ICCV 2025 | 突破小目标检测瓶颈!多通道注意力+扩散模型,航拍域适配性能碾压传统方法
然而,当模型从一个地理区域迁移到另一个区域时,环境条件、成像参数等差异导致的"域转移"问题,常常让检测性能大打折扣。更棘手的是,高质量带标注的航空图像数据集稀缺,尤其针对特定地域的标注成本极高。可视化结果显示,不同令牌的注意力图会聚焦车辆的不同区域:[V1]更关注车身主体,"汽车"文本更侧重整体轮廓,背景令牌则有效排除非目标区域,三者融合显著提升定位精度。所有数据均采用12.5厘米/像素的高分辨率
点击上方“小白学视觉”,选择加"星标"或“置顶”
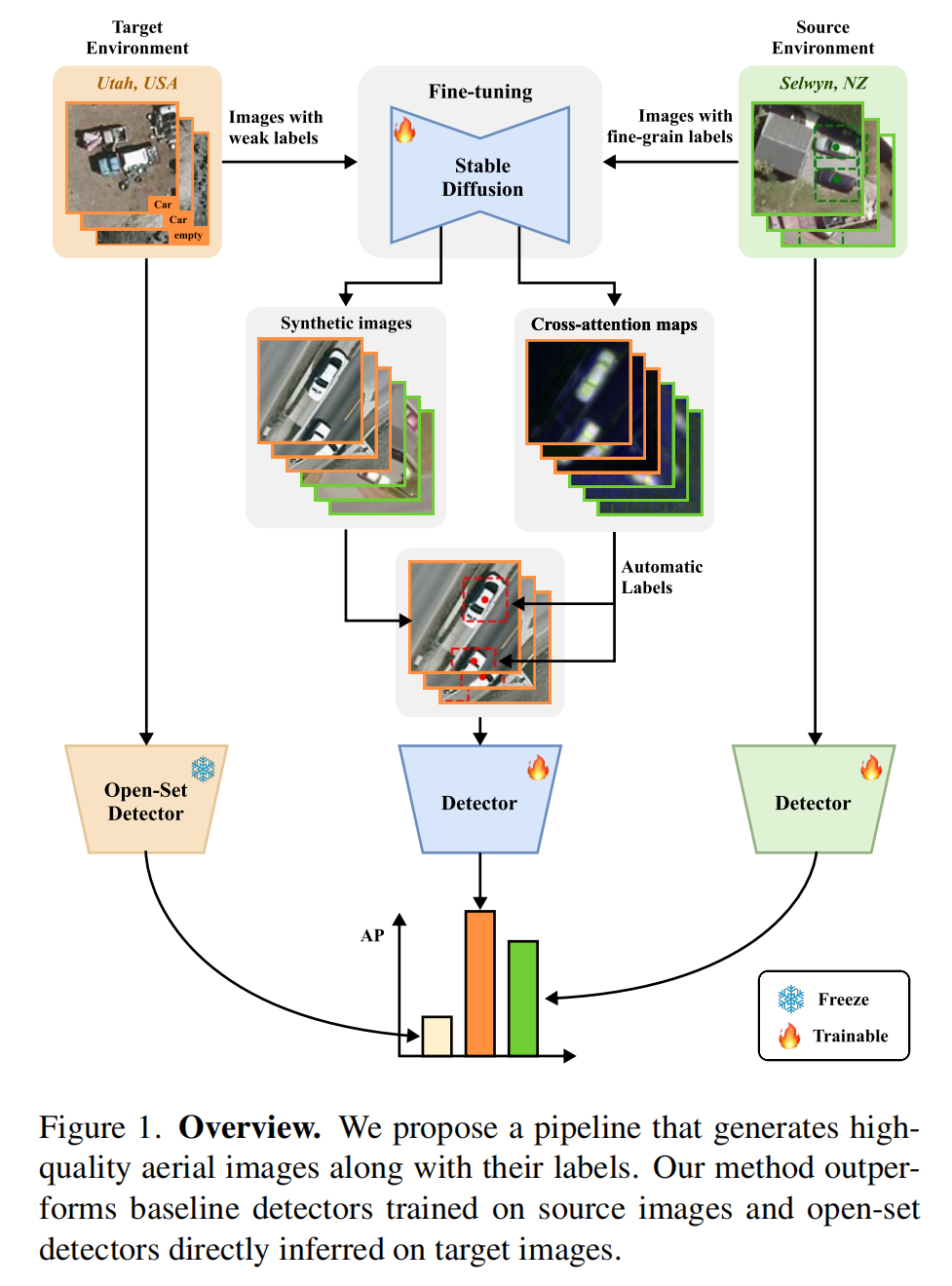
重磅干货,第一时间送达在交通监控、城市规划和国防安全等领域,航空图像中的车辆检测始终是一项关键任务。然而,当模型从一个地理区域迁移到另一个区域时,环境条件、成像参数等差异导致的"域转移"问题,常常让检测性能大打折扣。ICCV 2025最新研究《Adapting Vehicle Detectors for Aerial Imagery to Unseen Domains with Weak Supervision》提出了一种基于生成式AI的创新解决方案,通过弱监督合成目标域数据,将跨域检测精度提升最高达50%。
论文信息
题目:Adapting Vehicle Detectors for Aerial Imagery to Unseen Domains with Weak Supervision
基于弱监督将航空图像车辆检测器适配到未知领域
作者:Xiao Fang, Minhyek Jeon, Zheyang Qin, Stanislav Panev, Celso de Melo, Shuowen Hu, Shayok Chakraborty, Fernando De la Torre
