一文搞懂大模型的预训练、微调和蒸馏
预训练使用海量无标注标注数据(如互联网文本、图像库)进行通识教育(大学基础课程);微调使用专业领域标注数据(如医疗影像、法律文书、代码库)进行专业培训(入职后的岗位技能培训);蒸馏使用教师模型的输出(如概率分布、推理链)进行经验传承(老员工带新人)。
初学者常对大模型的预训练(Pre-training)、微调(Fine-tuning)和蒸馏(Distillation)感到困惑,三者虽均属模型训练,但目标、数据和实现方式差异显著。
预训练使用海量无标注标注数据(如互联网文本、图像库)进行通识教育(大学基础课程);微调使用专业领域标注数据(如医疗影像、法律文书、代码库)进行专业培训(入职后的岗位技能培训);蒸馏使用教师模型的输出(如概率分布、推理链)进行经验传承(老员工带新人)。
预训练(Pre-training)
预训练(Pre-training):大学通识教育
让模型“学会思考”,具备通用能力。
(1)目标:让模型具备通用能力,理解语言、图像等底层规律。
(2)数据:海量无标注/弱标注数据(如互联网文本、图像库)。
(3)效果:模型具备基础能力,但缺乏针对特定任务的精细技能(类似“通过面试但未上岗”)。
预训练通过海量无标注数据(如互联网文本)让大语言模型(LLM)接受大学通识教育(如数学、物理、英语)。就像大学生先学基础学科,为未来专业方向打基础。
预训练(Pre-training)就是暴力美学,通过堆算力,实现Scaling Low。不过这条路目前有点停滞,因为大模型能学习的互联网高质量数据接近用尽,传统依赖大规模预训练和模型扩张的发展路径正面临瓶颈。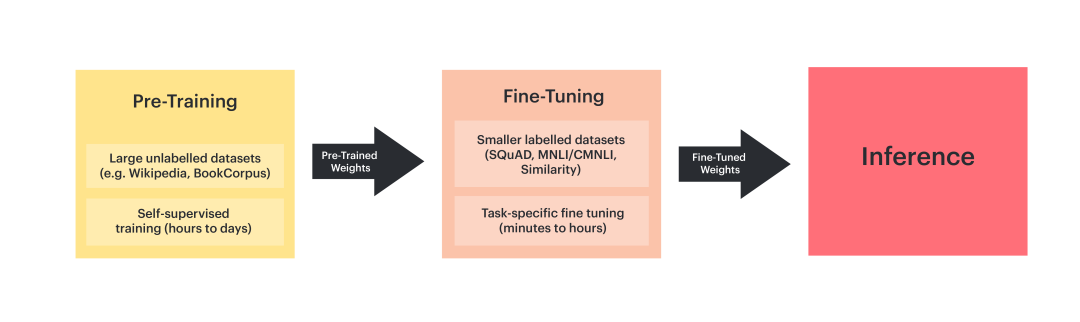
微调(Fine-tuning)
微调(Fine-tuning):专业培训(入职后的岗位技能培训)
让模型“学会干活”,针对特定任务优化。
