【大模型开发】在线大模型本地开发实战
开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。开发大模型相关应用,其技术核心点虽然在大语言模型上,但一般通过调用 API 或开源模型来实现核心的理解与生成,通过 Prompt Enginnering 来实现大语言模型的控制,因此,大模型虽然是深度学习领域的集大成之作,大模型开发却更多是一个工程问题。

✨✨ 欢迎大家来到景天科技苑✨✨
🎈🎈 养成好习惯,先赞后看哦~🎈🎈
🏆 作者简介:景天科技苑
🏆《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。
🏆《博客》:Rust开发,Python全栈,Golang开发,云原生开发,PyQt5和Tkinter桌面开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生K8S,linux,shell脚本等实操经验,网站搭建,数据库等分享。所属的专栏:Rust高性能并发编程
景天的主页:景天科技苑

文章目录
大模型开发
一、大模型的基本概念
大语言模型(Large Language Model): 通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-5 模型。
这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
大模型(Large Model)是指拥有数十亿乃至上万亿参数的机器学习模型。参数越多,模型能学习和表达的知识、模式、关系就越复杂。
它们通常基于神经网络结构(尤其是 Transformer 架构),通过对海量数据的训练,学习语言、图像、代码、声音等不同模态的特征。
核心特点
参数规模巨大:
从最初几百万到如今上万亿级别的参数,模型具备更强的拟合与推理能力。
预训练 + 微调机制:
先在通用大数据集上进行预训练,再在特定领域数据上进行微调,以适应不同任务。
多任务泛化能力:
不再局限于单一任务,可以在问答、翻译、摘要、推理、编程等任务中表现优异。
涌现能力(Emergent Abilities):
当参数规模达到一定程度后,模型会展现出在小模型中未出现的新能力,如逻辑推理、复杂指令理解等。
工作原理(以语言大模型为例)
模型架构:Transformer
利用自注意力机制(Self-Attention),让模型能够理解上下文中的依赖关系。
训练阶段:语言建模任务
模型通过预测“下一个词”的方式,在大量语料中学习语言结构和世界知识。
推理阶段:生成与理解
训练完成后,模型能根据输入(Prompt)生成合理的输出,如回答问题或撰写文本。
应用场景
自然语言处理(NLP):聊天机器人、搜索引擎、机器翻译、文本摘要
