京东大模型一面:“为什么 Prompt Engineering 可以提升效果?”
don't read, 老外经常在文章模型总结时候的缩略词),就在文本总结的任务上取得了还不错的效果。• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。上图是 GPT 3 关于 ICL 的介绍,该图展示了 In-context Lear
问题
为什么 Prompt Engineering 可以提升效果?
答案
Prompt Engineering 之所以能提升效果,一般是认为大模型具有 In-context Learning 的能力。也就是说,Prompt Engineering 是基于大模型 In-context Learning 的能力,寻找解决问题的最优 prompt 的过程。
In-context Learning 这个词最早出现在 GPT-3 中,但实际上,这项技术在 GPT-2 中就开始探索了,只不过还取这么高大上的名字。
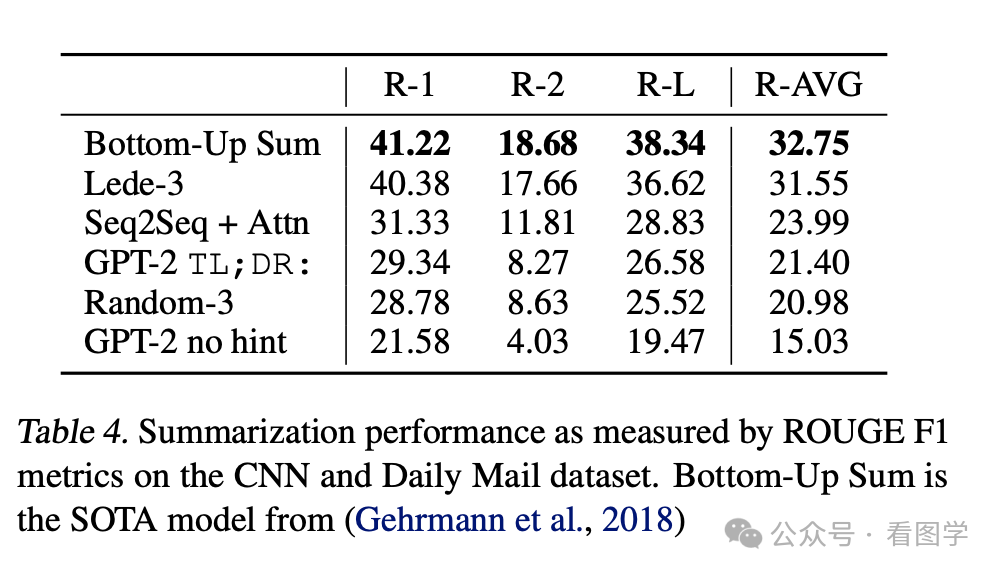
比如 GPT-2 中写道:“We demonstrate language models can perform down-stream tasks in a zero-shot setting – without any parameter or architecture modification. We demonstrate this approach shows potential by highlighting the ability of language models to perform a wide range of tasks in a zero-shot setting.” 这也是为什么 GPT2 为什么论文的名字叫: Language Models are Unsupervised Multitask Learners。
