比例数据可视化
1.数据读取与处理读取 CSV 文件:借助pandas的read_csv函数来读取存储在本地的 CSV 文件,进而创建DataFrame对象,以方便后续的数据处理。数据合并:运用pd.merge函数,能够按照指定的列(像aisle_id、department_id)对多个DataFrame进行合并,支持多种连接方式,这里使用的是左连接(how=‘left’)。
一、实验名称
比例数据可视化
二、实验目的
- 掌握数据文件读取
- 掌握数据处理的方法
- 实现板块层级图的绘制
三、实验原理
板块层级图(treemap)是一种基于面积的可视化方式,通过每一个板块(通常为矩形)的尺寸大小进行度量。外部矩形代表父类别,而内部矩形代表子类别。我们也可以通过板块层级图简单的呈现比例关系,不过它更擅于呈现树状结构的数据。
读取绘图所用的数据,并对数据进行处理将数据处理成我们可以使用的形式,绘制板块层级图,设置标签和标题。
四、实验环境
OS:win10
python:v3.6
五、实验步骤
(一)安装pandas、matplotlib、seaborn、squarify
1.输入命令:pip install pandas
2.输入命令:pip install matplotlib
3.输入命令:pip install seaborn
4.输入命令:pip install squarify
(二)读取数据
在这里我们使用pandas库中的read_csv函数来读取这3个数据文件。
数据读取的结果:
(三)数据处理
我们需要根据源表对目标表进行匹配查询,使用 merge 函数进行操作。
order_products_prior_df = pd.merge(products_df, aisles_df, on='aisle_id', how='left')
order_products_prior_df=pd.merge(order_products_prior_df,
departments_df,
on='department_id', how='left')
order_products_prior_df.head()
temp = order_products_prior_df[['product_name', 'aisle', 'department']]
temp = pd.concat([
order_products_prior_df.groupby('department')['product_name'].nunique().rename('products_department'),
order_products_prior_df.groupby('department')['aisle'].nunique().rename('aisle_department'
)
], axis=1).reset_index()
temp = temp.set_index('department')
temp2 = temp.sort_values(by="aisle_department", ascending=False)
print(temp)
print(temp2)
进行匹配操作后的数据: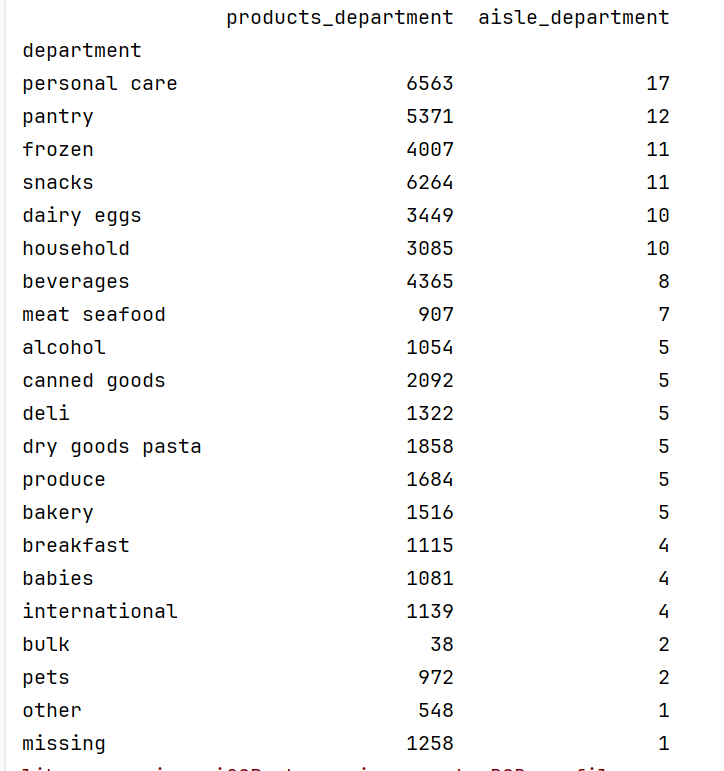
(四)绘制板块层级图
