集类别语义AtestA_{test}Atest之间存在的密切联系。其实任何ZSL方法有效的基础,都是因为这两者之间具体的联系。
3 存在的问题
在此,介绍一些目前ZSL中主要存在的问题,以便让大家了解目前ZS领域有哪些研究点。
3.1 领域漂移问题
该问题的正式定义首先由[2]提出。简单来说,就是同一种属性,在不同的类别中,视觉特征的表现可能很大。如图3所示,斑马和猪都有尾巴,因此在它的类别语义表示中,“有尾巴”这一项都是非0值,但是两者尾巴的视觉特征却相差很远。如果斑马是训练集,而猪是测试集,那么利用斑马训练出来的模型,则很难正确地对猪进行分类。
![domain shift示意图,图中的prototype表示类别在语义空间中的位置[2]](https://i-blog.csdnimg.cn/blog_migrate/a1ea6403dd0859aa419bd738046fce86.png)
domain shift示意图,图中的prototype表示类别在语义空间中的位置[2]
3.2 枢纽点问题(Hubness problem)
这其实是高维空间中固有的问题:在高维空间中,某些点会成为大多数点的最近邻点。这听上去有些反直观,细节方面可以参考[3]。由于ZSL在计算最终的正确率时,使用的是K-NN,所以会受到hubness problem的影响,并且[4]中,证明了基于岭回归的方法会加重hubness problem问题。
语义间隔(semantic gap)
样本的特征往往是视觉特征,比如用深度网络提取到的特征,而语义表示却是非视觉的,这直接反应到数据上其实就是:样本在特征空间中所构成的流型与语义空间中类别构成的流型是不一致的。(如下图所示)
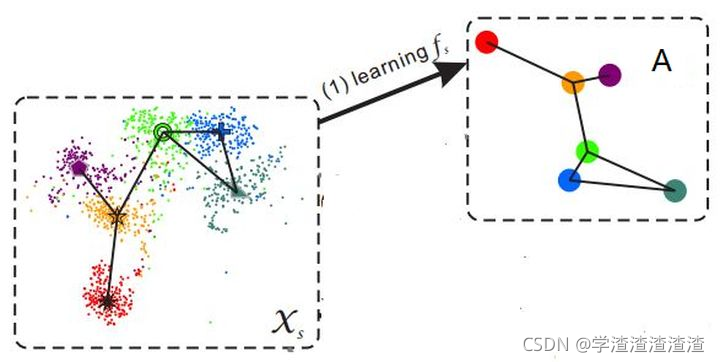
这使得直接学习两者之间的映射变得困难。
参考:
https://zhuanlan.zhihu.com/p/34656727
[2]Transductive Multi-View Zero-Shot Learning.
[3]Hubness and Pollution: Delving into Class-Space Mapping for Zero-Shot Learning.

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)