一.Yolov8量化感知训练微调(QAT)第一篇:QAT原理和微调训练流程
量化感知训练(QAT)是一种先进技术,它弥合了高精度浮点模型与适用于资源受限硬件部署的高效低精度整数模型之间的差距。在原先检测模型背景下,QAT使模型能够保持其检测精度,同时通过TensorRT优化显著提高推理性能。量化是将模型权重和激活值从高精度(通常是32位浮点)转换为低精度(如8位整数)的过程。减少内存占用:INT8模型所需的内存比FP32模型少约4倍更快推理:在大多数硬件上,整数运算的计算
一. 量化概述:
1.量化感知训练(QAT)
量化感知训练(QAT)是一种先进技术,它弥合了高精度浮点模型与适用于资源受限硬件部署的高效低精度整数模型之间的差距。在原先检测模型背景下,QAT使模型能够保持其检测精度,同时通过TensorRT优化显著提高推理性能。
量化是将模型权重和激活值从高精度(通常是32位浮点)转换为低精度(如8位整数)的过程。这种转换提供了几个优势:
减少内存占用:INT8模型所需的内存比FP32模型少约4倍
更快推理:在大多数硬件上,整数运算的计算成本更低且速度更快
能源效率:低精度计算消耗更少的电量,使其成为移动设备和边缘设备的理想选择
然而,简单的量化(通常称为训练后量化或PTQ)可能导致显著的精度下降。这就是量化感知训练变得至关重要的原因。
2.量化感知训练与训练后量化的比较
QAT和PTQ之间的关键区别在于量化何时被引入模型:
2.1 训练后量化(PTQ)
PTQ在模型完全以浮点精度训练后应用量化。该过程包括:
(1) 训练一个标准的FP32模型
(2) 使用小型数据集校准量化参数
(3) 将模型转换为INT8而无需进一步训练
虽然PTQ简单快速,但它通常导致精度损失,因为模型在训练过程中从未学习过补偿量化误差。
2.2 量化感知训练(QAT)
QAT将量化模拟集成到训练过程本身:
(1) 训练一个标准的FP32模型至收敛
(2) 插入模拟INT8操作的伪量化节点
(3) 在这些量化节点激活的情况下微调模型
(4) 模型学习对量化效应具有鲁棒性的权重
这种方法使模型能够适应量化的约束,从而保留更多的原始精度。
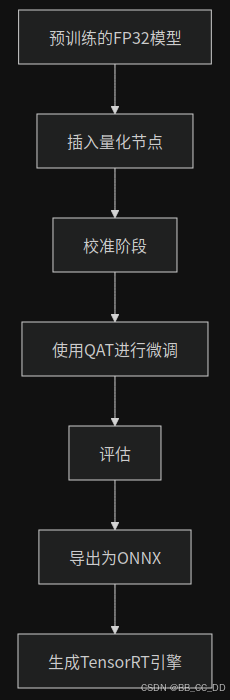
二. 模型量化感知训练微调(QAT)和模型导出的流程:
三. 安装运行环境
我电脑的环境
PyTorch version: 1.11.0
CUDA available: True
ONNX Runtime version: 1.16.3
OpenCV version: 4.10.0
PyTorch 1.11.0对应的pytorch_quantization==2.1.3:
安装pytorch_quantization(要和torch版本对应好, 否则会出错)
pip install --no-cache-dir --extra-index-url https://pypi.tuna.tsinghua.edu.cn/simple pytorch_quantization==2.1.3
运行下面的代码测试环境和库是否安装正确:
如果没有报错, 说明环境安装正确.
import torch
import pytorch_quantization
import onnxruntime
import cv2
import ultralytics
print('PyTorch version:', torch.__version__)
print('CUDA available:', torch.cuda.is_available())
print('PyTorch Quantization installed successfully')
print('ONNX Runtime version:', onnxruntime.__version__)
print('OpenCV version:', cv2.__version__)
print('Ultralytics imported successfully')
四. 模型量化感知训练微调(QAT)
1.加预训练模型
2.准备数据集
3.插入量化-反量化(QDQ)节点
4.应用自定义量化规则
5.校准模型
6.执行带量化感知的微调和评估
1. 准备一个训练好的yolo模型
用官方Yolo算法训练一个pt模型, 或者用官方的pt模型也可以自己训练的pt模型, 这个pt模型要用到QAT进行微调.
