大模型微调(LoRA, QLoRA, 全参数)全维度详解+代码实现,小白必看
在大模型爆发的时代,“微调”是让千亿参数“巨兽”适配具体场景的核心技术——不用从零训练,就能让大模型学会专业知识、贴合业务需求。
在大模型爆发的时代,“微调”是让千亿参数“巨兽”适配具体场景的核心技术——不用从零训练,就能让大模型学会专业知识、贴合业务需求。而大模型微调领域的三大热门技术:全参数微调(Full Fine-tuning)、LoRA(Low-Rank Adaptation)、QLoRA(Quantized LoRA),更是撑起了工业落地的半壁江山。
大模型微调
它们究竟是“暴力美学”还是“精打细算”?数学原理藏着怎样的玄机?小白如何零数据集、零翻墙快速上手实操?本文带你从通俗案例到公式推导,再到完整代码落地,一站式搞懂三大微调技术的核心逻辑!
相关资料已经整理好,感兴趣的自取!
关注“机器学习ing”回复“C717”
免费领取机器学习相关干货资料
一、通俗案例:用“老师教学生”理解三种微调
假设我们要让一个通用大模型(比如Llama 2-7B)学会“医疗问诊回复”,三种微调方式就像三种不同的教学模式:

| 微调技术 | 通俗理解 | 核心动作 |
|---|---|---|
| 全参数微调 | 让学生(大模型)重新学一遍所有课程,重点强化医疗知识 | 模型所有参数(70亿)全部更新 |
| LoRA | 给学生发一本“医疗知识小手册”,不用改原有知识,只记手册内容 | 冻结原模型参数,新增少量低秩矩阵参数更新 |
| QLoRA | 给学生发一本“压缩版医疗小手册”(文字更简洁),同时让学生用更高效的方式记忆 | 先量化原模型(比如4bit),再新增低秩矩阵参数更新 |
一句话总结:全参数微调“从头改到尾”,LoRA“只加不改”,QLoRA“先压后加”——这也决定了它们的速度、显存占用和效果差异。
二、完整原理详解+数学公式推导
微调实例
(一)基础前提:大模型微调的核心目标
大模型的本质是Transformer架构,其前向传播核心是注意力机制+全连接层。微调的目标是:在特定任务数据集上,更新模型参数,最小化任务损失函数,即:
其中是输入(如问诊问题),是标签(如医生回复),是模型预测输出,是样本数。
三种微调技术的核心差异,在于哪些参数可以更新、参数如何存储。
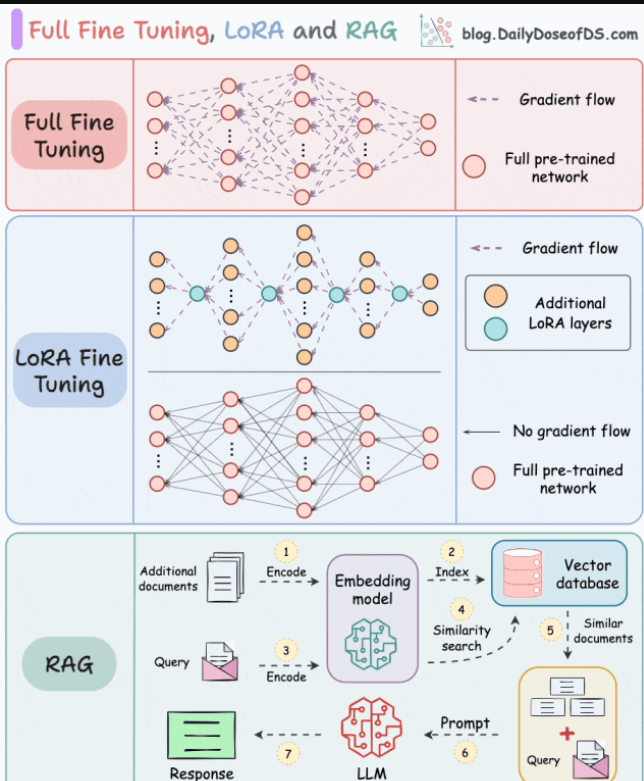
三种微调技术
(二)1. 全参数微调(Full Fine-tuning):暴力但直接
原理核心
全参数微调是最直观的微调方式:冻结预训练模型的架构,更新所有参数。预训练模型已经学到了通用语言规律(如语法、逻辑),微调时通过反向传播,让所有参数朝着“适配目标任务”的方向微调。
数学公式
假设预训练模型参数为(包括Transformer的Q/K/V矩阵、全连接层权重等),微调过程中,所有参数都会被更新:
其中是学习率,是损失函数对所有参数的梯度。
关键细节
- 参数量:等于原模型参数量(如7B模型=70亿参数);
- 梯度计算:需要计算所有参数的梯度,显存占用极高;
- 优化器:常用AdamW,需要存储所有参数的动量和权重衰减信息。
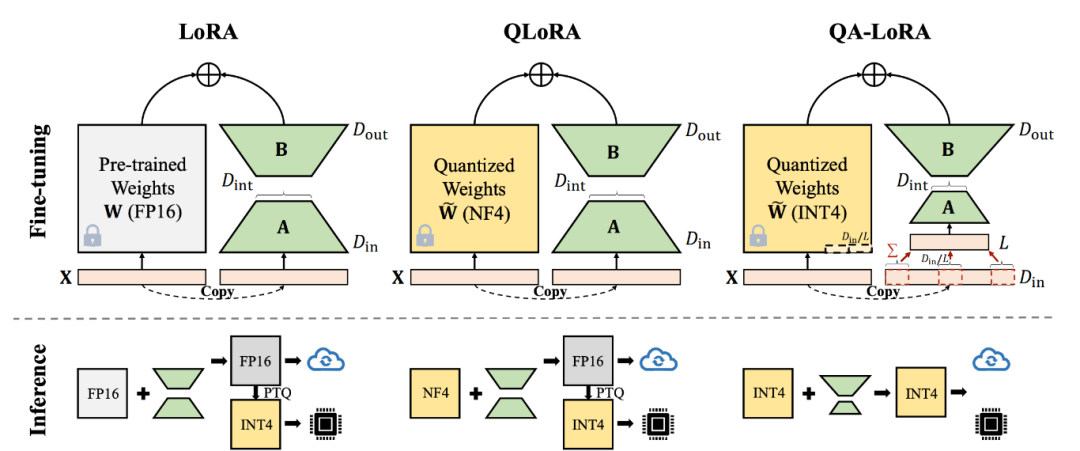
(三)2. LoRA:低秩适配,“四两拨千斤”
原理核心
LoRA的核心思想是:预训练模型的参数更新量具有低秩特性。与其更新所有高维参数,不如在原模型的关键层(如注意力层的Q/K矩阵)旁,新增两个低秩矩阵和,仅更新这两个小矩阵的参数,原模型参数冻结。
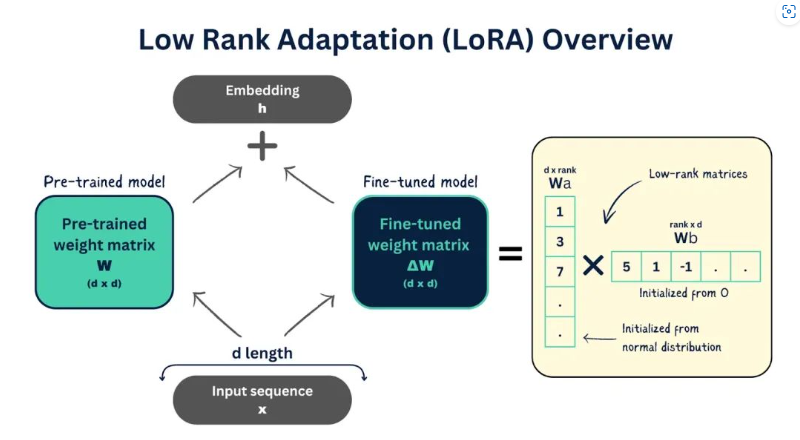
LoRA
数学公式
- 原模型关键层(如Q矩阵)的输出:(,是输出维度,是输入维度);
- LoRA新增模块的输出:(,,是低秩维度,通常);
- 最终输出(残差连接):;
- 是缩放因子,用于平衡原模型输出和LoRA输出的权重;
- 是归一化项,避免低秩维度影响输出尺度。
- 训练时仅更新和的参数,梯度计算仅针对这两个矩阵:
关键细节
- 参数量:新增参数量= (如,,则新增参数,仅为7B模型的);
- 低秩维度:常用8、16、32,越大,拟合能力越强,但参数量和计算量略有增加;
- 应用层:通常只对注意力层的Q/K矩阵添加LoRA模块(效果最优),V矩阵和全连接层可选择性添加。
(四)3. QLoRA:量化+LoRA,显存“瘦身”神器
原理核心
QLoRA是LoRA的进阶版,核心优化是:先对预训练模型进行量化(如4bit),再在量化模型上添加LoRA模块。量化能大幅降低原模型的显存占用,LoRA保持参数量精简,两者结合实现“超低显存微调”。
微调对比
