小杰-自然语言处理(nine)——transformer系列——LayerNormalization(层归一化)
东风夜放花千树,更吹落、星如雨。
1. 引入
Layer Normalization由Ba, Kiros, 和Hinton于2016年提出。它主要用于解决深度神经网络训练过程中的内部协变量偏移问题。不同于Batch Normalization(批归一化),Layer Normalization是独立于批次大小的,这使得它在处理小批次数据或循环神经网络(RNN)时特别有用。
2. 原理
一般而言,在一个神经网络输入图像之前,会将图像进行预处理,这个预处理可能是标准化处理等手段,由于输入数据满足某一分布规律,所以会加速网络的收敛。这样在输入第一次卷积的时候满足某一分布规律,但是在输入第二次卷积时,就不一定满足某一分布规律了,再往后的卷积的输入就更不满足了,那么就需要一个中间商,让上一层的输出经过它之后能够某一分布规律,Batch Normalization就是这个中间商,它可以让输入的特征矩阵的每一个channels满足均值为0,方差为1的分布规律。
举个例子,例如现在一张RGB图像,这张图像作为输入时是三个通道,假设![]() 是R对应的特征矩阵,
是R对应的特征矩阵,![]() 是G对应的特征矩阵,
是G对应的特征矩阵,![]() 是B对应的特征矩阵,那么如何求解这个所谓的Batch Normalization呢?下面列出求解公式:
是B对应的特征矩阵,那么如何求解这个所谓的Batch Normalization呢?下面列出求解公式:
先求出一批数据同一个通道所有数据的对应的均值和方差:
均值:
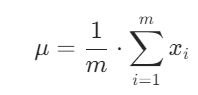
方差:
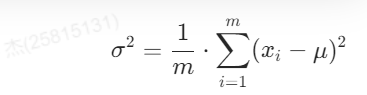
得到均值和方差之后,求出标准化数值,其中![]() 是为了防止分母为0:
是为了防止分母为0:
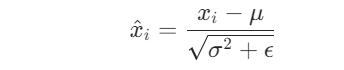
其实到这里就得到了均值为0方差为1的分布规律了,但是为了让标准化后增加一些随机噪音,并在一定程度上起到正则化作用,添加了自适应学习![]() 与
与![]() 同时可以让数据保留更多的原始信息:
同时可以让数据保留更多的原始信息:
![]()

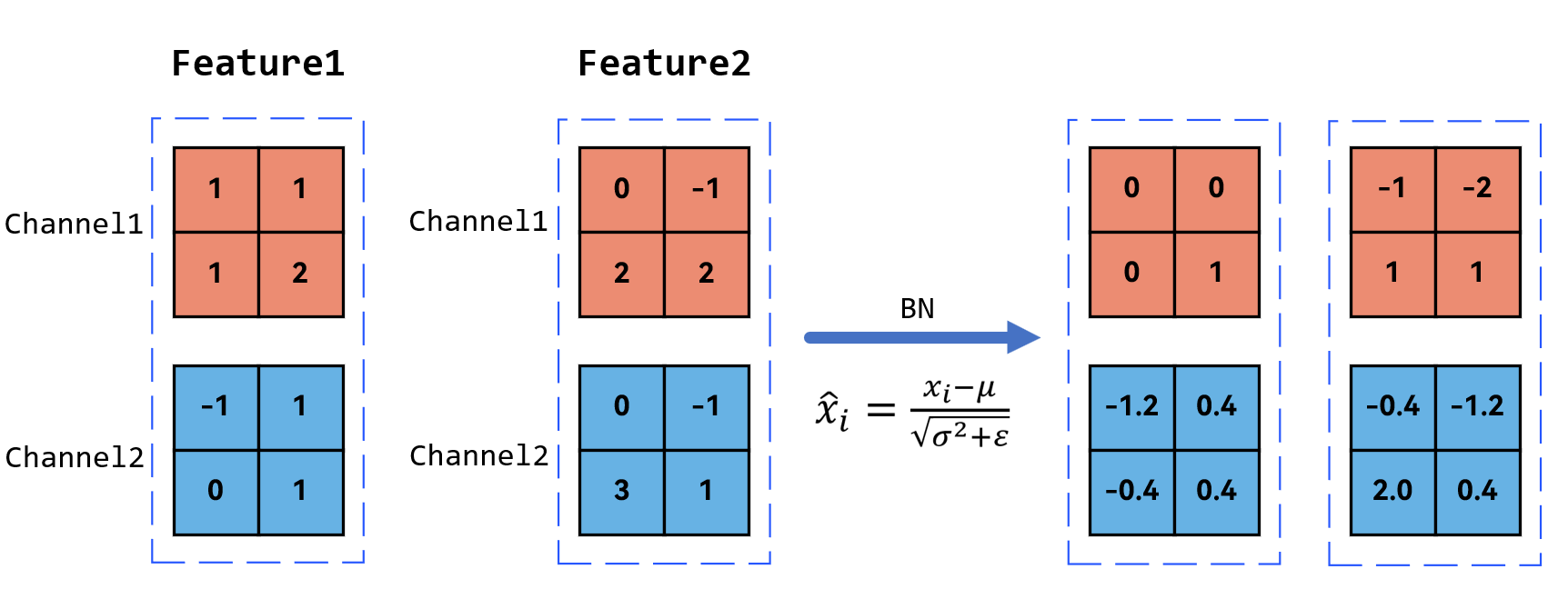
再举例:例如现在有这样两个特征矩阵(这里的特征矩阵的2指的是batch大小,即样本sample数量),每个有两个channels。
注意:取均值和方差时,是对同一个颜色的位置进行的。

卷积层的输出是(batch_size, channels, height, width)的四维张量,它是对0,2,3维进行BN操作,即N/H/W。
使用Numpy理解其内部实际的计算规则:
import numpy as np
import torch
# 对每个batch进行Batch-Normalization
def batch_normalization(BN_input, epsilon=1e-5):
