AerialVLN:基于门控循环单元(GRU)和跨模态注意力的无人机视觉语言导航模型
此工作的主要贡献:(1)提出一种无人机视觉语言导航数据集,收集25个不同的城市级环境,涵盖市中心、工厂、公园和村庄等各种场景,包括870多种不同类型的对象,总共8446条飞行路径,每条路径与注释中的3条指令对齐,子路径与子指令对齐,每条指令中最多有83个单词,涉及4470个词汇; (2)提出一种起始基线模型,该模型基于门控循环单元(GRU)和跨模态注意力CMA。
前言
此工作的主要贡献:
(1)提出一种无人机视觉语言导航数据集,收集25个不同的城市级环境,涵盖市中心、工厂、公园和村庄等各种场景,包括870多种不同类型的对象,总共8446条飞行路径,每条路径与注释中的3条指令对齐,子路径与子指令对齐,每条指令中最多有83个单词,涉及4470个词汇;
(2)提出一种起始基线模型,该模型基于门控循环单元(GRU)和跨模态注意力CMA。
一、数据集收集
1.1 收集背景
空中导航与地面导航的不同之处:
(1)空中导航空间行动更大,需要额外考虑上升、下降等动作;
(2)空中的室外环境更大,也更复杂;
(3)空中导航需飞行的路径更长;
(4)在空中飞行必须学会避免被3D空间中的物体卡住。
1.2 收集策略
数据收集过程包含两个主要步骤:路径生成和指令收集:
1.2.1 路径生成的方式:
(1)由人类操作员完成飞行,从而完成采集;
(2)路径生成的输出包括一系列带时间戳的6-DoF多旋翼姿态,然后将路径离散化为元动作,如“左转”和“前进”以进行训练
1.2.2 指令收集的方式:
(1)展示无人机飞行的视频,要求注释器给出自然语言命令;
(2)为了丰富语言多样性并减少偏见,每个视频都由三个注释者分别注释;
(3)为了验证数据质量,所有收集到的指令都由另一组工作人员手动检查。
1.3 数据集结构
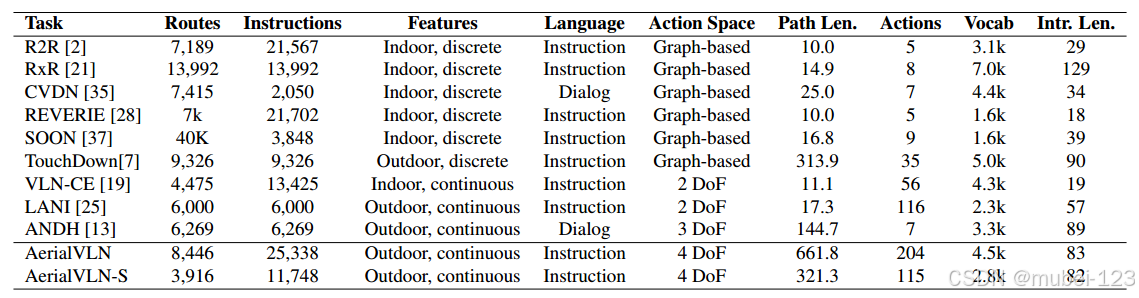
下图展示了AerialVLN/AerialVLN-S数据集和其他数据集的比较:
下图展示了两类数据集AerialVLN和AerialVLN-S的组成:
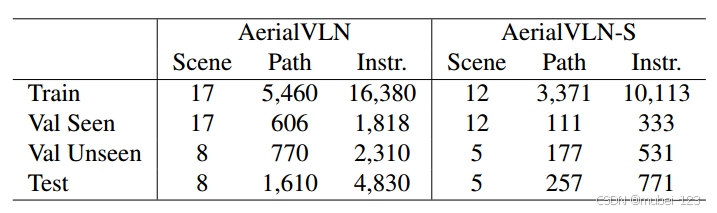
其中两类数据集分别的用处:
(1)使用AerialVLN来解决看不见的环境中的长路径长度3D VLN任务,并专注于长时间视野和稀疏奖励下的动作学习研究;