还有 “To induce summarization behavior we add the text TL;DR: after the article and generate 100 tokens”。就仅仅在文本后面加上 TL;DR: (意思是 too long; don't read, 老外经常在文章模型总结时候的缩略词),就在文本总结的任务上取得了还不错的效果。
“We test whether GPT-2 has begun to learn how to translate from one language to another. In order to help it infer that this is the desired task, we condition the language model on a context of example pairs of the format english sentence = french sentence and then after a final prompt of english sentence = we sample from the model with greedy decoding and use the first generated sentence as the translation"
也就是给定给一些英语和法语的平行语料,中间用 = 连起来,翻译某段英语文本的时候,只需要在文本后面加上 = 让模型生成就可以将英语翻译成法语。这其实就是 GPT-3 中的 few-shot learning。
所以 GPT-2 这么小的模型,就已经存在 In-context Learning 的能力了, GPT-3 只不过是该能力变得更强大了。
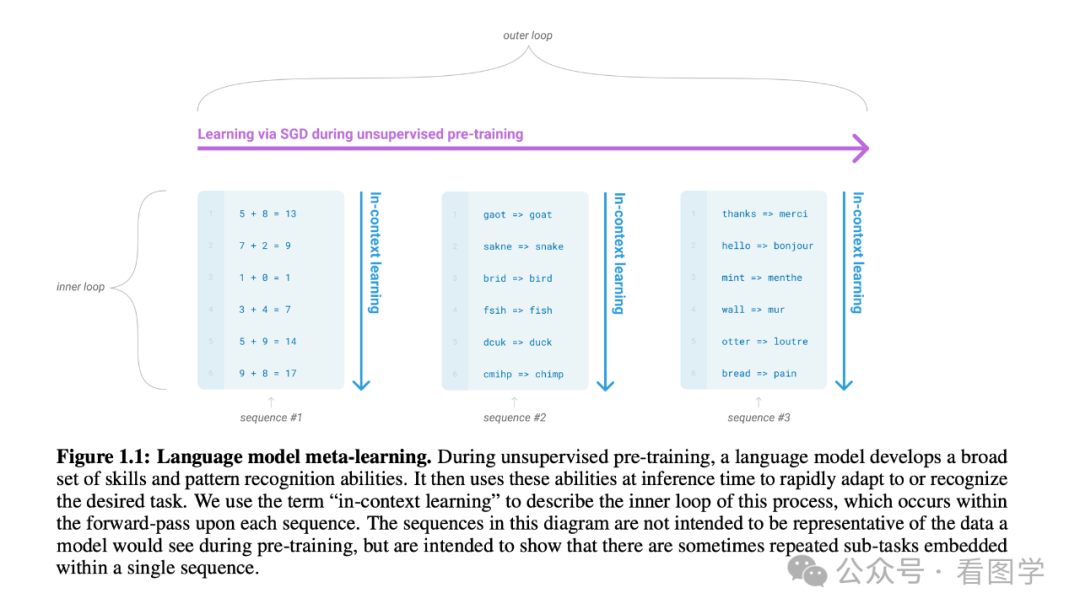
上图是 GPT 3 关于 ICL 的介绍,该图展示了 In-context Learning 通过给出一些输入和输出的例子,结果模型就理解了这个任务,并且很大概率会输出该任务的正确答案。
