使用大模型计算语义相似度
计算语义相似度的方法有很多,具体选择哪种方法取决于应用场景和数据类型。以下是一些常见的计算语义相似度的方法:
### 1. **基于词袋模型(Bag of Words, BoW)**
- **原理**: 将文本表示为词频向量,然后计算向量之间的余弦相似度。
- **优点**: 简单易实现。
- **缺点**: 忽略了词序和语义信息。
### 2. **TF-IDF(Term Frequency-Inverse Document Frequency)**
- **原理**: 结合词频和逆文档频率,计算文本中词语的重要性,然后计算向量之间的余弦相似度。
- **优点**: 考虑了词语在文档中的重要性。
- **缺点**: 仍然忽略了词序和语义信息。
### 3. **Word2Vec**
- **原理**: 通过神经网络模型将词语映射到高维向量空间,然后计算词语向量之间的余弦相似度。
- **优点**: 捕捉词语的语义信息。
- **缺点**: 需要大量语料训练,且无法直接处理短语或句子。
### 4. **Doc2Vec**
- **原理**: 类似于Word2Vec,但用于处理整个文档或句子,生成文档或句子的向量表示。
- **优点**: 能够处理整个文档或句子,捕捉上下文信息。
- **缺点**: 需要大量语料训练。
### 5. **GloVe(Global Vectors for Word Representation)**
- **原理**: 结合全局统计信息和局部上下文信息,生成词语的向量表示。
- **优点**: 在捕捉词语语义方面表现良好。
- **缺点**: 需要大量语料训练。
### 6. **BERT(Bidirectional Encoder Representations from Transformers)**
- **原理**: 使用Transformer模型,生成上下文相关的词向量表示,然后通过模型输出的向量计算相似度。
- **优点**: 能够捕捉复杂的上下文信息,适用于多种NLP任务。
- **缺点**: 计算复杂度高,需要大量计算资源。
### 7. **Sentence-BERT**
- **原理**: 基于BERT,专门用于生成句子的向量表示,然后计算句子之间的余弦相似度。
- **优点**: 在句子级别的语义相似度计算上表现优异。
- **缺点**: 计算复杂度高。
### 8. **Siamese Networks**
- **原理**: 使用共享权重的神经网络,输入两个文本,输出它们的相似度。
- **优点**: 可以自定义相似度计算方式,适用于特定任务。
- **缺点**: 需要大量标注数据进行训练。
### 9. **Jaccard相似度**
- **原理**: 计算两个文本集合的交集与并集的比值。
- **优点**: 简单易实现。
- **缺点**: 忽略了词频和语义信息。