2. 模型加载和准备
使用 load_yolov8_model 函数加载预训练模型:
def load_yolov8_model(weight, device) -> OBBModel:
attempt_download(weight)
model = torch.load(weight, map_location=device)["model"]
# 兼容性调整
for m in model.modules():
if type(m) is nn.Upsample:
m.recompute_scale_factor = None
elif type(m) is Conv:
m._non_persistent_buffers_set = set()
model.args = cfg
model.float()
model.eval()
with torch.no_grad():
model.fuse()
return model
3. 量化模块替换
QAT 的核心涉及将标准 PyTorch 模块替换为其量化版本。这是通过 replace_to_quantization_module 函数完成, 此函数递归遍历模型并将兼容模块替换为量化版本:
def replace_to_quantization_module(model : torch.nn.Module, ignore_policy : Union[str, List[str], Callable] = None):
module_dict = {}
for entry in quant_modules._DEFAULT_QUANT_MAP:
module = getattr(entry.orig_mod, entry.mod_name)
module_dict[id(module)] = entry.replace_mod
def recursive_and_replace_module(module, prefix=""):
for name in module._modules:
submodule = module._modules[name]
path = name if prefix == "" else prefix + "." + name
recursive_and_replace_module(submodule, path)
submodule_id = id(type(submodule))
if submodule_id in module_dict:
ignored = quantization_ignore_match(ignore_policy, path)
if ignored:
print(f"Quantization: {path} has ignored.")
continue
module._modules[name] = transfer_torch_to_quantization(submodule, module_dict[submodule_id])
recursive_and_replace_module(model)
4. 自定义量化规则
用自定义量化规则以确保最佳性能。这些规则在 rules.py 文件中定义,并通过 apply_custom_rules_to_quantizer 函数应用, 此过程确保量化器在整个网络中正确对齐,这对于保持精度至关重要:
def apply_custom_rules_to_quantizer(model : torch.nn.Module, export_onnx : Callable):
# 将规则应用于图
export_onnx(model, "quantization-custom-rules-temp.onnx")
pairs = find_quantizer_pairs("quantization-custom-rules-temp.onnx")
for major, sub in pairs:
print(f"Rules: {sub} match to {major}")
get_attr_with_path(model, sub)._input_quantizer = get_attr_with_path(model, major)._input_quantizer
os.remove("quantization-custom-rules-temp.onnx")
5. 模型校准
在微调之前,需要校准模型以确定最佳量化参数。这是使用 calibrate_model 函数完成, 此过程将训练数据的一个子集输入模型,以收集确定最佳量化范围的统计信息。
def calibrate_model(model : torch.nn.Module, dataloader, device, num_batch=25):
def compute_amax(model, **kwargs):
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
if isinstance(module._calibrator, calib.MaxCalibrator):
module.load_calib_amax()
else:
module.load_calib_amax(**kwargs)
module._amax = module._amax.to(device)
def collect_stats(model, data_loader, device, num_batch=200):
# 启用校准器并收集统计信息
model.eval()
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.disable_quant()
module.enable_calib()
else:
module.disable()
with torch.no_grad():
for i, datas in tqdm(enumerate(data_loader), total=num_batch, desc="Collect stats for calibrating"):
imgs = datas['img'].to(device, non_blocking=True).float() / 255
imgs = imgs[:,1,:,:].unsqueeze(1)
model(imgs)
if i >= num_batch:
break
# 禁用校准器
for name, module in model.named_modules():
if isinstance(module, quant_nn.TensorQuantizer):
if module._calibrator is not None:
module.enable_quant()
module.disable_calib()
else:
module.enable()
collect_stats(model, dataloader, device, num_batch=num_batch)
compute_amax(model, method="mse")
6. 量化感知训练微调和评估
最后一步是带量化感知的微调模型和每个epoch后的QAT模型评估, 这是模型学习适应量化精度。在微调过程中,模型被训练以最小化其量化输出与原始(非量化)模型输出之间的差异。这有助于模型学习在量化效果下保持精度。
python qat-yolov8-obb.py --weight path/to/your/model.pt --cocodir path/to/your/dataset/ --finetune --eval-origin --eval-ptq
注意: QAT 通常需要比标准训练更低的学习率, 每个epoch量化训练后都会打印此时QAT模型针对数据集的验证结果.