源码:https://humansensinglab.github.io/AGenDA
研究背景:航空图像检测的"水土不服"难题
深度学习模型在航空图像车辆检测中已取得SOTA性能,但存在严重的"地域偏见"——在纽约训练的模型可能在伦敦表现糟糕。这种域转移源于:
-
环境差异:光照条件、植被覆盖、建筑风格不同
-
成像参数:分辨率、拍摄角度、传感器类型变化
-
目标特征:车辆类型、密度分布存在地域特性
现有解决方案存在明显局限:无监督域适应方法难以捕捉细粒度特征,弱监督方法依赖大量伪标签,开放集检测在航空场景中因训练数据不足表现惨淡。更棘手的是,高质量带标注的航空图像数据集稀缺,尤其针对特定地域的标注成本极高。
核心创新:四步突破跨域检测瓶颈
创新点1:多通道交叉注意力生成式合成框架
研究提出基于Stable Diffusion的两阶段微调策略,通过多通道交叉注意力图实现精准概念定位。与传统文本到图像生成不同,该方法:
-
为源域和目标域设计专属文本提示(如"在[新西兰]中带有[汽车]的航空图像")
-
引入可学习令牌[V1][V2][V3]分别捕获对象和背景概念
-
通过注意力图正则化损失,确保对象令牌与"汽车"概念高度相似,背景令牌与之显著区分
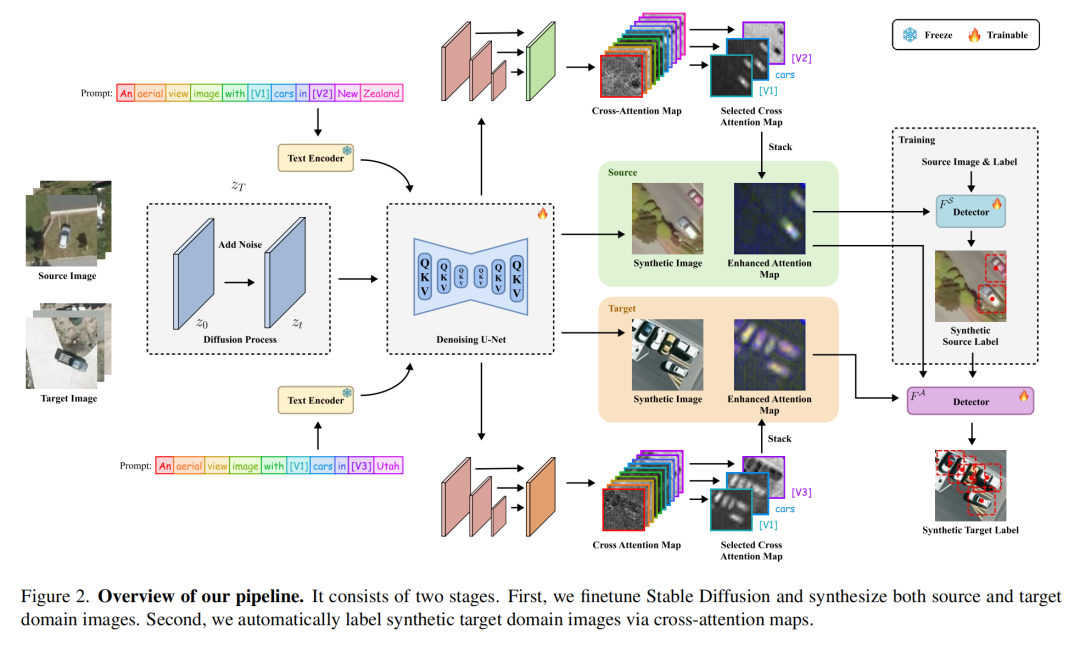
创新点2:跨注意力图自动标注技术
解决生成式模型缺乏目标注释的关键痛点,提出堆叠注意力图(eA)标注策略:
-
从U-Net的四层不同分辨率特征中提取交叉注意力图
-
融合"汽车"概念与可学习令牌的注意力图,形成增强特征
-
利用源域检测器生成伪标签,训练注意力图专用检测器F_A
-