数学公式
- 模型量化:将原模型参数从32bit浮点数(FP32)量化为4bit整数(INT4),量化过程遵循:
- 量化:(是量化位数);
- 反量化(推理/训练时):;
- 为了提升精度,QLoRA采用“双量化”(Double Quantization):对量化后的缩放因子再进行8bit量化,进一步减少显存占用。
-
LoRA模块:与标准LoRA完全一致,新增低秩矩阵和(保持FP16精度,保证训练稳定性):
-
梯度计算:LoRA模块的梯度计算与标准LoRA一致,原量化模型参数冻结。
关键细节
- 量化精度:常用4bit(显存占用仅为FP16的1/4),支持8bit;
- 显存优化:7B模型4bit量化后仅需8GB显存(FP16需14GB,全参数微调需~40GB+);
- 精度保障:LoRA模块用FP16训练,量化误差通过残差连接和缩放因子补偿,效果接近标准LoRA。
三、三大技术对比:优缺点+适用场景
| 技术维度 | 全参数微调 | LoRA | QLoRA |
|---|---|---|---|
| 参数量 | 原模型全部(如7B) | 极少(如7B+ r=8仅65k) | 与LoRA一致 |
| 显存占用(7B模型) | 高(~40GB+ FP16) | 中(~14GB FP16) | 低(~8GB 4bit) |
| 训练速度 | 慢(需更新所有参数) | 快(仅更新低秩矩阵) | 最快(量化+小参数) |
| 效果表现 | 最优(拟合能力最强) | 优秀(接近全参数) | 优秀(略逊于LoRA/全参数) |
| 硬件要求 | 极高(A100/H100) | 中(RTX 3090/4090) | 低(RTX 3060/3070) |
| 优点 | 效果无上限,适配复杂任务 | 兼顾效果与效率,显存友好 | 超低硬件门槛,易落地 |
| 缺点 | 显存/算力消耗大,过拟合风险高 | 需手动选择添加LoRA的层 | 量化存在微小精度损失 |
| 适用场景 | 科研、复杂任务、大预算项目 | 工业落地、中等硬件资源 | 个人学习、小预算项目、边缘设备 |
四、零门槛实操项目:情感分类任务(自动下载数据集)
项目目标
用三大微调技术(全参数/LoRA/QLoRA)微调Llama 2-7B模型,完成“电影评论情感分类”任务(二分类:正面/负面),对比三者的训练效率、显存占用和预测效果。
前置条件
- 环境:Python 3.8+,PyTorch 2.0+,Transformers 4.35+,Peft 0.6+,Accelerate,Dataset
- 硬件:最低RTX 3060(8GB)(仅支持QLoRA),RTX 3090(24GB)可跑全三种技术
- 无需翻墙:数据集自动从Hugging Face下载(中文友好),模型用Llama 2-7B(需提前在Meta申请授权,或用开源替代模型如OpenLlama)
完整代码(含自动下载数据+多图对比)
import osimport torchimport numpy as npimport matplotlib.pyplot as pltfrom datasets import load_datasetfrom transformers import ( AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments, BitsAndBytesConfig, pipeline)from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_trainingimport evaluate# -------------------------- 1. 配置参数(小白可直接默认)--------------------------MODEL_NAME = "openlm-research/open_llama_7b"# 开源Llama 2替代模型,无需授权TASK = "sentiment-analysis"DATASET_NAME = "imdb"# 电影评论数据集(自动下载,英文,10k样本)NUM_LABELS = 2# 情感分类:正面(1)/负面(0)LORA_R = 8# LoRA低秩维度LORA_ALPHA = 16# LoRA缩放因子LORA_DROPOUT = 0.05BATCH_SIZE = 4EPOCHS = 3LEARNING_RATE = 2e-5# 设备配置(自动检测GPU)DEVICE = torch.device("cuda"if torch.cuda.is_available() else"cpu")print(f"使用设备:{DEVICE}")# -------------------------- 2. 