–eval-origin: 模型在进行QAT训练前, 会先把原pt模型针对数据集的验证结果先统计出来.
–eval-ptq: 模型在进行QAT训练前, 会先把原pt模型直接经过int8量化后, 针对数据集的验证结果先统计出来.
# 源代码:quantize.py
def finetune(
model : torch.nn.Module, train_dataloader, per_epoch_callback : Callable = None,
preprocess : Callable = None, nepochs=200, early_exit_batchs_per_epoch=1000,
lrschedule : Dict = None, fp16=True, learningrate=1e-5,
supervision_policy : Callable = None
):
origin_model = deepcopy(model).eval()
disable_quantization(origin_model).apply()
model.train()
model.requires_grad_(True)
scaler = amp.GradScaler(enabled=fp16)
optimizer = optim.Adam(model.parameters(), learningrate)
quant_lossfn = torch.nn.MSELoss()
device = next(model.parameters()).device
# 设置监督模块对
supervision_module_pairs = []
for ((mname, ml), (oriname, ori)) in zip(model.named_modules(), origin_model.named_modules()):
if isinstance(ml, quant_nn.TensorQuantizer): continue
if supervision_policy:
if not supervision_policy(mname, ml):
continue
supervision_module_pairs.append([ml, ori])
# 训练循环
for iepoch in range(nepochs):
if iepoch in lrschedule:
learningrate = lrschedule[iepoch]
for g in optimizer.param_groups:
g["lr"] = learningrate
model_outputs = []
origin_outputs = []
remove_handle = []
for ml, ori in supervision_module_pairs:
remove_handle.append(ml.register_forward_hook(make_layer_forward_hook(model_outputs)))
remove_handle.append(ori.register_forward_hook(make_layer_forward_hook(origin_outputs)))
model.train()
pbar = tqdm(train_dataloader, desc="QAT", total=early_exit_batchs_per_epoch)
for ibatch, imgs in enumerate(pbar):
if ibatch >= early_exit_batchs_per_epoch:
break
if preprocess:
imgs = preprocess(imgs, device)
with amp.autocast(enabled=fp16):
model(imgs)
with torch.no_grad():
origin_model(imgs)
quant_loss = 0
for index, (mo, fo) in enumerate(zip(model_outputs, origin_outputs)):
quant_loss += quant_lossfn(mo, fo)
model_outputs.clear()
origin_outputs.clear()
if fp16:
scaler.scale(quant_loss).backward()
scaler.step(optimizer)
scaler.update()
else:
quant_loss.backward()
optimizer.step()
optimizer.zero_grad()
pbar.set_description(f"QAT Finetuning {iepoch + 1} / {nepochs}, Loss: {quant_loss.detach().item():.5f}, LR: {learningrate:g}")
# 清理钩子
for rm in remove_handle:
rm.remove()
if per_epoch_callback:
if per_epoch_callback(model, iepoch, learningrate):
break
6.1 finetune()方法的参数:
(1) per_epoch_callback: 每个epoch结束后的回调函数
1.在 qat-yolov8-obb.py 中对应 per_epoch 函数.
2.用于保存最佳模型和记录训练日志.
(2) preprocess: 数据预处理函数:
1.在 qat-yolov8-obb.py 中对应 preprocess_batch 函数.
2.对输入batch进行预处理(如数据格式转换、归一化等).
(3) nepochs VS iters 的区别:
核心区别:
1.nepochs: 训练的总轮数(多少个完整的训练周期)
2.iters: 每个epoch的迭代次数(每个epoch处理多少个batch, 可以理解成batch)
总训练batch数 = nepochs × iters
总训练数据集样本数 = nepochs × iters × batchsize但这里有一个iters和Train数据集的数量问题:
(1) 比如我的train数量是454, batchsize是16(即ultralytics/cfg/default.yaml中的batch参数), 那么iters_actual = 454 / 16 = 28.375即29次迭代.
