机器视觉:视觉大模型——从技术突破到产业革新的全面解析
本文从定义、研究现状、技术分支、产业应用等维度,带您全面读懂视觉大模型的技术内核与发展脉络。
文章目录
前言
当我们用手机扫码支付时的人脸识别、自动驾驶汽车对路况的实时判断、医生借助AI辅助分析医学影像、设计师通过文本指令生成创意图像——这些看似无关的场景,背后都离不开同一类核心技术的支撑:视觉大模型。
在自然语言大模型掀起AI革命之后,视觉大模型正以同样迅猛的势头重塑计算机视觉领域。作为人工智能感知世界的"眼睛",视觉大模型打破了传统视觉算法"一任务一模型"的局限,通过大规模数据训练和先进架构设计,实现了从图像识别到场景理解、从被动感知到主动决策的能力跃升。它不仅让机器具备了接近人类的视觉认知水平,更成为连接物理世界与数字世界的关键桥梁,推动千行百业的智能化转型。
本文将从定义、研究现状、技术分支、产业应用等维度,带您全面读懂视觉大模型的技术内核与发展脉络。
一、视觉大模型的核心定义
视觉大模型(Visual Large Model)本质上是一类基于基础模型(Foundational Models) 理念构建的人工智能系统,其核心定义可概括为:通过自监督或半监督学习方式,在海量视觉数据(图像、视频)及多模态数据(文本-图像、音频-视频等)上训练,具备大规模参数规模和强泛化能力,能够自适应解决多种下游视觉任务的通用型模型。
这一定义包含三个关键特征,区别于传统计算机视觉模型:
- 通用泛化性:无需针对特定任务重新训练,通过提示工程(Prompt Engineering)或少量微调即可适配目标检测、语义分割、图像生成等多种任务,实现零样本/少样本学习;
- 大规模基础:训练数据量通常达到数千万至数十亿级,模型参数规模从亿级到千亿级不等,通过数据与参数的双重规模效应实现能力涌现;
- 多模态融合:打破单一视觉模态局限,普遍集成文本、音频等信息,实现跨模态语义对齐与交互(如文本生成图像、图像描述生成)。
其技术根源可追溯至Transformer架构在视觉领域的应用(如ViT模型),通过将图像转化为序列数据进行处理,解决了传统CNN模型在长距离依赖建模上的不足,为大规模视觉模型的发展奠定了基础。
