【GitHub项目推荐--X推荐算法开源项目:社交媒体的智能推荐引擎】⭐⭐⭐⭐⭐
简介
X推荐算法(前身为Twitter推荐算法)是X平台(前Twitter)开源的社交媒体内容推荐系统。该项目包含了构建X平台"For You"时间线、搜索推荐、探索功能和通知推荐的核心算法和服务,是业界领先的大规模社交媒体推荐系统。
🔗 GitHub地址:
https://github.com/twitter/the-algorithm
📊 核心价值:
社交媒体推荐 · 机器学习 · 实时处理 · 大规模系统 · 开源学习
项目背景:
-
透明度需求:平台算法透明度
-
研究价值:学术研究价值
-
技术分享:技术经验分享
-
社区参与:开发者社区参与
-
创新推动:推荐系统创新推动
项目特色:
-
🌐 大规模系统:亿级用户系统
-
🤖 AI驱动:人工智能驱动
-
⚡ 实时推荐:实时内容推荐
-
🏢 生产验证:生产环境验证
-
🔓 开源学习:开源学习资源
技术亮点:
-
Scala/Java:主要开发语言
-
机器学习:多种ML模型
-
图计算:图算法应用
-
实时处理:实时数据流
-
分布式系统:分布式架构
主要功能
1. 核心功能体系
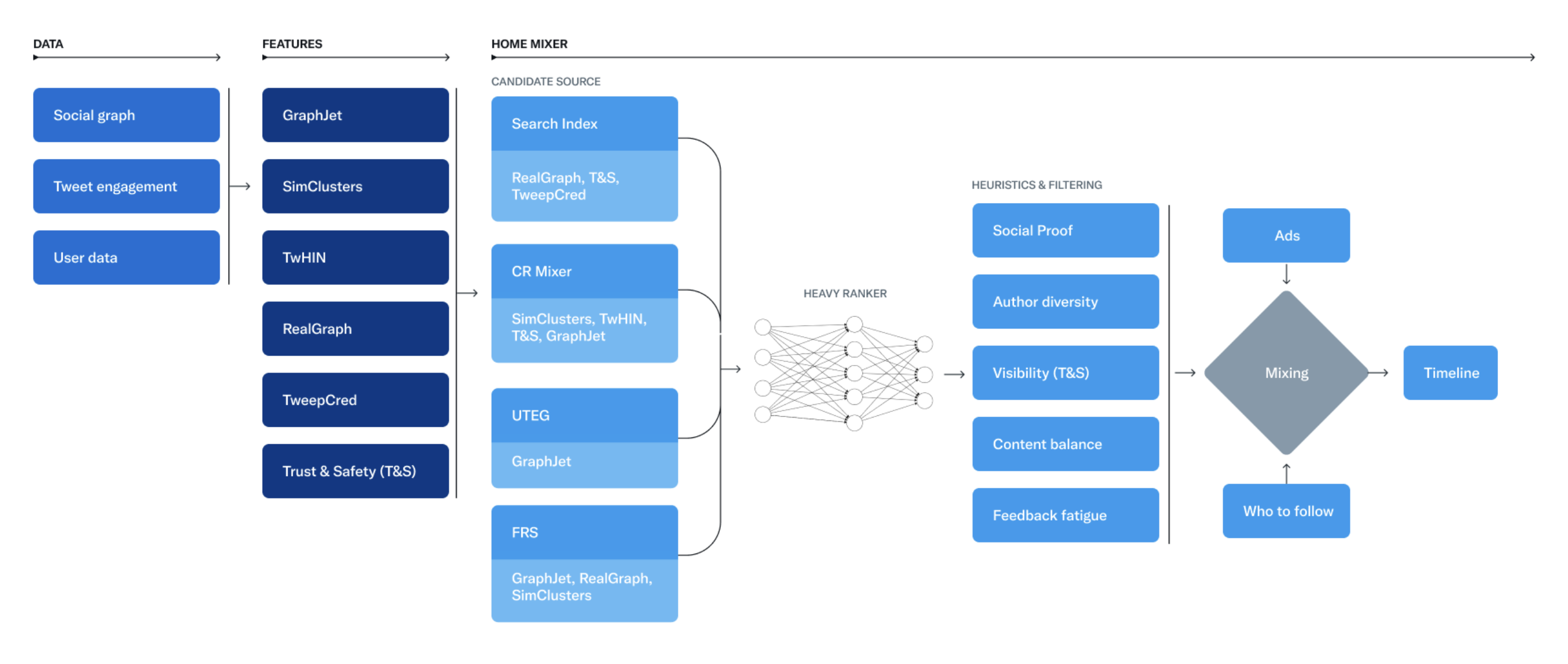
X推荐算法提供了一套完整的社交媒体推荐解决方案,涵盖候选生成、内容排序、混合过滤、用户建模、内容理解、实时处理、批量处理、质量保证、安全过滤、个性化推荐、多样化保证、系统监控、性能优化、扩展功能等多个方面。
推荐流水线功能:
流水线阶段:
- 候选生成: 生成推荐候选集
- 特征提取: 提取内容特征
- 模型预测: 模型预测评分
- 排序过滤: 排序结果过滤
- 最终呈现: 最终结果呈现
候选来源:
- 社交图谱: 关注用户内容
- 兴趣匹配: 兴趣相似内容
- 热门内容: 平台热门内容
- 地理位置: 地理位置内容
- 新鲜内容: 最新发布内容
排序因素:
- 相关性: 内容相关程度
- 新鲜度: 内容发布时间
- 互动率: 预期互动概率
- 多样性: 内容类型多样
- 质量分: 内容质量评分机器学习功能:
模型类型:
- 协同过滤: 协同过滤推荐
- 内容分析: 内容特征分析
- 图神经网络: 图关系学习
- 深度学习: 深度神经网络
- 集成模型: 多模型集成
特征工程:
- 用户特征: 用户属性特征
- 内容特征: 内容属性特征
- 交互特征: 用户交互特征
- 上下文特征: 上下文环境特征
- 时序特征: 时间序列特征
模型服务:
- 模型训练: 批量模型训练
- 实时预测: 实时预测服务
- 模型更新: 在线模型更新
- 效果评估: 模型效果评估
- 版本管理: 模型版本管理2. 高级功能