(2) 那么iters设置为200, 一次epoch的迭代次数也不会超出29次迭代;
(3) 但要注意的是, 如果Train数据集很大, 一定要通过上述计算得到iters_actual, 然后再设置iters值, 否则很可能会出现 iters_actual > iters, 进而导致迭代次数不够而使一些样本没有训练到.
6.2 原始模型和量化模型计算损失,以及训练设计原理
- 量化模型处理输入数据
- 原始模型(未量化)处理相同的输入数据
- 使用MSE损失函数计算两个模型在指定层的输出差异
- 这个差异损失用于反向传播,调整量化参数,使量化模型的输出尽可能接近原始模型
(Loss值越小,量化模型的行为越接近原始模型,量化效果越好。)这就是知识蒸馏(Knowledge Distillation)的思想,用原始模型作为"教师"来指导量化模型(学生)的训练
# 1.创建教师模型
origin_model = deepcopy(model).eval() # 创建原始模型副本
disable_quantization(origin_model).apply() # 禁用量化,保持原始精度
# 2.建立监督关系
for ml, ori in supervision_module_pairs:
remove_handle.append(ml.register_forward_hook(make_layer_forward_hook(model_outputs)))
remove_handle.append(ori.register_forward_hook(make_layer_forward_hook(origin_outputs)))
# 3. 损失计算
# 使用MSE损失函数, 用于比较量化模型和原始模型的输出差异损失。
# Loss值越小,说明量化模型的行为越接近原始模型,量化效果越好。
quant_lossfn = torch.nn.MSELoss()
with amp.autocast(enabled=fp16):
model(imgs) # 量化模型前向传播
with torch.no_grad():
origin_model(imgs) # 原始模型前向传播
quant_loss = 0
for index, (mo, fo) in enumerate(zip(model_outputs, origin_outputs)):
quant_loss += quant_lossfn(mo, fo) # MSE损失比较输出差异
6.3 QAT finetuning的注意事项:
(1) 使用适当的学习率:QAT 通常需要比标准训练更低的学习率。
(2) 监控训练和验证损失:防止模型在 QAT 过程中过拟合。
(3) 尝试不同的忽略策略:不同的层对量化可能有不同的敏感性。使用敏感性分析功能来确定哪些层应保持全精度。
(4) 内存问题:QAT 比标准训练需要更多内存, 如果遇到内存问题,请减少批量大小, 由于额外的量化操作,QAT 本质上比标准训练慢。
五. 评估量化模型(和原模型对比)
训练后,需要评估量化模型以确保其保持可接受的精度, 对两个模型运行评估并将结果保存到 JSON 文件以进行比较。
python qat-yolov8-obb.py --weight path/to/your/model.pt --cocodir path/to/your/dataset/ --finetune --eval-origin --eval-ptq
1. 检查QAT模型是否正确
# 加载QAT模型
qat_model = torch.load("qat.pt")["model"]
# 检查是否包含量化节点
for name, module in qat_model.named_modules():
if "QuantizeLinear" in str(type(module)) or "DequantizeLinear" in str(type(module)):
print(f"Found quantization node: {name}")
2. 推理原始pt模型和QAT之后的pt模型:
运行2_infer_obb_pt_onnx.py, 分别测试原始pt和QAT之后的pt模型对同一数据集的精度.
3.用Precision和Recall评估原始pt模型和QAT之后的pt模型:
运行3_infer_obb_cal_pt_qat_prec_recall.py统计val验证集或者带有标注的数据集的Precision和Recall.
(1) 如果你统计的指标是下面的指标, 表示QAT之后的pt模型和原始pt模型精度没有偏差, 这是我们最最想要的情况.
(2) 如果你统计的指标是下面的指标, 表示原始pt模型和QAT之后的pt模型精度有一点偏差, 视情况再进行QAT训练.
(3) 如果你统计的指标是下面的指标, 表示QAT之后的pt模型精度下降非常了, 必须重新QAT训练.
六. 量化模型qat.pt导出为伪量化onnx模型
转为伪量化onnx模型
python qat-yolov8-obb.py --weight path/to/your/qat_model.pt --export --save path/to/output.onnx
1. 为什么要做伪量化onnx模型导出这一步?