这个现象让人们感到非常兴奋,因为很多测试的案例根本就没有出现在训练的样本中,大模型通过输入这些任务示例的 prompt "学习" 到了一种解决问题的思路。
即使没有示例,我们也可以认为大模型处理 prompt 的过程也可以认为是一种学习,因为输入的 prompt 越长,大模型就预测新的 token 就越准确。大模型很明显是从 prompt 中学习到了一些上下文信息。
那么 In-context Learning 的工作原理到底是怎样的呢?目前其实也不是很确定,但是有一些解释。
贝叶斯推断
在论文《An Explanation of In-context Learning as Implicit Bayesian Inference》 中,将认为大模型的 In-context learning 其实是贝叶斯推断,其工作原理如下:

大模型在预训练的过程中学到了一些潜在的概念,比如 wikipedia 的个人介绍。
而当 prompt 中提到这些学习到的概念时,就触发了贝叶斯推断,这个过程可以建模为:
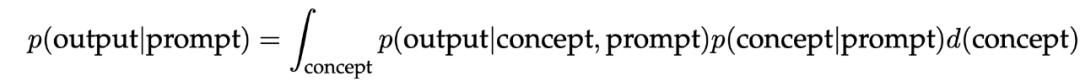
归纳头 induction heads
Anthropic 的工作人员对一个迷你的 transformers 进行了研究,建模了一个数学框架来解释 transformer 是如何工作的。其中一个发现就是 Transformer 存在归纳头(induction heads)。简单来说,induction heads 就是复读机,如果 transformer 在处理的序列中存在 AB…A 这样的 pattern,那就会把 B 输出来。
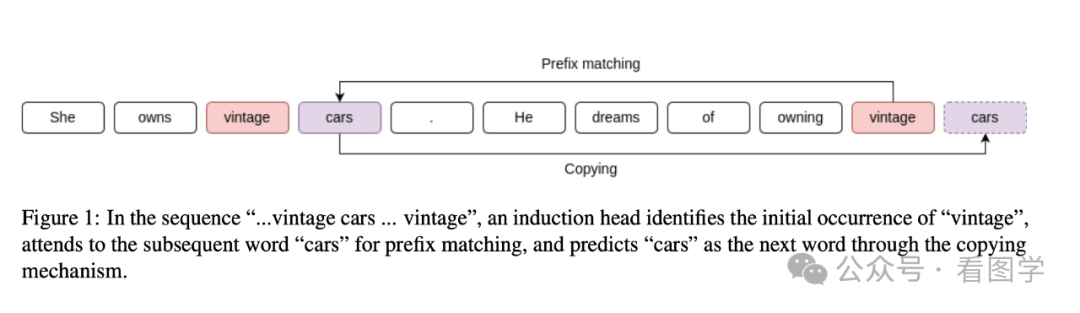
上图来自论文《Induction Heads as an Essential Mechanism for Pattern Matching in In-context Learning》,该论文表示 attention 会发现后面的 vintage 和前面的 vintage cars 匹配上了,就提高了 cars 的生成概率。而且通过一些消融实验证明了,当人工干预归纳头的 attention 计算方式时,In-context Learning 的能力确实下降了。
