Python 交通标志检测识别系统:深度学习 YOLOv8 算法 + PyQt5 界面 + OpenCV 大数据实战(毕设版・建议收藏)✅
Python 交通标志检测识别系统:深度学习 YOLOv8 算法 + PyQt5 界面 + OpenCV 大数据实战(毕设版・建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈:
Python语言、YOLOv8算法、PyQt5界面设计、OpenCV、保存数据、导出数据
数据集(20G):
数据集总共包含以下类别,且已经分好 train、val、test文件夹,也提供转好的yolo格式的标注文件,可以直接使用。总共有9千多张数据集,161种类别,基本上包含了遇到的绝大部分交通标志的类别了。
2、项目界面
(1)上传图片检测识别----限速30
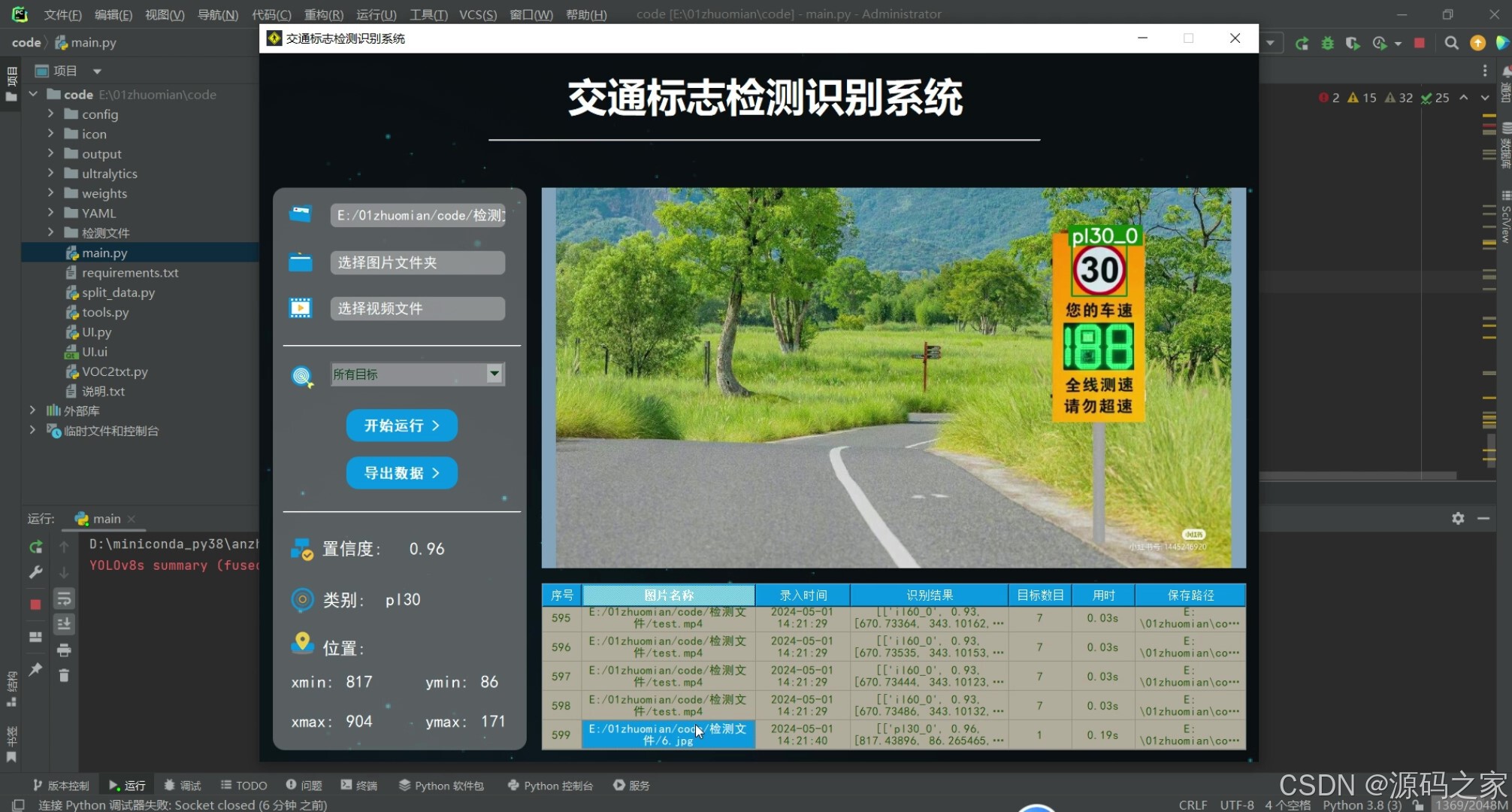
(2)上传图片检测识别----限速50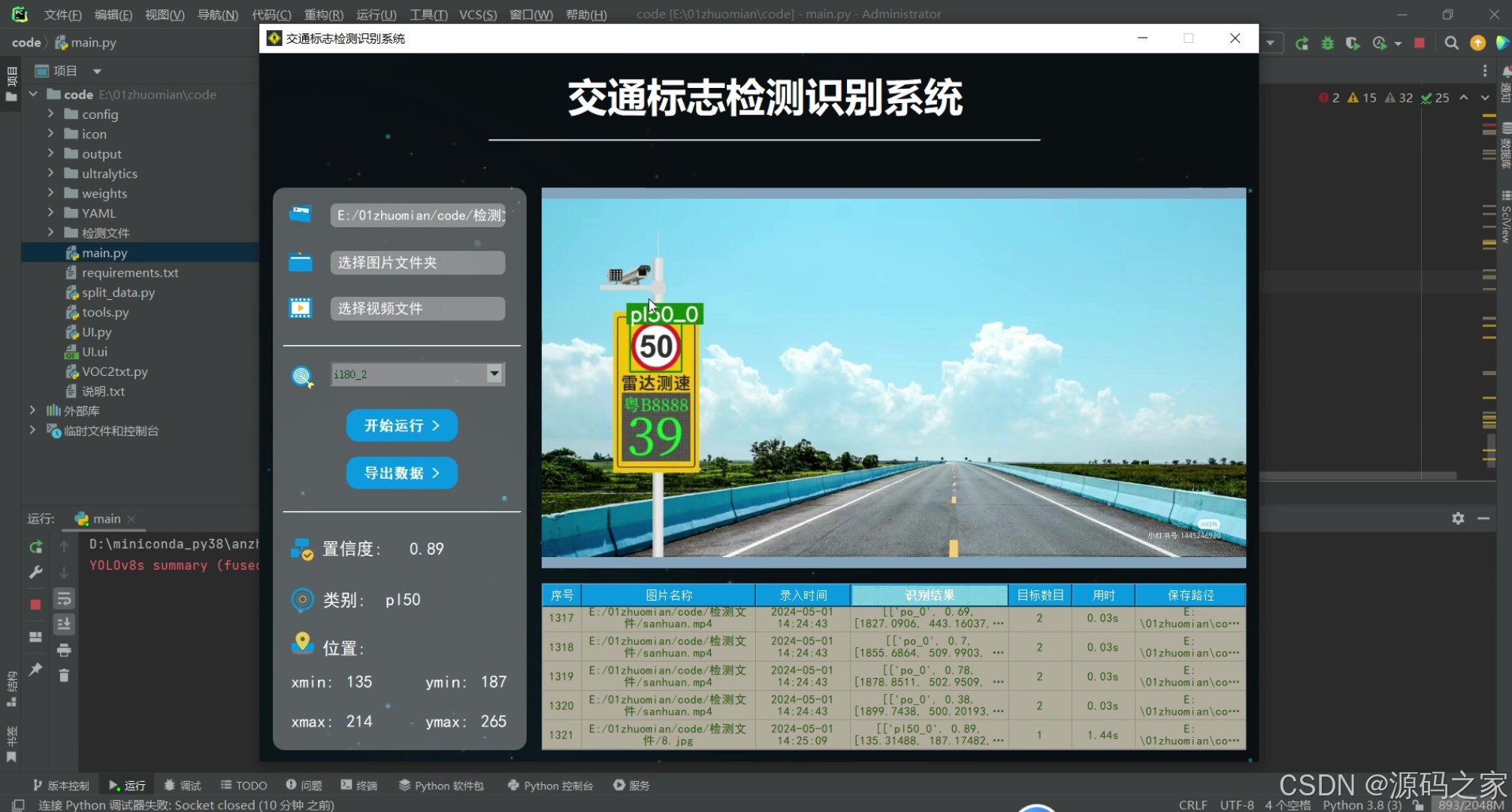
(3)上传视频检测识别
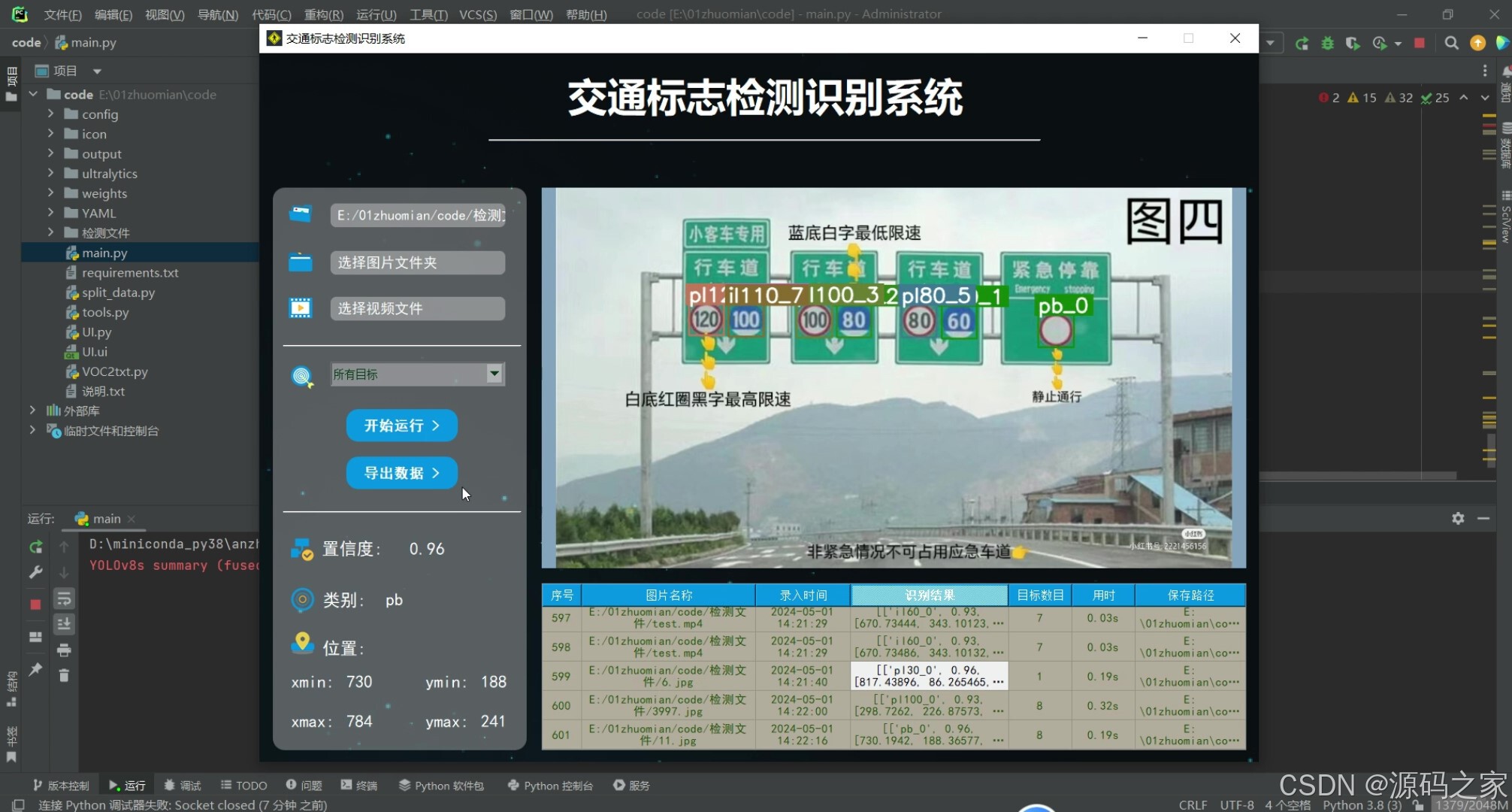
(4)上传视频检测识别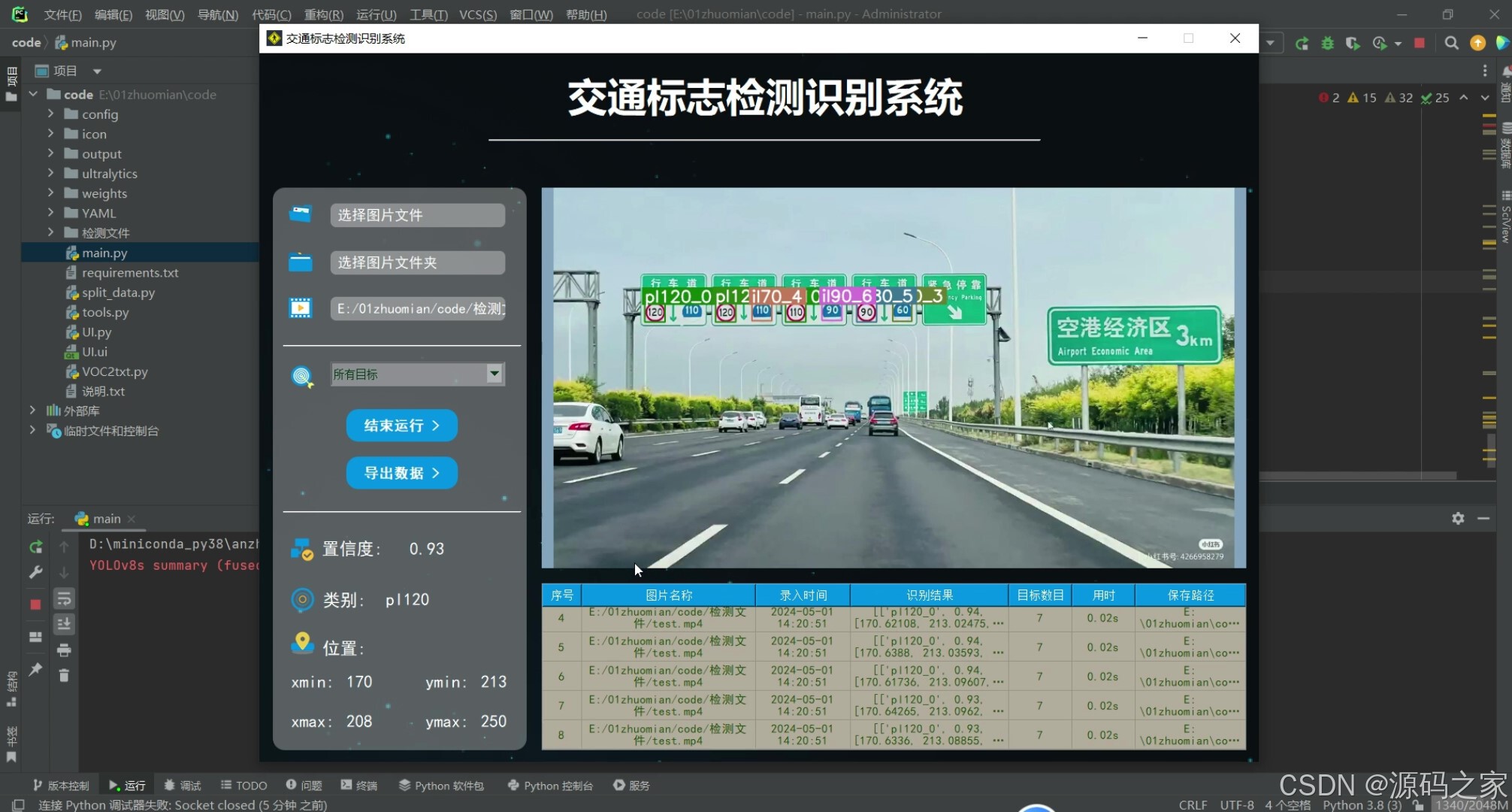
(5)上传视频检测识别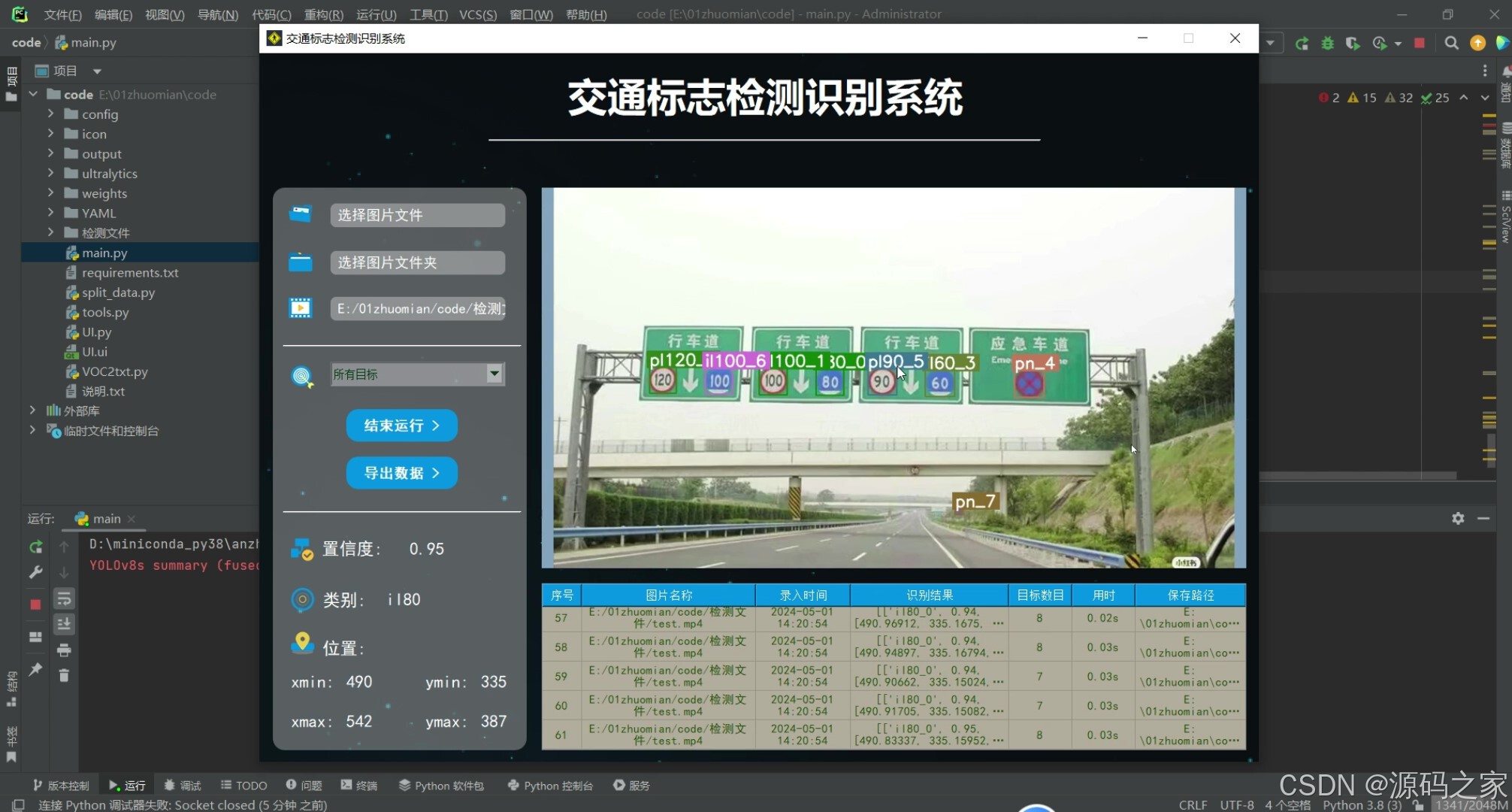
(6)上传视频检测识别
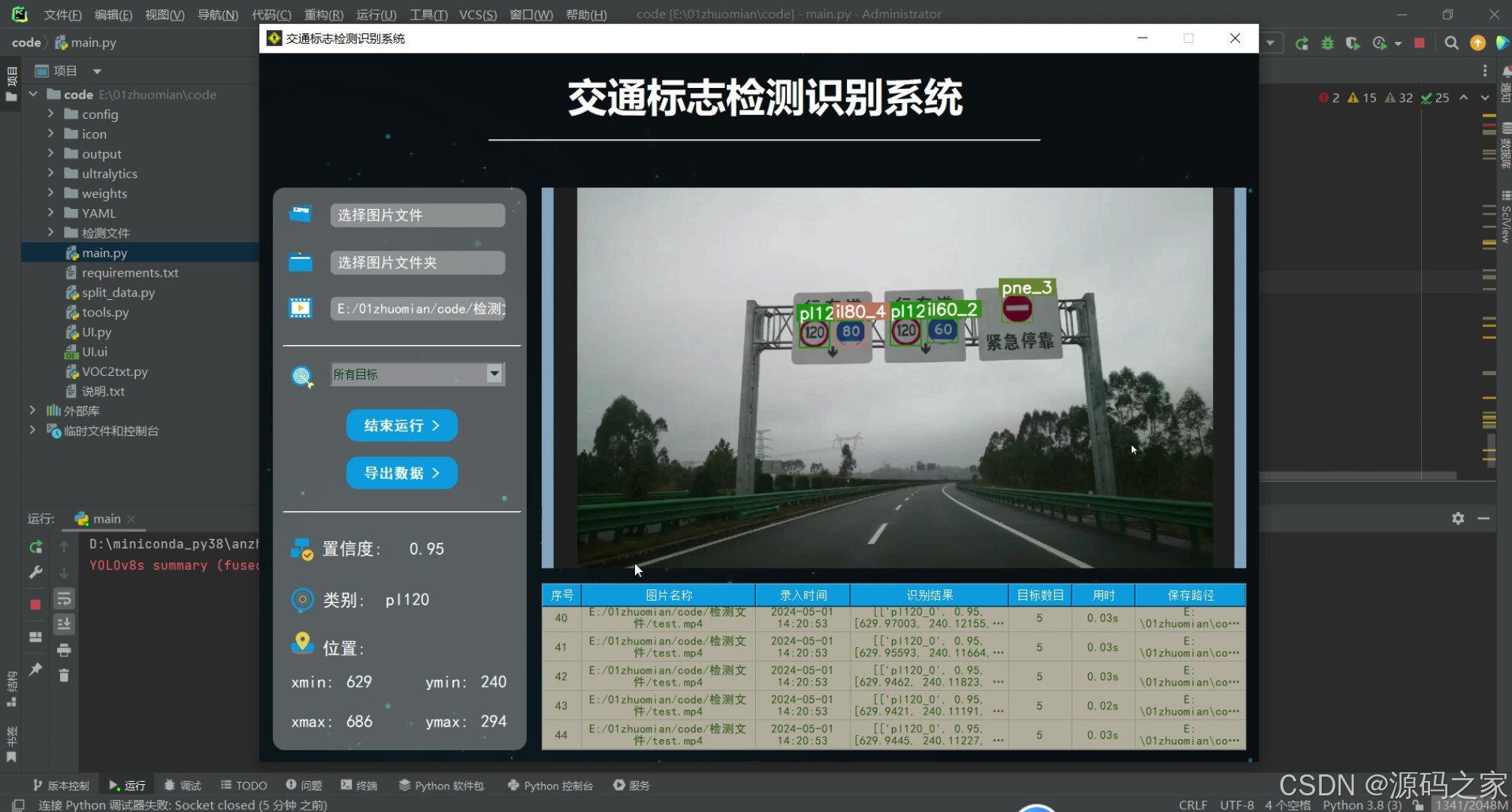
(7)摄像头实时检测识别–限速80
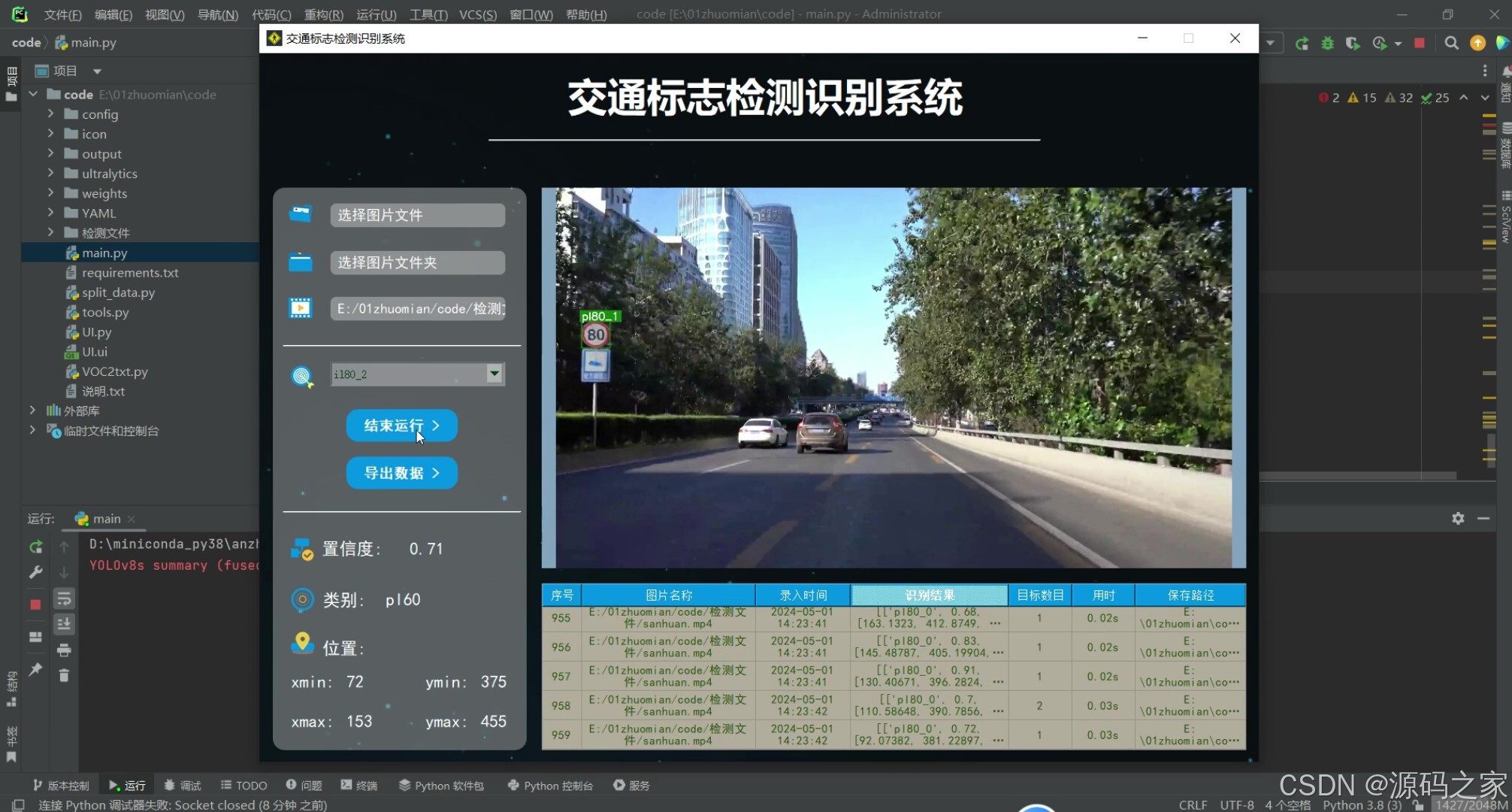
(8)界面设计
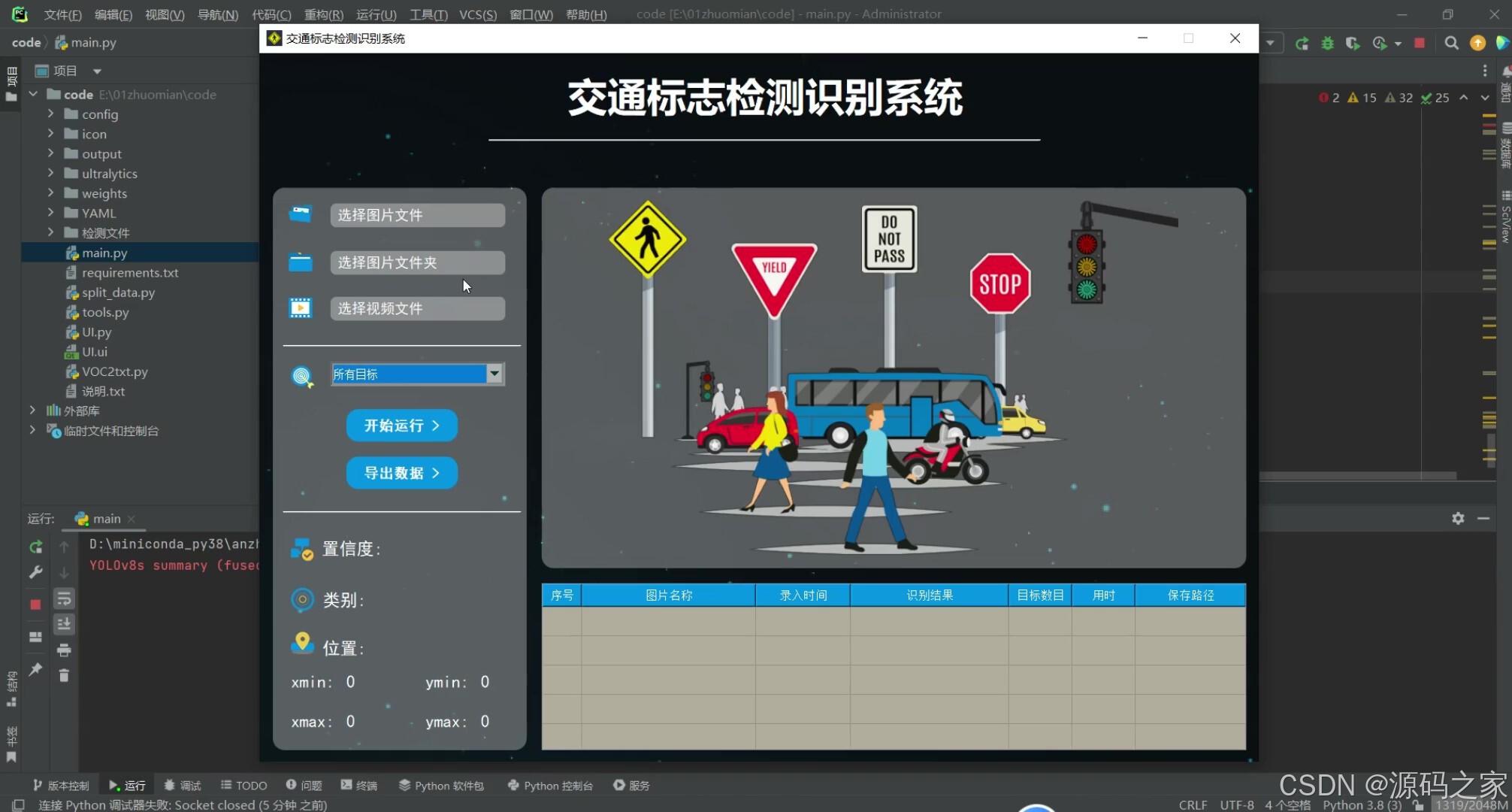
(9)导出数据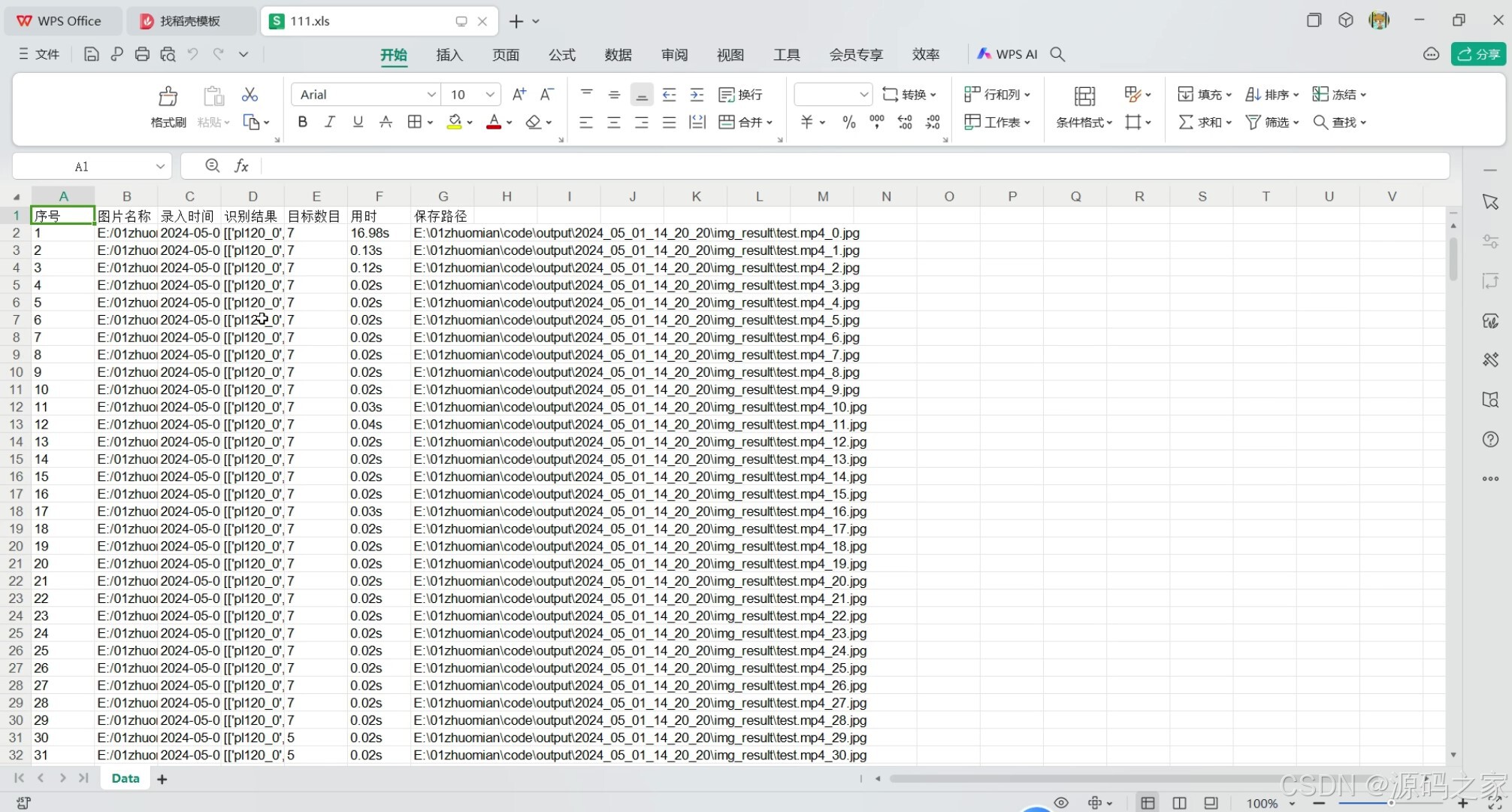
3、项目说明
本项目是专为毕业设计打造的 Python 交通标志检测识别解决方案,以深度学习为核心,融合 YOLOv8 目标检测算法、PyQt5 可视化界面与 OpenCV 大数据处理技术,构建高效、精准的交通标志检测系统,可应用于智能驾驶、交通监控等场景,同时满足毕设的技术完整性与成果展示需求。
技术层面,项目以 YOLOv8 算法为检测核心,凭借其优异的实时性与准确率,能快速定位并识别限速、禁止通行、指示等各类交通标志,解决复杂道路场景下标志遮挡、尺寸差异大的问题;OpenCV 负责图像预处理与大数据处理,支持批量图像解析、特征提取,提升数据处理效率;PyQt5 搭建直观交互界面,涵盖模型选择、图像导入(本地 / 摄像头实时采集)、检测结果展示等功能,降低操作门槛。
