超简单!基于PyTorch的高光谱图像分类2D_CNN网络实战
·
高光谱图像分类2D_CNN网络代码 基于pytorch框架制作 全套项目,包含网络模型,训练代码,预测代码,直接下载数据集就能跑,拿上就能用,简单又省事儿 内附indian pines数据集,采用20%数据作为训练集,并附上迭代10次的模型结果,准确率99左右。
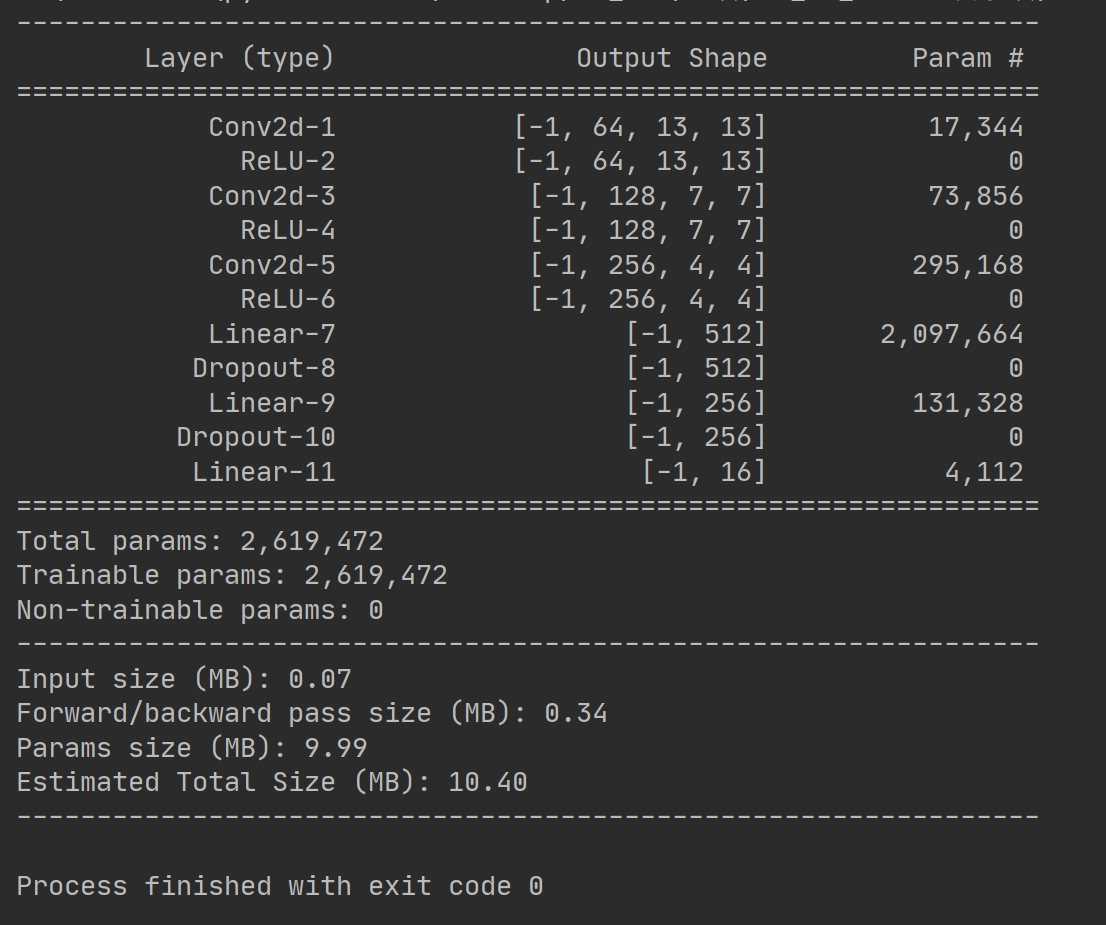
最近在研究高光谱图像分类,发现基于PyTorch框架搭建的2D_CNN网络真是又简单又高效,今天就来和大家分享一下这个全套项目,保证直接下载数据集就能跑,拿上就能用。
一、项目概览
我们这个项目主打就是一个便捷,涵盖了网络模型、训练代码以及预测代码。还贴心地附上了indian pines数据集,并且把20%的数据划分出来作为训练集,经过10次迭代后,模型准确率稳稳达到99%左右。
二、网络模型代码解析
import torch
import torch.nn as nn
class TwoDCNN(nn.Module):
def __init__(self):
super(TwoDCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(32 * 28 * 28, 128)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(128, 16)
def forward(self, x):
out = self.conv1(x)
out = self.relu1(out)
out = self.pool1(out)
out = self.conv2(out)
out = self.relu2(out)
out = self.pool2(out)
out = out.view(-1, 32 * 28 * 28)
out = self.fc1(out)
out = self.relu3(out)
out = self.fc2(out)
return out
这段代码定义了我们的2D_CNN网络模型。TwoDCNN类继承自nn.Module,这是PyTorch中所有神经网络模块的基类。
- 在
init函数里,我们定义了网络的各个层。首先是两个卷积层conv1和conv2,nn.Conv2d用于创建二维卷积层,第一个参数是输入通道数,这里因为高光谱图像是单通道(在这个例子里简化处理),所以初始为1;第二个参数是输出通道数,分别为16和32;kernel_size是卷积核大小,padding为1保证卷积后图像尺寸不变。 - 接着是
ReLU激活函数relu1、relu2、relu3,用来给模型引入非线性。 - 然后是池化层
pool1和pool2,nn.MaxPool2d进行最大池化操作,缩小图像尺寸同时保留重要特征。 - 最后是两个全连接层
fc1和fc2,将池化后的特征图展平后连接到全连接层进行分类。
forward函数定义了数据在网络中的前向传播路径,依次经过各个层的操作得到最终输出。
三、训练代码
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from model import TwoDCNN