实时处理功能:
实时能力:
- 实时采集: 实时数据采集
- 流处理: 实时流处理
- 实时特征: 实时特征计算
- 实时推荐: 实时推荐生成
- 实时反馈: 实时反馈学习
处理框架:
- 流处理引擎: 流处理框架
- 消息队列: 消息队列系统
- 实时存储: 实时数据存储
- 状态管理: 流状态管理
- 容错处理: 容错处理机制
实时优化:
- 低延迟: 低延迟处理
- 高吞吐: 高吞吐量
- 一致性: 数据一致性
- 可靠性: 系统可靠性
- 可扩展: 水平可扩展个性化功能:
个性化维度:
- 兴趣个性化: 兴趣偏好匹配
- 行为个性化: 行为模式匹配
- 社交个性化: 社交关系匹配
- 情境个性化: 情境环境匹配
- 历史个性化: 历史偏好匹配
个性化技术:
- 用户画像: 用户画像构建
- 兴趣挖掘: 兴趣模式挖掘
- 行为分析: 行为模式分析
- 情境感知: 情境感知推荐
- 动态调整: 动态偏好调整
个性化控制:
- 透明度: 推荐透明度
- 可控性: 用户可控性
- 可解释: 推荐可解释性
- 隐私保护: 隐私数据保护
- 伦理考虑: 伦理道德考虑质量安全功能:
质量保障:
- 内容质量: 内容质量评估
- 用户体验: 用户体验优化
- 系统性能: 系统性能保障
- 数据质量: 数据质量保证
- 监控告警: 监控告警系统
安全过滤:
- 有害内容: 有害内容过滤
- 垃圾信息: 垃圾信息过滤
- 虚假信息: 虚假信息识别
- 版权保护: 版权内容保护
- 合规审查: 合规性审查
审核机制:
- 自动审核: 自动审核系统
- 人工审核: 人工审核辅助
- 混合审核: 混合审核机制
- 申诉处理: 用户申诉处理
- 改进优化: 持续改进优化安装与配置
1. 环境准备
系统要求:
最低要求:
- 操作系统: Linux
- 内存: 16GB RAM
- 存储: 100GB 可用空间
- CPU: 多核处理器
- 网络: 高速网络连接
推荐要求:
- 操作系统: Linux Ubuntu 20.04+
- 内存: 64GB+ RAM
- 存储: 1TB+ 可用空间
- CPU: 16核+处理器
- 网络: 万兆网络连接
生产要求:
- 服务器集群: 多节点集群
- 分布式存储: 分布式存储
- 负载均衡: 负载均衡器
- 监控系统: 系统监控
- 备份系统: 数据备份软件依赖:
核心依赖:
- Java: Java 8+
- Scala: Scala 2.12+
- Python: Python 3.7+
- Bazel: Bazel构建工具
- Docker: Docker容器
数据存储:
- Hadoop: Hadoop生态系统
- Spark: Spark计算框架