功能上,系统实现 “数据处理 - 模型检测 - 结果反馈” 闭环:支持海量交通图像数据导入,通过 OpenCV 优化图像质量;调用 YOLOv8 模型完成精准检测,标注标志类别与置信度;自动统计检测结果,生成可视化报告。项目配套完整源码与设计文档,技术路线清晰、注释详细,既符合毕业设计规范,又具备实际应用价值,是兼顾学习与实践的优质毕设项目。
技术栈:
Python语言、YOLOv8算法、PyQt5界面设计、OpenCV、保存数据、导出数据
数据集(20G):
数据集总共包含以下类别,且已经分好 train、val、test文件夹,也提供转好的yolo格式的标注文件,可以直接使用。总共有9千多张数据集,161种类别,基本上包含了遇到的绝大部分交通标志的类别了。
4、核心代码
import ctypes
from datetime import datetime
import time
import sys
import xlwt
from PyQt5.QtCore import QThread, pyqtSignal, Qt, QUrl
from PyQt5.QtWidgets import QApplication, QMainWindow, QButtonGroup, QComboBox, QMessageBox
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtGui import QBrush, QColor, QFont, QDesktopServices, QIcon
from UI import Ui_MainWindow
from PyQt5 import QtGui
from PyQt5.QtWidgets import QFileDialog
from PyQt5.QtGui import QDesktopServices
import cv2
import os
import numpy as np
root = os.getcwd()
sys.path.append(os.path.join(root, 'ultralytics'))
from YAML.parser import get_config
from tools import draw_info
from inferer import YOLOV8_infer
