自动驾驶新成果!基于CARLA的多车协同3D感知数据集与评测方法
当单车感知遇到遮挡和距离限制时,车对车协同如何实现更完整的3D场景理解?如何利用CARLA仿真环境,突破传统LiDAR标注的稀疏性瓶颈?
编者荐语:
随着V2X协同感知在自动驾驶领域的广泛应用,如何提升多车协同环境中的感知精度变得尤为重要。本文基于CARLA构建了一个用于协同3D语义占用预测的数据集Co3SOP,旨在弥补现有数据集在多车协同感知中的不足。借助CARLA的高保真仿真能够生成丰富且精细的体素级标注数据,支持更精确的感知和预测任务。让我们一起深入了解这项推动自动驾驶协同感知发展的创新工作!

论文链接:arxiv.org/abs/2506.17004
项目主页:github.com/tlab-wide/Co3SOP
亮点直击
- 提出Co3SOP,首个基于仿真直接生成密集体素标注的V2V协同3D语义占用预测数据集。
- 通过在 CARLA 中开发高分辨率语义体素传感器,提供密集完整的体素级标注,突破了基于 LiDAR 生成标注的稀疏性限制。
- 建立了25.6m、51.2m 和 76.8m三种不同预测范围的基准测试,系统评估空间范围对协同预测效果的影响。
- 提出Co3SOP-Base 基线模型,通过空间对齐和置信度引导的稀疏注意力机制实现多智能体特征融合,在所有基准测试中显著优于单车模型。
- 数据集覆盖100×100×7m³的空间范围,0.1m 分辨率,包含24 个语义类别,支持灵活的多对多协同配置。
总结速览
解决的问题
在自动驾驶中,单车的 3D 语义占用预测能力受到遮挡、传感器范围限制和狭窄视角的固有约束。虽然协同感知可以通过交换互补信息来增强感知的完整性和准确性,但目前缺乏专门用于协同 3D 语义占用预测的数据集和基准。现有数据集主要依赖单车 LiDAR 点云生成标注,存在稀疏性问题,且不支持多智能体配置。
提出的方案
Co3SOP 通过在 CARLA 中重放 OPV2V 多智能体驾驶场景,使用自主开发的高分辨率语义体素传感器生成密集的体素级标注。该方案不依赖于传感器可见性,而是利用 CARLA 的语义引擎直接获取完整的几何和语义信息,为每个体素分配类别标签(包括" 空" 类),消除了“未知”标签,提供了适合协同设置的时空对齐的多智能体标签。
