【小白无痛】CLIP 多模态模型基石:从原理图解到 PyTorch 代码逐行复现
前言
在很长一段时间里,计算机视觉(CV)领域都面临着一个尴尬的瓶颈:我们训练的模型太“死板”了。
如果你用经典的 ImageNet 数据集训练一个 ResNet,它可能极其擅长识别那 1000 种预定义的物体。但如果你给它一张这 1000 类之外的照片,哪怕是三岁小孩都能脱口而出的东西,模型也会直接“瞎猜”一个离谱的答案。这种封闭集(Closed-set)的限制,曾经锁死了 AI 的想象力。
直到 2021 年,OpenAI 发布了 CLIP (Contrastive Language-Image Pre-training),彻底打破了图像与文字之间的次元壁。
CLIP 不再死记硬背固定的标签,而是学会了理解图像与自然语言之间的语义关联。它不仅拥有惊人的 Zero-Shot(零样本)分类能力,更是后来大火的 Stable Diffusion、DALL-E 等 AIGC 模型的“眼睛”和“地基”——没有 CLIP 对文本和图像的深刻理解,就没有现在 AI 绘画的百花齐放。
很多教程喜欢堆砌复杂的数学公式来解释 CLIP,但在我看来,代码才是程序员通用的语言。在这篇文章中,我将避开晦涩的公式,通过拆解 CLIP 最核心的 几十行 PyTorch 代码,带你从直觉上彻底搞懂:这个连接文字与像素的“多模态桥梁”,到底是怎么架起来的?
一、CLIP 的核心直觉 (The Intuition)
1、告别“死记硬背”,开始“看图识字”
- 老师(人类标注员)拿着一张图说:“这是猫(label: cat)”。
- 又拿一张图说:“这是狗(label: dog)”。
- 这种方式虽然有效,但很死板。如果给它看一张“斑点狗”,它可能因为只学过“黄狗”而不知所措。
而 CLIP 的学习方式,更像是给孩子看绘本。 OpenAI 从互联网上收集了 4 亿 (400 million) 组的配对数据。

CLIP 不需要你告诉它“这是披萨”,它只需要通过阅读大量的这种“图文对”,自己去领悟图像内容和文本语义之间的关系。
2、核心架构:双塔结构 (Two-Tower Architecture)
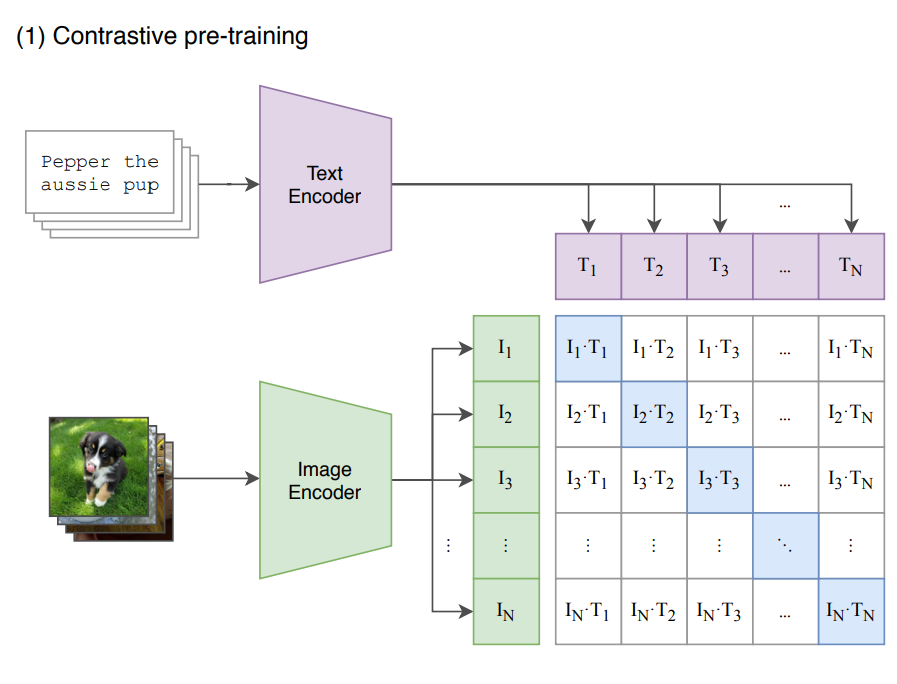

CLIP 之所以能同时理解图和文,是因为它有两个“大脑”,或者说两个独立的编码器(Encoder)。
-
左脑(Image Encoder):通常是一个 ResNet 或 Vision Transformer (ViT),负责“看图”,把图像变成一串数字(特征向量)。
-
右脑(Text Encoder):通常是一个 Transformer,负责“读字”,把文本也变成一串数字(特征向量)
假设我们在一个批次(Batch)中输入了 N 张图和 N 段文字(比如N=32)。
模型现在的任务是:在 32 \times 32 个可能的组合中,找到那 32 个正确的配对。
-
正样本(Positive):原本就是一对的图和文(比如“图1”和“文1”)。我们要拉近它们在特征空间中的距离(最大化相似度)。
-
负样本(Negative):原本不匹配的图和文(比如“图1”和“文3”)。我们要推远它们的距离(最小化相似度)。
通过这 4 亿次不断的“拉近匹配”和“推远不匹配”,CLIP 最终学会了将图像和文本映射到同一个“语义空间”中。
简化版的 PyTorch 代码:
import torch
import torch.nn as nn
class CLIPModel(nn.Module):
def __init__(self):
super().__init__()
# 1. 图像编码器 (Image Encoder)
# 负责将图片像素转换为特征向量
# 例如使用 ResNet50 或 ViT
self.image_encoder = MyVisionTransformer()
# 2. 文本编码器 (Text Encoder)
# 负责将文本文字转换为特征向量
# 例如使用 Transformer
self.text_encoder = MyTextTransformer()
# 3. 只有这两个可学习的"大脑",没有分类头(Head)!
# 这就是 CLIP 和传统分类模型的最大区别。
# 4. 一个可学习的温度系数 (用于缩放 logits)
self.logit_scale = nn.Parameter(torch.ones([]) * 2.6592)
