Spark大数据开发与应用案例(视频教学版)(二十)--第十四章
作者: 余辉微信公众号:辉哥大数据购买地址:读者须知:本书配套示例源码、PPT课件、教学视频与作者答疑服务,购买之后可加粉丝群。
作者信息
作者: 余辉 微信公众号:辉哥大数据
购买地址: 京东、 淘宝、 当当网
读者须知:本书配套示例源码、PPT课件、教学视频与作者答疑服务,购买之后可加粉丝群
本书封面

第14章 Spark实战案例
本章将带你领略Spark在数据分析领域的实战风采。从使用Spark Core进行电影数据与日志数据分析,到使用Spark SQL进行电商数据和金融数据分析,帮助你全方位掌握Spark数据分析方法与技巧。本章是你提升Spark实战能力的绝佳选择。
本章主要知识点:
- Spark Core电影数据分析
- Spark Core日志数据分析
- Spark SQL电商数据分析
- Spark SQL金融数据分析
14.1 Spark Core电影数据分析
在深入探索Spark Core的统计功能时,我们将通过两个紧密相关的案例——用户连续登录超过3天和电影统计,来展示其强大的数据处理能力。为了增强学习的全面性,我们将使用同一组数据集,但分别采用Spark SQL的DSL编程风格和传统的SQL编程风格来实现相同的需求。
在第一个案例中,我们将关注用户的登录行为,利用Spark SQL的DSL风格编写代码,以识别出连续登录超过3天的用户。
而在第二个案例中,我们将转换风格,使用SQL语句对电影数据进行统计分析,如计算各类电影的评分分布和受欢迎程度。
通过这两种不同的实现方式,读者不仅能够复习Spark SQL的两种编程风格,还能更深入地理解如何在不同场景下灵活运用Spark Core进行数据处理和统计分析。
14.1.1 表格及数据样例
为了让读者直观了解本次实战案例的数据和字段类型,这里将数据和字段类型以图片和表格形式进行展示。其中,图14-1所示的“用户登录表和电影评分表”是本次实验的两组数据的表格和字段。图14-1所示的“用户登录表数据”是以CSV文件进行存储的,文件名为loginUser.csv。图14-2所示的电影评分表数据是以JSON文件进行存储的,文件名为rating.json。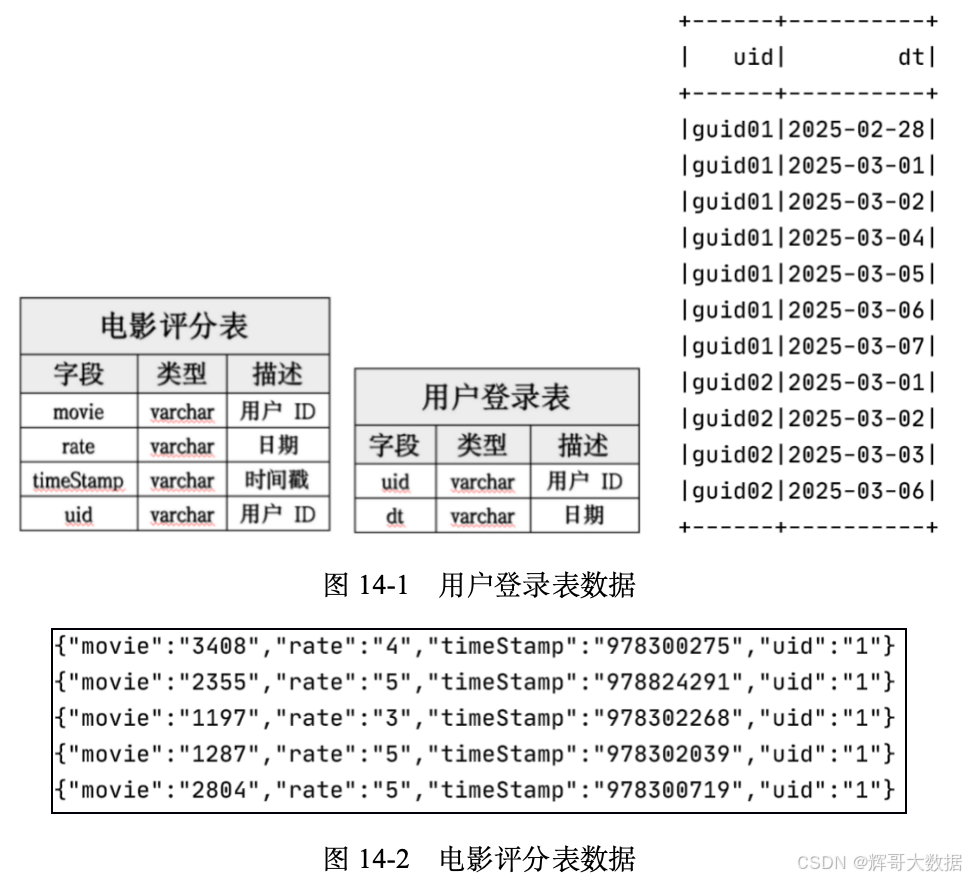
14.1.2 连续登录超过3天的用户DSL风格
本案例需求:
(1)使用DSL风格进行编程。
(2)使用用户登录表中的数据。
(3)根据提供的数据找出连续登录超过3天的用户。
连续登录超过3天的用户DSL风格示例代码如代码14-1所示。
代码14-1 LoginDSL.scala
package chapter14
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import utils.SparkUtils
/**
* 需求:
* 找出连续登录超过3天的用户
*
* 步骤:
* 1. 开窗,按照uid分区,按照dt排序,标记rn
* 2. 然后使用date_sub函数,用dt减去rn,标记为dis
* 3. 使用uid和dis分组,标记count为cn
* 4. where cs > 2
**/
object LoginDSL {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkUtils.getSparkSeesion()
import org.apache.spark.sql.functions._
import spark.implicits._
val df = spark.read
.options(Map("header" -> "true", "inferSchema" -> "true"))
.csv("doc/exercise/用户登录/loginUser.csv")
df.printSchema()
df.show()
/** *
* Error:(29, 40) type mismatch;
* found : Symbol
* required: Int
* .select('uid, 'dt, date_sub('dt, 'rn))
*/
val win = Window.partitionBy('uid).orderBy('dt)
df.select('uid, date_format('dt, "yyyy-MM-dd") as "dt", row_number() over (win) as "rn")
.select('uid, 'dt, expr("date_sub(dt,rn)") as "dis")
.groupBy('uid,'dis).agg(min('dt),max('dt),count('uid) as "cs")
.where("cs > 2").drop('dis)
.show()
}
}
执行以上代码,输出结果如图14-3所示。
14.1.3 连续登录超过3天的用户SQL风格
本案例需求:
(1)使用SQL风格进行编程。
(2)使用用户登录表中的数据。
(3)根据提供的数据找出连续登录超过3天的用户。
连续登录超过3天的用户SQL风格示例代码如代码14-2所示。
代码14-2 LoginSQL.scala
package chapter14
import org.apache.spark.sql.{DataFrame, SparkSession}
import utils.SparkUtils
/**
* 需求:
* 找出连续登录超过3天的用户
*
* 步骤:
* 1. 开窗,按照uid分区,按照dt排序,标记rn
* 2. 然后使用date_sub函数,用dt减去rn,标记为dis
* 3. 使用uid和dis分组,标记count为cn
* 4. where cs > 2
**/
object LoginSQL {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkUtils.getSparkSeesion()
val frame: DataFrame = spark.read
.option("header",true)
.csv("doc/exercise/用户登录/loginUser.csv")
frame.printSchema()
frame.show()
frame.createTempView("login")
spark.sql(
"""
|select
|uid , min(dt) , max(dt) ,count(1) as cts
|from
|(
| select
| uid , dt ,date_sub(dt,rn) as dis
| from
| (
| select
| uid , dt , row_number() over(partition by uid order by dt) rn
| from login
| ) t2
|) t3
|group by uid , dis
|having cts > 2
|""".stripMargin).show()
}
}
执行以上代码,输出结果如图14-4所示。
14.1.4 电影统计DSL风格
本案例需求:
(1)使用DSL风格。
(2)求每个人评价最高的10部电影。
(3)求最热门的前50部电影(被评分的次数说明热门程度)。
(4)求每个人的评分总和。
(5)求每部电影的总得分和平均得分。
电影统计DSL风格示例代码如代码14-3所示。
代码14-3 MovieDSL.scala
package chapter14
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SparkSession}
import utils.SparkUtils
/**
* 需求:
* 1. 求每个人评价最高的10部电影
* 2. 求最热门的前50部电影 (被评分的次数说明热门程度)
* 3. 求每个人的评分总和
* 4. 求每部电影的总得分和平均得分
**/
object MovieDSL {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkUtils.getSparkSeesion()
import org.apache.spark.sql.functions._
