上海交通大学数据结构课程课件全套
htmltable {th, td {th {pre {简介:数据结构是计算机科学基础,涉及数据存储与操作的高效性。上海交通大学的数据结构课程深入讲解了包括数组、链表、栈、队列、树、图、哈希表在内的数据结构,并介绍排序和查找算法、算法复杂度分析,为学生提供理论和实践基础,提升解决复杂问题的编程能力。

简介:数据结构是计算机科学基础,涉及数据存储与操作的高效性。上海交通大学的数据结构课程深入讲解了包括数组、链表、栈、队列、树、图、哈希表在内的数据结构,并介绍排序和查找算法、算法复杂度分析,为学生提供理论和实践基础,提升解决复杂问题的编程能力。 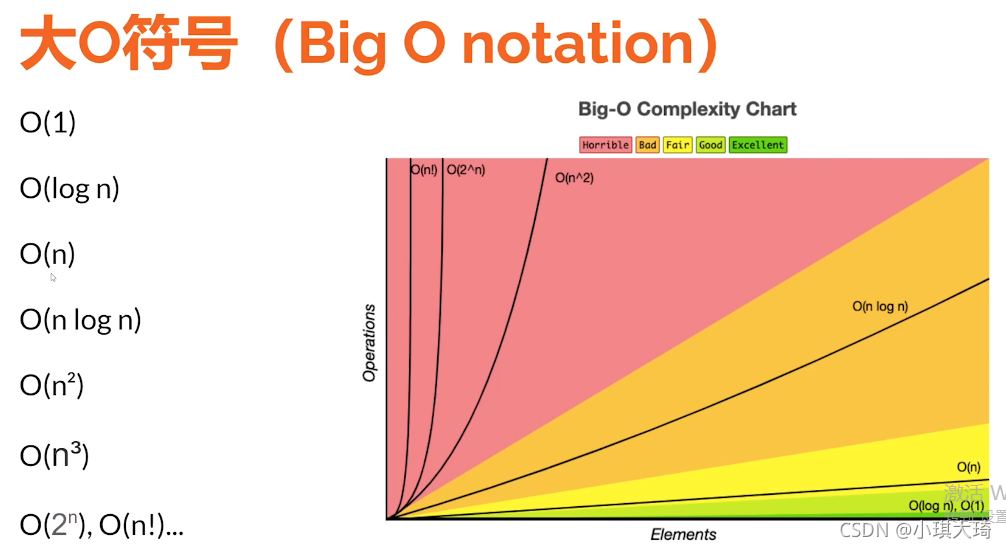
1. 数据结构核心概念及应用
数据结构是计算机存储、组织数据的方式,它决定了数据处理的效率。了解数据结构核心概念,能够帮助我们深入理解计算机科学的基础,进而高效利用数据结构解决实际问题。本章主要介绍数据结构的基本概念、分类以及它们在现代软件开发中的应用。
1.1 数据结构基本概念
数据结构由数据元素及其关系组成,包括了数据的逻辑结构和存储结构。逻辑结构指的是数据元素之间的逻辑关系,如线性关系和非线性关系;存储结构则是数据及其关系在计算机中的物理表示,如顺序存储和链式存储。
1.2 数据结构的分类
数据结构按照不同的标准有不同的分类方法。按照逻辑结构可以分为线性结构和非线性结构。线性结构中每个元素最多只有一个前驱和一个后继,如数组和链表;非线性结构包括树、图等复杂的数据结构。
1.3 数据结构的应用
数据结构在软件开发的各个领域都有着广泛的应用。在数据库系统中,树结构用于实现索引;在缓存机制中,哈希表大大提高了数据检索速度;图结构在社交网络和网络路由中有重要应用。掌握数据结构,对于提升软件性能和处理复杂数据集至关重要。
2. 各类基础数据结构特性与操作
2.1 线性数据结构
2.1.1 数组与链表
数组是一种基础的线性数据结构,通过连续的内存空间存储一系列相同类型的数据。数组的优点是可以通过索引快速访问任何一个元素,其访问时间复杂度为O(1)。然而,数组在插入和删除元素时可能需要移动大量元素,因此在这些操作上的时间复杂度为O(n)。
链表由一系列节点组成,每个节点包含数据和指向下一个节点的指针。链表的优点在于插入和删除操作非常高效,只需改变指针的指向即可,时间复杂度为O(1)。但链表访问任意元素需要从头节点开始遍历,其时间复杂度为O(n)。
数组与链表的对比表格:
| 操作 | 数组 | 链表 |
|---|---|---|
| 访问元素 | O(1) | O(n) |
| 插入元素 | O(n) | O(1) |
| 删除元素 | O(n) | O(1) |
| 内存占用 | 固定 | 动态 |
| 使用场景 | 随机访问多的场景 | 经常插入删除的场景 |
以下是一个简单的链表节点定义和插入操作的代码示例:
struct Node {
int data;
struct Node* next;
};
void insertNode(struct Node** head, int data) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->data = data;
newNode->next = *head;
*head = newNode;
}
在这个例子中, insertNode 函数创建一个新节点,并将其插入到链表的头部。这是链表插入操作中最高效的一种,因为它不需要遍历链表。
2.1.2 栈和队列的操作及应用场景
栈是一种后进先出(LIFO)的数据结构,只允许在一端进行插入和删除操作。栈的 push 操作将元素添加到栈顶,而 pop 操作则移除栈顶元素。 peek 操作可以查看栈顶元素但不移除它。
队列是一种先进先出(FIFO)的数据结构,允许在一端添加元素(入队),而在另一端移除元素(出队)。队列通常用于任务调度和处理数据流。
#include <stdio.h>
#include <stdlib.h>
typedef struct Stack {
int top;
unsigned capacity;
int* array;
} Stack;
// 创建栈
Stack* createStack(unsigned capacity) {
Stack* stack = (Stack*)malloc(sizeof(Stack));
stack->capacity = capacity;
stack->top = -1;