def forward(self, image, text):
# 提取图像特征 (形状: [Batch_Size, Feature_Dim])
image_features = self.image_encoder(image)
# 提取文本特征 (形状: [Batch_Size, Feature_Dim])
text_features = self.text_encoder(text)
# 归一化特征 (很重要!保证特征在单位球面上)
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
return image_features, text_features第二部分:核心代码与数学原理 (The Code & Math)
复杂的数学公式,会导致大家云里雾里。 其实,CLIP 的“对比学习”机制在代码层面非常优雅且简洁。作为程序员的我们,代码才是我们理解算法的最好钥匙。 下面这段代码,就是 CLIP 计算图文相似度的核心逻辑,也是整个模型的灵魂所在。
1. 模型初始化:搭建“双塔”架构 (__init__)
CLIP 的构造函数 __init__ 非常灵活,它不仅支持 Vision Transformer (ViT),还保留了对经典 ResNet 的支持。
让我们拆解这段初始化代码的三个关键动作:
A. 视觉塔的选择 (The Visual Tower) 代码会检查 vision_layers 的类型,以此决定是用 CNN 还是 Transformer 来充当“眼睛”。
# 这里的逻辑很像是一个"开关"
if isinstance(vision_layers, (tuple, list)):
# 如果层数是列表(比如 (3, 4, 6, 3)),说明是用 ResNet
self.visual = ModifiedResNet(...)
else:
# 否则使用 Vision Transformer (ViT)
# 这也是目前最主流的用法,比如 ViT-B/32
self.visual = VisionTransformer(...)B. 文本塔的搭建 (The Text Tower) 文本部分是一个标准的 Transformer 编码器。但这里有一个细节需要注意:Mask 的构建。
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
# 这里的 Mask 很关键!
attn_mask=self.build_attention_mask()
)C. 两个关键的“胶水”参数 怎么把图像和文本这两个完全不同的世界联系起来?靠这两个参数:
# 1. 文本投影层 (Text Projection)
# 图像编码器的输出维度通常不等于文本编码器的输出维度
# 这个矩阵把文本特征投影到和图像特征一样的维度 (embed_dim)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
# 2. 温度系数 (Logit Scale)
# 初始化为 log(1/0.07) ≈ 2.65
# 这个参数在后续计算相似度时起到"锐化"概率分布的作用
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))2. 独特的文本编码机制 (encode_text)
在 encode_text 方法中,CLIP 藏了一个非常经典的**“EOT (End of Text)”**技巧,这是很多初学者容易漏掉的细节。
def encode_text(self, text):
# 1. 正常的 Transformer 流程:Embedding -> Positional -> Layer -> Norm
x = self.token_embedding(text).type(self.dtype)
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND (Transformer 需要的时间步优先格式)
x = self.transformer(x)
x = x.permute(1, 0, 2) # 变回 NLD
x = self.ln_final(x).type(self.dtype)
