CV计算机视觉每日开源代码Paper with code速览-2023.10.17
精华置顶
墙裂推荐!小白如何1个月系统学习CV核心知识:链接
点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
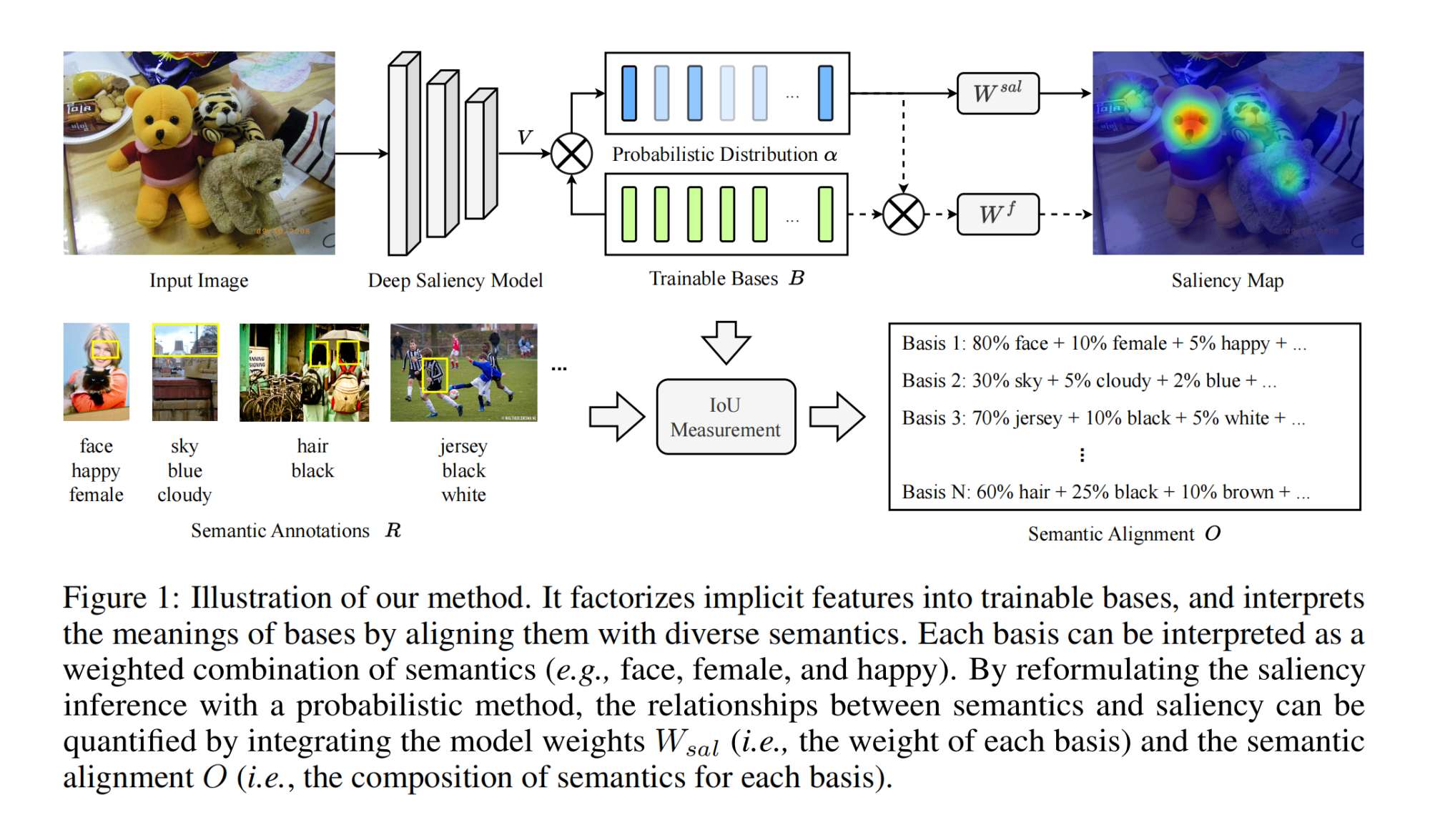
1.【基础网络架构】What Do Deep Saliency Models Learn about Visual Attention?
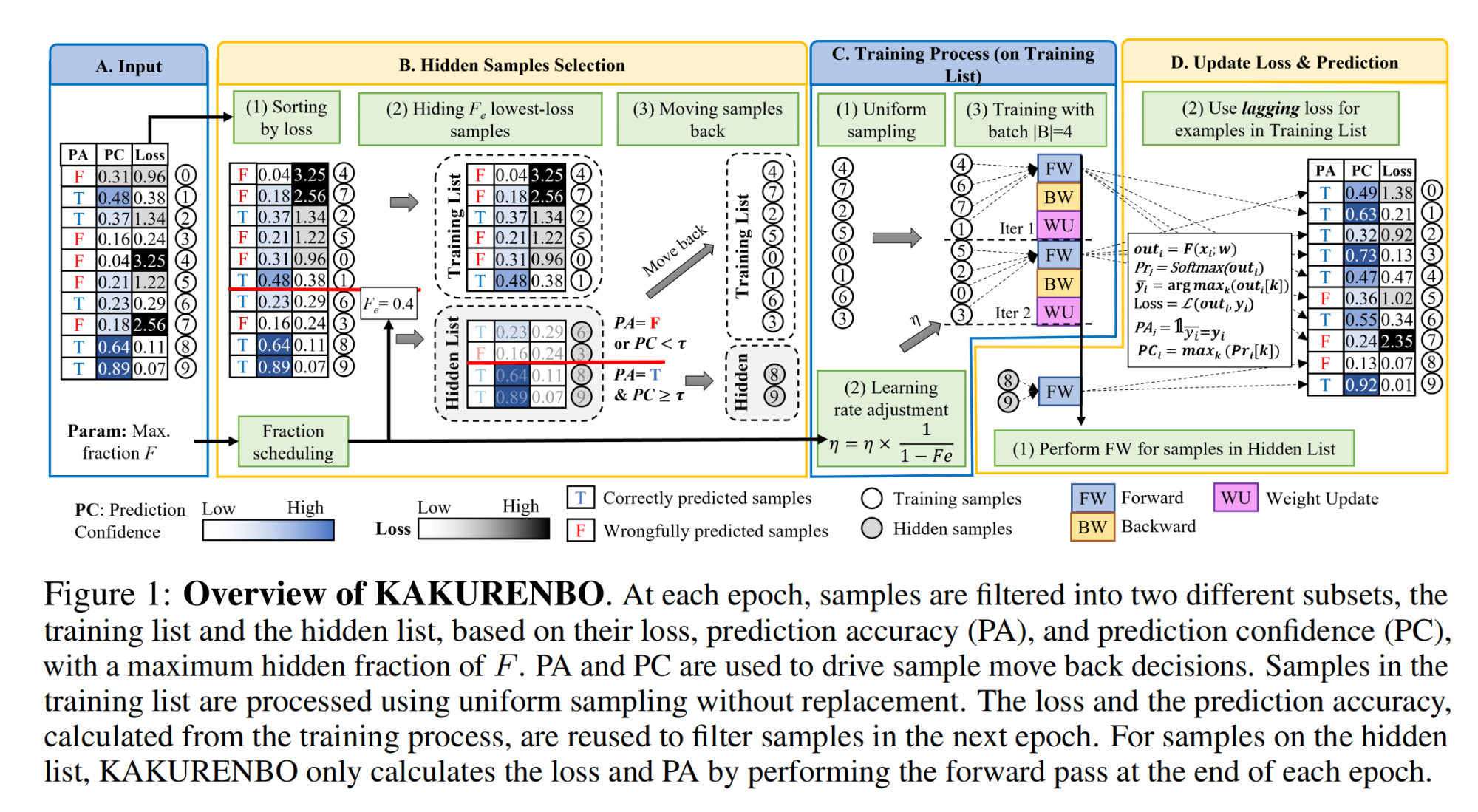
2.【基础网络架构】KAKURENBO: Adaptively Hiding Samples in Deep Neural Network Training
-
开源代码(即将开源):GitHub - TruongThaoNguyen/kakurenbo
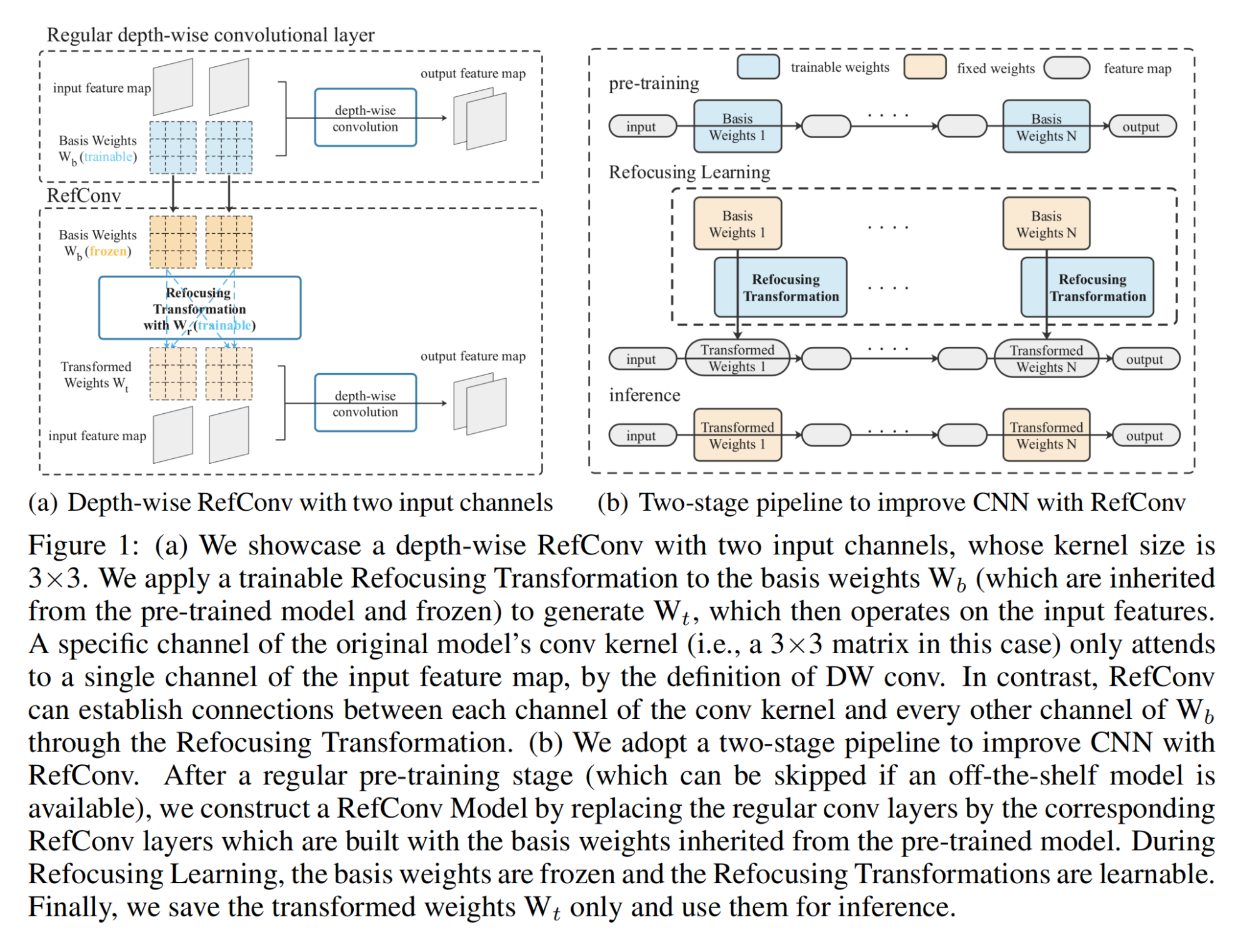
3.【基础网络架构:CNN】RefConv: Re-parameterized Refocusing Convolution for Powerful ConvNets
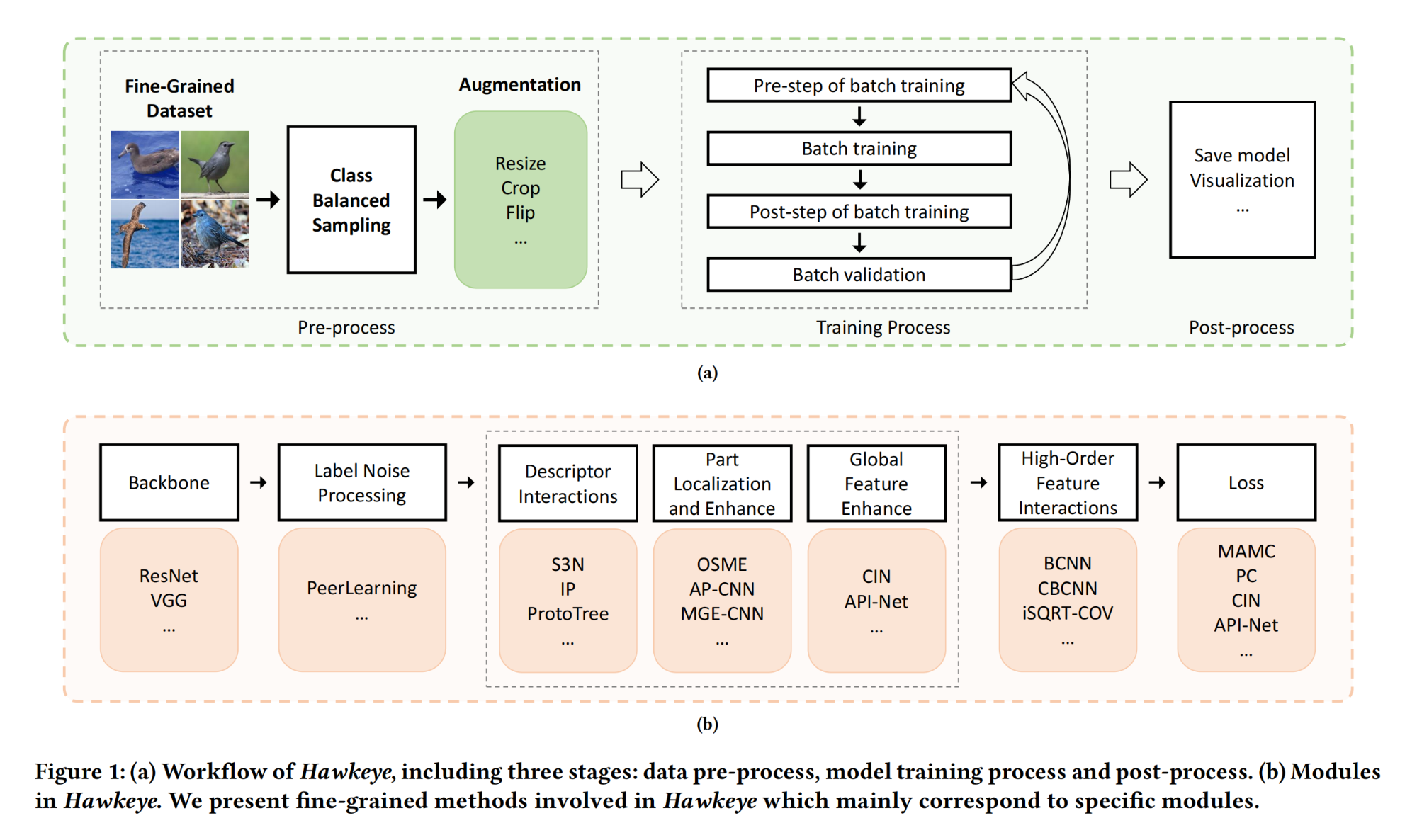
4.【图像分类】Hawkeye: A PyTorch-based Library for Fine-Grained Image Recognition with Deep Learning