- Kafka: Kafka消息队列
- Redis: Redis缓存
- MySQL: MySQL数据库
机器学习:
- TensorFlow: TensorFlow框架
- PyTorch: PyTorch框架
- XGBoost: XGBoost库
- Scikit-learn: Scikit-learn库
- 其他ML库: 各种机器学习库2. 安装步骤
开发环境安装:
# 克隆项目
git clone https://github.com/twitter/the-algorithm.git
cd the-algorithm
# 安装基础依赖
sudo apt-get update
sudo apt-get install openjdk-8-jdk scala python3 python3-pip
# 安装Bazel
curl -fsSL https://github.com/bazelbuild/bazel/releases/download/5.0.0/bazel-5.0.0-installer-linux-x86_64.sh -o bazel-installer.sh
chmod +x bazel-installer.sh
./bazel-installer.sh
# 安装Python依赖
pip3 install -r requirements.txt
# 构建项目
bazel build //...组件安装:
# 安装特定组件
# 例如安装推荐服务
bazel build //recommendation-service:all
# 安装机器学习组件
bazel build //ml-core:all
# 安装数据处理组件
bazel build //data-processing:all
# 安装API服务
bazel build //api-service:allDocker安装:
# Docker方式运行
docker build -t twitter-algorithm .
docker run -it twitter-algorithm
# 或使用Docker Compose
docker-compose up -d
# 生产环境部署
docker-compose -f docker-compose.prod.yml up -d云部署:
# 各种云平台部署
# AWS, GCP, Azure, 阿里云, 腾讯云等
# Kubernetes部署
kubectl apply -f kubernetes/
# 或使用Terraform
terraform init
terraform apply测试验证:
# 运行测试
bazel test //...