# 计算均值和方差
#N 样本 对H 对W进行操作
mean = np.mean(BN_input, axis=(0, 2, 3), keepdims=True)
variance = np.var(BN_input, axis=(0, 2, 3), keepdims=True)
# 归一化
normalized_data = (BN_input - mean) / np.sqrt(variance + epsilon)
# 假设gamma和beta分别是缩放和平移参数,但是无学习,实际上这两个参数会进行更新
gamma = np.ones_like(BN_input)
beta = np.zeros_like(BN_input)
# 应用缩放和平移
output_data = gamma * normalized_data + beta
return output_data
# 假设卷积后的结果如下:
# 卷积层的输出是(batch_size, channels, height, width)的四维张量
conv_output = [
[
[[1, 1],
[1, 2]],
[[-1, 1],
[0, 1]],
],
[
[[0, -1],
[2, 2]],
[[0, -1],
[3, 1]],
]
]
normalized_output = batch_normalization(np.array(conv_output))
print(normalized_output)
#比较一下
import torch.nn as nn
XTEST=nn.BatchNorm2d(2,affine=False).to(torch.device('cuda'))
data_Text=torch.tensor(conv_output,dtype=torch.float32).to(torch.device('cuda'))
print("f",XTEST(data_Text))
需要注意的是nn.BatchNorm2d(reshaped_embd_output.size(1), affine=True)的affine参数,也就是加入了![]() 和
和![]() ,使其可学习。
,使其可学习。
实际上,不仅仅视觉上的卷积可以使用BN层,其它也可以,在处理文字时:可以将整个文字的sequence看成是图像的channel,embedding_dimension看成是一位1维的图像。
如图中,N表示样本轴(batch大小), C表示通道轴, H,W是每个通道的特征数量,BN是取不同样本的同一个通道的特征做归一化。
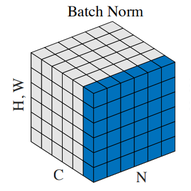
但是BN在一些情况下会有一些缺点,如BN是按照样本数计算归一化统计量的,当样本数很少时,比如说只有2个。这四个样本的均值和方差便不能反映全局的统计分布息,所以基于少量样本的BN的效果会变得很差。在一些场景中,比如说硬件资源受限等场景,BN是非常不适用的。
图像任务已经能够理解了,那么对于NLP任务呢?LN层是如何完成的呢?