应用的技术
- 自定义语义体素传感器:利用虚幻引擎的碰撞和重叠检测功能,高效获取体素级的占用和语义信息。
- 多阶段体素标注流水线:包括自顶向下的粗范围框追踪、基于对象的占用补全和标签分配,通过并行化的广度优先搜索(BFS) 实现高效标注。
- Co3SOP-Base 基线模型:采用图像可变形交叉注意力将 2D 特征提升到 3D 空间,通过3D 仿射变换对齐多智能体特征,使用混合注意力掩码调制的体素可变形交叉注意力进行特征融合。
达到的效果
- 生成了覆盖100×100×7m³空间、0.1m 分辨率的密集 3D 语义体素标注,显著优于基于 LiDAR 的标注方法。
- 在三种预测范围下,协同模型相比单车模型mIoU 分别提升了:25.6m 范围提升0.68,51.2m 范围提升1.81,76.8m 范围提升2.19。
- 对大型或易遮挡类别(如车辆)的预测性能提升尤为显著,在 76.8m 范围内车辆类 IoU 从 34.32 提升至 50.98。
- 模型在存在定位噪声的情况下仍保持相对稳定的性能,展现了良好的鲁棒性。
方法:基于仿真的密集体素标注
语义体素标注流水线
Co3SOP 的核心创新在于开发了一个高效的语义体素标注流水线,克服了传统基于 LiDAR 标注的稀疏性问题。该流水线利用 CARLA 高保真仿真环境的优势,直接从场景的 3D 几何和语义信息生成完整的体素标注。
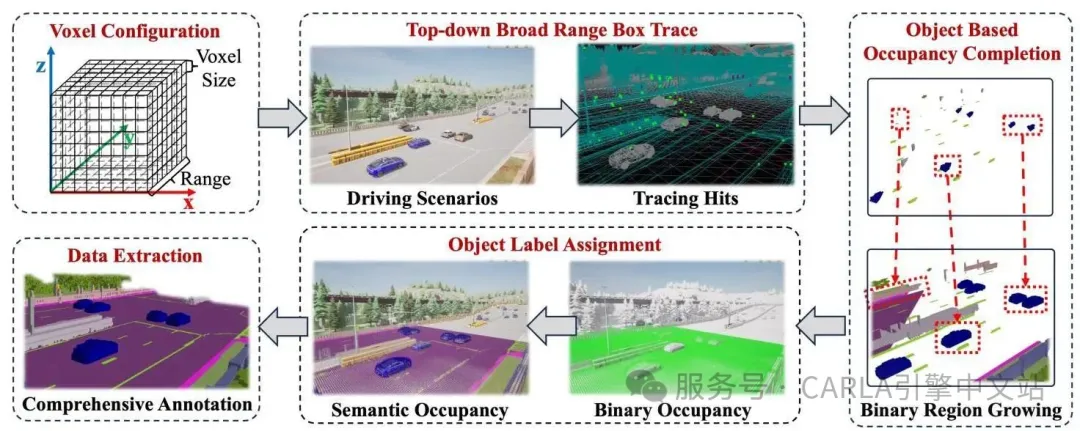
包括体素配置、自顶向下的粗范围框追踪、
基于对象的占用补全和标签分配四个关键步骤
标注流程包括以下关键步骤:
- 传感器配置:体素以每个自车为中心,配置特定的传感器参数,包括体素范围和分辨率。这些设置决定了场景如何被划分为 3D 体素。例如,100×100×4.8m³ 的检测范围在 0.1m 分辨率下会产生约 4800 万个检测操作。
