python 使用Pandas进行数据清洗
文章目录数据缺失缺失值检测 isnull()丢弃缺失值dropna()缺失值填充fillna()数据重复去重复值drop_duplicates()数据不一致值替换replace异常值处理数据清洗:对采集的数据进行重新审查和校验的过程,其目的在于删除重复信息、纠正存在的错误,保证数据的一致性。常见问题:数据缺失、数据重复、数据不一致数据缺失缺失值检测 isnull()丢弃缺失值dropna()dro
·
文章目录
数据清洗:对采集的数据进行重新审查和校验的过程,其目的在于删除重复信息、纠正存在的错误,保证数据的一致性。
常见问题:数据缺失、数据重复、数据不一致
数据缺失
缺失值检测 isnull()

丢弃缺失值dropna()
dropna(axis,how,thresh,…)axis:0表示按行滤除,1表示按列滤除,默认为axis=0 how: “all”表示滤除全部值都为NaN的行或列
Thresh:只留下有效数据数大于或等于thresh的行或列

案例:
缺失值填充fillna()
fillna(value, method,…)value:填充值,可以是标量、字典等 method:‘ffill’, ‘bfill’
用同列前一行或后一行数据填充

案例:

数据重复
去重复值drop_duplicates()
data. drop_duplicates(inplace=True) #去掉重复的数据,inplace=True时,直接删除重复数据
数据不一致
值替换replace
replace(to_replace, value, …)data[‘Age’].replace(20, np.nan) #将年龄20替换为空值
data[‘Age’].replace({20:np.nan, 21:0})
异常值处理
案例: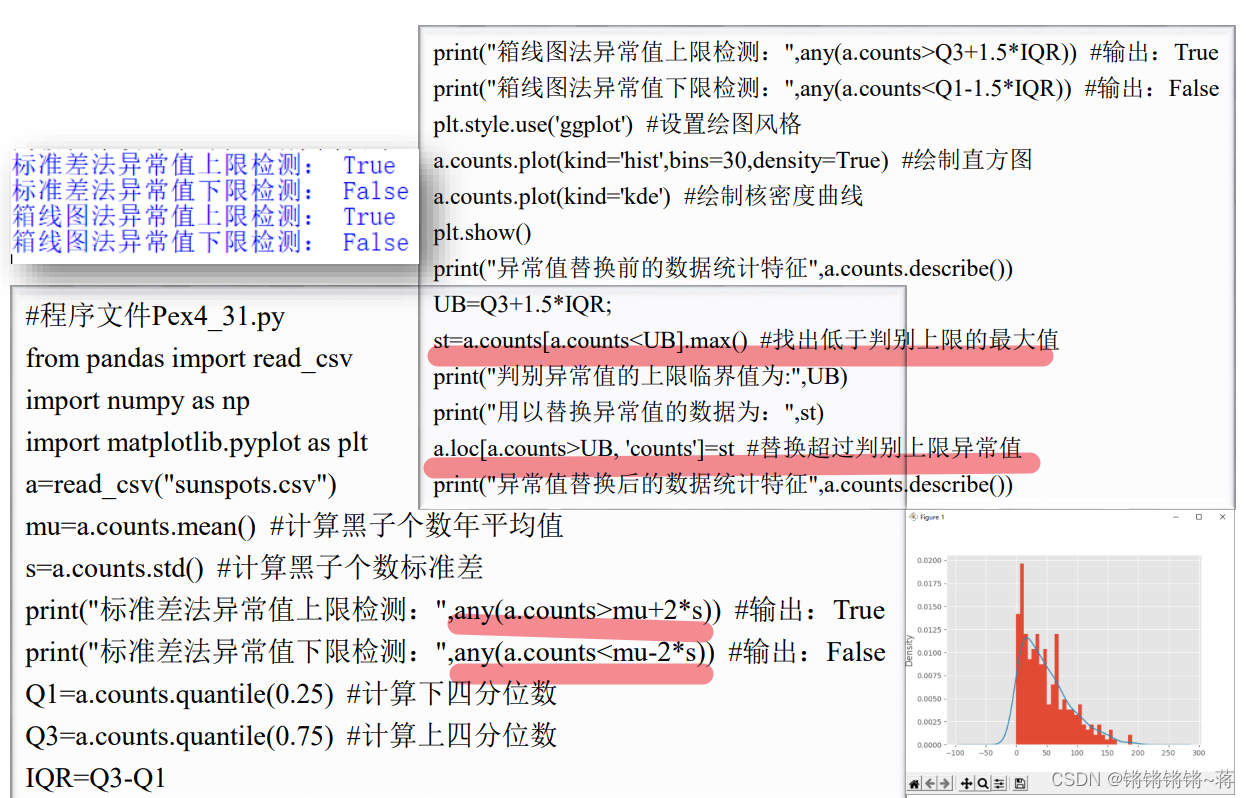

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)