(2)使用AerialVLN-S作为第一人称视角下一般3D无人机VLN任务的基准。
二、模型整体框架
2.1 任务描述
(1)开始时,代理被放置在初始位置,其中
表示代理的位置,
表示代理方向的俯仰、横滚和偏航部分;
(2)给出自然语言指令,需要代理预测一系列动作;
(3)代理访问其前视图(深度和RGB)。代理需要旋转以获得其他视图;
(4)当代理预测到停止操作或达到预定义的最大操作数时,导航结束。
2.2 模型介绍
模型的整体框架如下图所示:
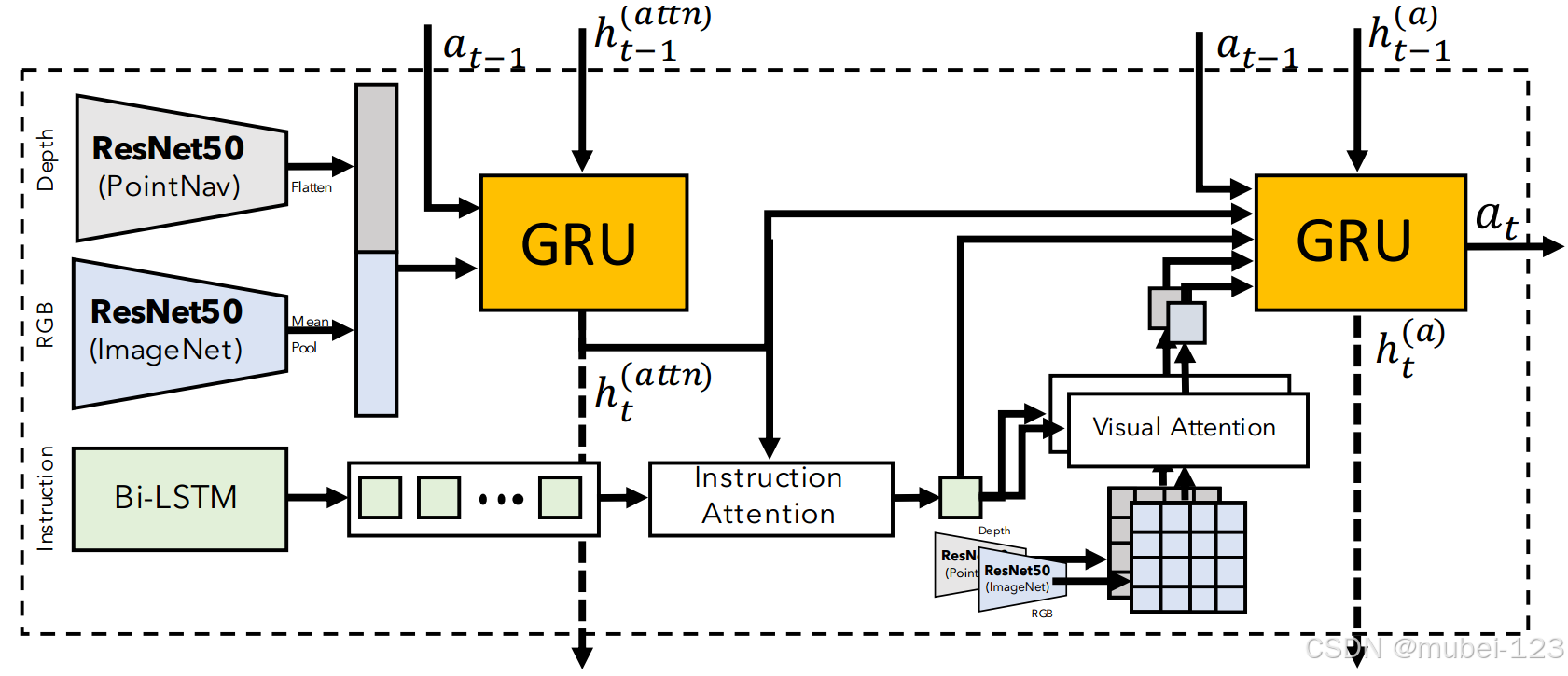
可以看出,主要由以下几部分组成:
(1)深度图像编码器;
(2)RGB图像编码器;
(3)文本编码器;
(4)深度图像注意力模块;
(5)RGB图像注意力模块;
(6)文本注意力模块;
(7)门控循环单元1——跟踪视觉观察;
(8)门控循环单元2——决策制定
三、难点
3.1 跟踪视觉观察
第一个门控循环单元可以用以下方程表示:
![]()
其中:
![]() ,
,为经过ResNet50后的RGB视觉特征,
为将
平均池化后的结果;
![]() ,
,为将经过ResNet50后的深度视觉特征展平后的结果;
![]() ,为先前动作的学习线性嵌入。
,为先前动作的学习线性嵌入。
3.2 决策制定
使用双向LSTM对指令进行编码,并保留所有中间隐藏状态:
![]()
得到后,使用文本注意力模块,计算文本特征:
![]()
同样地,使用RGB图像注意力模块,计算RGB特征:
![]()
同样地,使用深度图像注意力模块,计算深度特征:
![]()
以上的注意力模块均为self-attention点积注意力,对于一个查询![]() ,
,![]() 可以通过下式计算得出:
可以通过下式计算得出:
![]()
其中![]()
得到上述各部分后,第二个循环网络将以上特征的串联作为输入(包括动作编码和第一个循环网络的隐藏状态),并预测动作:
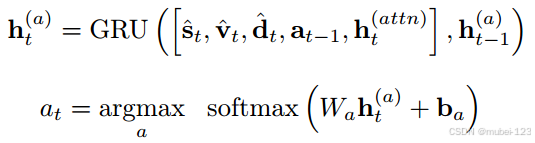
四、总结
目前不懂的地方:
(1)Bi-LSTM的输出和中间隐藏状态分别是什么?
(2)门控循环单元GRU的作用是什么?可否不使用它或用其他组件代替它?
(3)能不能直接使用Transformer来计算交叉注意力?

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)