中国国家土壤有机碳密度数据集(2010-2024)
中国国家土壤有机碳密度数据集(2010-2024)通过整合7,852个土壤剖面(23,103个样本)构建了迄今最完备的SOC密度数据库。研究采用集成学习方法填补了土壤容重缺失值,显著提升了青藏高原等地区的空间代表性。数据集提供标准化土壤属性、环境变量及元数据,支持碳循环研究和气候政策制定。该成果解决了传统SOC数据分辨率低、覆盖不均的问题,为"双碳"目标提供了重要基础数据支撑,
中国国家土壤有机碳密度数据集(2010-2024)
数据介绍
数据资源:中国国家土壤有机碳密度数据集(2010-2024)
背景与意义
1.土壤有机碳(SOC)的重要性
SOC是陆地生态系统的核心组分,影响土壤质量、农业潜力和气候调节。全球土壤表层1米内储存约2500 Pg碳,其中1500 Pg为SOC。SOC微小变化即可显著影响大气CO₂浓度,与中国"2030碳达峰、2060碳中和"目标密切相关。
2.数据缺口与挑战
•中国SOC数据长期存在分辨率低、空间覆盖不均(如青藏高原数据稀缺)、深层土壤(>100 cm)观测不足等问题。
•土壤容重(BD)缺失是SOC密度(SOCD)估算的主要瓶颈,因传统BD测量耗时且受砾石/根系干扰。
研究方法
1.数据来源与处理
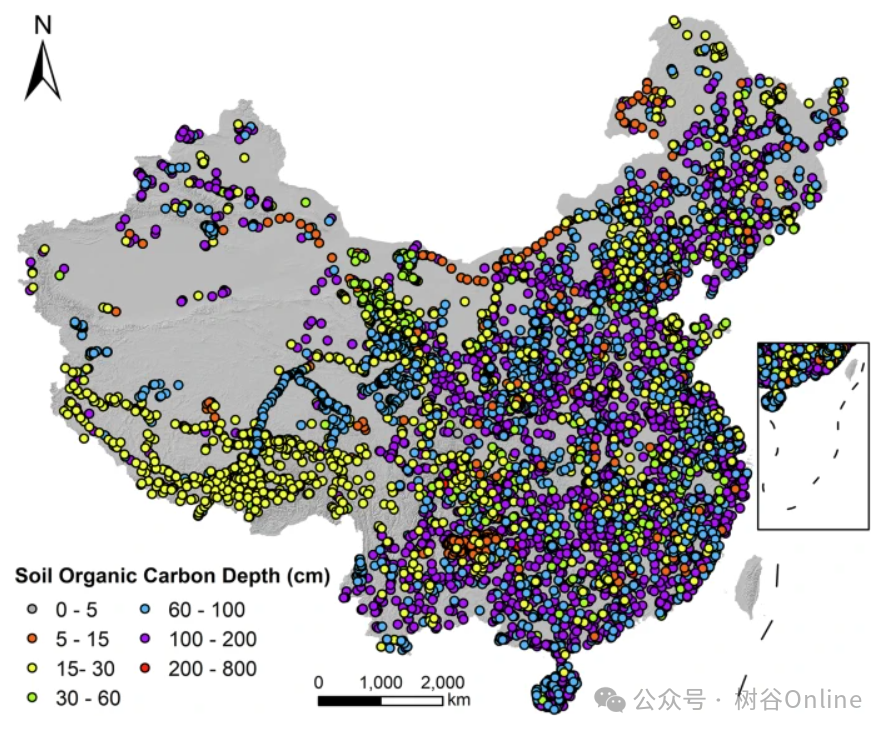
•整合7,852个土壤剖面(23,103个样本),覆盖中国全境(2010-2024年),最深至800 cm。
•数据源于国家土壤普查(2010s)、公开数据库(如时空三极环境大数据平台)及82篇文献(2015-2024年Web of Science检索)。