# 任务栏图标
winapi = ctypes.windll.shell32
winapi.SetCurrentProcessExplicitAppUserModelID("myappid")
class HyperLink(object):
'''
超链接控制
'''
def __init__(self, MyMainWindow, cfg):
MyMainWindow.label_csdn.setOpenExternalLinks(True) # 允许打开外部链接
MyMainWindow.label_csdn.setCursor(Qt.PointingHandCursor) # 更改光标样式
# 设置网址超链接
url_blog = QUrl("")
MyMainWindow.label_csdn.setToolTip(url_blog.toString())
# 博客点击
MyMainWindow.label_csdn.mousePressEvent = lambda event: self.open_url(
url_blog) if event.button() == Qt.LeftButton else None
MyMainWindow.label_mbd.setOpenExternalLinks(True) # 允许打开外部链接
MyMainWindow.label_mbd.setCursor(Qt.PointingHandCursor) # 更改光标样式
# 设置网址超链接
url_mbd = QUrl("")
MyMainWindow.label_mbd.setToolTip(url_blog.toString())
# 博客点击
MyMainWindow.label_mbd.mousePressEvent = lambda event: self.open_url(
url_mbd) if event.button() == Qt.LeftButton else None
MyMainWindow.label_tb.setOpenExternalLinks(True) # 允许打开外部链接
MyMainWindow.label_tb.setCursor(Qt.PointingHandCursor) # 更改光标样式
# 设置网址超链接
url_tb = QUrl("")
MyMainWindow.label_tb.setToolTip(url_blog.toString())