多模态理解:图文生成(如 DALL·E)、语音识别、视频理解
企业智能化:代码生成、文档总结、自动客服、知识管理
科研与创新:药物分子设计、材料发现、自动证明等
二、大模型分类
按照输入数据类型的不同,大模型的分类:
- 语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。
这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。
例如:GPT 系列(OpenAI)、Bard(Google)、文心一言(百度)。 - 视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。
这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。
例如:VIT 系列(Google)、文心UFO、华为盘古 CV、INTERN(商汤)。 - 多模态大模型: 是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。
这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。
例如:DingoDB 多模向量数据库(九章云极 DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
- 通用大模型 L0:是指可以在多个领域和任务上通用的大模型。
它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法,在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三”的强大泛化能力,
可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI 完成了“通识教育”。 - 行业大模型 L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于 AI 成为“行业专家”。
- 垂直大模型 L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
三、大模型开发
1)大模型开发介绍
开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。
开发大模型相关应用,其技术核心点虽然在大语言模型上,但一般通过调用 API 或开源模型来实现核心的理解与生成,通过 Prompt Enginnering 来实现大语言模型的控制,
因此,大模型虽然是深度学习领域的集大成之作,大模型开发却更多是一个工程问题。
在大模型开发中,我们一般不会去大幅度改动模型,而是将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,