绘制初始的板块层级图
cmap = matplotlib.cm.viridis
mini, maxi = temp2.products_department.min(), temp2.products_department.max()
norm = matplotlib.colors.Normalize(vmin=mini, vmax=maxi)
colors = [cmap(norm(value)) for value in temp2.products_department]
colors[1] = "#FBFCFE"
labels = ["%s\n%d aisle num\n%d products num" % (label) for label in
zip(temp2.index, temp2.aisle_department, temp2.products_department)]
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, aspect="equal")
ax = squarify.plot(temp2.aisle_department, color=colors, label=labels, ax=ax, alpha=.7)
绘制结果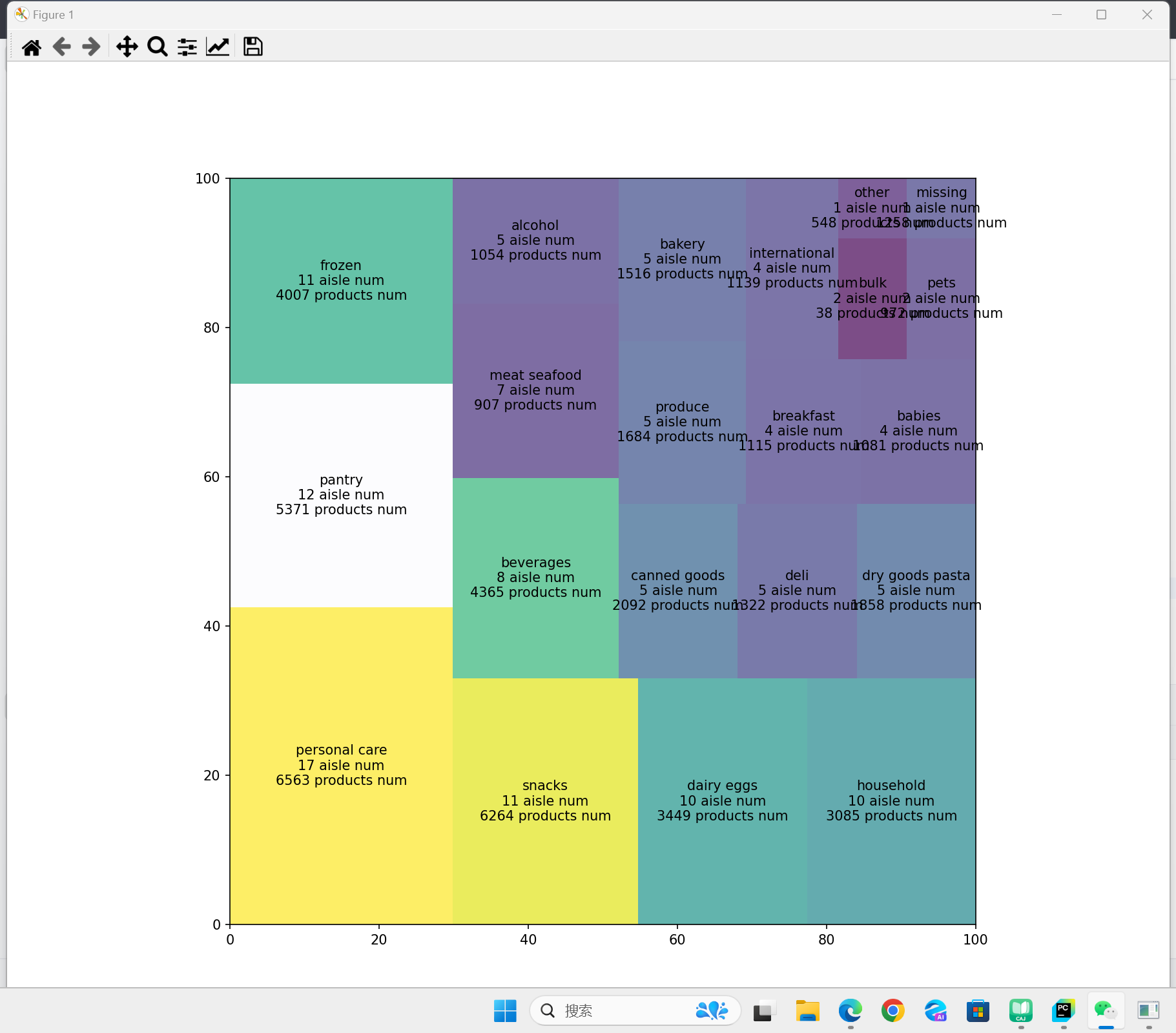
设置 x、y 轴的属性:
ax.set_xticks([])
ax.set_yticks([])
添加图表标题:
fig.suptitle("How are aisles organized within departments", fontsize=20 )
添加数据标签:
img = plt.imshow([temp2.products_department], cmap=cmap)
img.set_visible(False)
fig.colorbar(img, orientation="vertical", shrink=.96)
fig.text(.76, .9, "numbers of products", fontsize=14)
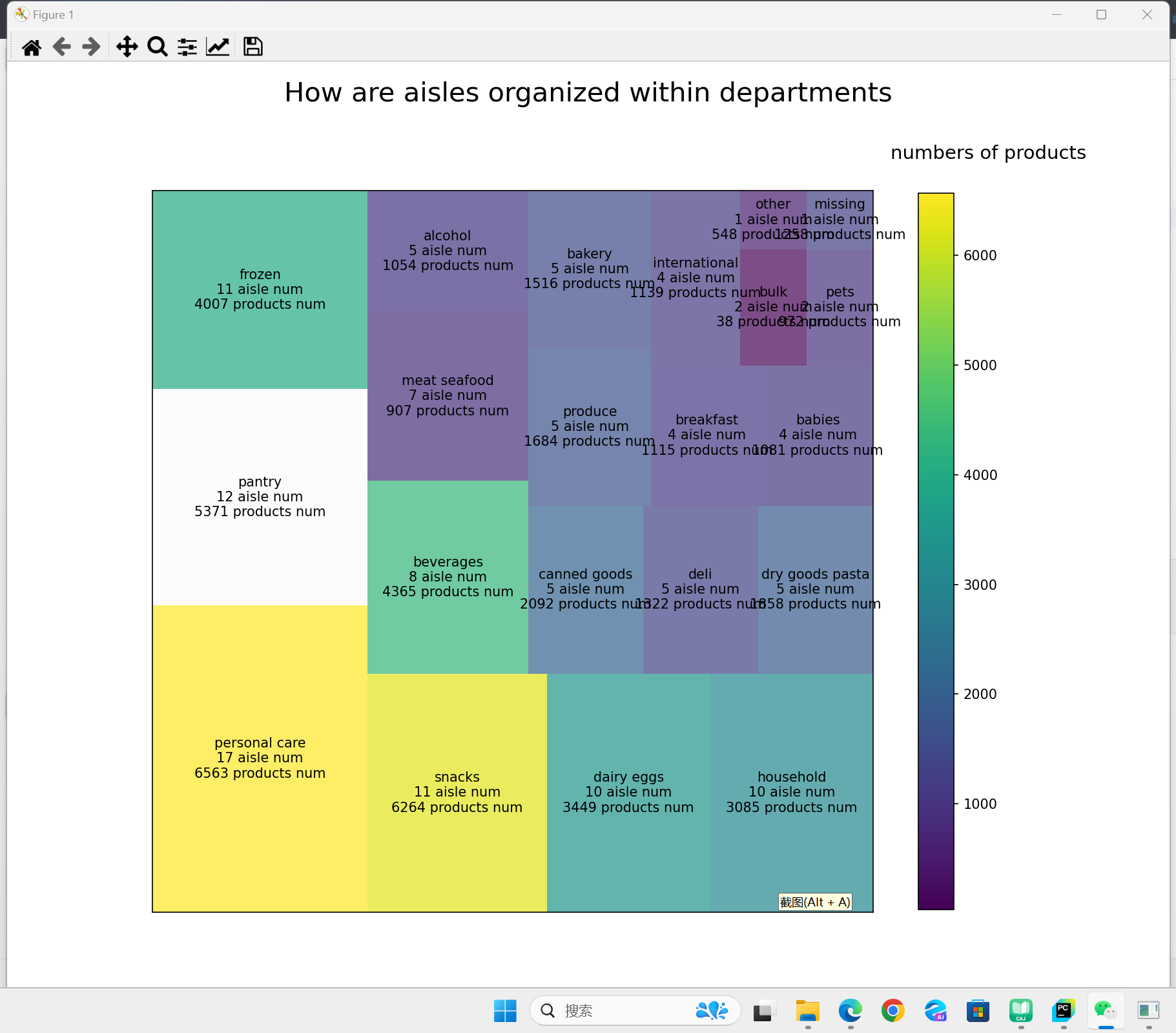
板块层级图效果如下:
完整代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib
import squarify
color = sns.color_palette()
pd.options.mode.chained_assignment = None # default='warn'
products_df = pd.read_csv("E:/数据可视化/products.csv")
aisles_df = pd.read_csv("E:/数据可视化/aisles.csv")
departments_df = pd.read_csv("E:/数据可视化/departments.csv")
order_products_prior_df = pd.merge(products_df, aisles_df, on='aisle_id', how='left')
order_products_prior_df=pd.merge(order_products_prior_df,
