基于骨骼关节的深度学习动作识别
使用骨骼关节运动进行识别人类活动的深度学习
摘要
随着消费电子技术的进步,人们对更精细地区分和分析人类日常活动的需求日益增加。此外,随着在老年人监护以及公共场所可疑人员及遗留物品的监控等应用领域的研究不断深入,机器学习尤其是深度学习的潜力已逐渐显现。尽管已经开发出一些使用可穿戴传感器的人体动作识别(HAR)技术,但这些设备可能给人们,特别是儿童和老年人,带来不必要的心理和生理不适。因此,研究重点已转向基于图像的人体动作识别,使其成为消费电子领域发展的前沿。本文提出一种智能人体动作识别系统,该系统能够利用深度传感器获取的人体骨骼信息,结合图像处理与深度学习技术,自动识别人们的日常活动。此外,由于采用骨骼信息的方法具有低计算成本和高精度的优势,已被证明极具前景,并可在不受环境或领域结构限制的情况下广泛应用。因此,本文探讨了一种高效的基于骨骼信息的HAR系统的开发,可用于嵌入式系统。实验在两个著名的人类日常活动公开数据集上进行。根据实验结果,提出的系统在两个数据集上的表现均优于其他最先进的方法。
索引词 —人体动作识别,消费电子视角,骨骼关节,相对关节图像生成,深度学习
I. 引言
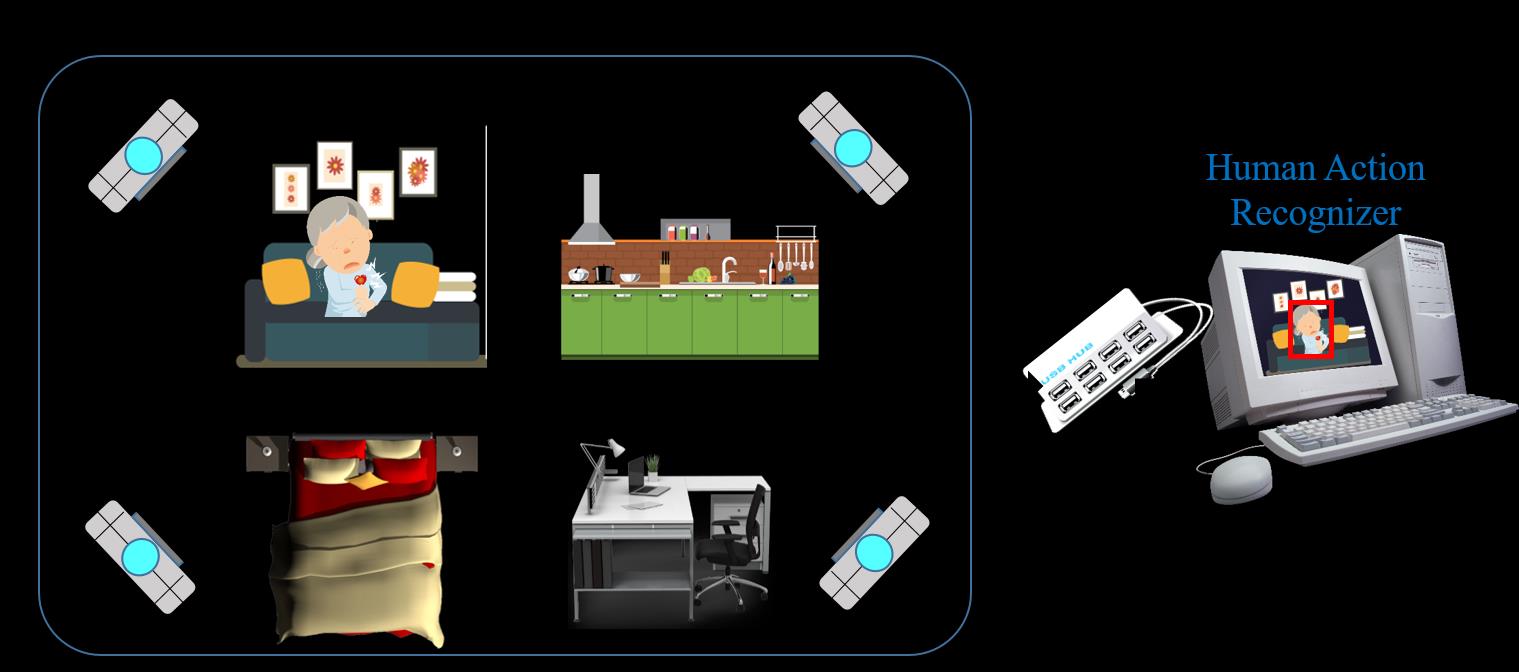
从一系列视频序列中进行人体动作识别(HAR)是计算机视觉技术中的一个具有挑战性的问题,且在学术、安全、工业和消费电子等多个研究领域的应用中具有基础性作用。其中包括用于视频监控、消费者行为分析以及面向老年人的智能家居健康监护系统的人体动作识别系统。HAR是一项重要的研究,因为通过识别和预测人类的行为。另一方面,消费电子领域成像技术的最新进展,例如消费级深度传感器,已引起研究人员的广泛关注,他们致力于开发各种应用以实现对人类行为的识别与鉴定。然而,由于尺度、形变和外观的变化,建模人体动作识别系统以产生准确高效的结果仍然是一项挑战。本文提出了一种新方法,通过利用彩色骨骼运动历史图像(Color Skl‐MHI)和相对关节图像(RJI)来监控独居老年人,从而在消费电子领域建立人体动作识别系统。
考虑到消费电子领域应用的开发,世界人口正在老龄化。未来,老年人将占总人口的更大比例。此外,大多数老年人更愿意在熟悉的环境中居家独立生活。这给护理人员提供了优质服务带来了挑战。同时,许多老年人难以找到负担得起的服务。因此,用于监控老年人日常活动的自动系统已成为消费电子领域的重要研究课题,特别是针对人体动作识别以及与智能手机、家用电器、药品和其他各种物品交互的自动识别。本文通过聚焦图像处理与深度学习的混合技术,致力于在消费电子中建立一个人体动作识别系统。本文重点讨论了三个方面的改进。
- 在方法论方面,本文提出使用深度传感器通过跟踪骨骼关节运动来识别人类日常活动。这些技术可用于在各种环境(无论白天或夜晚)中对各种类型的人类行为及其交互进行分析。
- 在应用方面,该提出的系统对于监控独居老年人非常有用,能够识别和分析老年人的正常与异常的日常活动。
- 在实现方面,该提出的系统可开发为嵌入式系统以实现实时处理。
本文的组织结构如下:第二部分介绍了与本文主题相关的其他工作;第三部分对提出的人体动作识别方法进行了概述和技术解释;第四部分展示了来自两个公开数据集的一些实验结果;第五部分进行了分析与讨论。最后,第六部分给出了结论。