import spark.implicits._
val df: DataFrame = spark.read.json("doc/exercise/电影评分/rating.json").drop("raete")
// df.printSchema()
// df.show(10)
/***
* 每个人评价最高的10部电影
* 1. 首先按照用户进行分区 ,按照评分进行排序(降序),且打上标签(窗口函数)
* 2. 只需要获取 rn <11
*
* uid rate rn
* uid1 5 1
* uid1 4 2
* uid1 4 3
* uid1 3 4
* uid1 3 5
*/
val win = Window.partitionBy('uid).orderBy('rate.desc)
df.select('uid,'movie,'rate,row_number() over(win) as "rn")
.where("rn < 11")
.show()
/***
* 最热门的前50部电影(被评分的次数说明热门程度)
* 1. 按照电影进行分组,求评分次数
* 2. 将评分次数进行排序(降序)
*/
df.groupBy('movie).agg(count('movie) as "cm").orderBy('cm.desc).show()
/***
* 每个人的评分总和
*/
df.groupBy('uid).agg(sum('rate)).show()
/***
* 每部电影的总得分和平均得分
* 1. 按照电影进行分组
* 2. 再在组内求sum和avg
*/
df.groupBy('movie).agg(sum('rate), avg('rate)).show()
}
}
注意:本节执行结果可查看14.1.6节。
14.1.5 电影统计SQL风格
本案例需求:
(1)使用SQL风格。
(2)求每个人评价最高的10部电影。
(3)求最热门的前50部电影(被评分的次数说明热门程度)。
(4)求每个人的评分总和。
(5)求每部电影的总得分和平均得分。
电影统计SQL风格示例代码如代码14-4所示。
代码14-4 MovieSQL.scala
package chapter14
import org.apache.spark.sql.{DataFrame, SparkSession}
import utils.SparkUtils
/**
* 需求:
* 1. 求每个人评价最高的10部电影
* 2. 求最热门的前50部电影 (被评分的次数说明热门程度)
* 3. 求每个人的评分总和
* 4. 求每部电影的总得分和平均得分
**/
object MovieSQL {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkUtils.getSparkSeesion()
val frame: DataFrame = spark
.read
.json("doc/exercise/电影评分/rating.json")
.drop("raete")
frame.createTempView("t")
/***
* 每个人评价最高的10部电影
* 1. 首先按照用户进行分区,按照评分进行排序(降序),且打上标签(窗口函数)
* 2. 只需要获取 rn <11
*
* uid rate rn
* uid1 5 1
* uid1 4 2
* uid1 4 3
* uid1 3 4
* uid1 3 5
*/
spark.sql(
"""
|
|select
| uid , movie ,rate,rn
|from
|(
| select
| uid , movie ,rate ,row_number() over(partition by uid order by rate desc) rn
| from t
|) t2
|where rn < 11
|
|""".stripMargin).show()
/***
* 最热门的前50部电影 (被评分的次数说明热门程度)
* 1. 按照电影进行分组,求评分次数
* 2. 将评分次数进行排序(降序)
*/
spark.sql(
"""
|
|select
| movie,cs
|from (
| select
| movie,count(1) as cs
| from t
| group by movie
|) t2
|order by cs desc
|
|""".stripMargin).show()
/***
* 每个人的评分总和
*/
spark.sql(
"""
|select
| uid,sum(rate)
|from t group by uid
|
|""".stripMargin).show()
/***
* 每部电影的总得分和平均得分
* 1. 按照电影进行分组
* 2. 再在组内求sum和avg
*/
spark.sql(
"""
|select
| movie,sum(rate),avg(rate)
|from t
|group by movie
|
|""".stripMargin).show()
}
}
本示例执行结果可查看14.1.6节。
14.1.6 电影统计运行结果
本案例最终代码实现的结果:
(1)每个人评价最高的10部电影,执行结果如图14-5所示。
(2)最热门的前50部电影(被评分的次数说明热门程度),执行结果如图14-6所示。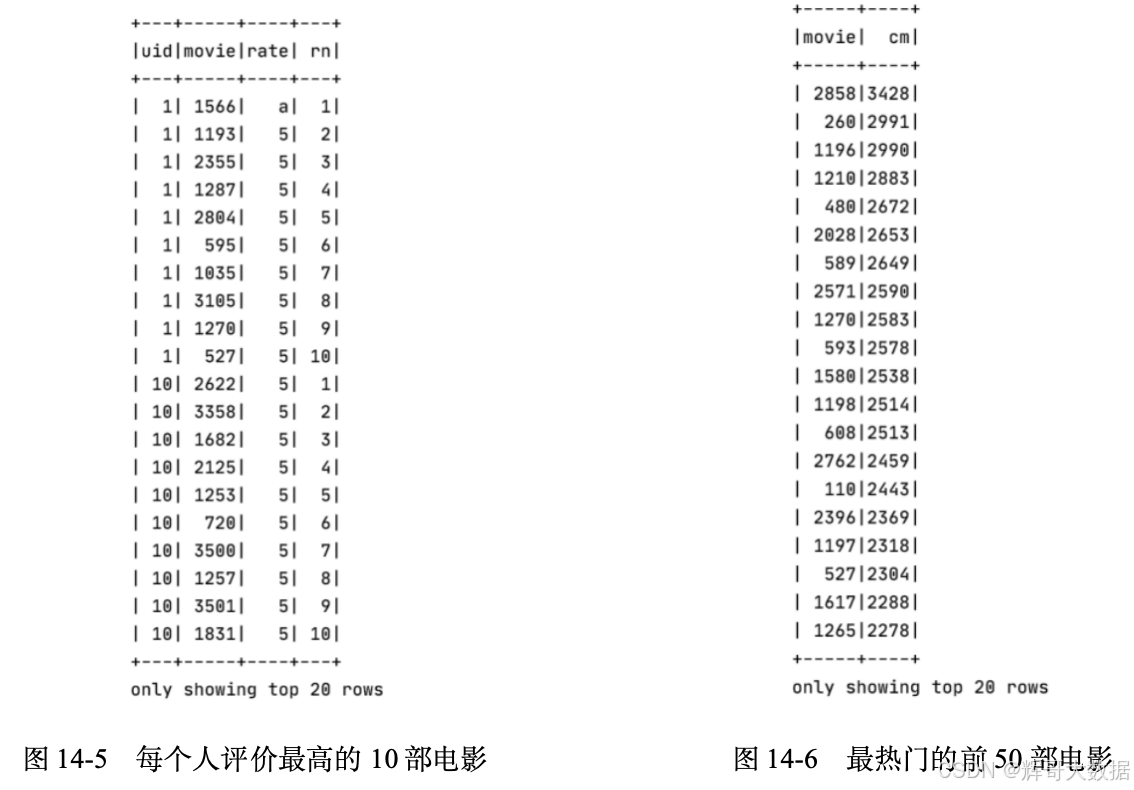
(3)每个人的评分总和,执行结果如图14-7所示。
(4)每部电影的总得分和平均得分,执行结果如图14-8所示。
14.2 Spark Core日志数据分析
在互联网企业中,用户浏览网页的日志分析项目极为常见。本节将演示基于互联网企业设计的一个浏览网页的日志分析案例。
首先需要从服务器或数据库中获取原始的日志数据。这些数据通常是非结构化或者结构化的,包含大量的用户访问信息。
接着,利用Spark进行数据清洗,包括筛选有效记录、去重、格式转换等步骤,以确保数据质量。完成数据清洗后,使用Spark进行计算和存储。例如,可以计算每个网页的访问量,并将结果存储到HDFS、关系数据库或NoSQL数据库中,以便后续的分析和查询。
最后,使用可视化工具如Echarts、FineBI或Tableau等,将分析结果以图表的形式展示出来。这些图表可以直观地展示各个网页的访问情况,帮助分析师更好地理解用户行为,优化网站设计和内容策略。
整个过程充分利用了Spark的高速计算能力和丰富的数据处理功能,确保分析结果的准确性和时效性。
通过本案例的学习,读者可以复习在Spark中使用Case Class、Schema+Row、JavaBean创建DataFrame方式,Spark SQL中的窗口函数的使用,以及foreach中连接MySQL的方法。
14.2.1 前期准备
1. 表格及数据样例
为了让读者直观了解本次实战案例的数据和字段类型,我们将数据和字段类型以图片形式进行展示。其中,图14-9所示的“页面浏览表及字段”是本次实验的表格和字段。图14-9所示的“前10条案例数据”是以TXT文件进行存储的,文件名为output_buffered.txt。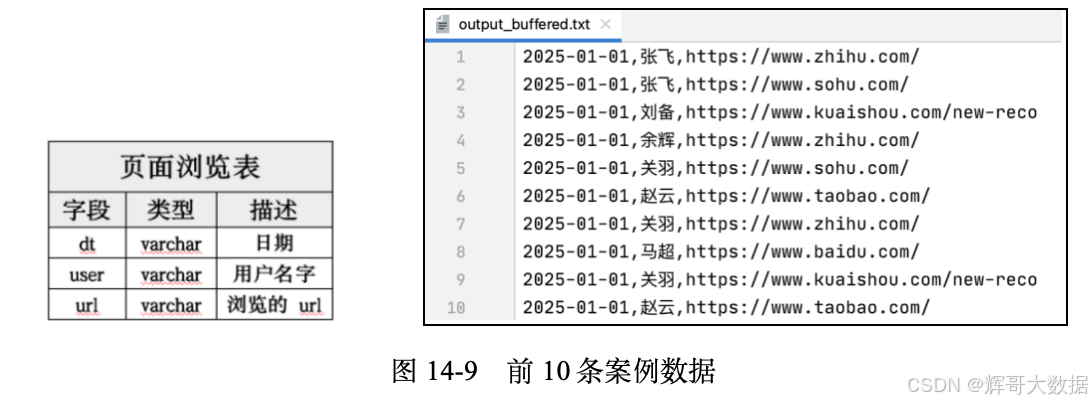
2. 需求实现及计算要求
统计每天PV并用FineBI可视化。要求使用Schema和Row创建DataFreme,使用Spark SQL进行计算,将每天对应的PV结果存储到MySQL中,存储字段有dt、pv,通过FineBI工具进行可视化展示。
统计每天UV并用FineBI可视化。要求使用Case Class创建DataFreme,使用Spark SQL进行计算,将每天对应的UV结果存储到MySQL中,存储字段有dt、uv,通过FineBI工具进行可视化 展示。
统计每天TopN并用FineBI可视化。要求使用JavaBean创建DataFreme,使用Spark SQL进行计算,将每天Top5的RUL结果存储到MySQL中,存储字段有dt、url、url_count,通过FineBI工具进行可视化展示。
3. 可视化工具
FineBI是帆软软件有限公司推出的一款商业智能(Business Intelligence,BI)产品。它旨在帮助企业快速搭建面向全员的自助分析BI平台,通过简单拖曳即可制作出丰富多样的数据可视化信息,让业务人员能够自主分析数据并辅助决策。FineBI支持多种数据源,提供数据预览、血缘分析等功能,并注重数据安全,支持权限设置。此外,它还具备高性能计算引擎,能够处理大规模数据集。
