AI实践:大模型部署、算力测算与硬件选型
前言
这是篇关于本地部署大模型和硬件算力测算实践,在此整理记录分享。
本地部署大模型,有两个基准考虑:
-
部署多少参数的大模型?
-
硬件(显卡)最低要求?
基准1的考量,基于需求和业务。
如果只想要玩玩部署和对话,需求就是:能部署能对话即可。选择最小参数的模型即可。
模型参数是什么? 可通过Hugging Face或魔搭社区查看,这两个在本次部署过程中我都有使用到
国内用户可访问魔搭社区查看相关信息:ModelScope 魔搭社区
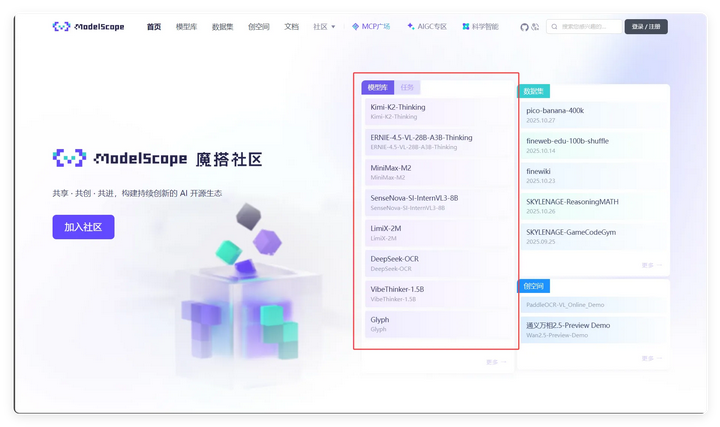
所看到的每个模型名称横杠(-)后面 数字+字母 的大概率就是它的参数。
如:Qwen3-4B。模型是Qwen3系列,4B参数,即40亿的参数训练而成——B是 Billion 的缩写。
到模型库,我们还会看到有大量的开源模型,眼花缭乱,如何选?
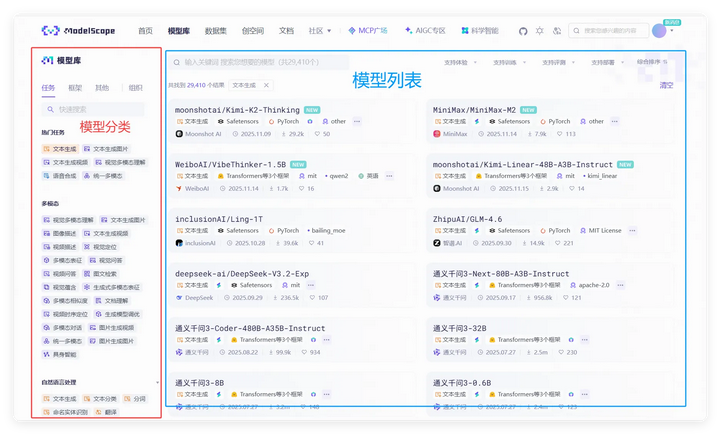
同样基于:能部署能对话 需求,筛选出任意一个文本模型(文本生成标签)—— 视觉模型在同等参数的情况下,通常比文本模型所需资源消耗会更多。
点击一个模型,首先查看对应参数和文件大小。通常,在模型库中未显示参数的模型,就是资源占用(显存GPU、硬盘、内存)是该模型厂商当前模型最强大的一款。如:Kimi-K2, Qwen3-Max
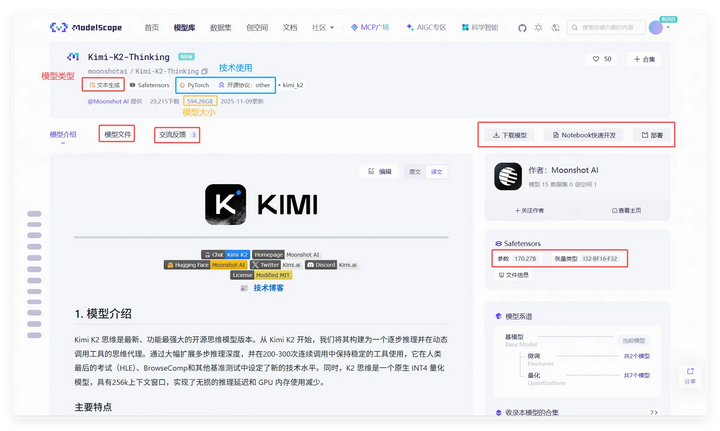
对于硬件资源不足或没有相关硬件,可以选择使用 Google Colab、魔搭在线实例(上图 Notebook快速开发)或选择算力租赁平台(建议选用按量计费)。
Google Colab
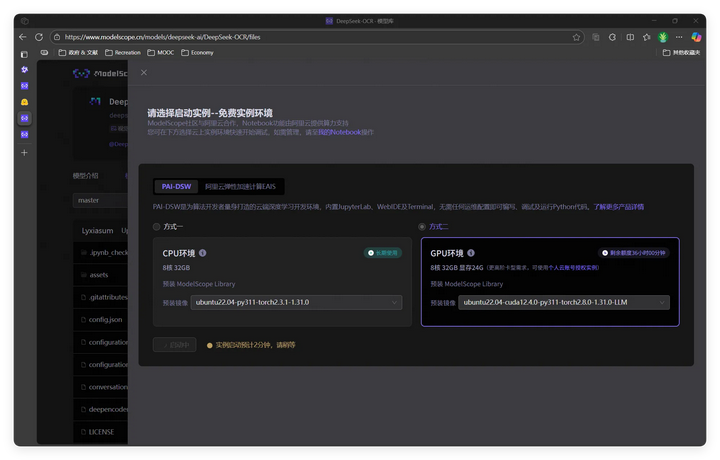
