强化学习做目标检测(通俗原理+结合案例+代码分析)
强化学习做目标检测(结合案例+代码分析)
什么是目标检测?
目标检测(Object Detection)的任务是在原始图像中找出感兴趣的目标, 具体分为两项工作:
- 找出目标"在哪里",即对目标物体定位,目前常用的方法是用矩形框标定。
- 判断目标"是什么",即进行分类(Classification),输出其类别。
目标检测为什么可以用强化学习来做?
目标检测目前普遍是用深度学习来做的,检测性能取决于特征提取网络的好坏,所以基于深度学习的目标检测方法几乎都在卷特征提取网络的设计。
强化学习的出现为目标检测问题提供了新的思路,它将目标检测问题看成一系列控制问题:强化学习具有强大的决策能力,它可以指导当前矩形框采取一个最合适的动作(平移或者伸缩)去靠近目标,经过多次迭代之后,矩形框就移动到了目标的位置。
我用强化学习的方法实现了对工业零件的检测,展示一下结果:

强化学习的建模
那么如何实现这个方法呢?强化学习有三个要素,状态(state)、动作(action)、奖励(reward), 我们需要根据不同的场景对这三个要素进行定义,建立模型。
状态建模
状态是智能体(agent)“眼中的世界”, 由不同特征信息构成,智能体会用这些信息来决定下一步做什么,所以我们在状态建模过程中要考虑有哪些特征信息会对决策有影响。
在目标检测中,我们通常把矩形框区域的图像特征作为当前状态,具体做法是将矩形框区域的图像从原始图像中裁剪出来,然后输入到预训练的卷积神经网络中,得到其特征向量,我这边用的是3层VGG。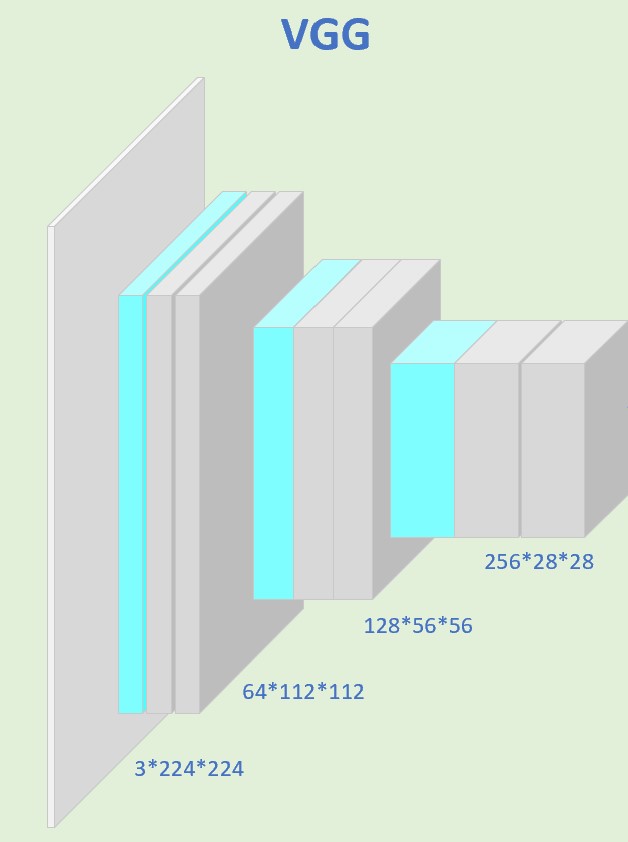
动作建模
动作的意义在于使智能体在不同状态进行切换、尝试,这样才有可能找到目标状态。所以设计的动作理论上要能够使智能体到达任意一种状态。
在目标检测中,动作主要包含平移、缩放、终止这三类动作,矩形框用左上角和右下角的顶点表示,部分代码如下:
if action == 0: # 左移
if self.current_box[0]-step_stride >= 0:#如果没有超过边界
self.current_box[0] -= step_stride
self.current_box[2] -= step_stride
elif action == 4: # 等比例压缩
dx = (self.current_box[2]-self.current_box[0])*0.1/2.0
dy = (self.current_box[2]-self.current_box[0])*0.1/2.0
self.current_box[0] += dx
self.current_box[2] -= dx
self.current_box[1] += dy
self.current_box[3] -= dy
奖励函数设计
奖励可以把好的状态和不好的状态区分开来,进而引导智能体向着好的状态靠近。所以在设计奖励函数时,我们要考虑可以用哪些指标来定义状态的好坏。
在目标检测当中,我们常用iou这个指标来衡量矩形框的精度。
如果当前的iou比上一时刻的值要大,说明当前矩形框更接近目标,那就给一个奖励+1,反之则为-1。
def reward_function(self,done):
reward = 0
#iou
iou = self.compute_iou()
if done == False: #如果还没到最后一步
if iou < iou_done_th:
d_iou = iou - self.last_iou #计算调整前后iou之差
if d_iou > iou_step_th:
reward1 = reward_iou_step
elif d_iou < -iou_step_th:
reward1 = -reward_iou_step
else :
reward1 = 0
reward += reward1