- FineBI的官网地址为https:// home.fanruan.com/。
- FineBI的帮助页面为https:// help.fanruan.com/finebi/。
4. MySQL的Maven
将以下MySQL的依赖复制到pom.xml中:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.30</version>
</dependency>
14.2.2 统计PV和可视化
由于结果数据需要存储到MySQL中,因此提前创建表格,MySQL的执行语句如下:
drop table view_pv;
CREATE TABLE view_pv(
dt char(20) not null primary key,
pv int
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
统计PV的示例代码如代码14-5所示。
代码14-5 DataViewPV.scala
package chapter14
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.sql.types.{StringType, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* drop table view_pv;
* CREATE TABLE view_pv(
* dt char(20) not null primary key,
* pv int
* )ENGINE=InnoDB DEFAULT CHARSET=utf8;
*
* SELECT * from view_pv;
*
*/
object DataViewPV {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("")
.master("local[*]")
.getOrCreate()
val schema = new StructType()
.add("dt", StringType)
.add("name", StringType)
.add("url", StringType)
val lines = spark.sparkContext.textFile("doc/output_buffered.txt")
// 将RDD关联了Schema,但依然是RDD
val row = lines.map(line => {
val fields = line.split(",")
Row(fields(0), fields(1), fields(2))
})
val df = spark.createDataFrame(row, schema)
df.show()
df.createTempView("dataTable")
val view_pv = spark.sql(
"""
|
| select
| dt ,
| cast(count(name) as int) as pv
| from dataTable group by dt
|
|""".stripMargin)
// 把数据保存到MySQL表中
view_pv.rdd.foreach(line => {
// 每条数据与MySQL建立连接
// 把数据插入MySQL表操作
// 1. 获取连接
val connection: Connection = DriverManager.getConnection("jdbc:mysql:// localhost:3306/spark", "root", "yuhui888")
// 2. 定义插入数据的SQL语句
val sql = "insert into view_pv(dt,pv) values(?,?)"
// 3. 获取PreParedStatement
try {
val ps: PreparedStatement = connection.prepareStatement(sql)
// 4. 获取数据,给?号赋值
ps.setString(1, line.getAs[String](0))
ps.setInt(2, line.getAs[Int](1))
// 执行
ps.execute()
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
}
})
}
}
执行上述代码,将数据存储到MySQL的view_pv表中,结果如图14-10所示。
在FineBI的“数据中心”中,加载MySQL中的view_pv表,形成FineBI中的spark_view_pv数据集,如图14-11所示。
在FineBI的“我的分析”中,加载FineBI中的spark_view_pv数据集,通过拖曳方式形成最终需要的图表。统计PV数据可视化展示如图14-12所示。横轴为日期,纵轴为PV总数。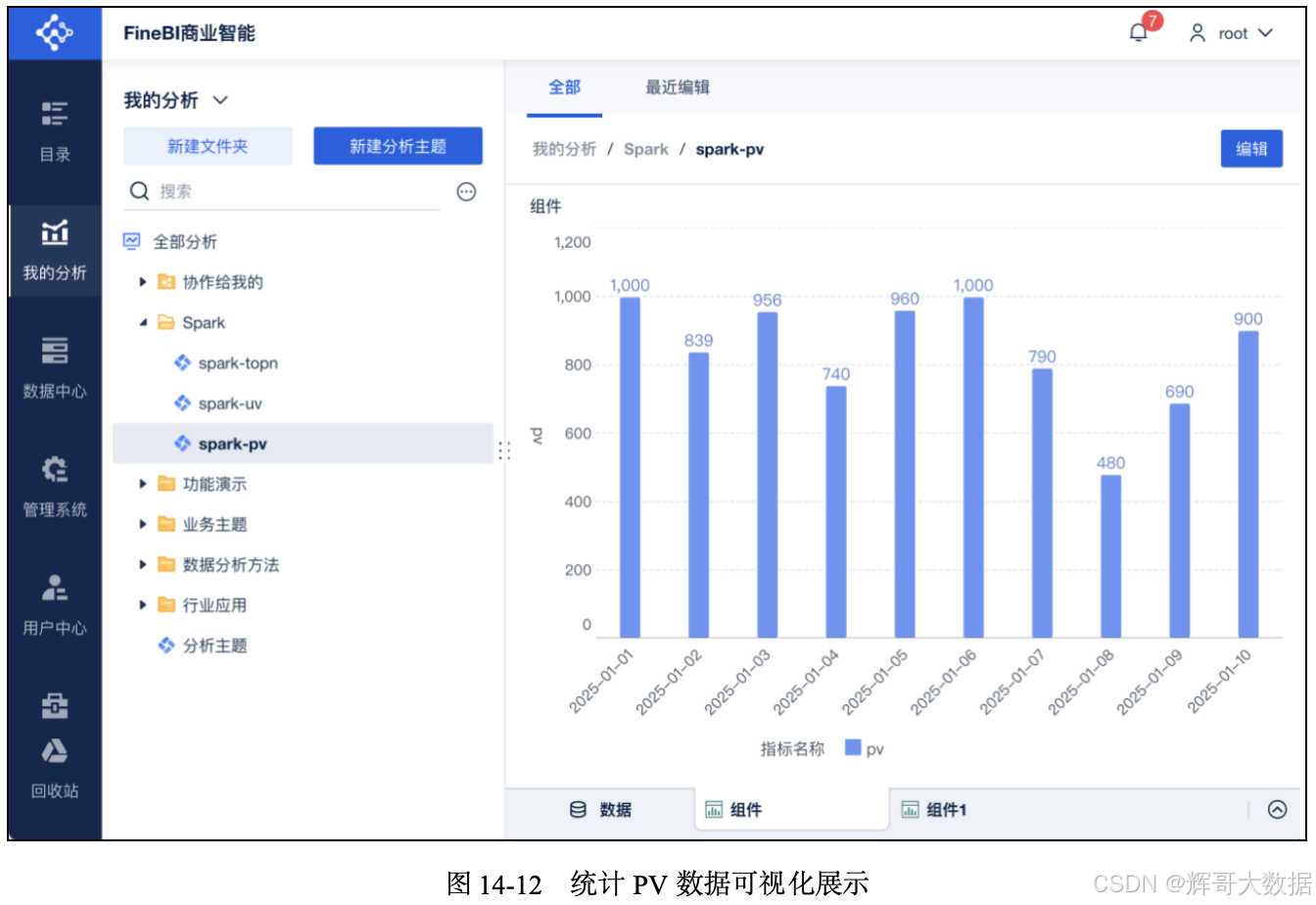
14.2.3 统计UV和可视化
MySQL表格创建
由于结果数据需要存储到MySQL中,因此提前创建表格,MySQL的执行语句如下:
drop table view_uv;
CREATE TABLE view_uv(
dt char(20) not null primary key,
uv int
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
统计UV的示例代码如代码14-6所示。
代码14-6 DataViewUV.scala
package chapter14
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
/**
* author: yuhui
* descriptions:
* date: 2024 - 10 - 26 3:50 下午
*
* drop table view_uv;
* CREATE TABLE view_uv(
* dt char(20) not null primary key,
* uv int
* )ENGINE=InnoDB DEFAULT CHARSET=utf8;
*
* 需求:
*
*/
case class DataViewUV(dt: String, name: String, url: String)
object DataViewUV {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val lines = spark.sparkContext.textFile("doc/output_buffered.txt")
// 将RDD关联了Schema,但依然是RDD
val dataDF: DataFrame = lines.map(line => {
val fields = line.split(",")
DataViewUV(fields(0), fields(1), fields(2))
}).toDF()
dataDF.createTempView("dataTable")
val view_uv = spark.sql(
"""
|
| select
| dt ,
| cast(count(DISTINCT name) as int) as uv
| from dataTable
| group by dt
|
|""".stripMargin)
// 把数据保存到MySQL表中
view_uv.rdd.foreach(line => {
// 每条数据与MySQL建立连接
// 把数据插入MySQL表操作
// 1. 获取连接
val connection: Connection = DriverManager.getConnection("jdbc:mysql:// localhost:3306/spark", "root", "yuhui888")
// 2. 定义插入数据的SQL语句
val sql = "insert into view_uv(dt,uv) values(?,?)"
