26届大数据毕业设计选题推荐| (基于django豆瓣电影数据分析及可视化系统 猫眼电影电视剧分析 票房预测系统 电影推荐系统)
本文介绍了一个基于Django框架的电影数据分析系统,该系统整合了数据爬取、存储、分析和可视化功能。系统采用Python+Django技术栈,结合Hadoop+Spark进行大数据处理,实现电影信息的智能推荐与可视化展示。主要功能包括:用户端支持登录注册、电影信息浏览、评论收藏等功能;管理员端提供用户管理、电影信息维护等功能;系统亮点在于运用爬虫技术获取数据、协同过滤算法实现个性化推荐,并通过EC
🔥作者:it毕设实战小研🔥
💖简介:java、微信小程序、安卓;定制开发,远程调试 代码讲解,文档指导,ppt制作💖
精彩专栏推荐订阅:在下方专栏👇🏻👇🏻👇🏻👇🏻
Java实战项目
Python实战项目
微信小程序实战项目
大数据实战项目
PHP实战项目
💕💕文末获取源码
文章目录
本次文章主要是介绍基于Django+数据可视化的电影数据分析系统的功能,
1、电影数据分析系统-前言介绍
1.1背景
近年来电影产业呈现出蓬勃发展的态势,全球电影市场规模不断扩大。根据中国电影发行放映协会发布的数据显示,2023年全国电影总票房达到549.15亿元,观影人次超过12.99亿,电影产业已成为文化娱乐领域的重要支柱。随着数字化技术的深入应用,电影相关数据呈现爆炸式增长趋势,包括影片基础信息、用户评价数据、票房统计信息等多维度数据资源日益丰富。国家电影局统计数据表明,截至2023年底全国银幕总数已达到86310块,年度新增影片备案数量超过3000部,海量的电影数据资源为深度挖掘用户偏好、优化内容推荐提供了坚实基础。然而现有的电影信息平台普遍存在数据分散、分析能力不足、个性化推荐效果有限等问题,难以满足用户日益增长的精准化需求。电影数据的价值挖掘和智能化应用成为行业发展的关键瓶颈,迫切需要构建一套完整的电影数据分析系统来解决这些现实问题。
1.2课题功能、技术
电影数据分析系统采用分布式架构设计,融合了多项前沿技术来实现全方位的数据处理和分析功能。系统核心功能模块包括数据采集、用户管理、内容展示、智能推荐和可视化分析五大部分,通过网络爬虫技术自动获取豆瓣、猫眼等主流平台的电影数据,涵盖影片基本信息、用户评分、评论内容等多维度数据源。技术实现方面,系统后端基于Django框架构建,提供稳定的Web服务和数据接口;数据存储采用MySQL数据库管理结构化信息,同时利用Hadoop+Spark分布式计算框架处理海量数据的存储和分析任务。推荐算法采用协同过滤技术,通过分析用户行为数据和电影特征信息,为用户提供个性化的电影推荐服务;可视化模块运用ECharts图表库,将电影评分分布、年代统计、热门影片排行等数据以直观的图表形式呈现,帮助用户快速了解电影市场的整体趋势和热点信息。系统还配备了完善的用户权限管理机制,区分普通用户和管理员角色,确保数据安全和系统稳定运行。
1.3 意义
理论意义方面,该系统在数据挖掘和推荐算法领域具有重要的研究价值。通过将协同过滤算法应用于电影推荐场景,深入探索了用户偏好模式的识别方法和相似度计算策略,为推荐系统理论研究提供了实践验证平台;同时系统集成了网络爬虫、大数据处理、机器学习等多项技术,形成了完整的数据分析技术栈,对相关技术的融合应用具有一定的理论指导意义。分布式计算框架在电影数据处理中的应用,也为大数据分析技术在娱乐文化领域的推广提供了有价值的参考案例。实际意义层面,系统能够有效解决电影信息获取困难、推荐精度不高等现实问题,提升用户的观影体验和决策效率。对于电影产业而言,系统提供的数据分析和可视化功能能够帮助从业者更好地了解市场动态、用户需求变化和影片表现情况,为内容制作和营销策略制定提供数据支撑;对于普通用户来说,个性化推荐功能能够帮助发现符合个人喜好的优质影片,节省筛选时间并拓展观影视野,具有显著的实用价值和社会效益。
