(2025-AAAI-低光图像增强)Zero-Shot Low-Light Image Enhancement via Latent Diffusion Models
本文提出一种基于预训练潜在扩散模型(LDM)的零样本低光图像增强方法。该方法通过LDM提供的自然图像先验,将增强任务转化为潜空间优化问题,无需任务特定训练数据。创新点包括:1) 曝光感知退化模块,利用亮通道自适应建模照明变化;2) 带自适应引导的潜空间正则化方案,平衡输入保真度与自然图像统计特性。实验表明,该方法在真实场景中优于现有零样本方案,解决了传统方法对成对数据的依赖问题,并展现出优异的跨场
(AAAI-2025)Zero-Shot Low-Light Image Enhancement via Latent Diffusion Models
原文
基于潜空间扩散模型的零样本低光图像增强方法研究
代码
https://github.com/Eileen000/LLIEDiff
作者单位:
1 华南理工大学计算机科学与工程学院
2 北京大学计算机学院多媒体信息处理国家重点实验室
3 北京大学计算机学院视觉技术国家工程研究中心
4 琶洲实验室
前驱知识
1) 低照度成像与退化建模(LLIE 的物理/解析基础)
你需要理解:低光图像为什么会暗、噪、偏色、低对比度,以及常见的解析建模思路(例如照明图/曝光因子等)。这篇论文明确把“退化过程”当作关键挑战,并提出曝光感知退化建模,用亮通道(bright channel)表征照明并引入图像自适应曝光因子。
2) 概率图像恢复:先验、似然、后验(MAP / Bayesian)
这篇工作把增强问题写成“逆问题”:
- 先验(prior):自然图像应该长什么样(由预训练 LDM 提供强先验)
- 似然(likelihood)/数据一致性(data consistency):输出退化回去要能解释输入低光图
- 后验(posterior)采样:在先验 + 观测约束下,从后验分布里找解(论文强调“从后验进行原则性采样”可以缓解回归到均值等伪影)。
3) LLIE 方法谱系:监督、无监督、零参考、零样本
你需要知道 LLIE 领域有哪些主流范式、各自依赖什么数据:
- 回归式(学习低光 → 正常光映射)
- 生成式(GAN / Flow 等)
- 扩散式(diffusion-based)
论文在 Related Works 里按这条脉络梳理,并把自己的定位放在“零样本(只用测试图像)”这条线上。
4) 扩散模型基础:DDPM / Score-based / SDE
你需要理解扩散模型的三种等价/近似视角:
- DDPM:前向加噪 + 反向去噪
- NCSN / Score-based:学习 score(对数密度梯度)来生成/去噪
- SDE:用随机微分方程统一描述扩散/反扩散
论文明确把这些当作扩散建模的主流形式。
5) 潜在扩散模型 LDM / Stable Diffusion:VAE 潜空间 + 扩散先验
这篇论文的关键前提是你理解:LDM 不是在像素空间扩散,而是在压缩潜空间扩散;这样既降低计算量,又能捕捉自然图像流形,并能在多种逆问题里“少/免任务训练”发挥作用。
同时要理解“编码器/解码器把 X↔ZX \leftrightarrow ZX↔Z 连起来”这种 VAE 结构(例如 X=D(Z), Z=E(X)X=D(Z),\ Z=E(X)X=D(Z), Z=E(X))。
6) 用生成式先验解逆问题:Guidance + 正则化(Posterior sampling 思想)
你需要理解:把“观测约束”注入扩散采样通常靠 guidance(用梯度引导去噪轨迹),而 guidance 强度过大/过小会带来“保留低光缺陷 vs 内容漂移/细节幻觉”的权衡。论文把这点写得很直白,并提出自适应 guidance scale来动态平衡输入与先验。
同时,论文的“原则性潜空间正则化”本质就是:惩罚那些解码后落在自然图像流形之外的潜变量,确保结果更自然。
Abstract(摘要)
低照度图像增强(Low-Light Image Enhancement, LLIE)旨在提升在弱光条件下采集图像的可见性与信噪比。尽管深度学习方法在该领域已展现出良好潜力,但现有方法通常依赖大量成对训练数据,从而限制了其实用性。本文提出一种新颖框架:利用预训练的潜在扩散模型(Latent Diffusion Models, LDMs)将低照度图像增强重构为零样本推断(zero-shot inference)问题,从而无需任务特定的训练数据。我们的关键洞见在于,LDMs 所编码的丰富自然图像先验能够通过精心设计的优化过程用于恢复正常照度图像。为应对低照度退化问题的病态性(ill-posedness)以及潜空间优化的复杂性,本文框架引入一种曝光感知退化模块(exposure-aware degradation module)以自适应建模照明变化,并提出一种带有自适应引导(adaptive guidance)的原则性潜空间正则化方案(principled latent regularization scheme),以同时保障增强质量与自然图像统计特性。实验结果表明,本文框架在多样化真实场景中优于现有零样本方法。
Introduction(引言)
低照度图像增强(Low-Light Image Enhancement, LLIE)是计算机视觉领域的一项关键挑战,直接影响从自动驾驶导航到医学诊断等多类应用(Li et al. 2022)。该问题的复杂性源于低照度条件下存在非线性退化过程,并由此引发多种相互耦合的困难:严重噪声污染、对比度受损以及显著的颜色失真。这些因素不仅会降低图像的视觉质量,还可能对后续视觉任务带来风险。
传统低光照图像增强(LLIE)方法主要基于解析模型和手工先验(Fu et al., 2016; Guo et al., 2017; Wei et al., 2018; Zhang et al., 2019; Liu et al., 2021b)。虽然这些方法具备理论支撑,但由于难以捕捉自然图像中复杂精细的统计特征,在多样化真实场景中的应用效果存在局限。随着深度学习技术的进步,LLIE 领域取得了显著突破(Chen et al., 2018; Wang et al., 2019; Xu et al., 2020; Yang et al., 2020; Liu et al., 2021b; Liang et al., 2023a),但仍面临两大核心挑战:
- 对大规模成对训练数据的依赖:真实场景下配对数据采集成本高、获取困难。即便无监督方法(Jiang et al., 2021; Guo et al., 2020)减少了配对依赖,仍需要大量未配对数据支撑。