•新增青藏高原样本,显著改善空间代表性。
2.预测变量
涵盖土壤属性(pH、质地、SOC浓度)、地形(90m SRTM高程)、气候(1km分辨率降水/温度)、植被(30m NDVI)及土地利用(30m CLCD分类)。
3.集成建模(EM)框架
•采用Granger-Ramanathan加权回归融合四类机器学习模型:SVM、Cubist、随机森林(RF)、梯度提升机(GBM)。
•通过五折交叉验证优化权重,预测缺失BD值(图2a):
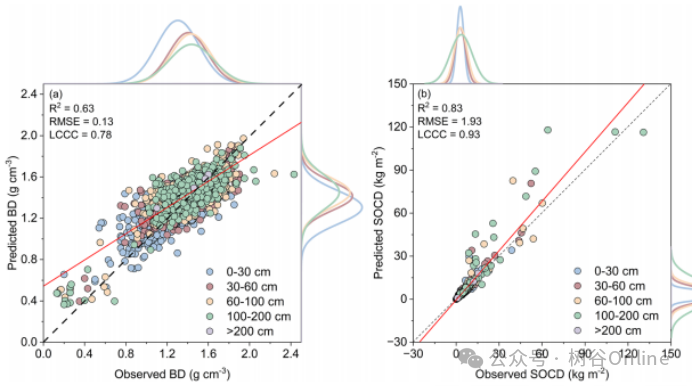
•性能指标:BD预测R²=0.63,RMSE=0.13 g cm⁻³;SOCD预测R²=0.83,RMSE=1.93 kg m⁻²(图2b)。
4.SOCD计算
公式:SOCD=SOC×BD×Depth×(1−CF)/100
其中CF为粗碎片比例,BD缺失值通过最优EM模型填补(5,053个样本)。
核心成果
1.数据集内容
•版本V9:包含23,103个样本的标准化SOCD数据,附带土壤属性、坐标、环境变量及元数据。
•版本V8:公开模型训练数据及预测结果,支持方法复现。
2.统计特征
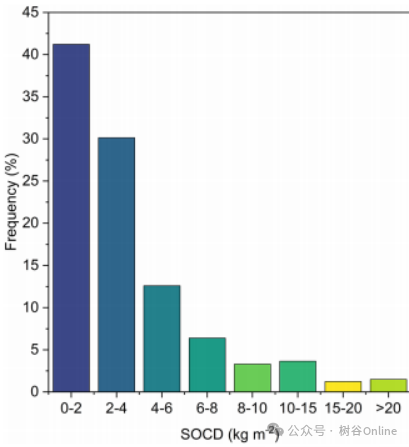
•SOCD均值:3.85 kg m⁻²,中位数:2.41 kg m⁻²,范围:0.0018–434.37 kg m⁻²(图3):
应用与局限
1.价值
•首次实现全国多深度(至800 cm)高分辨率SOCD覆盖,支持地球系统建模、碳汇评估及农业管理。
•为青藏高原碳储量研究提供关键数据。