# 2. 重点来了!取哪个 Token 作为整句话的特征?
# CLIP 并没有像 BERT 那样取第一个 [CLS] token
# 而是取了句子结束符 [EOT] 对应的特征
# text.argmax(dim=-1) 会找到每一句话中最大索引的位置(即 EOT 的位置)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)]
# 3. 最后映射到联合空间
x = x @ self.text_projection
return x 为什么是 argmax?因为在 CLIP 的词表中,结束符(End of Text)的 ID 是最大的。通过找到这个最大 ID 的位置,我们就能精确地把这句话“读完”那一刻的脑回路(特征向量)提取出来,代表整句话的含义。
3. 图像编码机制 (encode_image)
这一步相对简单直观,直接调用初始化好的视觉骨干网络。
def encode_image(self, image):
return self.visual(image.type(self.dtype))4. 前向传播:从像素到相似度 (forward)
万事俱备,终于到了最激动人心的 forward 环节。这里就是我们将图片和文本变成向量,然后计算它们“默契程度”的地方。
让我们看看这段仅有寥寥数行的代码,是如何完成这惊人的一跃的:
def forward(self, image, text):
# ---------------------------------------------------
# 第一步:特征编码 (Encoding)
# ---------------------------------------------------
# 调用之前定义的 encode_image 和 encode_text
# 图片变成向量: [Batch_Size, Embed_Dim] (例如 32 x 512)
image_features = self.encode_image(image)
# 文本变成向量: [Batch_Size, Embed_Dim] (例如 32 x 512)
text_features = self.encode_text(text)
# ---------------------------------------------------
# 第二步:特征归一化 (L2 Normalization)
# ---------------------------------------------------
# 这一步至关重要!将向量长度统一为 1
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# ---------------------------------------------------
# 第三步:计算余弦相似度矩阵 (Cosine Similarity)
# ---------------------------------------------------
# 取出可学习的温度系数,并取指数保证其为正
logit_scale = self.logit_scale.exp()
# 矩阵乘法:计算所有图和所有文的两两相似度
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text这里有三个核心细节,是理解 CLIP 训练机制的“钥匙”:
A. 归一化的奥秘:从点积到余弦
代码中执行了 x / x.norm()。
-
数学原理:向量 A和 B的点积公式是
。
-
物理意义:当我们把向量长度
和
都强行缩放为 1 后,点积的结果就直接等于夹角的余弦值
。
-
为什么这么做? 我们只关心向量的方向(代表语义),不关心向量的长度(代表信号强度)。这样计算出的相似度严格限制在
之间,极大地稳定了训练过程。
B. 温度系数 (Temperature):模型的“自信程度”
logit_scale = self.logit_scale.exp()-
CLIP 设置了一个可学习的参数
logit_scale(初始化约为 2.65)。 -
作用:原始的余弦相似度数值通常很小(比如在 0.2 到 0.3 之间)。如果不乘这个系数,Softmax 输出的概率分布会非常平缓(Flat)。
-
乘以这个系数(通常会学到 100 左右)可以拉大数值差距,让模型对“正确答案”更加确信(Sharpness),加速收敛。
C. 矩阵乘法的几何视图 (The Matrix Magic)
这是全段代码的灵魂:
logits_per_image = logit_scale * image_features @ text_features.t()这里发生了一个形状变换:。
结果是一个 的方阵,我们用一张图来形象化它:
-
对角线 (Diagonal):代表 第
张图 和 第
-
非对角线 (Off-Diagonal):代表张冠李戴(比如“图:狗”配上了“文本:车”)。这是错误的配对(负样本)。我们希望非对角线上的数值越小越好。
D. 为什么要返回两个 Logits?
-
最后返回了
logits_per_image和logits_per_text。 这体现了 CLIP 的对称性损失 (Symmetric Loss) 设计: -
图找文 (
logits_per_image):给定一张图,在 Batch 里找最匹配的那句话。 -
文找图 (
logits_per_text):给定一句话,在 Batch 里找最匹配的那张图。
总结:看到这里,你会发现 CLIP 的核心并不复杂。 它没有复杂的检测框(Bounding Box),也没有繁琐的图文对齐规则。它只是简单粗暴地把图和文都压成向量,然后用最基础的矩阵乘法来计算它们的距离。 大道至简,这就是 CLIP 能够在大规模数据上展现惊人能力的秘密。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)