# 博客点击
MyMainWindow.label_tb.mousePressEvent = lambda event: self.open_url(
url_tb) if event.button() == Qt.LeftButton else None
# 打开超链接
def open_url(self, url):
QDesktopServices.openUrl(url)
# 设置label不可见
def label_invalid(self):
MyMainWindow.label_csdn.setVisible(False)
MyMainWindow.label_mbd.setVisible(False)
MyMainWindow.label_tb.setVisible(False)
class MyMainWindow(QMainWindow, Ui_MainWindow):
def __init__(self, cfg=None):
super().__init__()
self.results = None
self.result_img_name = None
self.setupUi(self)
# 加载超链接
HyperLink(self, cfg)
if cfg.CONFIG.MODE != "mbd":
self.label_csdn.setVisible(False)
self.label_mbd.setVisible(False)
self.label_tb.setVisible(False)
# 修改table的宽度
self.update_table_width()
self.start_type = None
self.img = None
self.img_path = None
self.video = None
self.video_path = None
# 绘制了识别信息的frame
self.img_show = None
# 是否结束识别的线程
self.start_end = False
self.sign = True
self.worker_thread = None
self.result_info = None
# 获取当前工程文件位置
self.ProjectPath = os.getcwd()
self.selected_text = '所有目标'
run_time = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