// 3. 获取PreParedStatement
try {
val ps: PreparedStatement = connection.prepareStatement(sql)
// 4. 获取数据,给?号赋值
ps.setString(1, line.getAs[String](0))
ps.setInt(2, line.getAs[Int](1))
// 执行
ps.execute()
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
}
})
}
}
执行上述代码,将数据存储到MySQL的view_uv表中,结果如图14-13所示。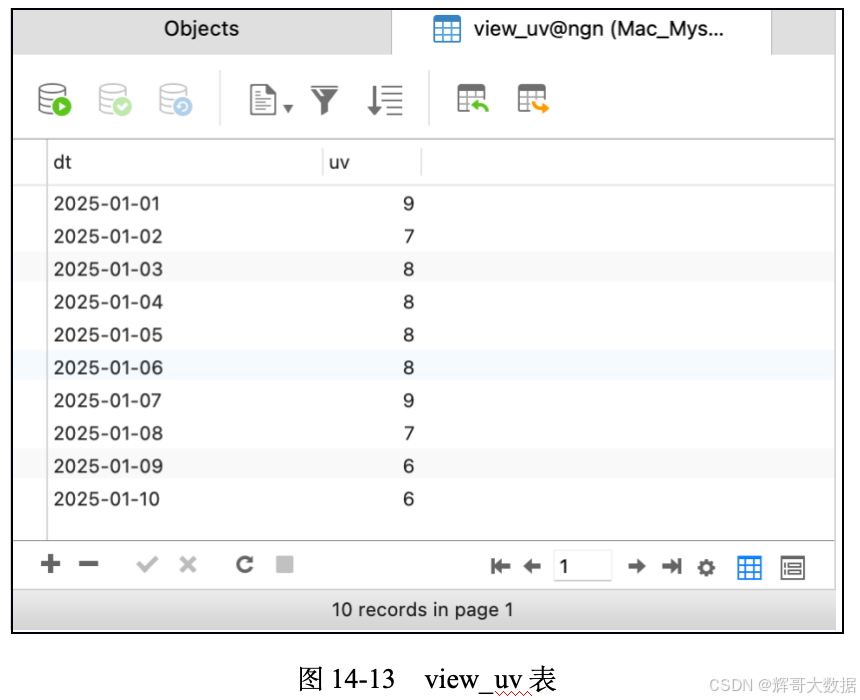
在FineBI的“数据中心”中,加载MySQL中的view_uv表,形成FineBI中的spark_view_uv数据集,如图14-14所示。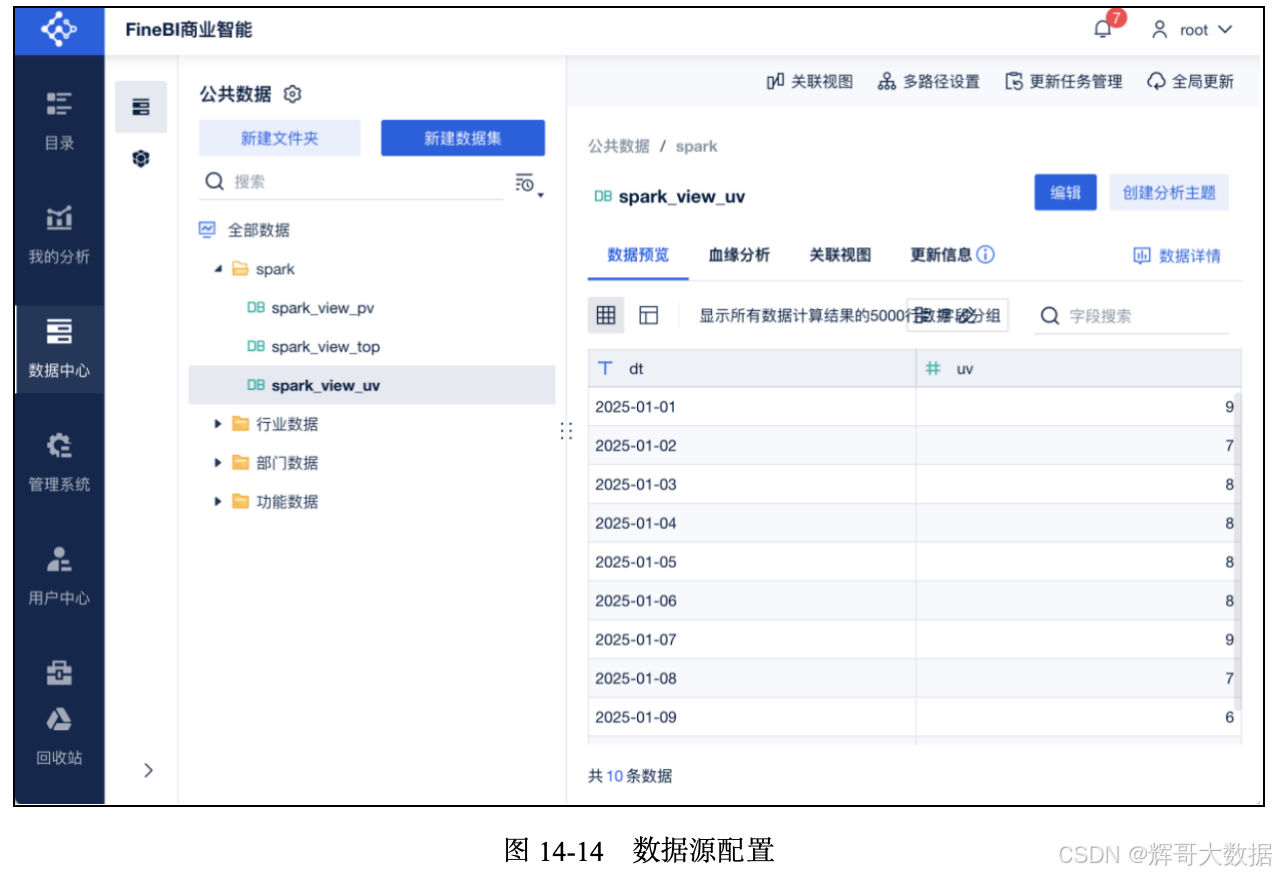
在FineBI的“我的分析”中,加载FineBI中的spark_view_uv数据集,通过拖曳方式形成最终需要的图表。统计UV数据可视化展示如图14-15所示。横轴为日期,纵轴为UV总数。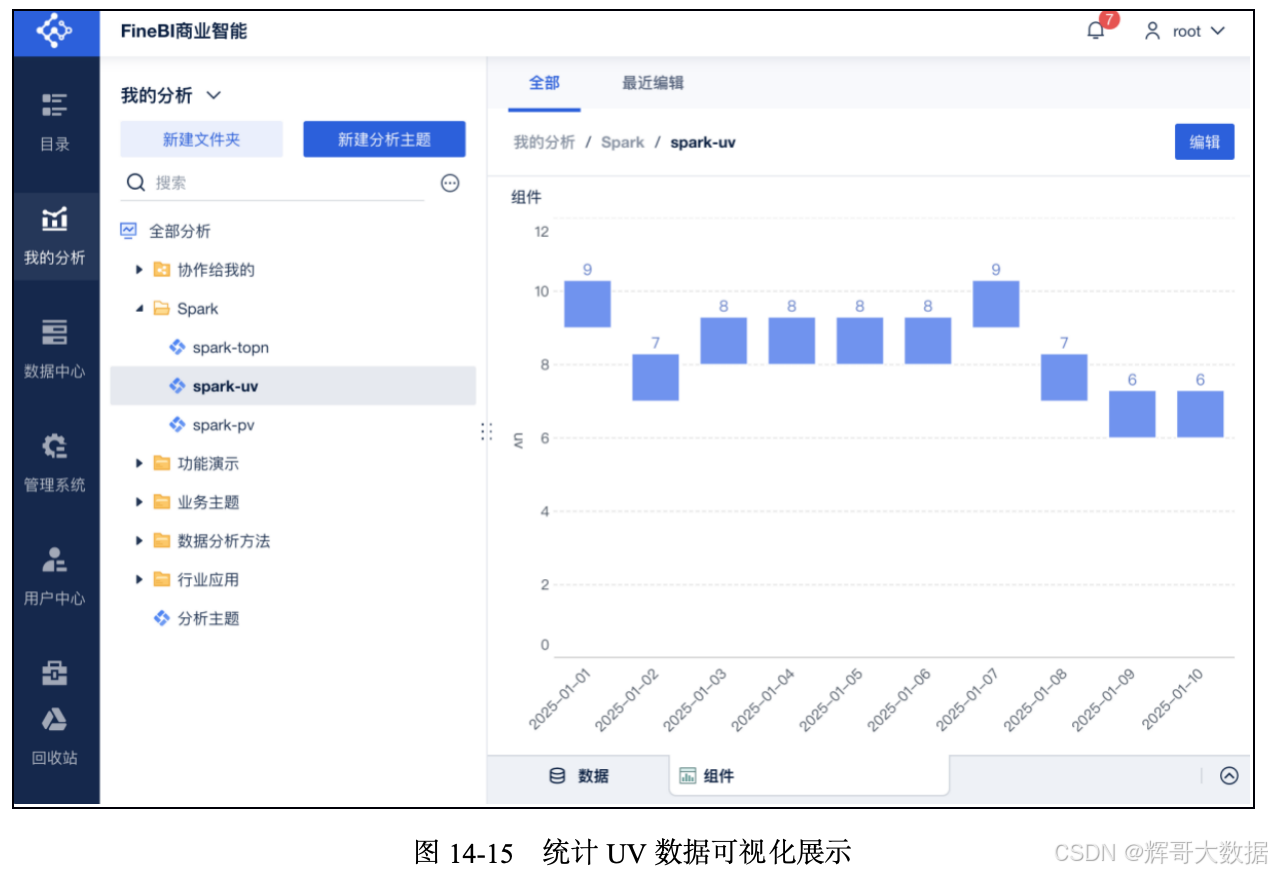
14.2.4 统计TopN和可视化
由于结果数据需要存储到MySQL中,因此提前创建表格,MySQL的执行语句如下:
drop table view_top;
CREATE TABLE view_top(
dt char(20) ,
url char(50),
url_count int
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
select * from view_top;
求TopN涉及窗口函数的使用,下面对窗口函数的解题步骤进行说明。
- WITH RankedUrls AS (…) 定义了一个公用表表达式(CTE),它首先按dt和url分组,并计算每个dt中每个url出现的次数(url_count)。
- ROW_NUMBER() OVER (PARTITION BY dt ORDER BY COUNT(*) DESC) 为每个dt分组内的url分配一个排名,排名依据是url出现的次数(降序)。
- 在外部查询中,我们从RankedUrls CTE中选择dt、url和url_count,但只选择排名在前五的记录(WHERE rank <= 5)。
- 最后,我们按dt和rank对结果进行排序,以确保输出是有序的。
统计TopN的示例代码如代码14-7所示。
代码14-7 DataViewTopN.scala
package chapter14
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.sql.SparkSession
/**
* CREATE TABLE view_top(
* dt char(20) ,
* url char(50),
* url_count int
* )ENGINE=InnoDB DEFAULT CHARSET=utf8;
*
*/
object DataViewTopN {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("")
.master("local[*]")
.getOrCreate()
val lines = spark.sparkContext.textFile("doc/output_buffered.txt")
// 将RDD关联了Schema,但依然是RDD
val rddBean = lines.map(line => {
val fields = line.split(",")
new DataView(fields(0), fields(1), fields(2))
})
val dataDF = spark.createDataFrame(rddBean, classOf[DataView])
dataDF.show()
dataDF.createTempView("dataTable")
/** *
* 1)WITH RankedUrls AS (...) 定义了一个公用表表达式(CTE),它首先按dt和url分组,并计算每个dt中每个url出现的次数(url_count)
* 2)ROW_NUMBER() OVER (PARTITION BY dt ORDER BY COUNT(*) DESC) 为每个dt分组内的url分配一个排名,排名依据是url出现的次数(降序)
* 3)在外部查询中,我们从RankedUrls CTE中选择dt、url和url_count,但只选择排名在前五的记录(WHERE rank <= 5)
* 4)最后,我们按dt和rank对结果进行排序,以确保输出是有序的
*/
val frame = spark.sql(
"""
|
| WITH RankedUrls AS (
| SELECT
| dt,
| url,
| count(*) as url_count,
| ROW_NUMBER() OVER (PARTITION BY dt ORDER BY COUNT(*) DESC) AS rank
| FROM
| dataTable
| GROUP BY
| dt,
| url
|)
|
|SELECT
| dt,
| url,
| cast(url_count as int) as url_count
|FROM
| RankedUrls
|WHERE
| rank <= 5
|ORDER BY
| dt,
| rank;
|
|""".stripMargin)
// 把数据保存到MySQL表中
frame.rdd.foreach(line => {
// 每条数据与MySQL建立连接
// 把数据插入MySQL表操作
// 1. 获取连接
val connection: Connection = DriverManager.getConnection("jdbc:mysql:// localhost:3306/spark", "root", "yuhui888")
// 2. 定义插入数据的SQL语句
val sql = "insert into view_top(dt,url,url_count) values(?,?,?)"
// 3. 获取PreParedStatement
try {
val ps: PreparedStatement = connection.prepareStatement(sql)
// 4. 获取数据,给?号赋值
ps.setString(1, line.getAs[String](0))
ps.setString(2, line.getAs[String](1))
ps.setInt(3, line.getAs[Int](2))
// 执行
ps.execute()
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
}
})
}
}
执行上述代码,将数据存储到MySQL的view_top表中,结果如图14-16所示。
在FineBI的“数据中心”中,加载MySQL中的view_top表,形成FineBI中的spark_view_top数据集,如图14-17所示。
在FineBI的“我的分析”中,加载FineBI中的spark_view_top数据集,通过拖曳的方式形成最终需要的图表。统计UV数据可视化展示如图14-18所示。第一列为日期,第二列为URL,第三列为URL的个数。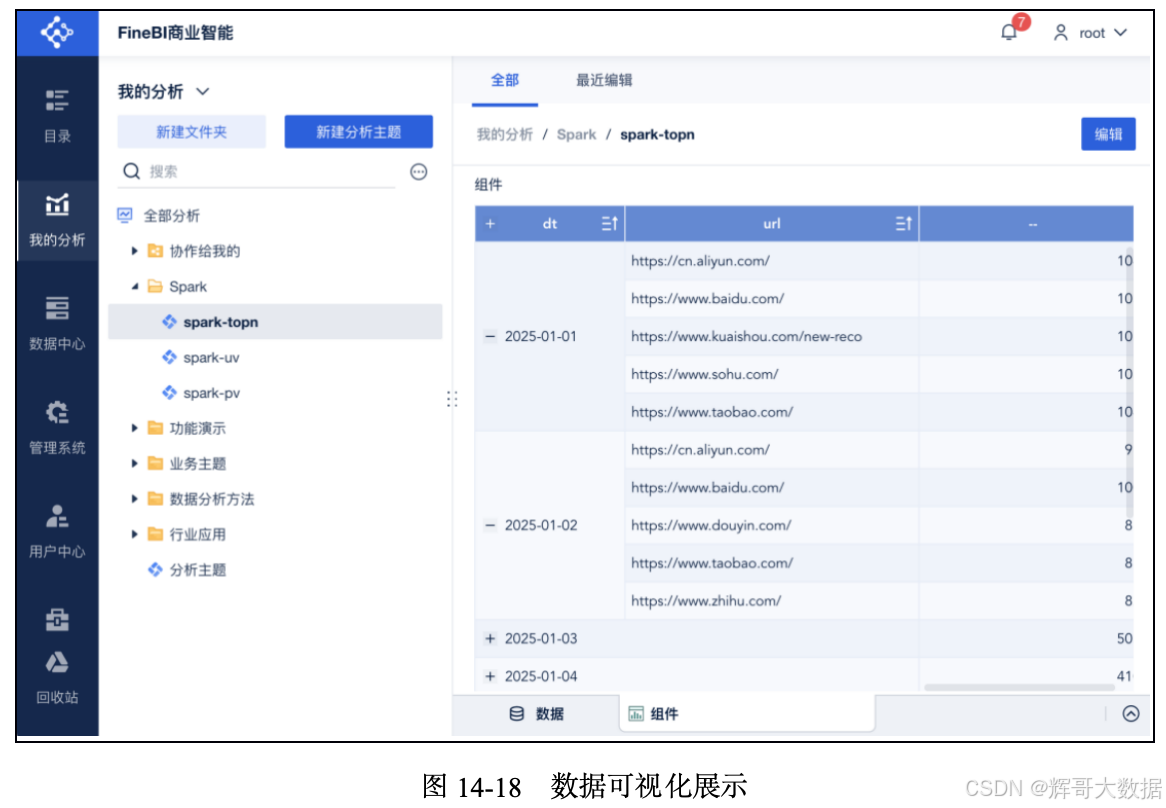
14.3 Spark SQL电商数据分析
基于Spark SQL的电商实战案例,需要涵盖以下3个需求。
(1)在电商数据分析中,我们利用Spark SQL对销售数据进行深度挖掘。首先,我们计算每年的销售单数和销售总额,这通过GROUP BY语句按年份分组,并使用COUNT和SUM函数分别统计销售单数和金额。
(2)其次,我们查询每年金额最大的订单及其具体金额。这涉及两步操作:先使用窗口函数ROW_NUMBER按年份和订单金额降序为每个年份的订单编号,然后筛选出每年排名第一的订单。
(3)最后,我们计算每年最畅销的货品。这同样需要分组和排序,但这次是按年份和货品分组,使用SUM函数统计每年每个货品的销售数量,再通过排序和限制结果集来找出每年销量最高的货品。
通过Spark SQL,我们能够高效地处理大规模电商销售数据,快速响应各种业务分析需求,如销售趋势分析、热销商品推荐等,为电商企业的决策提供有力支持。
14.3.1 数据和表格说明
本案例有三张表,每张表的数据字段如下。
- tbDate:时间维度表,用于记录交易的时间信息。
- tbStockDetail:订单明细表,用于记录交易的详细信息。
- tbStock:关联表,用于将订单、时间、地点的信息连接在一起。
三张表的数据字典如图14-19所示。每个订单可能包含多个货品,每个订单可以产生多次交易,不同的货品有不同的单价。也就是说,tbStock与tbStockDetail是一对多的关系,ordernumber(订单号)与itemid(货品)也是一对多的关系。其中,tbDate时间跨度从2013−2024年,tbStock时间跨度从2014−2020年。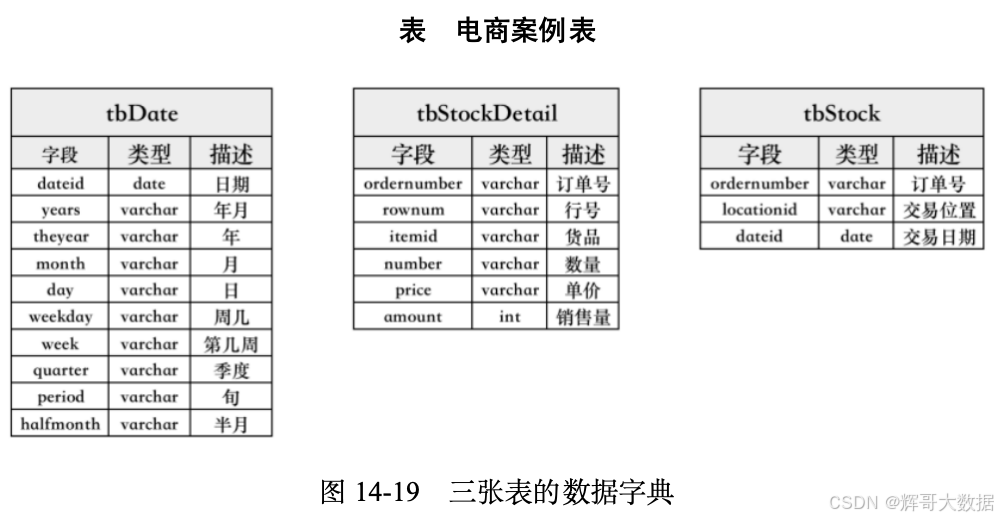
14.3.2 加载数据
(1)YARN启动spark-shell,如图14-20所示。