# 或运行特定测试
bazel test //recommendation-service:test
# 集成测试
bazel test //integration-test:all
# 性能测试
bazel run //performance-test:run3. 配置说明
基础配置:
# application.yaml
server:
port: 8080
host: 0.0.0.0
database:
url: jdbc:mysql://localhost:3306/recommendation
username: user
password: pass
poolSize: 10
cache:
redis:
host: localhost
port: 6379
password:
database: 0
logging:
level: INFO
file: /var/log/recommendation.log机器学习配置:
# ml-config.yaml
models:
collaborative-filtering:
enabled: true
version: v2.1.0
parameters:
factors: 100
iterations: 20
regularization: 0.01
content-based:
enabled: true
version: v1.5.0
parameters:
tfidf: true
min-df: 5
max-features: 10000
deep-learning:
enabled: false
version: v3.0.0-beta
parameters:
layers: [256, 128, 64]
dropout: 0.2
learning-rate: 0.001
training:
batch-size: 1000
epochs: 100
validation-split: 0.2
early-stopping: true实时处理配置:
# streaming-config.yaml
kafka:
bootstrap-servers: localhost:9092
topics:
user-events: user-events
content-updates: content-updates
recommendations: recommendations
consumer:
group-id: recommendation-group
auto-offset-reset: earliest
producer:
acks: all
retries: 3
spark:
master: local[4]
app-name: recommendation-streaming
streaming:
batch-interval: 1000
checkpoint-dir: /tmp/checkpoint
sql:
shuffle-partitions: 200性能配置:
# performance.yaml
thread-pool:
core-size: 20
max-size: 100
queue-capacity: 1000
keep-alive-time: 60
cache:
local:
maximum-size: 10000
expire-after-write: 300
distributed:
enabled: true
timeout: 1000
retry-attempts: 3
database:
connection-pool:
maximum-pool-size: 20
minimum-idle: 5
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000使用指南
1. 基本工作流
使用X推荐算法的基本流程包括:环境准备 → 项目安装 → 配置设置 → 数据准备 → 模型训练 → 服务启动 → 请求处理 → 结果生成 → 效果评估 → 优化调整 → 监控维护 → 扩展开发 → 生产部署 → 持续改进。整个过程设计为完整的推荐系统工作流。
2. 基本使用
推荐服务使用:
服务启动:
1. 启动依赖服务: 启动数据库、缓存等
2. 启动推荐服务: 启动推荐服务
3. 健康检查: 检查服务健康状态
4. 负载测试: 进行负载测试
5. 监控设置: 设置监控告警
API调用:
- 用户推荐: 获取用户推荐
- 内容推荐: 获取内容推荐
- 实时推荐: 实时推荐生成
- 批量推荐: 批量推荐生成
- 个性化推荐: 个性化推荐
请求示例:
GET /recommendations/user/{userId}
GET /recommendations/content/{contentId}
POST /recommendations/batch
GET /recommendations/personalized模型训练使用:
训练流程:
1. 数据准备: 准备训练数据
2. 特征工程: 特征提取处理
3. 模型训练: 训练推荐模型
4. 模型评估: 评估模型效果
5. 模型部署: 部署训练模型
训练类型:
- 批量训练: 定期批量训练
- 增量训练: 增量模型更新
- 在线学习: 在线学习训练
- 迁移学习: 迁移学习训练
- 联邦学习: 联邦学习训练
评估指标:
- 准确率: 推荐准确率
- 召回率: 推荐召回率