stack->array = (int*)malloc(stack->capacity * sizeof(int));
return stack;
}
// 入栈操作
void push(Stack* stack, int item) {
if (stack->top == stack->capacity - 1) {
return; // 栈已满,无法添加
}
stack->array[++stack->top] = item;
}
// 出栈操作
void pop(Stack* stack) {
if (stack->top == -1) {
return; // 栈为空,无法删除
}
stack->top--;
}
// 查看栈顶元素
int peek(Stack* stack) {
if (stack->top == -1) {
return INT_MIN; // 栈为空
}
return stack->array[stack->top];
}
// 销毁栈
void destroyStack(Stack* stack) {
free(stack->array);
free(stack);
}
以上代码定义了一个简单的栈结构以及基本操作的实现。可以看到,栈操作的核心在于维护一个顶部索引 top ,以及在数组的末尾进行插入和删除操作。在使用栈之前,总是先调用 createStack 来初始化栈,而在完成操作后,使用 destroyStack 来释放资源。
3. 树结构在数据管理和搜索中的应用
3.1 二叉树基础
二叉树是一种特殊的树形数据结构,其中每个节点最多有两个子节点,通常被称为左子节点和右子节点。二叉树结构简单但应用广泛,特别是在数据存储、管理和搜索场景中。
3.1.1 二叉树的性质与遍历方法
二叉树的性质不仅决定了其结构,而且还影响着在各种应用场景中的表现。比如,在二叉搜索树中,任何一个节点的左子树都只包含小于该节点的数,而右子树都只包含大于该节点的数。这个性质使得二叉搜索树在数据查找时非常高效。
遍历是树结构中的一个基本操作,它根据不同的节点访问顺序,可以分为三种主要的遍历方法:
- 前序遍历 (Pre-order Traversal):首先访问根节点,然后递归地进行前序遍历左子树,接着递归地进行前序遍历右子树。
- 中序遍历 (In-order Traversal):首先递归地进行中序遍历左子树,然后访问根节点,最后递归地进行中序遍历右子树。中序遍历在二叉搜索树中可以按顺序访问所有节点。
- 后序遍历 (Post-order Traversal):首先递归地进行后序遍历左子树,然后递归地进行后序遍历右子树,最后访问根节点。
下面是一个简单的二叉树遍历的代码实现,使用Python语言:
class TreeNode:
def __init__(self, value=0, left=None, right=None):
self.val = value
self.left = left
self.right = right
def preorderTraversal(root):
if not root:
return
print(root.val, end=' ')
preorderTraversal(root.left)
preorderTraversal(root.right)
def inorderTraversal(root):
if not root:
return
inorderTraversal(root.left)
print(root.val, end=' ')
inorderTraversal(root.right)
def postorderTraversal(root):
if not root:
return
postorderTraversal(root.left)
postorderTraversal(root.right)
print(root.val, end=' ')
# 构建一个简单的二叉树进行遍历
root = TreeNode(1)
root.right = TreeNode(2)
root.right.left = TreeNode(3)
print("Pre-order Traversal:")
preorderTraversal(root)
print("\nIn-order Traversal:")
inorderTraversal(root)
print("\nPost-order Traversal:")
postorderTraversal(root)