适配应用任务,而不会将精力聚焦在优化模型本身上。
2)大模型开发与传统的AI开发的不同
大模型开发与传统的AI 开发在整体思路上有着较大的不同:
传统AI 开发:首先需要将复杂的业务逻辑依次拆解,对于每个子业务构造训练数据与验证数据,对于每个子业务训练优化模型,最后形成完整的模型链路来解决整个业务逻辑。
比如使用fastapi,django等框架调用Yolo模型等,由web框架调用摄像头等。
大模型开发:用 Prompt Engineering 来替代子模型的训练调优,通过 Prompt 链路组合来实现业务逻辑,用一个通用大模型 + 若干业务 Prompt 来解决任务,
从而将传统的模型训练调优转变成了更简单、轻松、低成本的 Prompt 设计调优。
目前大部分企业都是基于 LangChain 、qwen-Agent、lammaIndex框架进行大模型应用开发。
LangChain 提供了 Chain、Tool 、RAG等架构的实现,可以基于 LangChain 进行个性化定制,实现从用户输入到 向量数据库 再到大模型最后输出的整体架构连接。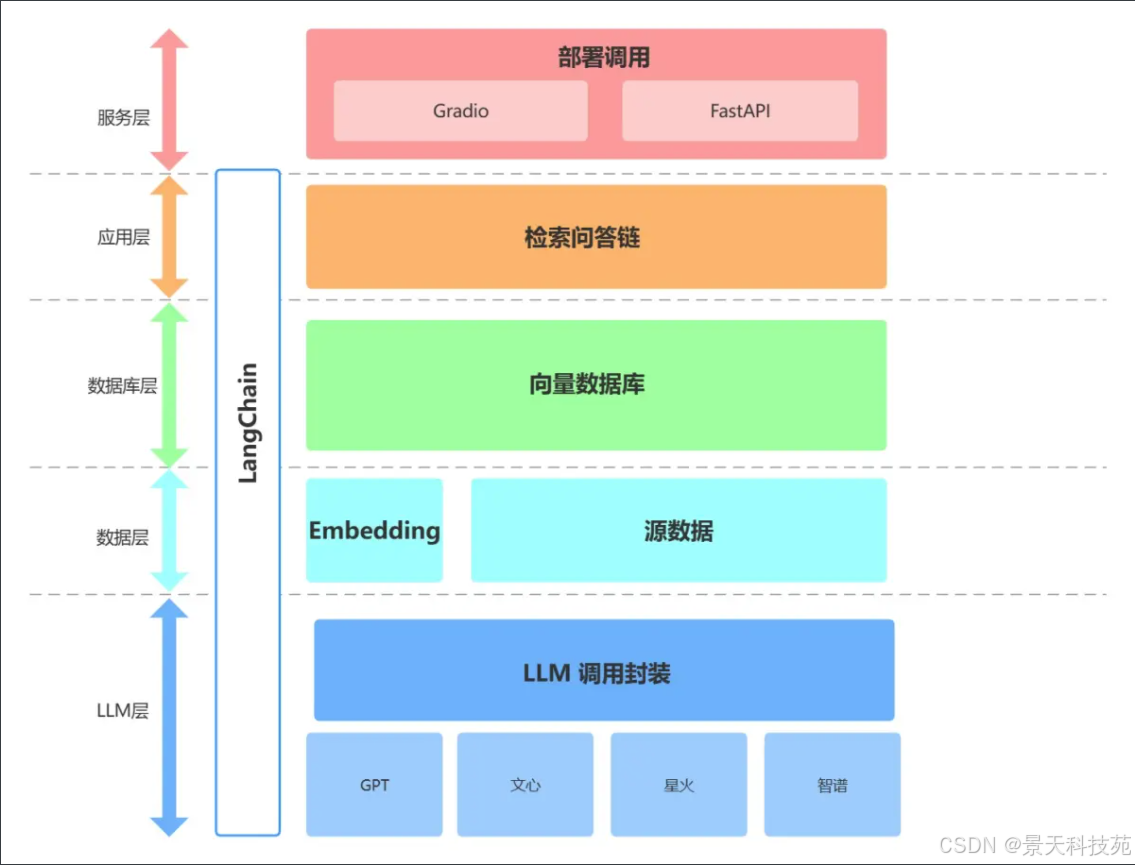
3)在线大模型应用
采用python的langchain/fastgpt大模型框架调用常见的大模型的接口:Chatgpt/月之暗面kimi/通义千问Qwen/百川Baichuan/盘古/文心一言/讯飞星火。
3.1 python调用chatgpt实现问答
在登陆到OpenAPI开发者平台时,左下角可以选择document进入文档界面。
创建一个项目 https://platform.openai.com/settings/organization/projects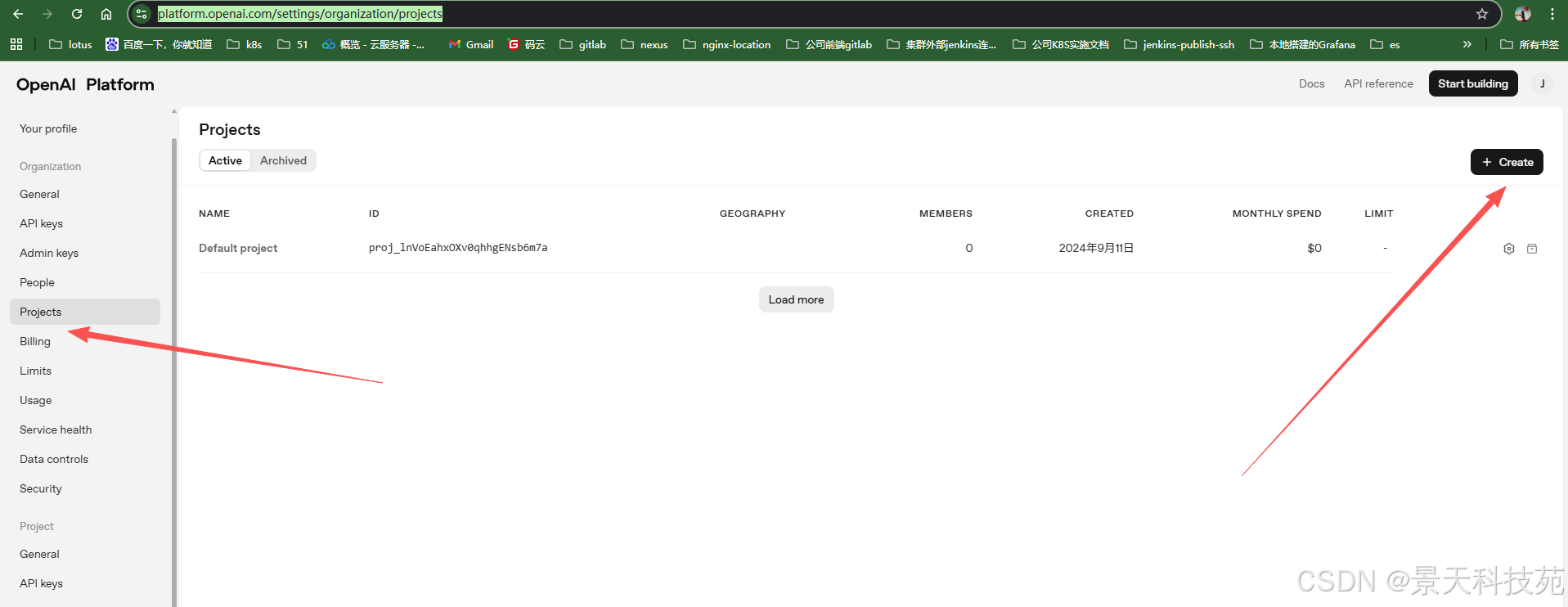
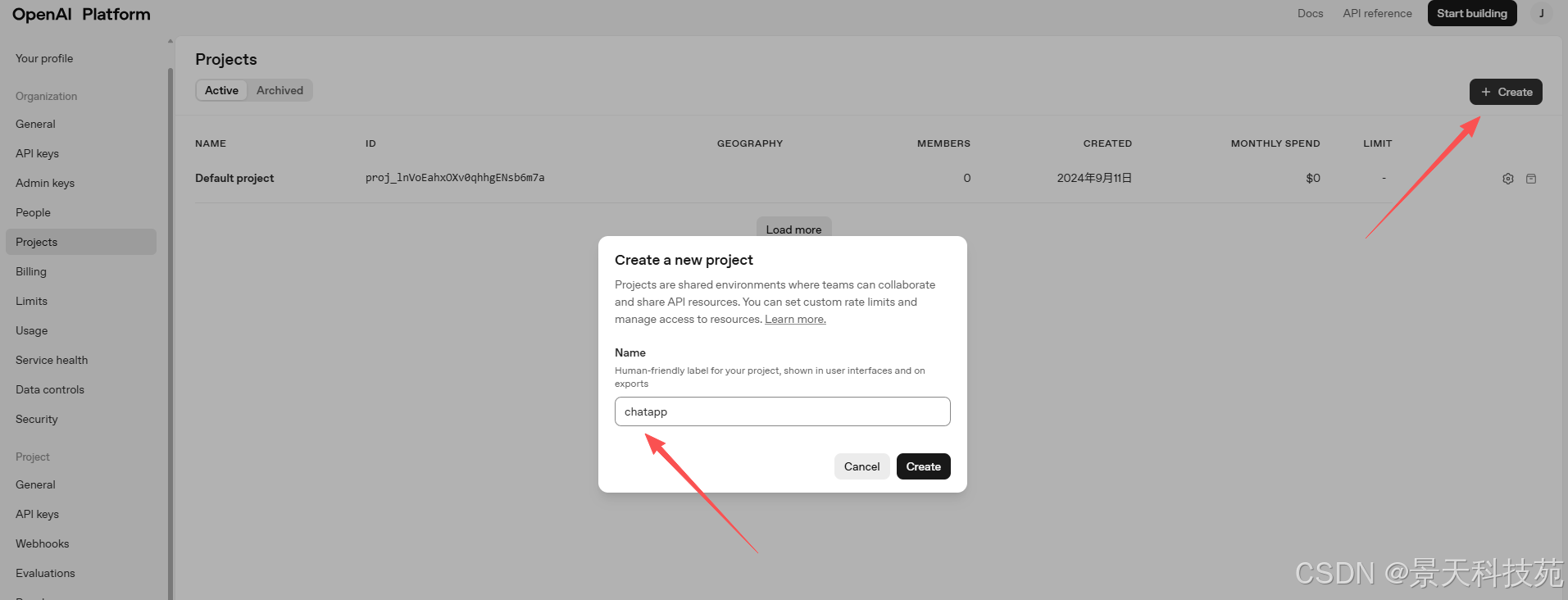
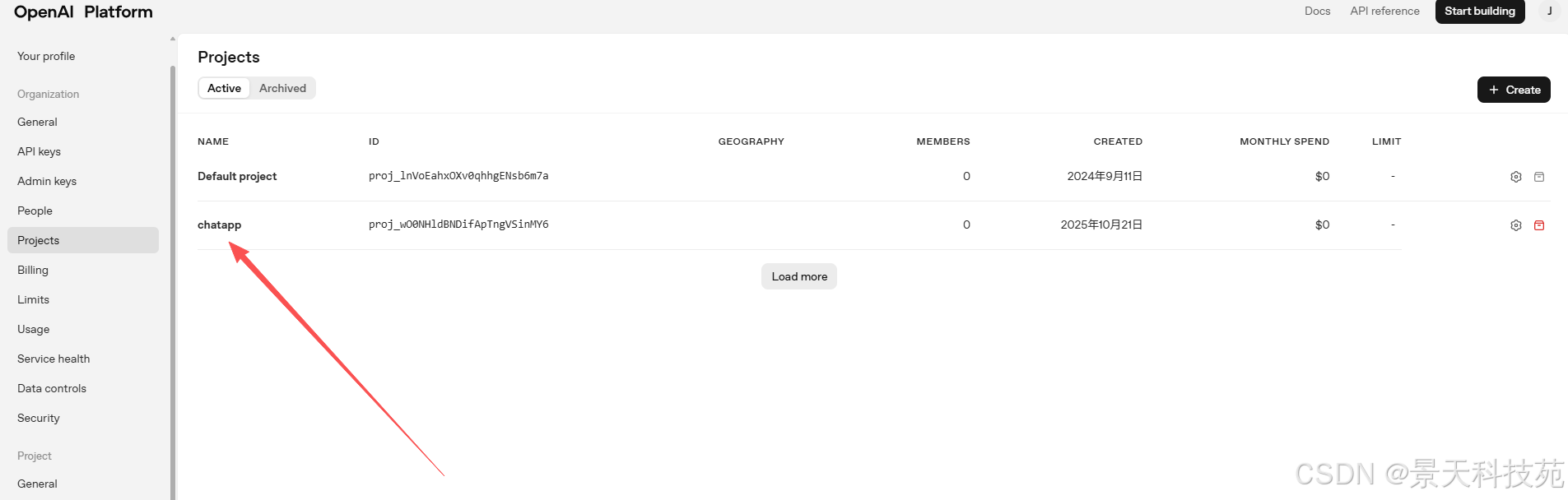
创建apikey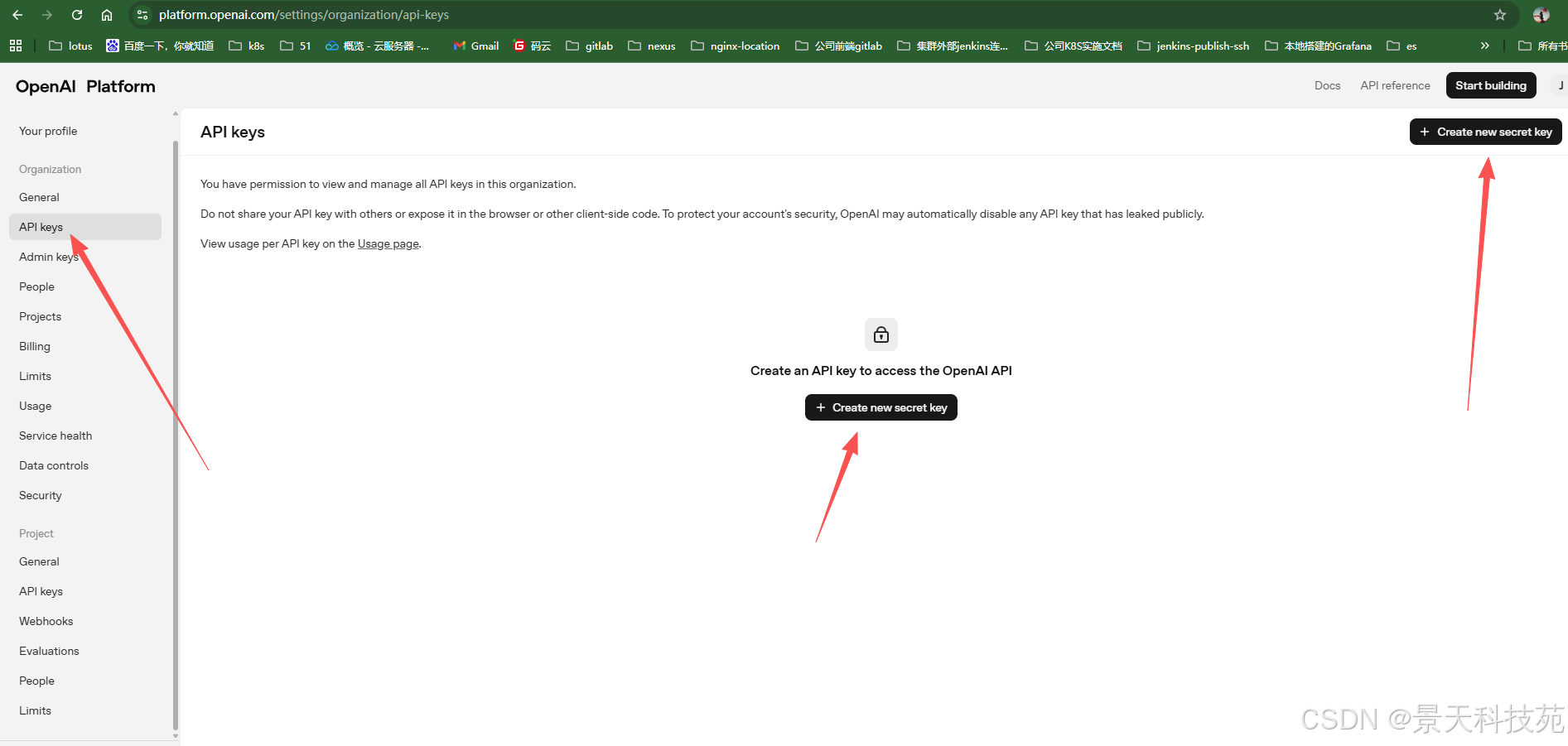
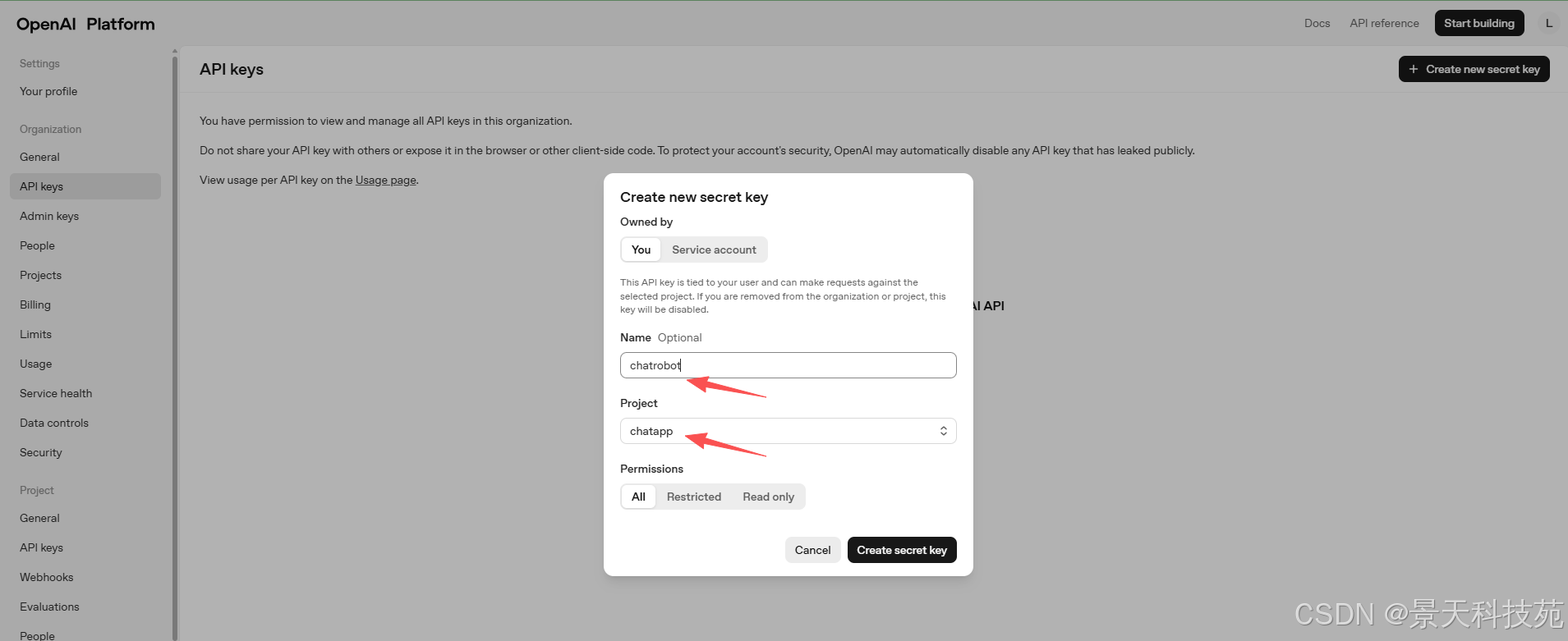
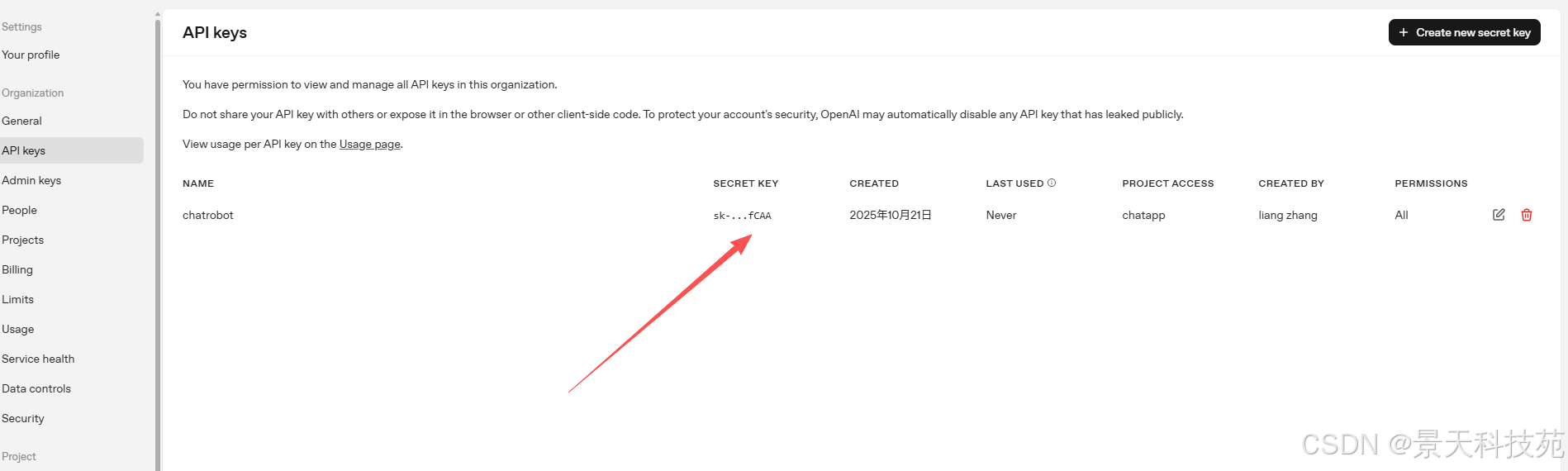
得到一个apikey,记得保存,只有创建时能看到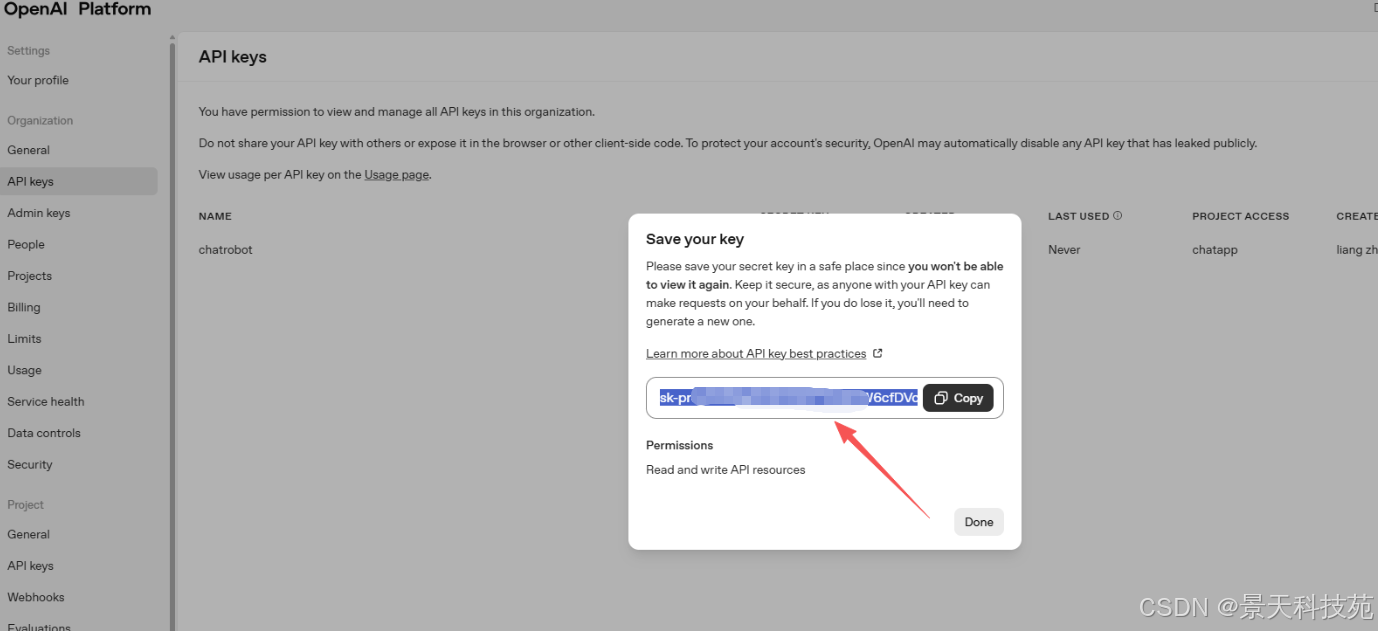
安装openai模块
pip install openai
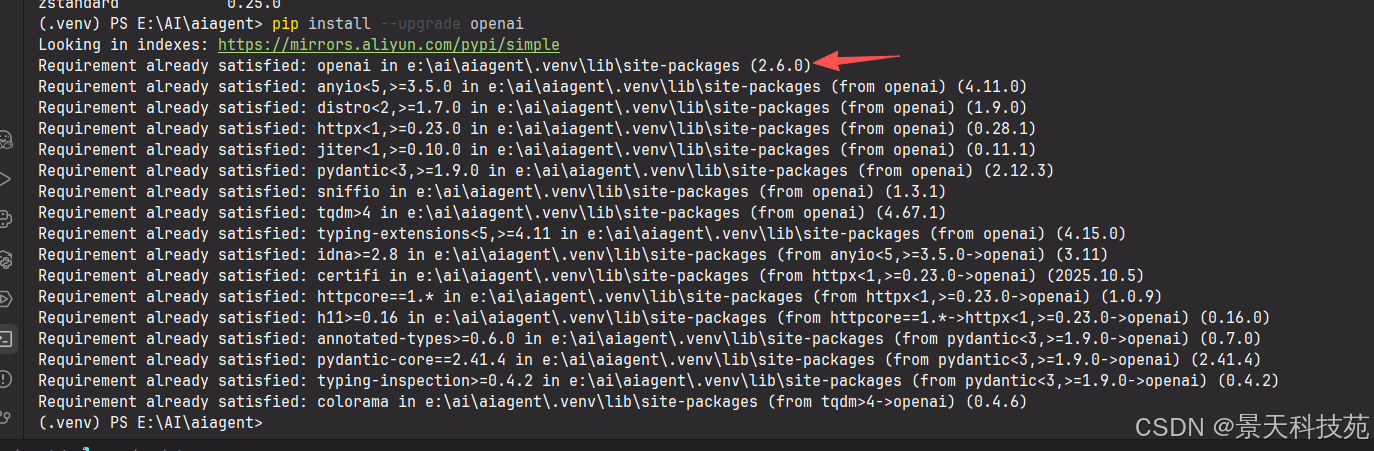