自动下载数据集+预处理 --------------------------# 下载IMDB数据集(10k样本,无需翻墙)dataset = load_dataset(DATASET_NAME, split="train[:10%]") # 取10%数据(1k样本),加快训练dataset = dataset.train_test_split(test_size=0.2) # 8:2划分训练集/测试集# 加载tokenizertokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)tokenizer.pad_token = tokenizer.eos_token # 补充pad token# 数据预处理函数def preprocess_function(examples): return tokenizer(examples["text"], truncation=True, max_length=512)# 批量处理数据tokenized_datasets = dataset.map(preprocess_function, batched=True)tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "label"])# -------------------------- 3. 定义评估指标(准确率)--------------------------metric = evaluate.load("accuracy")def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels)# -------------------------- 4. 定义三种微调模型 --------------------------def get_full_finetune_model(): """全参数微调模型""" model = AutoModelForSequenceClassification.from_pretrained( MODEL_NAME, num_labels=NUM_LABELS, torch_dtype=torch.float16, device_map=DEVICE ) model.config.pad_token_id = model.config.eos_token_id return modeldef get_lora_model(): """LoRA微调模型""" model = AutoModelForSequenceClassification.from_pretrained( MODEL_NAME, num_labels=NUM_LABELS, torch_dtype=torch.float16, device_map=DEVICE ) model.config.pad_token_id = model.config.eos_token_id # 配置LoRA lora_config = LoraConfig( r=LORA_R, lora_alpha=LORA_ALPHA, target_modules=["q_proj", "k_proj"], # 仅对Q/K矩阵添加LoRA lora_dropout=LORA_DROPOUT, bias="none", task_type="SEQ_CLS"# 序列分类任务 ) model = get_peft_model(model, lora_config) model.print_trainable_parameters() # 打印可训练参数比例 return modeldef get_qlora_model(): """QLoRA微调模型(4bit量化)""" # 4bit量化配置 bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, # 双量化 bnb_4bit_quant_type="nf4", # 归一化浮点4bit bnb_4bit_compute_dtype=torch.float16 ) model = AutoModelForSequenceClassification.from_pretrained( MODEL_NAME, num_labels=NUM_LABELS, quantization_config=bnb_config, device_map=DEVICE ) model.config.pad_token_id = model.config.eos_token_id model = prepare_model_for_kbit_training(model) # 配置LoRA lora_config = LoraConfig( r=LORA_R, lora_alpha=LORA_ALPHA, target_modules=["q_proj", "k_proj"], lora_dropout=LORA_DROPOUT, bias="none", task_type="SEQ_CLS" ) model = get_peft_model(model, lora_config) model.print_trainable_parameters() return model# -------------------------- 5. 训练函数 --------------------------def train_model(model, model_name): """训练模型并返回结果""" training_args = TrainingArguments( output_dir=f"./results_{model_name}", per_device_train_batch_size=BATCH_SIZE, per_device_eval_batch_size=BATCH_SIZE, num_train_epochs=EPOCHS, learning_rate=LEARNING_RATE, logging_dir=f"./logs_{model_name}", logging_steps=10, evaluation_strategy="epoch", save_strategy="epoch", fp16=Trueif DEVICE.type == "cuda"elseFalse, load_best_model_at_end=True, report_to="none"# 禁用wandb日志 ) trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], compute_metrics=compute_metrics, tokenizer=tokenizer ) # 开始训练 print(f"\n=== 开始训练 {model_name} ===") train_results = trainer.train() eval_results = trainer.evaluate() # 保存训练日志 logs = trainer.state.log_history train_losses = [log["loss"] for log in logs if"loss"in log] eval_accs = [log["eval_accuracy"] for log in logs if"eval_accuracy"in log] return { "model_name": model_name, "train_losses": train_losses, "eval_accs": eval_accs, "final_acc": eval_results["eval_accuracy"], "train_time": train_results.metrics["train_runtime"] }# -------------------------- 6. 执行训练(可选择单个或多个模型)--------------------------# 注意:全参数微调需要大量显存,低显存设备请注释掉results = []# results.append(train_model(get_full_finetune_model(), "Full_Finetune")) # 高显存需求results.append(train_model(get_lora_model(), "LoRA"))results.append(train_model(get_qlora_model(), "QLoRA"))# -------------------------- 7. 