这个例子中,我们定义了一个 TreeNode 类来表示树节点,并实现了三种遍历方法。在遍历过程中,我们按照前序、中序和后序的规则访问每个节点,并打印出节点的值。
3.1.2 二叉搜索树的应用场景
二叉搜索树由于其在搜索、插入和删除操作上的高效性,在数据库索引、文件系统等领域有着广泛的应用。其基本操作的时间复杂度为O(log n),其中n是树中元素的数量,这使得二叉搜索树成为实现快速查找、插入和删除操作的理想选择。
二叉搜索树的这些操作都是基于其固有的有序性。例如,在搜索操作中,从根节点开始,通过比较节点值,我们可以迅速决定是向左子树还是右子树继续搜索,或者直接找到目标值。
一个二叉搜索树的应用场景示例代码如下:
class BST:
def __init__(self):
self.root = None
def insert(self, val):
self.root = self._insert(self.root, val)
def _insert(self, node, val):
if not node:
return TreeNode(val)
if val < node.val:
node.left = self._insert(node.left, val)
elif val > node.val:
node.right = self._insert(node.right, val)
return node
def search(self, val):
return self._search(self.root, val)
def _search(self, node, val):
if not node:
return False
if val == node.val:
return True
elif val < node.val:
return self._search(node.left, val)
else:
return self._search(node.right, val)
# 创建一个二叉搜索树实例
bst = BST()
bst.insert(5)
bst.insert(2)
bst.insert(8)
bst.insert(1)
# 搜索操作
print(bst.search(2)) # 输出:True
print(bst.search(7)) # 输出:False
在这个例子中,我们定义了一个 BST 类来表示二叉搜索树,并实现了插入和搜索操作。我们创建了一个二叉搜索树实例,并插入了几个值,然后执行了搜索操作来验证插入值是否在树中。
3.2 高级树结构
3.2.1 B树、B+树和红黑树的原理及优化
随着数据量的增加,单节点存储能力有限和树的高度持续增加成为二叉搜索树性能瓶颈。为了优化这些性能,出现了多种多样的自平衡二叉搜索树的扩展,例如B树、B+树和红黑树。这些树结构能够在磁盘存储和大规模数据管理方面提供更好的性能。
B树(B-Tree)
B树是一种自平衡的树,它允许每个节点存储多个键值对,从而减少了树的高度,并且可以有效减少磁盘I/O操作的次数。B树广泛应用于数据库和文件系统中。B树的特性包括:
- 所有叶子节点都在同一层。
- 节点可以有多个子节点,最多有M个子节点,其中M是树的阶。
- 节点中的键将数据项排序,并将它们分成子树,每个子树中的键都小于它右子树中的键。
B+树(B+-Tree)
B+树是B树的一种变种,它将数据全部存储在叶子节点上,非叶子节点仅用于索引。由于索引和数据分离,B+树相比B树有以下优势:
- 磁盘读写代价更低。
- 可以进行范围查询。
- 叶子节点形成链表,便于顺序访问和范围查询。
红黑树(Red-Black Tree)
红黑树是一种自平衡的二叉搜索树,它通过在节点中引入颜色(红色和黑色)的概念,确保最长路径不会超过最短路径的两倍,从而保证基本操作的时间复杂度为O(log n)。红黑树的特点包括:
- 每个节点要么是红色,要么是黑色。
- 根节点总是黑色。
- 所有叶子节点都是黑色。
- 如果一个节点是红色,那么它的子节点必须是黑色。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
下面是红黑树的简化实现代码段,主要展示节点插入的过程:
class Node:
def __init__(self, data, color="RED"):
self.data = data
self.color = color
self.parent = None
self.left = None
self.right = None
class RedBlackTree:
# ... 省略其他函数的实现 ...
def insert(self, data):
new_node = Node(data)
# 插入节点的初始化操作
# ... 省略 ...
# 插入后进行调整,以保持红黑树的性质
self.fix_insert(new_node)
def fix_insert(self, node):
# 插入节点后调整红黑树性质的函数实现
# ... 省略 ...
# 红黑树的实际使用
rbt = RedBlackTree()
rbt.insert(10)
rbt.insert(20)
rbt.insert(30)
在这个简化的红黑树插入过程中,我们首先创建了一个新节点并初始化其基本属性,然后将其插入到树中。最后,我们调用 fix_insert 函数来调整树的结构,保证红黑树的性质不被破坏。
3.2.2 堆和优先队列的实现与应用
堆是一种特殊的完全二叉树,其中每个父节点的值都大于或等于其子节点的值(最大堆)或小于或等于其子节点的值(最小堆)。堆通常使用数组来表示,方便实现向上和向下调整操作,保证堆的性质。
堆的基本操作
- 插入 :将新元素添加到堆的末尾,然后通过“上浮”操作调整堆。
- 删除最大或最小元素 :从堆顶删除元素,然后将最后一个元素移动到堆顶,并通过“下沉”操作调整堆。
- 向上调整(上浮) :在插入新元素后进行,确保堆性质不被破坏。
- 向下调整(下沉) :在删除最大或最小元素后进行,以维护堆的结构。
优先队列
优先队列是一种抽象数据类型,它允许插入具有优先级的数据项,并允许删除具有最高优先级的数据项。优先队列通常基于堆实现,其中堆的根节点总是具有最高优先级。
在优先队列中,数据项的优先级通常由其值确定,最小值具有最高优先级的优先队列称为最小优先队列,反之则为最大优先队列。
优先队列的应用包括:
- 作业调度 :操作系统中调度进程,总是优先执行具有最高优先级的进程。
- 事件驱动模拟 :在事件驱动的模拟中,事件根据发生时间被存储在优先队列中。
- 图的最短路径搜索 :如Dijkstra算法中,使用优先队列可以加速搜索过程。
下面是一个最小堆实现的Python代码示例:
class MinHeap:
def __init__(self):
self.heap = []
def insert(self, item):
self.heap.append(item)
self._bubble_up(len(self.heap) - 1)
def _bubble_up(self, index):
parent_index = (index - 1) // 2
if index and self.heap[parent_index] > self.heap[index]:
self.heap[parent_index], self.heap[index] = self.heap[index], self.heap[parent_index]
self._bubble_up(parent_index)
def extract_min(self):
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self._bubble_down(0)
return min_val
def _bubble_down(self, index):
smallest = index
left = 2 * index + 1
right = 2 * index + 2
if left < len(self.heap) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self.heap) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != index:
self.heap[index], self.heap[smallest] = self.heap[smallest], self.heap[index]
self._bubble_down(smallest)
# 使用最小堆
min_heap = MinHeap()
min_heap.insert(2)
min_heap.insert(5)
min_heap.insert(1)
print(min_heap.extract_min()) # 输出:1
print(min_heap.extract_min()) # 输出:2
在这个代码示例中,我们定义了 MinHeap 类来表示最小堆,并实现了插入和删除最小元素的方法。通过调用这些方法,我们可以看出最小堆的性质始终保持,每次删除的都是堆中的最小元素。
4. ```
第四章:图数据结构及其遍历算法
4.1 图的基本概念与分类
4.1.1 有向图与无向图的特性
