深度学习中的音频表示方法(附代码)(波形图、频谱图、梅尔谱图、梅尔倒谱)
本文介绍了四种音频表示方法:波形图(Waveform)直接显示振幅随时间变化;频谱图(Spectrogram)通过STFT转换到时频域;梅尔谱图(Mel Spectrogram)将频率压缩到接近人耳感知的Mel刻度;梅尔倒谱(MFCC)对梅尔谱图进行DCT变换提取共振峰特征。每种方法各有优劣:波形图信息完整但难以建模,频谱图易建模但维度高,梅尔谱图接近人耳感知但会丢失信息,MFCC计算高效但无法还
·
波形图(Waveform)
是音频的最原始表示,也叫振幅图,衡量的是声音的震动幅度在时间维度上的状态。波形图的横坐标一般为时间,纵坐标一般为dB(即分贝)来表示。
- 优点:不丢失任何信息。
- 缺点:规律难以学习,难以进行长期依赖的建模
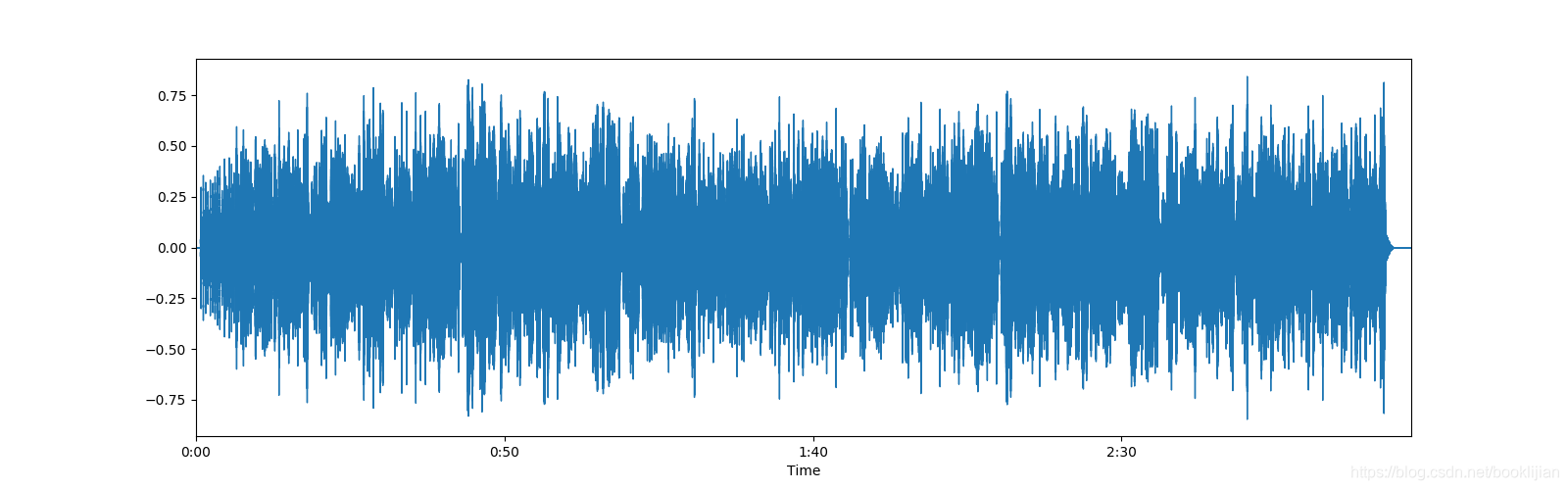
import librosa
import librosa.display
import matplotlib.pyplot as plt
audio_path = 'test.wav'
# y是波形,sr是采样率
y, sr = librosa.load(audio_path, sr=None)
plt.figure(figsize=(10, 4))
librosa.display.waveshow(y, sr=sr)
plt.title('Waveform')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')
plt.tight_layout()
plt.show()
频谱图(Spectrogram)
通过短时傅里叶变换(STFT)把声音从时域转换为频域信号,变成”时间+频率“的二维图像
- 优点:模型容易捕捉到其中的模式
- 缺点:频谱的维度高,且听感不直接
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
audio_path = 'test.wav'
y, sr = librosa.load(audio_path, sr=None)
D = np.abs(librosa.stft(y))
plt.figure(figsize=(10, 4))
librosa.display.specshow(librosa.amplitude_to_db(D, ref=np.max), sr=sr, x_axis='time', y_axis='log')
plt.title('Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.tight_layout()
plt.show()
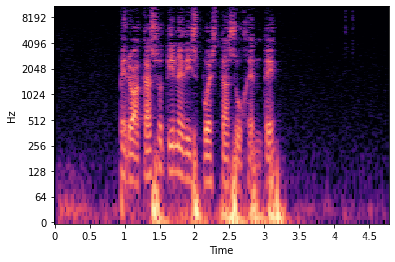