- 跨场景泛化能力不足:在取证、医学等高风险应用中,模型需适应多样照明与场景类型,但有限训练数据难以支撑鲁棒先验学习。
近期,潜空间扩散模型(Latent Diffusion Models, LDMs)(Rombach et al. 2022)的突破为该领域提供了新的方向。这类模型通过扩散过程学习一个压缩的潜空间来表征自然图像流形,从而在避免像素空间高计算开销的同时,获得强大的生成能力。其在多种逆问题中无需针对任务进行训练即可取得良好效果(Chung et al. 2023; Rout et al. 2023),提示其在 LLIE 中同样具有潜力:可利用丰富的已学习先验适应多样照明条件,并提供更具原则性的(principled)不确定性估计。
基于上述观察,本文提出一种新的思路:利用预训练 LDMs 实现零样本(zero-shot)LLIE。该策略具有多方面优势:首先,依托在大规模通用领域数据上学习到的丰富先验,可避免任务特定训练,并有效实现来自基础模型(foundation models)的知识迁移;其次,可复用既有的预训练计算投入;再次,生成模型的概率性质使得能够从后验分布中进行更具理论依据的采样,从而在一定程度上缓解确定性方法中常见的回归到均值(regression-to-mean)伪影。
然而,将 LDMs 适配到零样本 LLIE 仍存在独特技术难点。低照度成像的退化过程包含场景辐射(scene radiance)、传感器特性与噪声源之间复杂且空间变化的交互关系;而在预训练 LDMs 的潜空间中,这些关系会变得更加模糊。此外,在“保留输入图像内容”与“生成自然光照效果输出”之间需要精细平衡:若对输入的引导(guidance)过强,可能保留不希望出现的低照度特征;若引导过弱,则可能导致内容被修改或出现细节幻觉(detail hallucination)。
针对上述挑战,本研究提出以下创新性解决方案:
- 提出基于曝光感知的退化建模模块,通过亮通道表征照明条件,并采用图像自适应的曝光因子精确描述退化过程;
- 设计自适应引导的潜空间正则化方法,通过惩罚偏离自然图像流形的潜变量,在保证增强效果的同时维持图像统计特性。

图1 无监督学习与零样本学习方法在 LLIE 任务上的性能对比: (b) QuadPrior、c) ZeroDEC、(d) ZeroIG、(e) GDP以及 (f) 基于预训练 LDM 的改进方法。
本框架无需任何配对或非配对训练数据,展现出优异的跨场景泛化能力。如图1所示,我们的方法在零样本和零参考场景下均显著优于现有方案。综上所述,本研究首次提出了基于潜在扩散模型(LDMs)的零样本潜在空间扩散低光图像增强框架,主要创新点包括:
- 开发了基于亮通道的自适应曝光退化建模模块,能够根据实际光照条件动态调整处理参数;
- 设计了具有自适应引导机制的潜在空间正则化项,在提升图像质量的同时有效保持了自然图像的统计特性。
Related Work(相关工作)
低照度图像增强(Low-Light Image Enhancement, LLIE)领域已取得显著进展,研究范式也从传统的手工设计方法逐步转向数据驱动的深度学习方法(Li et al. 2022;Liu et al. 2021a)。下文将围绕与本文最相关的深度学习类技术进行综述。
回归式 LLIE 方法(Regression LLIE methods)
基于深度学习的回归方法通常通过学习“低照度图像 → 正常照度图像”的映射来实现增强,做法包括直接利用现有网络结构,或显式融入与问题相关的先验/信息(Guo et al. 2020;Yang et al. 2020;Liang et al. 2021;Zhou et al. 2023)。代表性工作如 HWMNet(Fan, Liu, and Liu 2022)将半小波注意力(half wavelet attention)与 CNN 结合;IAT(Cui et al. 2022)则是在不同光照条件下具备自适应能力的轻量级照明自适应 Transformer(illumination adaptive Transformer)。此外,Retinex 思路也被广泛用于深度学习增强,例如 RUAS(Liu et al. 2021b)、KinD(Zhang, Zhang, and Guo 2019)与 KinD++(Zhang et al. 2021)。这类方法虽在结构恢复与失真度量指标方面表现突出,但往往倾向于生成过度平滑的结果,从而丢失高频细节并削弱感知真实感。
生成式 LLIE 方法(Generative LLIE methods)
生成式方法通常以更强的感知质量见长,且更擅长生成高频细节(Jiang et al. 2021;Zhou, Yang, and Yang 2023;Jiang et al. 2023)。不同方法之间的差异主要体现在所采用的生成模型类型与学习原则上。例如 EnlightenGAN 将注意力机制与图像相关的正则化项结合(Jiang et al. 2021);同时也有工作采用归一化流(normalizing flow)模型,如 LLFlow(Wang et al. 2022)。然而,GAN 体系往往面临训练不稳定与伪影引入等问题,而归一化流模型在表达能力上也存在一定局限。
基于扩散的 LLIE 方法(Diffusion-based LLIE methods)
扩散模型(Diffusion Models, DMs)推动了图像生成的快速发展,其主流建模形式包括:去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPMs)(Ho, Jain, and Abbeel 2020)、随机微分方程(Stochastic Differential Equations, SDE)(Song et al. 2021)以及噪声条件得分网络(Noise Conditional Score Networks, NCSN)(Song and Ermon 2020)。其中,DDPM 通常由“加噪扩散过程”与“去噪反向过程”构成;NCSN 更强调基于得分(score-based)的生成建模以实现去噪与增强;SDE 框架则通过正向/反向 SDE 对上述思想进行统一与推广(Huang, Lim, and Courville 2021)。扩散模型已被用于多种逆问题或恢复任务,如恶劣天气图像复原(Ozdenizci and Legenstein 2023)、阴影去除(Guo et al. 2023)以及低分辨率潜空间扩散(Luo et al. 2023)等。