2.局限与展望
•空间不确定性:稀疏采样区(如极端环境)需结合地统计学进一步验证。
•拓展应用:数据集可耦合遥感产品生成栅格化SOCD图,提升模型精度。
总结:本研究通过集成学习和多源数据融合,构建了中国迄今最完备的SOCD数据集,为碳循环研究和气候政策制定提供了重要基础。
数据信息
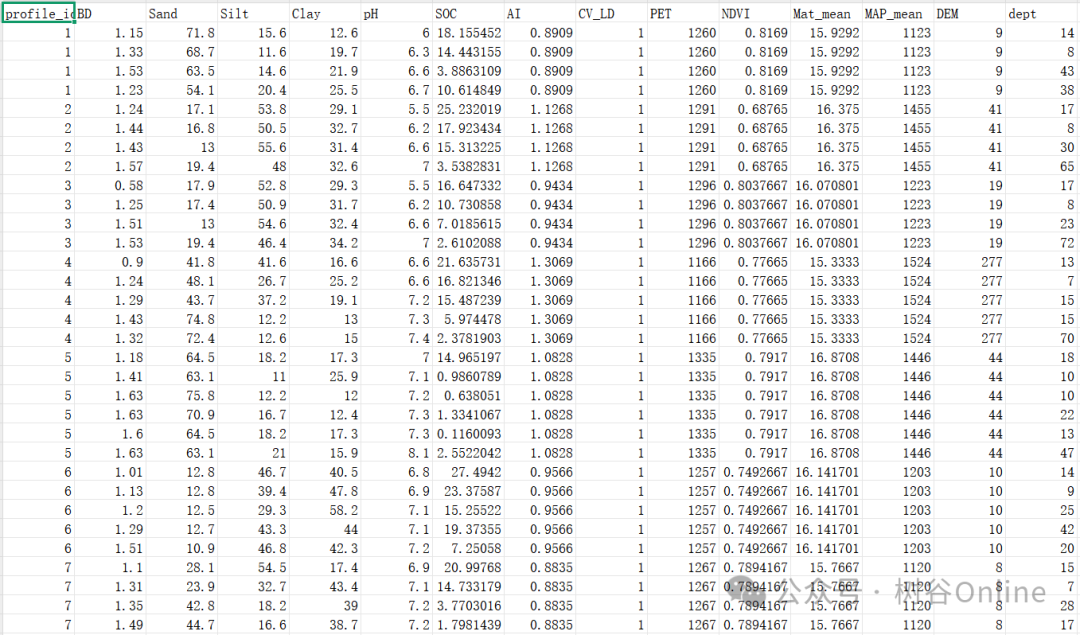
该数据集中国土壤有机碳密度(SOCD)数据集第9版(V9)。这套全国性尺度数据集采用集合建模方法,基于来自中国全境的23,103份土壤样本(7,852个剖面)开发而成。包含标准化的土壤属性数据(如容重BD、有机碳SOC、pH值、质地)、地理坐标、土层深度、环境协变量(高程、气候、土地覆盖)及元数据(如检测方法、采样年份)。
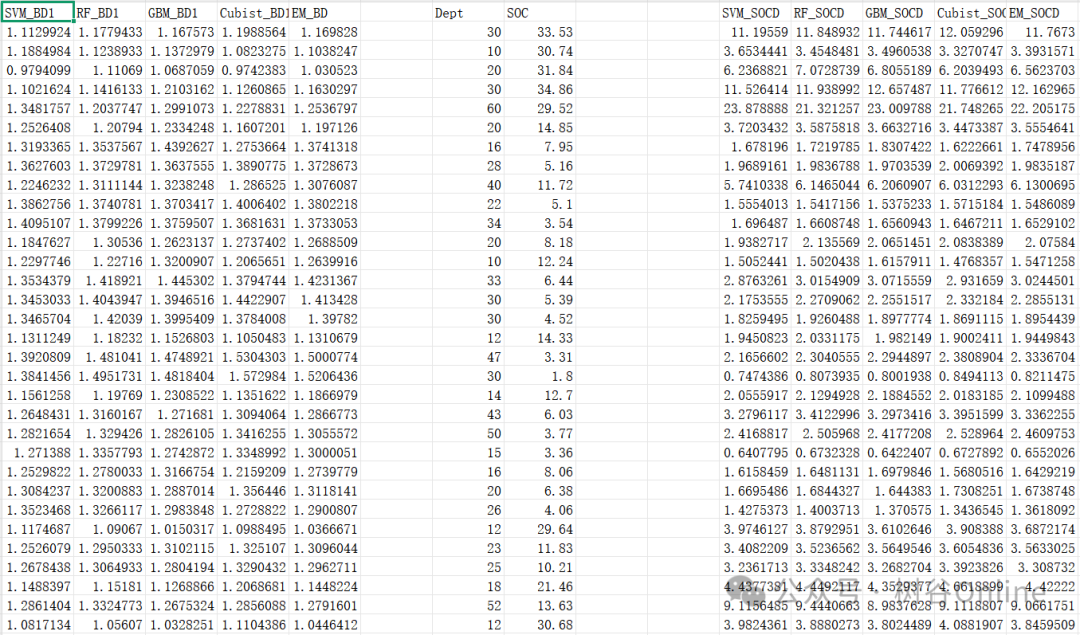
同时提供的第8版(V8)数据集包含用于开发集合土壤传递函数的模型训练数据与预测结果。V8版本侧重于研究方法可复现性与模型开发,而V9版本则是经过验证的最终数据集,可直接用于应用研究与结果解读。使用者需同时引用该数据集及本文献。
V9预览:
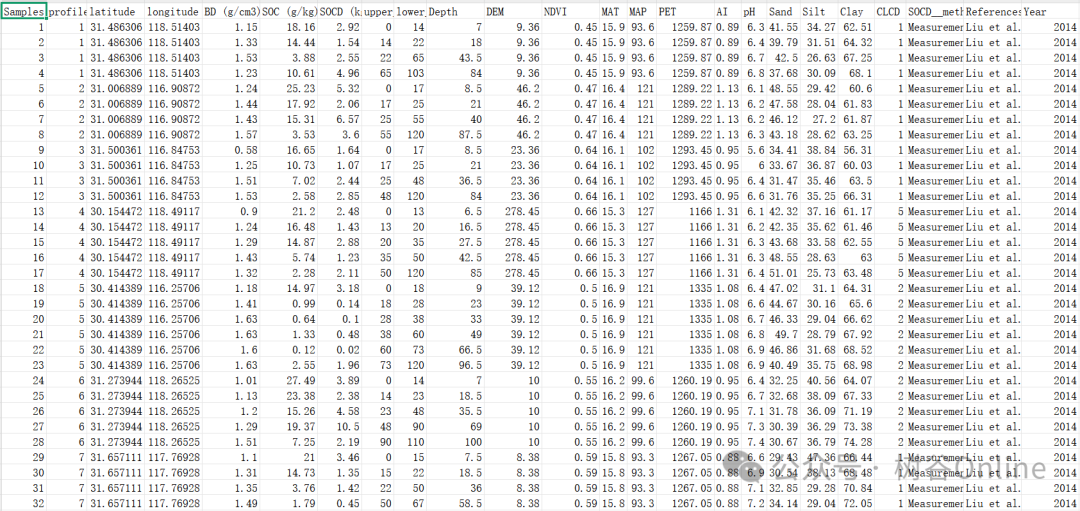
V8预览:
ensemble model_train_preeedicted_data.csv
ensemble model_train_data.csv
数据格式:CSV
数据容量:5.3MB

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)