- 自顶向下的粗范围框追踪:执行自顶向下的重叠检测,粗略识别与体素化场景相交的所有物理对象。记录每个对象的交点(即影响体素),用于初始化可能被占用的种子体素列表。
- 基于对象的占用补全:对每个对象,从其种子体素开始执行并行化的广度优先搜索(BFS)。BFS 选择性地扩展到六个相邻体素(上、下、左、右、前、后),执行细粒度的碰撞检查以确定占用情况。如果发现邻居被占用,则将其添加到种子体素中。这种局部探索持续迭代,直到标注了所有可达的占用体素。
- 对象标签分配:占用补全后,从 CARLA 检索相交对象的语义类别,并分配给其每个占用体素,完成体素级标注过程。
数据集统计与特性
Co3SOP 提供了密集的 3D 语义体素标注,覆盖以每个自车为中心的100×100×7m³空间范围。每个体素大小为0.1×0.1×0.1m³,总体素分辨率为1000×1000×70。所有体素都参考车辆坐标系,轴的边界为x∈[-50,50]m(左到右)、y∈[-50,50]m(前到后)和z∈[-2,5]m(下到上)。
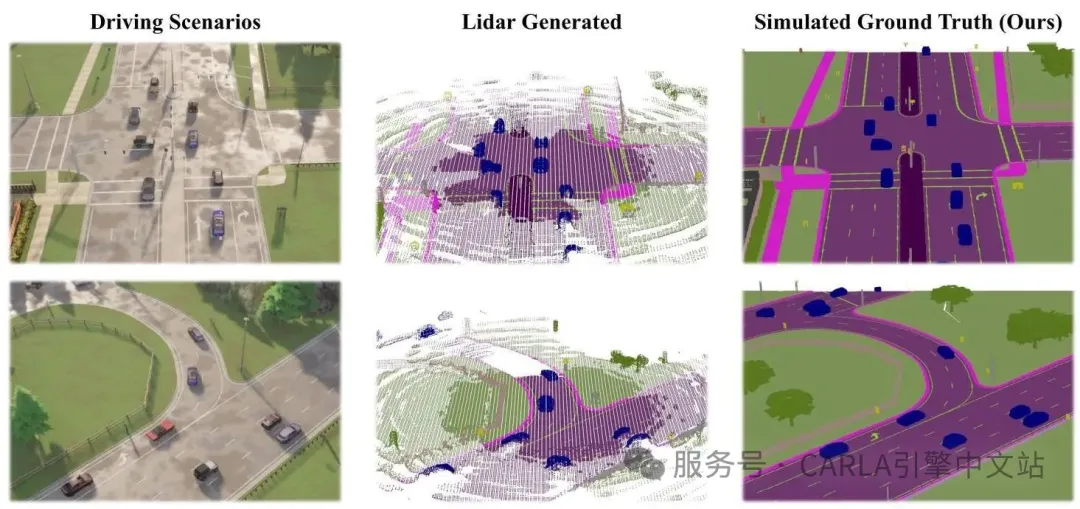
左:CARLA中三个V2V场景的截图;
中:基于LiDAR生成的3D语义体素标注;
右:使用研究开发的3D语义体素传感器收集的标注
如图所示,与基于 LiDAR 扫描生成的标注相比,Co3SOP 的标注流水线产生了显著更密集和完整的语义体素标注,特别是在遮挡或远距离区域,LiDAR 标注会因稀疏性和数据缺失而受到影响。
Co3SOP-Base:协同 3D 占用预测基线
为了充分利用 Co3SOP 数据集的优势,研究提出了Co3SOP-Base 基线模型,旨在高效整合多智能体观测和空间知识,生成统一的基于体素的预测。
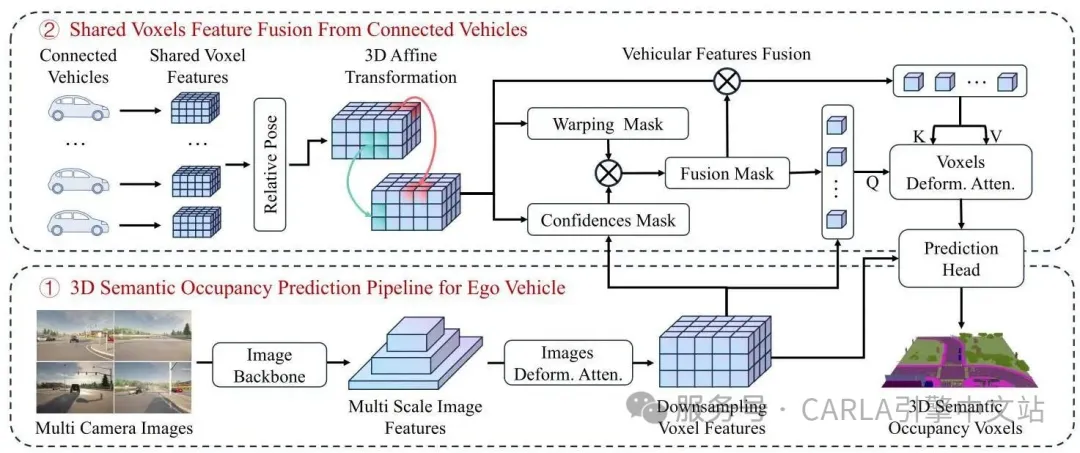
(1)自车预测流水线,包括图像主干网络、图像可变形注意力和预测头;(2)V2V特征融合流水线,包括3D仿射变换和掩码体素可变形注意力
模型的关键组件包括:
- 图像主干网络:采用ResNet101-DCN作为图像主干网络,从多视角相机图像中提取多尺度图像特征。提取的特征通过特征金字塔网络(FPN) 进一步细化,以聚合跨尺度的上下文信息。