进一步地,面向 LLIE 的扩散方法通常在反向过程引入噪声估计网络(Yin et al. 2023;Jiang et al. 2023;Zhou, Yang, and Yang 2023)。基础 DDPM(Ho, Jain, and Abbeel 2020)由于缺乏空间自适应能力,可能难以在复杂纹理中保留精细细节。PyDiff(Zhou, Yang, and Yang 2023)通过逐步提升分辨率并进行全局退化校正来增强低照度图像;DiffLL(Jiang et al. 2023)则引入小波变换(wavelet transformation)。此外,还有基于扩散的后处理框架(Panagiotou and Bosman 2023)、融合图像退化与先验的 LLDiffusion(Wang et al. 2023a),以及提供增强与区域级可控性的 CLEDiff(Yin et al. 2023)。同时也存在一种零参考(zero-reference)方法:利用预训练扩散模型,并通过模拟数据对其权重进行微调(Wang et al. 2024)。
方法(Methodology)
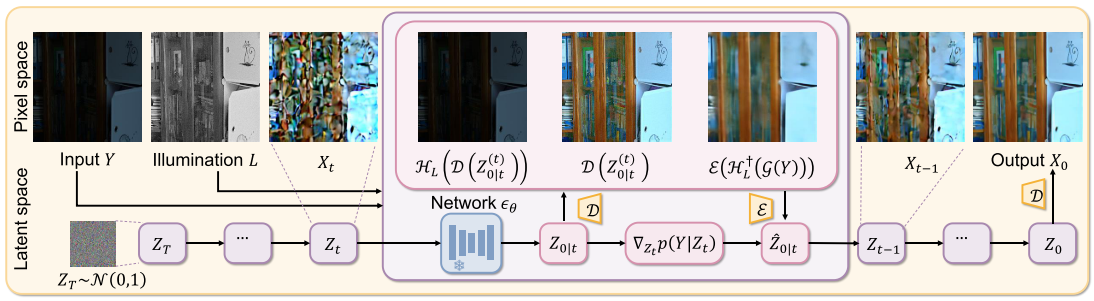
图2 展示了我们提出的零样本学习 LLIE 框架示意图。该框架充分利用了预训练潜在扩散模型(Latent Diffusion Model, LDM)——稳定扩散(Stable Diffusion)(Rombach et al., 2022)的强大图像先验能力。编码器 EEE 和解码器 DDD 构成了隐空间与像素空间之间的桥梁:X=D(Z)X = D(Z)X=D(Z),Z=E(X)Z = E(X)Z=E(X)。我们从纯高斯噪声 ZT∼N(0,I)Z_T \sim \mathcal{N}(0, I)ZT∼N(0,I) 出发,借助预训练神经网络迭代估计目标潜在表示 Z0∣tZ_{0|t}Z0∣t,确保生成结果符合自然图像特征。针对低光输入图像 YYY 及其估计的照明映射 LLL(基于退化模型 HHH 及其逆 H†H^{\dagger}H† 定义),我们在每个时间步 ttt 通过最小化低光图像似然 p(Y∣Zt)p(Y\mid Z_t)p(Y∣Zt) 来保持输入保真度。优化目标包括公式 (18)–(20) 定义的正则化项 LmeasL_{\text{meas}}Lmeas、LinvL_{\text{inv}}Linv 和 LlatentL_{\text{latent}}Llatent,其中引入模糊运算 GGG 以增强低频信息。最终在 t=0t=0t=0 时,通过 X0=D(Z0)X_0 = D(Z_0)X0=D(Z0) 获得增强后的图像。
本节提出一种用于零样本(zero-shot)低照度图像增强的潜空间扩散(latent diffusion)框架,利用在大规模数据上预训练的潜在扩散模型(Latent Diffusion Models, LDMs)作为强先验。整体流程如图2所示。该方法以扩散生成模型的最新进展为基础,尤其依托 Stable Diffusion(Rombach et al., 2022)在多种图像生成任务中展现的强大能力,并针对 LLIE 的特定难点引入若干关键设计。
退化模型(Degradation Model)
给定低照度图像 Y∈RH×W×3Y\in\mathbb{R}^{H\times W\times 3}Y∈RH×W×3,目标是估计其对应的正常照度图像 X∈RH×W×3X\in\mathbb{R}^{H\times W\times 3}X∈RH×W×3。假设低照度退化过程 H(⋅)H(\cdot)H(⋅) 可建模为正常照度图像与照度图(illumination map)L∈RH×WL\in\mathbb{R}^{H\times W}L∈RH×W 的逐元素相乘,并叠加噪声:
Y=H(X)=X⊙Lβ+N,(1) Y = H(X)= X \odot L^{\beta} + N,\qquad (1) Y=H(X)=X⊙Lβ+N,(1)
其中 ⊙\odot⊙ 表示逐元素乘法,β\betaβ 为曝光因子(exposure factor),NNN 表示加性噪声。该退化形式受光照物理过程启发,并在 LLIE 文献中被广泛采用,属于基于 Retinex 模型的一类建模思路;这里 LLL 表示照度图,且对彩色图像假设三个通道共享同一个照度图。
在最大后验(Maximum a Posteriori, MAP)框架下,可写为:
X∗=argmaxXp(X∣Y,L)=argmaxXp(Y,L∣X) p(X),(2) X^{*}=\arg\max_{X} p(X\mid Y,L) = \arg\max_{X} p(Y,L\mid X)\,p(X),\qquad (2) X∗=argXmaxp(X∣Y,L)=argXmaxp(Y,L∣X)p(X),(2)
其中 p(Y,L∣X)p(Y,L\mid X)p(Y,L∣X) 为数据一致性的似然项(likelihood),p(X)p(X)p(X) 为对潜在正常照度图像的先验(prior)。
由于照度图的估计对框架至关重要(其刻画输入图像的低照度条件),本文采用亮通道先验(bright channel prior)来提取照明信息。亮通道定义为每个像素在三个颜色通道上的最大值:
L0(i,j)=maxc∈{R,G,B}Yc(i,j),(3) L_0(i,j)=\max_{c\in\{R,G,B\}} Y^{c}(i,j),\qquad (3) L0(i,j)=c∈{R,G,B}maxYc(i,j),(3)
其中 YcY^{c}Yc 表示低照度图像 YYY 的第 ccc 个颜色通道,(i,j)(i,j)(i,j) 为像素位置。为获得更平滑、空间一致的照度图,对亮通道施加高斯滤波 GGG:
L=G(L0).(4) L = G(L_0).\qquad (4) L=G(L0).(4)
该操作可抑制亮通道中可能存在的高频噪声与伪影,从而得到更可靠的照度估计。
在无噪声假设下,正常照度图像可通过对式(1)的“逆操作” H†H^{\dagger}H† 直接恢复:
Xb=H†(Y)=YLβ.(5) X_b = H^{\dagger}(Y)= \frac{Y}{L^{\beta}}.\qquad (5) Xb=H†(Y)=LβY.(5)
基于潜扩散的后验构建(Posterior Based on Latent Diffusion)
在 Stable Diffusion 等 LDMs 中,扩散过程发生在潜空间(latent space)。像素空间与潜空间通过编码器 E(⋅)E(\cdot)E(⋅) 与解码器 D(⋅)D(\cdot)D(⋅) 相互映射:
X=D(Z),Z=E(X). X=D(Z),\quad Z=E(X). X=D(Z),Z=E(X).