(2)加载tbStock表。创建tbStock表的DataFrame,在spark-shell命令行中执行以下语句:
scala> case class tbStock(ordernumber:String,locationid:String,dateid:String) extends Serializable
defined class tbStock
scala> val tbStockRdd = spark.sparkContext.textFile("hdfs:// ns/spark_book_data/tbStock.txt")
tbStockRdd: org.apache.spark.rdd.RDD[String] = tbStock.txt MapPartitionsRDD[1] at textFile at <console>:23
scala> val tbStockDS = tbStockRdd.map(_.split(",")).map(attr=>tbStock(attr(0),attr(1),attr(2))).toDS
tbStockDS: org.apache.spark.sql.Dataset[tbStock] = [ordernumber: string, locationid: string ... 1 more field]
scala> tbStockDS.show()
执行以上语句,输出结果为:
+------------+----------+---------+
| ordernumber|locationid| dateid|
+------------+----------+---------+
|BYSL00000893| ZHAO|2017-8-23|
|BYSL00000897| ZHAO|2017-8-24|
|BYSL00000898| ZHAO|2017-8-25|
|BYSL00000899| ZHAO|2017-8-26|
|BYSL00000900| ZHAO|2017-8-26|
|BYSL00000901| ZHAO|2017-8-27|
|BYSL00000902| ZHAO|2017-8-27|
|BYSL00000904| ZHAO|2017-8-28|
|BYSL00000905| ZHAO|2017-8-28|
|BYSL00000906| ZHAO|2017-8-28|
|BYSL00000907| ZHAO|2017-8-29|
|BYSL00000908| ZHAO|2017-8-30|
|BYSL00000909| ZHAO| 2017-9-1|
|BYSL00000910| ZHAO| 2017-9-1|
|BYSL00000911| ZHAO|2017-8-31|
|BYSL00000912| ZHAO| 2017-9-2|
|BYSL00000913| ZHAO| 2017-9-3|
|BYSL00000914| ZHAO| 2017-9-3|
|BYSL00000915| ZHAO| 2017-9-4|
|BYSL00000916| ZHAO| 2017-9-4|
+------------+----------+---------+
only showing top 20 rows
(3)加载tbStockDetail表。创建tbStockDetail表的DataFrame,在spark-shell命令行中执行以下语句:
scala> case class tbStockDetail(ordernumber:String, rownum:Int, itemid:String, number:Int, price:Double, amount:Double) extends Serializable
defined class tbStockDetail
scala> val tbStockDetailRdd = spark.sparkContext.textFile("hdfs:// ns/spark_book_data/tbStockDetail.txt")
tbStockDetailRdd: org.apache.spark.rdd.RDD[String] = tbStockDetail.txt MapPartitionsRDD[13] at textFile at <console>:23
scala> val tbStockDetailDS = tbStockDetailRdd.map(_.split(",")).map(attr=> tbStockDetail(attr(0),attr(1).trim().toInt,attr(2),attr(3).trim().toInt,attr(4).trim().toDouble, attr(5).trim().toDouble)).toDS
tbStockDetailDS: org.apache.spark.sql.Dataset[tbStockDetail] = [ordernumber: string, rownum: int ... 4 more fields]
scala> tbStockDetailDS.show()
执行以上语句,输出结果为:
+------------+------+--------------+------+-----+------+
| ordernumber|rownum| itemid|number|price|amount|
+------------+------+--------------+------+-----+------+
|BYSL00000893| 0|FS527258160501| -1|268.0|-268.0|
|BYSL00000893| 1|FS527258169701| 1|268.0| 268.0|
|BYSL00000893| 2|FS527230163001| 1|198.0| 198.0|
|BYSL00000893| 3|24627209125406| 1|298.0| 298.0|
|BYSL00000893| 4|K9527220210202| 1|120.0| 120.0|
|BYSL00000893| 5|01527291670102| 1|268.0| 268.0|
|BYSL00000893| 6|QY527271800242| 1|158.0| 158.0|
|BYSL00000893| 7|ST040000010000| 8| 0.0| 0.0|
|BYSL00000897| 0|04527200711305| 1|198.0| 198.0|
|BYSL00000897| 1|MY627234650201| 1|120.0| 120.0|
|BYSL00000897| 2|01227111791001| 1|249.0| 249.0|
|BYSL00000897| 3|MY627234610402| 1|120.0| 120.0|
|BYSL00000897| 4|01527282681202| 1|268.0| 268.0|
|BYSL00000897| 5|84126182820102| 1|158.0| 158.0|
|BYSL00000897| 6|K9127105010402| 1|239.0| 239.0|
|BYSL00000897| 7|QY127175210405| 1|199.0| 199.0|
|BYSL00000897| 8|24127151630206| 1|299.0| 299.0|
|BYSL00000897| 9|G1126101350002| 1|158.0| 158.0|
|BYSL00000897| 10|FS527258160501| 1|198.0| 198.0|
|BYSL00000897| 11|ST040000010000| 13| 0.0| 0.0|
+------------+------+--------------+------+-----+------+
only showing top 20 rows
(4)加载tbDate表。创建tbDate表的DataFrame,在spark-shell命令行中执行以下语句:
scala> case class tbDate(dateid:String, years:Int, theyear:Int, month:Int, day:Int, weekday:Int, week:Int, quarter:Int, period:Int, halfmonth:Int) extends Serializable
defined class tbDate
scala> val tbDateRdd = spark.sparkContext.textFile("hdfs:// ns/spark_book_data/tbDate.txt")
tbDateRdd: org.apache.spark.rdd.RDD[String] = tbDate.txt MapPartitionsRDD[20] at textFile at <console>:23
scala> val tbDateDS = tbDateRdd.map(_.split(",")).map(attr=> tbDate(attr(0),attr(1).trim().toInt, attr(2).trim().toInt,attr(3).trim().toInt, attr(4).trim().toInt, attr(5).trim().toInt, attr(6).trim().toInt, attr(7).trim().toInt, attr(8).trim().toInt, attr(9).trim().toInt)).toDS