通过置信度阈值过滤与分类器细化,提升标签可靠性

可视化结果显示,不同令牌的注意力图会聚焦车辆的不同区域:[V1]更关注车身主体,"汽车"文本更侧重整体轮廓,背景令牌则有效排除非目标区域,三者融合显著提升定位精度。
创新点3:多检测器验证的鲁棒性设计
通过四种主流检测器全面验证方法有效性:
-
两阶段检测器:Faster-RCNN
-
单阶段检测器:YOLOv5、YOLOv8
-
Transformer架构:ViTDet
对比实验表明,该方法在不同架构上均能稳定提升性能,证明其与检测器类型的解耦性和广泛适用性。
创新点4:两个超大规模航空数据集
为解决领域数据稀缺问题,研究团队发布两个全新数据集:
-
LINZ:新西兰塞尔温地区207万张图像,含3.5万小型车辆标注
-
UGRC:美国犹他州268万张图像,含3.8万小型车辆标注
所有数据均采用12.5厘米/像素的高分辨率,统一裁剪为112×112像素块,与DOTA数据集形成互补,为跨域检测研究提供重要基准。

方法框架:从数据合成到检测适配的全流程
整个方法流程可分为四个核心步骤,总体框架如下:
-
模型微调:在源域(带完整标注)和目标域(仅图像级标注)数据上微调Stable Diffusion,学习域特定特征
-
注意力图生成:通过两阶段训练,优化可学习令牌与交叉注意力图,实现精准概念定位
-
合成数据标注:利用增强注意力图训练专用检测器,为合成目标域图像生成伪标签
-
检测器适配:使用合成的带标注目标域数据,训练最终的跨域车辆检测器
实验结果:全面超越现有方法
在LINZ→UGRC和DOTA→UGRC两个跨域场景中,该方法表现出显著优势:
-
相比源域监督学习,AP50提升4-23%
-
超越弱监督适应方法6-10%
-
领先无监督域适应方法7-40%
-
