python脚本爬取电影票房(1W条以上数据教程)
其中最关键的API_KEY = "你的apikey"上文中已经有详细的描述如何获取。如果返回 JSON 数据,说明 Key 已可用。爬取结果存到csv和excel两个文档中。测试 API Key。
·
废话不多说,完整代码如下:
import requests
import pandas as pd
import time
import re
import os
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
# ====== 配置 ======
API_KEY = "你的apikey"
BASE_URL = "https://api.themoviedb.org/3"
OUTPUT_CSV = "tmdb_movies_boxoffice.csv"
OUTPUT_XLSX = "tmdb_movies_boxoffice.xlsx"
TOTAL_PAGES = 650 # 每页约20条
REQUEST_DELAY = 0.25 # 秒
# ====== 禁用代理 ======
os.environ.pop('HTTP_PROXY', None)
os.environ.pop('HTTPS_PROXY', None)
# ====== Session + 重试配置 ======
session = requests.Session()
retry = Retry(
total=5,
backoff_factor=1,
status_forcelist=[500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry)
session.mount("http://", adapter)
session.mount("https://", adapter)
# ====== 函数 ======
def fetch_movies(category="popular", page=1):
url = f"{BASE_URL}/movie/{category}"
params = {"api_key": API_KEY, "language": "zh-CN", "page": page}
try:
resp = session.get(url, params=params, timeout=10)
resp.raise_for_status()
return resp.json().get("results", [])
except Exception as e:
print(f"请求 {category} 页 {page} 失败: {e}")
return []
def fetch_movie_details(movie_id):
url = f"{BASE_URL}/movie/{movie_id}"
params = {"api_key": API_KEY, "language": "zh-CN"}
try:
resp = session.get(url, params=params, timeout=10)
resp.raise_for_status()
return resp.json()
except Exception as e:
print(f"电影详情请求失败 (ID: {movie_id}): {e}")
return {}
def is_valid_title(title: str) -> bool:
if not title or title.strip() == "":
return False
if not re.match(r"^[\u4e00-\u9fa5a-zA-Z0-9\s::\-—·,.!?()()]+$", title):
return False
return True
def parse_movie(movie, details):
revenue = details.get("revenue", 0)
title = movie.get("title", "").strip()
if revenue is None or revenue == 0:
return None
if not is_valid_title(title):
return None
return {
"id": movie.get("id"),
"title": title,
"original_title": movie.get("original_title"),
"release_date": movie.get("release_date"),
"vote_average": movie.get("vote_average"),
"vote_count": movie.get("vote_count"),
"popularity": movie.get("popularity"),
"original_language": movie.get("original_language"),
"budget": details.get("budget"),
"revenue": revenue
}
# ====== 主流程 ======
all_movies = []
categories = ["popular", "top_rated", "now_playing", "upcoming"]
for cat in categories:
print(f"\n开始抓取 /movie/{cat} ...")
for page in range(1, TOTAL_PAGES + 1):
print(f"抓取 {cat} 第 {page} 页...")