- 图像可变形交叉注意力:为了将 2D 图像特征整合到 3D 空间中,应用了图像可变形交叉注意力机制。该机制聚合多视角 2D 特征,并学习将它们映射到相应的 3D 体素位置,通过考虑几何关系确保从 2D 到 3D 空间转换时保持空间一致性。
- 3D 仿射变换:在多智能体融合之前,使用受空间变换网络启发的3D 仿射变换模块,将邻近智能体的体素特征变换到自车坐标系。变换矩阵根据智能体之间的相对位姿计算,确保来自不同坐标系的体素特征得到正确对齐。
- 掩码体素可变形交叉注意力:为实现鲁棒和自适应的融合,每个车辆维护一个可学习的置信度掩码,估计其特征的体素级可靠性。此外,在特征对齐期间生成二进制变形掩码以指示有效投影区域。这两个掩码组合形成混合注意力掩码,调制体素可变形交叉注意力。
- 预测头:Co3SOP-Base 的最后阶段是预测头,应用一系列3D 卷积和 3D 反卷积,逐步将融合的体素特征上采样到原始分辨率,并输出 3D 语义占用结果。
损失函数
为了监督协同 3D 占用预测,研究结合了三种损失函数:
- 用于语义分类的体素级交叉熵损失
- 场景类亲和力损失,鼓励语义和几何特征之间的一致性
- 置信度损失,正则化学习的置信度掩码以实现智能体间特征一致性
实验:多范围协同感知评估
数据集和评估指标
为了在不同空间条件下评估协同 3D 语义占用预测的性能,研究在基准测试中定义了三种感知范围设置:
- 25.6×25.6×4.8m³范围,0.1m 体素大小
- 51.2×51.2×4.8m³范围,0.2m 体素大小
- 76.8×76.8×4.8m³范围,0.3m 体素大小
这些设置使研究能够评估随着覆盖区域增加,协同感知如何改善场景理解,特别是在单车感知能力受限的遮挡或远距离区域。评估采用交并比(IoU),包括每个类别的单独 IoU 以及所有语义类别的平均 IoU(mIoU)。
基准方法对比
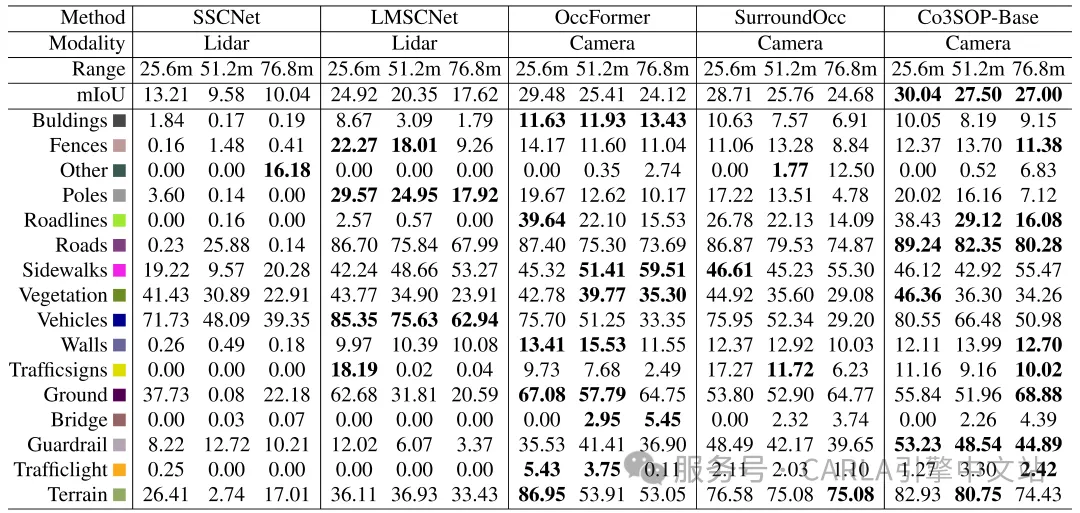
报告了最先进方法和基线模型在三个不同范围任务下的mIoU以及部分对象类别的IoU