departments_df,
on='department_id', how='left')
order_products_prior_df.head()
temp = order_products_prior_df[['product_name', 'aisle', 'department']]
temp = pd.concat([
order_products_prior_df.groupby('department')['product_name'].nunique().rename('products_department'),
order_products_prior_df.groupby('department')['aisle'].nunique().rename('aisle_department'
)
], axis=1).reset_index()
temp = temp.set_index('department')
temp2 = temp.sort_values(by="aisle_department", ascending=False)
print(temp)
print(temp2)
x = 0
y = 0
width = 100
height = 100
cmap = matplotlib.cm.viridis
mini, maxi = temp2.products_department.min(), temp2.products_department.max()
norm = matplotlib.colors.Normalize(vmin=mini, vmax=maxi)
colors = [cmap(norm(value)) for value in temp2.products_department]
colors[1] = "#FBFCFE"
labels = ["%s\n%d aisle num\n%d products num" % (label) for label in
zip(temp2.index, temp2.aisle_department, temp2.products_department)]
fig = plt.figure(figsize=(12, 10))
ax = fig.add_subplot(111, aspect="equal")
ax = squarify.plot(temp2.aisle_department, color=colors, label=labels, ax=ax, alpha=.7)
fig.suptitle("How are aisles organized within departments", fontsize=20 )
ax.set_xticks([])
ax.set_yticks([])
img = plt.imshow([temp2.products_department], cmap=cmap)
img.set_visible(False)
fig.colorbar(img, orientation="vertical", shrink=.96)
fig.text(.76, .9, "numbers of products", fontsize=14)