有向图和无向图是图论中的两种基本图类型。在有向图中,边是有方向的,从一个顶点指向另一个顶点;而在无向图中,边是没有方向的,连接两个顶点的边可以双向通行。
无向图
无向图由一组顶点和一组无方向边组成。在无向图中,任意两个顶点之间的边都是相互的,即如果顶点A和顶点B之间有一条边连接,那么顶点B和顶点A之间也有一条边连接。例如社交网络中的朋友关系就可以用无向图来表示,因为如果A是B的朋友,那么B也是A的朋友。
有向图
有向图由一组顶点和一组有方向的边组成,每条边连接一对顶点,通常表示为(A,B),意味着存在从顶点A到顶点B的方向。在有向图中,A到B和B到A是不同的路径,这种图适合表示各种依赖关系,比如网页链接关系,A网页指向B网页与B指向A是完全不同的。
4.1.2 图的存储结构:邻接矩阵与邻接表
图可以用多种方式存储,其中最常用的是邻接矩阵和邻接表。
邻接矩阵
邻接矩阵是一种二维数组,其中的元素表示顶点之间的连接关系。如果顶点i和顶点j之间有边,那么矩阵中的元素matrix[i][j]通常设置为1,否则为0。在无向图中,邻接矩阵是对称的,而有向图的邻接矩阵则不一定。
邻接矩阵适合用于顶点数量较少的情况,因为它需要的空间复杂度为O(V^2),其中V是顶点的数量。邻接矩阵的一个优点是可以快速判断任意两个顶点之间是否存在边。
邻接表
邻接表是一种链表的组合,通常使用一个数组存储,数组的每个元素是一个链表的头节点,链表存储了指向与该顶点相邻的其它顶点的边。在有向图中,链表存储的是从该顶点出发的边;在无向图中,链表则存储了所有相邻的边。
邻接表的空间复杂度为O(V+E),其中E是边的数量。它比邻接矩阵节省空间,尤其适合存储稀疏图。遍历与某个顶点相连的所有顶点在邻接表中也很容易实现。
表格展示两种存储方式的对比
| 特性 | 邻接矩阵 | 邻接表 |
|---|---|---|
| 空间复杂度 | O(V^2) | O(V+E) |
| 边查询 | O(1) (无向图) O(1) (有向图) | O(V) (无向图) O(1) (有向图) |
| 存储密度 | 密集图适合 | 稀疏图适合 |
| 实现复杂度 | 实现简单 | 实现相对复杂 |
| 动态变化支持 | 较差,增加顶点或边需要重新分配 | 较好,动态添加顶点和边方便 |
4.2 图的遍历与搜索算法
4.2.1 深度优先搜索(DFS)与广度优先搜索(BFS)
图的遍历主要是指访问图中的每个顶点一次且仅一次。深度优先搜索和广度优先搜索是最常用的图遍历算法。
深度优先搜索(DFS)
深度优先搜索是一种用于遍历或搜索树或图的算法。该算法沿着图的分支尽可能深地搜索,直到搜索不到任何分支,然后再回溯到上一个分支的节点上继续搜索。它使用递归或栈实现。
def DFS(graph, node, visited):
if node not in visited:
print(node)
visited.add(node)
for neighbour in graph[node]:
DFS(graph, neighbour, visited)
visited = set()
graph = {'A': ['B', 'C'], 'B': ['D', 'E'], 'C': ['F'], 'D': [], 'E': [], 'F': []}
DFS(graph, 'A', visited)
在上述Python示例中,定义了一个图的邻接表表示,并使用深度优先搜索遍历所有顶点。输出将会是按照深度优先搜索顺序的顶点序列。
广度优先搜索(BFS)
广度优先搜索是一种遍历或搜索树或图的算法,它从根节点开始,逐层向外扩展,直到所有可达节点均被访问。广度优先搜索常使用队列实现。
from collections import deque
def BFS(graph, start):
visited = set()
queue = deque([start])
while queue:
vertex = queue.popleft()
if vertex not in visited:
print(vertex, end=' ')
visited.add(vertex)
queue.extend(set(graph[vertex]) - visited)
graph = {'A': ['B', 'C'], 'B': ['A', 'D', 'E'], 'C': ['A', 'F'],
'D': ['B'], 'E': ['B', 'F'], 'F': ['C', 'E']}
BFS(graph, 'A')
在上述Python示例中,使用广度优先搜索遍历图结构,并打印出顶点的访问顺序。输出显示了顶点的访问层次。
4.2.2 最短路径算法:迪杰斯特拉与弗洛伊德
图中顶点之间的路径长度是指路径上边的数量。在加权图中,路径长度也可以定义为所有边的权重之和。最短路径问题是要找到两个顶点之间长度最小的路径。