# 保存所有的输出文件
self.output_dir = os.path.join(self.ProjectPath, 'output')
if not os.path.exists(self.output_dir):
os.mkdir(self.output_dir)
result_time_path = os.path.join(self.output_dir, run_time)
os.mkdir(result_time_path)
# 保存txt内容
self.result_txt = os.path.join(result_time_path, 'result.txt')
with open(self.result_txt, 'w') as result_file:
result_file.write(str(['序号', '图片名称', '录入时间', '识别结果', '目标数目', '用时', '保存路径'])[1:-1])
result_file.write('\n')
# 保存绘制好的图片结果
self.result_img_path = os.path.join(result_time_path, 'img_result')
os.mkdir(self.result_img_path)
# 默认选择为所有目标
self.comboBox_value = '所有目标'
self.number = 1
self.RowLength = 0
self.consum_time = 0
self.input_time = 0
# 打开图片
self.pushButton_img.clicked.connect(self.open_img)
# 打开文件夹
self.pushButton_dir.clicked.connect(self.open_dir)
# 打开视频
self.pushButton_video.clicked.connect(self.open_video)
# 绑定开始运行
self.pushButton_start.clicked.connect(self.start)
# 导出数据
self.pushButton_export.clicked.connect(self.write_files)
self.comboBox.activated.connect(self.onComboBoxActivated)
self.comboBox.mousePressEvent = self.handle_mouse_press
