Pytorch中的深度学习模型驱动的可学习小波变换方法
Pytorch环境下一种基于深度学习模型的可学习小波变换(learnable wavelet transforms)方法。 算法运行环境为Python,采用Pytorch深度学习模块,执行基于深度学习模型的可学习小波包变换和基于深度学习模型的离散小波变换框架,能够从数据中自动进行学习并根据目标函数进行优化,附带参考。
折腾过图像处理的朋友应该对小波变换不陌生。传统方法靠人工设计滤波器,但深度学习给了我们新思路——让模型自己学滤波器参数。今天咱们聊聊怎么用PyTorch实现这种可进化的小波变换。
先看个可学习离散小波变换(DWT)的骨架代码:
class LearnableDWT(nn.Module):
def __init__(self, init_low=None, init_high=None):
super().__init__()
self.low = nn.Parameter(torch.randn(4) if init_low is None else init_low)
self.high = nn.Parameter(torch.randn(4) if init_high is None else init_high)
def _decimate(self, x, kernel):
# 二维可分离卷积实现下采样
return F.conv2d(x, kernel.unsqueeze(0).unsqueeze(0), stride=2)
def forward(self, x):
# 低通分支
ll = self._decimate(x, self.low)
# 高通分支
lh = self._decimate(x, self.high)
return ll, lh注意这里的low和high参数都是可学习的。有个细节很有意思——初始化时如果用随机值,模型需要从混沌中自行摸索出有效滤波器。不过实践中更稳妥的做法是用传统小波基(比如db4)的系数作为初始值,相当于给模型一个知识起点。
再来看看更灵活的小波包变换实现。相比固定分解路径的传统方法,可学习版本能自动决定每层分解的最优方向:
class WaveletPacket(nn.Module):
def __init__(self, depth=3):
super().__init__()
self.layers = nn.ModuleList([LearnableDWT() for _ in range(depth)])
def forward(self, x):
outputs = []
current = x
for layer in self.layers:
ll, lh = layer(current)
outputs.extend([lh, ll])
current = ll # 逐层向下分解低频部分
return outputs这里有个梯度传播的隐患:如果直接堆叠多层,反向传播时梯度可能会在逐层下采样的过程中衰减。解决方法是在每层引入跨层连接,或者采用类似UNet的跳跃连接结构。不过这就是另一个话题了。
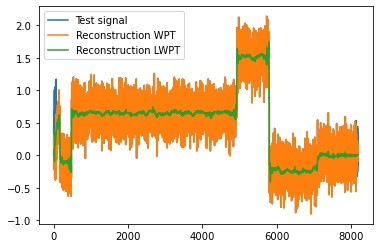
实际训练时,损失函数的设计是核心。以图像重建任务为例:
model = WaveletPacket(depth=3)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for img_batch in dataloader:
coeffs = model(img_batch)
# 重构过程需要自定义逆变换
reconstructed = inverse_transform(coeffs)
loss = F.mse_loss(reconstructed, img_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()有趣的是,当我们在端到端任务(比如分类)中将这些可学习小波层作为特征提取器时,滤波器参数会朝着有利于分类的方向演化。有次实验中发现,经过训练的low-pass滤波器在频域上呈现出类似边缘检测器的特性。
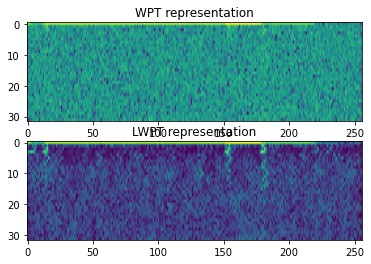
不过要注意数值稳定性。小波变换需要满足双正交条件,可以给损失函数加上正则项:
# 低通滤波器能量约束
energy_loss = torch.abs(torch.sum(self.low**2) - 1.0)
loss += 0.1 * energy_loss最后提个醒:别用普通卷积层直接替代小波层。虽然结构相似,但小波变换特有的下采样方式和滤波器间的数学约束才是其精髓。
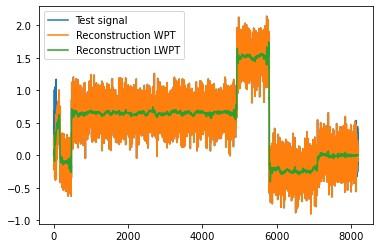
想玩转这些代码的话,推荐看看Wei Xiang的《Deep Learning for Wavelet Transform》和GitHub上那个标星800+的pytorch-wavelets库,里头的可微分实现比咱们这个demo更完备。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)