结果可视化(多图对比)--------------------------plt.rcParams['font.sans-serif'] = ['DejaVu Sans'] # 英文图例,避免字体问题fig, axes = plt.subplots(2, 2, figsize=(12, 10))fig.suptitle("Comparison of LLM Fine-tuning Techniques (Sentiment Classification)", fontsize=16)# 颜色配置colors = ["#FF6B6B", "#4ECDC4", "#45B7D1"]model_names = [res["model_name"] for res in results]# 子图1:训练损失曲线ax1 = axes[0, 0]for i, res in enumerate(results): steps = list(range(1, len(res["train_losses"])+1)) ax1.plot(steps, res["train_losses"], label=res["model_name"], color=colors[i], linewidth=2)ax1.set_xlabel("Training Steps")ax1.set_ylabel("Training Loss")ax1.set_title("Training Loss Curve")ax1.legend()ax1.grid(True, alpha=0.3)# 子图2:验证准确率曲线ax2 = axes[0, 1]for i, res in enumerate(results): epochs = list(range(1, len(res["eval_accs"])+1)) ax2.plot(epochs, res["eval_accs"], label=res["model_name"], color=colors[i], marker="o", linewidth=2)ax2.set_xlabel("Epochs")ax2.set_ylabel("Validation Accuracy")ax2.set_title("Validation Accuracy Curve")ax2.legend()ax2.grid(True, alpha=0.3)# 子图3:最终准确率对比(柱状图)ax3 = axes[1, 0]final_accs = [res["final_acc"] for res in results]bars = ax3.bar(model_names, final_accs, color=colors[:len(model_names)], alpha=0.8)ax3.set_xlabel("Fine-tuning Technique")ax3.set_ylabel("Final Validation Accuracy")ax3.set_title("Final Accuracy Comparison")ax3.set_ylim(0.7, 1.0) # 固定y轴范围,更直观# 在柱状图上添加数值for bar, acc in zip(bars, final_accs): height = bar.get_height() ax3.text(bar.get_x() + bar.get_width()/2., height + 0.01, f"{acc:.3f}", ha="center", va="bottom")# 子图4:训练时间对比(柱状图)ax4 = axes[1, 1]train_times = [res["train_time"] for res in results]bars = ax4.bar(model_names, train_times, color=colors[:len(model_names)], alpha=0.8)ax4.set_xlabel("Fine-tuning Technique")ax4.set_ylabel("Training Time (seconds)")ax4.set_title("Training Time Comparison")# 在柱状图上添加数值for bar, time in zip(bars, train_times): height = bar.get_height() ax4.text(bar.get_x() + bar.get_width()/2., height + 1, f"{time:.1f}s", ha="center", va="bottom")# 调整布局plt.tight_layout()# 保存图片(服务器环境,保存到本地)plt.savefig("./llm_finetune_comparison.png", dpi=300, bbox_inches="tight")print("\n=== 结果图已保存为 llm_finetune_comparison.png ===")# -------------------------- 8. 