梅尔谱图(Mel Spectrogram)
一种特殊的频谱图,它通过压缩频谱轴的方式(高频拉伸、低频压缩),把频率压缩到更接近人类听觉感知的Mel刻度上,类似于热力图。
- 优点:这种表示更加紧凑,且最趋近人耳的感知,最为常见(FastSpeech、Tacotron)
- 缺点:丢失信息,不能精准还原
import librosa
import librosa.display
import matplotlib.pyplot as plt
audio_path = 'test.wav'
y, sr = librosa.load(audio_path, sr=None)
S = librosa.feature.melspectrogram(y, sr=sr, n_mels=128)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure(figsize=(10, 4))
librosa.display.specshow(S_dB, sr=sr, x_axis='time', y_axis='mel')
plt.title('Mel Spectrogram')
plt.colorbar(format='%+2.0f dB')
plt.tight_layout()
plt.show()
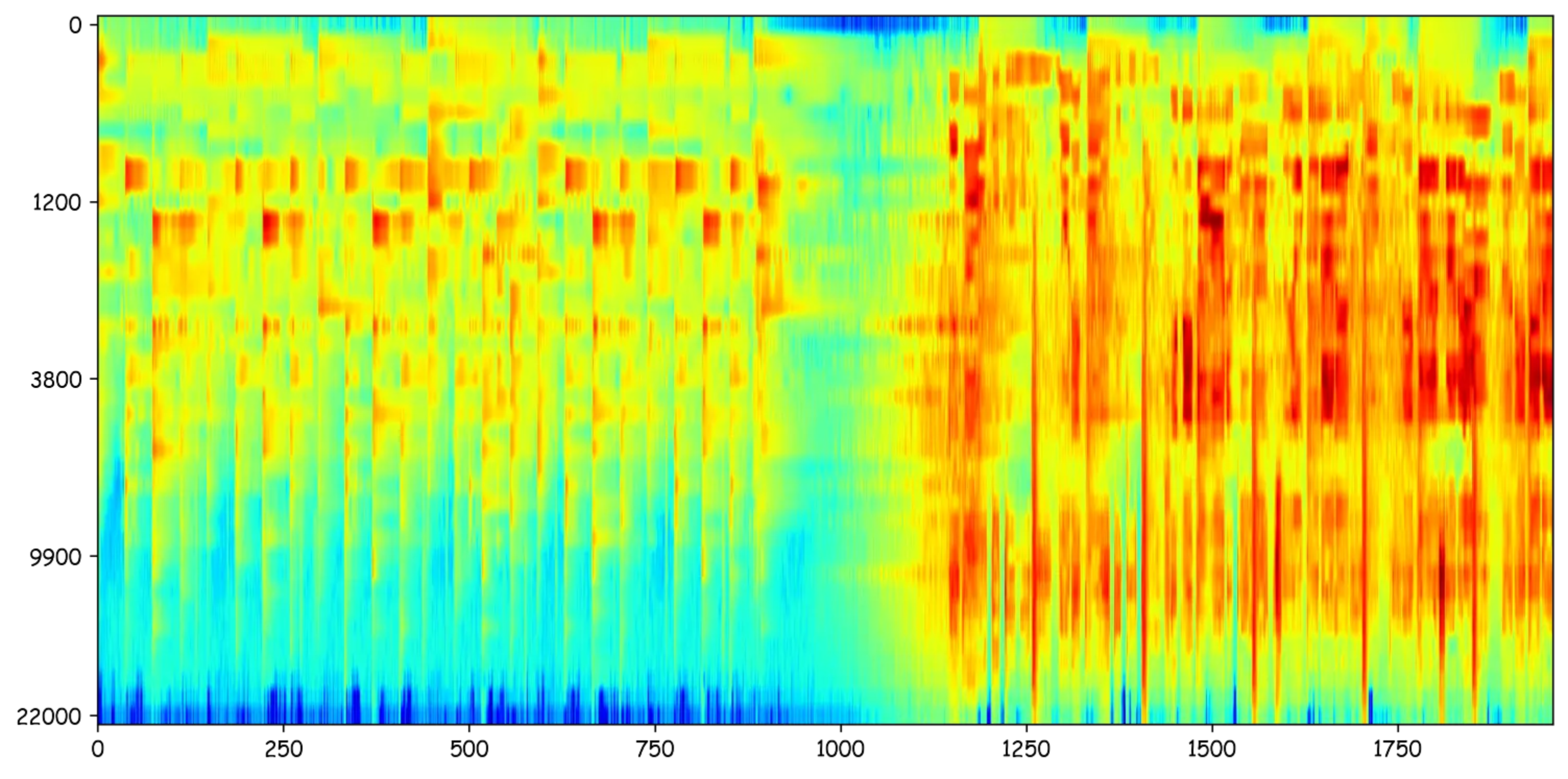
梅尔倒谱(MFCC)
对梅尔谱图再做一层 DCT(离散余弦变换),相当于提取音频的“共振峰”,是在进一步压缩信息的表示,把频谱数据变成一组更稳定、少量但足够的系数,适合做声纹识别、说话人识别。
- 优点:计算快,资源占用低,压缩强,信息密集
- 缺点:去掉了时序结构,不能反向还原音频
import librosa
import librosa.display
import matplotlib.pyplot as plt
audio_path = 'test.wav'
y, sr = librosa.load(audio_path, sr=None)
mfccs = librosa.feature.mfcc(y, sr=sr, n_mfcc=13)
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs, sr=sr, x_axis='time')
plt.title('MFCC')
plt.colorbar()
plt.tight_layout()
plt.show()
Audio Waveform
↓ STFT(短时傅里叶变换)
Spectrogram
↓ Apply Mel Filter Bank
Mel Spectrogram
↓ DCT(离散余弦变换)
MFCC

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)