魔搭-在线实例
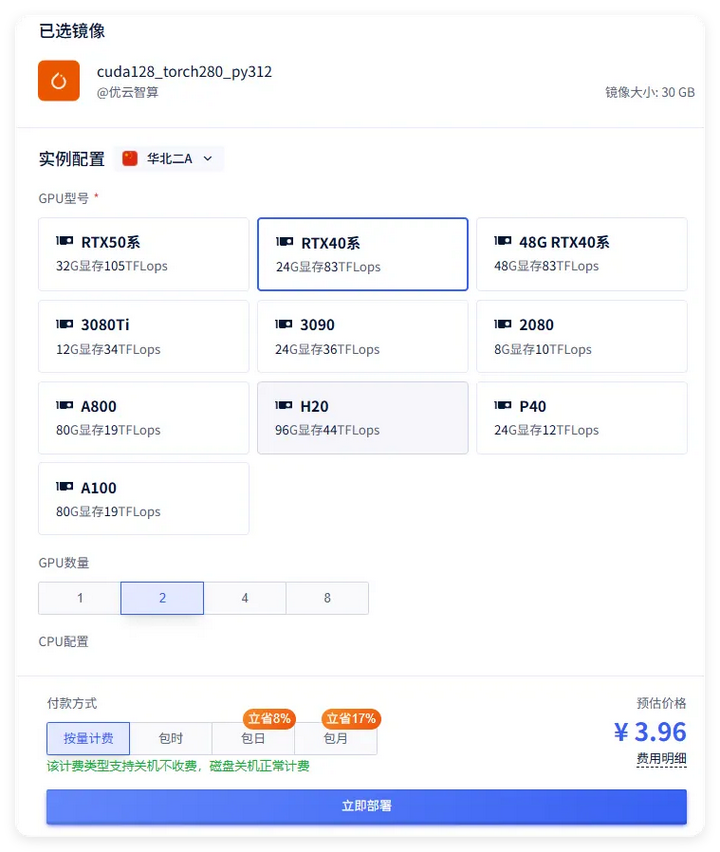
算力租赁
如果是需要从实际业务需求侧出发,验证模型能力,最快速的方法使用网上已经在线部署好的服务或HF(Hugging Face)/ 魔搭社区的在线API进行测试。
但对于较新发布的模型,如前面举例的Kimi-K2,还有本次我所使用的PaddleOCR-VL、DeepSeekOCR就不存在可调用的API,虽然已有在线使用测试,但我的最终目标还有:确定本地部署的硬件配置方案,如该模型需要多少算力(显存)能够启动服务、支撑多少并发量。
本次部署,跟刚选中AI作为职业学习部署不同。
那时(六月初),使用Ollama+Google Colab 真就一键部署一键使用。但使用Colab的过程还是有些坎坷。
这次同样走了这条路:Google Colab —> 魔搭在线实例 —> 算力租赁。
主打一个全免费。算力租赁的免费是因为高校学生认证,优刻得租赁送了20块。我用了两个号也就是40块完成了验证。
在大模型部署完成和业务能力验证后,我发现远不止这么简单。还需要做:能够一键Docker部署,上生产环境使用。这需要我在后面补足的技能。
下面内容,是我在此过程,实践+理论(不断地问AI学习知识点)的详细记录。
说明我在该过程使用AI场景与区分:
-
技术方案、疑问和Bug:Kimi
-
名词解释:元宝DeepSeek

Kimi对话1

Kimi对话2

元宝Deep Seek对话
其中,关于多卡并行和算力计算应该是最长也是思考密集的对话,我会将笔记和对话链接放在 ⌈算力测算⌋ 部份
模型测试
首先是基于业务需求,进行模型选型和测试验证。
我选择了:
-
DeepSeek OCR 7B
-
PaddleOCR-VL 0.7B
-
Qwen3-VL(视觉模型)