else:
reward += reward_done
done = True
else:
if iou > iou_done_th:
reward += reward_done
elif iou < iou_done_th-0.1: #如果iou<0.5,认为检测不成功
reward += -reward_done
else:
reward += 0.5*reward_done
self.last_iou = iou
return reward,done
DQN网络
在定义了状态、动作、奖励之后,我们可以用探索与利用策略产生经验(experience), 送入强化学习网络中进行训练。经典的强化学习网络有PPO、TD3、DQN系列等。我这边用的是DQN网络,DQN使用神经网络训练拟合最优Q函数,它告诉了我们在当前状态下采取哪个动作价值最大。常用的模型结构是先用3层卷积提取图像特征,最后使用2个线性层进行预测。
class DQN(nn.Module):
def __init__(self, num_actions):
super(DQN, self).__init__()
self.features = nn.Sequential(
# 第一层卷积块
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第二层卷积块
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 第三层卷积块
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(256 * 28 * 28, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(4096, num_actions), # 输出每个动作的Q值
)
训练
我这边用了500张图片构建数据集,包含5种零件,各100张。每张图片训练40步,每次模型优化的batch_size是100,每1000步更新一次target_net的网络参数。
def train(env, agent):
for episode in range(num_episodes):#进入一个周期
#初始化
state = env.reset()
done = False
total_reward = 0
step = 0
while not done:
state_temp = state.unsqueeze(0)
step += 1
if step >= num_step:
done = True
#收集经验并更新模型
action = agent.select_action(state_temp)
next_state, reward, done = env.step(action,done)
env.draw_block(reward, episode*num_step+step)
agent.memory.push(state,action,reward,next_state,int(done))
state = next_state
total_reward += reward
agent.optimize_model()
if episode % target_update == 0:#更新目标网络参数
agent.update_target_net()
env.get_new_pic(episode+1)
训练结果
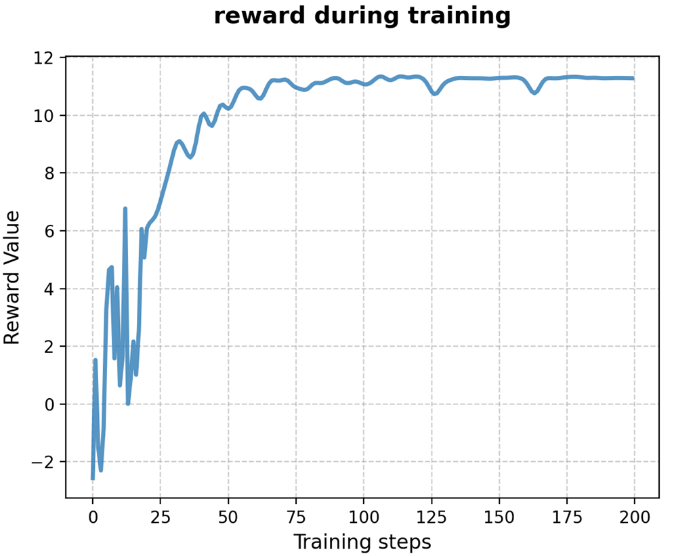
训练结束后,保存模型参数,并绘制奖励变化曲线图。从曲线图中可以看出,在训练初期奖励呈上升的趋势,证明训练的模型也越来越好。到了中后期,奖励上升趋势减缓并逐渐收敛到11左右,说明模型最后达到了稳定。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)