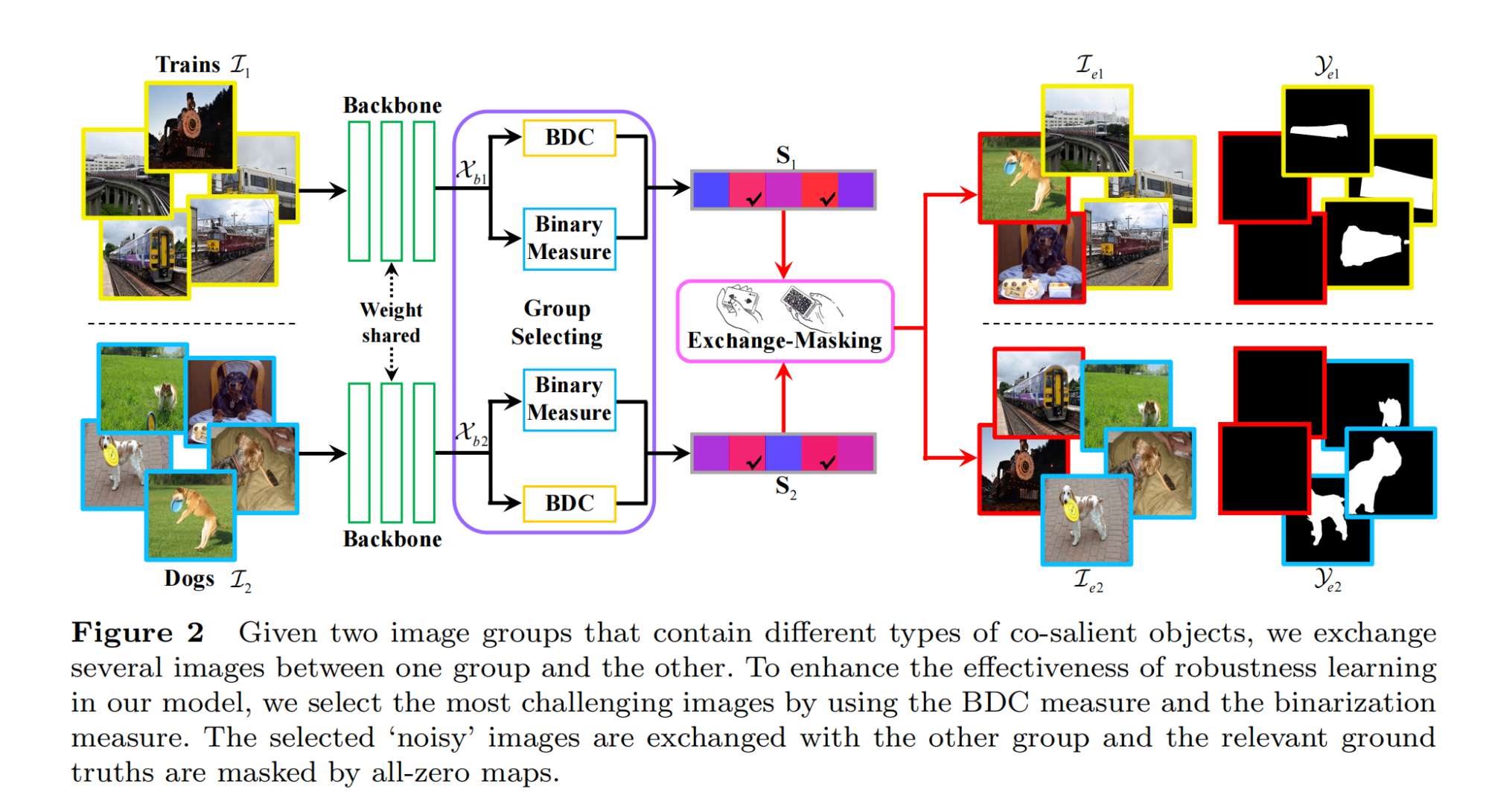
5.【显著目标检测】Towards Open-World Co-Salient Object Detection with Generative Uncertainty-aware Group Selective Exchange-Masking
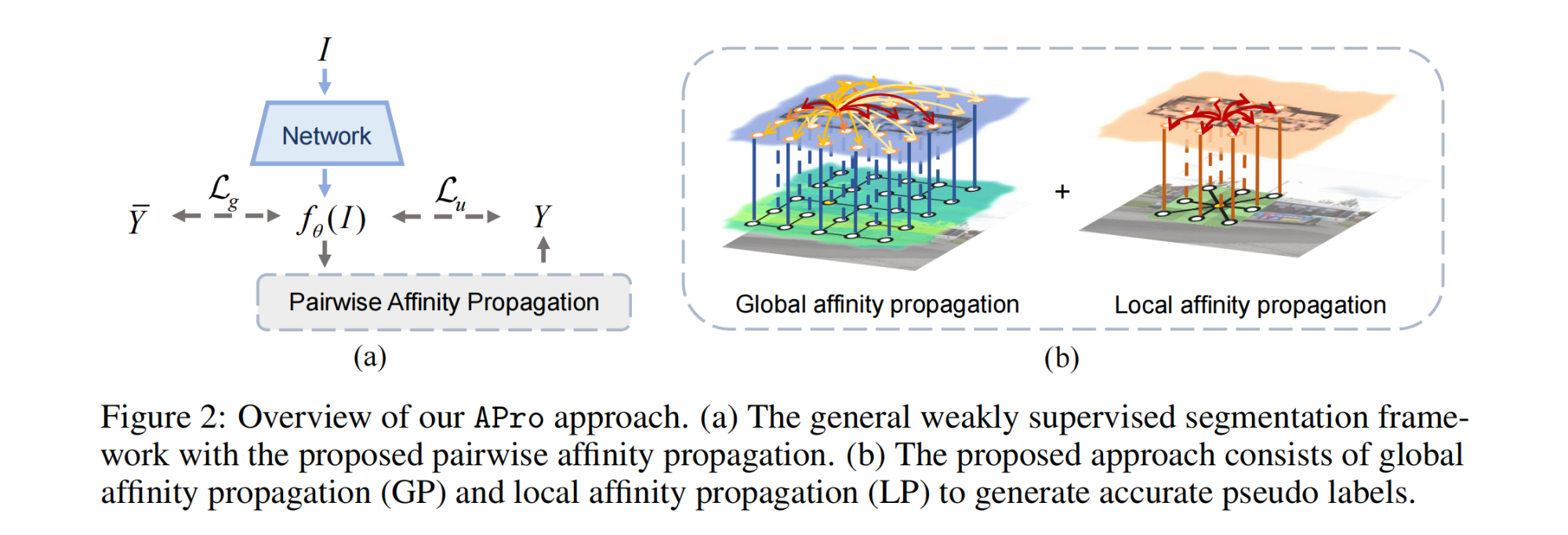
6.【图像分割】Label-efficient Segmentation via Affinity Propagation
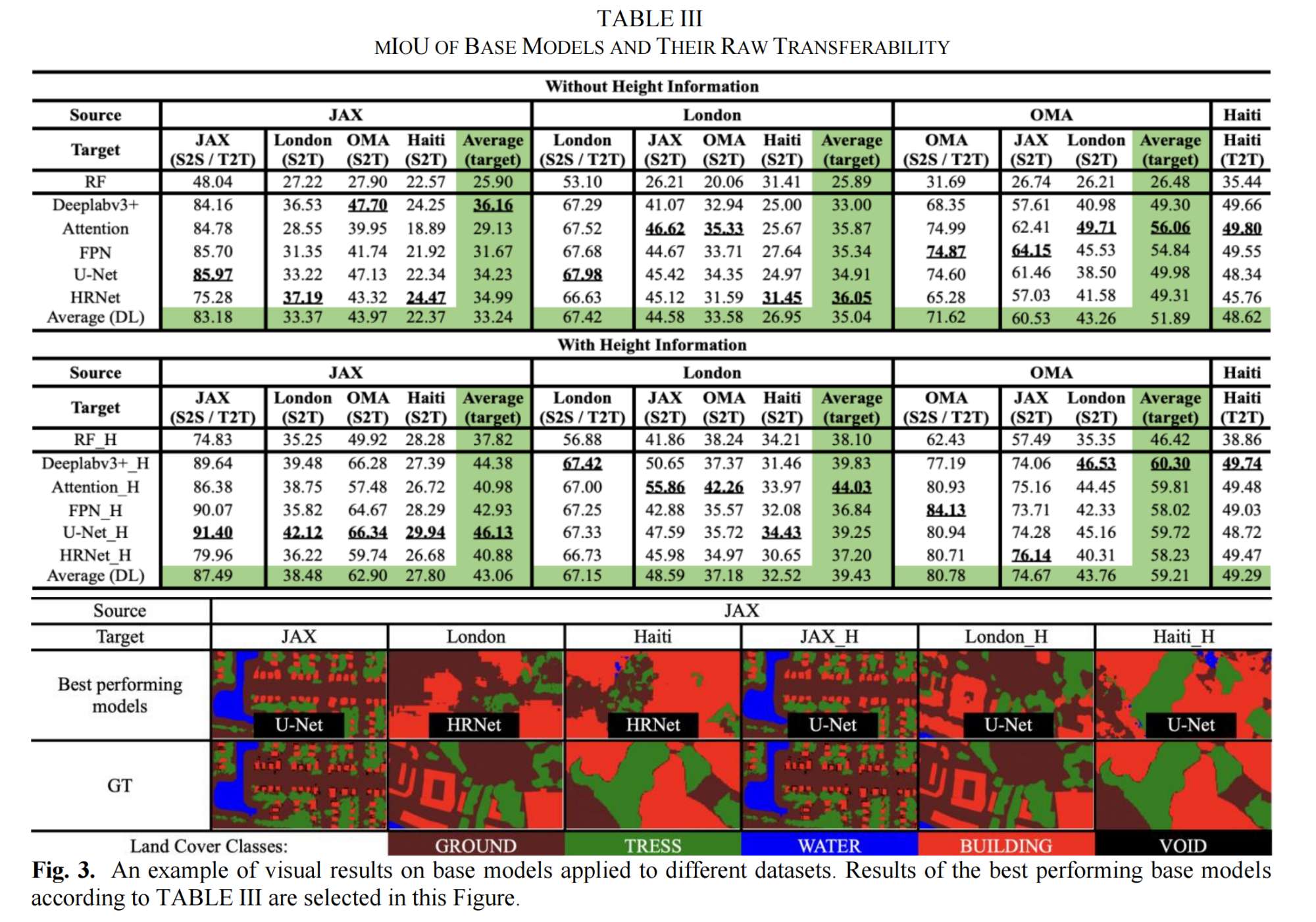
7.【图像分割】On the Transferability of Learning Models for Semantic Segmentation for Remote Sensing Data
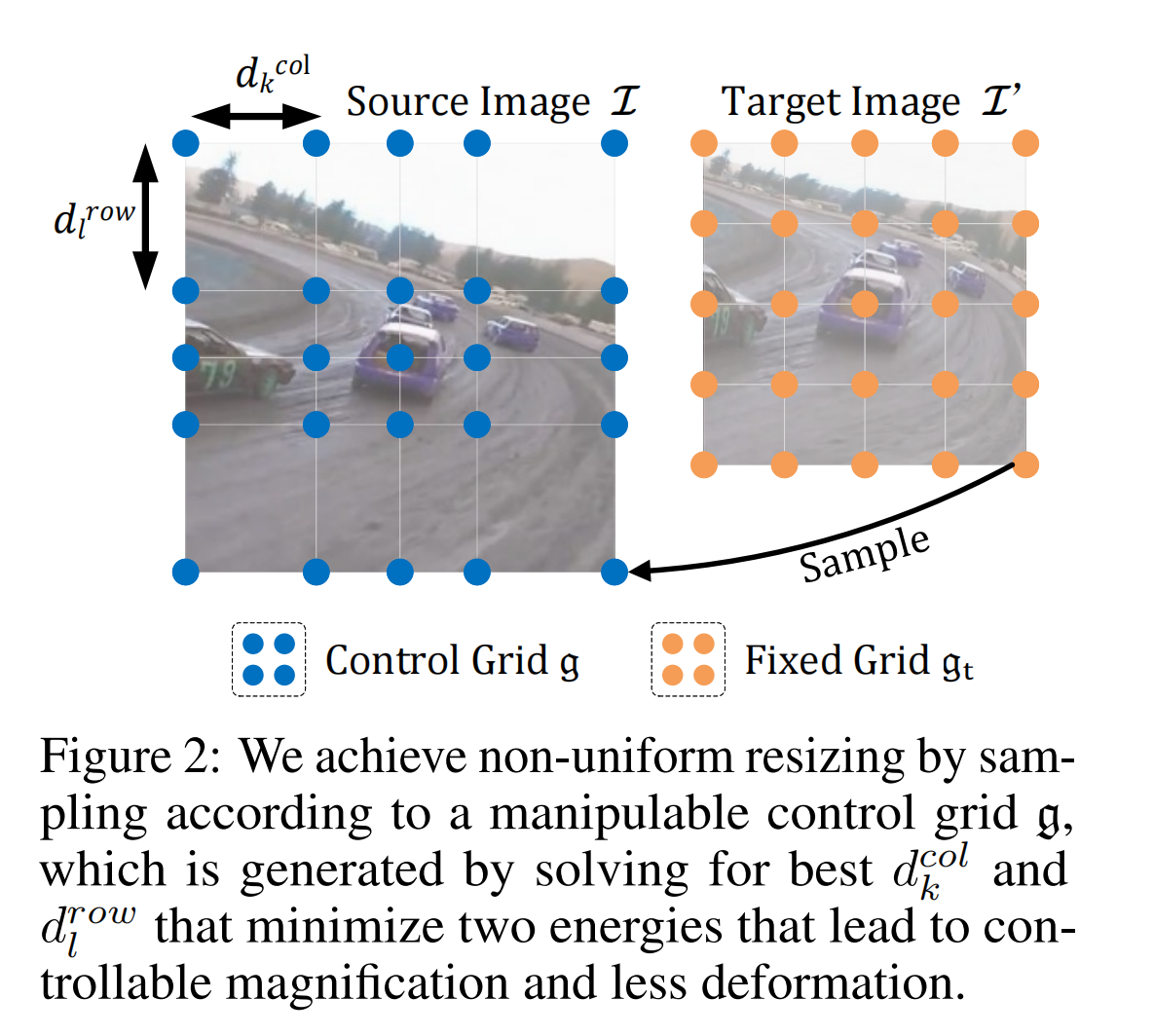
8.【目标跟踪】ZoomTrack: Target-aware Non-uniform Resizing for Efficient Visual Tracking
9.【人脸识别】New Benchmarks for Asian Facial Recognition Tasks: Face Classification with Large Foundation Models