II. 一些相关工作
人体动作识别(HAR)的研究领域涉及许多不同的研究方向,已在消费电子领域基于HAR开发出成功的应用。在日常生活中,人类会使用或与智能手机、其他消费电子设备、家用电器以及许多其他物体进行交互。人体动作识别的研究已在消费电子、医疗监控系统、视频监控和深度学习技术的框架下展开。以下将介绍其中一些出色的研究工作。
A. 人体动作识别与消费电子
人类的日常活动在很大程度上涉及与智能手机、家用电器及许多其他物品等消费电子设备的交互和操作。因此,涉及此类活动的研究在面向消费电子技术的人体动作识别(HAR)发展中起着关键作用[1]。在物联网中,人类与数以百万计的消费电子设备相连接。然而,也可能存在一些副作用。例如,许多人在家和办公室使用计算机,导致长时间保持坐姿,且常常姿势不良,这可能引发重复性劳损。因此,监测日常行为、识别不健康习惯并采取适当措施具有重要意义。研究人员已利用自采集数据集对这类问题进行了模型化,包括提供图示,并开发了相应的硬件和软件技术用于识别人类活动[2]。
类似地,已开发出一种使用消费级视频传感器和隐马尔可夫模型的系统,用于识别老年人的六种异常行为,例如向前跌倒、向后跌倒、晕厥、呕吐以及出现头痛或胸痛[3]。另一种方法则利用消费级深度相机捕捉六种典型人类行为的深度图像,如行走、跑步、拳击、拍手、坐下和站起。随后,采用R变换方法进行特征提取,主成分分析(PCA)降低特征向量维度,线性判别分析(LDA)提取更显著的特征,并利用隐马尔可夫模型进行分类,从而实现对这些行为的识别[4]。
B. 人体动作识别与医疗监护
人体动作识别(HAR)是建立智能医疗监控系统的重要组成部分,尤其有助于老年人在保持高质量生活的同时独立生活。同时,建立服药和进餐等活动的规律性和正常时间对于制定指南和规范也非常重要。在众多研究中,一些研究采用了多层马尔可夫链模型[5]和基于马尔可夫的方法[6],利用图像技术分析和识别日常生活活动,不仅能够识别行走、站立、坐着等简单动作,还能识别做家务、交流、服药等复合活动。
除了图像技术外,许多研究还集中在使用可穿戴消费设备进行人体动作识别和监测,这些设备用于测量生理心电图(ECG)信号,并利用全球定位系统(GPS)在户外环境中寻找跌倒的老年人[7]。另一种跌倒检测系统是通过在家用家庭网络中应用传感器而开发的[8]。在另一方面的研究中,已为老年人开发了健康管理系统,该系统利用射频识别(RFID)、短距离无线传输技术和互联网进行血压管理[9]。
C. 人体动作识别与视频监控
视频监控是面向应用的人体动作识别研究的另一个领域。例如,视频监控已被用于购物中心、体育中心和交通枢纽等公共场所,以检测可疑人员和可疑物品。已开发出一种智能视频监控系统,能够利用二维随机游走模型[10]自动检测徘徊人员。在消费电子研究中,作为研究人与物体交互的一部分,通过开发静止物体分析器[11]来开展遗留物体检测的研究。
D. 人体动作识别与深度学习