1.1 保持训练一致性
(1) QAT训练期间的行为:
1> QAT训练时,前向传播:
输入数据 → QuantizeLinear → FP32计算 → DequantizeLinear → 输出结果
(FP32) → (模拟INT8) → (神经网络层) → (转回FP32) → (用于loss计算)
2> QAT训练时,反向传播:
输出损失 ← 梯度计算 ← 梯度通过量化层 ← 梯度通过FP32层 ← 梯度反向传播
(2) 导出onnx时需要保持与训练相同的行为:
重要: 需要设置use_fb_fake_quant 为 True
1> 如果不设置use_fb_fake_quant = True:
输入 → FP32计算 → 输出 (失去了量化效果)
2> 设置use_fb_fake_quant = True后:
输入 → QuantizeLinear → FP32计算 → DequantizeLinear → 输出
(与训练时一致)
1.2 ONNX模型的要求
1.2.1 总结:
(1) 创建带有量化节点的onnx模型, 这样既能保证原始onnx模型精度, 也能把带有量化节点的onnx模型转为完全量化的onnx模型或者engine模型.
(2) 用伪量化模型推理,模拟量化效果.
(1)ONNX需要显式的量化节点:
- QuantizeLinear: 将FP32转换为量化格式
- DequantizeLinear: 将量化格式转回FP32
- 这些节点让ONNX Runtime知道如何处理量化
伪量化模型是真正INT8量化的中间步骤, 因为pytorch原始pt模型无法直接导出INT8量化Onnx模型(2)导出ONNX的目的:
- 验证QAT训练效果 (因为加入了量化节点)
- 通过量化节点测试量化模型的精度
- 检查推理性能
- 为真正INT8量化做准备
ONNX图结构:
Input -> QuantizeLinear -> FP32计算 -> DequantizeLinear -> Output
(INT8模拟) (实际还是FP32) (转回FP32)
2. 再简化ONNX模型
导出过程包括 ONNX 简化以优化模型进行推理, 用到simplify参数(在ultralytics/cfg/default.yaml中):
def export_onnx(model : OBBModel, save_file, size=(640,640), dynamic_batch=False, noanchor=False, prefix=colorstr('ONNX:')):
requirements = ['onnx>=1.12.0']
check_requirements(requirements)
output_names = ['output0','output1','output2']
dynamic = cfg.dynamic
if dynamic:
dynamic['output0'] = {0: 'batch', 2: 'anchors'}
device = next(model.parameters()).device
imgsz = check_imgsz(size, stride=model.stride, min_dim=2)
im = torch.zeros(1, 1, *imgsz).to(device)
quantize.export_onnx(model.cpu() if dynamic else model,
im.cpu() if dynamic else im,
save_file,
verbose=False,
opset_version=13,
do_constant_folding=True,
input_names=['images'],
output_names=output_names,
dynamic_axes=dynamic or None
)
# 简化
model_onnx = onnx.load(save_file)
if cfg.simplify:
try:
LOGGER.info(f'{prefix} simplifying with onnxsim {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(model_onnx)
assert check, 'Simplified ONNX model could not be validated'
except Exception as e:
LOGGER.info(f'{prefix} simplifier failure: {e}')
onnx.save(model_onnx, save_file)
3. 转伪量化onnx模型, 用于tensorrt部署
(依据tensorrt部署代码来定, 我的代码需要修改head.py的代码)
需要修改head.py的代码, “Yolov8_QAT_OBB-master/ultralytics/nn/modules/head.py”
参考:yolov8/yolov11 obb的pt转onnx再转engine, 并支持onnx和engine模型多batch推理
七. 伪量化ONNX模型转为量化engine模型, 在tensorrt中进行量化推理
由于内容比较多, 在后面第二篇中介绍
八. 关于QAT训练的pt模型和原始pt模型的一些问题
1. 量化和反量化
1.1 QAT训练时, 是把输入数据和权重都做了量化,
QAT训练时, 会学习缩放因子scale, 零点偏移zero_point参数, 通过这两个参数, 将输入数据和权重反量化回去.