10.【人脸识别】Learning Unified Representations for Multi-Resolution Face Recognition
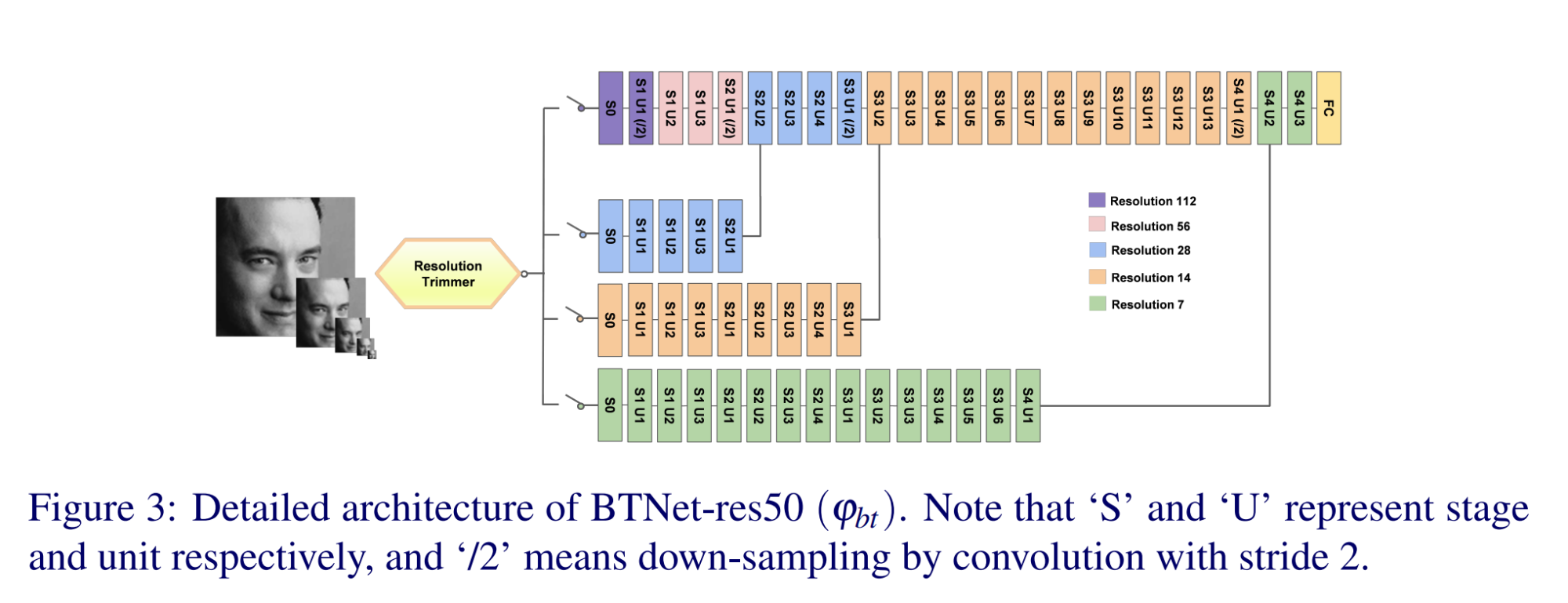
11.【OCR】EfficientOCR: An Extensible, Open-Source Package for Efficiently Digitizing World Knowledge
-
工程主页:Efficient OCR
-
开源代码(即将开源):https://github.com/dell-research-harvard/efficient_ocr

12.【点云】JM3D & JM3D-LLM: Elevating 3D Representation with Joint Multi-modal Cues
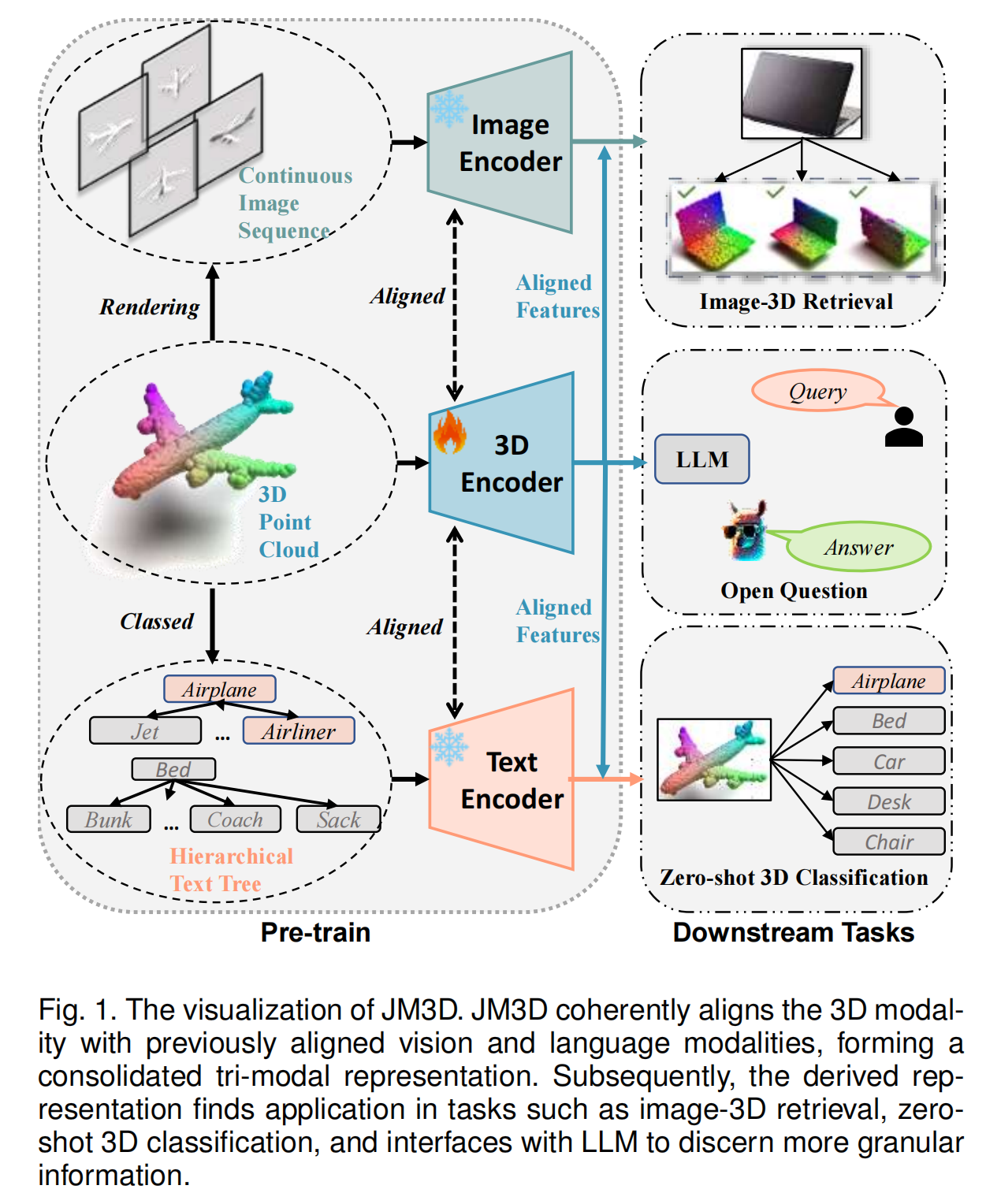
13.【医学图像处理】Generalizing Medical Image Representations via Quaternion Wavelet Networks
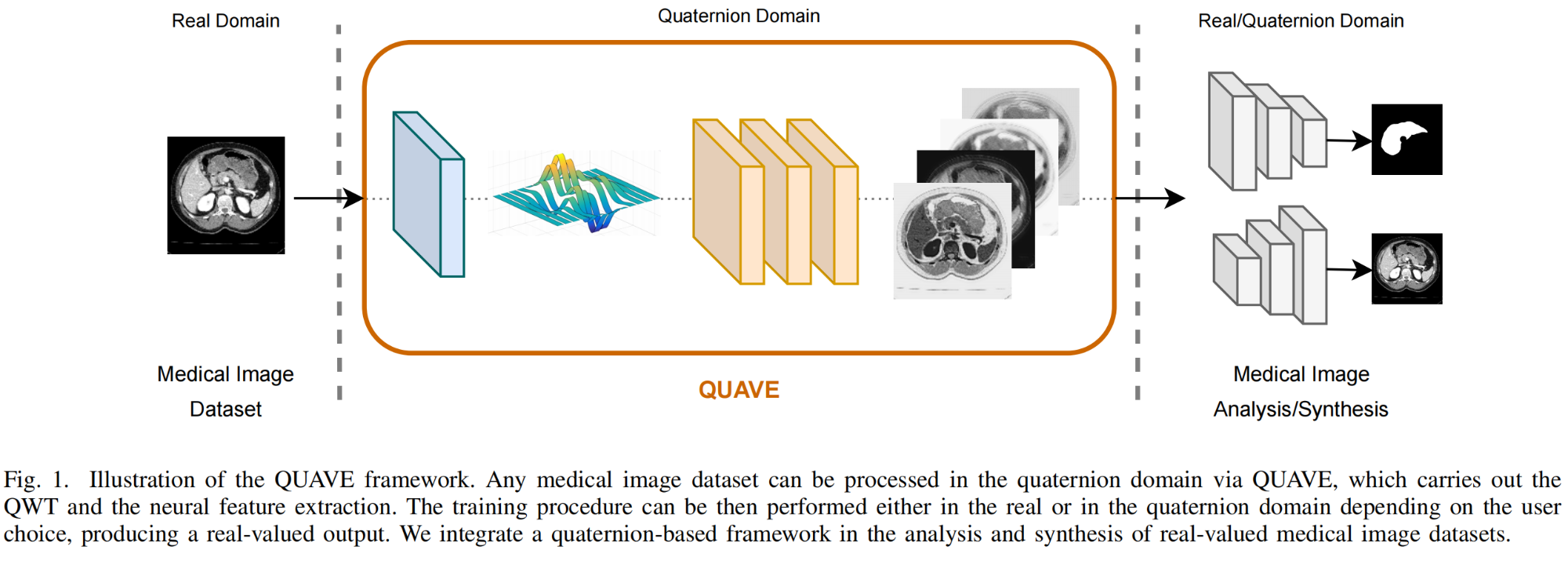
14.【超分辨率重建】Image super-resolution via dynamic network