其中 E:RH×W→RkE:\mathbb{R}^{H\times W}\rightarrow\mathbb{R}^{k}E:RH×W→Rk,D:Rk→RH×WD:\mathbb{R}^{k}\rightarrow\mathbb{R}^{H\times W}D:Rk→RH×W。本文关注:如何在式(2)中,利用 LDMs 在潜空间中所建模的自然图像先验 p(Z)p(Z)p(Z),来构造对应的后验分布。
从基于 score 的视角,数据 ZtZ_tZt(t∈[0,T]t\in[0,T]t∈[0,T])的前向扩散过程可由线性随机微分方程(Stochastic Differential Equation, SDE)表示:
dZ=−f(Z,t) dt+g(t) dw,(6) dZ = -f(Z,t)\,dt + g(t)\,dw,\qquad (6) dZ=−f(Z,t)dt+g(t)dw,(6)
其中 www 为标准布朗运动。采样时从高斯噪声 ZT∼N(0,I)Z_T\sim\mathcal{N}(0,I)ZT∼N(0,I) 出发,运行反向扩散过程,并在最终通过解码器 DDD 得到正常照度图像 X0X_0X0。其对应的反向 SDE 为:
dZ=[−f(Z,t)−g2(t)∇Ztlogpt(Zt)]dt+g(t) dw,(7) dZ=\big[-f(Z,t)-g^2(t)\nabla_{Z_t}\log p_t(Z_t)\big]dt+g(t)\,dw,\qquad (7) dZ=[−f(Z,t)−g2(t)∇Ztlogpt(Zt)]dt+g(t)dw,(7)
其中 ∇Ztlogpt(Zt)\nabla_{Z_t}\log p_t(Z_t)∇Ztlogpt(Zt) 为随时间变化的 score 函数,通常通过去噪 score 匹配(denoising score matching)训练得到:
minθ Et,Zt,Z0[∥ϵθ(Zt,t)−∇Ztlogp(Zt∣Z0)∥22].(8) \min_{\theta}\ \mathbb{E}_{t,Z_t,Z_0}\Big[\big\|\epsilon_{\theta}(Z_t,t)-\nabla_{Z_t}\log p(Z_t\mid Z_0)\big\|_2^2\Big].\qquad (8) θmin Et,Zt,Z0[ ϵθ(Zt,t)−∇Ztlogp(Zt∣Z0) 22].(8)
训练获得 θ∗\theta^{*}θ∗ 后,可用 ϵθ∗(Zt,t)\epsilon_{\theta^{*}}(Z_t,t)ϵθ∗(Zt,t) 近似 ∇Ztlogpt(Zt)\nabla_{Z_t}\log p_t(Z_t)∇Ztlogpt(Zt),并通过离散化求解(如 DDPM 的 ancestral sampling)实现从先验 p(Z0)p(Z_0)p(Z0) 的采样。
进一步地,若低照度图像 YYY 由正常照度潜变量 Z0Z_0Z0 通过式(1)生成,则目标是从后验 p(Z0∣Y)p(Z_0\mid Y)p(Z0∣Y) 进行采样。为此,可在反向 SDE 中加入与观测一致性的项 ∇Ztlogp(Y∣Zt)\nabla_{Z_t}\log p(Y\mid Z_t)∇Ztlogp(Y∣Zt):
dZ=[−f(Z,t)−g2(t)(∇Ztlogp(Zt)+∇Ztlogp(Y∣Zt))]dt+g(t) dw,(9) dZ=\big[-f(Z,t)-g^2(t)\big(\nabla_{Z_t}\log p(Z_t)+\nabla_{Z_t}\log p(Y\mid Z_t)\big)\big]dt+g(t)\,dw,\qquad (9) dZ=[−f(Z,t)−g2(t)(∇Ztlogp(Zt)+∇Ztlogp(Y∣Zt))]dt+g(t)dw,(9)
并利用贝叶斯公式得到:
∇Ztlogpt(Zt∣Y)=∇Ztlogp(Zt)+∇Ztlogp(Y∣Zt).(10) \nabla_{Z_t}\log p_t(Z_t\mid Y)=\nabla_{Z_t}\log p(Z_t)+\nabla_{Z_t}\log p(Y\mid Z_t).\qquad (10) ∇Ztlogpt(Zt∣Y)=∇Ztlogp(Zt)+∇Ztlogp(Y∣Zt).(10)
其中第一项可直接由预训练的 score 网络给出;第二项衡量当前迭代对观测低照度图像 YYY 的解释程度,但由于其对时间 ttt 的依赖且只与 D(Z0)D(Z_0)D(Z0) 存在显式联系,因此难以闭式求解。文中将其写为:
p(Y∣Zt)=∫p(Y∣Z0,Zt) p(Z0∣Zt) dZ0=∫p(Y∣Z0) p(Z0∣Zt) dZ0.(11) p(Y\mid Z_t)=\int p(Y\mid Z_0,Z_t)\,p(Z_0\mid Z_t)\,dZ_0 =\int p(Y\mid Z_0)\,p(Z_0\mid Z_t)\,dZ_0.\qquad (11) p(Y∣Zt)=∫p(Y∣Z0,Zt)p(Z0∣Zt)dZ0=∫p(Y∣Z0)p(Z0∣Zt)dZ0.(11)
对 DDPM/VP-SDE 等情形,前向扩散可写为:
Zt=αˉt Z0+1−αˉt z,z∼N(0,I).(12) Z_t=\sqrt{\bar{\alpha}_t}\,Z_0+\sqrt{1-\bar{\alpha}_t}\,z,\quad z\sim\mathcal{N}(0,I).\qquad (12) Zt=αˉtZ0+1−αˉtz,z∼N(0,I).(12)
据此可用 Tweedie 方法得到后验均值的特化表达:
Z0∣t=E[Z0∣Zt]=1αˉt(Zt+(1−αˉt)∇Ztlogpt(Zt)),(13) Z_{0\mid t}=\mathbb{E}[Z_0\mid Z_t] =\frac{1}{\sqrt{\bar{\alpha}_t}}\Big(Z_t+(1-\bar{\alpha}_t)\nabla_{Z_t}\log p_t(Z_t)\Big),\qquad (13) Z0∣t=E[Z0∣Zt]=αˉt1(Zt+(1−αˉt)∇Ztlogpt(Zt)),(13)
