自回归统一建模的原生多模态大模型
摘要:自回归多模态大模型采用"下一个token预测"技术,将文本、图像、视频等统一编码为离散token进行联合训练,实现跨模态理解与生成。代表模型包括智源Emu3、北大VARGPT等,在图像生成、视觉问答等任务表现优异。该技术优势在于参数共享和端到端处理,但面临计算效率低、数据需求大等挑战。应用涵盖机器人、数字人生成、AI搜索等领域,是迈向AGI的重要路径,仍需在训练效率等方面
·
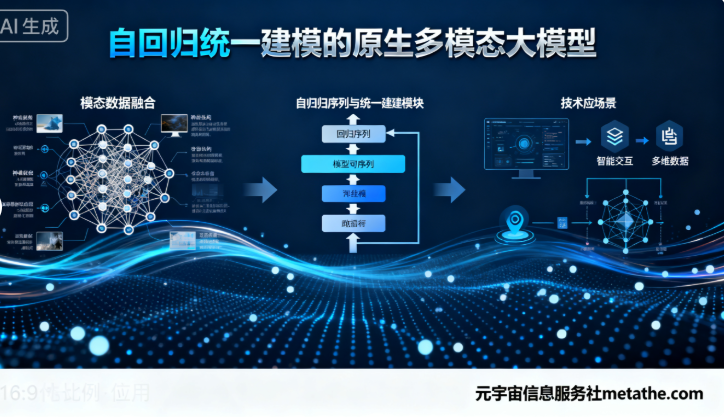
“自回归统一建模的原生多模态大模型”是一种基于自回归(Autoregressive)技术路线,从设计之初便原生融合多模态数据(如文本、图像、视频、音频)的大模型,其核心特征在于通过统一框架实现跨模态的深层关联、理解与生成,无需人工特征工程或后期模块拼接。以下从技术原理、代表模型、优势挑战及应用场景四方面展开说明:
技术原理
- 自回归统一建模:以“下一个token预测”为核心,将多模态数据(如文本、图像、视频)编码为离散空间,在混合序列上联合训练Transformer模型。例如,智源研究院的Emu3模型通过自回归技术,将图像、文本、视频统一编码为离散token,在多模态混合序列上从头训练,实现三种模态的统一理解与生成。
- 原生多模态融合:模型架构从设计阶段便支持多模态数据的原生融合,如百度2025年发布的“自回归统一建模的原生多模态大模型”支持语言、图像、视频、音频的统一建模,可同时处理任意模态的理解与生成,并构建了面向大模型的奖励系统,为多环境多任务场景提供强化学习信号。
代表模型
- Emu3(智源研究院):全球首个基于自回归路线的原生多模态世界模型,参数量80亿,通过“下一个token预测”实现视频、图像、文本的统一理解与生成,性能超越Stable Diffusion SDXL、LLaVA等主流模型,在图像生成、视觉语言理解、视频生成任务中表现优异。
- VARGPT(北大):基于自回归框架,通过“next-token”实现视觉理解(如视觉问答),通过“next-scale”实现视觉生成,统一了视觉理解与生成任务,支持混合模态输入输出。
- OneCAT:采用纯解码器架构,结合自回归机制,无需外部视觉编码器或扩散模型,通过多尺度生成机制实现高效图像生成,支持语言、视觉理解与生成的统一处理。
- 百度文心大模型:新一代文心大模型基于该技术框架,在各模态任务上显著提升,支持广泛场景应用,并通过奖励系统提升并发能力与响应速度。
优势与挑战
- 优势:参数共享实现跨模态关联,避免模块间信息损失;支持端到端的多模态推理与生成;架构简洁利于产业化(如智源Emu3开源预训练模型与SFT代码,推动社区研究)。
- 挑战:自回归生成需按顺序进行,限制并行计算速度;长期依赖问题(难以捕捉序列远距离依赖);训练数据规模与算力需求大(如Emu3语言数据占比小导致语言能力暂弱)。
应用场景
- 基础科研:如多模态世界模型(Emu3)支持机器人大脑、自动驾驶、多模态对话与推理。
- 工业应用:数字人生成(如高拟真唇形驱动、剧本智能创作)、AI搜索引擎(动态工具调用与反思机制)、自动驾驶横纵联合控制。
- 内容生成:图像/视频生成(如VARGPT的多样化风格图像生成)、文本到多模态的指令遵循(如OneCAT的图像编辑与生成)。
综上,自回归统一建模的原生多模态大模型通过自回归技术与原生多模态融合,推动了多模态AI从“模块化组合”向“端到端统一”的范式转变,是通往通用人工智能(AGI)的关键技术路径之一,但仍需在数据规模、算力效率、长期依赖等问题上持续突破。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)