在论文 《In-context Learning and Induction Heads》中则认为归纳头的工作机制为: [A*][B*] … [A] → [B] , where A* ≈ A and B* ≈ B are similar in some space。 也就是归纳头在复读的时候并不需要严格的匹配,只需要相似即可。这样就很好的解释了 few-shot 的工作原理。
这个解释还是蛮有意思的。都是人生的本质是复读机,结果 AI 也是一样的。
函数向量头 (function vector head)
在论文 《In-Context Learning Creates Task Vectors》 则认为 In-Context Learning 实际上是根据 示例 S 创建了一个任务函数向量,这个任务函数向量指导了大模型将任务作用于 x ,然后输出。建模如下所示
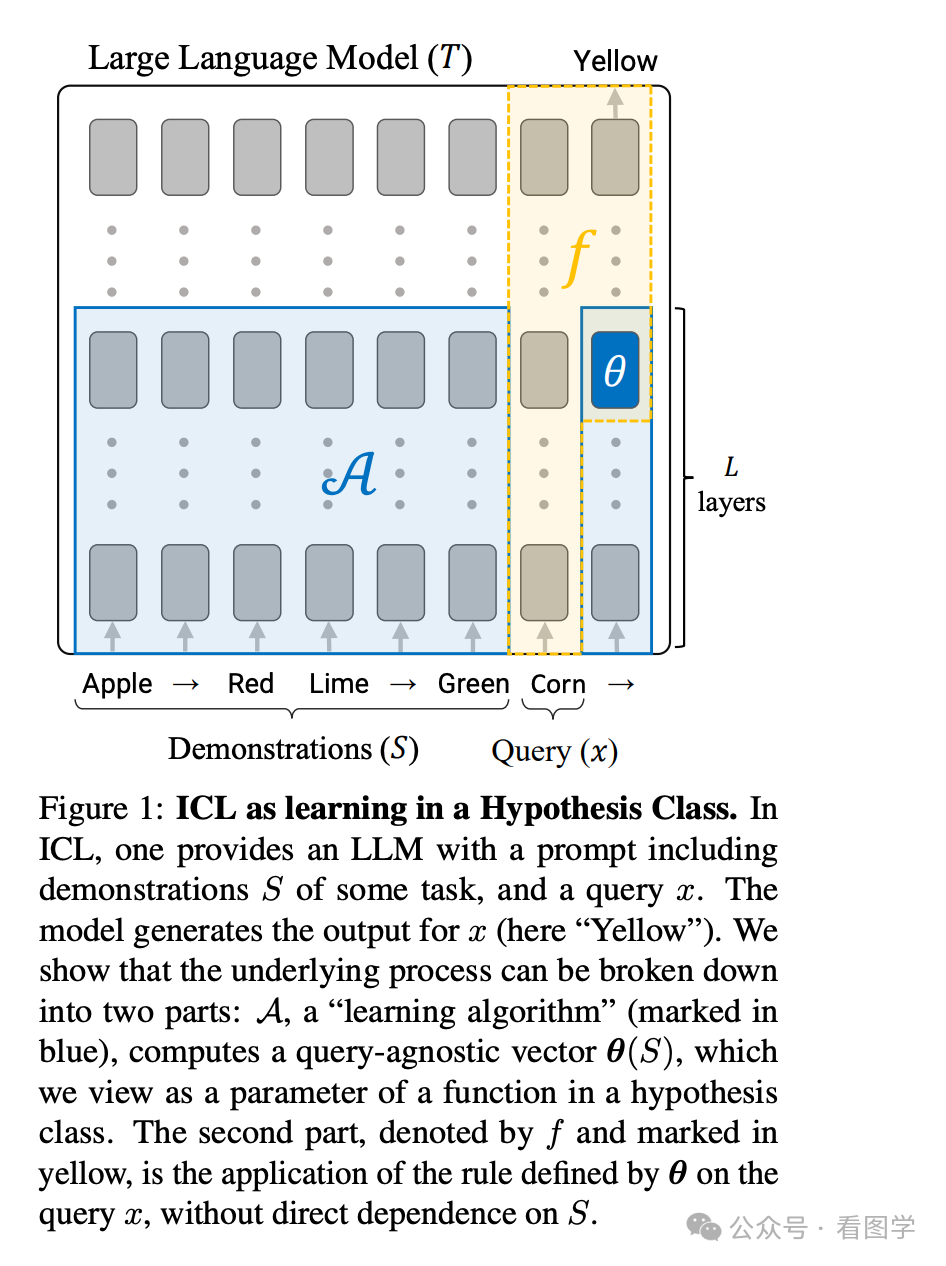
上图把推理过程分成两部分:
-
Learning Algorithm:
-
Rule Application: 输出为
在论文 《Which Attention Heads Matter for In-Context Learning?》 中,进一步讨论了函数向量头和归纳头,并且通过实验证明:
-
In-Context Learning 的性能主要依赖于函数向量头
-
许多向量头在训练初期表现为归纳头,随后逐渐转变为向量头。
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以在文末CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享

AI产品经理,0基础小白入门指南