迪杰斯特拉算法(Dijkstra’s Algorithm)
迪杰斯特拉算法用于加权无向图,它可以找到从单一源点到其他所有顶点的最短路径。该算法适用于没有负权重边的图。
import sys
import queue
class Graph():
def __init__(self, vertices):
self.V = vertices
self.graph = [[] for i in range(vertices)]
def min_distance(self, dist, sptSet):
min = sys.maxsize
for v in range(self.V):
if dist[v] < min and sptSet[v] == False:
min = dist[v]
min_index = v
return min_index
def dijkstra(self, src):
dist = [sys.maxsize] * self.V
dist[src] = 0
sptSet = [False] * self.V
for cout in range(self.V):
u = self.min_distance(dist, sptSet)
sptSet[u] = True
for v in self.graph[u]:
if dist[v[0]] > dist[u] + v[1]:
dist[v[0]] = dist[u] + v[1]
return dist
g = Graph(9)
g.graph = [[1, 4], [0, 4], [0, 3], [2, 1], [1, 1], [6, 4], [7, 2], [6, 3], [7, 2]]
print(g.dijkstra(0))
在上述Python示例中,实现迪杰斯特拉算法来计算从源点顶点0开始的最短路径。输出结果是到其他所有顶点的最短距离。
弗洛伊德算法(Floyd-Warshall Algorithm)
弗洛伊德算法用于找到图中所有顶点对之间的最短路径。该算法适用于包含负权重边的图,但不包含负权重环。
def floyd_warshall(graph):
V = len(graph)
dist = list(map(lambda i: list(map(lambda j: j, i)), graph))
for k in range(V):
for i in range(V):
for j in range(V):
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j])
return dist
graph = [[0, 5, float('inf'), 10],
[float('inf'), 0, 3, float('inf')],
[float('inf'), float('inf'), 0, 1],
[float('inf'), float('inf'), float('inf'), 0]]
print(floyd_warshall(graph))
在上述Python示例中,使用弗洛伊德算法计算图中所有顶点对之间的最短路径。输出结果是一个矩阵,表示从每个顶点到其他所有顶点的最短路径长度。
5. 哈希表及其性能优化
哈希表是一种高效的数据结构,以其常数时间复杂度的平均查找性能而闻名。在本章节中,我们将深入探讨哈希表的基本原理和实现方式,并且探讨如何通过优化哈希表来提升性能。
5.1 哈希表的基本原理与实现
5.1.1 哈希函数的构造与冲突解决方法
哈希函数是哈希表的核心,它将键映射到表中的一个位置。理想的哈希函数应具备高效、均匀分布的特点,以减少哈希冲突。
def hash_function(key, table_size):
"""简单的哈希函数实现"""
return key % table_size
5.1.2 哈希表的动态扩容策略
哈希表在插入元素时可能需要扩容以保持较低的负载因子。负载因子是指已填入哈希表的元素个数与表大小的比值。
def resize_hash_table(hash_table):
"""哈希表扩容"""
old_array = hash_table.array
hash_table.size *= 2
hash_table.array = [None] * hash_table.size
hash_table.count = 0
for item in old_array:
if item is not None:
hash_table.insert(item.key, item.value)
5.2 哈希表的性能优化技巧
5.2.1 负载因子的调整与优化
负载因子是决定哈希表性能的关键因素之一。负载因子过高会增加冲突,过低则浪费空间。调整负载因子的值可基于具体应用场景来决定。