人体动作识别(HAR)与机器学习,尤其是深度学习,可被视为互补的研究领域。为证明这一观点,巴库什等人在研究中提出了一种两步标注方法,该方法在灰度图像的时空特征上应用深度学习技术以识别人类行为[12]。此外,也尝试了其他类型的深度学习方法来处理人体动作识别问题,例如基于三维的深度卷积神经网络(3D2CNN)和支持向量机(SVM)。其中一种方法直接将3D2CNN应用于原始深度视频序列,以提取时空特征;另一种方法则在关节向量特征上使用SVM,这些特征基于人体骨骼关节之间的简单位置和角度信息[13]。在此项工作中,3D2CNN和SVM的结果被融合,以生成用于动作识别的最终输出结果。
在其他基于深度学习的人体动作识别研究中,通过在第一个卷积层之前添加一个硬连线层来使用三维卷积神经网络模型,从而生成五个信息通道,并在最后的识别层中用于动作识别[14]。值得一提的是,还有一些更相关的工作,通过增强骨架可视化和实验验证展示了视角不变的人体动作识别的概念。这些工作使用了Northwestern‐UCLA、UWA3DII、NTU RGB+D和MSRC‐12数据集[15]‐[16]。最后,在相关工作中,一些研究尝试通过开发一种校准骨骼坐标的算法,克服初始摄像机角度和位置带来的局限性[17]。
这是对相关人体动作识别研究的概述以及在消费电子领域的应用。事实上,文献中提供了大量此类研究的实例,具有多种潜在的应用。然而,这些工作均未开发出性能令人满意的技术。因此,我们提出了以下全新的人体动作识别方法。
III. 提出的人体动作识别
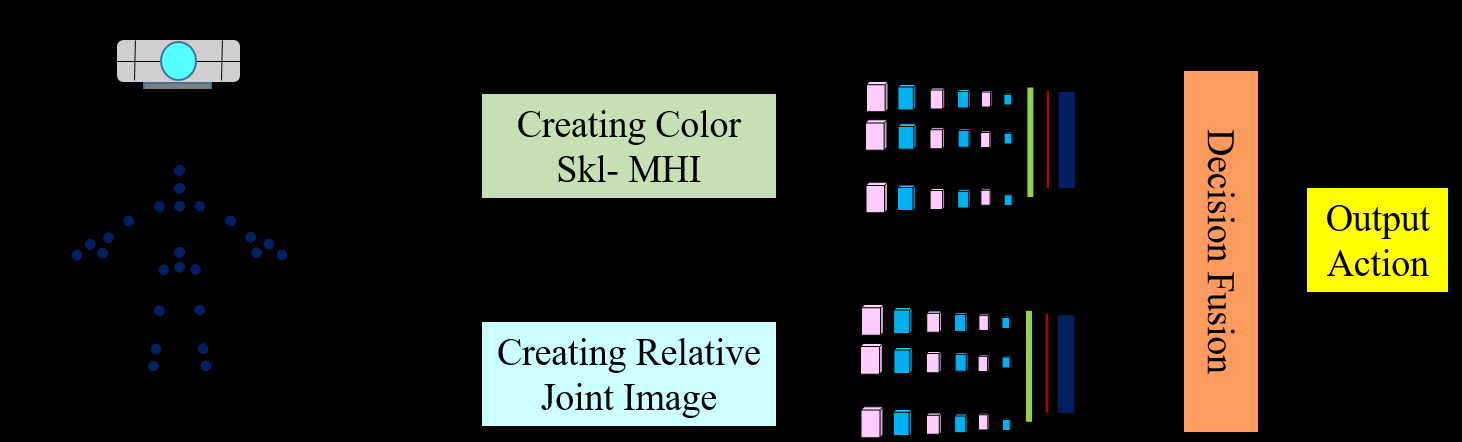
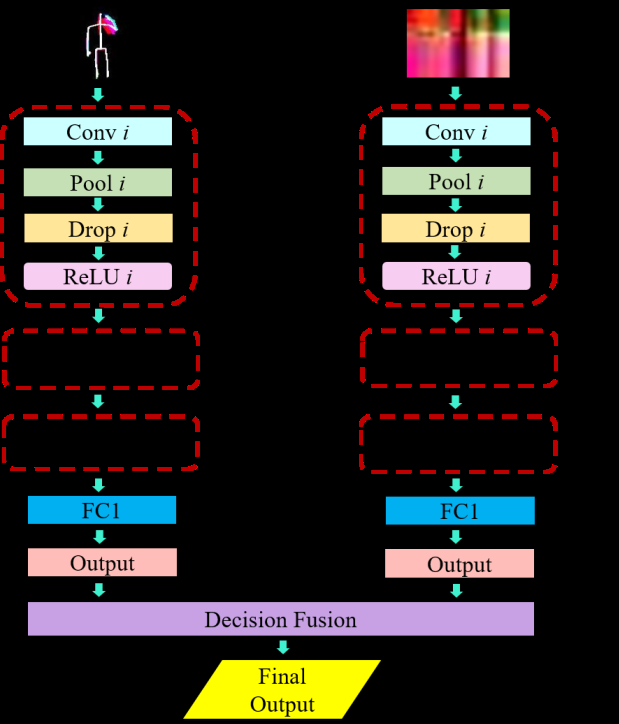
所提出的HAR架构如图1所示。该系统包含三个处理组件:1)输入数据采集,2)子图像生成与特征提取,3)输出融合与动作识别。在输入数据采集中,输入设备捕获人体关节的坐标信息。在涉及图像与特征的组件中,(i)生成彩色骨骼运动历史图像(Color Skl‐MHI),用于提取骨架运动历史特征,以及(ii)生成相对关节图像(RJI),用于获取参考关节与其他关节之间的相对距离特征。在输出融合与人体动作识别组件中,通过深度学习对预定义动作(如站立、坐着或弯曲)进行分类。图2展示了一个使用消费电子产品监测独居老人的HAR系统应用示例。下文将详细介绍各个组件的功能。
A. 输入数据采集组件的功能
输入数据采集使用深度传感器完成,该传感器可以生成5种输出流:RGB、深度、红外、音频和关节跟踪数据。这些数据对于识别人类行为和交互非常有用。然而,在所提出的HAR系统的实现中,仅使用了关节跟踪数据。原因是,在骨骼跟踪数据中,深度传感器能够跟踪人体的运动并生成关节坐标,其中包含时间t的帧中Ji(t) =[xi(t), yi(t), zi(t)]的三维坐标。这种关节信息能够很好地表示人体结构。
B. 子图像生成与特征提取
1) 创建彩色骨骼运动历史图像
在此组件中,使用深度传感器获取的关节信息来建立彩色Skl‐MHI和RJI。创建骨架运动历史图像(Skl‐MHI)首先需要使用相应关节生成二值骨骼图像。接着,在预定义时间维度[18]内将连续骨骼图像组合,生成二值 Skl‐MHI。然而,仅靠二值Skl‐MHI无法区分具有相似运动模式的动作,例如从站立位置坐下或从坐姿站起。
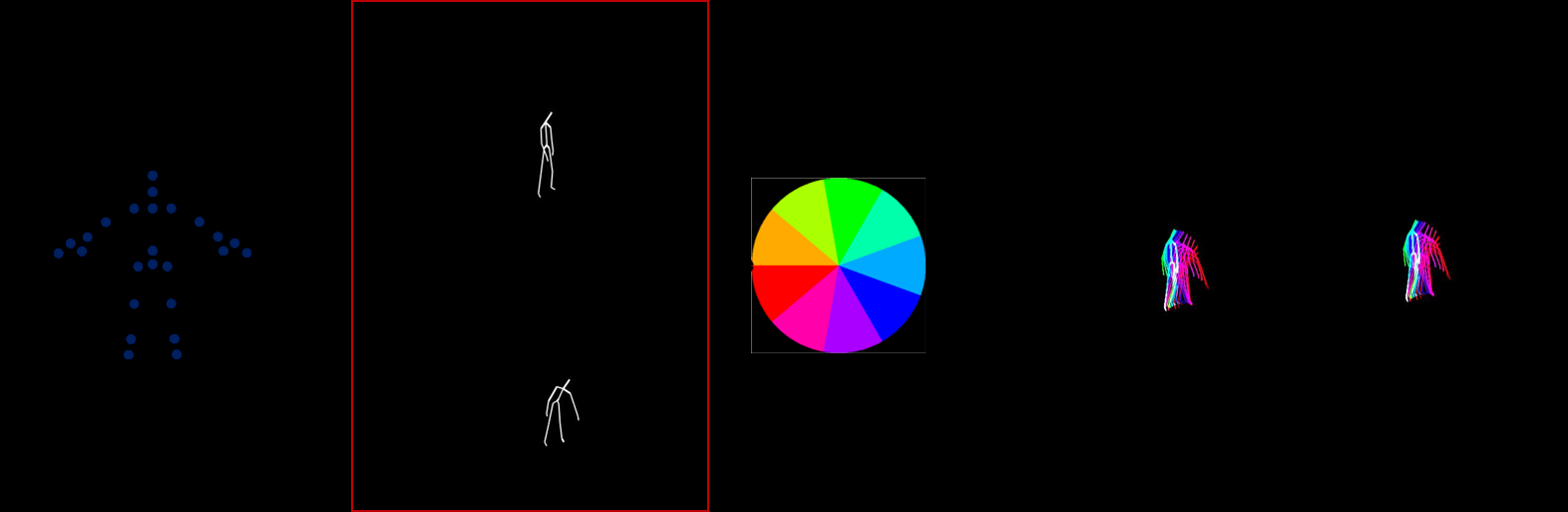
 坐下,(b) 站起)
坐下,(b) 站起)