实验结果表明,研究提出的 Co3SOP-Base 在所有三个感知范围内始终取得最佳的整体性能,mIoU 分别为30.04(25.6m)、27.50(51.2m) 和27.00(76.8m)。这些结果突出了协同体素融合的有效性,特别是随着空间范围的增加。
在四种选定的方法中,基于相机的方法在整体 mIoU 上始终优于基于 LiDAR 的方法,突显了它们从密集 RGB 输入中捕获丰富语义特征的优势。然而,基于 LiDAR 的模型在某些对象类别上仍然表现出优势,特别是在短距离设置中的车辆和杆子等类别,这些类别受益于 LiDAR 的精确几何结构。
消融研究
协同特征融合的效果
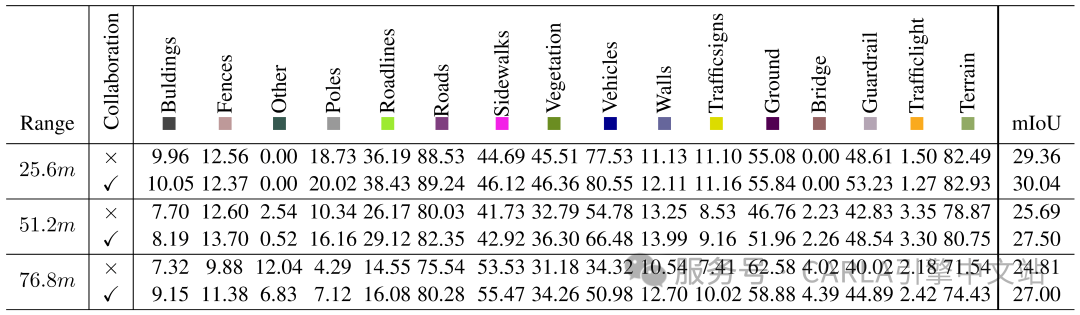
通过比较有无 V2V 特征融合的性能,研究发现协同在所有三个范围内始终提高 mIoU。增益在大范围设置中最为显著,其中智能体具有更广泛的可见性重叠,从互补视点中受益更多。对象级分析表明,协同显著增强了大型或易遮挡类别的性能,如车辆(例如,在 76.8m 时从 34.43 提升至 50.98 IoU)。
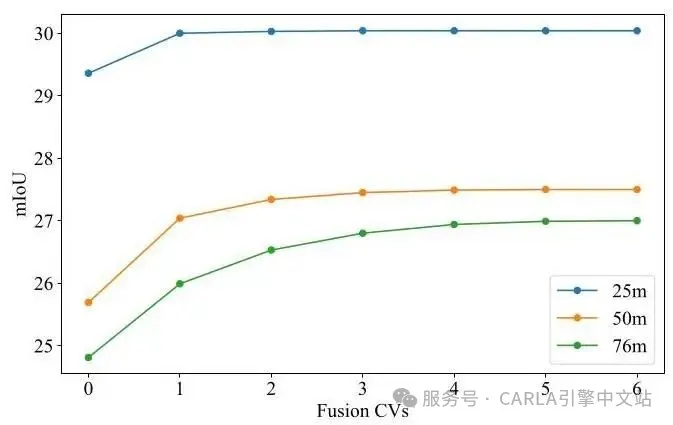
为了进一步探索协作规模的影响,研究评估了不同数量协作车辆下的性能。如图 4 所示,协作的性能增益主要来自1-2 个附近的智能体。在较短范围(25.6m)内,只有最近的协作者产生改进,而较大范围设置(51.2m、76.8m)由于增加的空间覆盖和互补视点而受益于额外的智能体。
对位姿噪声的鲁棒性
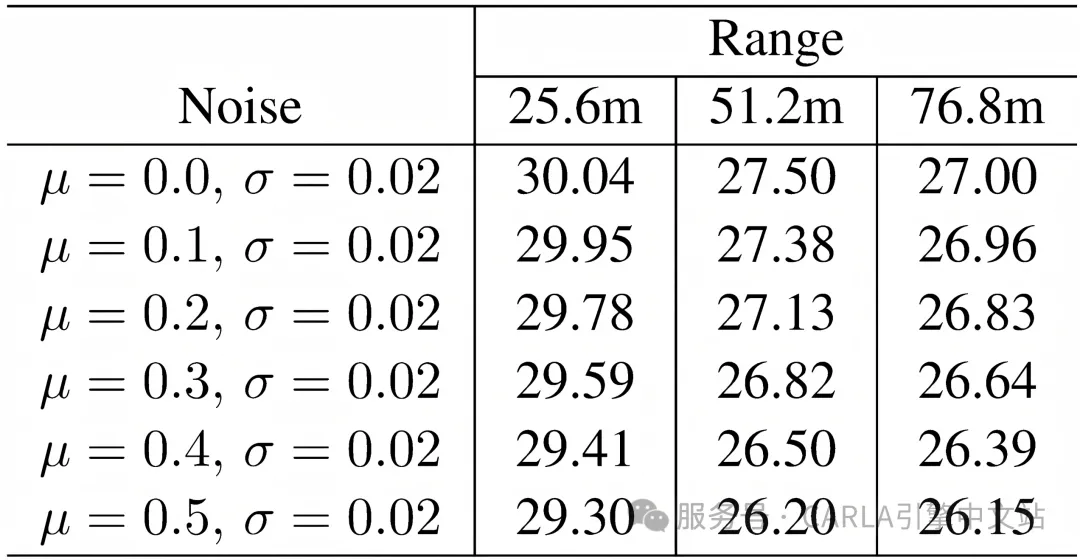
通过向用于智能体间特征对齐的相对变换注入高斯位姿噪声,研究评估了 Co3SOP-Base 在定位不确定性下的鲁棒性。如表 4 所示,将平均偏移从μ=0.1m 增加到 0.5m(固定标准差σ=0.02)会导致所有范围内的 mIoU 逐渐下降。然而,在中等噪声下性能保持相对稳定,表明基于变形的空间对齐和置信度感知融合在存在位姿扰动的情况下保持了合理的鲁棒性。
结论