二、视觉大模型的研究现状
视觉大模型的研究已从早期的单模态建模,发展为多模态融合、细粒度感知与决策推理并重的新阶段,关键突破集中在以下三大方向:
1. 基础架构与训练范式成熟化
- Transformer主导架构:ViT(Vision Transformer)的提出开启了视觉大模型的新时代,后续衍生出Swin Transformer、MAE(掩码自编码器)等优化架构,在保持模型性能的同时提升计算效率。智源团队的EVA模型通过融合CLIP的语义学习与MIM的几何结构学习,仅用十亿参数便实现了领先的视觉表示能力;
- 训练目标多元化:对比式学习(如CLIP的图像-文本对比损失)解决了多模态对齐问题,生成式学习(如扩散模型、掩码语言建模)强化了内容生成能力,而强化学习(RLHF、GRPO)则通过人类反馈或可验证奖励提升模型决策的可靠性;
- 数据利用高效化:从依赖人工标注数据转向大规模弱监督/无监督数据,通过Web爬取的图像-文本对(如CLIP使用的WebImageText)、伪标签数据(如GLIP、SA-1B)构建训练集,降低数据标注成本。
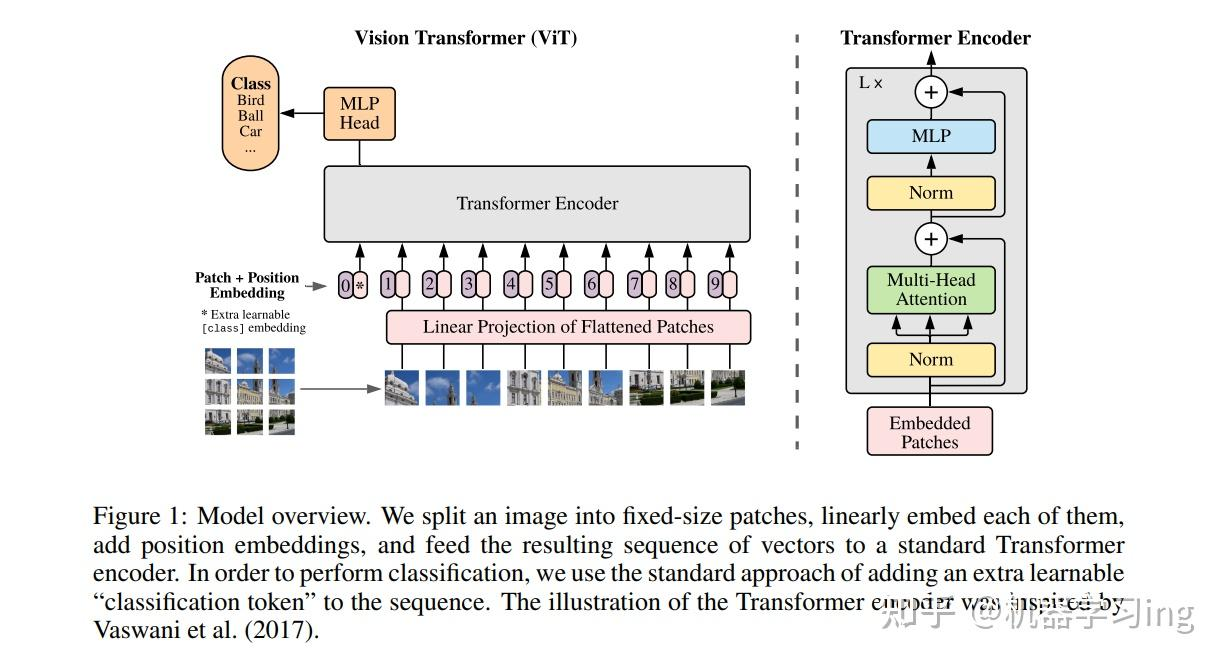
图 1:模型整体架构我们将图像分割为固定大小的补丁块(fixed-size patches),对每个补丁块进行线性嵌入(linearly embed),添加位置嵌入(position embeddings),并将得到的向量序列输入标准 Transformer 编码器。为实现分类功能,我们采用主流方案:在序列中额外添加一个可学习的 “分类令牌(classification token)”。Transformer 编码器的示意图设计灵感源自 Irwan Vaswani 等人(2017 年)的研究 [1]。
2. 关键模型与技术突破
近年来,一批具有里程碑意义的视觉大模型相继问世,推动技术边界持续拓展:
-