因此,根据每个动作的顺序时间间隔,为二值 Skl‐MHI添加颜色值,如图3所示。由此,从骨架数据中提取的运动历史图像的时间序列变得更加明显。该过程的输出如图4所示。在该图中,我们可以看到,通过对每个时间序列表示应用颜色值,能够区分具有非常相似的运动模式的动作。
2) 创建相对关节图像
使用关节的相对位置是表示人体运动的一种直观方法。例如,在检测挥手动作时,手部位置位于肩关节上方并左右移动。RJI是将动作的骨架序列转换为人体运动模式图像的新视角不变表示。在创建RJI时,我们首先计算参考关节与其他关节之间的相对距离。我们选择左肩(J5)、右肩(J9)、左髋(J13)和右髋(J17)这四个关节作为参考关节,因为它们在大多数动作中是最稳定的关节。
然后,通过计算四个参考关节与其他关节之间的(x, y, z)坐标差值来提取相对距离特征。通过连接在预定义时间维度内各帧中关节的相对距离,生成四个RJI,每个RJI包含一个大小为t ×(m‐1) × 3的三维数组,如图5所示,其中m表示每帧中的骨骼关节数量,t是包含足够帧数以表示动作的预定义时间维度,3表示(x, y, z)坐标。

C. 输出融合与人体动作识别
在此组件中,采用三维深度卷积神经网络 (3D‐DCNN)对彩色Skl‐MHI和RJI进行人类行为的训练与识别。最终输出动作为融合这两个网络结果后生成。深度卷积神经网络(DCNN)是一种多层卷积神经网络,由输入层、一个或多个隐藏层、全连接层和输出层组成。DCNN的隐藏层包含两种操作,即卷积和池化,以及一个称为激活函数的主要功能。
在输出层中,使用softmax函数将深度卷积神经网络的输出转换为相应的概率值。每个卷积核的权重值通过某些分布概念(如均匀分布和高斯分布)进行随机初始化。网络经过多次前向训练(将输入数据沿网络传递)和反向训练(更新所有层的权重),直到满足停止准则(最小损失或最大迭代次数)。权重值根据使用随机梯度下降算法计算出的损失值进行更新。
1) 卷积
卷积是将从原始输入数据中获取的信息与能够很好表示输入训练数据特征的提取代表性数据进行混合的过程。卷积的输出称为特征图,其结果会因卷积操作中所使用的核滤波器不同而有所差异。当对图像数据应用卷积时,会在图像的每个颜色通道上使用二维核。图6 (a) 展示了使用边缘检测核在图像上执行卷积操作的示例。
2) 池化
池化操作的主要目的是减少每个隐藏层中特征图的空间维度。根据池化过程中所使用的数学运算,池化有多种类型,例如最大池化(MAX)和平均池化(AVE)。池化操作也称为子采样,这是一种简单的操作,即在预定义的卷积核的宽度和高度范围内取最大值或平均值。图6 (b) 展示了在二维矩阵上应用最大池化操作的示例。
3) 激活函数
激活函数是深度卷积神经网络中的一个重要函数,因为它可以根据接收到的输入是否相关来决定神经元是否应被激活。激活函数的输出将成为下一层的输入,而神经元输入与对应卷积核权重的乘法以及与偏置值的加法所得到的数据将作为激活函数的输入,可表示为(1)。
$$
Y = f(\sum(kernel_weight * input) + bias)
$$
在提出的系统中,我们使用修正线性单元(ReLU)作为激活函数,当x < 0时输出为0,当x > 0时为斜率为1的线性函数,如公式(2)所述。
$$
f(x) = \max(0, x)
$$
其中x是激活函数的输入。
4) softmax函数
