关于深度学习的计算机考研复试项目(三)
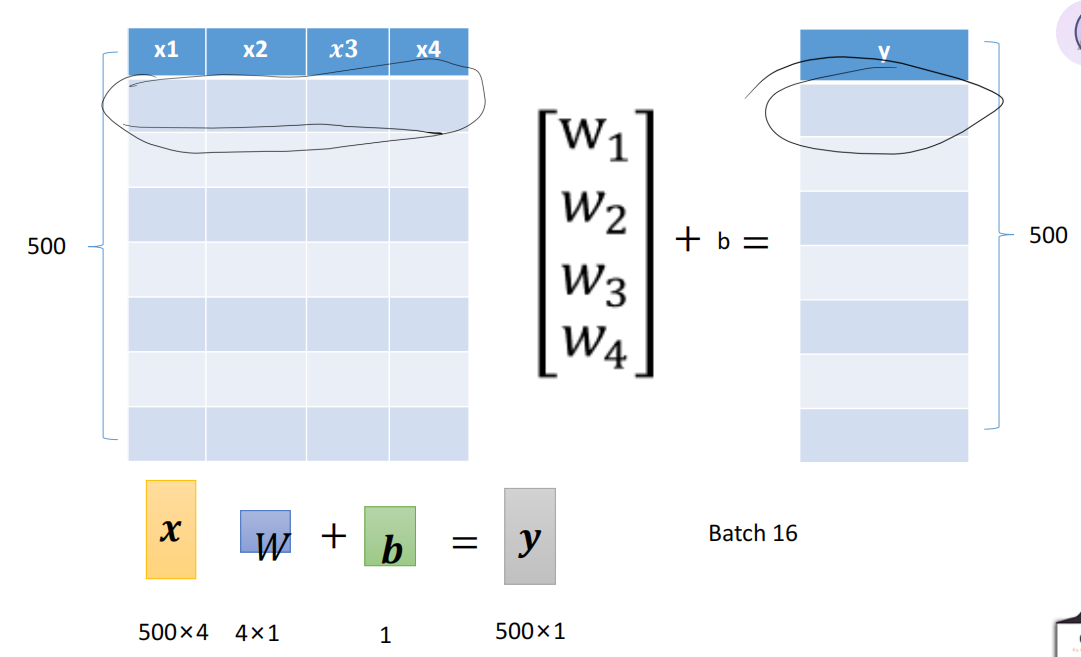
上两节我们学习了理论,接下来让我们基于python来实现一个简单的线性回归,深度学习必须要动手才能理解!就以第一节里面的所提的简单例子为例来实现别忘了我们神经网络的目的是:通过随机生成的参数反求真实的参数。我们往往有很多组输入数据x,而一组输入数据x=[x1,x2,x3,x4]就要与其对应的系数w1,w2,w3,w4相乘,最后加上偏置值b得到一个输出结果y^又我们有多组输入,那么转为矩阵相乘的形式
线性回归代码linear的简单实现
上两节我们学习了理论,接下来让我们基于python来实现一个简单的线性回归,深度学习必须要动手才能理解!