并以 ϵθ∗(Zt)\epsilon_{\theta^{*}}(Z_t)ϵθ∗(Zt) 近似其中的 score 项。基于可高效计算的中间估计 Z0∣tZ_{0\mid t}Z0∣t,本文采用 Chung et al. (2023) 的近似,使 p(Y∣Zt)p(Y\mid Z_t)p(Y∣Zt) 变得可处理:
p(Y∣Zt)≈p(Y∣Z0∣t:=D(E[Z0∣Zt]))=p(Y∣D(Z0∣t)⊙Lβ).(14) p(Y\mid Z_t)\approx p\big(Y\mid Z_{0\mid t}:=D(\mathbb{E}[Z_0\mid Z_t])\big) = p\big(Y\mid D(Z_{0\mid t})\odot L^{\beta}\big).\qquad (14) p(Y∣Zt)≈p(Y∣Z0∣t:=D(E[Z0∣Zt]))=p(Y∣D(Z0∣t)⊙Lβ).(14)
该近似本质上以 E[Z0∣Zt]\mathbb{E}[Z_0\mid Z_t]E[Z0∣Zt] 替代未知的 Z0Z_0Z0,从而将观测一致性项转化为可优化的形式。
低照度图像似然与潜空间正则(Low-light Image Likelihood)
在概率建模中,若噪声 NNN 服从标准差为 σ\sigmaσ 的高斯分布,则在式(14)下最大化观测低照度图像 YYY 的似然,可等价为最小化:
L=1σ2∥Y−D(Z0∣t)⊙Lβ∥22.(15) \mathcal{L}=\frac{1}{\sigma^{2}}\big\|Y-D(Z_{0\mid t})\odot L^{\beta}\big\|_2^{2}.\qquad (15) L=σ21 Y−D(Z0∣t)⊙Lβ 22.(15)
将 score 函数代入式(10)可得带引导(guidance)的后验 score:
∇Ztlogpt(Zt∣Y)=ϵθ∗(Zt,t)−s ∇ZtL,(16) \nabla_{Z_t}\log p_t(Z_t\mid Y)=\epsilon_{\theta^{*}}(Z_t,t)-s\,\nabla_{Z_t}\mathcal{L},\qquad (16) ∇Ztlogpt(Zt∣Y)=ϵθ∗(Zt,t)−s∇ZtL,(16)
其中 sss 表示由观测 YYY 引入的引导强度(guidance scale)。
为在预训练 LDM 的潜空间中施加有效约束,本文进一步提出潜空间正则项,引导扩散过程趋向既能解释测量(measurement)又能保持在“数据流形”(data manifold)上的潜变量,并要求其满足解码器—编码器复合映射的固定点性质(decoder-encoder composition 的 fixed points)。总体目标定义为:
L=1σp2Lmeas+1σi2Linv+1σl2Llatent+1σc2Lcol,(17) \mathcal{L}=\frac{1}{\sigma_p^{2}}\mathcal{L}_{\text{meas}} +\frac{1}{\sigma_i^{2}}\mathcal{L}_{\text{inv}} +\frac{1}{\sigma_l^{2}}\mathcal{L}_{\text{latent}} +\frac{1}{\sigma_c^{2}}\mathcal{L}_{\text{col}},\qquad (17) L=σp21Lmeas+σi21Linv+σl21Llatent+σc21Lcol,(17)
其中 σ\sigmaσ 系列为平衡各项权重的尺度因子(scalers)。各项分别为:
Lmeas=∥Y−D(Z0∣t)⊙Lβ∥22,(18) \mathcal{L}_{\text{meas}}=\big\|Y-D(Z_{0\mid t})\odot L^{\beta}\big\|_2^{2},\qquad (18) Lmeas= Y−D(Z0∣t)⊙Lβ 22,(18)
Linv=∥YLβ−D(Z0∣t)∥22,(19) \mathcal{L}_{\text{inv}}=\big\|\frac{Y}{L^{\beta}}-D(Z_{0\mid t})\big\|_2^{2},\qquad (19) Linv= LβY−D(Z0∣t) 22,(19)
Llatent=∥E(G(YLβ))−Z0∣t∥22,(20) \mathcal{L}_{\text{latent}}=\big\|E\big(G(\frac{Y}{L^{\beta}})\big)-Z_{0\mid t}\big\|_2^{2},\qquad (20) Llatent= E(G(LβY))−Z0∣t 22,(20)
其中 GGG 为模糊/低通操作(用于强调低频信息)。上述正则从不同侧面约束解的搜索空间;在 LLIE 场景中,由于潜空间的不确定性更强,若缺乏约束易产生伪影或不自然结果,引入这些项可有效提升增强图像的整体质量与自然性。
此外,为在采样过程中保持颜色通道间的内在一致性、避免色偏,文中引入通道一致性损失:
Lcol=∑∀(p,q)∈Ω(D(Z0∣t)p−D(Z0∣t)q)2,(21) \mathcal{L}_{\text{col}}=\sum_{\forall (p,q)\in\Omega}\Big(D(Z_{0\mid t})_{p}-D(Z_{0\mid t})_{q}\Big)^{2},\qquad (21) Lcol=∀(p,q)∈Ω∑(D(Z0∣t)p−D(Z0∣t)q)2,(21)
其中 (p,q)(p,q)(p,q) 为从 Ω={(R,G),(R,B),(G,B)}\Omega=\{(R,G),(R,B),(G,B)\}Ω={(R,G),(R,B),(G,B)} 采样得到的通道对,D(Z0∣t)pD(Z_{0\mid t})_{p}D(Z0∣t)p 表示解码结果中第 ppp 个通道的像素值。