plt.show()
六、实验心得
(一)数据处理
实验初期,我通过pandas的read_csv函数读取了三个独立的数据源(产品、货架、部门数据),并借助merge函数以左连接的方式完成多表关联,这一过程让我深刻理解到数据清洗与整合是可视化的基础。例如,在处理order_products_prior_df时,通过groupby结合nunique函数统计各部门的产品数量和货架数量,这种分组聚合操作不仅规范了数据格式,更构建了适合板块层级图(Treemap)的树状结构 —— 父类别(部门)与子类别(货架、产品)的层级关系通过数据预处理得以清晰呈现。
(二)可视化实现
本次实验的核心是使用squarify库绘制板块层级图,这一过程充满技术挑战与设计思考:
(1)图表特性的选择:板块层级图通过矩形面积映射数据大小,相较于传统饼图,其优势在于能同时展示多层级比例关系(如部门 - 货架 - 产品的嵌套结构),尤其适合树状数据。例如,实验中 “personal care” 部门的矩形面积最大,直观反映其货架和产品数量均为最高,而 “bulk” 部门的极小面积则凸显其数据特征。
(2)视觉元素的调优:颜色映射使用matplotlib.cm.viridis渐变色,结合Normalize函数实现数据范围归一化,确保颜色对比度合理;通过手动调整特定板块颜色(如设置colors[1]=“#FBFCFE”),避免视觉干扰。标签设计上,采用"%s\n%d aisle num\n%d products num"格式分层展示部门名称、货架数、产品数,解决了信息密度与可读性的平衡问题。
(3)细节优化的重要性:移除坐标轴(set_xticks([])/set_yticks([]))使图表更简洁,添加垂直颜色条并标注 “numbers of products”,辅助观众理解颜色与产品数量的映射关系,这些细节处理显著提升了图表的信息传达效率。
七、扩展内容
(一)库的导入与设置 pandas:用于数据处理和分析,比如读取 CSV 文件、数据合并、分组聚合等操作。
pandas:用于数据处理和分析,比如读取 CSV 文件、数据合并、分组聚合等操作。
matplotlib.pyplot:用于创建和定制可视化图表。
seaborn:用来提供调色板等可视化辅助功能。
matplotlib:matplotlib.pyplot的基础库,提供了颜色映射等工具。
squarify:用于绘制板块层级图。
pd.options.mode.chained_assignment = None:关闭pandas中链式赋值的警告信息。
(二)数据读取与合并
pd.read_csv:从 CSV 文件中读取数据并创建DataFrame对象。
pd.merge:将多个DataFrame按照指定的列进行合并,how='left’表示左连接。
(三)数据聚合与统计
groupby:按照指定列对数据进行分组。
nunique:统计每个分组中唯一值的数量。
pd.concat:将多个Series或DataFrame沿着指定轴(这里是axis=1,即列方向)进行拼接。
reset_index:将索引转换为列。
set_index:将指定列设置为索引。
sort_values:按照指定列对数据进行排序,ascending=False表示降序排序。
(四)颜色映射与标签设置