其实也很好理解,NLP任务如下图所示:
2.2 Layer-Normalization
Layer Normalization的核心是对单个数据样本的所有特征进行归一化。具体来说,对于网络中的每一层,它计算该层所有激活结果的均值和均值,并使用这些统计数据来规范化激活。这种规范化发生在网络的每一层,独立于其他样本。Layer-Normalization的计算流程如下:
- 计算输入向量的均值:
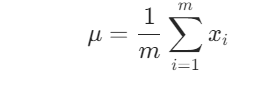
- 计算输入向量的方差:
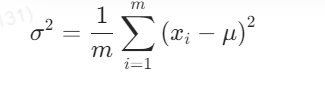
- 对输入向量进行归一化:
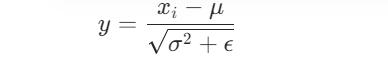

在图像任务使用LN时,卷积层的输出是(batch_size, channels, height, width)的四维张量,它是对1,2,3维进行BN操作,即C/H/W。
注意:取均值和方差时,是对同一个颜色的位置进行的。
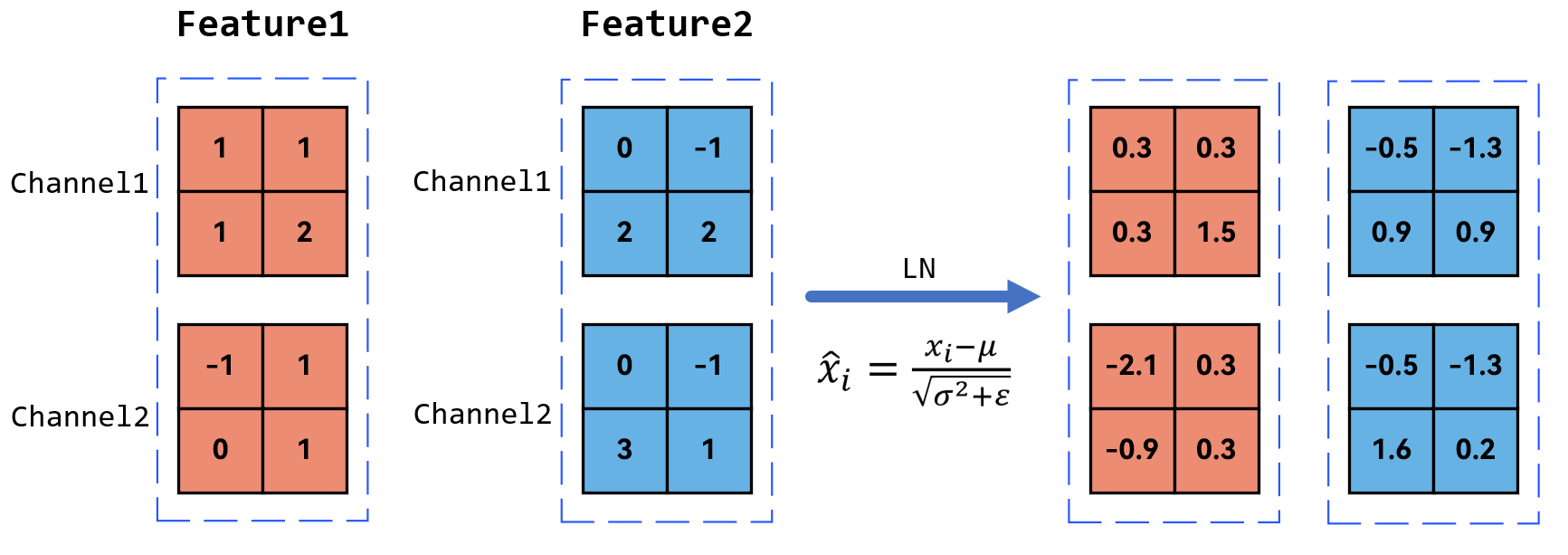
在图中可以看到:Feature1和Feature2是两个输入的样本,即同一个batch的不同样本。
那么在做LN时,与BN不同,它是对同一个样本的C/H/W进行取均值和方差。
可以进行求解:对于Feature1的均值是0.75,方差是0.785。通过公式可以求解,Feature2同理。
使用PyTorch如何实现图像任务的LN层呢?如下:
代码
import torch
import torch.nn as nn
conv_output=[
[
[[1, 1], [1, 2]],
[[-1, 1], [0, 1]],
],
[
[[0, -1], [2, 2]],
[[0, -1], [3, 1]],
]
]
embd_output = torch.tensor(conv_output, dtype=torch.float)
layer_norm = nn.LayerNorm(embd_output.shape[1:4])
normalized_output = layer_norm(embd_output)
print("Original Input:")
print(embd_output)
print("\nLN Normalized Output:")
print(normalized_output)
图像任务已经能够理解了,那么对于NLP任务呢?LN层是如何完成的呢?