接下来根据官方文档直接调用请求chatgpt即可。注意,官方文档中演示的代码存在缺失,所以需要根据我的代码来调用。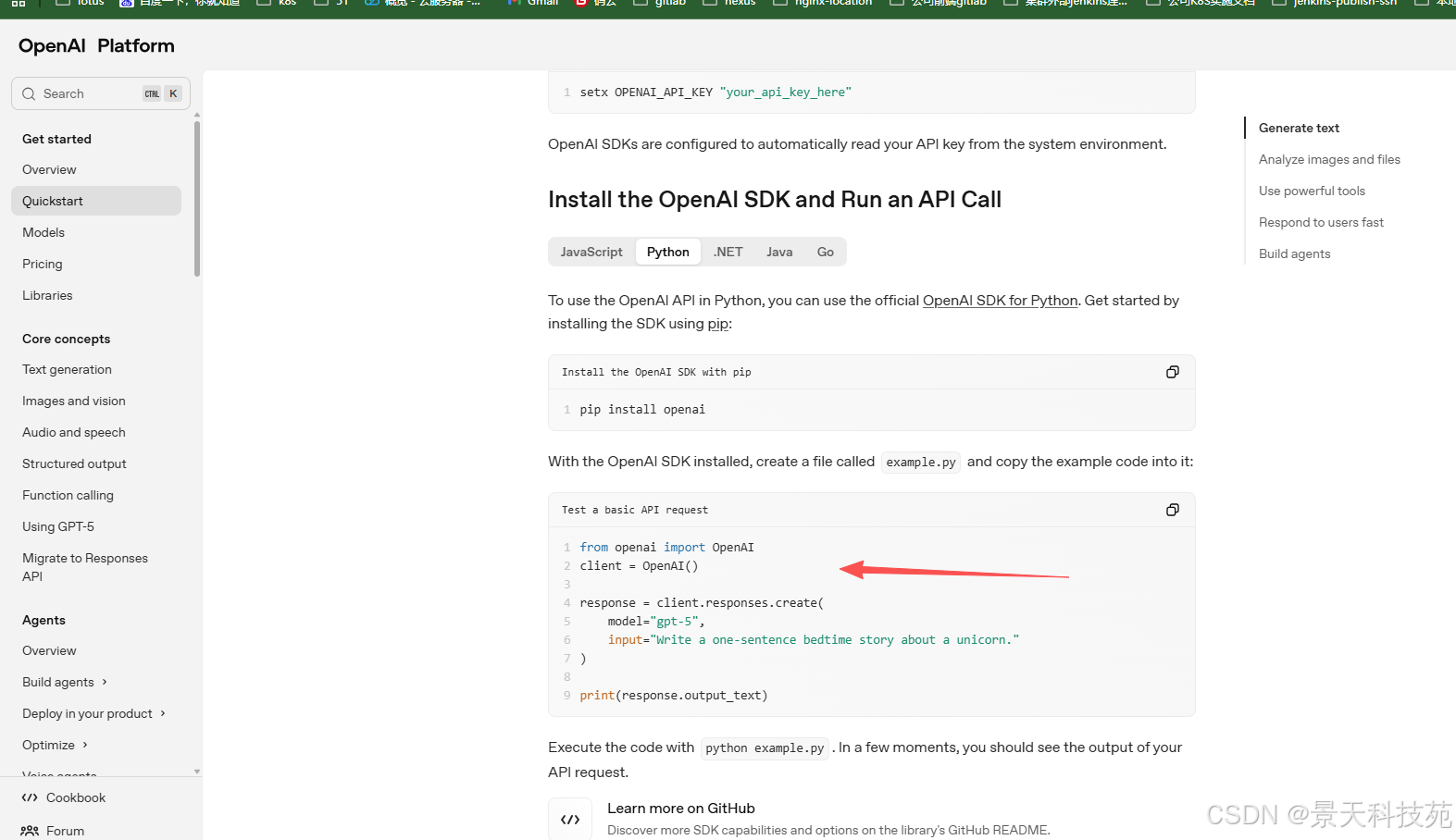
from openai import OpenAI
# 解决请求超时问题
import os
os.environ["http_proxy"] = "http://localhost:7890"
os.environ["https_proxy"] = "http://localhost:7890"
# 需要在实例化OpenAI对象时候,指定秘钥
client = OpenAI(api_key="sk-18q8W3BfIhs9vsgsgshgsdhwerwtwtwei0mBptIVWHQkXOvv")
completion = client.chat.completions.create(
model="gpt-5", # 指定使用的大模型是谁,gpt-5,
messages=[ # 提示词,
# {"role": "身份", "content": "你是一个老师."}, # 让chatgpt充当什么身份
# {"role": "user", "content": "请帮我基于中文."}, # 约束条件或基于什么条件
{"role": "assistant", "content": "编写一段歌颂元宵节的歌词"} # 具体要chatgpt完成的操作了。
]
)
print(completion.choices[0].message)
但是调用chatgpt,账户得有额度,否则调用失败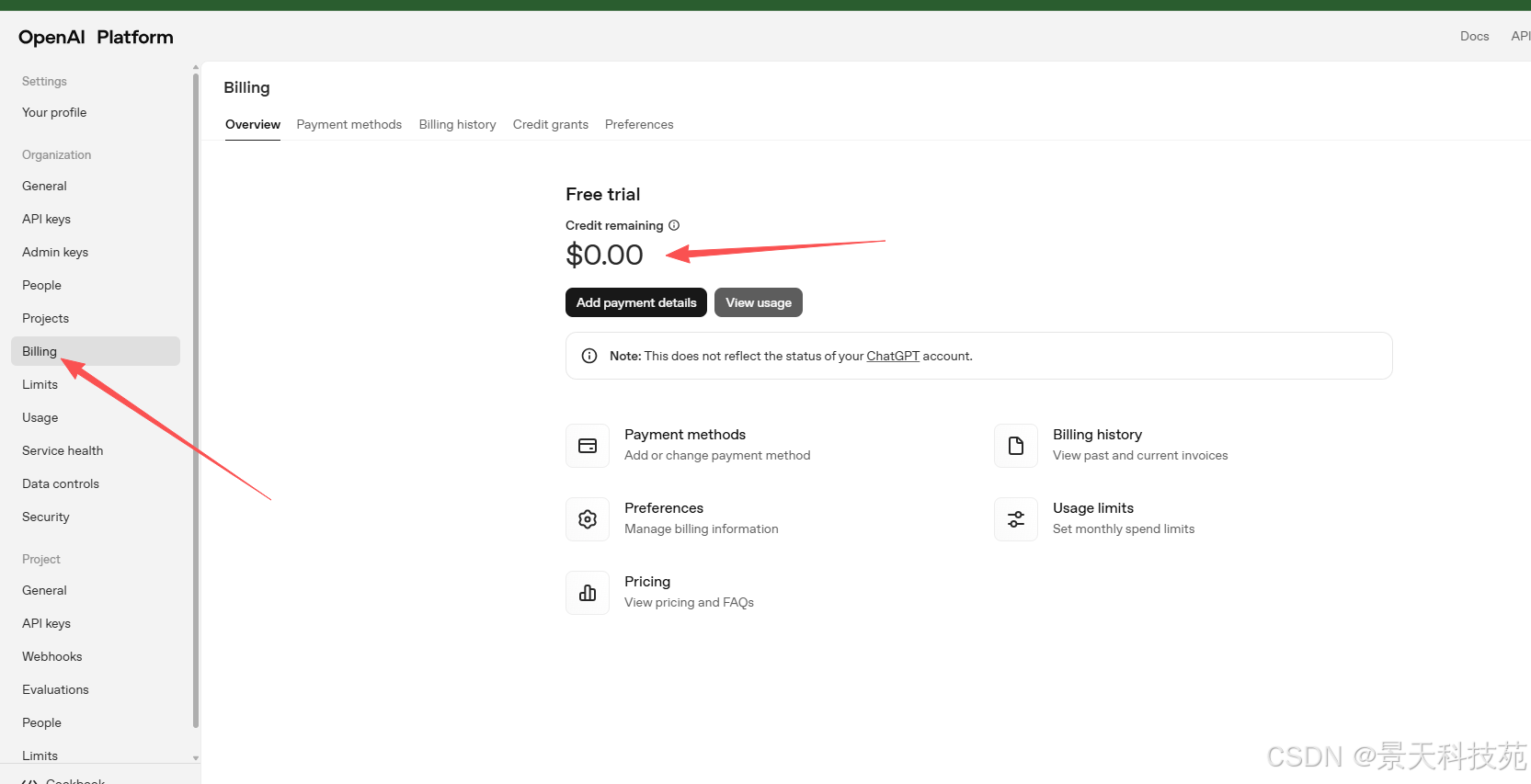
3.2 python调用通义千问
进入通义千问主页,查看API参考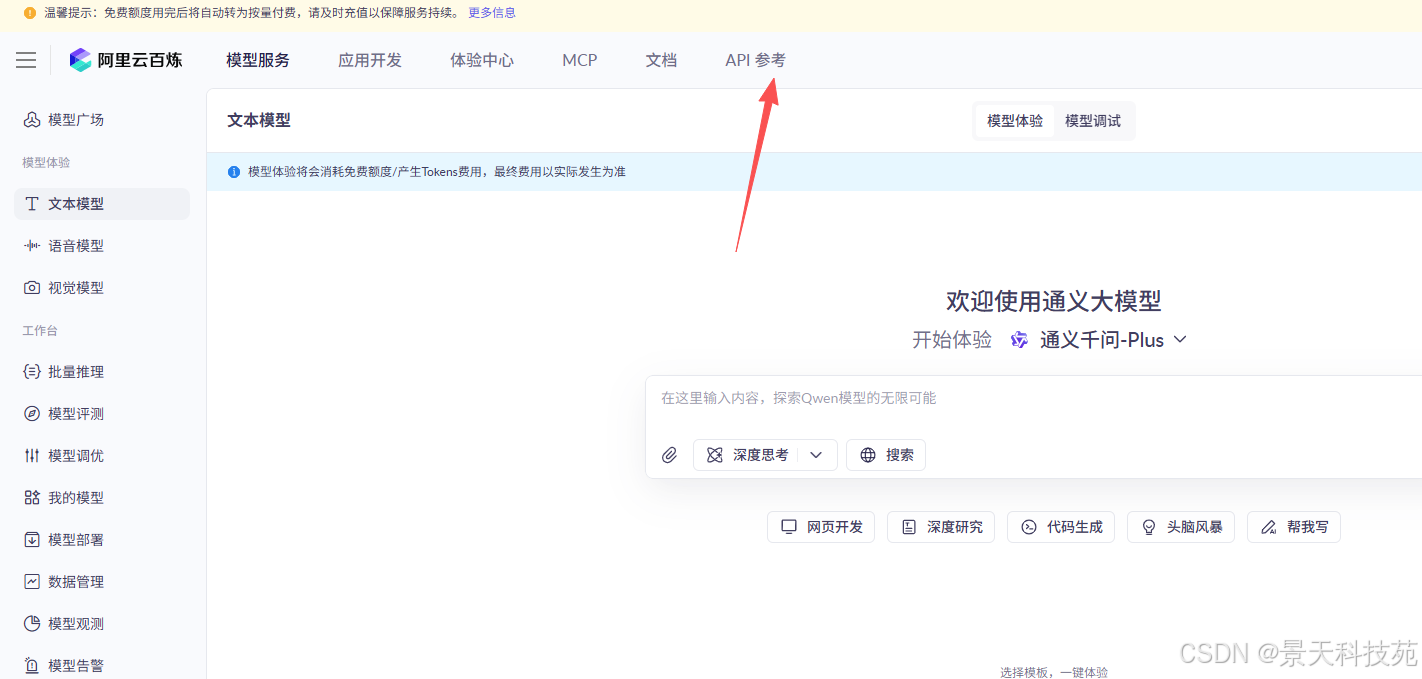
查看获取API key方法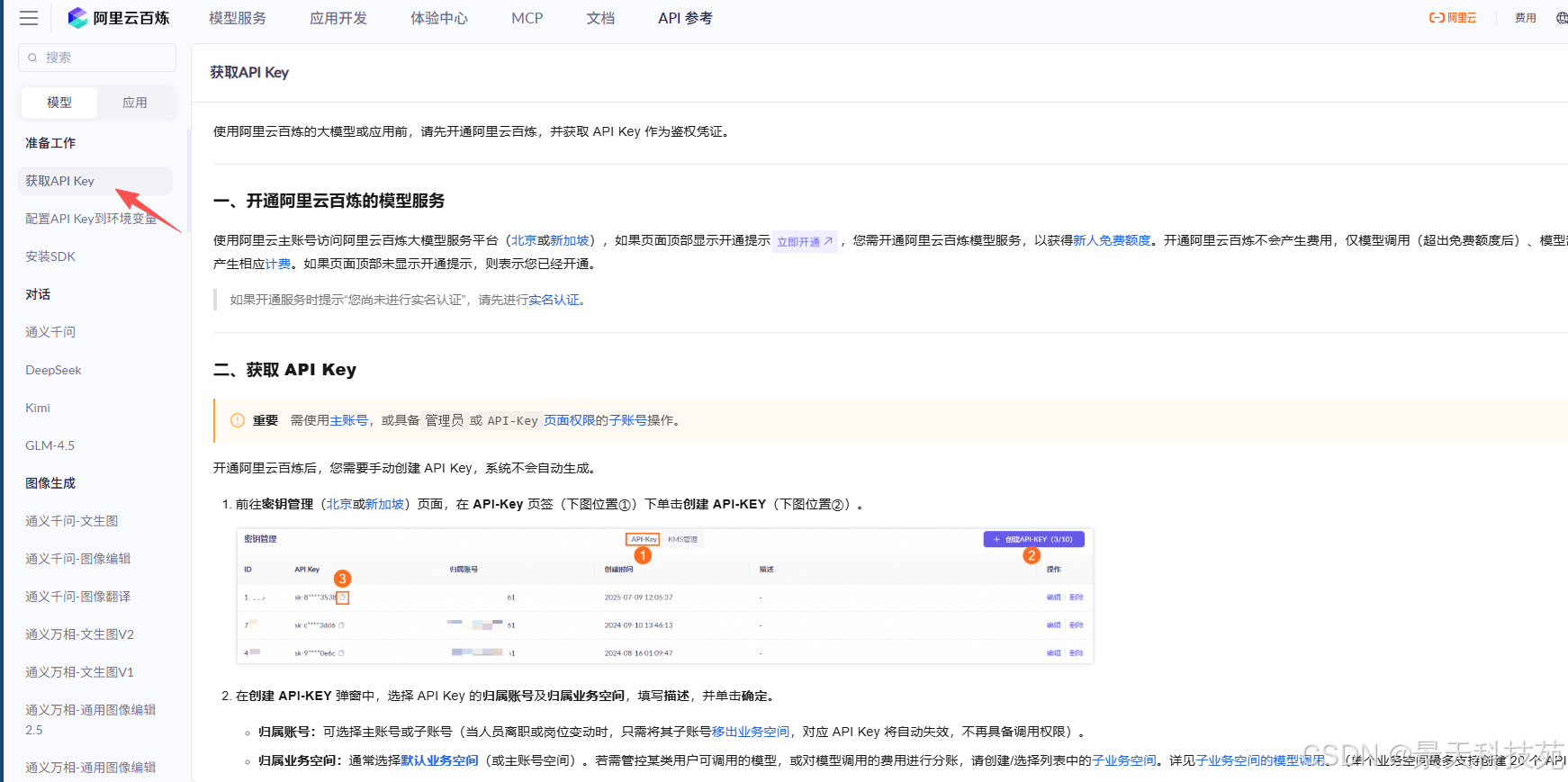
在秘钥管理,获取api key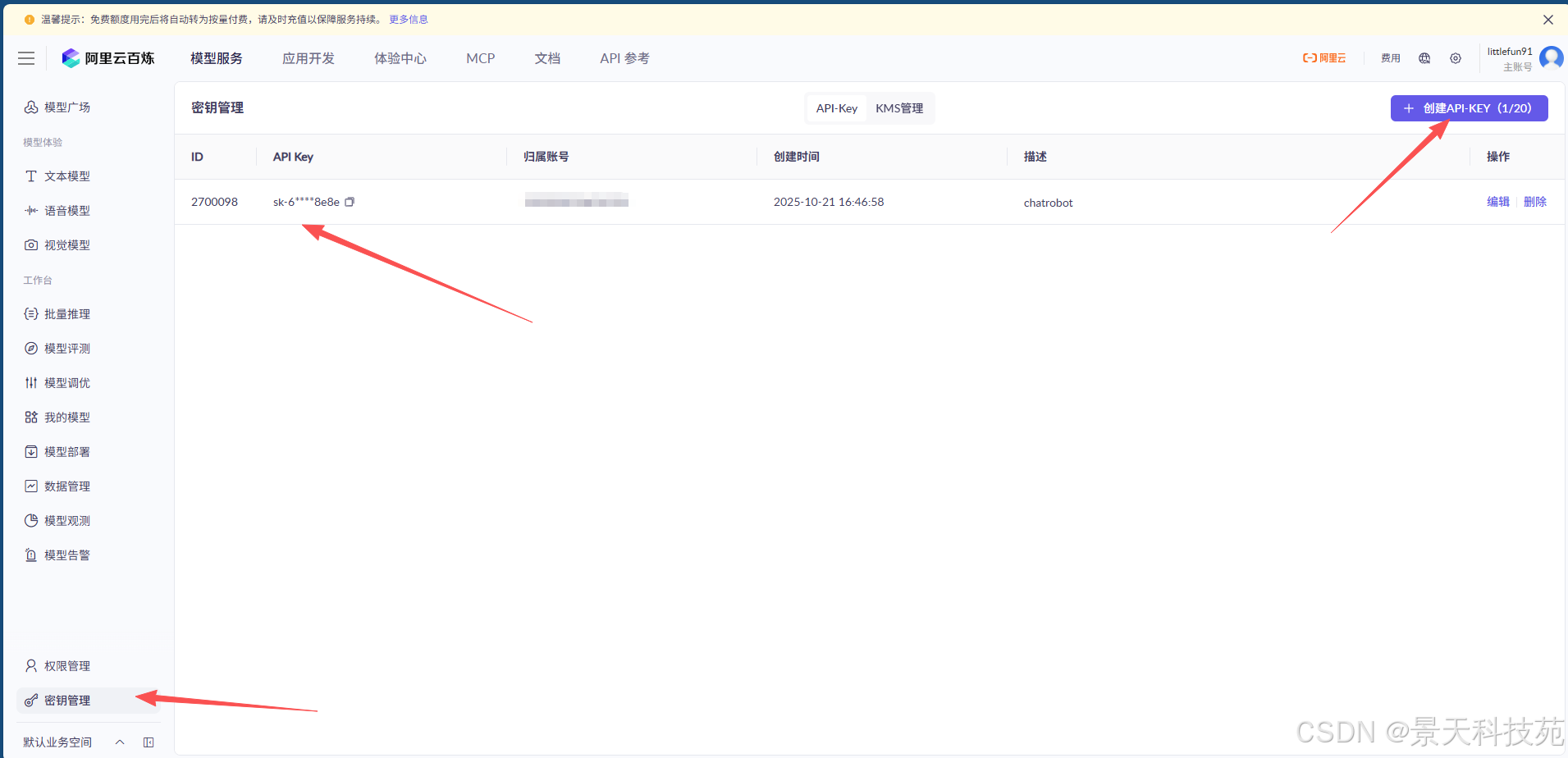
可以找到对话代码参考
1)文生文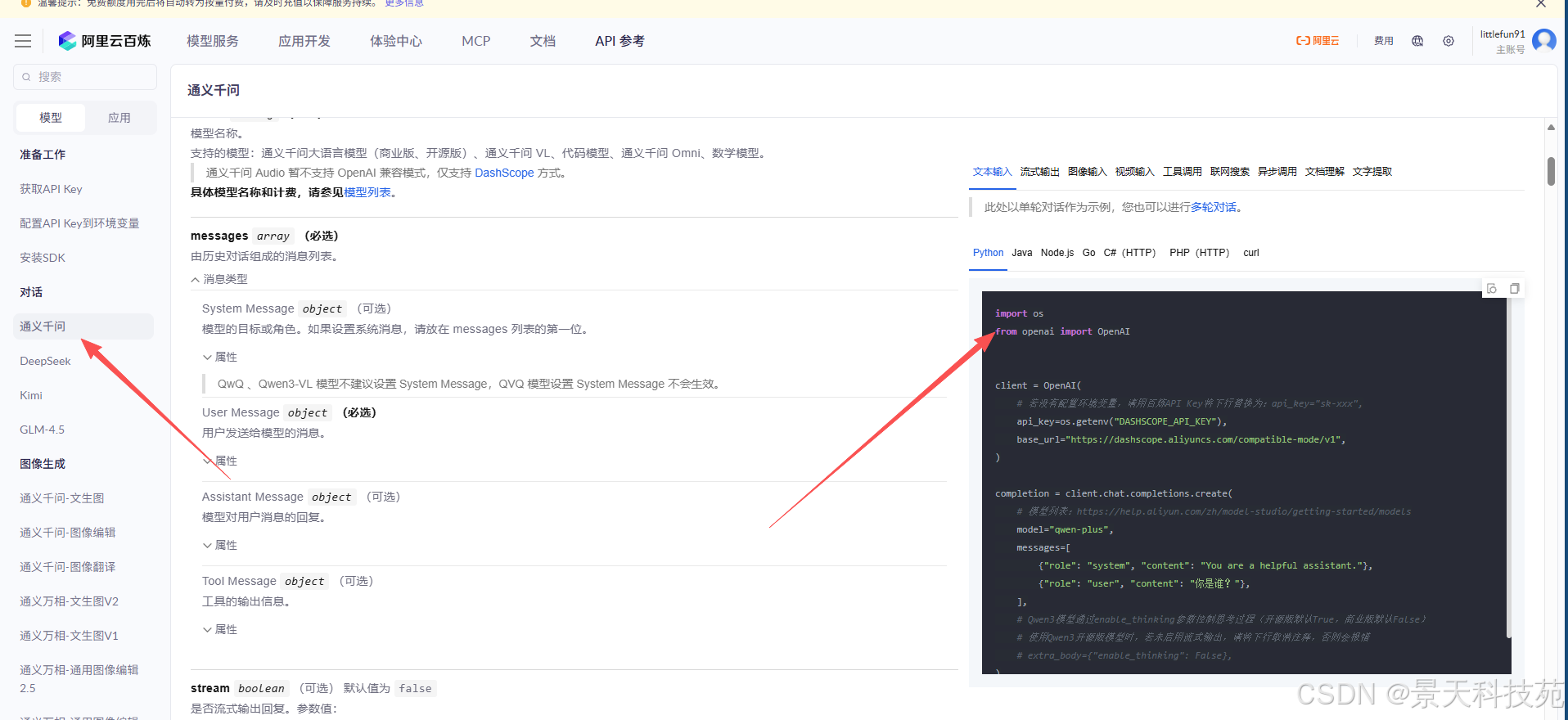
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key="sk-68e9gddhdhhdhdhdgsgsd80daa78e8e",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
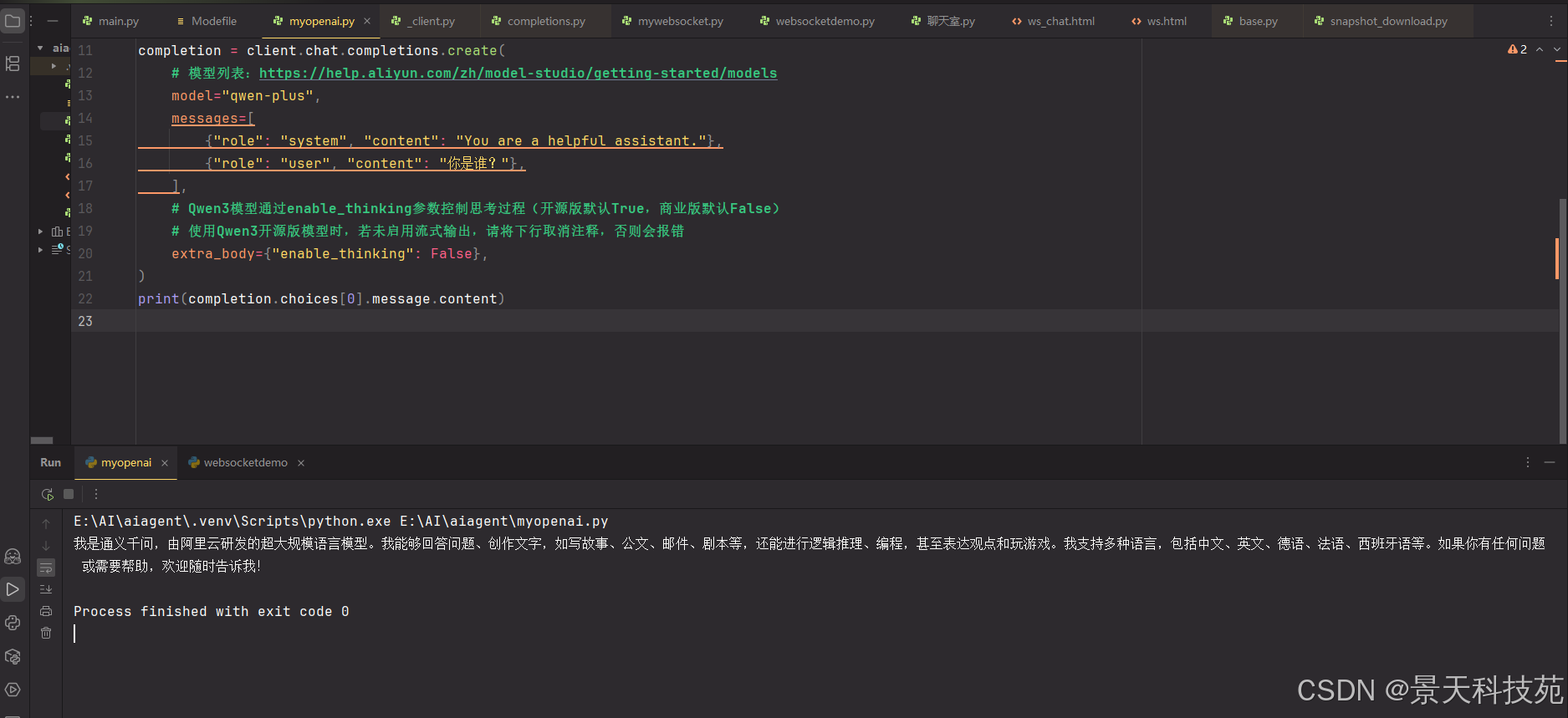
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-plus",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
