玩转大模型,你的GPU显存够用吗?一文看懂估算方法
本文探讨了大模型私有化部署中GPU显存配置的关键因素。首先分析了显存占用主要来源:模型参数(约14GB/7B参数FP16)、激活值和KV缓存(与批次/序列长度相关)、梯度(16GB/8B参数)以及优化器状态(64GB/8B参数)。对比了不同场景下的显存需求:推理场景约22-24GB(Llama3 8B),全量微调则高达107-128GB。重点介绍了PEFT微调技术(如LoRA)可将需求降至27-4
日常做项目,对大模型的私有化部署也有刚需,花点时间深入研究了下模型使用和GPU显卡配置的关系,做个记录。
GPU的显存大小直接决定了我们能跑多大的模型、跑多快(影响批处理大小和序列长度),以及训练过程是否稳定。
那么如何评估呢,包含以下几个考虑的因素:
1. 模型参数本身
最基础的显存占用来自于模型参数本身。这部分的计算相对直接:
VRAM_参数 ≈ 模型参数总量 × 单个参数所需字节数。
FP32: 4 字节
FP16 / BF16: 2 字节
INT8: 1 字节
INT8: 1 字节
INT4: 0.5 字节
不同的量化方案会将模型参数进行压缩。
以一个 70 亿参数的 Llama 3 8B 模型为例,若采用 FP16 加载,
7B × 2 bytes ≈ 14 GB
2.激活值(Activations)& KV Cache
这是模型前向传播时的中间计算结果。其大小与批次大小 (Batch Size)、序列长度 (Sequence Length)、模型隐藏维度 (Hidden Dimension) 和 层数 (Number of Layers) 强相关。
在模型生成文本(自回归)时,为加速计算,需要缓存过去每个 Transformer 层的 Key 和 Value 状态。这部分显存消耗巨大,会随着序列长度和批次大小线性增长。
VRAM_KV_Cache (近似) ∝ 2 × 层数 × 隐藏维度 × 序列长度 × 批次大小 × 单值字节数
当面对模型训练或SFT的场景时,还有以下两大显存消耗者需要考虑。
3.梯度 (Gradients)
其一是梯度(Gradients)。
在反向传播过程中,系统需要为每一个可训练的参数计算梯度值,以便更新模型权重。
VRAM_梯度 ≈ 可训练参数量 × 训练精度对应的字节数
通常,梯度的精度与训练时模型参数的精度保持一致,例如,若使用 FP16 进行训练,梯度也占用 FP16 的空间。
4.优化器状态(Optimizer States)
其二是优化器状态(Optimizer States),这是训练时的“显存大户”。 优化器(如 Adam, AdamW)需要为每个可训练参数维护状态信息(如动量、方差)。
更关键的是,这些状态值往往以 FP32(4字节)精度存储,即使模型主体是使用 FP16 或 BF16 进行训练。AdamW 对每个可训练参数,常需 2 × 4 = 8 字节额外存储。
全量微调 7B 模型,仅此项就可能需
7B × 8 bytes = 56 GB
使用 8-bit 优化器可大幅降低此项。
推理/训练场景下GPU显存估算
1. 推理
总推理 VRAM ≈ VRAM_参数 + VRAM_激活器 + VRAM_kv_cache + VRAM_开销