其实也很好理解,NLP任务如下图所示:
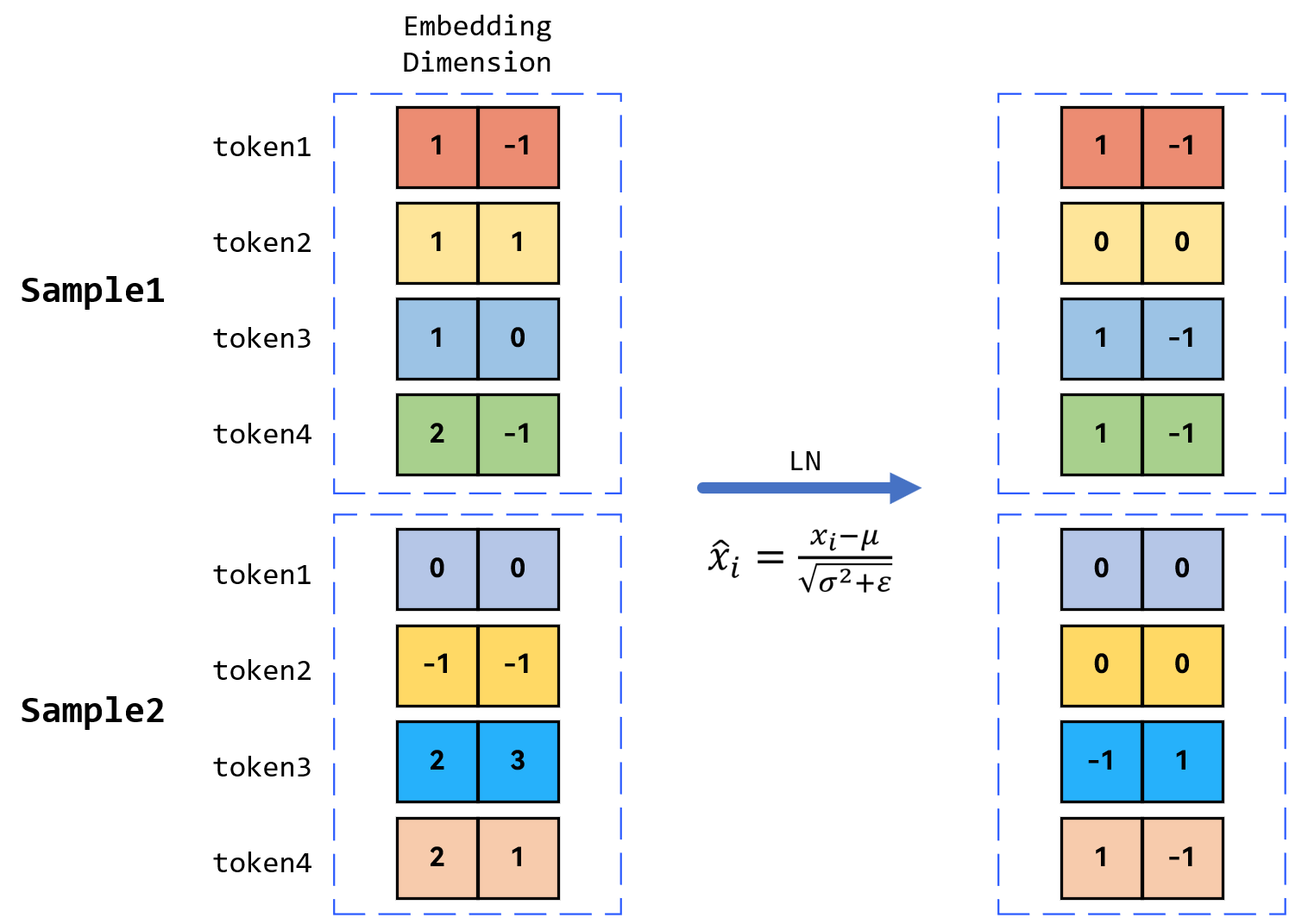
对于输入,有样本1和样本2,即Sample1和Sample2,每个样本有四个字,即4个token,或者叫sequence_len,每个字的Embedding有自己的维度,即embedding dimension。那么LN规则化其实就是对每个样本的每一个token的embedding dimension求均值和方差,然后运算。图中相同颜色的格子就是做LN规则化的。
使用PyTorch如何实现NLP任务的LN层呢?如下:
代码
import torch
import torch.nn as nn
# 假设文字的Embedding编码如下:
# (batch, sequence, embedding_dimension)
embd_output = [
[
[1, -1],
[1, 1],
[1, 0],
[2, -1],
],
[
[0, 0],
[-1, -1],
[2, 3],
[2, 1],
]
]
embd_output = torch.tensor(embd_output, dtype=torch.float)
# 在最后一维上,即embedding_dimension进行Layer Normalization
layer_norm = nn.LayerNorm(embd_output.size(-1))
normalized_output = layer_norm(embd_output)
print("Original Input:")
print(embd_output)
print("\nLN Normalized Output:")
print(normalized_output)
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)