-
Qwen3(文本模型)
先通过在线服务进行能力测试,看是否能够满足业务侧需求。
模型下载
大语言模型都能够满足我的业务场景,所以直接测试的是百度飞桨最新的OCR视觉模型。但把官方指导文档看的挺懵,执行顺序和描述一时半会看不懂,尝试了一个早上。
我抱有的希望是,PaddleOCR-VL也能注入提示词,那它应该也可以通过自定义Prompt来决定输出结果吧?但在线测试只有Table(表格)、Text(文本)、Chart(图表)、Formula(公式),应该不是仅限于这些。
官网一查,设置为false 就能定义Prompt了,但模型下载、服务启动后发现没用啊!再一查发现,下面还有一个介绍,仅支持**类型。
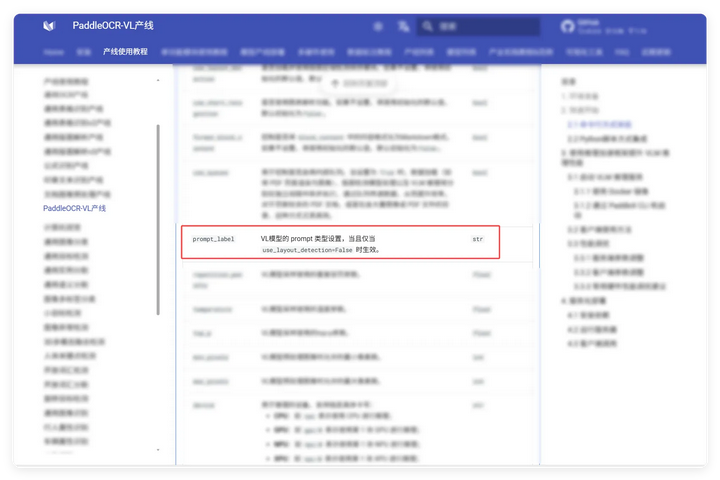
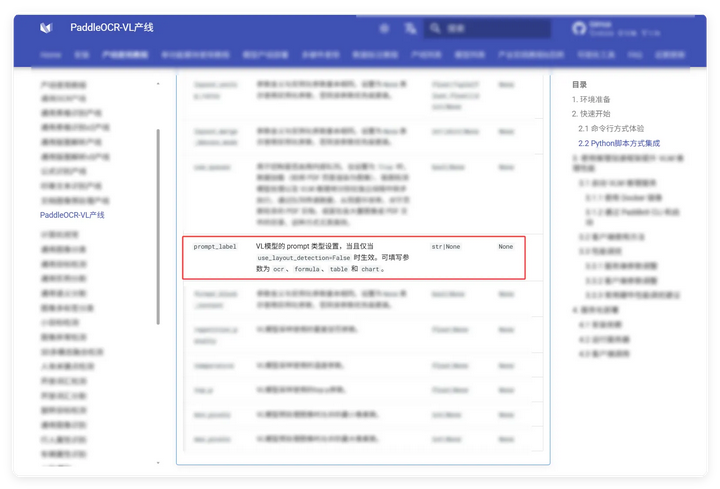
死心了,换Qwen3-VL视觉模型。
当然了,这期间还有老板、产品经理在跟我一起研究这款模型能否满足业务需求,老板发现可能不太够。
这期间,有考虑过也是我们最终敲定的方案:OCR模型+文本模型。两个小模型达到大效果。
DeepSeekOCR
DeepSeekOCR部署起来就废点功夫了。
第一次,忽略掉了 flash-attn 库的安装。这时我还在 Google Colab 中受尽折磨。即使最终安装完成,受限于 T4 TPU 的某个框架是7.5版本,不满足 DeepSeekOCR 模型的8以上,故此作罢。
随后换成魔搭在线实例,到下载 flash-attn 时,出现两个情况:
-
wget 该下载链接非常慢
-
本机下载好后上传到魔搭在线实例文件无效。
一番折腾,用了GitHub镜像仓库 url 变量定义 + wget 下载速度满上 100Mb+ 以上