就以第一节里面的所提的简单例子为例来实现
别忘了我们神经网络的目的是:通过随机生成的参数反求真实的参数。
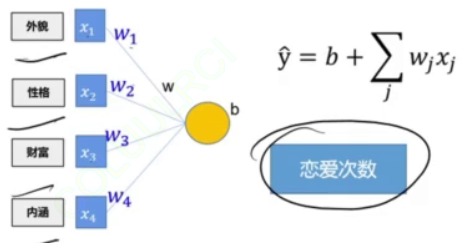
我们往往有很多组输入数据x,而一组输入数据x=[x1,x2,x3,x4]就要与其对应的系数w1,w2,w3,w4相乘,最后加上偏置值b得到一个输出结果y^
又我们有多组输入,那么转为矩阵相乘的形式更直观:
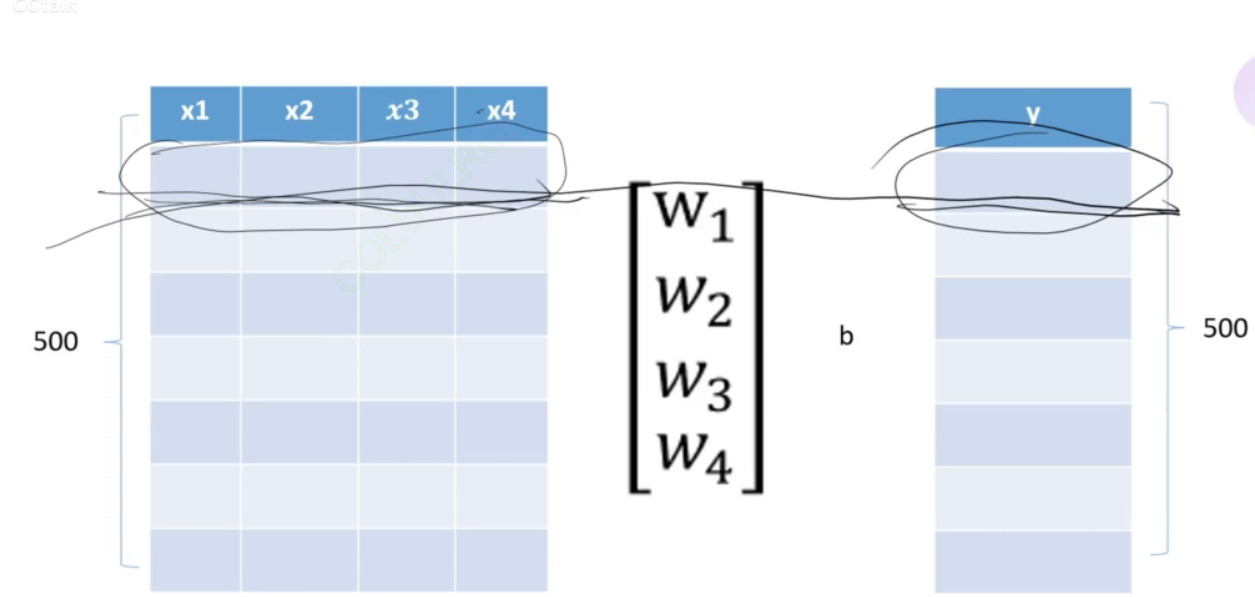
其中一行就代表一组输入
由浅入深,先测试一组数据,看外貌与恋爱次数的关系,假设我们初始设置的参数W与参数B为:(注意这个是真实参数)
true_w = torch.tensor([8.1,2,2,4])
true_b = torch.tensor(1.1)其他先不用看,盯住8.1和1.1,x1为外貌,则y^=w1*x1+b
我们要模拟这个过程需要三种python包,分别为:
import torch
import matplotlib.pyplot as plt #画图包
import randomtorch是我们的深度学习框架
根据我们上面给出的矩阵乘法图得,共有500组数据,则X为500x4的矩阵,W为4x1的向量,B为500x1的向量(这里需要有线性代数的基本知识)
模拟输入和输出的数据,定义一个函数:
def create_data(w,b,data_num):
#torch.normal(mean,std,size) size是维度,包含两个数,具体形式为(长,宽)
x = torch.normal(0,1,(data_num,len(w)))
y = torch.matmul(x,w)+b #matmul表示矩阵乘法
#噪声加到y上
noise = torch.normal(0,0.01,y.shape)
y += noise
return x,y具体的函数功能看我写的注释,值得一提的是模拟的过程必须要加噪声,因为我们实际问题中是一定有噪声的。
normal(期望,方差,维度)是正态分布,维度刚好是500,4即500x4的矩阵捏
随机生成了输入输出数据后,我们用两个变量接受返回值,并给他画出来:
X,Y = create_data(true_w,true_b,num)
plt.scatter(X[:,0],Y,1)
plt.show()结果:
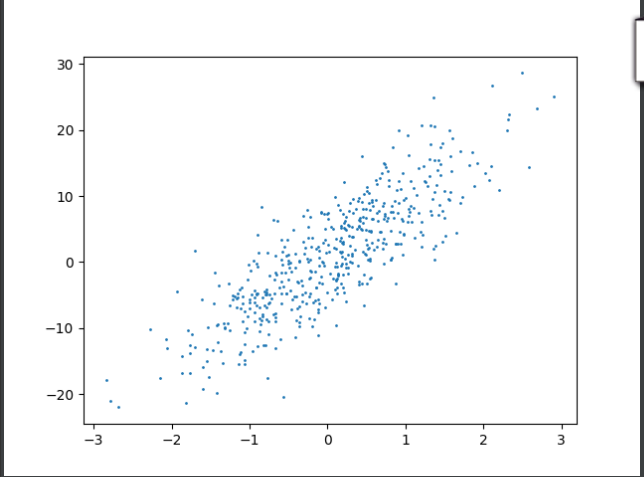
可以看见颜值对恋爱次数的影响基本呈现线性相关,那我们换一个输入类型(性格)试试呢?