为了使用(3)获得可能动作的概率,在三维深度卷积神经网络的输出层之后应用softmax函数。
$$
\sigma(z) j = \frac{e^{z_j}}{\sum {k=1}^{N} e^{z_k}}
$$
其中j和z表示每个动作及其网络输出,N表示动作总数。
5) 使用随机梯度下降法更新权重
使用随机梯度下降算法[19]更新所有层的核矩阵权重的逐步计算如下:
i. 使用(4)计算期望输出yd,k与网络输出yk之间的误差值 err。
$$
err = y_{d,k} - y_k
$$
ii. 输出层神经元的误差梯度Δk使用(5)计算。
$$
\Delta_k = err \cdot y_k (1 - y_k)
$$
iii. 使用预定义的学习率α计算输出层的权值和偏置修正 ΔWk和ΔBk ,如公式(6)和(7)所述。
$$
\Delta W_k = \alpha \cdot \Delta_k \cdot y_{hk}
$$
$$
\Delta B_k = \alpha \cdot \Delta_k
$$
其中yhk表示隐藏层输出。
iv. 隐藏层Δhk中神经元的误差梯度使用(8)计算。
$$
\Delta_{hk} = \Delta_k \cdot W_{hk} \cdot y_{hk} (1 - y_{hk})
$$
v. 使用预定义的学习率α计算隐藏层的权值和偏置修正值ΔWhk和ΔBhk,如公式(9)和(10)所述。
$$
\Delta W_{hk} = \alpha \cdot \Delta_{hk} \cdot y_{hk}
$$
$$
\Delta B_{hk} = \alpha \cdot \Delta_{hk}
$$
vi. 除输入层外,所有层的权重和偏置Wi,new和Bi,new均使用(11)和(12)中所述的相应权值和偏置修正值进行更新。
$$
W_{i,new} = W_{i,old} + \Delta W_i
$$
$$
B_{i,new} = B_{i,old} + \Delta B_i
$$
vii. 重复步骤(i)到(vi),直到满足停止准则。
6) 3D‐DCNN架构
用于训练Color Skl‐MHI和RJI数据以识别人类活动的三维深度卷积神经网络架构如图7所示。在此架构中,尺寸为62×62的归一化的Color Skl‐MHI和尺寸为15×19的 RJI被用作输入数据,每个隐藏层由卷积(Conv)和池化(Pool)、丢弃(Drop)以及神经元激活(ReLU)操作组成。该架构包含三个隐藏层(i=1, 2, 3)。各Conv和Pool层的预定义核大小和初始化类型见表I。三个隐藏层的丢弃率分别为0.1%、0.2%和0.3%。
对于卷积层的权重初始化,采用微软亚洲研究院(MSRA)提出的方法。该方法非常适合ReLU。对于全连接层(FC),使用大小为1,000的权重向量,并在输出层应用softmax函数以获得每个可能动作的概率。所有权重均使用反向传播算法结合随机梯度下降法进行训练。
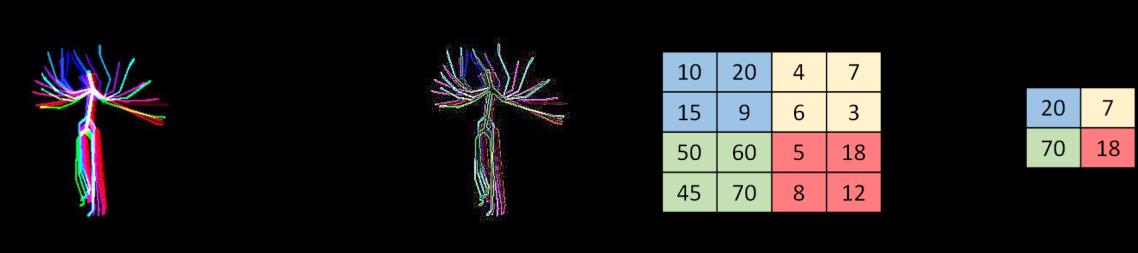
| 层 | 滤波器大小 | 初始化类型 | 特征图 |
|---|---|---|---|
| 卷积层1 | 7×7 | MSRA | 3 |
| 池1 | 2×2 | MAX | 3 |