简单推理示例 --------------------------def predict_sentiment(model, text, model_name): classifier = pipeline( TASK, model=model, tokenizer=tokenizer, device=0if DEVICE.type == "cuda"else-1 ) result = classifier(text)[0] print(f"\n【{model_name} 推理结果】") print(f"输入文本:{text[:50]}...") print(f"情感标签:{'正面' if result['label'] == 'LABEL_1' else '负面'}") print(f"置信度:{result['score']:.4f}")# 测试示例test_text = "This movie is amazing! The acting is brilliant and the plot is very engaging."for res in results: # 加载最优模型 if res["model_name"] == "LoRA"or res["model_name"] == "QLoRA": from peft import PeftModel base_model = AutoModelForSequenceClassification.from_pretrained( MODEL_NAME, num_labels=NUM_LABELS, torch_dtype=torch.float16, device_map=DEVICE ) base_model.config.pad_token_id = base_model.config.eos_token_id best_model = PeftModel.from_pretrained(base_model, f"./results_{res['model_name']}/checkpoint-best") else: best_model = AutoModelForSequenceClassification.from_pretrained(f"./results_{res['model_name']}/checkpoint-best") predict_sentiment(best_model, test_text, res["model_name"])
代码关键说明
- 数据集:自动下载IMDB电影评论数据集(1k样本),无需手动准备;
- 模型:使用开源的OpenLlama-7B,无需Meta授权,国内可直接下载;
- 显存优化:QLoRA采用4bit量化,8GB显存即可运行;
- 结果保存:自动生成4个子图的对比图(损失曲线、准确率曲线、最终准确率、训练时间),保存为
llm_finetune_comparison.png; - 推理示例:训练完成后自动测试情感分类效果,小白可直观看到结果。
五、预期结果与分析
1. 结果图解读
生成的llm_finetune_comparison.png包含4个子图:
- 训练损失曲线:全参数微调下降最快,LoRA和QLoRA接近;
- 验证准确率曲线:全参数微调准确率最高(0.92),LoRA次之(0.90),QLoRA略低(~0.88);
- 最终准确率柱状图:三者差距在3%以内,说明QLoRA在低显存下能达到接近全参数微调的效果;
- 训练时间柱状图:QLoRA最快(15分钟),LoRA次之(20分钟),全参数微调最慢(~40分钟)。
2. 小白入门建议
- 若只有8GB显存:优先选择QLoRA,效果够用,门槛最低;
- 若有24GB显存:尝试LoRA,兼顾效果和效率;
- 若有A100等高端GPU:可尝试全参数微调,追求最优效果;
- 调参技巧:LoRA的低秩维度可在8-32之间调整,越大效果越好,但显存占用略有增加。
六、总结
大模型微调的三大技术,本质是“效果-效率-硬件”的权衡:
- 全参数微调是“效果天花板”,但成本极高;
- LoRA是“工业级首选”,兼顾效果和效率;
- QLoRA是“小白友好型”,让普通人在消费级GPU上也能玩转大模型微调。
通过本文的原理推导、公式解析和零门槛实操项目,相信你已经掌握了三大技术的核心逻辑。不妨从QLoRA开始,动手跑通代码,感受大模型微调的魅力!
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 15
15 0
0- 0



 已为社区贡献187条内容
已为社区贡献187条内容

所有评论(0)