修改成
plt.scatter(X[:,1],Y,1) #X是500x4矩阵,Y是500x1向量,只能让X,Y同形才能画图结果:
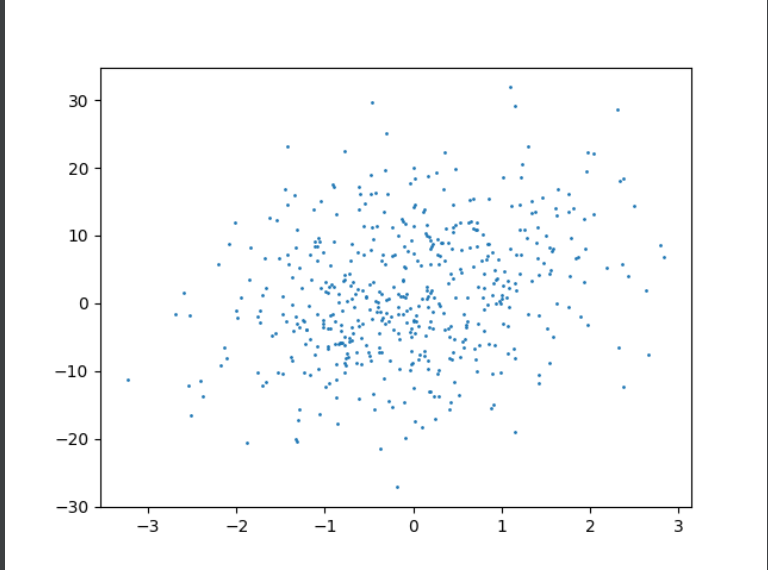
结论:清晰可见系数w最小影响程度越小
有了数据接下来就要模拟整个线性回归的过程了
通过前面两节的学习我们知道,要想通过原数据推测出参数。
一丶首先要建立模型计算得出预测值y^
二丶再设置loss损失函数计算y^与真实数据y的绝对值。
三丶计算得出的损失值L是关于待测两个参数函数,通过将L对w和b求偏导进行梯度回转,找到某一个w和b使得L最小,L越小表示算得的参数越好。
经过不断地迭代,计算出的参数不断逼近真实的参数值。
但是在实际问题中原数据量可能是千千万万的,数量极其庞大,因此我们需要将原数据分批次的进行输入。这才是真的第一步
我们再次把这个图搬出来
初始有500组输入,设置一变量num=500
num = 500接下来分批处理数据,定义一个函数provide
#每次访问这个函数,就提供一批数据
def data_provider(data,label,batchsize):
length = len(label) #获取数据集的长度
indices = list(range(length)) #500变成范围,再化为列表
#以批次获取数据,批次大小为batchsize
#随机打乱数据(符合实际问题)
random.shuffle(indices)
for each in range(0,length,batchsize):
get_indices = indices[each:each+batchsize]
get_data = data[get_indices]
get_label = label[get_indices]
yield get_data,get_label #yield返回一个迭代器,就是有存档点的return,每轮循环返回一次不结束函数
#以16个数据为一批次
batchsize = 16indices是一个列表,存着500个数据的索引值,即0,1,2,3...499
有了这个函数后,我们开始建立模型进行模拟啦!