作为一个零基础小白,如何做到真正的入局AI产品?
什么才叫真正的入局?
是否懂 AI、是否懂产品经理,是否具备利用大模型去开发应用能力,是否能够对大模型进行调优,将会是决定自己职业前景的重要参数。
你是否遇到这些问题:
1、传统产品经理
不懂Al无法对AI产品做出判断,和技术沟通丧失话语权
不了解 AI产品经理的工作流程、重点
2、互联网业务负责人/运营
对AI焦虑,又不知道怎么落地到业务中想做定制化AI产品并落地创收缺乏实战指导
3、大学生/小白
就业难,不懂技术不知如何从事AI产品经理想要进入AI赛道,缺乏职业发展规划,感觉遥不可及
为了帮助开发者打破壁垒,快速了解AI产品经理核心技术原理,学习相关AI产品经理,及大模型技术。从原理出发真正入局AI产品经理。
这里整理了一些AI产品经理学习资料包给大家
📖AI产品经理经典面试八股文
📖大模型RAG经验面试题
📖大模型LLMS面试宝典
📖大模型典型示范应用案例集99个
📖AI产品经理入门书籍
📖生成式AI商业落地白皮书
🔥作为AI产品经理,不仅要懂行业发展方向,也要懂AI技术,可以帮助大家:
✅深入了解大语言模型商业应用,快速掌握AI产品技能
✅掌握AI算法原理与未来趋势,提升多模态AI领域工作能力
✅实战案例与技巧分享,避免产品开发弯路
这份《AI产品经理学习资料包》已经上传CSDN,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
资料包: CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
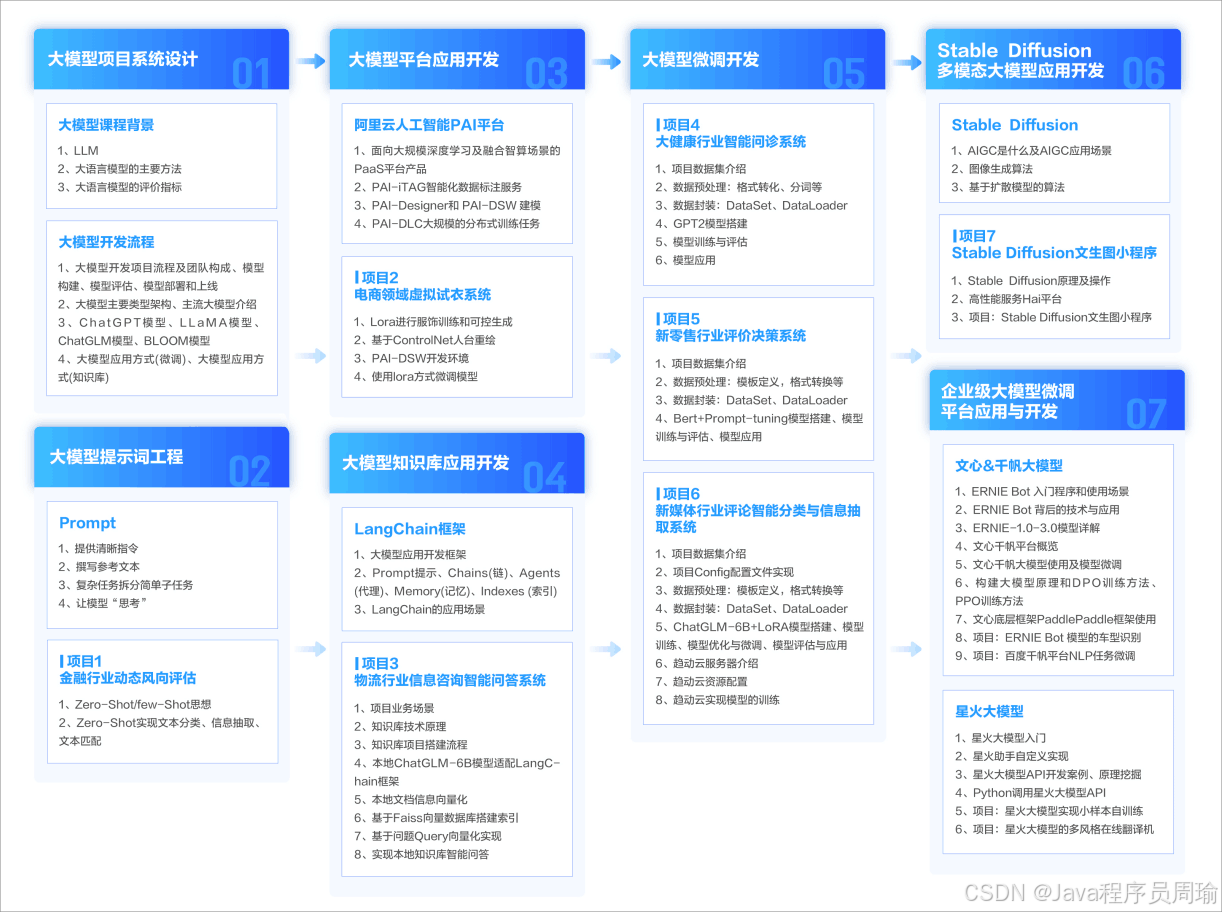
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以CSDN大礼包:《对标阿里黑客&网络安全入门&进阶学习资源包》免费分享免费领取【保证100%免费】🆓

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)