url="<https://hub.gitmirror.com/https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl>"
wget -O flash_attn-2.7.3.whl "$url"我在这里遇到一个错误,-O参数,应该是文件的原名称,即:
url="<https://hub.gitmirror.com/https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl>"
wget -O flash_attn-2.7.3+cu11torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl "$url"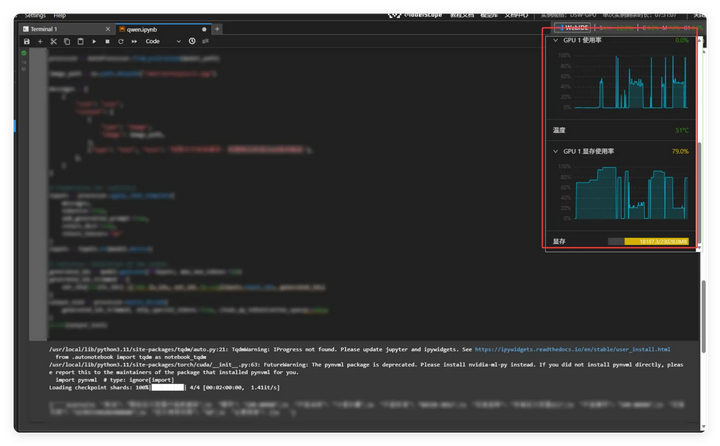
这是一次性使用所占用的GPU资源。
使用Qwen3更是占用多:
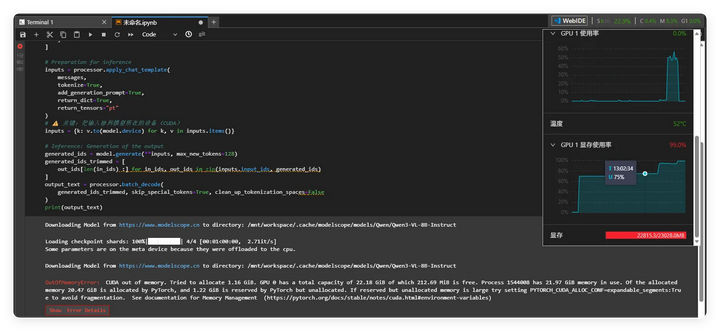
Qwen3-VL(视觉模型)
经过前面模型、依赖下载的折腾后,经验有了。到部署Qwen3-VL快了许多。
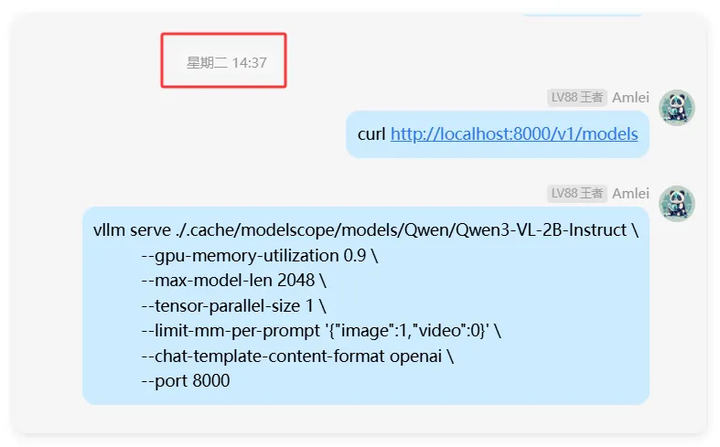
星期二 14:37 分,开始起服务,用的最小2B模型。也是第一次使用VLLM启用服务。
除了最开头提到的Ollama,常用的还有VLLM、SGLang。
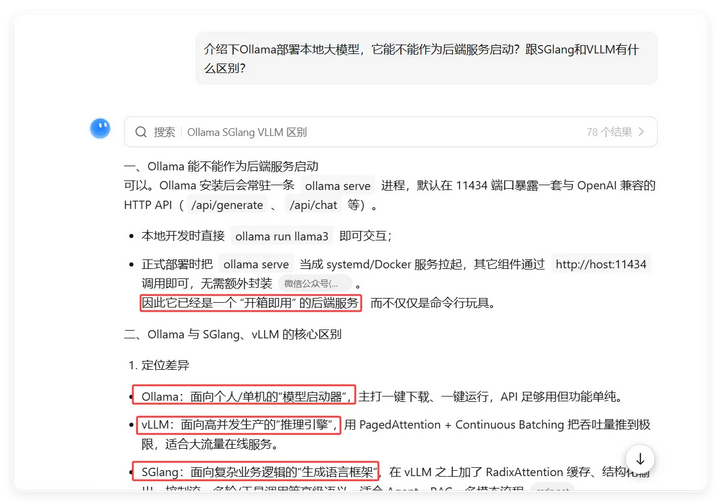
服务跑通,成功对话。日志输出了响应信息、平均Prompt吞吐量:1.3 tokens/s,平均生成吞吐量 9.3 tokens/s。该数据是由于脚本中请求的模型型号跟使用VLLM请求时的不一样,导致该模型不存在的提示。