#定义模型
def fun(x,w,b):
pred_y = torch.matmul(x,w)+b
return pred_y自己定义的模型函数就是原来的线性函数
返回的是y^,也就是预测值
定义损失函数
#定义损失函数
def maeLoss(pre_y,y):
return torch.sum(abs(pre_y-y))/len(y)损失函数参数为预测值y^和真实数据y,返回的是一组数据的的平均损失值
计算出损失值L后,进行梯度回卷,pytorch自动计算最小值
#随机梯度下降,更新参数
def sgd(paras,lr):
with torch.no_grad(): #属于这句代码的部分不需要计算梯度
for para in paras:
para -= lr*para.grad #不能写成para = para-lr*para.grad
para.grad.zero_() #使用过的梯度需要归零注意:每一次梯度计算后需清零,在张量上的梯度是一直值不变的。
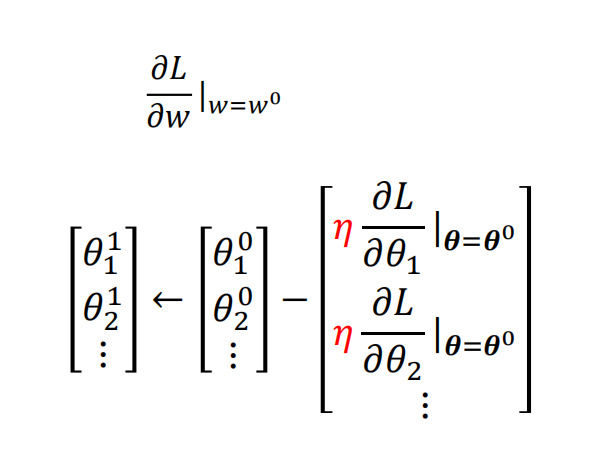
好现在开始迭代,我们初始设置迭代次数为50
#训练
epochs = 50设置学习率和迭代初值
lr = 0.03 #学习率
w_0 = torch.normal(0,0.01,true_w.shape,requires_grad=True) #这个w需要计算梯度
b_0 = torch.tensor(0.01,requires_grad=True)
print(w_0,b_0)进行共计50轮的梯度回转,注意是每轮500个数据,数据总量还是很多的哈
for epoch in range(epochs):
data_loss = 0
for batch_x,batch_y in data_provider(X,Y,batchsize):
pred_y = fun(batch_x,w_0,b_0)
loss = maeLoss(pred_y,batch_y)
loss.backward()#梯度回传
sgd([w_0,b_0],lr)
data_loss += loss
print("epoch %03d:loss:%.6f"%(epoch,data_loss))OK,训练完成,看看最终输出的参数成果和图:
![]()
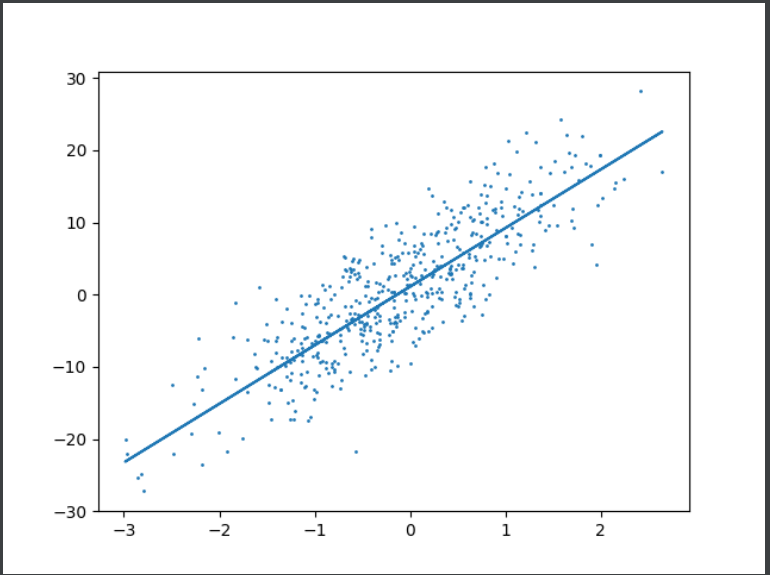
效果非常好!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)