# 表格点击事件绑定
self.tableWidget_info.cellClicked.connect(self.cell_clicked)
def update_table_width(self):
# 设置每列宽度
column_widths = [50, 220, 120, 200, 80, 80, 140]
for column, width in enumerate(column_widths):
self.tableWidget_info.setColumnWidth(column, width)
# 连接单元格点击事件
def cell_clicked(self, row, column):
result_info = {}
# 判断此行是否有值
if self.tableWidget_info.item(row, 1) is None:
return
# 图片路径
self.img_path = self.tableWidget_info.item(row, 1).text()
# 识别结果
self.results = eval(self.tableWidget_info.item(row, 3).text())
# 保存路径
self.result_img_name = self.tableWidget_info.item(row, 6).text()
self.img_show = cv2.imdecode(np.fromfile(self.result_img_name, dtype=np.uint8), -1)
box = self.results[0][2]
score = self.results[0][1]
cls_name = self.results[0][0]
result_info['label_xmin_v'] = int(box[0])
result_info['label_ymin_v'] = int(box[1])
result_info['label_xmax_v'] = int(box[2])
result_info['label_ymax_v'] = int(box[3])
result_info['score'] = score
result_info['cls_name'] = cls_name
self.get_comboBox_value(self.results)
self.show_all(self.img_show, result_info)
def handle_mouse_press(self, event):