],
# Qwen3模型通过enable_thinking参数控制思考过程(开源版默认True,商业版默认False)
# 使用Qwen3开源版模型时,若未启用流式输出,请将下行取消注释,否则会报错
extra_body={"enable_thinking": False},
)
print(completion.model_dump_json())
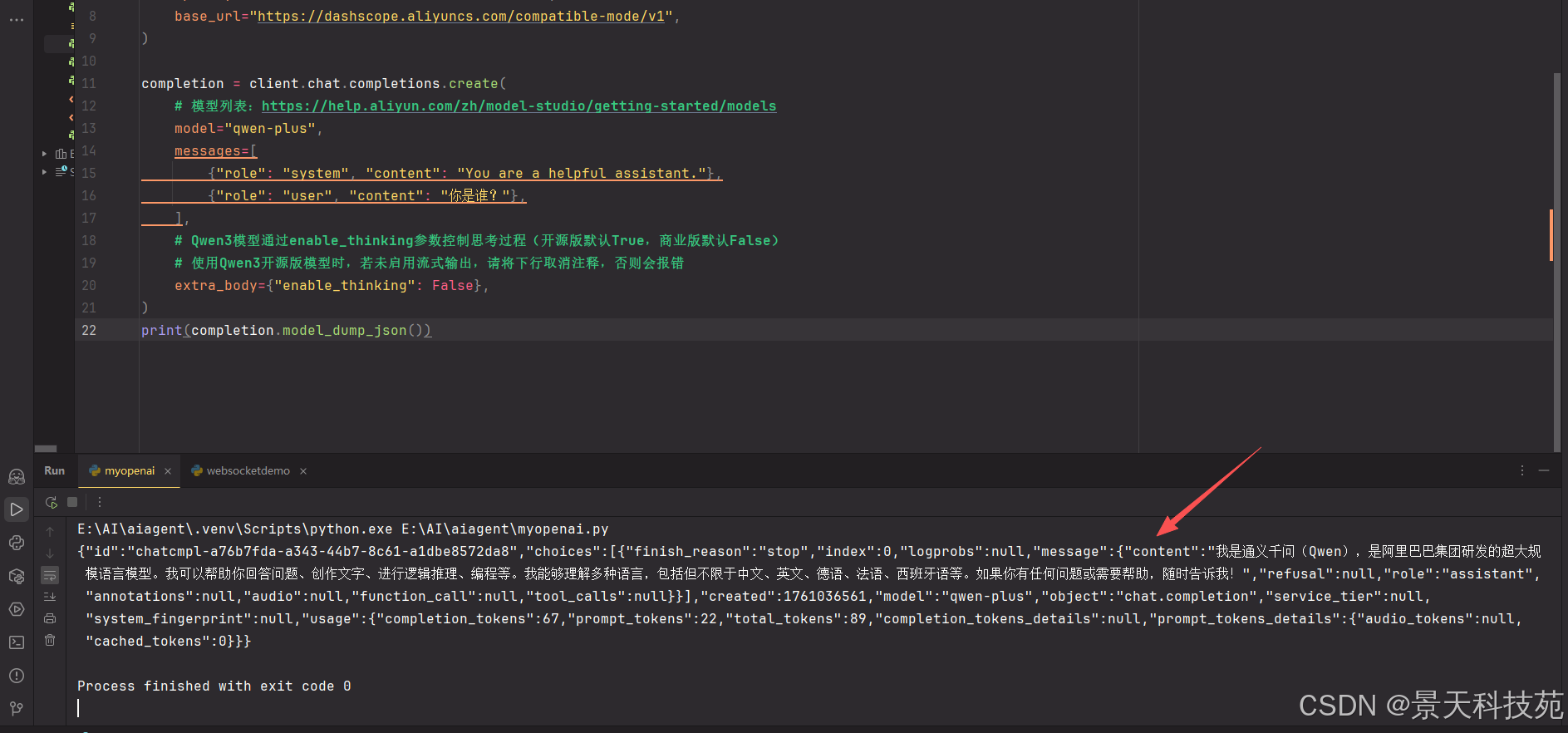
只获取回答内容
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key="sk-68esgsghshshshshshdaa78e8e",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-plus",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"},
],
# Qwen3模型通过enable_thinking参数控制思考过程(开源版默认True,商业版默认False)
# 使用Qwen3开源版模型时,若未启用流式输出,请将下行取消注释,否则会报错
extra_body={"enable_thinking": False},
)
print(completion.choices[0].message.content)
开启联网搜索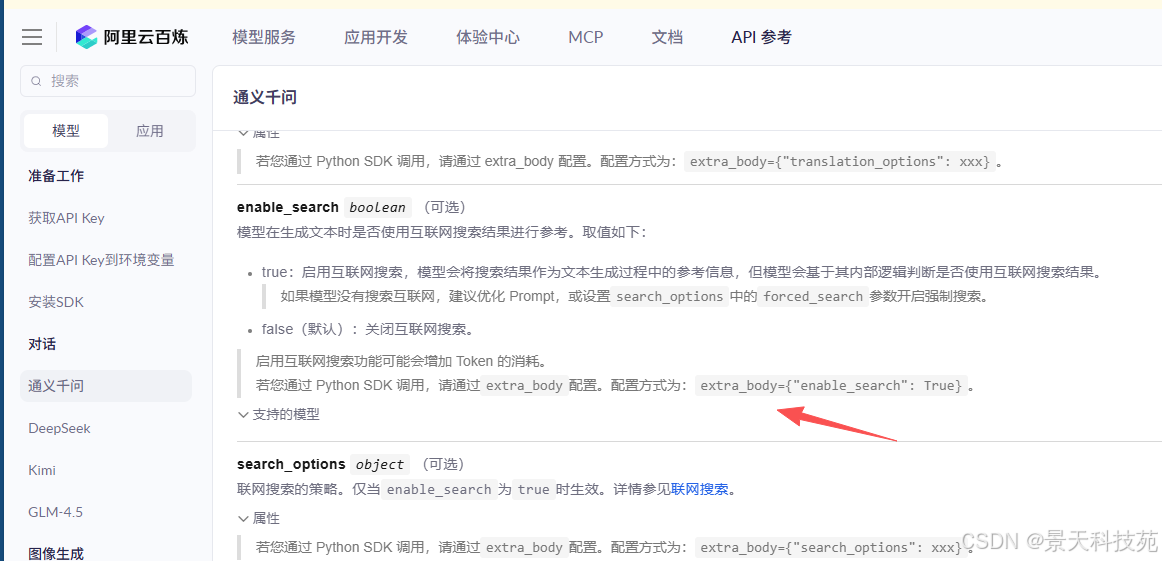
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx",
api_key="sk-68e9ffagagaggagagag78e8e",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
# 模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
model="qwen-plus",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "明天深圳天气怎么样?"},
],
# Qwen3模型通过enable_thinking参数控制思考过程(开源版默认True,商业版默认False)
# 使用Qwen3开源版模型时,若未启用流式输出,请将下行取消注释,否则会报错
# enable_search 是否开启互联网搜索
extra_body={"enable_thinking": False,"enable_search": True},
)
print(completion.choices[0].message.content)