| 卷积2 | 5×5 | MSRA | 10 |
| 池2 | 2×2 | AVE | 10 |
| 卷积3 | 3×3 | MSRA | 15 |
| 池3 | 2×2 | AVE | 15 |
IV. 实验结果
我们在两种不同的数据集上对所提出的HAR进行了多种条件下的实验:UTKinect动作3D数据集和CAD‐60先进的公开的人类活动3D数据集。这些数据集包含了喝水、接电话和做饭等日常活动。在UTKinect动作3D数据集中,我们通过多个摄像头视角和时间持续长度观察了相同的动作。在该数据集中,我们还观察了不同人执行相同动作的情况,每个人以不同的方式完成动作,这被称为高类内差异。在CAD‐60数据集中,我们在多个不同环境(如厨房、办公室和浴室)中进行了这些实验。该数据集包含不同动作之间的高度相似性,这对识别技术来说尤其具有挑战性。来自这两个数据集的实验结果表明了所提出HAR的有效性。详细参数和实验数据可在 http://github.com/CNPhyo/ColorSklMHI‐and‐RJI‐based‐HAR 下载。
A. UTKinect动作3D数据集
该数据集中的视频使用单个固定深度相机拍摄,包含10名不同受试者执行的10个动作。每名受试者均执行所有动作两次。该数据集提供了199个动作序列中20个关节的3D位置[17]。此数据集包含视角变化和高类内差异。为了进行实验,我们通过连接20个骨骼关节并在每15帧内将其组合来生成Color Skl‐MHI和RJI数据。在性能评估中,采用省略一个受试者的交叉验证方法。我们交替使用9名受试者的动作作为训练数据,并省略1名受试者的数据用于测试来训练3D‐DCNN模型。在使用RJI数据训练3D‐DCNN的情况下,需要针对4种RJI分别训练3D‐DCNN模型:RJI (J5)、RJI (J9)、RJI (J13)、RJI (J17)。因此,在所有实验中,使用RJI数据总共训练了40个模型(4 × 10受试者),而基于Color Skl‐MHI的模型则训练了10个(1 × 10受试者)。
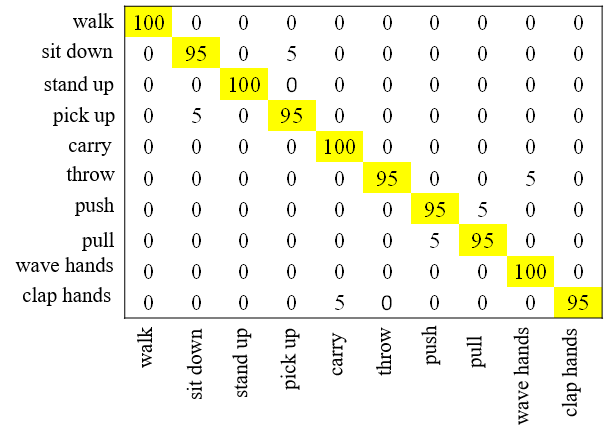
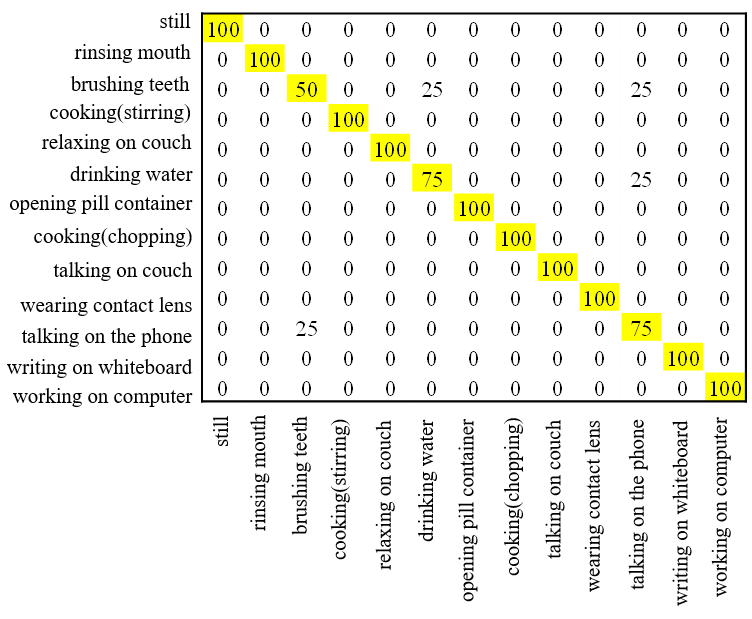
首先,使用Color Skl‐MHI训练3D‐DCNN。UTKinect动作3D数据集中10种日常活动的Color Skl‐MHI样本如图8所示。在评估中,基于Color Skl‐MHI的方法达到了94%的总体准确率。然后,也使用RJI训练3D‐DCNN。拾取物体和挥手动作中涉及的四个参考关节(J5、J9、J13、J17)的RJI样本分别如图9和图10所示。采用相同的评估方法,基于RJI的3D‐DCNN达到了95%的总体准确率。在完成对Color Skl‐MHI和RJI的3D‐DCNN训练后,通过对相应动作的概率进行平均并选择具有最大概率的动作来进行两个3D‐DCNN的决策融合。决策融合方法的详细混淆矩阵见图11。从表II可以看出,提出的系统达到了97%的总体准确率,高于其他最先进的方法。
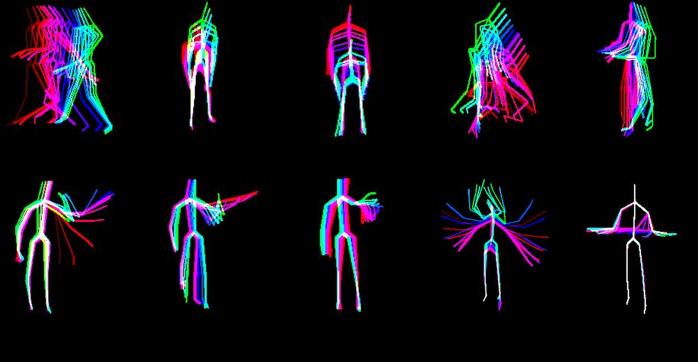 RJI (J5),(b) RJI (J9),(c) RJI (J13),(d) RJI (J17))