tbDateDS: org.apache.spark.sql.Dataset[tbDate] = [dateid: string, years: int ... 8 more fields]
scala> tbDateDS.show()
执行以上语句,输出结果为:
+---------+------+-------+-----+---+-------+----+-------+------+---------+
| dateid| years|theyear|month|day|weekday|week|quarter|period|halfmonth|
+---------+------+-------+-----+---+-------+----+-------+------+---------+
| 2013-1-1|201301| 2013| 1| 1| 3| 1| 1| 1| 1|
| 2013-1-2|201301| 2013| 1| 2| 4| 1| 1| 1| 1|
| 2013-1-3|201301| 2013| 1| 3| 5| 1| 1| 1| 1|
| 2013-1-4|201301| 2013| 1| 4| 6| 1| 1| 1| 1|
| 2013-1-5|201301| 2013| 1| 5| 7| 1| 1| 1| 1|
| 2013-1-6|201301| 2013| 1| 6| 1| 2| 1| 1| 1|
| 2013-1-7|201301| 2013| 1| 7| 2| 2| 1| 1| 1|
| 2013-1-8|201301| 2013| 1| 8| 3| 2| 1| 1| 1|
| 2013-1-9|201301| 2013| 1| 9| 4| 2| 1| 1| 1|
|2013-1-10|201301| 2013| 1| 10| 5| 2| 1| 1| 1|
|2013-1-11|201301| 2013| 1| 11| 6| 2| 1| 2| 1|
|2013-1-12|201301| 2013| 1| 12| 7| 2| 1| 2| 1|
|2013-1-13|201301| 2013| 1| 13| 1| 3| 1| 2| 1|
|2013-1-14|201301| 2013| 1| 14| 2| 3| 1| 2| 1|
|2013-1-15|201301| 2013| 1| 15| 3| 3| 1| 2| 1|
|2013-1-16|201301| 2013| 1| 16| 4| 3| 1| 2| 2|
|2013-1-17|201301| 2013| 1| 17| 5| 3| 1| 2| 2|
|2013-1-18|201301| 2013| 1| 18| 6| 3| 1| 2| 2|
|2013-1-19|201301| 2013| 1| 19| 7| 3| 1| 2| 2|
|2013-1-20|201301| 2013| 1| 20| 1| 4| 1| 2| 2|
+---------+------+-------+-----+---+-------+----+-------+------+---------+
only showing top 20 rows
(5)注册3张临时表,在spark-shell命令行中执行以下语句:
scala> tbStockDS.createOrReplaceTempView("tbStock")
scala> tbDateDS.createOrReplaceTempView("tbDate")
scala> tbStockDetailDS.createOrReplaceTempView("tbStockDetail")
14.3.3 计算每年的销售单数和销售总额
本小节统计所有订单中每年的销售单数和销售总额。三张表连接后,以count(distinct a.ordernumber)统计销售单数、sum(b.amount)统计销售总额。
在spark-shell命令行中执行以下语句:
spark.sql("
SELECT c.theyear,
COUNT(DISTINCT a.ordernumber),
SUM(b.amount)
FROM tbStock a
JOIN tbStockDetail b
ON a.ordernumber = b.ordernumber
JOIN tbDate c
ON a.dateid = c.dateid
GROUP BY c.theyear
ORDER BY c.theyear desc
").show
执行以上语句,输出结果为:
+-------+---------------------------+--------------------+
|theyear|count(DISTINCT ordernumber)| sum(amount)|
+-------+---------------------------+--------------------+
| 2020| 94| 210949.65999999995|
| 2019| 2619| 6323697.189999991|
| 2018| 4861|1.4674295299999997E7|
| 2017| 4885|1.6719354559999991E7|
| 2016| 3772| 1.36809829E7|
| 2015| 3828| 1.325756415000001E7|
| 2014| 1094| 3268115.499200004|
+-------+---------------------------+--------------------+
14.3.4 查询每年最大金额的订单及其金额
本小节完成统计每年最大金额订单的销售额,统计分为两个步骤进行。
(1)统计每年每个订单一共有多少销售额。在spark-shell命令行中执行以下语句:
spark.sql("
SELECT a.dateid,
a.ordernumber,
SUM(b.amount) AS SumOfAmount
FROM tbStock a
JOIN tbStockDetail b
ON a.ordernumber = b.ordernumber
GROUP BY a.dateid, a.ordernumber
ORDER BY a.dateid desc
").show
执行以上语句,输出结果为:
+--------+------------+------------------+
| dateid| ordernumber| SumOfAmount|
+--------+------------+------------------+
|2020-1-9|LZSL00016335| 1096.0|
|2020-1-9|TSSL00016329| 4542.0|
|2020-1-9|RMSL00016334| 2174.0|
|2020-1-9|SSSL00016327| 6883.4|
|2020-1-9|GHSL00016326| 1427.0|
|2020-1-9|DYSL00016336| 498.0|
|2020-1-9|DGSL00016328| 2894.0|
|2020-1-8|DGSL00016324| 2420.0|
|2020-1-8|RMSL00016325| 319.0|
|2020-1-8|LZSL00016321| 349.0|
|2020-1-8|TSSL00016322| 3177.8|
|2020-1-8|SSSL00016320|3781.0999999999995|
|2020-1-8|GHSL00016323| 1148.0|
|2020-1-7|RMSL00016317| 2007.0|
|2020-1-7|LZSL00016315| 697.0|
|2020-1-7|SSSL00016313|1793.0799999999997|
|2020-1-7|TSSL00016319| 1715.0|
|2020-1-7|DGSL00016311| 808.0|
|2020-1-7|DYSL00016316| 658.0|
|2020-1-7|GHSL00016318| 937.0|
+--------+------------+------------------+
only showing top 20 rows
(2)以上一步的查询结果为基础表,与表tbDate使用dateid字段进行Join操作,求出每年最大金额订单的销售额。在spark-shell命令行中执行以下语句:
spark.sql("
SELECT theyear,
MAX(c.SumOfAmount) AS SumOfAmount
FROM
(SELECT a.dateid,
a.ordernumber,
SUM(b.amount) AS SumOfAmount
FROM tbStock a
JOIN tbStockDetail b
ON a.ordernumber = b.ordernumber
GROUP BY a.dateid, a.ordernumber ) c
JOIN tbDate d
ON c.dateid = d.dateid
GROUP BY theyear
ORDER BY theyear DESC
").show
执行以上语句,输出结果为:
+-------+------------------+
|theyear| SumOfAmount|
+-------+------------------+
| 2020|13065.280000000002|