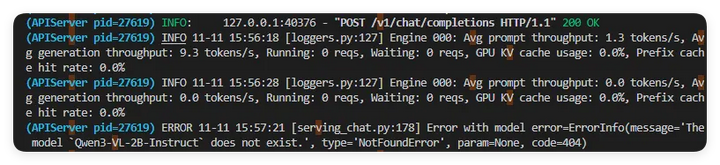
成功设置模型型号再次请求。
-
平均Prompt吞吐量:214.6 tokens/s
-
平均生成吞吐量 52.0 tokens/s
-
一个请求执行
-
GPU KV cache使用率:2.3%
-
Prefix Cache(前缀缓存),逐渐增多,最终到74.9%
KV cache使用率表示,在该神经网络层的计算中,有2.3%被重复使用计算。前缀缓存类似。
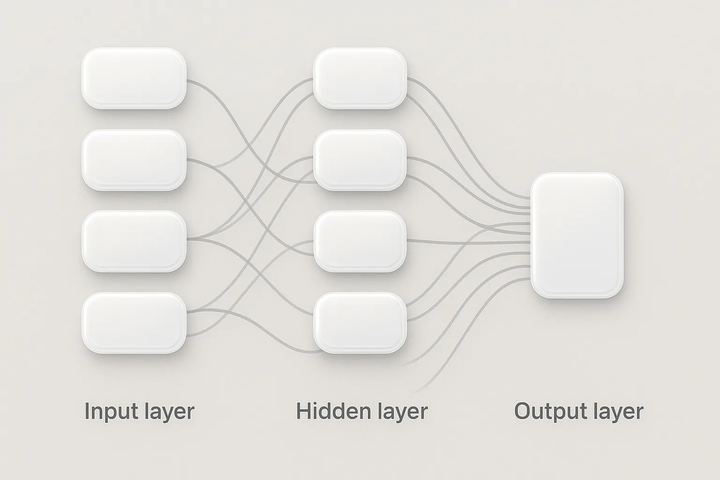
神经网络:包含输入层、输出层,在输入层和输出层中间的层级,被称之为隐藏层,大量的计算就在隐藏层中。
这些数据说明,在该硬件和模型参数的配置上,可以满足使用,但不意味着模型输出的结果符合业务需求。
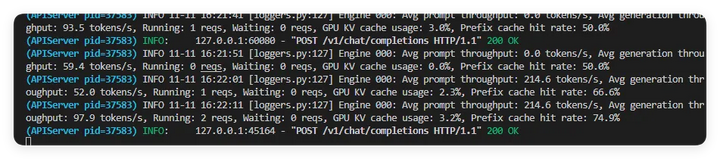
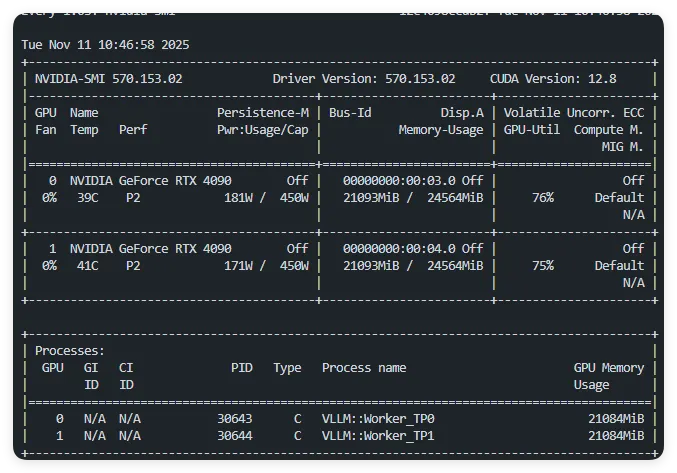
但24G显存卡,即使上了两张共48GB显存依旧无法启动 30B-A3B 的Qwen3视觉模型。
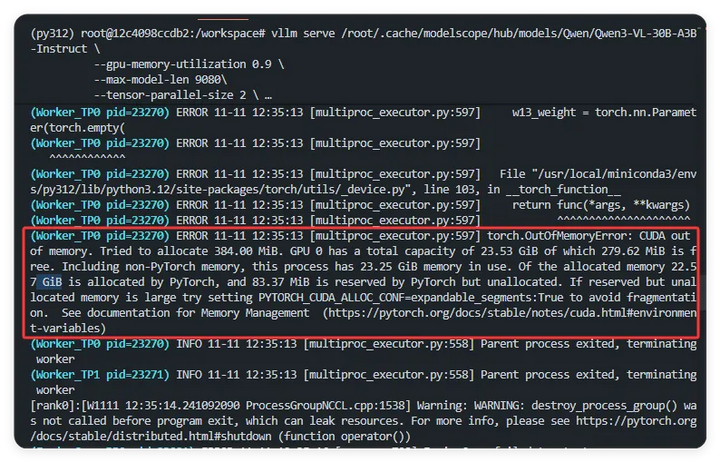
甚至连8B的视觉推理模型也无法启用,最高部署8B-Instruct(常规)模型——可能是当时服务器资源占用多,导致无法启动了。
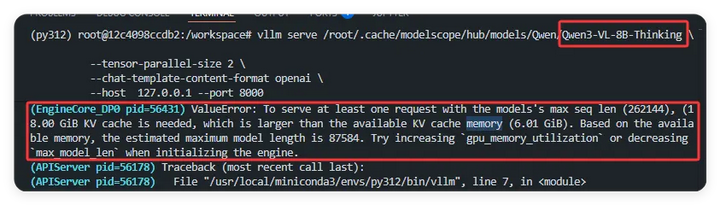
Qwen3(文本模型)
-
0.6B
-
1.7B
-
4B
-
8B
经过测试,最终敲定使用8B的文本模型。
启用大模型服务和能力测试,现在回过头来看很多都是硬件资源不够导致的错误。