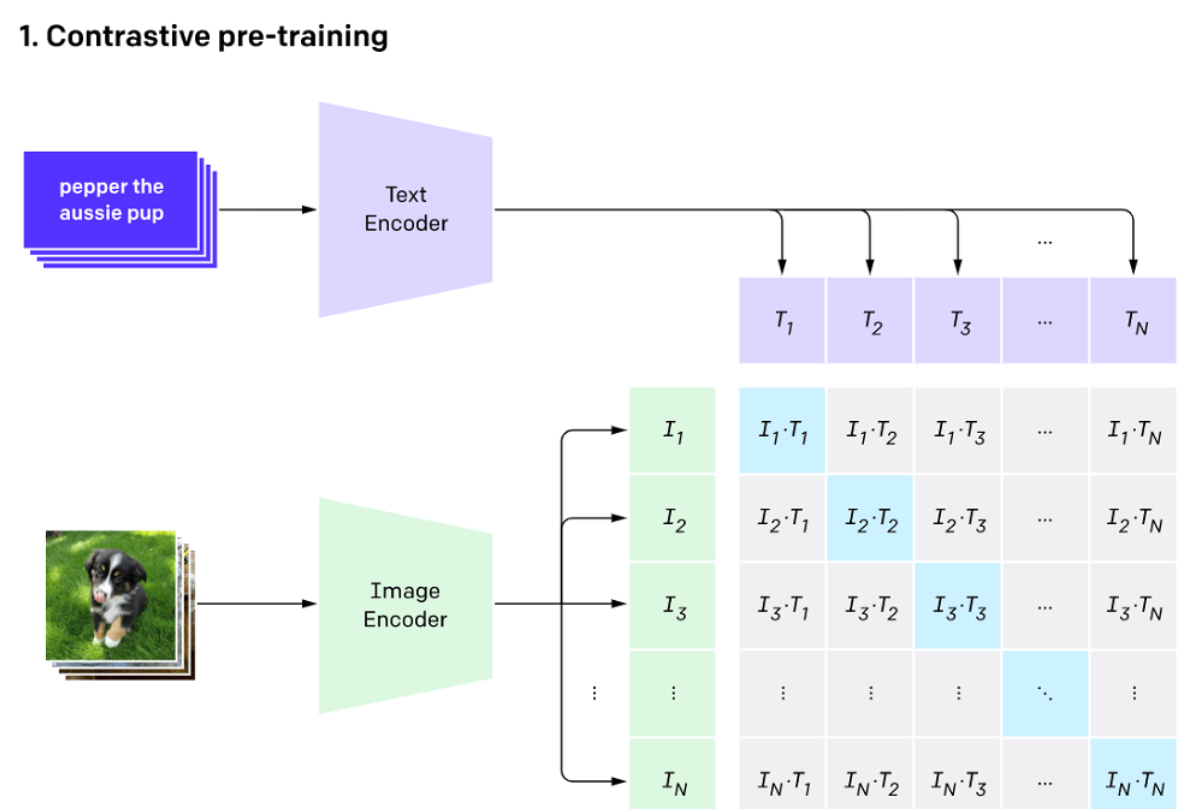
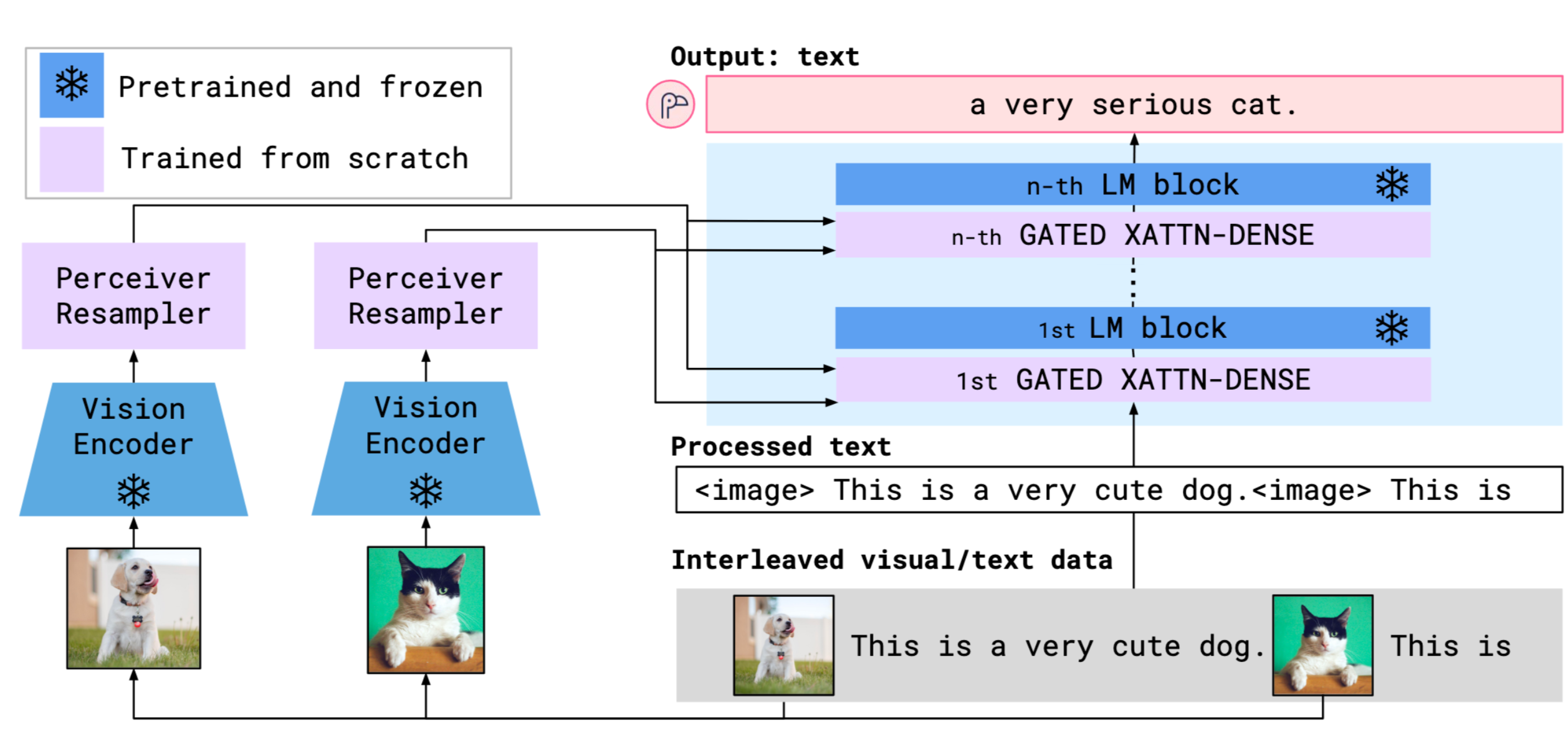
多模态对齐模型:OpenAI的CLIP首次实现了文本与图像的深度语义对齐,使模型能够通过自然语言提示完成零样本分类;Google的Flamingo通过Perceiver Resampler连接视觉与语言模型,提升了跨模态推理能力;
-
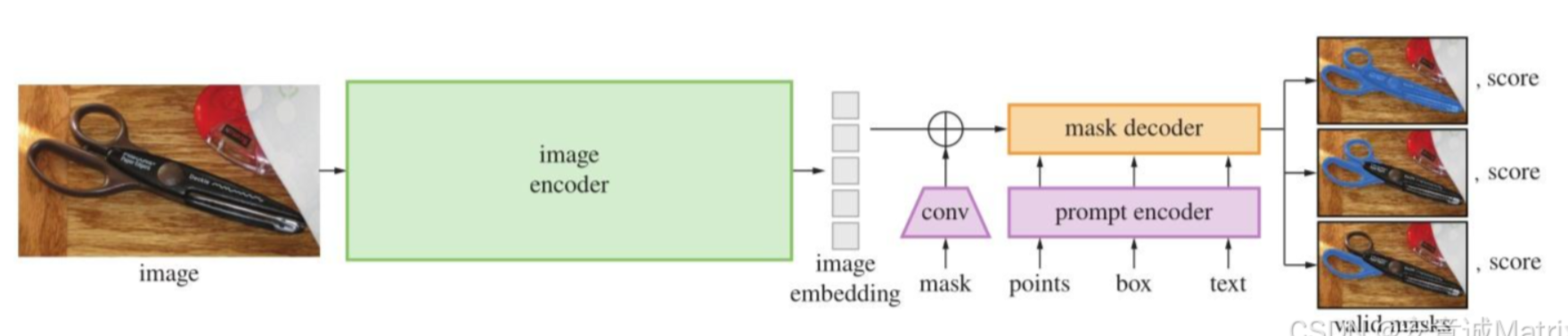
视觉提示模型:Meta的SAM(Segment Anything Model)开创了"分割一切"的先河,通过点、框等视觉提示即可实现通用目标分割,无需任务特定训练,已广泛应用于医学影像、遥感等领域;
-
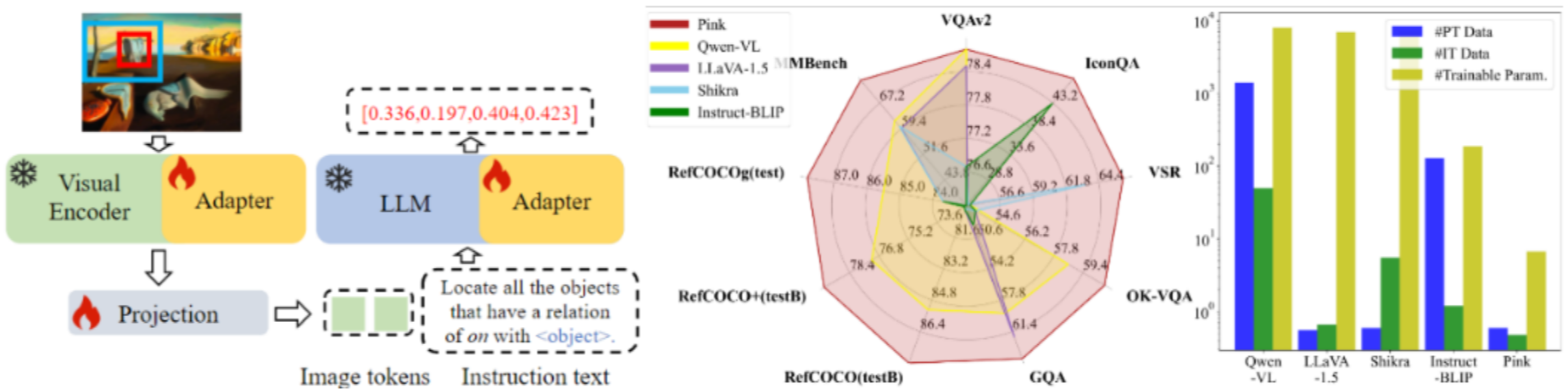
细粒度感知模型:北京大学的Pink模型通过坐标框文本化、适配器微调等创新,实现了图像中特定物体的细粒度指代分析,在GQA数据集上超越同类方法5.2%;LocLLM则将多模态大模型拓展至人体姿态感知,跨数据集泛化准确率领先传统方法11.0%;
-
强化学习融合模型:Gemini 2.5通过RL优化视觉-文本推理过程,VLM-R1采用GRPO算法提升零样本鲁棒性,使模型决策更贴合人类偏好与实际场景需求。
3. 性能与效率持续优化
当前视觉大模型在各项基准测试中表现亮眼:在多模态评测基准MMBench上,Pink模型以仅6.7M可微调参数量和477K指令微调数据,超越第二名5.6%;在目标检测、语义分割等传统任务上,通过预训练+微调的方式,模型性能已远超传统专用算法;同时,通过LoRA(低秩适配)、知识蒸馏等技术,模型微调成本显著降低,已可在消费级GPU上完成训练。
三、视觉大模型的研究方向分支
随着技术发展,视觉大模型的研究已形成多个明确分支,涵盖架构设计、能力拓展、落地优化等多个维度:
1. 基于提示方式的分类
- 文本提示模型(Textually Prompted Models):通过自然语言指令驱动模型完成任务,核心是视觉-文本语义对齐,代表模型有CLIP、BLIP、InstructBLIP等,支持零样本分类、图像描述、跨模态检索等任务;