(1)目标:让模型在特定任务上表现优异。
(2)数据:专业领域标注数据(如医疗影像、法律文书、代码库)。
(3)效果:模型在特定任务上达到高精度(类似“上岗干活”)。
大语言模型在预训练模型基础上通过大量标注数据进行微调(调整模型最后几层参数),从而学习垂直领域的专项技能。就像医生入职后学习专科知识(如心内科、骨科),针对具体岗位提升技能。
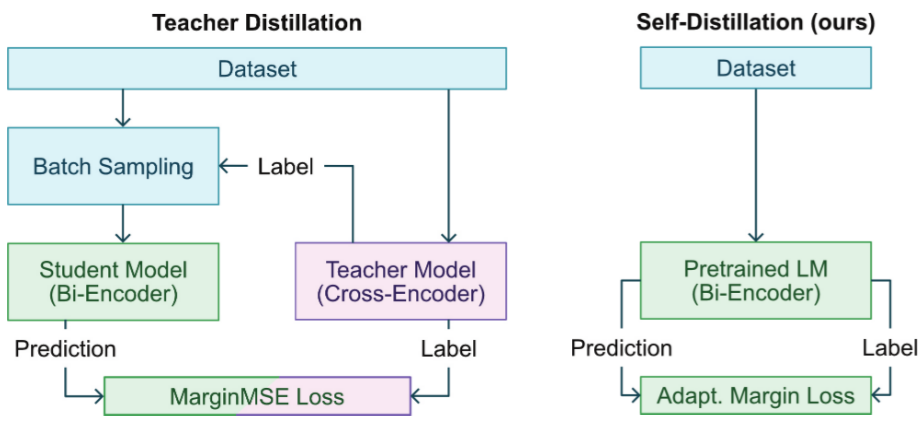
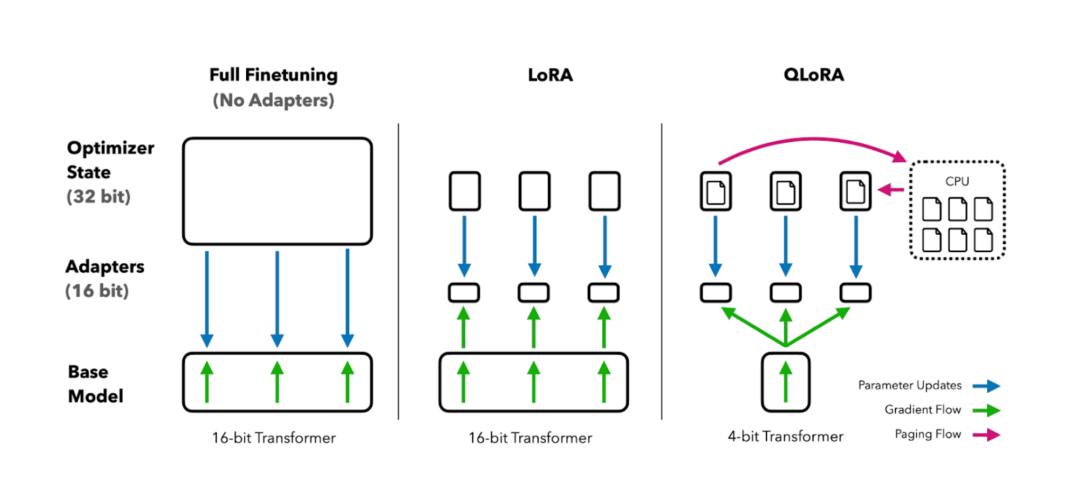
微调(Fine-tuning)是目前将通用大模型训练为垂直大模型比较有效的方式。Adapter微调在预训练模型中插入轻量级模块(如Adapter层),仅训练这些模块,减少参数更新量;而LoRA微调则通过低秩矩阵分解,降低微调时的参数更新量,提升效率。
蒸馏(Knowledge Distillation)
蒸馏(Knowledge Distillation):经验传承(老员工带新人)
让模型“学会传承”,将大模型的经验迁移到小模型。
(1)目标:将大模型(教师)的知识迁移到小模型(学生)。
(2)数据:教师模型的输出(如概率分布、推理链)。
(3)效果:学生模型在保持轻量化的同时,学习到教师的经验(类似“新人快速上手”)。
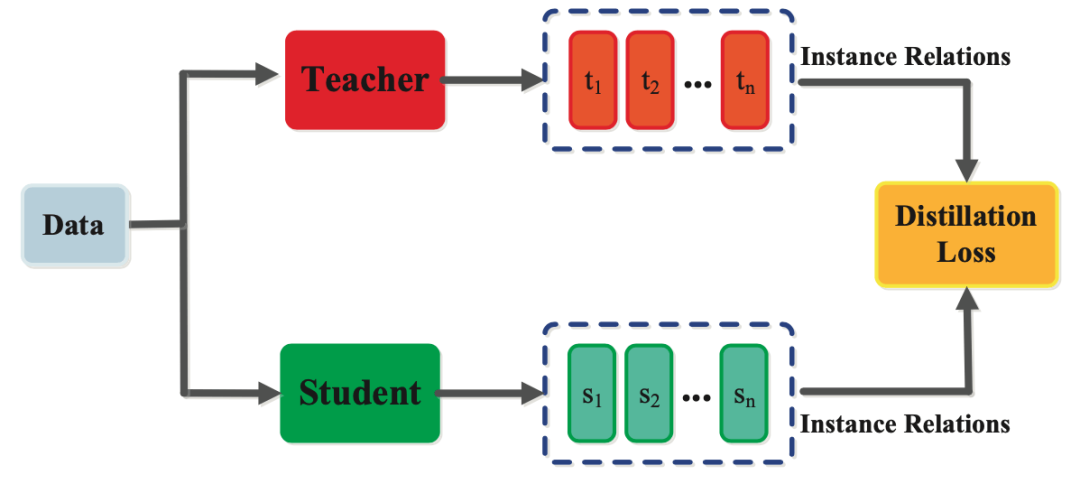
小模型通过蒸馏学习到大模型(教师)的“软标签”(如概率分布)或推理过程。就像老员工将经验传授给新人,而非直接学习书本知识。
大模型虽性能卓越,但部署成本高(如推理延迟、内存占用)。蒸馏通过将大模型(教师模型)的“隐性知识”迁移到小模型(学生模型),实现轻量化部署,同时保留核心能力。这样可以解决AI在资源受限、隐私敏感、领域垂直等场景中的应用。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)