大幅优于开放集检测器(提升超50%)
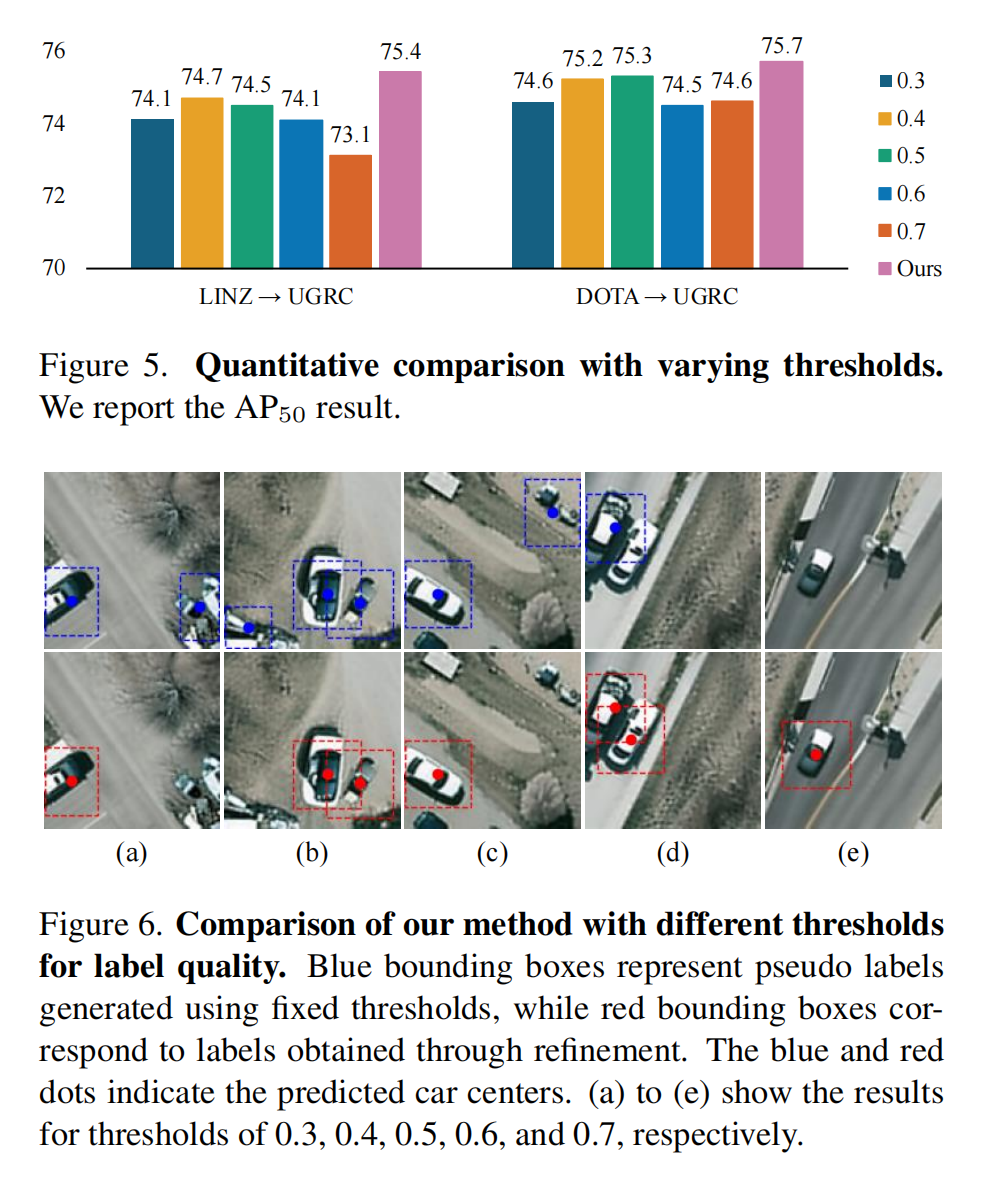
消融实验验证了各组件的有效性:
-
多通道注意力图融合使精度提升1.2-5.6%
-
标签细化模块有效解决阈值选择难题,在不同数据集上保持稳定性能
-
两阶段微调策略显著提升合成图像与目标域的分布一致性
局限与未来方向
研究团队坦诚指出当前方法的局限性:
-
受限于Stable Diffusion的8×8交叉注意力分辨率,需将图像裁剪为112×112块,可能丢失全局上下文
-
处理重叠车辆时,注意力图易混淆,影响标注精度
未来将整合航空专用视觉大语言模型(VLLMs),实现完全无监督的跨域适配流程,进一步拓展在复杂场景中的应用能力。
总结
该研究创新性地将生成式AI与弱监督学习结合,为航空图像跨域车辆检测提供了全新范式。其核心价值在于:
-
降低对目标域标注数据的依赖,仅需图像级存在性标签
-
合成数据兼具源域标注质量与目标域分布特性
-
通用框架可适配多种检测器架构,易于工程落地
随着两个超大规模数据集的公开,相信将推动航空图像理解领域的更多创新研究。对于需要处理多区域航空数据的企业和研究机构,该方法提供了切实可行的跨域迁移解决方案。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:人工智能0基础学习攻略手册
在「小白学视觉」公众号后台回复:攻略手册,即可获取《从 0 入门人工智能学习攻略手册》文档,包含视频课件、习题、电子书、代码、数据等人工智能学习相关资源,可以下载离线学习。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献540条内容
已为社区贡献540条内容

所有评论(0)