以一个Llama 3 8B (FP16) 推理为例:
模型参数:
8B 参数 * 2 字节/参数 = 16 GB激活和 KV 缓存:高度依赖于序列长度和批次大小。对于批次大小为 4,序列长度为 2048: 假设 Hidden Dim = 4096,Num Layers = 32,KV Cache (FP16):
2×32×4096×2048×4×2 bytes≈4.3 GB
开销: 框架、CUDA 内核,估计为 1-2 GB
2.训练
全量微调
VRAM ≈ VRAM_params + VRAM_gradients + VRAM_optimizer + VRAM_activations + VRAM_overhead
Llama 3 8B (FP16), AdamW (FP32 状态)
1、模型参数 (FP16):80 亿参数 * 2 字节/参数 = 16 GB
2、梯度(FP16):8B 参数 * 2 字节/参数 = 16 GB优化器状态(AdamW,FP32):
2 个状态/参数 * 8B 参数 * 4 字节/状态 = 64 GB 激活值:很大程度上取决于批次大小和序列长度。可能为 10-30 GB 或更多(高度近似)。
3、额外开销:估计 1-2 GB。
4、估计总计:16 + 16 + 64 + (10 到 30) + (1 到 2) ≈ 107 - 128 GB
PEFT微调
使用LoRA等技术进行微调,通过冻结基础模型参数并仅训练小型适配器层,可以显著降低VRAM 需求。
带有 LoRA 的 Llama 3 8B(Rank=8,Alpha=16)
1、基础模型参数(冻结,例如,FP16):16 GB
2、LoRA 参数(可训练,BF16):通常非常小,例如,约 1000 万到 5000 万个参数。假设 2000 万个参数 * 2 字节/参数 ≈ 40 MB(相对于基础模型可以忽略不计)。
3、LoRA 梯度 (BF16):20M 参数 * 2 字节/参数 ≈ 40 MB。4、4、LoRA 优化器状态 (AdamW, FP32): 2 * 20M 参数 * 4 字节/状态 ≈ 160 MB。
5、激活值: 仍然很重要,类似于推理,但在通过适配器的正向/反向传递期间为完整模型计算。估计 10-30 GB(取决于批大小/序列长度)。
6、开销: 1-2 GB。
7、合计RAM(LoRA) :16 GB (Base) + ~0.24 GB (LoRA Params/Grads/Optim) + (10 到 30) GB (Activations) + (1 到 2) GB (Overhead) ≈ 27 - 48 GB
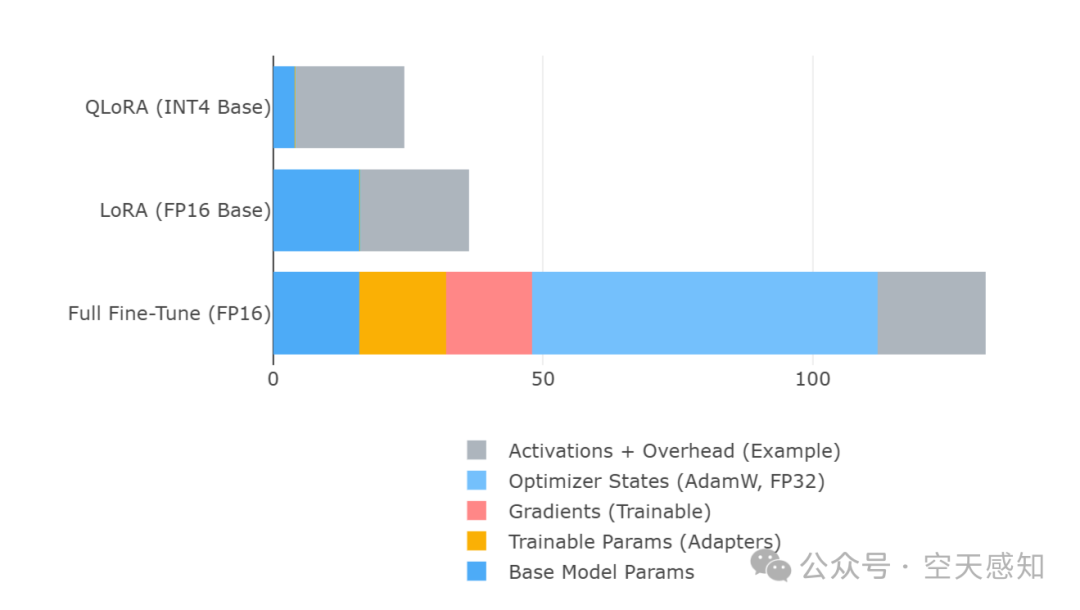
不同微调方法对RAM的需求
用于GPU RAM的计算器
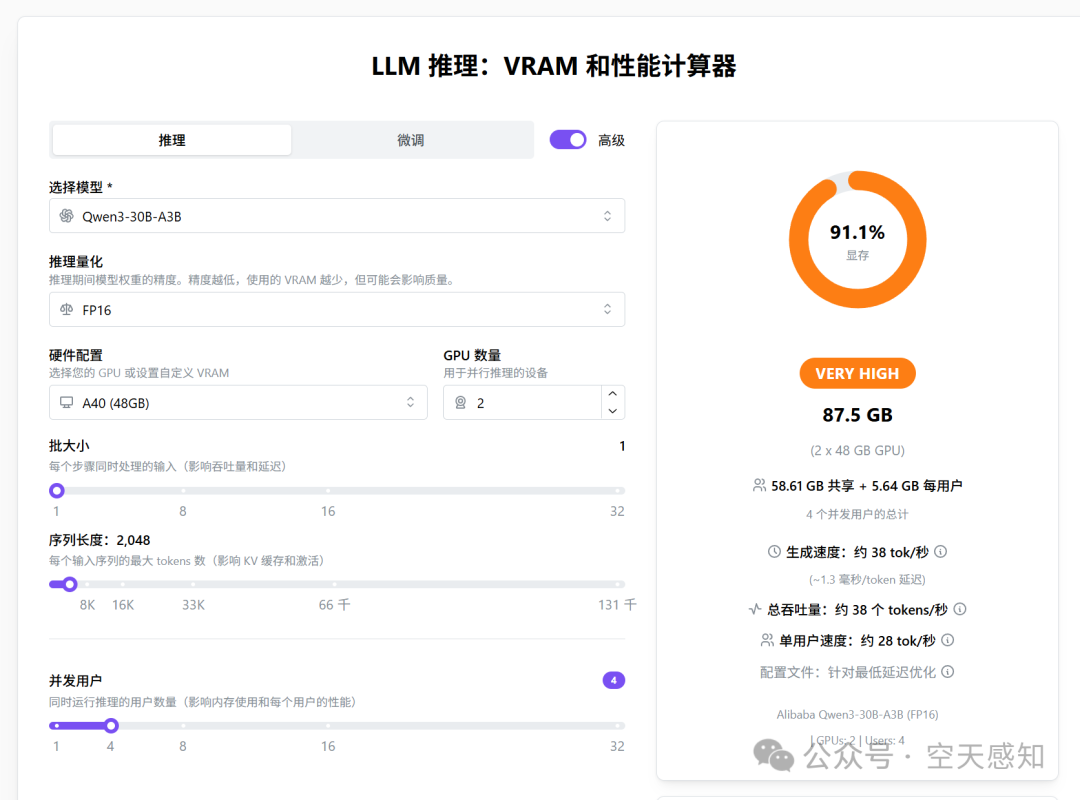
国外有个APP,做了一个在线计算显存的计算器,可以试下。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集***
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献285条内容
已为社区贡献285条内容

所有评论(0)