RJI (J5),(b) RJI (J9),(c) RJI (J13),(d) RJI (J17))
 RJI (J5),(b) RJI (J9),(c) RJI (J13),(d) RJI (J17))
RJI (J5),(b) RJI (J9),(c) RJI (J13),(d) RJI (J17))

| 方法 | 准确率 (%) |
|---|---|
| L. Mengyuan 等人 (2016) [15] | 95.50 |
| L. Zhi 等人 (2014) [16] | 95.00 |
| X. Lu 等人 (2012) [17] | 90.92 |
| M. Devanne 等人 (2013) [21] | 91.50 |
| A. Chrungoo 等人(2014年)[22] | 91.96 |
| 颜色Skl‐MHI 3D‐DCNN | 94.00 |
| RJI 3D‐DCNN | 95.00 |
| 提出的系统 | 97.00 |
| ## B. CAD‐60日常活动数据集 | |
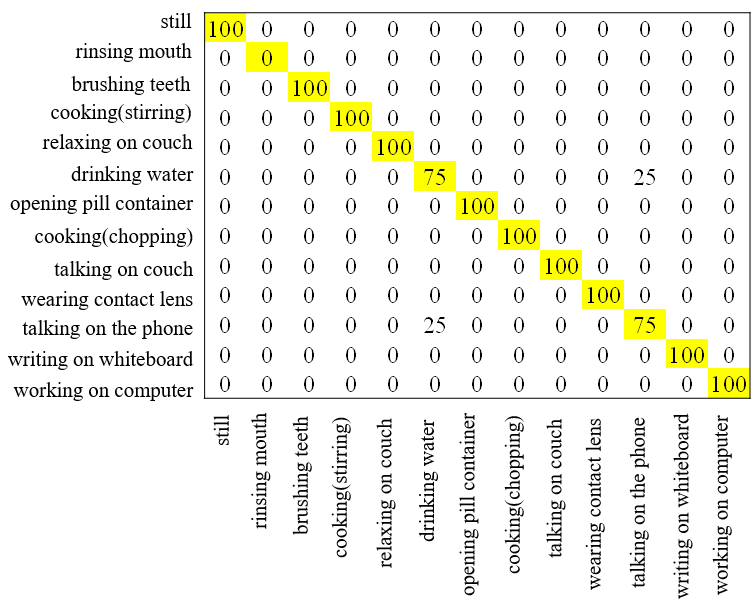
| CAD‐60日常活动数据集包含由4人在5种不同环境(如办公室、厨房、卧室、浴室和客厅)中执行的12种高级日常活动和1种静止活动[23]。由于动作之间的高度相似性,该数据集具有挑战性。在生成彩色Skl‐MHI和RJI数据时,我们使用每15帧内的骨骼关节信息。为了提高对左撇子个体动作识别的性能,将彩色Skl‐MHI和RJI数据进行镜像处理,使其动作与其他三位右撇子的行为相似。图12展示了CAD‐60数据集中10种日常活动的彩色Skl‐MHI样本。在性能评估方面,我们采用了与UTKinect动作3D数据集相同的方法:通过轮流使用3人的数据进行训练,剩下1人的数据用于测试来训练3D‐DCNN模型。所有实验中,基于彩色 Skl‐MHI训练的模型总数为4(人),基于RJI的为16(4×4人)。在CAD‐60日常活动数据集上,基于彩色 Skl‐MHI和RJI的3D‐DCNN分别达到了71.15%和86.5%的总体准确率,而决策融合方法的准确率达到92.31%。 |
在图13中,我们可以看到提出的系统能够以100%的准确率识别大多数动作。然而,由于手部位置接近,少数动作被误识别。考虑到环境因素以解决此类问题。应用这些环境考虑后,总体准确率提高到96.15%,如图14所示。刷牙与打电话以及刷牙与喝水的动作无法区分的情况已被消除,因为这些动作在不同环境中进行了实验。表III比较了其他最先进的方法的准确率、精确率和召回率。如我们所见,提出的系统表现出更优越的性能。其他方法的结果来自CAD‐60日常活动数据集网站。该网站包含使用此数据集的其他方法的性能报告[23]。由于其他作者报告其算法性能时仅提供了精确率和召回率或准确率,因此表III中存在一些空白单元格。
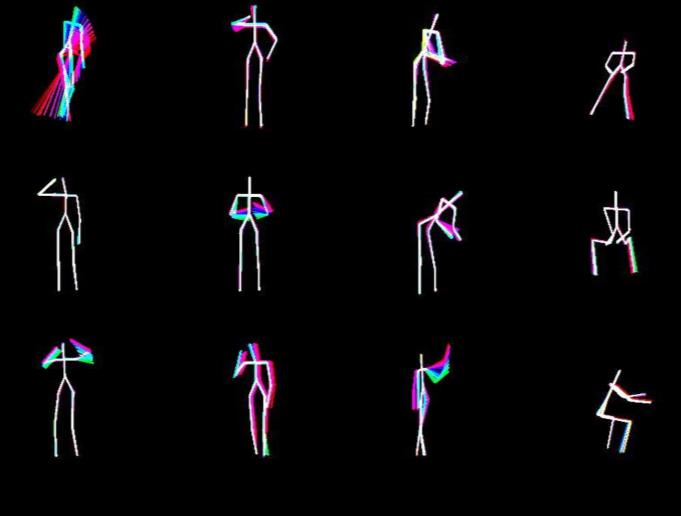
| 方法 | 准确率 (%) | 精确率 (%) | 召回率 (%) |
|---|---|---|---|
| N. Bingbing 等人 (2012) [24] | 65.32 | – | – |