Co3SOP作为首个基于仿真直接生成密集体素标注的协同3D语义占用预测数据集,通过高保真仿真和全面的体素标注,为多智能体感知系统的稳健评估提供了重要资源。与受LiDAR稀疏性限制的先前数据集不同,Co3SOP利用定制设计的体素标注流水线提供完整且细粒度的语义体素标签。
研究进一步提出的Co3SOP-Base 基线框架,通过结合置信度和对齐感知的掩码体素可变形注意力进行多智能体特征融合,在改善感知性能方面展现了V2V 协作的有效性,特别是在远距离或遮挡区域。
Co3SOP 数据集的推出,为推进协同场景下基于体素的 3D 场景理解研究奠定了坚实基础,有望推动自动驾驶感知技术向更智能、更全面的方向发展。
引用格式
Wu, H., Lin, P., Javanmardi, E., Bao, N., Qian, B., Si, H., & Tsukada, M. (2025). A Synthetic Benchmark for Collaborative 3D Semantic Occupancy Prediction in V2X Autonomous Driving. arXiv preprint arXiv:2506.17004.
💬 互动话题
这篇论文展示了CARLA在构建高质量协同感知数据集中的关键作用,通过自定义语义体素传感器实现了密集完整的3D占用标注,显著提升了多智能体协同感知的评估精度。Co3SOP数据集的发布为研究体素级3D场景理解提供了宝贵资源,推动了协同自动驾驶技术的发展。
你在使用CARLA进行多智能体仿真时,是否遇到过传感器开发或数据标注的挑战?对于V2X协同感知在实际部署中的应用前景,你有什么看法?欢迎在评论区分享你的经验和见解!我们将优先挑选最受关注的问题,安排详细的技术解析~
📢 加入社群添加小助手微信【synkrotron1】,备注“CARLA”即可加入开发者交流群,获取最新资源与1V1答疑!
往期推荐:
Carla联合仿真驱动数字孪生:多模态数据融合的混合交通主动安全验证框架

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)