- 视觉提示模型(Visually Prompted Models):以视觉信号(点、框、掩码)作为输入提示,实现精准目标定位与分割,代表模型有SAM、SegGPT、Grounding-DINO,在开放世界检测、像素级分割任务中表现突出;
- 多模态提示模型(Heterogeneous Modalities-based Models):融合文本、视觉、音频等多种提示信号,实现复杂场景理解,代表模型有ImageBind、Valley、Gemini,支持跨模态内容生成与交互。
2. 基于架构设计的分类
- 双编码器架构:独立处理视觉与文本模态,通过对比损失优化模态对齐,如CLIP、ALBEF,优势是训练高效、跨模态检索性能优异;
- 融合架构:引入额外融合编码器学习跨模态表示,如FLAVA、BLIP-2,擅长复杂语义理解与推理任务;
- 编码器-解码器架构:结合视觉编码器与语言解码器,支持生成式任务,如Flamingo、KOSMOS,可实现图像字幕生成、多模态对话;
- 自适应LLM架构:以大语言模型为核心,通过视觉编码器将图像转化为LLM兼容格式,如GPT-4V、Qwen-VL,具备强大的逻辑推理与多任务处理能力。
3. 基于核心能力的分类
- 细粒度感知:聚焦图像局部特征与复杂关系理解,如Pink的指代分析、LocLLM的人体关键点定位,突破传统模型"图像级"理解局限;
- 3D与视频理解:从2D图像扩展至3D场景重建、视频时序分析,如PointE的3D生成、VideoMAE的视频预训练,支撑自动驾驶、虚拟现实等场景;
- 视觉-语言-行动(VLA):融合感知、推理与执行能力,如李飞飞团队的语言指令机器人、VLA智能体,推动具身智能发展;
- 模型轻量化与边缘部署:通过压缩、蒸馏、量化等技术,适配边缘设备,如大小模型协同架构、联邦学习部署,解决云端依赖与隐私问题。
4. 基于训练目标的分类