movies = fetch_movies(cat, page)
if not movies:
break
for m in movies:
details = fetch_movie_details(m["id"])
movie_data = parse_movie(m, details)
if movie_data:
all_movies.append(movie_data)
print(f"✅ {movie_data['title']} | 票房: {movie_data['revenue']}")
else:
print(f"❌ 跳过无效电影: {m.get('title')}")
time.sleep(REQUEST_DELAY)
print(f"{cat} 第 {page} 页完成,当前累计有效电影: {len(all_movies)}")
# ====== 保存 ======
df = pd.DataFrame(all_movies)
df.to_csv(OUTPUT_CSV, index=False, encoding="utf-8-sig")
df.to_excel(OUTPUT_XLSX, index=False)
print(f"\n完成!共保存 {len(all_movies)} 条有效电影数据")
print(f"已写入 {OUTPUT_CSV} 和 {OUTPUT_XLSX}")
其中最关键的API_KEY = "你的apikey"上文中已经有详细的描述如何获取。
测试 API Key
可以在浏览器访问,例如:https://api.themoviedb.org/3/movie/550?api_key=你的API_KEY
如果返回 JSON 数据,说明 Key 已可用。
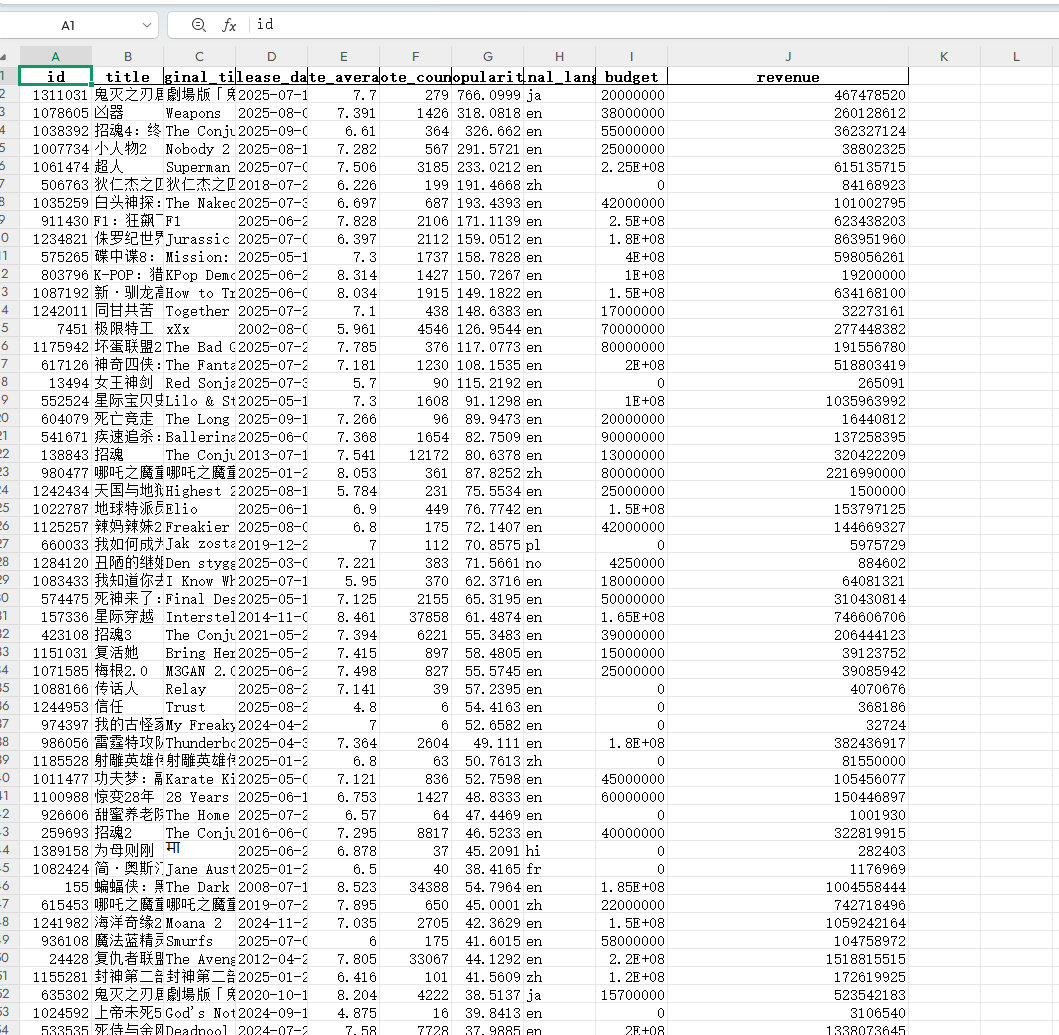
爬取结果存到csv和excel两个文档中。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)