1.1.1输入数据量化:
# 输入激活值的量化过程:
input_fp32 = torch.randn(1, 3, 640, 640) # FP32输入
scale = 0.1 # 缩放因子
zero_point = 0 # 零点偏移
# 量化过程
input_int8 = QuantizeLinear(input_fp32, scale, zero_point) # 变成INT8
output_fp32 = DequantizeLinear(input_int8, scale, zero_point) # 变回FP32
print(f"输入类型: {input_fp32.dtype}") # torch.float32
print(f"量化后类型: {input_int8.dtype}") # torch.int8
print(f"反量化后类型: {output_fp32.dtype}") # torch.float32
1.1.2权重参数量化和反量化:
# 权重的量化过程:
weight_fp32 = torch.randn(64, 3, 3, 3) # FP32权重
weight_scale = 0.05 # 权重缩放因子
weight_zero_point = 0 # 权重零点偏移
# 权重量化
weight_int8 = QuantizeLinear(weight_fp32, weight_scale, weight_zero_point) # 变成INT8
output_weight_fp32 = DequantizeLinear(weight_int8, scale, zero_point) # 变回FP32
print(f"权重类型: {weight_fp32.dtype}") # torch.float32
print(f"量化后权重类型: {weight_int8.dtype}") # torch.int8
print(f"量化后权重类型: {output_weight_fp32.dtype}") # torch.float32
| 计算类型 | QAT训练 | 真正INT8推理 |
|---|---|---|
| 输入数据 | FP32 → 模拟量化 → FP32计算 | INT8直接计算 |
| 权重 | FP32 → 模拟量化 → FP32计算 | INT8直接计算 |
| 神经网络计算过程 | FP32计算 | INT8计算 |
| 梯度流动 | 连续,稳定 | 不适用(推理阶段) |
| 数值精度 | 高(FP32) | 低(INT8) |
| 目的 | 训练适应量化 | 部署加速 |
2. 为什么中间计算保持FP32?
2.1 保持数值精度
如果中间计算用INT8:
输入(INT8) → INT8卷积 → 输出(INT8)
问题:INT8计算精度低,梯度不稳定,训练困难
QAT的方式:
输入(FP32) → QuantizeLinear → FP32卷积 → DequantizeLinear → 输出(FP32)
优势:保持FP32计算精度,梯度稳定
2.2 梯度正常流动
量化节点支持梯度传播:
QuantizeLinear: 模拟量化,但梯度可以正常流动
DequantizeLinear: 反量化,梯度也可以正常流动
这样设计的好处:
权重可以正常更新
量化参数(scale, zero_point)也可以学习
训练过程稳定
3. QAT训练的pt模型和原始pt模型大小差不多的原因
3.1 QAT训练阶段, 不改变模型大小
(1) QAT(Quantization Aware Training) 是感知量化训练,不是真正的量化, 训练时模型权重仍然是FP32格式, 只是在前向传播时模拟量化效果.
(2) 增加了量化节点:
QAT模型比原始模型多了这些组件:
- QuantizeLinear节点(输入量化)
- DequantizeLinear节点(输出反量化)
- 量化参数(scale, zero_point)
- 校准器信息
原始模型.pt:
├── model.state_dict (FP32权重)
└── 其他元数据
QAT模型.pt:
├── model.state_dict (FP32权重 + 量化节点)
├── quantization_params (量化参数)
├── calibration_info (校准信息)
└── 其他元数据
3.2 导出伪量化onnx模型, 不改变模型大小
原始模型.pt: ~100MB (FP32权重)
伪量化ONNX.onnx: ~100MB (FP32权重 + 量化节点)
伪量化的典型特征:
节点类型:大量 QuantizeLinear 和 DequantizeLinear 节点
权重类型:(1) 未量化: 权重基本都是 FLOAT 类型;
(2) 部分量化或混合量化: 有FLOAT也有 INT8
(3) 大部分卷积层:FP32权重 + QuantizeLinear/DequantizeLinear节点;少数特定层:真正INT8量化(可能是某些敏感层或测试层)文件大小:与原始模型大小相近
-计算模式:QuantizeLinear → FP32计算 → DequantizeLinear
3.3 真正量化, 改变模型大小
真正INT8量化的典型特征:
-节点类型:直接使用量化算子(如 QLinearConv)
-权重类型:大部分权重是INT8类型(比如90%以上), 少量特殊层保持FP32(如输出层)
-文件大小:比原始模型小3-4倍
-计算模式:直接用量化int8进行计算

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)