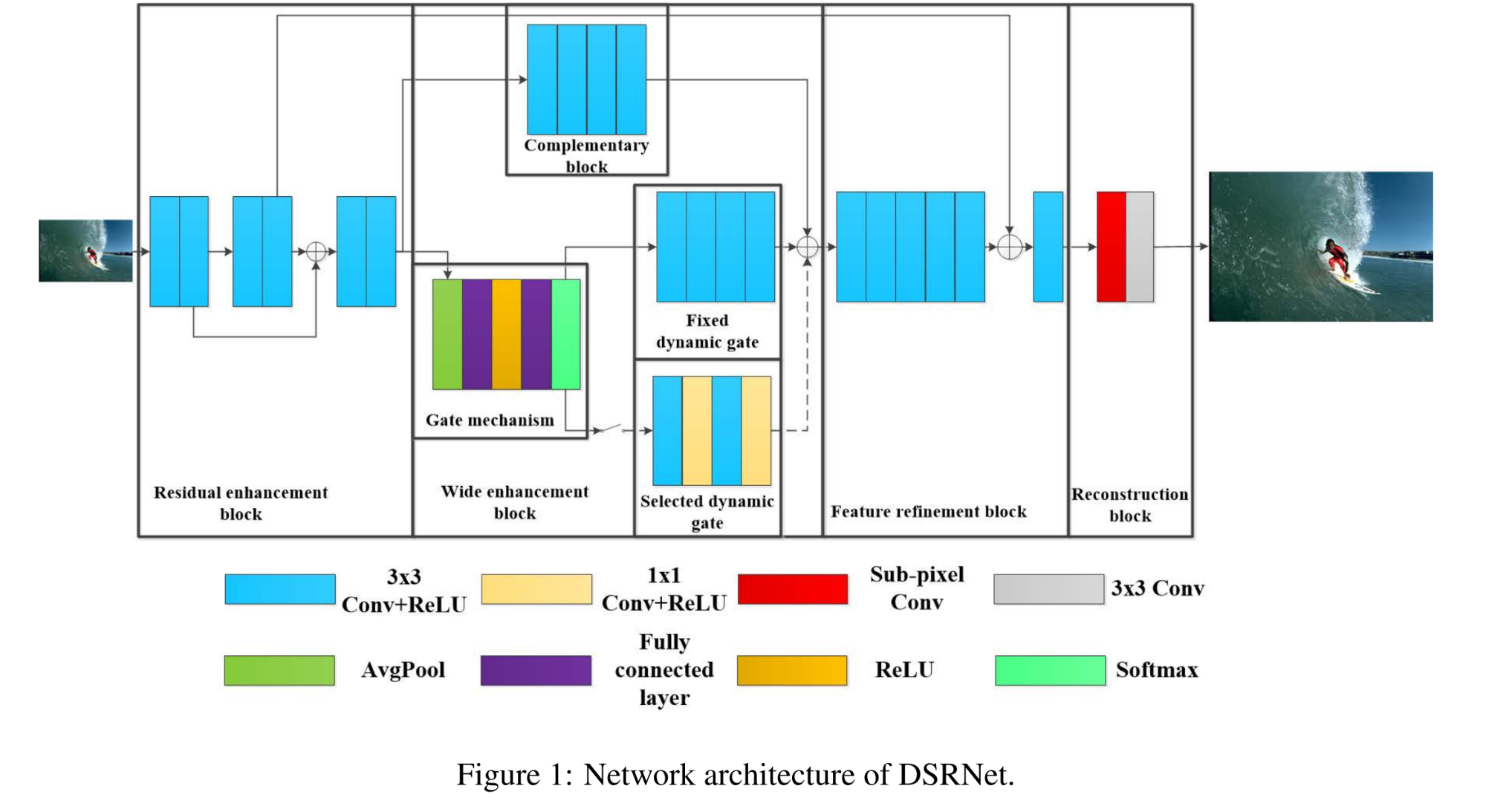
15.【图像增强】Dimma: Semi-supervised Low Light Image Enhancement with Adaptive Dimming
-
开源代码:GitHub - WojciechKoz/Dimma: Dimma: Semi-supervised Low Light Image Enhancement with Adaptive Dimming

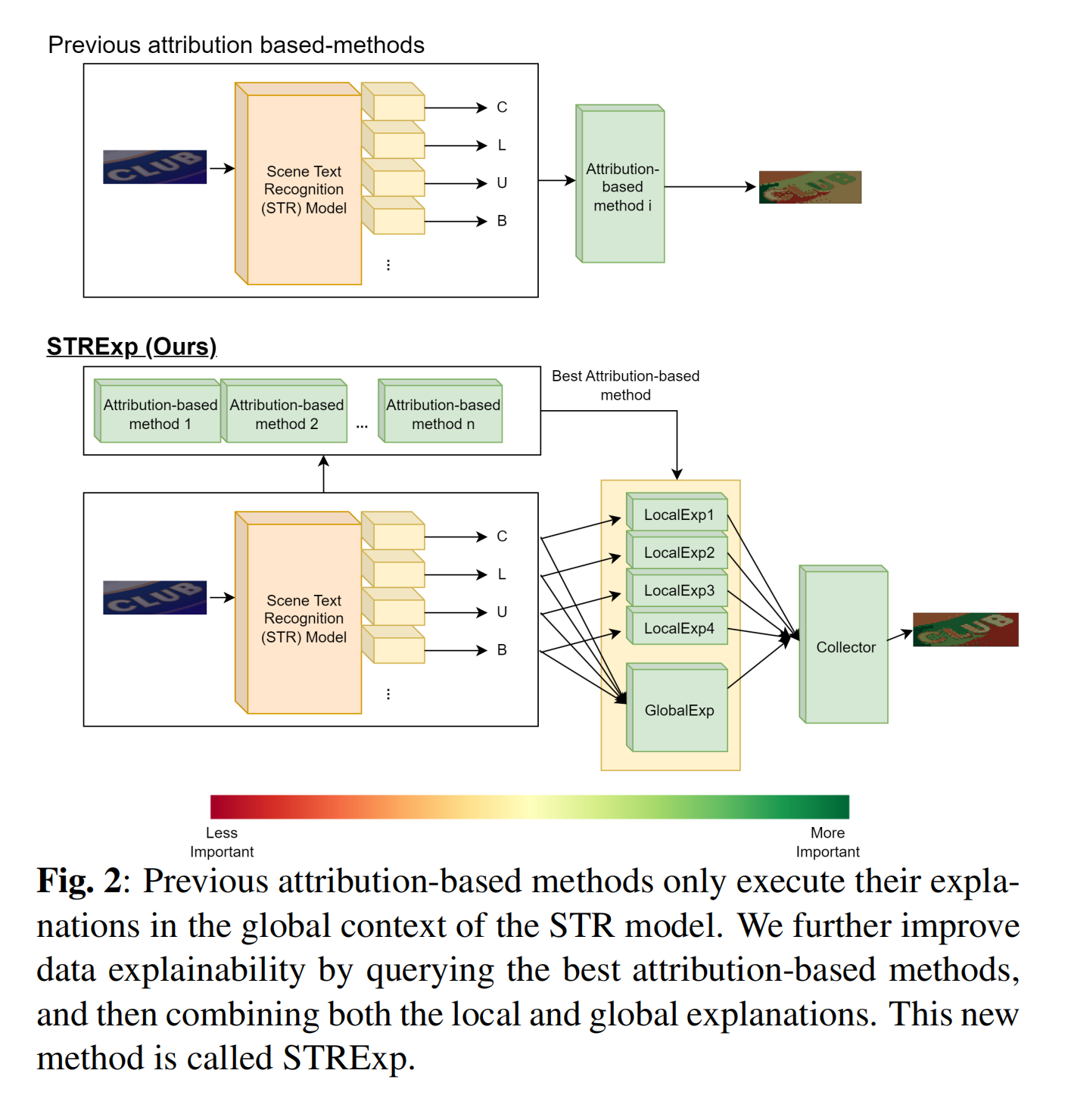
16.【场景文本识别】Scene Text Recognition Models Explainability Using Local Features
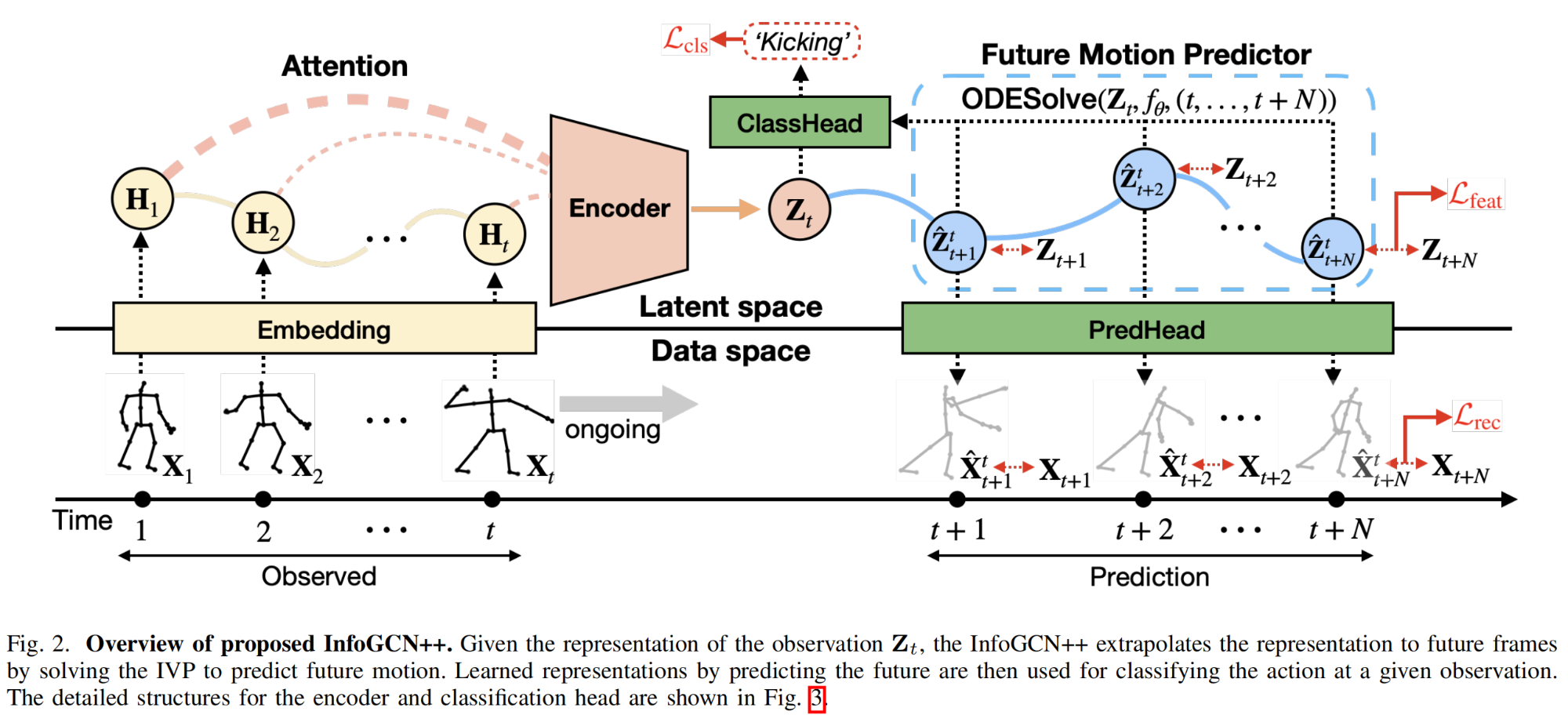
17.【动作识别】InfoGCN++: Learning Representation by Predicting the Future for Online Human Skeleton-based Action Recognition
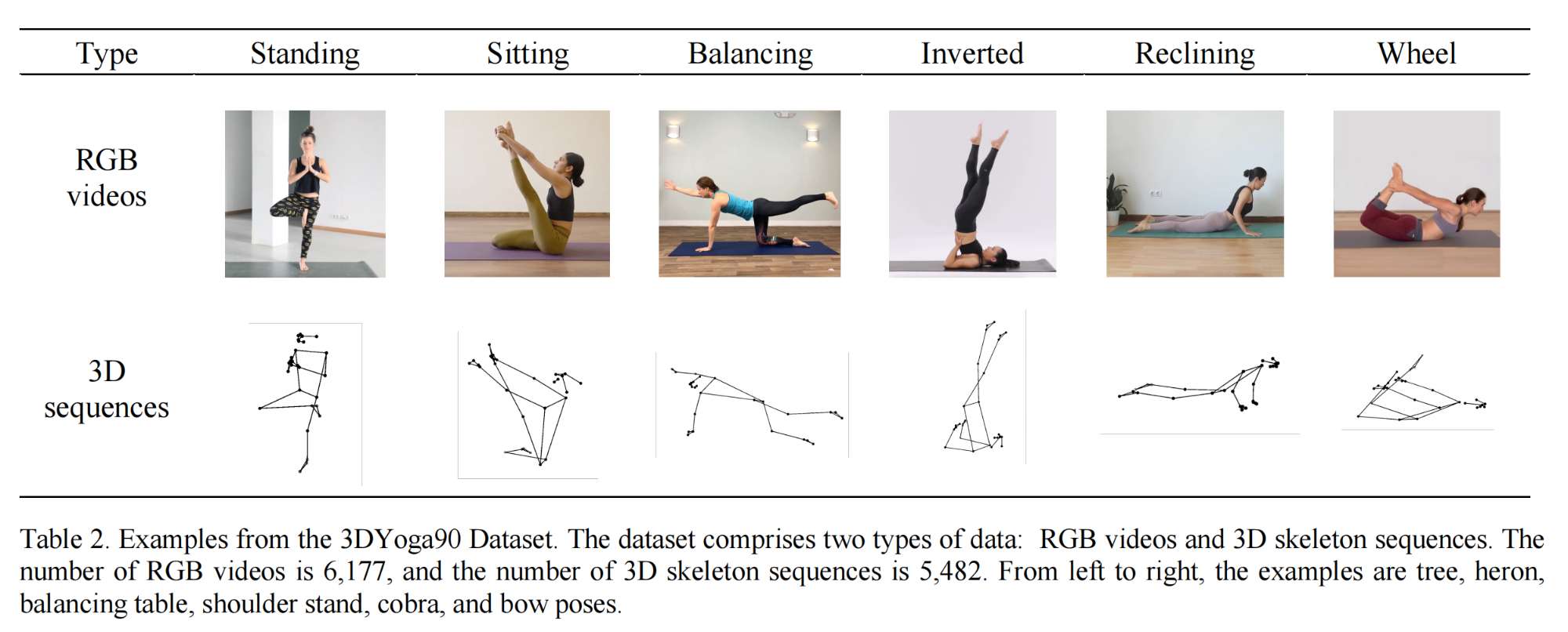
18.【动作识别】3DYoga90: A Hierarchical Video Dataset for Yoga Pose Understanding
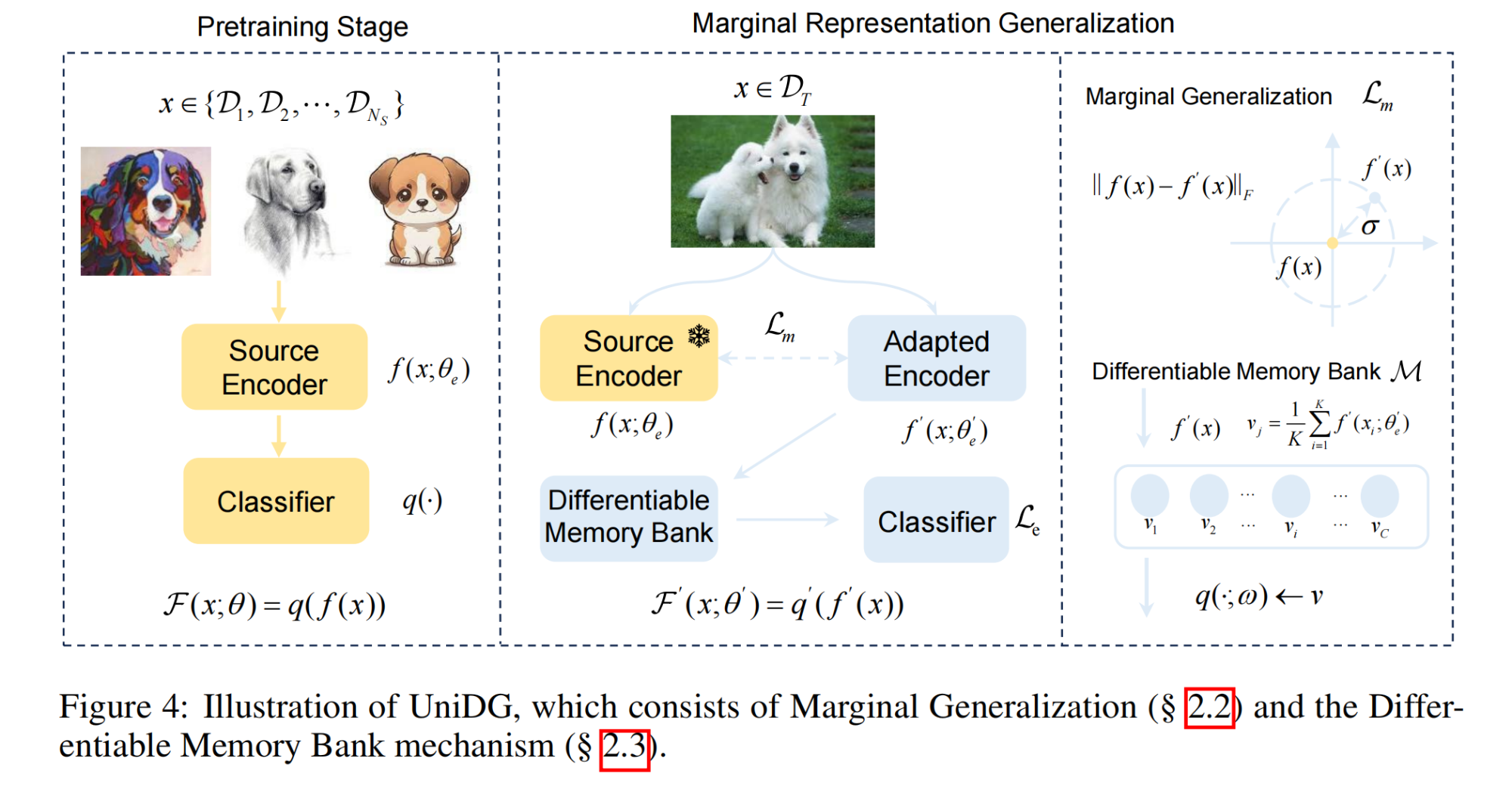