不开启联网搜索,无法获取天气等实时信息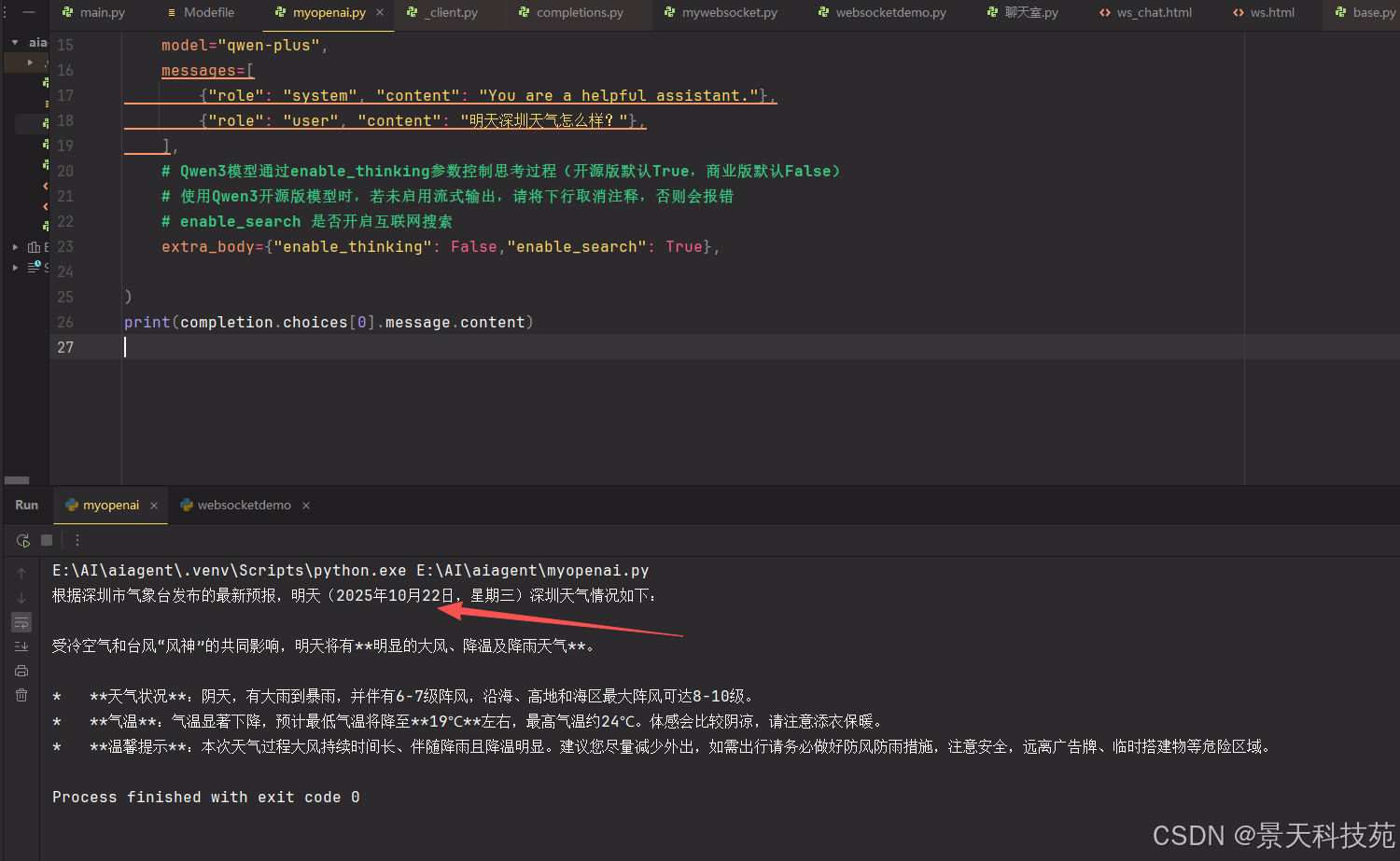
也可以使用其他其他模型
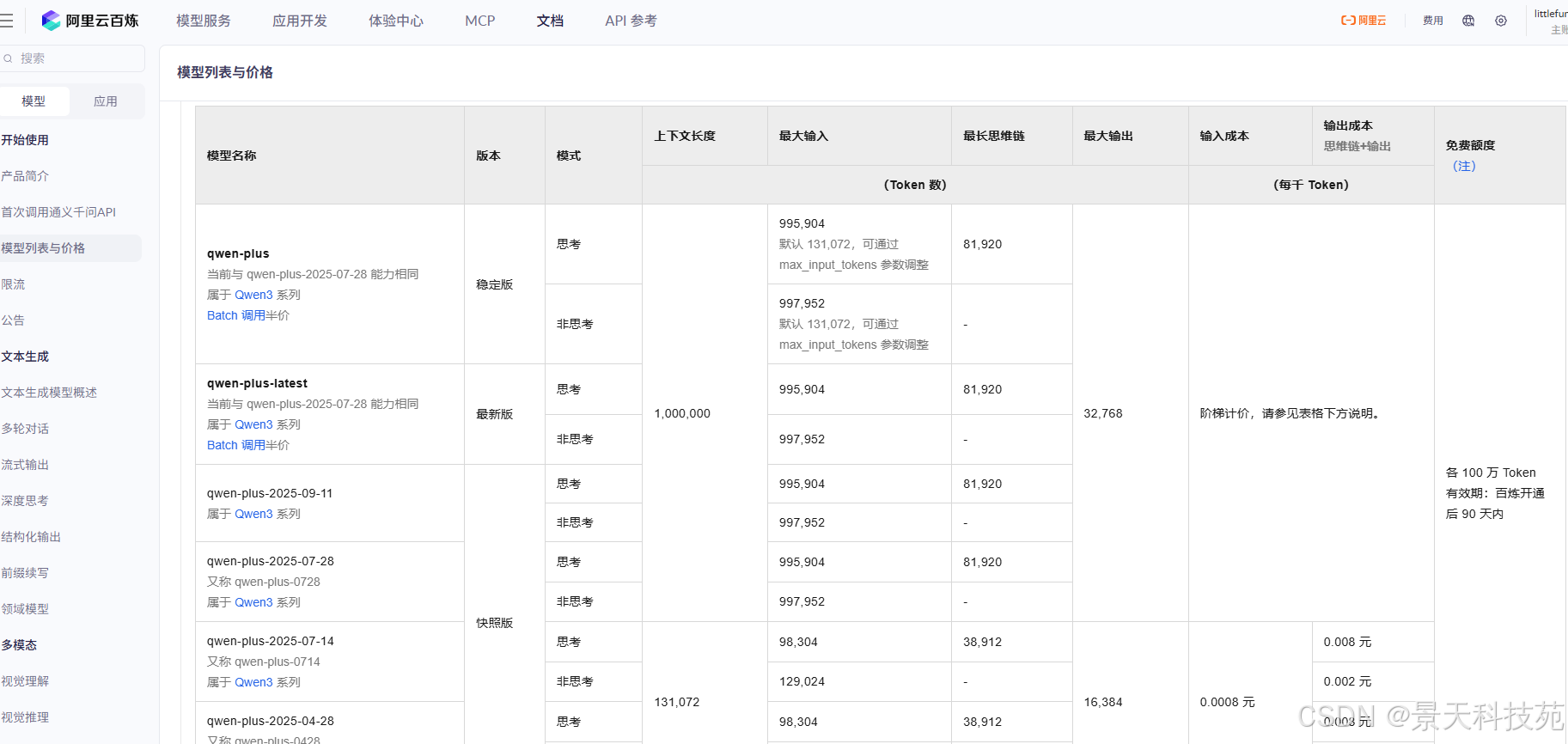
2)文生图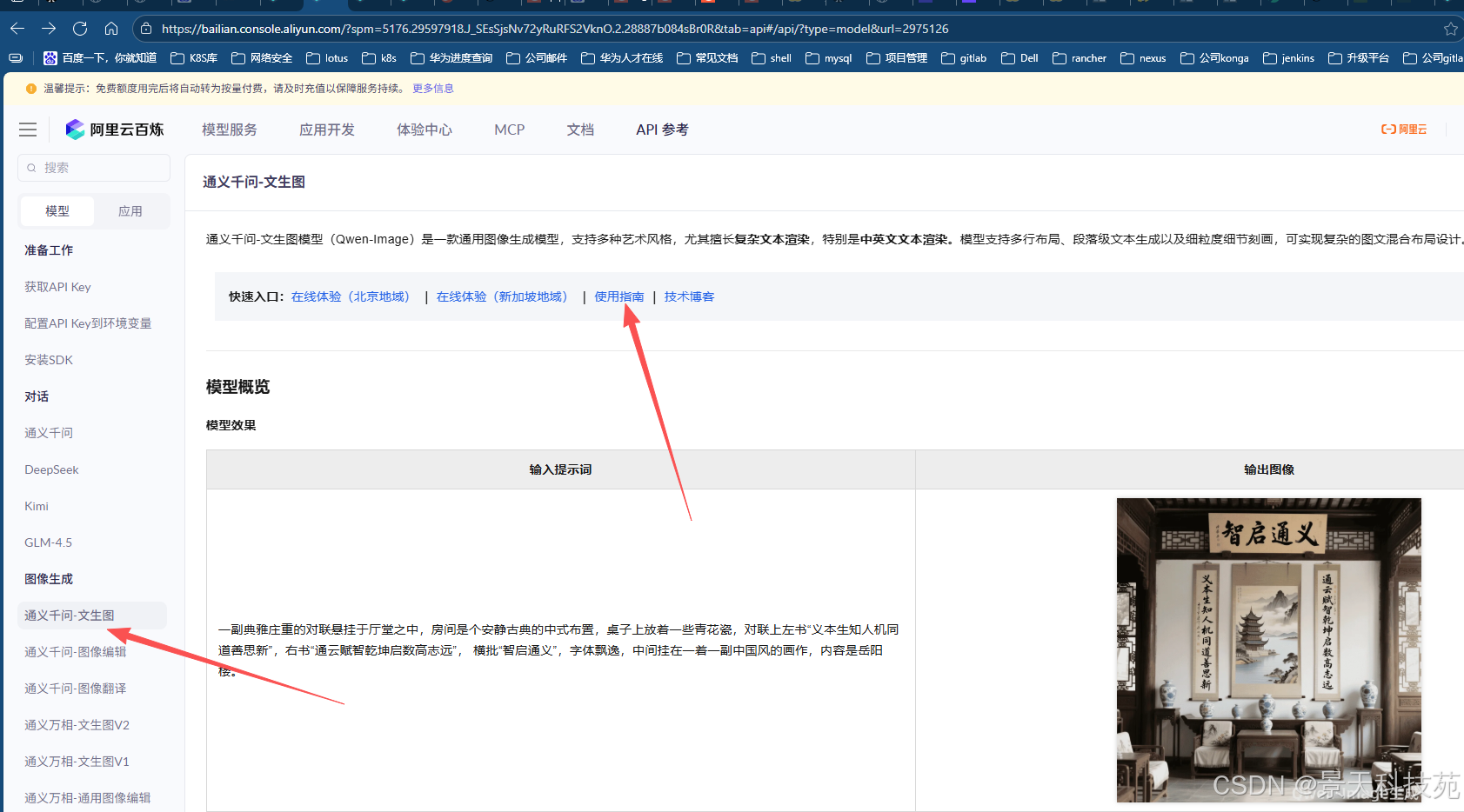
分为通义千问和通义万象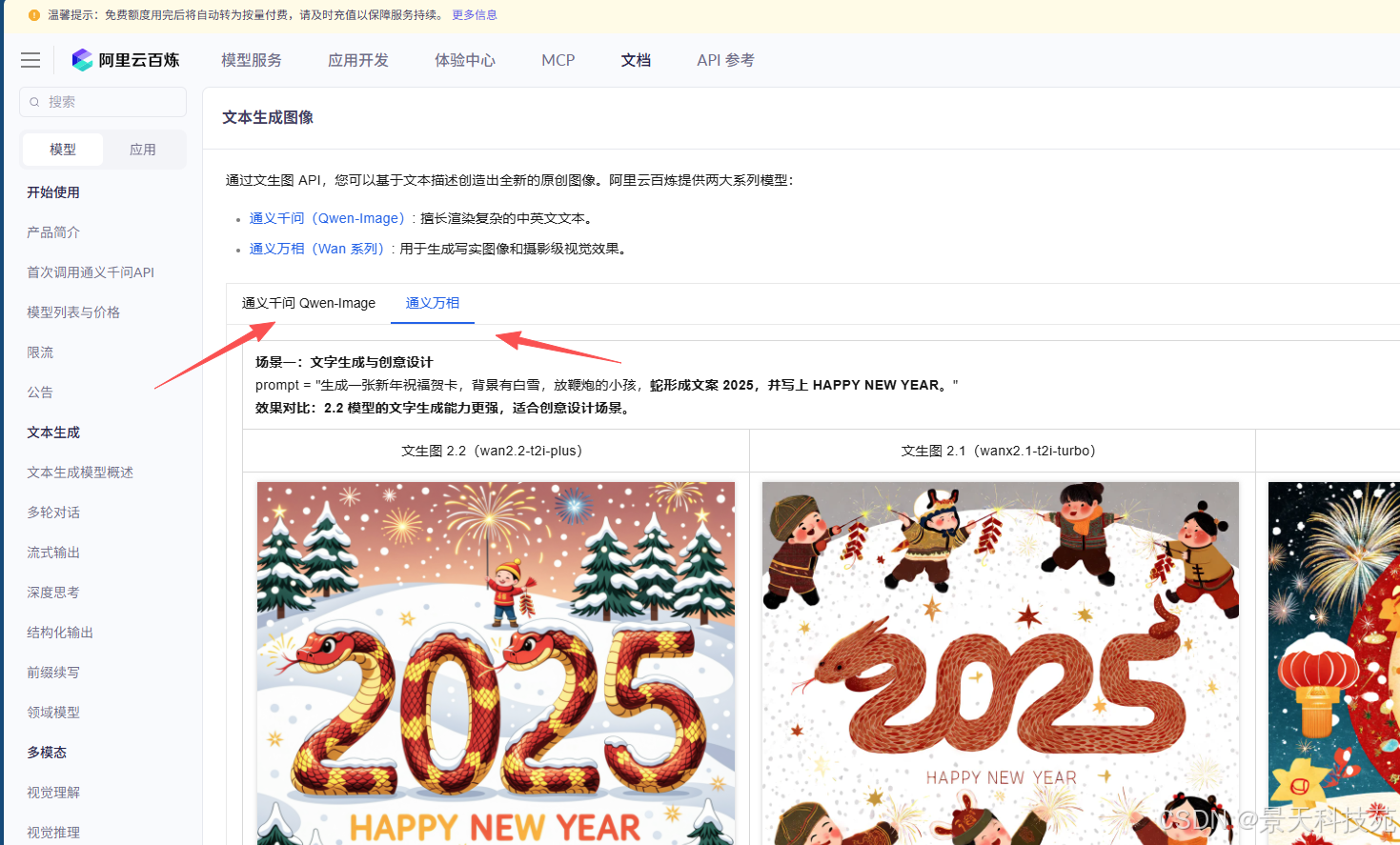
我们使用通义万象,有代码参考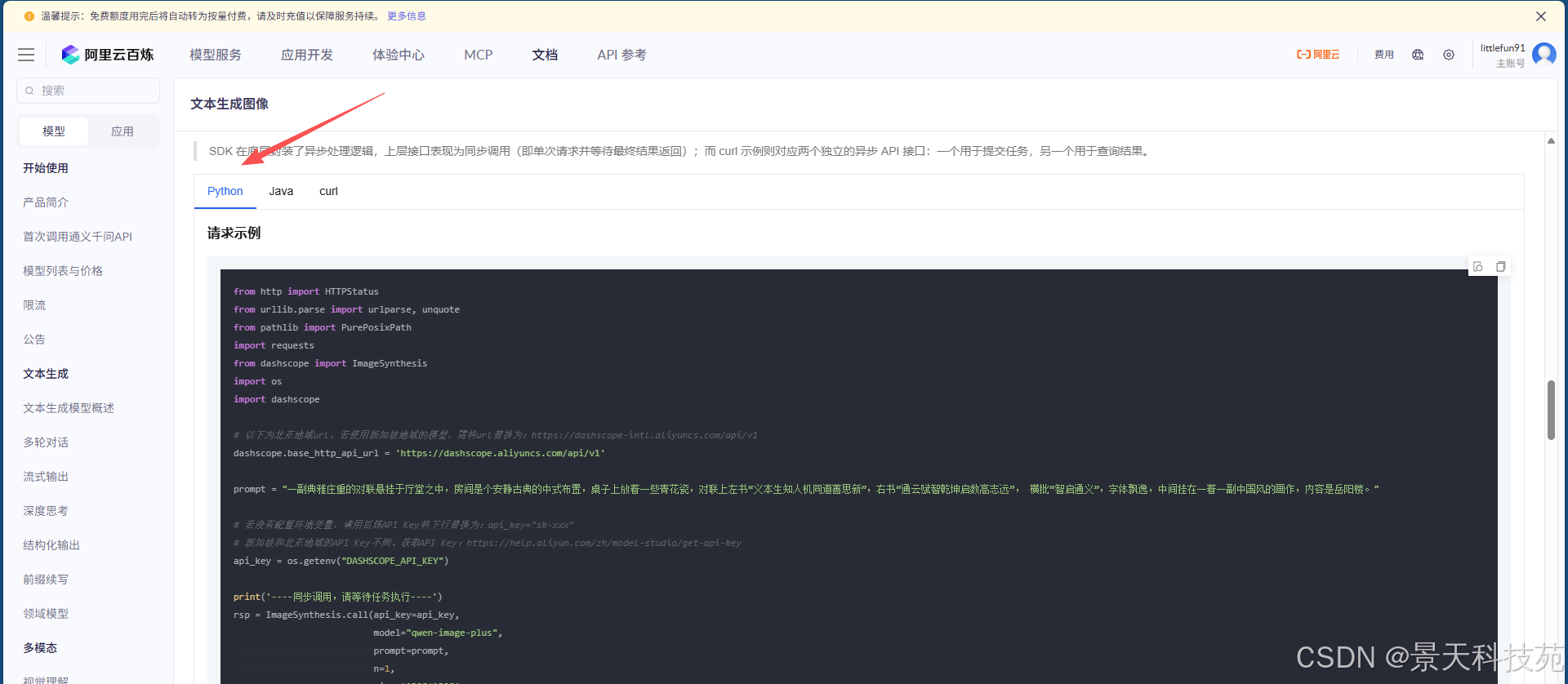
需要下载通义的包dashscope
pip install dashscope
完整代码
from http import HTTPStatus
from urllib.parse import urlparse, unquote
from pathlib import PurePosixPath
import requests
from dashscope import ImageSynthesis
import dashscope
# 以下为北京地域url,若使用新加坡地域的模型,需将url替换为:https://dashscope-intl.aliyuncs.com/api/v1
dashscope.base_http_api_url = 'https://dashscope.aliyuncs.com/api/v1'
# 提示词
prompt = "生成一张符合中国古典美女气质的美女图片"
# 若没有配置环境变量,请用百炼API Key将下行替换为:api_key="sk-xxx"
# 新加坡和北京地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
# api_key = os.getenv("DASHSCOPE_API_KEY")
api_key = "sk-68e95rwgsgsgshshshsgsaa78e8e"
print('----同步调用,请等待任务执行----')
rsp = ImageSynthesis.call(api_key=api_key,
model="qwen-image-plus", #模型
prompt=prompt, #提示词
n=1, #生成图片的数量
size='1328*1328', #生成图片的尺寸
prompt_extend=True,
watermark=True)
print('response: %s' % rsp)
if rsp.status_code == HTTPStatus.OK:
# 在当前目录下保存图片
for result in rsp.output.results:
file_name = PurePosixPath(unquote(urlparse(result.url).path)).parts[-1]