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载数据集
train_dataset = datasets.ImageFolder(root='train_data_path', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 初始化模型、损失函数和优化器
model = TwoDCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
在训练代码部分:
- 首先对数据进行预处理,
transforms.ToTensor()将图像数据转换为PyTorch的张量格式,transforms.Normalize对数据进行归一化,这里均值和标准差都设为0.5。 - 然后通过
datasets.ImageFolder加载训练数据集,并用DataLoader将其包装成可迭代的数据加载器,设置batch_size为32并打乱数据顺序。 - 接着初始化我们刚刚定义的模型
TwoDCNN,选择交叉熵损失函数nn.CrossEntropyLoss,优化器选用Adam,学习率设为0.001。 - 在训练循环中,每次迭代都先将梯度清零,通过模型得到预测输出,计算损失,反向传播计算梯度,最后更新模型参数。每一轮结束打印当前轮次的平均损失。
四、预测代码
import torch
from torchvision import datasets, transforms
from model import TwoDCNN
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载测试数据集
test_dataset = datasets.ImageFolder(root='test_data_path', transform=transform)
test_loader = DataLoader(test_dataset, batch_size=32)
# 加载训练好的模型
model = TwoDCNN()
model.load_state_dict(torch.load('trained_model.pth'))
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the test images: {100 * correct / total}%')
预测代码相对简洁:
- 同样先对数据进行预处理。
- 加载测试数据集并包装成数据加载器。
- 加载训练好的模型权重,将模型设为评估模式
model.eval()。 - 在不计算梯度的情况下,对测试数据进行预测,通过
torch.max找到预测概率最大的类别,统计正确预测的数量并计算准确率。
有了这一套代码,再加上我们提供的indian pines数据集,直接就能开启高光谱图像分类之旅啦,是不是很方便呢!快来试试吧。
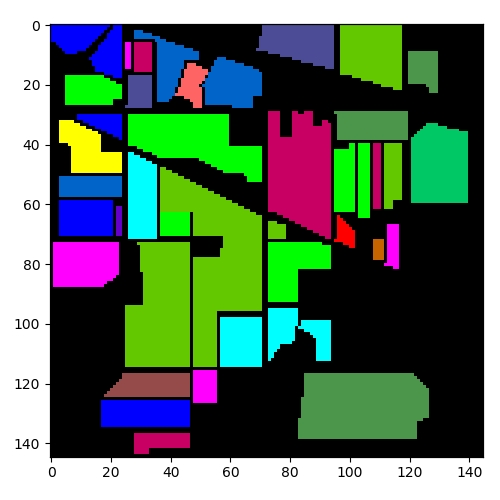
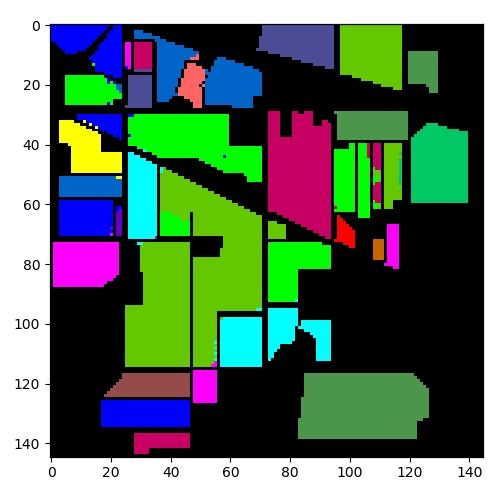

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)