- 对比式学习:通过最大化正样本对相似度、最小化负样本对相似度学习表示,如CLIP的ITC损失、FILIP Loss;
- 生成式学习:通过生成目标优化模型,如掩码语言建模(MLM)、字幕生成损失(Cap Loss)、扩散模型的生成损失;
- 强化学习:基于反馈信号优化策略,如RLHF(人类反馈强化学习)、GRPO(群体相对策略优化)、RLVR(可验证奖励强化学习),提升模型决策可靠性。
四、视觉大模型的产业应用现状
视觉大模型已从实验室走向产业落地,在多个行业形成规模化应用,展现出"技术工具"向"产业操作系统"进化的清晰路径:
1. 智慧城市与公共安全
- 城市治理:大华星汉大模型2.0实现对出店经营、流动摊贩等20类城市事件的精准识别,平均准确率较传统模型提升10%以上,场景覆盖从街道园区扩展至水域河岸、建筑工地;
- 交通管理:通过解析90余种交通场景信息,实现道路抛洒物、违规行驶等事件的自动检测与分级预警,抛洒物检测准确率提升50%,支持危险等级智能判断;
- 周界安防:基于SAM的动态分割技术,实现场景自动分类与异常行为识别(如翻越护栏、破坏设施),大幅缩短设备部署周期,降低运维成本。
2. 工业与能源领域
- 工业质检:在煤矿、制造业场景中,实现传送带20余种异常(锚杆、异物、水煤)实时识别,矿料质量分析(煤块大小、装载率)自动化,平均准确率提升10%以上,无需人工配置规则参数;
- 设备运维:通过分析设备运行视频与历史数据,实现故障预测性维护,如轴承磨损预警、管线泄漏检测,降低非计划停机风险;
- 遥感监测:高分辨率遥感图像语义分割、多时相变化检测技术,应用于城市规划、灾害监测、农作物估产,支撑智能地球建设。
3. 医疗健康领域
- 医学影像分析:基于视觉大模型的病灶分割与检测技术,已应用于CT、MRI、X射线等多模态医学图像分析,实现肿瘤边界精准勾画、早期病灶筛查,提升诊断效率与准确性;
- 临床辅助决策:融合医学知识图谱与视觉模型,支持影像报告自动生成、疾病分期评估,辅助医生制定治疗方案;
- 远程医疗:通过边缘端小模型实现手术视频实时处理与关键区域提取,降低传输延迟,支撑远程手术指导。