19.【领域泛化】Towards Unified and Effective Domain Generalization
20.【多模态】Interpreting and Controlling Vision Foundation Models via Text Explanations
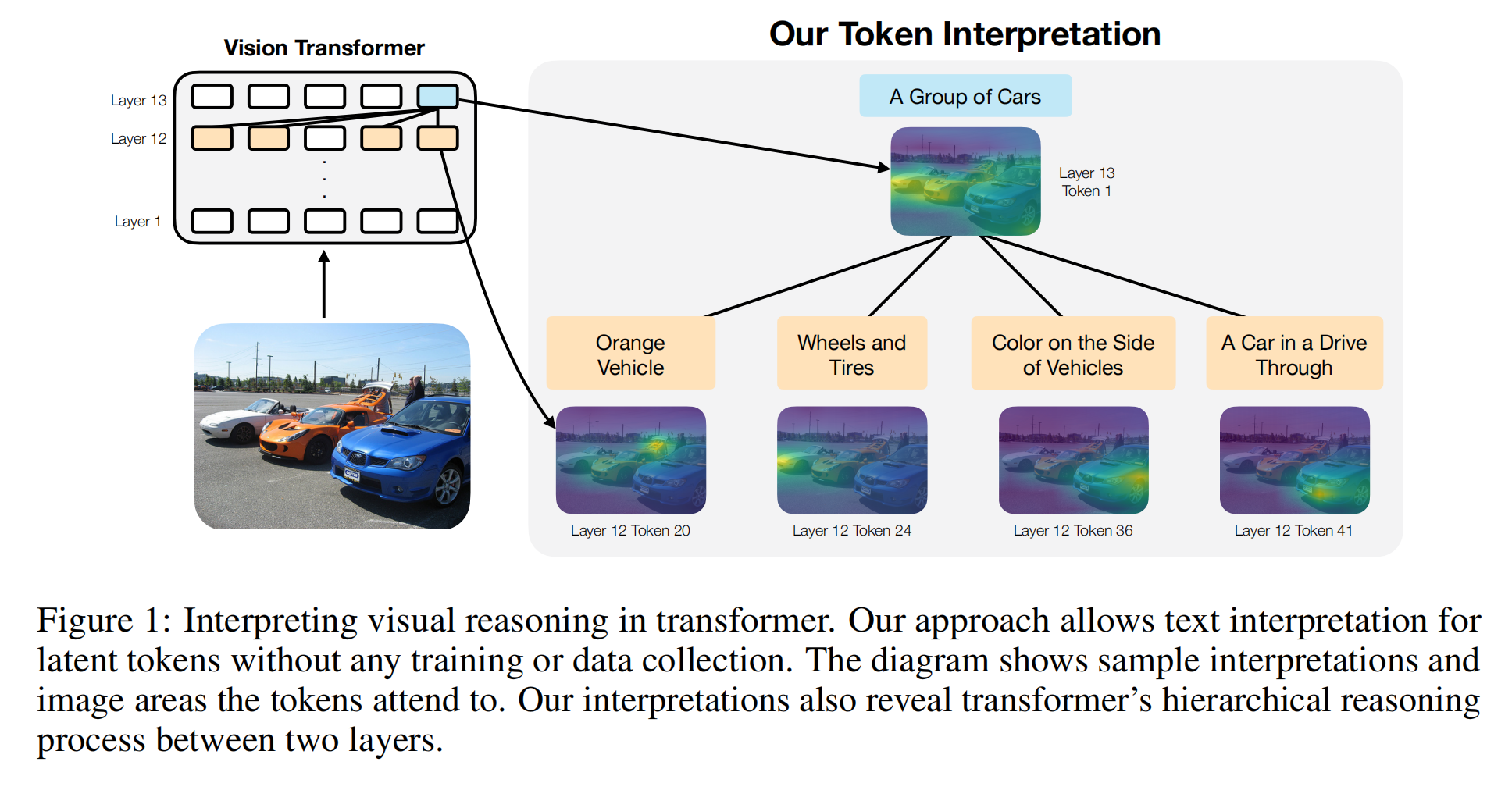
21.【多模态】Weakly Supervised Fine-grained Scene Graph Generation via Large Language Model
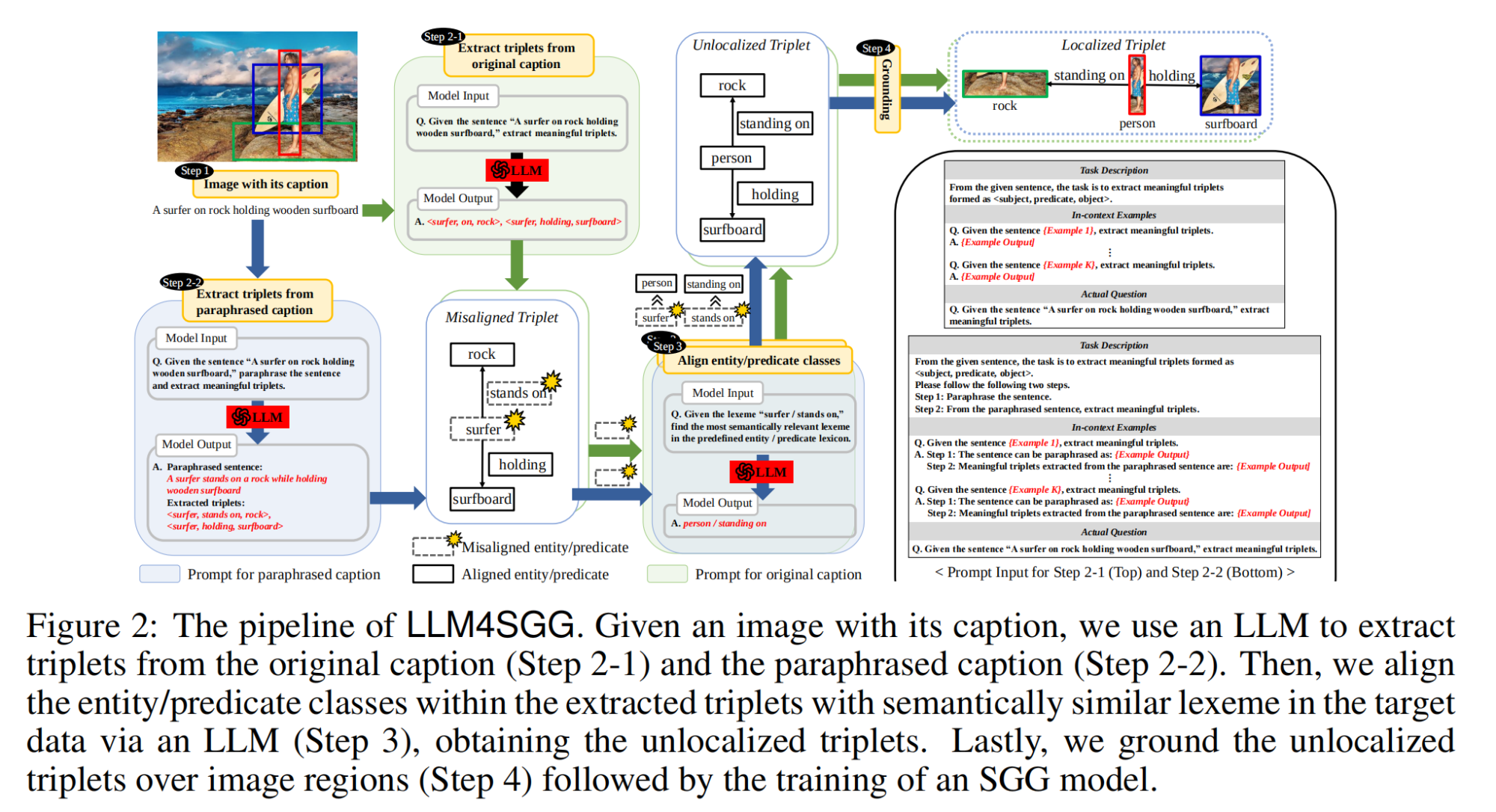
22.【多模态】LICO: Explainable Models with Language-Image Consistency
-
开源代码(即将开源):GitHub - ymLeiFDU/LICO
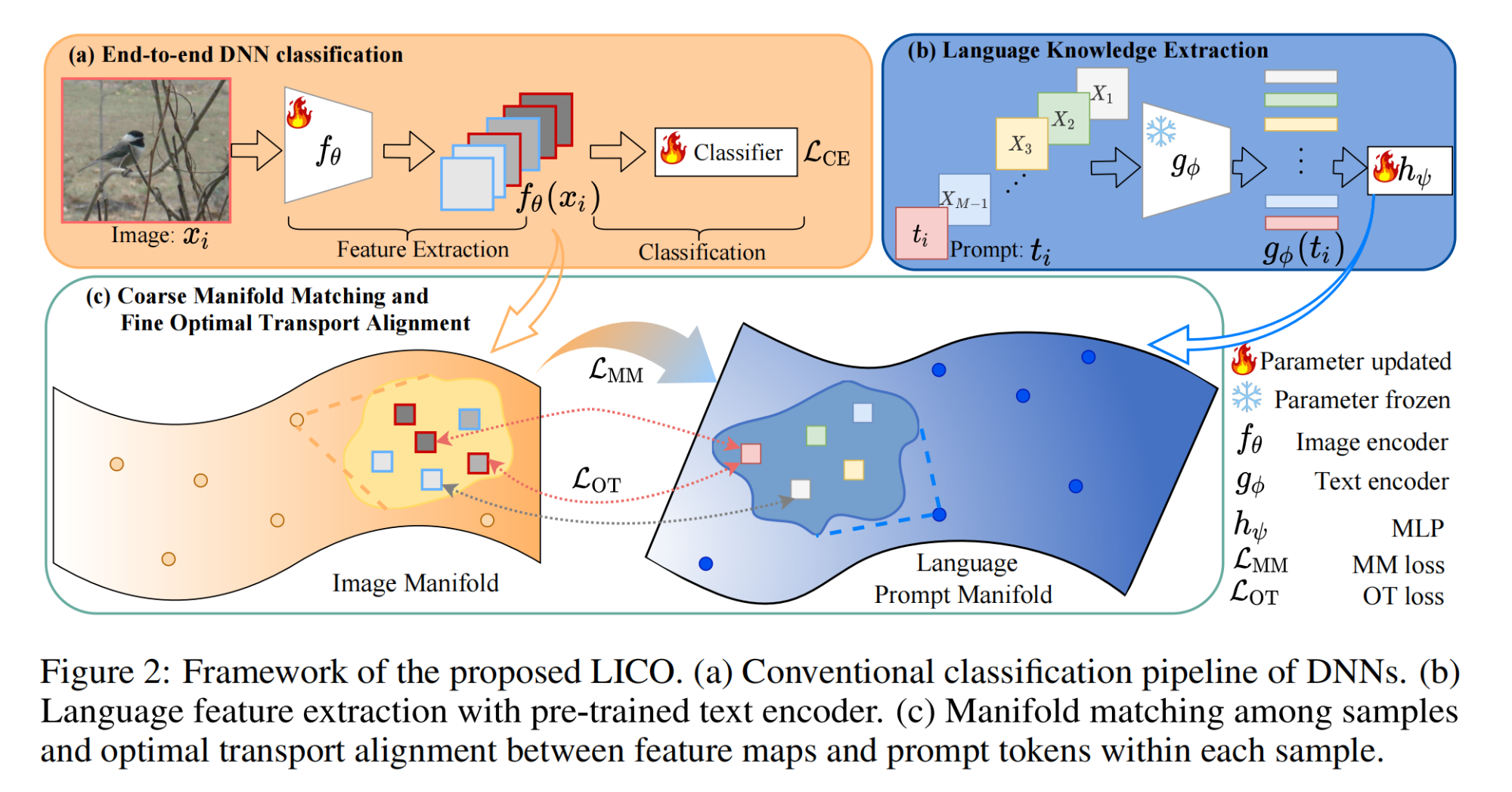
23.【多模态】CAPro: Webly Supervised Learning with Cross-Modality Aligned Prototypes
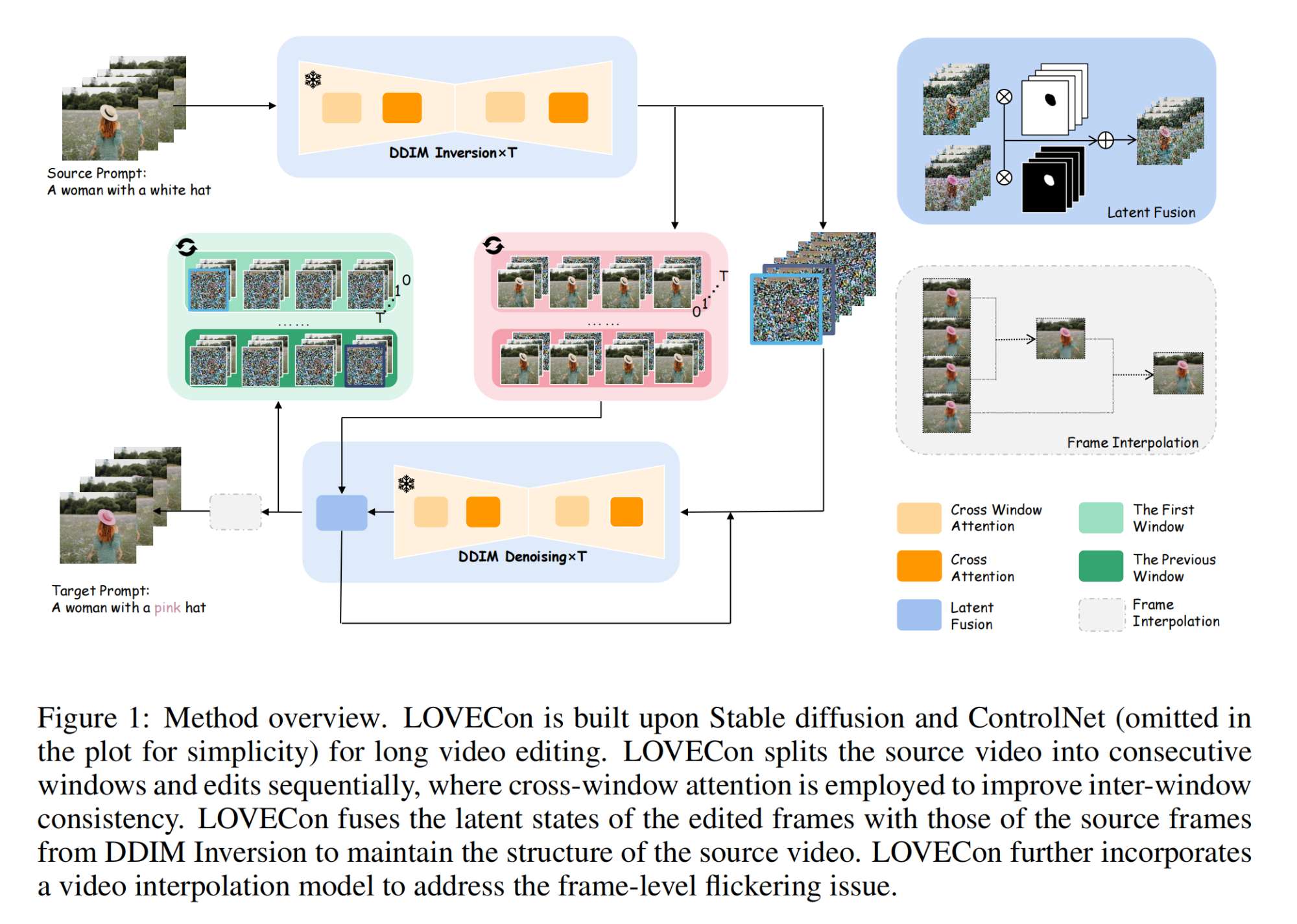
24.【多模态】LOVECon: Text-driven Training-Free Long Video Editing with ControlNet