with open('./%s' % file_name, 'wb+') as f:
f.write(requests.get(result.url).content)
else:
print('同步调用失败, status_code: %s, code: %s, message: %s' %
(rsp.status_code, rsp.code, rsp.message))
看下生成的图片
四、Embedding
4.1 Embedding介绍
“Embedding”(嵌入)是机器学习和自然语言处理(NLP)中的一个核心概念。
简单来说,Embedding 是一种把离散的事物(比如文字、图片、用户、商品等)转换成连续向量的方式,让计算机能更好地理解和运算这些数据。
向量是多维数学空间中的一个坐标点,指具有大小和方向的量,它在直角坐标系里通常表现为一段带箭头的线段。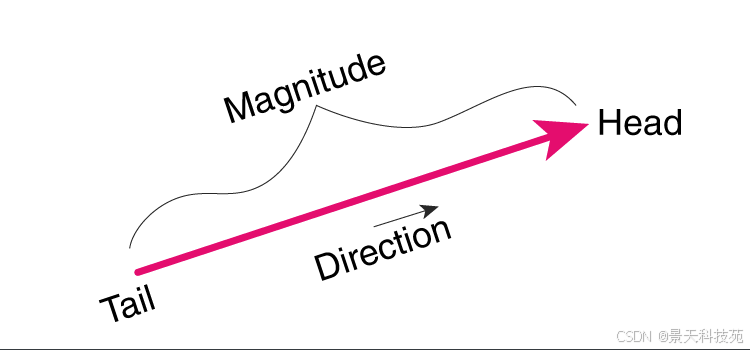
由于向量可以高度抽象地表示事物的特征和属性,世界上几乎所有类型的数据——视频、图像、声音、文本……统统都可以通过数据处理转换成向量数据。
因而,在AI领域流传着一句话,万物皆可Embedding。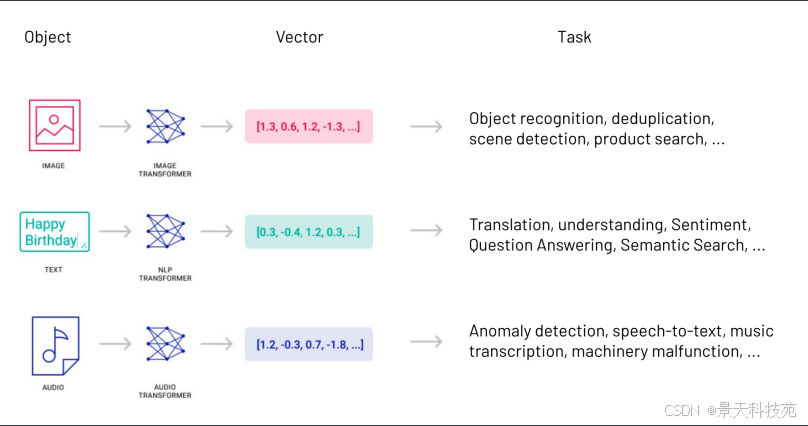
Embedding(向量表示):
指将原本不能直接用于数学计算的对象(如单词、句子、图片、用户ID等),转换成一组实数向量。
例如,单词 “猫” 可能被表示为一个 768 维的向量:
[0.12, -0.45, 0.33, … , 0.27]
这些向量能保留语义或特征信息,让计算机能够“理解”相似性。
比如:
“猫” 和 “狗”的向量距离会很近;
“猫” 和 “飞机”的距离会很远。
所谓的向量数据,通常指的是将实体(如文本、图像、音频等)转换为数值形式的高维向量。
这些向量能够捕捉实体的关键特征,并在向量空间中进行各种计算和比较。
向量数据在AI中的应用非常广泛,包括但不限于自然语言处理(NLP)、计算机视觉、语音识别、推荐系统等。通过向量化,
AI系统能够更好地理解和处理复杂的数据类型,从而提供更加智能和个性化的服务。
将其他类型的信息转换为向量数据的过程就是向量化。
在传统AI领域中(机器学习和自然语言处理(NLP),Embeddings(嵌入,向量化)是一种将类别数据,如单词、句子或者整个文档,转化为实数向量的技术,
这些实数向量可以被计算机更好地理解和处理。嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。
我喜欢吃苹果。 -> [1, 0, 0, 5, 2, 1]
我喜欢苹果手机。-> [1, 2, 5, 0, 3, 2.8]