| 2019|25813.200000000008|
| 2018| 55828.0|
| 2017| 159126.0|
| 2016| 36124.0|
| 2015|38186.399999999994|
| 2014| 23656.79999999997|
+-------+------------------+
14.3.5 计算每年最畅销的货品
本小节统计每年最畅销的货品(哪个货品销售额amount在当年最高,哪个就是最畅销的 货品)。
(1)先求出每年每个货品的销售额。在spark-shell命令行中执行以下语句:
spark.sql("
SELECT c.theyear,
b.itemid,
SUM(b.amount) AS SumOfAmount
FROM tbStock a
JOIN tbStockDetail b
ON a.ordernumber = b.ordernumber
JOIN tbDate c
ON a.dateid = c.dateid
GROUP BY c.theyear, b.itemid
ORDER BY c.theyear DESC
").show
执行以上语句,输出结果为:
+-------+--------------+-----------+
|theyear| itemid|SumOfAmount|
+-------+--------------+-----------+
| 2020|01127157980401| 58.0|
| 2020|84127374060306| 58.0|
| 2020|YL428437620101| 198.0|
| 2020|JX329467480104| 1276.2|
| 2020|79126117060102| 58.0|
| 2020|04128137019202| 120.0|
| 2020|SN828409520181| 158.0|
| 2020|DP219372102201| 319.0|
| 2020|BM217392020101| 150.0|
| 2020|77926452010181| 238.0|
| 2020|00160000000000| 26.0|
| 2020|QY128121070406| 98.0|
| 2020|QY128111059202| 58.0|
| 2020|ZX219359720101| 358.0|
| 2020|JX329459410106| 399.0|
| 2020|30627235871007| 10.0|
| 2020|XR127168310306| 232.0|
| 2020|QY127170120704| 58.0|
| 2020|JX329467870201| 957.2|
| 2020|QY128136080402| 98.0|
+-------+--------------+-----------+
only showing top 20 rows
(2)在上一步的基础上,统计每年单个货品中的最大金额。在spark-shell命令行窗口中执行以下语句:
spark.sql("
SELECT d.theyear,
MAX(d.SumOfAmount) AS MaxOfAmount
FROM
(SELECT c.theyear,
b.itemid,
SUM(b.amount) AS SumOfAmount
FROM tbStock a
JOIN tbStockDetail b
ON a.ordernumber = b.ordernumber
JOIN tbDate c
ON a.dateid = c.dateid
GROUP BY c.theyear, b.itemid ) d
GROUP BY d.theyear
ORDER BY d.theyear desc
").show
执行以上语句,输出结果为:
+-------+------------------+
|theyear| MaxOfAmount|
+-------+------------------+
| 2020| 4494.0|
| 2019| 30029.2|
| 2018| 98003.59999999995|
| 2017| 70225.1|
| 2016|113720.60000000005|
| 2015| 56627.33000000001|
| 2014| 53401.76|
+-------+------------------+
14.4 Spark SQL金融数据分析
在金融领域,对时间序列数据的统计分析至关重要。某金融机构拥有大量股票交易数据,包括每日的开盘价、收盘价、最高价、最低价和交易量等。为了评估股票的表现,预测市场趋势,该机构决定利用Apache Spark进行深度统计分析。
面对海量的交易数据,Spark的分布式计算能力显得尤为重要。机构的技术团队利用Spark读取存储于Hadoop分布式文件系统(HDFS)中的交易数据,并转换为DataFrame。随后,他们利用Spark SQL和DataFrame API计算了股票价格的最大值、最小值、平均值和标准差,以评估价格的波动情况。
此外,为了更深入地了解数据的分布情况,团队还计算了中位数和四分位数。这些统计值不仅有助于识别数据的异常值,还能为制定投资策略提供重要参考。通过Spark,该金融机构成功实现了对大规模金融数据的快速统计分析,为市场预测和风险管理提供了有力支持。
14.4.1 数据准备
为了让读者直观了解本次实战案例的数据和字段类型,我们将数据和字段类型以图片形式进行展示。其中,图14-21所示是本次实验的表格和字段,前10条案例数据是以CSV文件进行存储的,文件名为DataAnalysis.csv。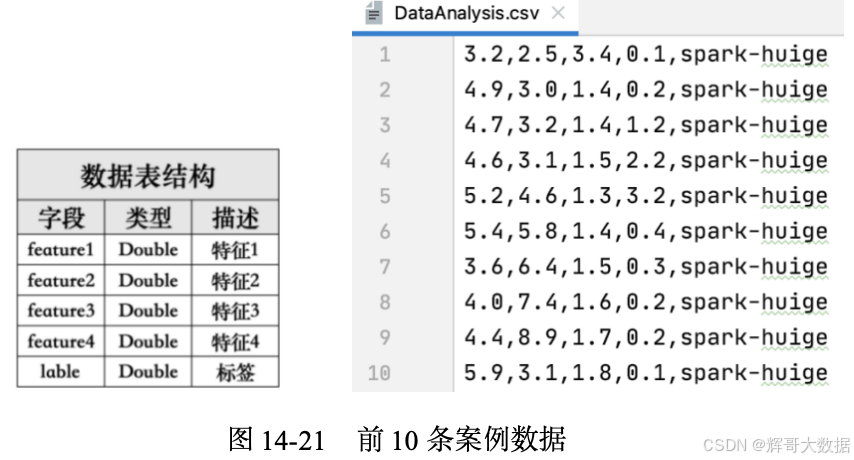
通过Spark读取DataAnalysis.csv数据,并得到一个DataFrame,示例代码如代码14-8所示。
代码14-8 DataAnalysis.scala
import org.apache.spark.sql.functions._
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, SparkSession}
case class DataAnalysis(feature1: Double, feature2: Double, feature3: Double, feature4: Double, label: String)
object DataAnalysis {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession
.builder()
.appName("")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val lines = spark.sparkContext.textFile("doc/DataAnalysis.csv")
// 将RDD关联了Schema,但依然是RDD
val dataDF: DataFrame = lines.map(line => {
val fields = line.split(",")
DataAnalysis(fields(0).toDouble, fields(1).toDouble, fields(2).toDouble, fields(3).toDouble, fields(4))
}).toDF()
// 显示全部值
dataDF.show()
}
}
执行上述代码,执行结果如图14-22所示。
14.4.2 最大值和最小值
使用Spark SQL统计最大值或最小值,首先使用agg函数对数据进行聚合,这个函数一般配合group by使用。如果不使用group by,就相当于对所有的数据进行聚合。
随后,直接使用max和min函数聚合就可以。想要输出多个结果,中间用逗号分开,并使用as给聚合后的结果赋予一个列名,相当于SQL中的as:
import spark.implicits._
dataDF.agg(max($"feature1") as "max_feature1",
min($"feature2") as "min_feature2")
.show()
执行结果如下:
+------------+------------+
|max_feature1|max_feature2|
+------------+------------+
| 9.5| 1.5|
+------------+------------+
上面代码中的$代表一列,相当于col函数:
import spark.implicits._
dataDF.agg(max(col("feature1")) as "max_feature1",
min(col("feature2")) as "min_feature2")
.show()
14.4.3 平均值
平均值的计算使用mean函数:
dataDF.agg(mean($"feature1") as "mean_feature1",
mean($"feature2") as "mean_feature2")
.show()
执行结果如图14-23所示。
14.4.4 样本标准差和总体标准差
样本标准差的计算可以使用stddev函数和stddev_samp函数,而总体标准差可以使用stddev_pop方法。需要注意的是,这里的函数和Hive SQL还是存在区别的。在Hive SQL中,stddev函数代表的是总体标准差;而在Spark SQL中,stddev函数代表的是样本标准差。我们可以查看一下源代码,如图14-24所示。