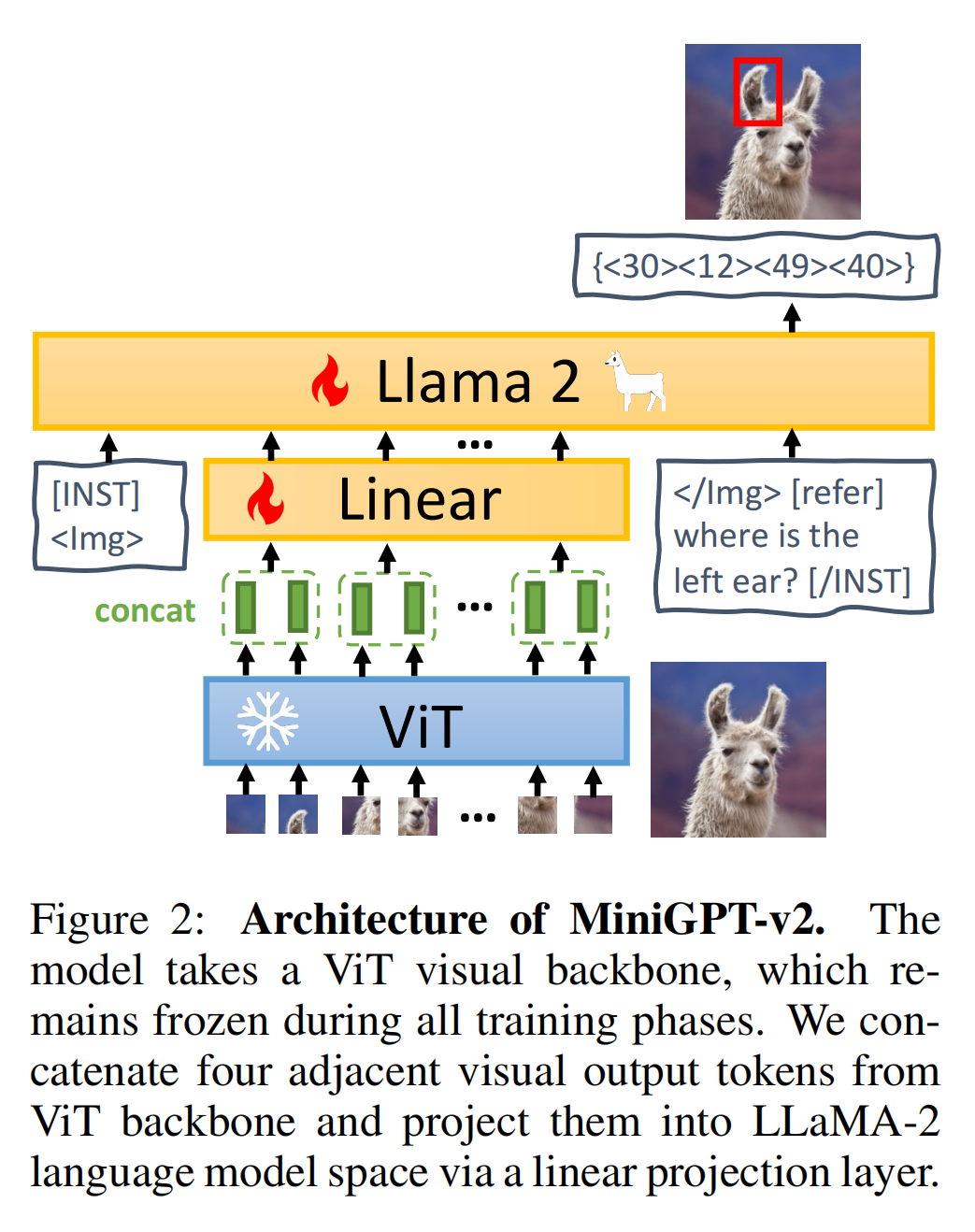
25.【多模态】MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning
-
工程主页:MiniGPT-v2
-
开源代码:GitHub - Vision-CAIR/MiniGPT-4: Open-sourced codes for MiniGPT-4 and MiniGPT-v2
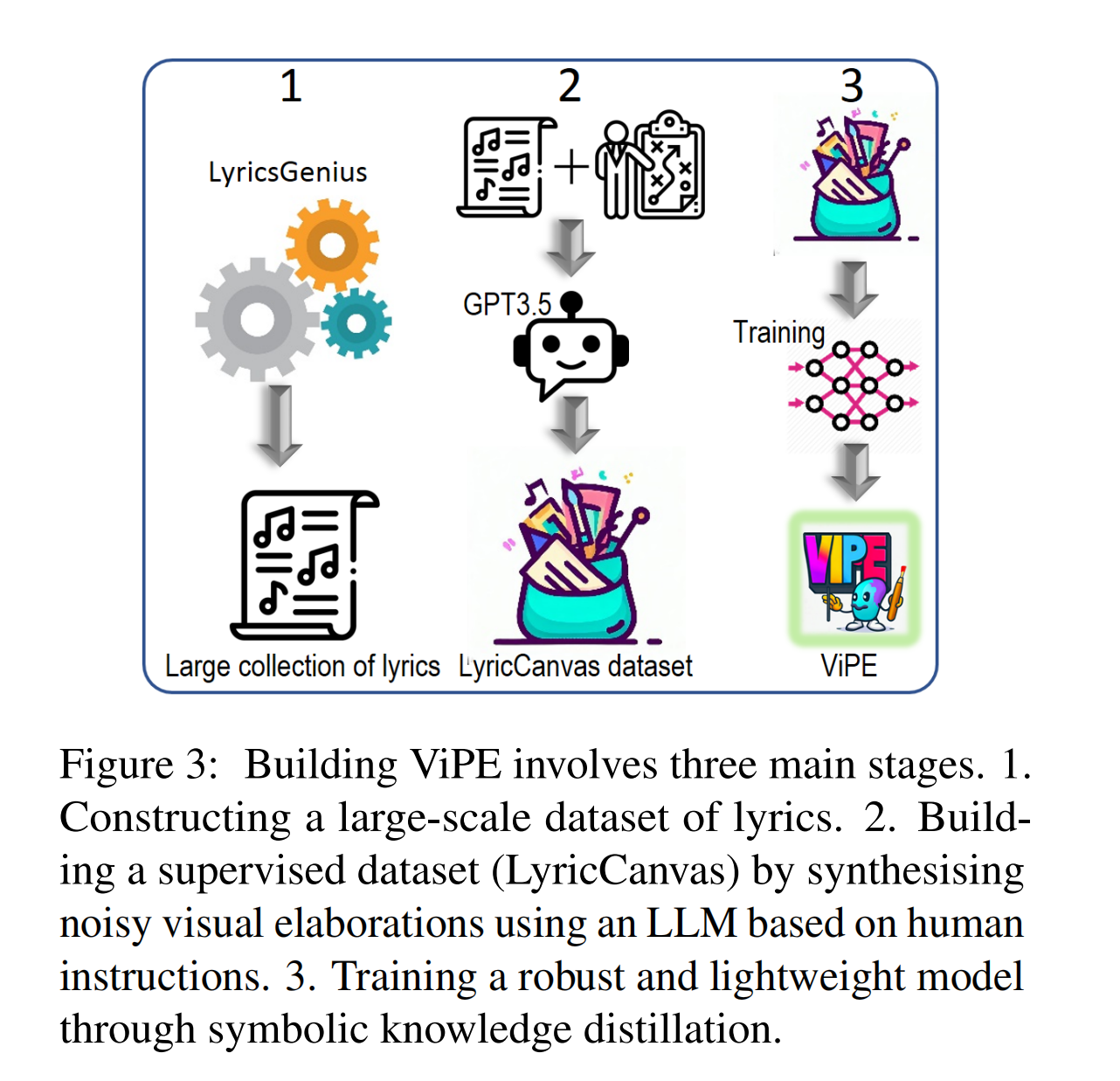
26.【多模态】ViPE: Visualise Pretty-much Everything
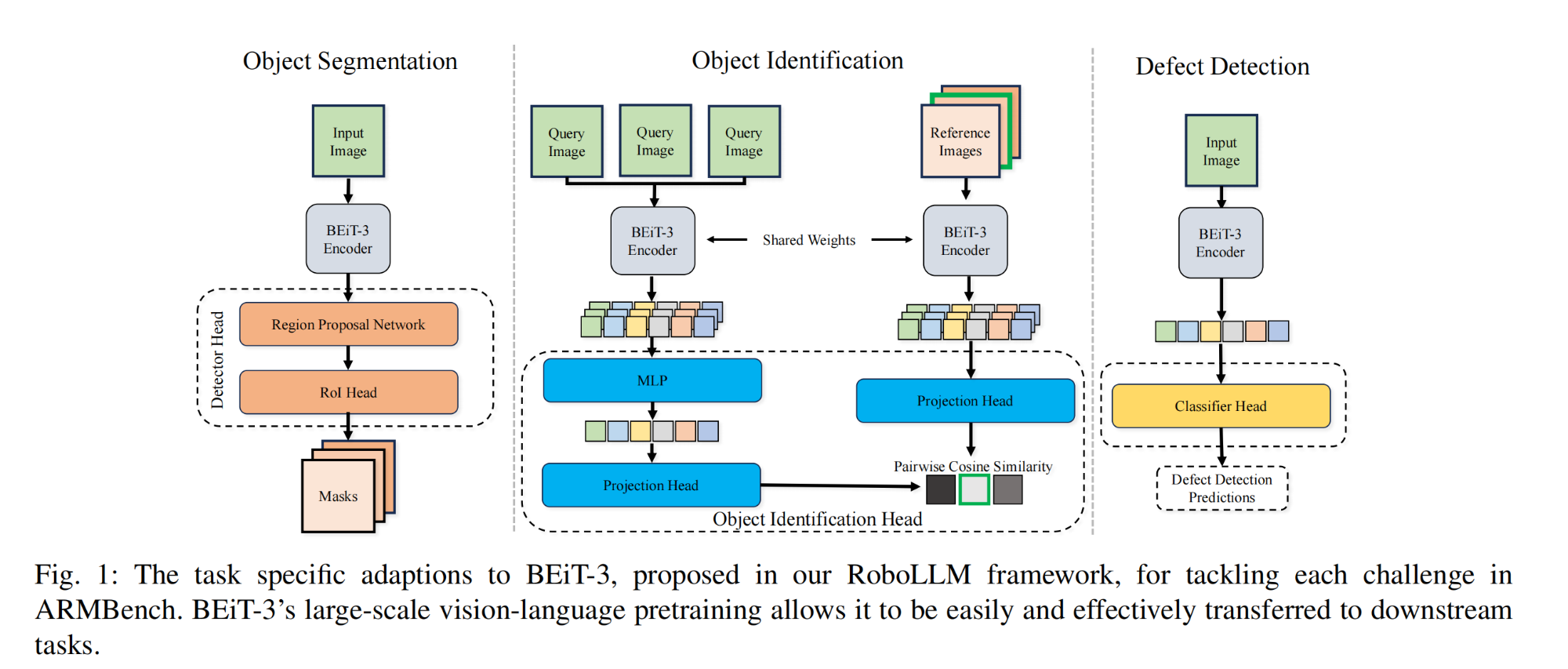
27.【多模态】RoboLLM: Robotic Vision Tasks Grounded on Multimodal Large Language Models
28.【Diffusion】A Survey on Video Diffusion Models
29.【Diffusion】ConsistNet: Enforcing 3D Consistency for Multi-view Images Diffusion
-
工程主页:ConsistNet: Enforcing 3D Consistency for Multi-view Images Diffusion