| R. Gupta 等人 (2013) [25] | – | 78.10 | 75.40 |
| J. 王 等人 (2013) [26] | 74.70 | – | – |
| Y. 朱 等人 (2014) [27] | – | 93.20 | 84.60 |
| D. R. 法里亚 等 (2014年) [28] | – | 91.10 | 91.90 |
| J. 单 等 (2014年) [29] | – | 93.80 | 94.50 |
| S. 加利奥 等 (2014年) [30] | – | 77.30 | 76.70 |
| G. I. 巴里斯 等 (2015年) [31] | – | 91.90 | 90.20 |
| E. 奇皮泰洛 等 (2016年) [32] | – | 93.90 | 93.50 |
| 颜色Skl‐MHI 3D‐DCNN | 71.15 | 70.02 | 69.39 |
| RJI 3D‐DCNN | 86.50 | 82.78 | 82.08 |
| 提出的系统 | 96.15 | 90.39 | 88.46 |
V. 讨论
由于采用了彩色Skl‐MHI和RJI,提出的系统具有低计算成本。结果对于实时应用非常有前景。所提出系统的处理时间基于彩色Skl‐MHI和RJI的特征提取时间以及使用15 fps视频数据的分类时间进行评估。为了比较时间复杂度,提出的系统在与[17]中描述相同的硬件环境下进行测试。然后,我们的提出的系统进行特征提取耗时0.0636秒,并且对于来自UTKinect动作3D数据集的1个输入序列,平均测试时间为0.0081秒,而[17]中的系统对同一数据集的序列平均测试时间为0.0125秒。此外,在相同规格的机器上执行时,使用我们提出的系统进行特征提取的平均耗时为0.1179秒,而[32]中的方法对UTKinect动作3D数据集的1个序列耗时0.18秒。
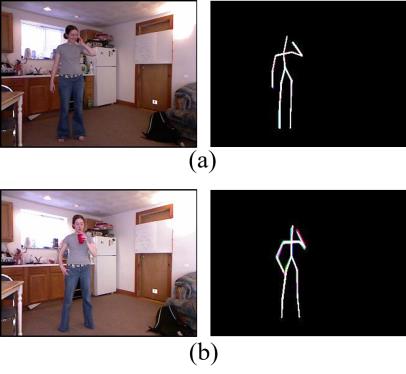
此外,由于使用了彩色Skl‐MHI,对于UTKinect动作3D数据集中具有相似运动模式的动作(如投掷和推)也能够正确区分,如图15(a)和图15(b)所示。对于CAD‐60日常活动数据集,提出的系统误识别了喝水和打电话等动作。如图16(a)和图16(b)所示,这是因为这些动作包含的运动非常少,且手部位置非常接近。这表明,为了正确分类这些动作,必须考虑之前状态的历史信息。
 投掷, (b) 推)
投掷, (b) 推)
 打电话, (b) 喝水)
打电话, (b) 喝水)
VI. 结论
本文提出了一种智能人体动作识别系统,旨在开发成一种消费电子产品(具有低计算成本和高精度的特点),用于自动监测和识别独居老年人的日常活动。此外,该系统不受环境条件或领域结构的限制,且由于处理速度快,非常适合实时应用。本系统解决了视角变化(单摄像头)和类内差异的问题。实验结果表明,所提出的系统在UTKinect Action‐3D和CAD‐60日常活动数据集上的表现优于其他最先进的方法。未来,该系统将结合可供性假设进一步改进动作识别。还将针对与健康问题相关的复杂动作(如头痛和呕吐)在相关数据集上进行更多实验。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)