我喜欢吃香蕉。 -> [1, 0, 0, 5, 2, 3]
举个例子,可以使用词嵌入(word embeddings)来表示文本数据,在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。
例如,“king” 和 “queen” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的词性与含义相似;
而 “apple” 和 “orange” 也会很接近,因为它们都是水果;而 “king” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
Embedding 的直观理解
你可以把它理解为:
把复杂的东西映射到一个高维空间的“坐标点”。
相似的对象,坐标点也更接近。
这就让我们能用数学方法(比如计算余弦相似度)来判断“语义相似度”。
4.2 用途
-
自然语言处理(NLP)
词向量(Word Embedding):如 Word2Vec、GloVe、fastText
句向量 / 文档向量:如 BERT、OpenAI Embeddings
➡️ 使得机器能理解语义相似度、进行语义搜索、文本分类、推荐、问答等任务。 -
推荐系统
用户与商品都可嵌入到同一个向量空间中;
例如:如果用户喜欢“动作电影”,他的向量会靠近动作电影的向量。 -
图像与多模态任务
将图片或音频转化为向量,与文字向量进行对比(如 CLIP 模型)。
4.3 向量数据库
向量数据库(Vector Database)也叫矢量数据库,是专为存储、处理、分析「向量数据」而生的,
能够基于目标向量快速进行相似度搜索,并返回最相近的数据。总而言之,就是用来存储和处理向量数据的数据库。
随着大型AI语言模型的崛起,向量数据库成为了解决模型“幻觉”问题的关键。
它号称是LLM记忆的海马体,是大模型的记忆和存储核心,通过注入实时和私域数据的形式(比如爬虫形式获取最新数据,注入向量数据库),可以使得LLM能够在更多通用场景中落地应用,缓解模型”幻觉“的问题。
常见的向量数据库:Milvus、Chroma、Weaviate、Faiss、Elasticsearch、PGVector、opensearch、腾讯VectorDB,ClickHouse。
数据库排名网站:https://db-engines.com/en/ranking/vector+dbms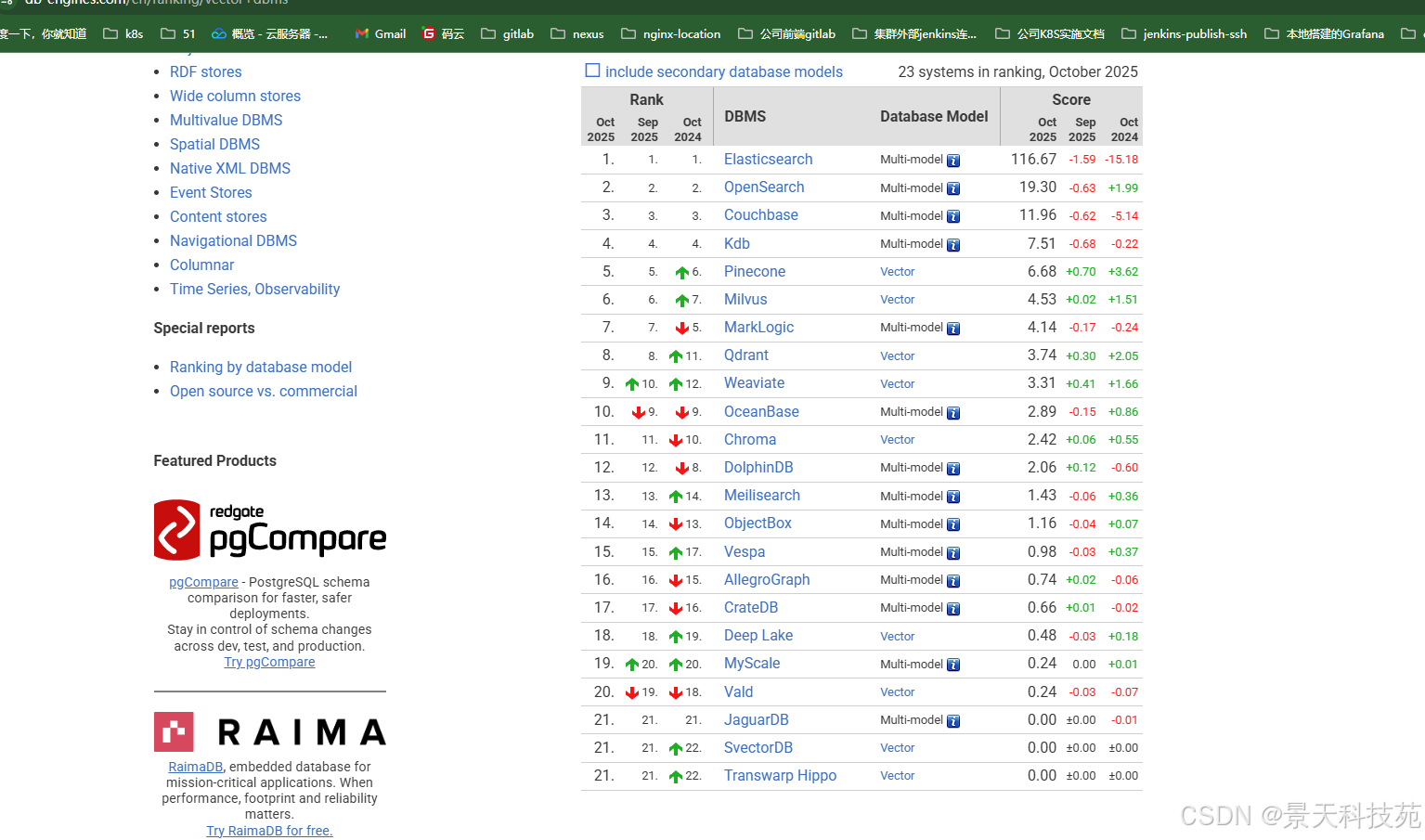
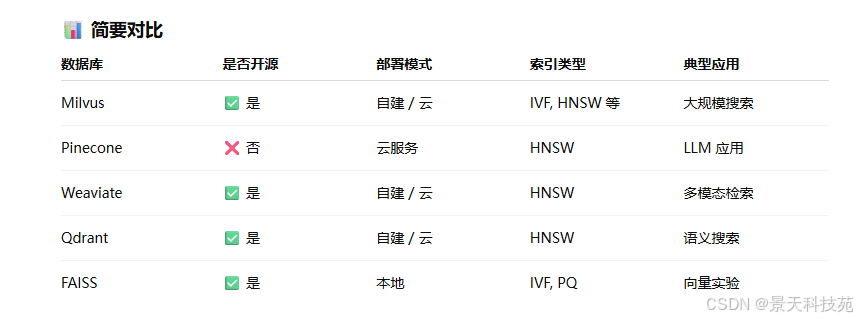
向量数据库的特点: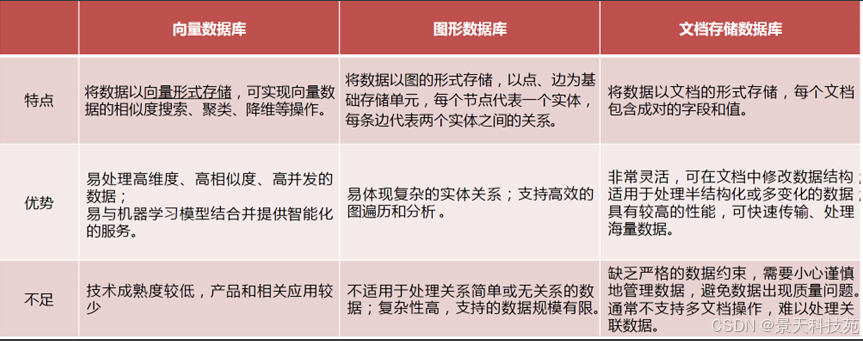

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)