5.2.2 开放寻址法与链表法的比较分析
开放寻址法和链表法是解决哈希冲突的两种主要方法。开放寻址法通过探测解决冲突,而链表法则在每个槽位维护一个链表。每种方法都有其优缺点。
class HashTable:
def __init__(self, size):
self.size = size
self.count = 0
self.array = [None] * size
def insert(self, key, value):
index = hash_function(key, self.size)
while self.array[index] is not None:
if self.array[index].key == key:
self.array[index].value = value
return
index = (index + 1) % self.size
self.array[index] = Item(key, value)
self.count += 1
def search(self, key):
index = hash_function(key, self.size)
while self.array[index] is not None:
if self.array[index].key == key:
return self.array[index].value
index = (index + 1) % self.size
return None
在上面的代码示例中,我们创建了一个简单的哈希表类,并在插入和搜索方法中使用开放寻址法处理冲突。
哈希表是处理快速查找场景的理想选择,但它也伴随着哈希冲突的问题。在本章节中,我们重点介绍了哈希表的基本原理和实现方法,并且讲解了性能优化的技巧。我们通过构造哈希函数和解决冲突的方式,确保了哈希表的高效率。在实际应用中,根据不同的数据特征和访问模式,开发者可以选择适合的哈希函数和冲突处理策略,从而实现更加优化的性能表现。
6. 排序与查找算法详解
6.1 排序算法的分类与比较
6.1.1 简单排序:冒泡、选择与插入
简单排序算法是指那些对小规模数据集效率尚可,且实现相对简单的排序方法。它们包括冒泡排序、选择排序和插入排序。
冒泡排序
冒泡排序的核心思想是通过重复遍历待排序的数列,一次比较两个元素,如果顺序错误就交换它们的位置。这个过程重复进行,直到没有再需要交换的元素,即数列已经排序完成。
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
虽然易于实现,但冒泡排序的平均和最坏情况时间复杂度均为O(n^2),因此不适合大规模数据集的排序。
选择排序
选择排序通过从未排序部分选出最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小(大)元素,以此类推。
def selection_sort(arr):
for i in range(len(arr)):
min_idx = i
for j in range(i+1, len(arr)):
if arr[min_idx] > arr[j]:
min_idx = j
arr[i], arr[min_idx] = arr[min_idx], arr[i]
选择排序的时间复杂度无论最好、最坏和平均情况均为O(n^2),性能表现稳定,但同样不适合大数据集。
插入排序
插入排序的工作方式类似于排序手中的扑克牌。它不断地将新元素插入到已排序的元素序列中,确保插入后的序列依然有序。
def insertion_sort(arr):
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
插入排序在最好的情况下(已排序数据)时间复杂度为O(n),但最坏情况和平均情况的时间复杂度是O(n^2),适用于小规模数据集。
6.1.2 高级排序:快速排序、归并排序与堆排序
高级排序算法在实际应用中更加广泛,它们能更有效地处理大规模数据集,时间复杂度通常为O(nlogn)。
快速排序
快速排序是通过选取一个“基准”元素,将数组分为两部分,一部分都比基准小,另一部分都比基准大,然后递归对这两部分进行快速排序。
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
快速排序在平均情况下的时间复杂度为O(nlogn),但在最坏情况下会退化到O(n^2),这通常发生在选取的基准元素是最大或最小值的时候。
归并排序
归并排序是采用分治策略的典型算法。它将数据分成两半分别排序,然后将结果归并起来。归并操作是将两个或两个以上的有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] < right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