通过代码验证一下:
dataDF.agg(stddev($"feature1") as "stddev_feature1",
stddev_pop($"feature1") as "stddev_pop_feature1",
stddev_samp($"feature1") as "stddev_samp_feature1")
.show()
执行结果如图14-25所示。
14.4.5 中位数
Spark SQL中没有直接计算中位数的方法,所以我们借鉴14.4.4节的思路,来回顾一下。计算中位数也好,计算四分位数也好,无非就是要取得两个位置。假设我们的数据从小到大排,按照1, 2, 3, …, n进行编号。当数量n为奇数时,取编号(n + 1)/2位置的数即可;当n为偶数时,取(int)(n + 1)/2位置和(int)(n + 1)/2 + 1位置的数的平均值即可。但二者其实可以统一到一个公式中:
(1)假设n = 149(奇数),(n+1)/2=75,小数部分为0,那么中位数=75位置的数×(1 − 0)+76位置的数×(0 − 0)。
(2)假设n = 150(偶数),(n+1)/2=75.5,小数部分为0.5,那么中位数=75位置的数×(1 − 0.5)+76位置的数×(0.5 − 0)。
因此,可以把这个过程分解为三个步骤:第一步是给数字进行编号,Spark中同样使用row_number()函数(该函数的具体用法后续再展开,这里只提供一个简单的例子);第二步是计算(n+1)/2的整数部分和小数部分;第三步是根据公式计算中位数。
首先使用row_number()函数给数据进行编号:
val windowFun = Window.orderBy(col("feature3").asc)
dataDF.withColumn("rank",row_number().over(windowFun)).show(false)
执行结果如图14-26所示。
接下来确定中位数的位置,这里我们分别拿到(n + 1)/2的整数部分和小数部分:
val median_index = dataDF.agg(
((count($"feature3") + 1) / 2).cast("int") as "rank",
((count($"feature3") + 1) / 2 % 1) as "float_part"
)
median_index.show()
执行结果如图14-27所示。
这里小数部分不为0,意味着我们不仅要拿到rank=75的数,还要拿到rank=76的数。我们最好把其放到一行上,这里同样使用lead函数,lead函数的作用就是拿到分组排序后,下一个位置或下n个位置的数。我们在后面还会细讲,这里只是抛砖引玉:
val windowFun = Window.orderBy(col("feature3").asc)
dataDF.withColumn("next_feature3", lead(col("feature3"), 1).over(windowFun)).show(false)
执行结果如图14-28所示。
接下来Join两个表,按公式计算中位数就可以了。完整的代码如下:
val median_index = dataDF.agg(
((count($"feature3") + 1) / 2).cast("int") as "rank",
((count($"feature3") + 1) / 2 % 1) as "float_part"
)
dataDF.withColumn("next_feature3", lead(col("feature3"), 1).over(windowFun)).show(false)
dataDF.withColumn("rank", row_number().over(windowFun))
.withColumn("next_feature3", lead(col("feature3"), 1).over(windowFun))
.join(median_index, Seq("rank"), "inner")
.withColumn("median", ($"float_part" - lit(0)) * $"next_feature3" + (lit(1) - $"float_part") * $"feature3")
.show()
执行结果如图14-29所示。
14.4.6 四分位数
先来复习一下四分位数的两种解法:n+1方法和n−1方法。
对于n+1方法,如果数据量为n,则四分位数的位置为:
- Q1的位置= (n+1)×0.25。
- Q2的位置= (n+1)×0.5。
- Q3的位置= (n+1)×0.75。
对于n−1方法,如果数据量为n,则四分位数的位置为: - Q1的位置=1+(n−1)× 0.25。
- Q2的位置=1+(n−1)× 0.5。
- Q3的位置=1+(n−1)×0.75。
这里的思路和求解中位数的思路是一样的,我们分别实现这两种方法。首先是n+1方法:
val windowFun = Window.orderBy(col("feature3").asc)
val q1_index = dataDF.agg(
((count($"feature3") + 1) * 0.25).cast("int") as "rank",
((count($"feature3") + 1) * 0.25 % 1) as "float_part"
)
dataDF.withColumn("rank", row_number().over(windowFun))
.withColumn("next_feature3", lead(col("feature3"), 1).over(windowFun))
.join(q1_index, Seq("rank"), "inner")
.withColumn("q1", ($"float_part" - lit(0)) * $"next_feature3" + (lit(1) - $"float_part") * $"feature3")
.show()
执行结果如图14-30所示。
接下来是n−1方法:
val windowFun = Window.orderBy(col("feature3").asc)
val q1_index_sub = dataDF.agg(
((count($"feature3") - 1) * 0.25).cast("int") as "rank",
((count($"feature3") - 1) * 0.25 % 1) as "float_part"
)
dataDF.withColumn("rank", row_number().over(windowFun))
.withColumn("next_feature3", lead(col("feature3"), 1).over(windowFun))
.join(q1_index_sub, Seq("rank"), "inner")
.withColumn("q1", ($"float_part" - lit(0)) * $"next_feature3" + (lit(1) - $"float_part") * $"feature3")
.show()
执行结果如图14-31所示。
14.5 本章小结
本章通过4个Spark实战案例,全面展示了Spark在不同领域的应用价值。在Spark Core日志统计案例中,我们掌握了处理和分析大规模日志数据的方法。通过日志分析可视化案例,我们学会了如何将分析结果以直观的方式呈现,增强了数据的可读性和洞察力。电商实战案例让我们领略了Spark SQL在处理电商大数据时的强大功能,为业务决策提供了有力支持。而数据分析案例则展示了Spark SQL在复杂数据分析任务中的广泛应用和卓越性能。这些案例不仅加深了我们对Spark的理解,也提升了我们的实战技能。
本书其他章节
- Spark大数据开发与应用案例(视频教学版)(一)–文前
- Spark大数据开发与应用案例(视频教学版)(二)–第一章上
- Spark大数据开发与应用案例(视频教学版)(三)–第一章下
- Spark大数据开发与应用案例(视频教学版)(四)–第二章上
- Spark大数据开发与应用案例(视频教学版)(五)–第二章下
- Spark大数据开发与应用案例(视频教学版)(六)–第三章上
- Spark大数据开发与应用案例(视频教学版)(七)–第三章下
- Spark大数据开发与应用案例(视频教学版)(八)–第四章上
- Spark大数据开发与应用案例(视频教学版)(九)–第四章下
- Spark大数据开发与应用案例(视频教学版)(十)–第五章
- Spark大数据开发与应用案例(视频教学版)(十一)–第六章
- Spark大数据开发与应用案例(视频教学版)(十二)–第七章
- Spark大数据开发与应用案例(视频教学版)(十三)–第八章
- Spark大数据开发与应用案例(视频教学版)(十四)–第九章
- Spark大数据开发与应用案例(视频教学版)(十五)–第十章上
- Spark大数据开发与应用案例(视频教学版)(十六)–第十章下
- Spark大数据开发与应用案例(视频教学版)(十七)–第十一章
- Spark大数据开发与应用案例(视频教学版)(十八)–第十二章
- Spark大数据开发与应用案例(视频教学版)(十九)–第十三章
- Spark大数据开发与应用案例(视频教学版)(二十)–第十四章
- Spark大数据开发与应用案例(视频教学版)(二十一)–第十五章


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)