if event.button() == Qt.LeftButton:
self.sign = False
# 清空列表
self.comboBox.clear()
if type(self.comboBox_value) == str:
self.comboBox_value = [self.comboBox_value]
self.comboBox.addItems(self.comboBox_value)
QComboBox.mousePressEvent(self.comboBox, event)
def onComboBoxActivated(self):
self.sign = True
self.selected_text = self.comboBox.currentText()
result_info = {}
lst_info = []
box = []
# 所有目标,默认显示结果中的第一个
if self.selected_text == '所有目标':
if len(self.results) == 0:
return
box = self.results[0][2]
score = self.results[0][1]
cls_name = self.results[0][0]
lst_info = self.results
else:
for bbox in self.results:
box = bbox[2]
cls_name = bbox[0]
score = bbox[1]
lst_info = [[cls_name, score, box]]
if self.selected_text == cls_name:
break
if len(box) == 0:
return
result_info['label_xmin_v'] = int(box[0])
result_info['label_ymin_v'] = int(box[1])
result_info['label_xmax_v'] = int(box[2])
result_info['label_ymax_v'] = int(box[3])
result_info['score'] = score
result_info['cls_name'] = cls_name
self.img = cv2.imdecode(np.fromfile(self.img_path, dtype=np.uint8), cv2.IMREAD_COLOR)
self.img_show = draw_info(self.img, lst_info)
self.show_all(self.img_show, result_info)
def resize_with_padding(self, image, target_width, target_height, padding_value=None):
# 原始图像大小
if padding_value is None:
padding_value = [190, 162, 129]
original_height, original_width = image.shape[:2]
# 计算宽高比例
width_ratio = target_width / original_width
height_ratio = target_height / original_height
# 确定调整后的图像大小和填充大小
if width_ratio < height_ratio:
new_width = target_width
new_height = int(original_height * width_ratio)
top = (target_height - new_height) // 2
bottom = target_height - new_height - top
left, right = 0, 0
else:
new_width = int(original_width * height_ratio)
new_height = target_height
left = (target_width - new_width) // 2
right = target_width - new_width - left
top, bottom = 0, 0
# 调整图像大小并进行固定值填充
resized_image = cv2.resize(image, (new_width, new_height))
padded_image = cv2.copyMakeBorder(resized_image, top, bottom, left, right, cv2.BORDER_CONSTANT,
value=padding_value)
return padded_image
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献131条内容
已为社区贡献131条内容

所有评论(0)