-
开源代码(即将开源):https://github.com/JiayuYANG/ConsistNet

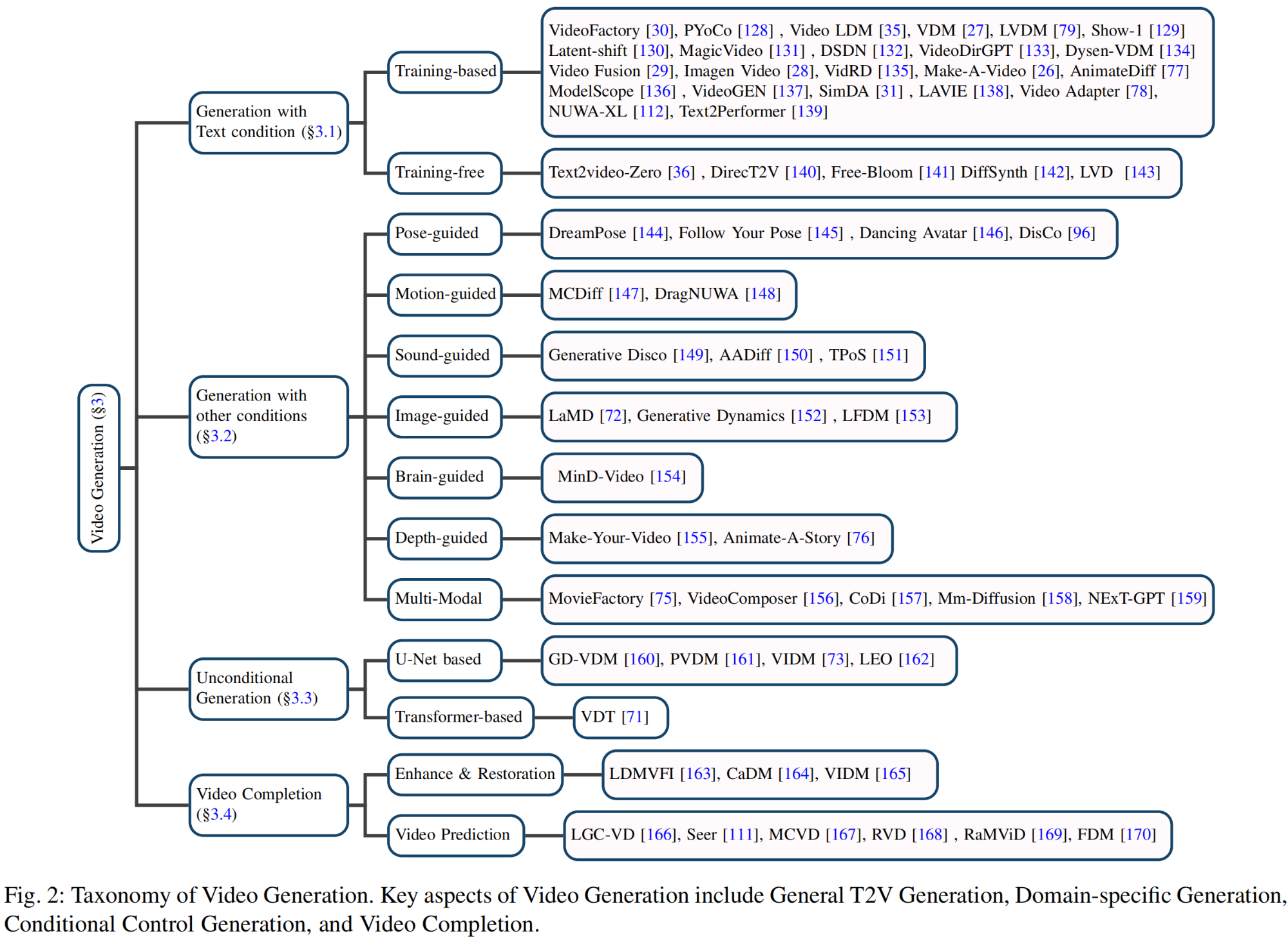
30.【Diffusion】Scene Graph Conditioning in Latent Diffusion
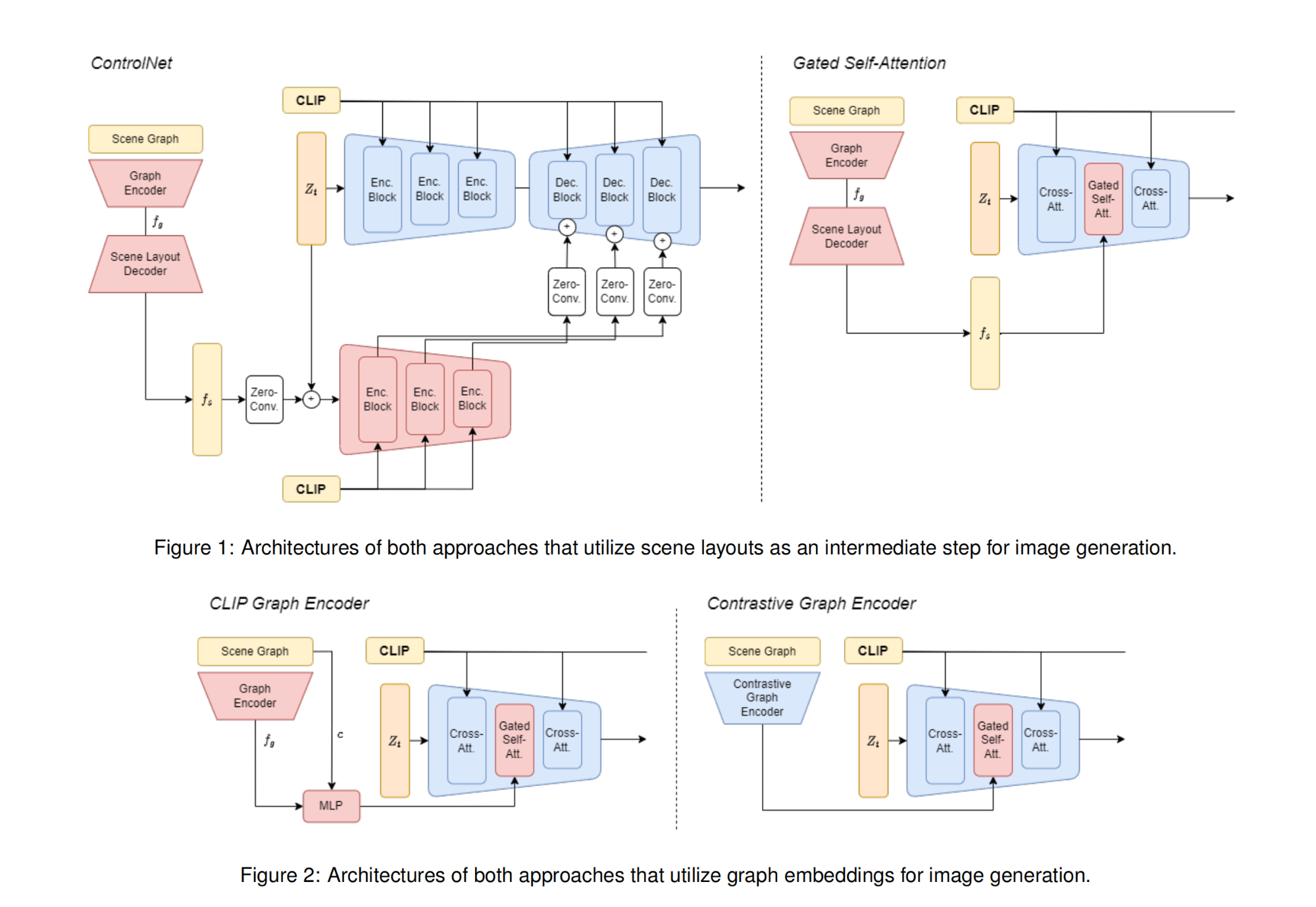
31.【图像去噪】A cross Transformer for image denoising
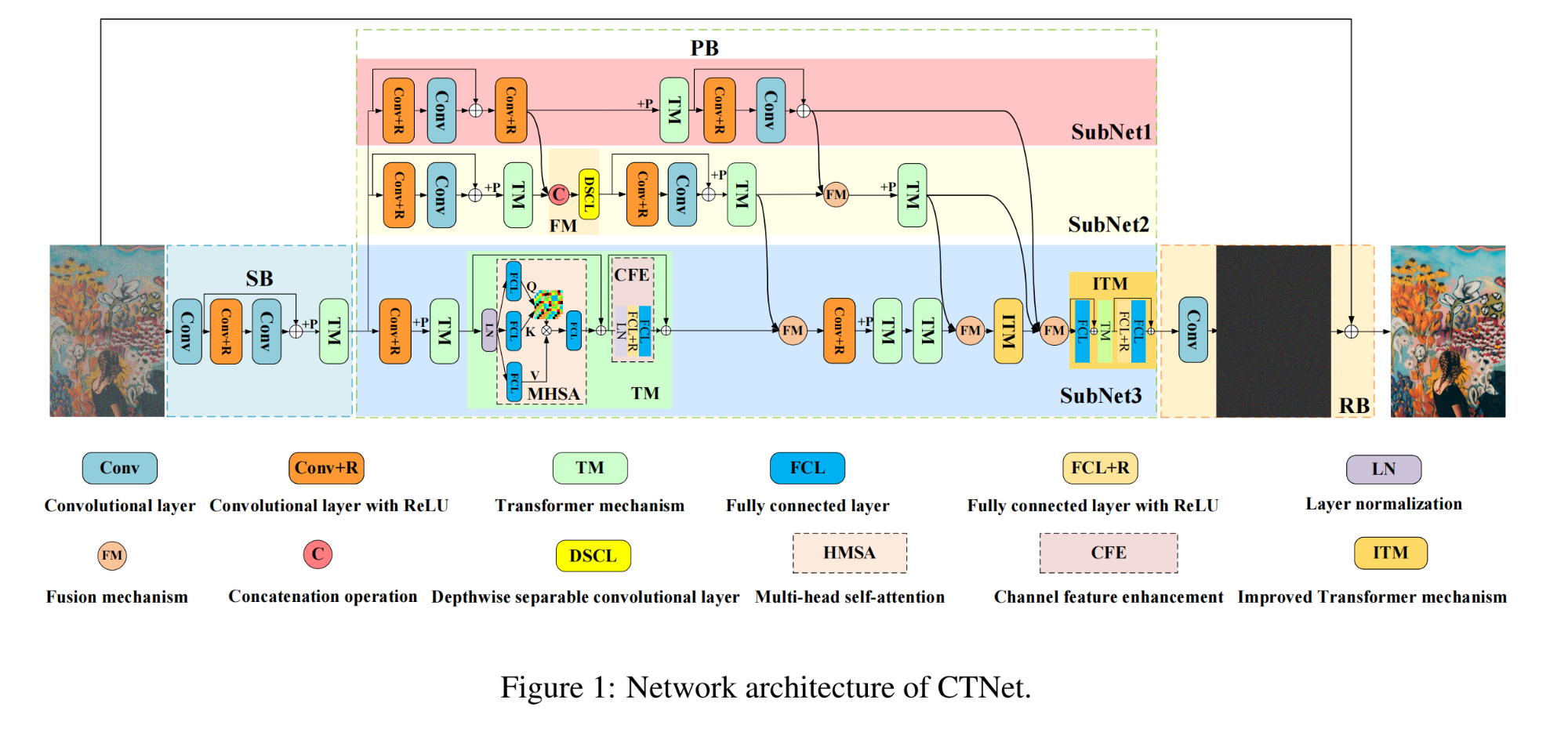
32.【图像去噪】PUCA: Patch-Unshuffle and Channel Attention for Enhanced Self-Supervised Image Denoising
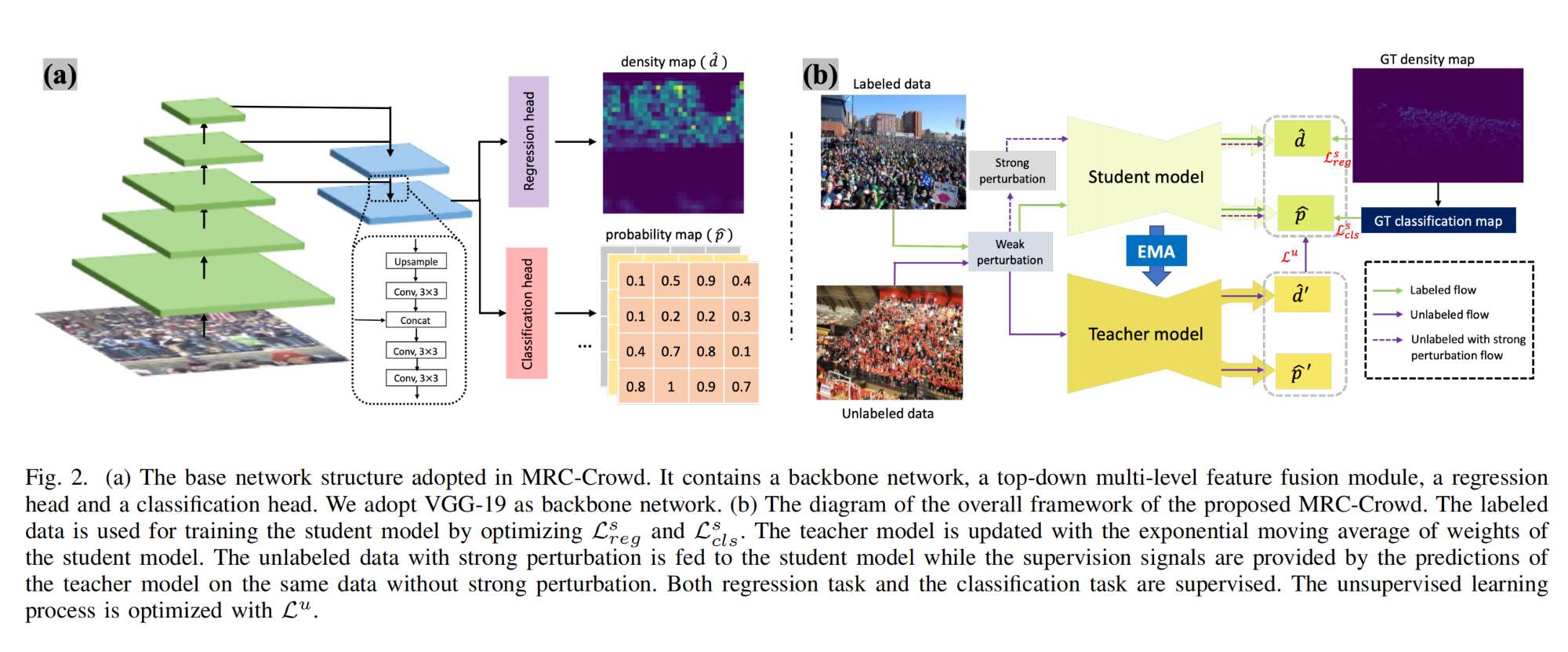
33.【人群计数】Semi-Supervised Crowd Counting with Contextual Modeling: Facilitating Holistic Understanding of Crowd Scenes
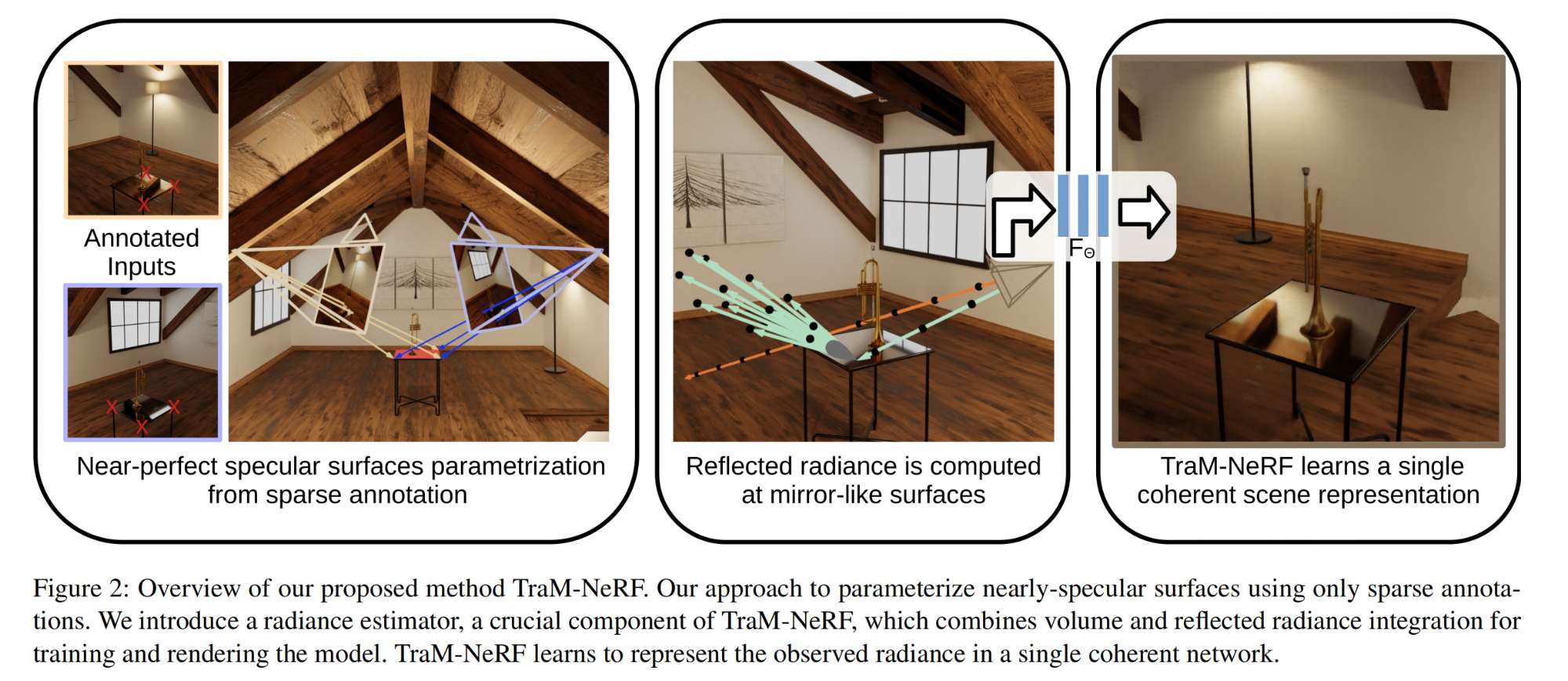
34.【NeRF】TraM-NeRF: Tracing Mirror and Near-Perfect Specular Reflections through Neural Radiance Fields