自适应引导尺度(Adaptive Guidance Scale)
采样过程中观察到:式(16)中的最优引导强度 sss 会随图像内容及优化状态变化而变化。因此,本文提出自适应引导尺度,在去噪过程中动态调节来自低照度观测 YYY 的引导强度。其思想是基于潜空间中当前估计与前一次估计的距离来调节引导力度,定义:
st=∥Zt−Zt−1∥22(∇ZtL−∇Zt−1L)⊤(Zt−Zt−1),(22) s_t=\frac{\|Z_t-Z_{t-1}\|_2^{2}}{\big(\nabla_{Z_t}\mathcal{L}-\nabla_{Z_{t-1}}\mathcal{L}\big)^{\top}(Z_t-Z_{t-1})},\qquad (22) st=(∇ZtL−∇Zt−1L)⊤(Zt−Zt−1)∥Zt−Zt−1∥22,(22)
该自适应机制在“观测一致性”(来自 YYY 的约束)与“扩散模型先验”(自然图像统计)之间实现动态平衡,从而更稳健地应对多样的低照度条件与图像内容,获得更具视觉吸引力的增强结果。
Experiments(实验)
Experimental Settings(实验设置)
Datasets(数据集) 我们在两个广泛使用、包含成对低照度图像与正常照度图像的数据集上开展实验:LOL-v1(Wei et al., 2018)与 LOL-v2(Yang et al., 2020)。此外,我们也在无真值(ground truth)的数据集上给出可视化对比结果,包括 DICM(Lee, Lee, and Kim, 2013)、MEF(Ma, Zeng, and Wang, 2015)、NPE(Wang et al., 2013)以及 LIME(Guo, Li, and Ling, 2017),相关内容见补充材料。
Metrics(评价指标) 我们采用多种指标对各方法性能进行评估,包括:峰值信噪比 PSNR(Peak Signal-to-Noise Ratio)、结构相似性指数 SSIM(Structural Similarity Index Measure),以及学习感知图像块相似度 LPIPS(Learned Perceptual Image Patch Similarity)。
Implementation Details(实现细节) 我们的方法基于 PyTorch 实现,并在单张 NVIDIA GTX 3090 Ti GPU 上运行。在所有实验中,采用 DDIM sampling(Song, Meng, and Ermon, 2020),并设置扩散步数 T=1000T = 1000T=1000。为在退化模型中进一步增强局部对比度,我们在每个像素 iii 处基于照明图 LLL 采用像素级曝光参数 β(i)\beta(i)β(i)(自适应于 L(i)L(i)L(i)),其中超参数 ϕ=0.3\phi = 0.3ϕ=0.3。对式(4)中亮通道(bright channel)所施加的高斯模糊滤波器 GGG 使用 5×55\times55×5 的卷积核,标准差为 1.5。针对输入分辨率与预训练模型训练分辨率不一致的问题,我们采用 Wang et al. (2023b) 提出的方法进行处理。
Comparison with State-of-the-Art Methods(与最新方法对比)
我们在 LOL-v1 与 LOL-v2 数据集上,将所提出的方法与多类代表性 LLIE 方法进行对比:包括 8 种**有监督(supervised)方法(KinD、DRBN、KinD++、RetinexNet、URetinexNet、SNR-Aware、DiffLL、GSAD),4 种无配对学习(unpaired learning)方法(EnlightenGAN、PairLIE、NeRCo、CLIP-LIT),4 种零参考(zero-reference)**方法(Zero-DCE、RUAS、SCI、QuadPrior),以及零样本方法(ExCNet、GDP、ZeroIG)。
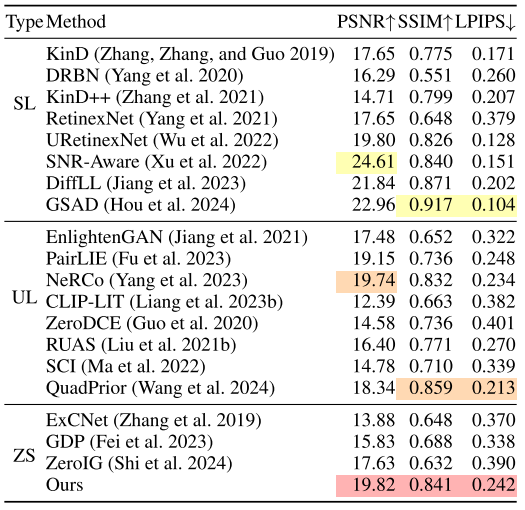
表1:Wei 等人(2018)提出的最新方法在真实数据集上的比较。黄色、橙色和红色高亮分别表示在基于该数据集的有监督学习(SL、无监督学习(UL)以及仅从输入测试图像学习的零样本学习(ZS)方法中表现最优的方法。↑(↓)表示数值越高(越低)越好。
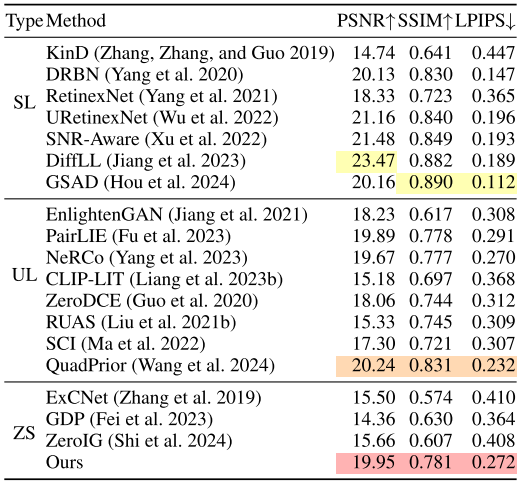
表2:Yang et al. 2020提出的在真实数据集上的弱光增强性能评估。
定量结果如 Table 1 与 Table 2 所示:我们的方法在两个数据集上均表现出更优的综合性能。以 LOL-v1 测试集为例,在 PSNR/SSIM/LPIPS 三项指标上均显著优于现有零样本方案;与无配对训练和零参考方法相比,我们取得更高的 PSNR,并在 SSIM 与 LPIPS 上也具有竞争力,甚至达到部分有监督方法的性能水平。我们在 SSIM 与 LPIPS 上未能超过当前最佳有监督方法,原因在于有监督方法通常能通过成对训练集学习到数据分布偏置(distribution bias)。在 LOL-v2 测试集上,我们的方法同样在三项指标上显著优于其他零样本技术,其中 SSIM 甚至超过部分无配对学习方法,表明该方法能够生成高质量图像并有效应对真实场景。

我们在 Figure 3 与 Figure 4 中给出了与竞争方法在成对数据集上的可视化对比。可以观察到,以往方法常出现噪声放大、曝光不足/过曝或颜色失真等问题;相比之下,我们的方法能够抑制噪声、重建纹理细节并生成光照更自然的增强结果。例如在 Figure 3 中,我们的方法不仅能增强红框内物体的标识可见性,还能有效去噪并恢复纹理细节;同时,在 Figure 4 中蓝框区域的结果更接近 Ground Truth,体现出在颜色偏移(color shifts)处理上的有效性。总体而言,该方法能显著提升暗区可见性,并在视觉效果上接近有监督方法。