在文本模型测试时:无论怎么对话,大模型都无法接收到信息:It looks like your message is empty. How can I assist you today? Feel free to ask questions or share what you need help with! 😊
Token消耗量也反应的特别少。
INFO: 127.0.0.1:50920 - "POST /v1/chat/completions HTTP/1.1" 200 OK (APIServer pid=9997)
INFO 11-13 18:38:42 [loggers.py:127] Engine 000: Avg prompt throughput: 0.8 tokens/s, Avg generation throughput: 17.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0% (APIServer pid=9997)
INFO 11-13 18:38:52 [loggers.py:127] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 0.0%这个可能是我下载的模型文件太多了,导致超出魔搭在线实例提供的硬盘容量大小,连保存文件都做不到了。
实践总结
在部署成功后,起服务调参数等待启动最耗费时间。
节点、模型最大Token限制、多卡GPU资源分配、服务资源分配、模型下载/切换命令等等如此。主要还是经验补足,知识不够
五、六个小时,算力租赁消耗近18块。算上使用朋友的号,差不多10个小时,消耗近29元。
算力测算
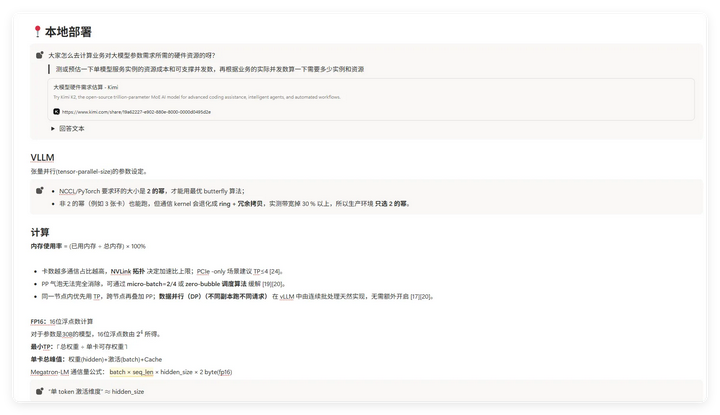
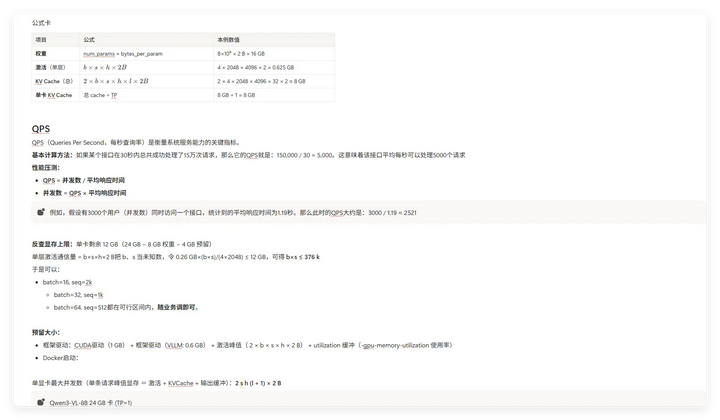
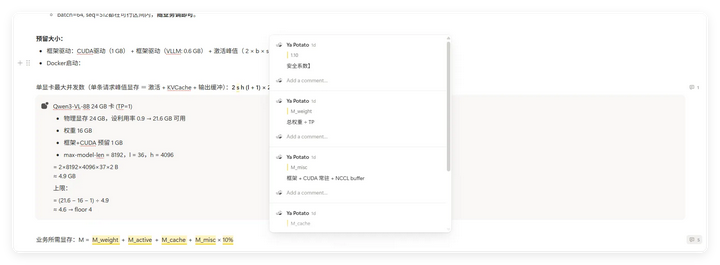