matplotlib.cm.viridis:选择viridis颜色映射。
matplotlib.colors.Normalize:对数据进行归一化处理,将数据映射到[0, 1]区间。
zip:将多个可迭代对象打包成元组序列。
(五)绘制板块层级图
plt.figure:创建一个新的图形窗口,figsize参数指定图形的大小。
fig.add_subplot:在图形窗口中添加一个子图。
squarify.plot:绘制板块层级图,alpha参数控制透明度。
(六)图表的定制与展示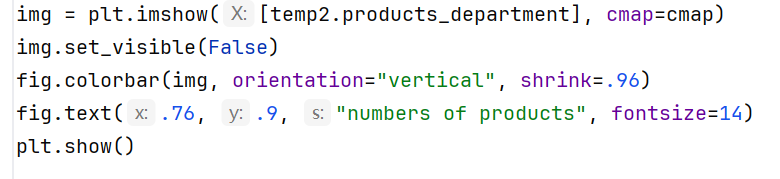
fig.suptitle:设置图形的总标题。
ax.set_xticks([])和ax.set_yticks([]):移除坐标轴刻度。
plt.imshow:创建一个图像对象,用于颜色条的生成。
fig.colorbar:添加颜色条。
fig.text:在图形中添加文本注释。
plt.show:显示图形。
知识点总结
1.数据读取与处理
读取 CSV 文件:借助pandas的read_csv函数来读取存储在本地的 CSV 文件,进而创建DataFrame对象,以方便后续的数据处理。
数据合并:运用pd.merge函数,能够按照指定的列(像aisle_id、department_id)对多个DataFrame进行合并,支持多种连接方式,这里使用的是左连接(how=‘left’)。
数据筛选与提取:通过DataFrame的索引操作,筛选出需要的列(例如[‘product_name’, ‘aisle’, ‘department’]),以聚焦于关键数据。
分组聚合:groupby方法可以按照指定列对数据分组,接着利用nunique函数统计每个分组内唯一值的数量,从而完成数据的聚合操作。
数据拼接:使用pd.concat函数,能将多个Series或DataFrame沿着指定轴(这里是列方向,axis = 1)拼接起来。
索引设置与排序:set_index方法可将指定列设置为索引,而sort_values方法则能按照指定列对数据进行排序,排序方式可选择升序或降序。
2. 可视化准备
调色板选择:seaborn库的color_palette函数可用于选择调色板,为可视化提供丰富的颜色选项。
颜色映射与归一化:matplotlib.cm模块提供了多种颜色映射,如viridis;matplotlib.colors.Normalize函数能将数据归一化到[0, 1]区间,以此实现数据与颜色的映射。
3. 可视化绘制
板块层级图绘制:squarify库的plot函数可用于绘制板块层级图,通过设置不同的参数(如颜色、标签、透明度等),能定制图表的外观。
图表创建与布局:plt.figure函数可创建一个新的图形窗口,fig.add_subplot函数能在图形窗口中添加子图。
图表元素设置:可通过一系列方法设置图表的各种元素,例如fig.suptitle设置总标题,ax.set_xticks和ax.set_yticks移除坐标轴刻度,fig.colorbar添加颜色条,fig.text添加文本注释等。
图表显示:最后使用plt.show函数显示绘制好的图表。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)