Ablation Study(消融实验)
我们在 LOL-v1 数据集上进行消融实验以验证主要贡献的有效性。本节所有实验均将输入分辨率设为 256×256256\times256256×256 以加速采样过程;并注意在这些实验中 不包含 LcolL_{col}Lcol。
Regularization term in the latent space(潜空间正则项)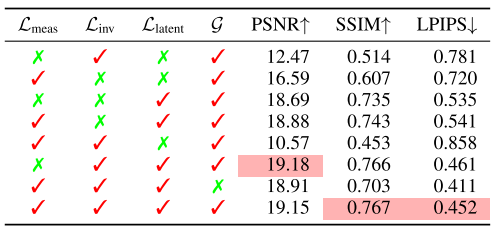
表3:正则化项的消融研究。红色高亮表示最佳性能设置。
图5:在不同正则项设置下生成结果的对比。(a) 输入图像。(b) 真实图像(Ground Truth)。c) 我们的方法。(d) 使用 LmeasL_{\text{meas}}Lmeas。(e) 使用 LinvL_{\text{inv}}Linv。(f) 使用 LlatentL_{\text{latent}}Llatent。(g) 去除 LmeasL_{\text{meas}}Lmeas(w/o LmeasL_{\text{meas}}Lmeas)。(h) 去除 LinvL_{\text{inv}}Linv(w/o LinvL_{\text{inv}}Linv)。(i) 去除 LlatentL_{\text{latent}}Llatent(w/o LlatentL_{\text{latent}}Llatent)。
通过将完整模型与去除正则项的变体对比,我们分析其对结果自然性(naturalness)维持的作用。Table 3 的结果表明,正则项有助于保持增强结果的自然外观并减少伪影。结合 Figure 5 可见:仅使用 LmeasL_{meas}Lmeas 虽可将低照度图像“推向”非低照度外观,但会以牺牲图像内容为代价;LinvL_{inv}Linv 与 LlatentL_{latent}Llatent 能增强纹理细节(红框区域可见),但两两组合仍非最优;当三项同时使用时,细节进一步丰富(例如绿框区域能正确生成褶皱),从而凸显在潜空间中施加先验分布约束的重要性。进一步地,Table 3 最后两行显示:在 LlatentL_{latent}Llatent 中引入低频提取算子 GGG 可带来显著提升,验证其能够在适当保留纹理的同时有效去除噪声。
Adaptive guidance scale(自适应引导尺度)
图6:在不同引导尺度设置下生成结果的对比。(a) 采用常量引导尺度(st=0.7s_t = 0.7st=0.7)。(b) 采用自适应引导尺度(adaptive guidance scale)。© 真实图像(Ground Truth)。
我们考察自适应引导尺度对扩散去噪过程中“受引导的低照度信息”与先验之间平衡的影响。Figure 6 的可视化结果表明,自适应引导尺度能够生成更清晰的边缘与更接近 Ground Truth 的颜色,说明该机制有助于在不同噪声与失真程度下获得更稳健的增强结果。
Bright channel for degradation modeling(用于退化建模的亮通道)
图7:采用不同退化模型生成结果的对比。(a) 使用由伽马校正定义的退化模型(γ=0.7\gamma = 0.7γ=0.7)。(b) 使用由亮通道(bright channel)定义的本文退化模型。(c 真实图像(Ground Truth)。
我们评估以亮通道(bright channel)刻画低照度退化过程的效果。如 Figure 7 所示,采用亮通道先验后,红框处碗的边缘以及绿框处柜体角落更为清晰,说明该方式能够更有效地处理局部区域;相较之下,使用常量照明值会导致对比度信息丢失。该结果表明,在亮度域中显式建模退化过程对于有效的低照度图像增强具有重要意义。
Conclusion(结论)
本文提出了首个零样本(zero-shot)框架,利用预训练潜在扩散模型(pre-trained Latent Diffusion Models, LDMs)作为强大的图像先验(image priors),从而无需任务特定的训练数据(task-specific training data)或对网络结构进行修改(architectural modifications)。本文的关键技术创新——曝光自适应亮通道先验(exposure-adaptive bright channel prior)以及结合自适应引导(adaptive guidance)的原则性潜空间正则化(principled latent space regularization)——有效解决了在增强任务中利用生成式先验(generative priors)所面临的核心挑战。通过在具有挑战性的真实世界数据集上开展大量实验,我们证明该方法不仅优于现有零样本方法,同时在多样化照明条件下展现出更强的泛化能力。
下面我用“这篇 LLIE + LDM 的方法”为主线,把**先验(prior)和后验(posterior)**讲清楚:它们分别表示什么、为什么需要、在文中具体对应哪一项、以及直观例子。
知识基础–先验,似然与后验(选读)
1) 先验(Prior)是什么?
一句话:先验就是“在看到你的低光输入 YYY 之前,我认为正常图像 XXX(或潜变量 ZZZ)应该长什么样”的偏好/知识。
在论文里,作者把要恢复的正常照度图像记为 XXX(或其潜空间表示 ZZZ)。
那么先验通常写成:
- 图像先验:p(X)p(X)p(X) —— “自然、正常曝光的照片”更可能出现的分布
- 潜空间先验:p(Z)p(Z)p(Z) —— LDM 在潜空间学到的“自然图像潜变量”分布
直观理解
如果只给你一个很暗很噪的图,能解释它的“正常图像”其实有无数种。
先验就像一个审美/常识过滤器:更倾向于选择“看起来像真实照片”的那一类解,而不是奇怪的、带伪影的解。
在本文中:先验来自哪里?