### 10. **编辑距离(Levenshtein Distance)**
- **原理**: 计算将一个字符串转换为另一个字符串所需的最少编辑操作次数。
- **优点**: 适用于字符串相似度计算。
- **缺点**: 忽略了语义信息。
### 11. **基于知识图谱的方法**
- **原理**: 利用知识图谱中的实体和关系,计算文本之间的语义相似度。
- **优点**: 能够捕捉实体间的语义关系。
- **缺点**: 需要构建和维护知识图谱。
### 12. **基于深度学习的方法**
- **原理**: 使用深度神经网络(如LSTM、GRU、Transformer等)生成文本的向量表示,然后计算相似度。
- **优点**: 能够捕捉复杂的语义信息。
- **缺点**: 计算复杂度高,需要大量数据和计算资源。
### 总结
- **简单任务**: 可以选择基于词袋模型、TF-IDF、Jaccard相似度等简单方法。
- **复杂任务**: 建议使用深度学习方法,如BERT、Sentence-BERT等,以捕捉更复杂的语义信息。
选择合适的方法需要根据具体的应用场景、数据量、计算资源等因素综合考虑。
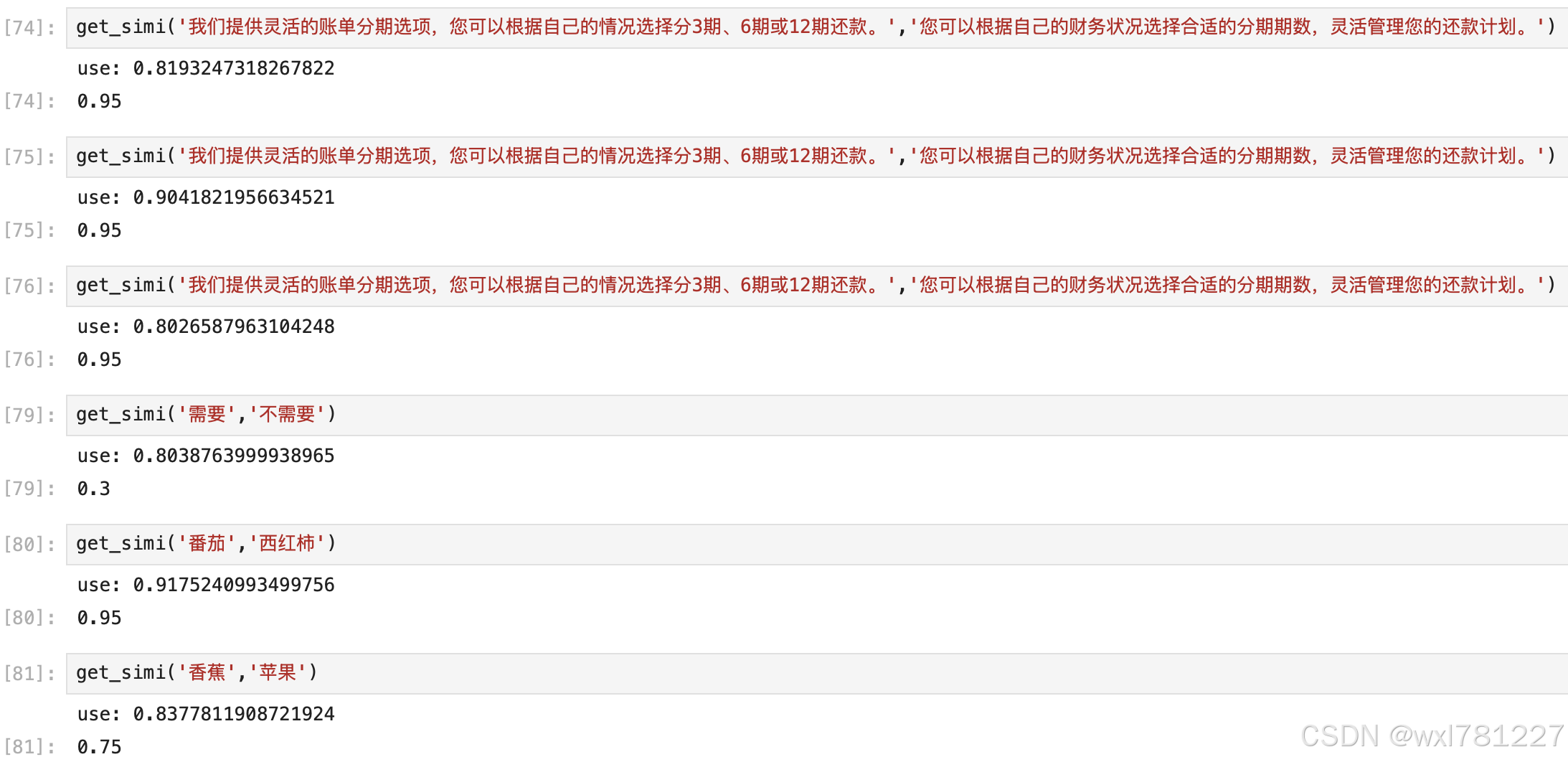
本文提供一种新的方法,主要因为在实际使用中大部分方法的准确率存在问题,如:TF-IDF准确率太低,值偏低,Sentence-BERT的值偏高,且不准确。本尝试使用大模型来计算语义相似度。
具体代码如下:
import requests
import json
import time
def get_simi(param1, param2):
start=time.time()
user_input=f"计算'{param1}'和'{param2}'的语义相似度,直接给出0-1之间的数值,以JSON格式输出,key为similarity."
data = {
"model": "qwen2.5",
"messages": [{"role": "user", "content": user_input}],
"stream": False,
"options": {"seed": 42, "temperature":0}
}
response = requests.post('http://172.17.0.7:11434/api/chat', json=data)
res = response.json()
result = res['message']['content']
result = json.loads(result.replace('```json\n','').replace('```',''))['similarity']
print('use:', time.time()-start)
return result结果如下:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)