- 覆盖率: 内容覆盖率
- 多样性: 推荐多样性
- 新颖性: 推荐新颖性数据处理使用:
数据处理:
1. 数据采集: 采集原始数据
2. 数据清洗: 数据清洗处理
3. 数据转换: 数据格式转换
4. 特征提取: 特征提取计算
5. 数据存储: 处理数据存储
处理类型:
- 批量处理: 批量数据处理
- 实时处理: 实时流处理
- 增量处理: 增量数据处理
- 回溯处理: 历史数据处理
- 采样处理: 数据采样处理
数据质量:
- 完整性: 数据完整性
- 准确性: 数据准确性
- 一致性: 数据一致性
- 及时性: 数据及时性
- 可用性: 数据可用性3. 高级用法
个性化推荐使用:
个性化配置:
1. 用户画像: 构建用户画像
2. 兴趣模型: 建立兴趣模型
3. 行为分析: 分析用户行为
4. 情境感知: 情境感知配置
5. 动态调整: 动态调整策略
个性化维度:
- 基础属性: 年龄性别等
- 兴趣偏好: 兴趣爱好等
- 行为模式: 行为习惯等
- 社交关系: 社交网络等
- 时空情境: 时间地点等
控制调整:
- 权重调整: 特征权重调整
- 策略调整: 推荐策略调整
- 反馈学习: 用户反馈学习
- A/B测试: A/B测试优化
- 多目标优化: 多目标平衡实时推荐使用:
实时处理:
1. 事件采集: 实时事件采集
2. 流处理: 实时流处理
3. 实时特征: 实时特征计算
4. 实时预测: 实时预测推荐
5. 实时推送: 实时结果推送
实时能力:
- 低延迟: 毫秒级延迟
- 高吞吐: 高吞吐处理
- 状态管理: 流状态管理
- 容错处理: 故障容错
- 弹性扩展: 弹性扩展
应用场景:
- 实时个性化: 实时个性化推荐
- 实时热点: 实时热点推荐
- 实时交互: 实时交互推荐
- 实时情境: 实时情境推荐
- 实时反馈: 实时反馈学习系统优化使用:
性能优化:
1. 性能分析: 系统性能分析
2. 瓶颈识别: 性能瓶颈识别
3. 优化方案: 制定优化方案
4. 实施优化: 实施优化措施
5. 效果验证: 验证优化效果
优化方向:
- 算法优化: 推荐算法优化
- 系统优化: 系统架构优化
- 数据优化: 数据处理优化
- 资源优化: 资源使用优化
- 网络优化: 网络通信优化
监控调优:
- 性能监控: 性能指标监控
- 资源监控: 资源使用监控
- 质量监控: 推荐质量监控
- 告警处理: 异常告警处理
- 自动调优: 自动调优机制应用场景实例
案例1:社交媒体推荐
场景:社交媒体内容推荐
解决方案:使用X推荐算法进行内容推荐。
实施方法:
-
用户分析:分析用户行为
-
内容分析:分析内容特征
-
匹配推荐:匹配用户内容
-
排序呈现:排序推荐结果
-
反馈优化:根据反馈优化
推荐价值:
-
用户体验:提升用户体验
-
内容发现:帮助内容发现
-
参与度:提高用户参与
-
平台价值:增加平台价值
-
创作者支持:支持创作者
案例2:电商推荐
场景:电子商务产品推荐
解决方案:使用X推荐算法进行商品推荐。
实施方法:
-
用户偏好:分析用户偏好
-
商品分析:分析商品特征
-
匹配推荐:匹配用户商品
-
个性化:个性化商品推荐
-
转化优化:优化购买转化
电商价值:
-
销售提升:提升销售额
-
用户体验:改善购物体验
-
库存优化:优化库存周转
-
客户忠诚:提高客户忠诚
-
精准营销:精准营销推广
案例3:新闻推荐
场景:新闻内容推荐
解决方案:使用X推荐算法进行新闻推荐。
实施方法:
-
兴趣分析:分析用户兴趣
-
新闻分析:分析新闻内容
-
实时推荐**:实时新闻推荐
-
多样性:保证内容多样
-
质量保证:保证新闻质量
新闻价值:
-
信息获取:帮助信息获取
-
兴趣满足:满足用户兴趣
-
时效性:保证新闻时效
-
多样性:内容多样性
-
质量保证:新闻质量保证
案例4:视频推荐
场景:视频内容推荐
解决方案:使用X推荐算法进行视频推荐。
实施方法:
-
观看分析:分析观看行为
-
视频分析:分析视频内容
-
相似推荐:相似视频推荐
-
热门推荐:热门视频推荐
-
系列推荐:系列内容推荐
视频价值:
-
观看体验:提升观看体验
-
内容发现:帮助内容发现
-
观看时长:增加观看时长
-
创作者成长:支持创作者
-
平台生态:健康平台生态
案例5:音乐推荐
场景:音乐内容推荐
解决方案:使用X推荐算法进行音乐推荐。
实施方法:
-
听歌分析:分析听歌行为
-
音乐分析:分析音乐特征
-
心情推荐:心情匹配推荐
-
场景推荐:场景适配推荐
-
发现推荐:新音乐发现推荐
音乐价值:
-
聆听体验:提升聆听体验
-
音乐发现:帮助音乐发现
-
心情匹配:心情匹配音乐
-
场景适配:场景适配音乐
-
艺术家支持:支持艺术家
总结
X推荐算法作为一个成熟的大规模推荐系统,通过其先进的机器学习技术、实时处理能力、个性化推荐和系统优化,为各种推荐需求提供了理想的解决方案。
核心优势:
-
🤖 AI先进:先进AI技术
-
⚡ 实时高效:实时高效处理
-
🎯 精准推荐:精准个性化
-
🏢 规模验证:大规模验证
-
🔓 开源学习:开源学习资源
适用场景:
-
社交媒体推荐
-
电子商务推荐
-
新闻内容推荐
-
视频内容推荐
-
音乐内容推荐
立即开始使用:
# 克隆项目
git clone https://github.com/twitter/the-algorithm.git
# 安装依赖
cd the-algorithm
bazel build //...