来自 预训练潜空间扩散模型(LDM / Stable Diffusion)。
扩散模型在大规模数据上训练,本质上学到了“自然图像长什么样”的统计规律,所以它提供了一个非常强的先验。
2) 似然(Likelihood)是什么?
你提的是先验/后验,但中间必须有“似然”,否则后验没法理解。
一句话:似然表示“如果真实正常图像是 XXX,那么在退化模型作用下观测到当前低光图 YYY 的概率有多大”。
写成:
- p(Y∣X)p(Y \mid X)p(Y∣X)
- 或在潜空间里(通过解码)写成:p(Y∣Z)p(Y \mid Z)p(Y∣Z)
在本文中:似然对应什么?
对应作者的退化模型(degradation model):
Y=X⊙Lβ+N Y = X \odot L^{\beta} + N Y=X⊙Lβ+N
给定一个候选正常图像 XXX,把它“加上低光退化”应该能逼近你观察到的 YYY。
如果逼近得好,说明这个 XXX 对 YYY 的解释强,似然就大。
论文里把它转成了一个“数据一致性损失”(比如 LmeasL_{meas}Lmeas 这种),本质就是在最大化似然或最小化负对数似然。
3) 后验(Posterior)是什么?
一句话:后验就是“看到你的低光输入 YYY 之后,我对正常图像 XXX(或潜变量 ZZZ)的更新后的相信程度”。
写成:
- p(X∣Y)p(X \mid Y)p(X∣Y)
- 或 p(Z∣Y)p(Z \mid Y)p(Z∣Y)
它同时考虑两件事:
- 先验:解要像自然图像(自然照片的统计规律)
- 似然:解退化后要能解释你的输入 YYY
两者通过贝叶斯公式连接:
p(X∣Y)∝p(Y∣X) p(X) p(X\mid Y) \propto p(Y\mid X)\,p(X) p(X∣Y)∝p(Y∣X)p(X)
在潜空间同理:
p(Z∣Y)∝p(Y∣Z) p(Z) p(Z\mid Y) \propto p(Y\mid Z)\,p(Z) p(Z∣Y)∝p(Y∣Z)p(Z)
4) 为什么后验很重要?(直觉:解决“不适定”)
低光增强是典型不适定(ill-posed):同一个 YYY 可能对应很多 XXX。
- 只看似然:能找到很多 XXX 让退化后接近 YYY,但可能出现奇怪颜色、伪影、过曝等(因为它没被“自然性”约束)
- 只看先验:可能生成一张“自然照片”,但与输入内容不一致(内容漂移、细节幻觉)
后验 = 把二者平衡起来:既自然,又忠实输入。
5) 在这篇论文里,先验/后验具体对应到哪些操作?
(A) 先验 p(Z)p(Z)p(Z) —— 扩散模型的 score
扩散模型通过 score(梯度)来表达先验方向:
∇Ztlogpt(Zt) \nabla_{Z_t}\log p_t(Z_t) ∇Ztlogpt(Zt)
它告诉你:“在当前噪声层级 ttt 下,怎样移动 ZtZ_tZt 才更像来自自然图像分布”。
这就是**“往自然图像流形靠拢”**的力。
(B) 似然 p(Y∣Z)p(Y\mid Z)p(Y∣Z) —— 数据一致性项(measurement consistency)
作者把 p(Y∣Zt)p(Y\mid Z_t)p(Y∣Zt) 近似成可优化形式,并最终变成损失项(如 LmeasL_{meas}Lmeas、LinvL_{inv}Linv 等),其梯度:
∇Ztlogp(Y∣Zt)≈−∇ZtL \nabla_{Z_t}\log p(Y\mid Z_t) \approx -\nabla_{Z_t}\mathcal{L} ∇Ztlogp(Y∣Zt)≈−∇ZtL
表示“让解码后的结果退化回去能贴合输入 YYY”。
这就是“忠实输入”的力。
C) 后验 score = 先验 score + 似然项
论文用的核心式子就是:
∇Ztlogp(Zt∣Y)=∗∇Ztlogp(Zt)+∇Ztlogp(Y∣Zt) \nabla_{Z_t}\log p(Z_t\mid Y) =* \nabla_{Z_t}\log p(Z_t) + \nabla_{Z_t}\log p(Y\mid Z_t) ∇Ztlogp(Zt∣Y)=∗∇Ztlogp(Zt)+∇Ztlogp(Y∣Zt)
等价于:去噪时同时被两股力量引导。
实现上常写成类似:
posterior score≈ϵθ∗(Zt,t)−s ∇ZtL \text{posterior score} \approx \epsilon_{\theta^*}(Z_t,t) - s\,\nabla_{Z_t}\mathcal{L} posterior score≈ϵθ∗(Zt,t)−s∇ZtL
其中 sss 是 guidance scale:控制“听输入 YYY” vs “听先验”的权重。
作者还做了 adaptive guidance:让 sss 随步数/状态自适应变化,避免过强导致保留低光缺陷、过弱导致内容漂移。
6) 一个非常直观的小例子
你有一张很暗的夜景照片 YYY。
- 只用先验:扩散模型可能生成一张“很自然的白天街景”,但街道结构、车的位置可能变了(内容不一致)
- 只用似然:把亮度硬拉上去,虽然和输入像素关系很一致,但噪声被放大、颜色偏绿、细节糊(不自然)
- 用后验:既保持街道和车的位置(由似然约束),又让增强后的图像像真实曝光(由先验约束)
7) 一句话总结(便于记忆)
- 先验 p(X)p(X)p(X) / p(Z)p(Z)p(Z):自然图像应当是什么样(“自然性”)
- 似然 p(Y∣X)p(Y|X)p(Y∣X) / p(Y∣Z)p(Y|Z)p(Y∣Z):候选解能不能解释输入低光图(“一致性”)
- 后验 p(X∣Y)p(X|Y)p(X∣Y) / p(Z∣Y)p(Z|Y)p(Z∣Y):看到输入后,最可信的解分布(“自然性 + 一致性”平衡)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)