-
开源代码(即将开源):GitHub - Rubikalubi/TraM-NeRF
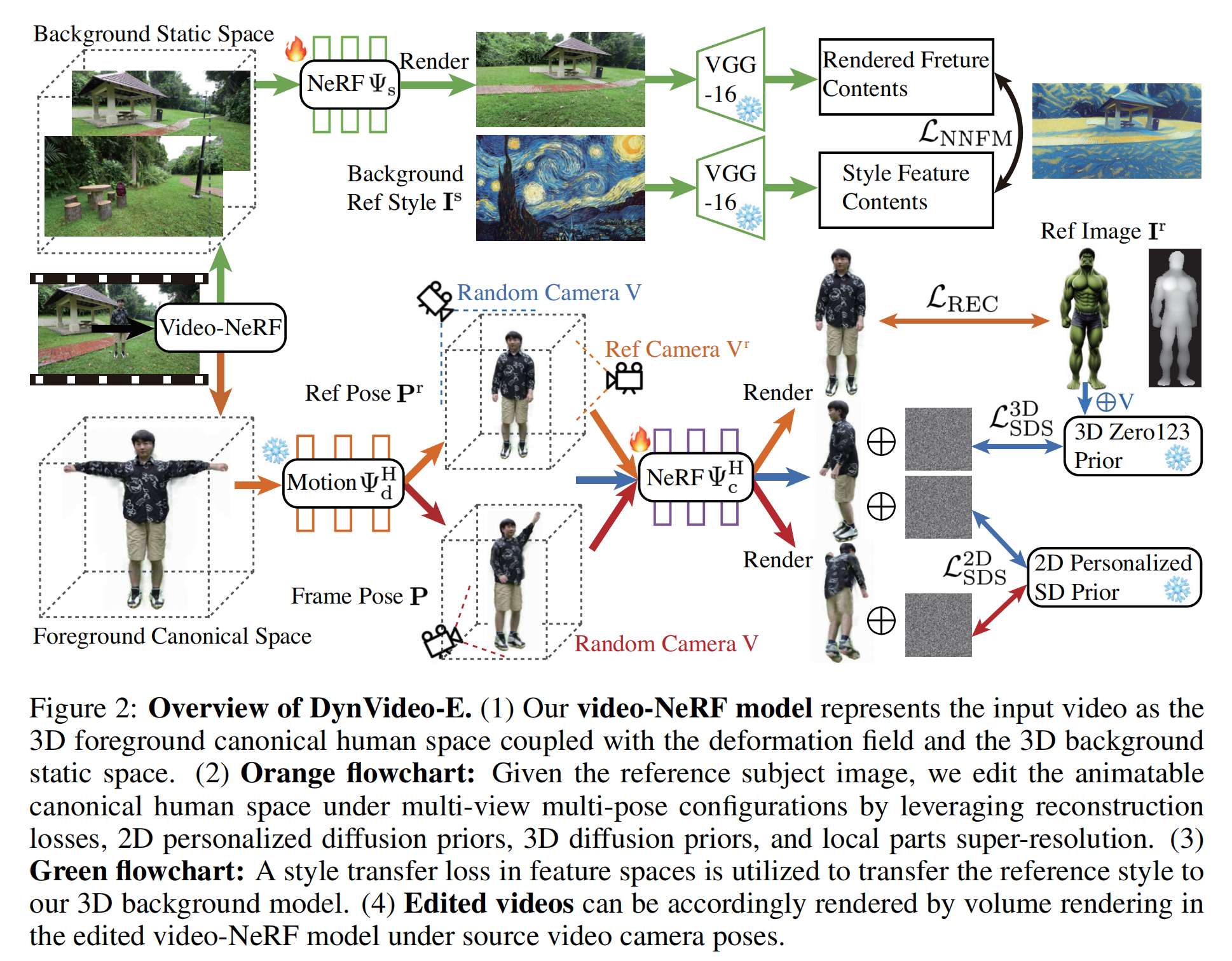
35.【NeRF】DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
-
代码即将开源
36.【NeRF】ProteusNeRF: Fast Lightweight NeRF Editing using 3D-Aware Image Context
-
工程主页:ProteusNeRF
-
代码即将开源

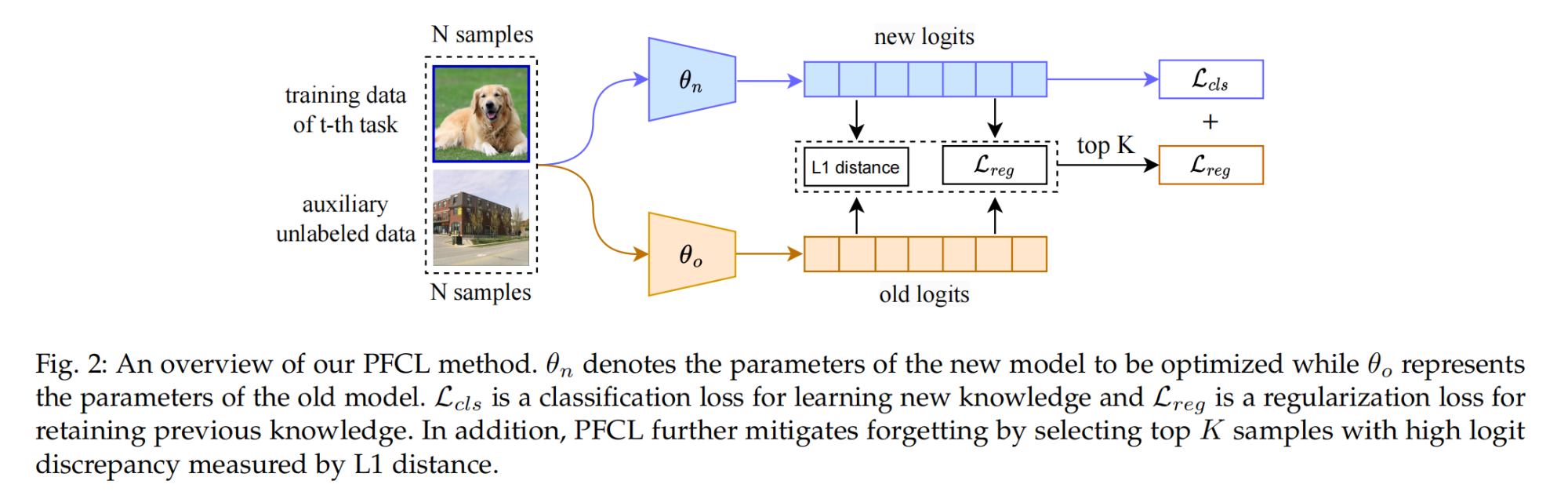
37.【Continual Learning】Prior-Free Continual Learning with Unlabeled Data in the Wild
论文已打包,点击进入—>下载界面
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.10.16
CV计算机视觉每日开源代码Paper with code速览-2023.10.13
HSN:微调预训练ViT用于目标检测和语义分割,华南理工和阿里巴巴联合提出

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)