这场计算虽然最终没有使用到,但让我对GPU和大模型之间的关系及使用有了初步了解。
-
大模型服务启用,需要占用多少资源
-
GPU并发策略
-
KV缓存占用、大模型权重、神经网络层数
-
业务支撑
-
控制GPU使用率
-
Token控制单条请求,超过则等待
-
单条请求最大Token量
-
流式/推理输出控制
也是在这期间意识到需要马上学习微调的重要性。业务推动,还有许多技术需要学习和补足。加上时间紧、任务重,更得打起精神努力起来。
做事方法
可改进之处:
-
不要什么都AI,视场景和需求自己动手去做、去算、去测
-
了解业务侧具体需求
-
在线测试模型能力,大概就能知道它能做到什么程度。要是有把不准的,先把官方文档仔细看完。
-
本地模型测试,应从硬件能够满足的最大模型参数逐级向下进行比对。这就跟使用AI进行代码测试一样,有好的干嘛要去用差的一样。
-
做好系统隔离。无论环境还是逻辑。
-
有公司兜底,从最大化效率出发。
-
给自己发消息是一个工作记录缓存站而不是记录站。有点子、收获,写到笔记里,当下就会整理和结构化,需要量化数据的时候也可直接用
-
专业的事,交给专业的人。就像硬件设施配置和成本估算,直接找商家店铺表达需求和场景即可解决。但实际落地,还得自己来测才能知晓。
总结
经由这一次的实践,要说大模型部署有没有难点?现在来看,是没有的,只需要三步就能完成:
-
下载模型
-
起服务
-
测试
熟练的情况下,我10分钟就搞定了这一套,只需要经验。在不熟练,不了解时,各种脑内搏斗。现在还没做的就是资源下载和Docker部署准备,还不清楚如何做,晚点再学习尝试。
现在,我已经开始学习微调。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)