4. 消费电子与内容创作
- 智能终端:手机、相机等设备集成视觉大模型,实现人像美化、场景识别、实时翻译等功能,提升用户体验;
- 内容生成:文本-图像生成(如Stable Diffusion)、图像编辑、视频剪辑辅助,赋能设计师、创作者提升生产效率;
- 多模态交互:数字人、智能音箱等产品通过视觉-语言融合技术,实现更自然的人机交互,如通过手势指令控制设备、图像内容问答。
五、总结与展望
视觉大模型的出现,标志着计算机视觉领域从"任务专用"向"通用智能"的跨越。通过大规模数据训练与先进架构设计,它打破了模态壁垒与任务边界,不仅在技术层面实现了感知、理解、生成、决策能力的全面提升,更在产业层面成为驱动数字化转型的核心引擎。
当前,视觉大模型的发展仍面临多重挑战:数据隐私与安全风险(训练数据泄露、模型投毒)、算法偏见与公平性问题、算力成本过高、可解释性不足,以及边缘部署的效率瓶颈。这些问题需要学界与业界协同解决,通过技术创新(如差分隐私、模型压缩)、制度建设(如伦理审查框架)、标准规范(如数据治理准则)共同推动行业健康发展。
展望未来,视觉大模型将呈现三大发展趋势:
- 多模态深度融合:从简单的视觉-文本对齐走向视觉、语言、音频、传感器数据的全域融合,实现更全面的场景理解与交互能力;
- 专用化与轻量化并行:一方面面向垂直行业打造专用模型(如医疗、工业定制版大模型),另一方面通过技术优化实现边缘端高效部署,满足实时性与隐私保护需求;
- 具身智能与自主进化:视觉大模型将与机器人技术、强化学习深度结合,形成具备感知-决策-执行闭环的智能体,应用于自动驾驶、服务机器人、工业自动化等领域,从"理解世界"走向"改造世界"。
从实验室的技术突破到产业界的规模化应用,视觉大模型正以惊人的速度重塑我们的生活与工作。随着技术的持续迭代与生态的不断完善,相信在不久的将来,视觉大模型将如同水电一样融入社会生产生活的各个角落,成为推动新质生产力发展的核心力量。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)