归并排序的稳定性好于快速排序,且在最坏情况下的时间复杂度也是O(nlogn),适合大数据集排序。
堆排序
堆排序是利用堆这种数据结构设计的一种排序算法。堆是一种近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。
def heapify(arr, n, i):
largest = i
l = 2 * i + 1
r = 2 * i + 2
if l < n and arr[i] < arr[l]:
largest = l
if r < n and arr[largest] < arr[r]:
largest = r
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
def heap_sort(arr):
n = len(arr)
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
for i in range(n-1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
heapify(arr, i, 0)
堆排序的时间复杂度同样为O(nlogn),但和归并排序相比,堆排序不会占用额外的内存空间,适合内存空间受限的情况。
6.2 查找算法的实现与应用
6.2.1 顺序查找与二分查找的原理与优化
查找算法用于在数据集合中找到指定元素的位置。最简单的是顺序查找,而对于有序数据集合,二分查找的效率更高。
顺序查找
顺序查找是最简单的查找方法,它对无序或有序的数组均适用。顺序查找从数组的一端开始,逐个检查元素,直到找到所需的元素或遍历完数组。
def sequential_search(arr, item):
for i in range(len(arr)):
if arr[i] == item:
return i
return -1
顺序查找的时间复杂度为O(n),适用于数据量不大的情况。
二分查找
二分查找要求待查找的数据集合必须是有序的。二分查找的基本思想是将数组的中间元素与待查元素进行比较,如果中间元素正好是要查找的元素,则查找过程结束;如果要查找的元素比中间元素大,则在数组的右半部分继续查找;反之则在数组的左半部分查找。
def binary_search(arr, item):
low = 0
high = len(arr) - 1
while low <= high:
mid = (low + high) // 2
guess = arr[mid]
if guess == item:
return mid
if guess > item:
high = mid - 1
else:
low = mid + 1
return -1
二分查找的时间复杂度为O(logn),比顺序查找更高效,但需要数据有序。
6.2.2 哈希查找与平衡二叉树查找
哈希查找
哈希查找适用于需要快速访问元素的场景。哈希表通过哈希函数将元素映射到一个表中,从而实现快速查找。
def hash_table_search(hash_table, item):
return hash_table.get(item, -1)
哈希查找的平均时间复杂度为O(1),但可能会因为哈希冲突导致性能下降。
平衡二叉树查找
平衡二叉树(如AVL树或红黑树)通过树的旋转操作保持树的平衡,使得树的高度最小化,从而保证查找、插入和删除操作的时间复杂度为O(logn)。
class TreeNode:
def __init__(self, key, left=None, right=None):
self.key = key
self.left = left
self.right = right
self.height = 1
# AVL树的平衡因子判断和旋转操作省略
# AVL树查找操作类似二叉搜索树
平衡二叉树查找算法保持了树结构的有序性,适用于查找频繁的场景。
通过上述讨论,我们了解了各种排序和查找算法的特点和应用场景。在实际应用中,开发者需要根据数据集的特点和需求,选择最合适的排序和查找算法。
简介:数据结构是计算机科学基础,涉及数据存储与操作的高效性。上海交通大学的数据结构课程深入讲解了包括数组、链表、栈、队列、树、图、哈希表在内的数据结构,并介绍排序和查找算法、算法复杂度分析,为学生提供理论和实践基础,提升解决复杂问题的编程能力。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 29
29 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)