# 运行测试
bazel test //...资源链接:
-
🌐 项目地址:GitHub仓库
-
📖 文档:官方文档
-
💬 社区:社区讨论
-
🎓 教程:使用教程
-
🔧 API:API文档
通过X推荐算法,您可以:
-
学习研究:学习推荐技术
-
开发实践:开发推荐系统
-
性能优化:优化系统性能
-
算法改进:改进推荐算法
-
创新应用:创新应用推荐
特别提示:
-
💻 技术基础:需要技术基础
-
🏢 系统复杂:系统较复杂
-
📊 数据需求:需要数据支持
-
🔧 配置复杂:配置较复杂
-
👥 团队协作:建议团队协作
通过X推荐算法,深入学习推荐系统!
未来发展:
-
🚀 更多功能:持续添加功能
-
🤖 更强AI:更强AI能力
-
🌐 更多应用:更多应用场景
-
📊 更好性能:更好性能表现
-
👥 更大社区:更大用户社区
加入社区:
参与方式:
- GitHub: 提交问题和PR
- 文档: 贡献文档改进
- 代码: 参与代码开发
- 测试: 功能测试反馈
- 分享: 分享使用经验
社区价值:
- 共同改进项目
- 问题解答帮助
- 经验分享交流
- 功能需求反馈
- 项目发展推动通过X推荐算法,共同推动推荐技术发展!
许可证:
AGPL-3.0开源许可证
严格开源要求致谢:
特别感谢:
- 开发团队: Twitter/X团队
- 贡献者: 代码贡献者
- 用户: 用户反馈支持
- 社区: 社区支持者免责声明:
重要提示:
需要技术知识
注意系统复杂度
遵守许可证
企业使用建议咨询
注意数据隐私通过X推荐算法,负责任地学习开发!
成功案例:
用户群体:
- 研究者: 学术研究人员
- 开发者: 软件开发者
- 学生: 学生学习
- 企业: 各种企业
- 机构: 研究机构
使用效果:
- 学习效果: 学习效果显著
- 开发帮助: 开发帮助大
- 研究价值: 研究价值高
- 实践指导: 实践指导强
- 满意度高: 用户满意度高最佳实践:
使用建议:
1. 从简单开始: 从简单开始
2. 逐步深入: 逐步深入理解
3. 实践结合: 理论与实践结合
4. 社区参与: 参与社区交流
5. 持续学习: 持续学习更新
避免问题:
- 复杂度高: 避免开始过于复杂
- 数据不足: 避免数据不足
- 配置错误: 避免配置错误
- 资源不足: 避免资源不足
- 孤立学习: 避免孤立学习通过X推荐算法,实现有效的学习开发!
资源扩展:
学习资源:
- 推荐系统学习
- 机器学习学习
- 分布式系统学习
- 实时处理学习
- 系统优化学习通过X推荐算法,构建您的推荐系统未来!
未来展望:
技术发展:
- 更好算法
- 更强性能
- 更多功能
- 更好体验
- 更易使用
应用发展:
- 更多场景
- 更好效果
- 更广应用
- 更深理解
- 更大影响
社区发展:
- 更多用户
- 更多贡献
- 更好文档
- 更多案例
- 更大影响通过X推荐算法,迎接推荐技术的未来!
结束语:
X推荐算法作为一个业界领先的推荐系统,为推荐技术的学习、研究和应用提供了宝贵的资源。通过合理利用这一项目,您可以深入理解推荐系统的工作原理、学习先进的技术实现并开发自己的推荐应用。
记住,技术是服务人类的手段,结合正确的价值观与合理的技术应用,共同成就技术卓越。
Happy learning with X Recommendation Algorithm! 📊🤖🚀

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 26
26 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)