3D-LLaVA代码详解(三):数据集结构
文字部分的数据集路径:处理数据集部分的代码位置:llava/train/train.py。
文字部分的数据集路径:
playground/data/train_info
处理数据集部分的代码位置:llava/train/train.py
# 处理数据集部分
data_module = make_supervised_data_module(tokenizer=tokenizer,
data_args=data_args)关于文字部分的输入格式:
{
"id": "scanrefer_0",
"scene_id": "scene0000_00",
"conversations": [
{
"from": "human",
"value": "<pc>\n Please output the segmentation mask according to the following description. \na white cabinet in the corner of the room. in the direction from the door and from the inside . it will be on the left, there is a small brown table on the left side of the cabinet and a smaller table on the right side of the cabinet"
},
{
"from": "gpt",
"value": "[SEG]."
}
],
"object_id": 39,
"task_type": "refer_seg"
},主要的键包括:
"id": 每条数据的独特id
"scene_id": "scene0000_00" 场景id
"conversations" 是一个数组,分别含有human的问题和gpt的回答:
[{"from": "human",
"value": "<pc>\n Please output the segmentation mask according to the following description. \nit is the kitchen counter furthest away from the refrigerator, with a sink in it"
},
{"from": "gpt",
"value": "[SEG]."}],对于segmentation的输出:
提问会加上:Please output the segmentation mask according to the following description.
对于回答:如果有目标物体,就会输出单个[SEG],如果没有目标物体,就会输出I cannot find it.
"conversations": [
{
"from": "human",
"value": "<pc>\n Please output the segmentation mask according to the following description. \nas you enter the room, the second cabinet on the left is the object.\nThere may be no corresponding object, or there may be one or more objects."
},
{
"from": "gpt",
"value": "I cannot find it."
}
],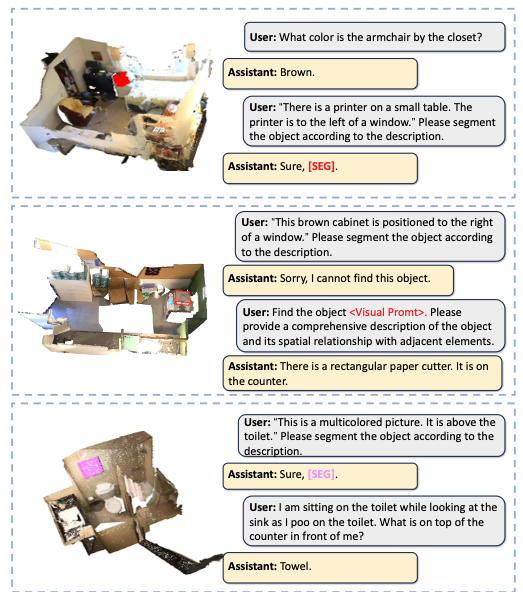
事实上模型的输出只有单个“[SEG]”和“I cannot find it.”两个结果,所以还是很难支持混合输出的情况
object_id:场景中目标物体的id
"object_id": [31,49], object_id可以用多个物体
task_type:任务类型
__getitem__核心代码分析:
在llava/train/train.py的def __getitem__(self, i) -> Dict[str, torch.Tensor]:中
preprocess代码
data_dict = preprocess(
conv_sources,
self.tokenizer,
has_image=('image' in self.list_data_dict[i] or 'scene_id' in self.list_data_dict[i]),
add_link_token=self.data_args.pc_use_link_token)这个preprocess的的目的是得到文字部分的token id,返回的键包括:
input_ids :输入的id序列
labels:gt的标注
scene_id:对应的原本llava的image部分,其中会由scene_id来得到具体的点云信息
pc_data_dict
处理得到的主要有两个dict,第一是pc_data_dict,主要包含了点云的信息,如下图:
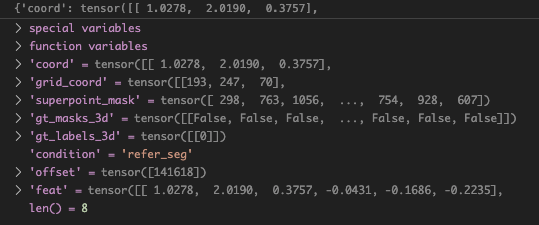
点云信息会加到最终的data_dict
data_dict.update(pc_data_dict)最终的data_dict
最终的data_dict,也就是get_item的输出是:
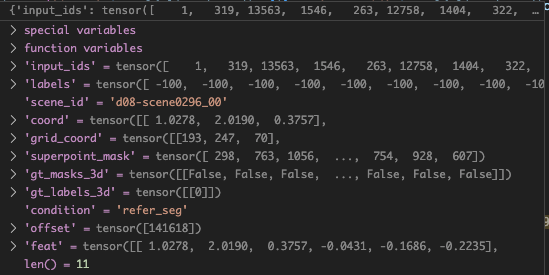
后面8个信息都是pc_data_dict的点云的信息

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)