2、电影数据分析系统-研究内容
1、电影数据分析系统需求分析与架构设计:深入调研当前电影信息平台的功能局限性和用户体验痛点,通过网络问卷、用户访谈等方式收集观影群体的个性化需求和功能期望。基于Django框架设计系统整体技术架构,采用前后端分离的开发模式构建可扩展的服务体系,制定MySQL数据库设计方案和RESTful API接口规范。运用UML建模工具绘制系统用例图、类图、时序图等设计文档,明确用户角色权限划分和业务流程逻辑;同时规划Hadoop+Spark分布式计算架构,设计数据存储和处理策略,确保系统能够高效处理海量电影数据并支持实时分析需求。
2、网络爬虫系统开发与数据采集实现:构建基于Python的分布式爬虫系统,针对豆瓣电影、猫眼票房、时光网等主流平台设计数据采集策略。开发多线程爬虫程序,实现电影基础信息、用户评分、评论内容、票房数据等多维度信息的自动化获取;建立反爬虫机制应对方案,通过IP代理池、请求头伪装、访问频率控制等技术手段确保数据采集的稳定性和持续性。设计数据清洗和预处理模块,对爬取的原始数据进行去重、格式标准化、异常值处理等操作,建立数据质量监控机制,确保入库数据的准确性和完整性。
3、大数据处理与推荐算法系统构建:基于Hadoop分布式文件系统搭建海量电影数据的存储平台,利用Spark计算引擎实现数据的并行处理和实时分析。开发协同过滤推荐算法,通过分析用户观影历史、评分行为和偏好特征,构建用户-电影评分矩阵和相似度计算模型;实现基于用户的协同过滤和基于物品的协同过滤两种推荐策略,通过机器学习方法优化推荐精度和覆盖率。建立推荐效果评估体系,采用召回率、准确率、多样性等指标衡量算法性能,设计A/B测试方案验证推荐系统的实际效果,为算法迭代优化提供数据支撑。
4、Web应用系统开发与功能模块实现:采用Django MVC架构开发Web应用后端,实现用户认证管理、电影信息展示、评论互动、收藏管理等核心业务功能。构建用户端界面,支持电影搜索筛选、详情浏览、在线评分、个人中心等功能模块;开发管理员后台系统,实现用户管理、电影信息维护、资讯内容发布、系统监控等管理功能。集成ECharts可视化组件构建数据大屏展示系统,通过柱状图、饼图、热力图等图表形式呈现电影评分分布、年代统计、热门排行等数据分析结果,为用户和管理者提供直观的数据洞察和决策参考。
5、系统集成测试与性能调优验证:完成各功能模块开发后,进行全系统集成联调测试,验证爬虫数据采集、推荐算法计算、Web界面交互等各环节的协调性和稳定性。设计包含单元测试、接口测试、性能压测、安全测试在内的综合测试方案,通过JMeter等工具模拟高并发访问场景,测试系统的响应速度和负载承受能力。针对数据库查询优化、缓存策略部署、静态资源压缩等方面进行性能调优,建立系统监控告警机制和异常恢复策略;同时进行用户体验测试和功能完整性验证,确保电影数据分析系统能够稳定运行并满足实际应用需求。
3、电影数据分析系统-开发技术与环境
1、开发环境: Python环境,pycharm,mysql(5.7或者8.0)
2、技术栈:Python+Djingo+爬虫,hadoop+spark
4、电影数据分析系统-功能介绍
2个角色:用户/管理员(亮点:爬虫、大屏可视化、协同过滤推荐算法)
用户:登录注册、电影资讯、查看电影信息、评论电影、我的收藏、大屏可视化(电影名称、评分区间、五星数、电影信息总数、年代)
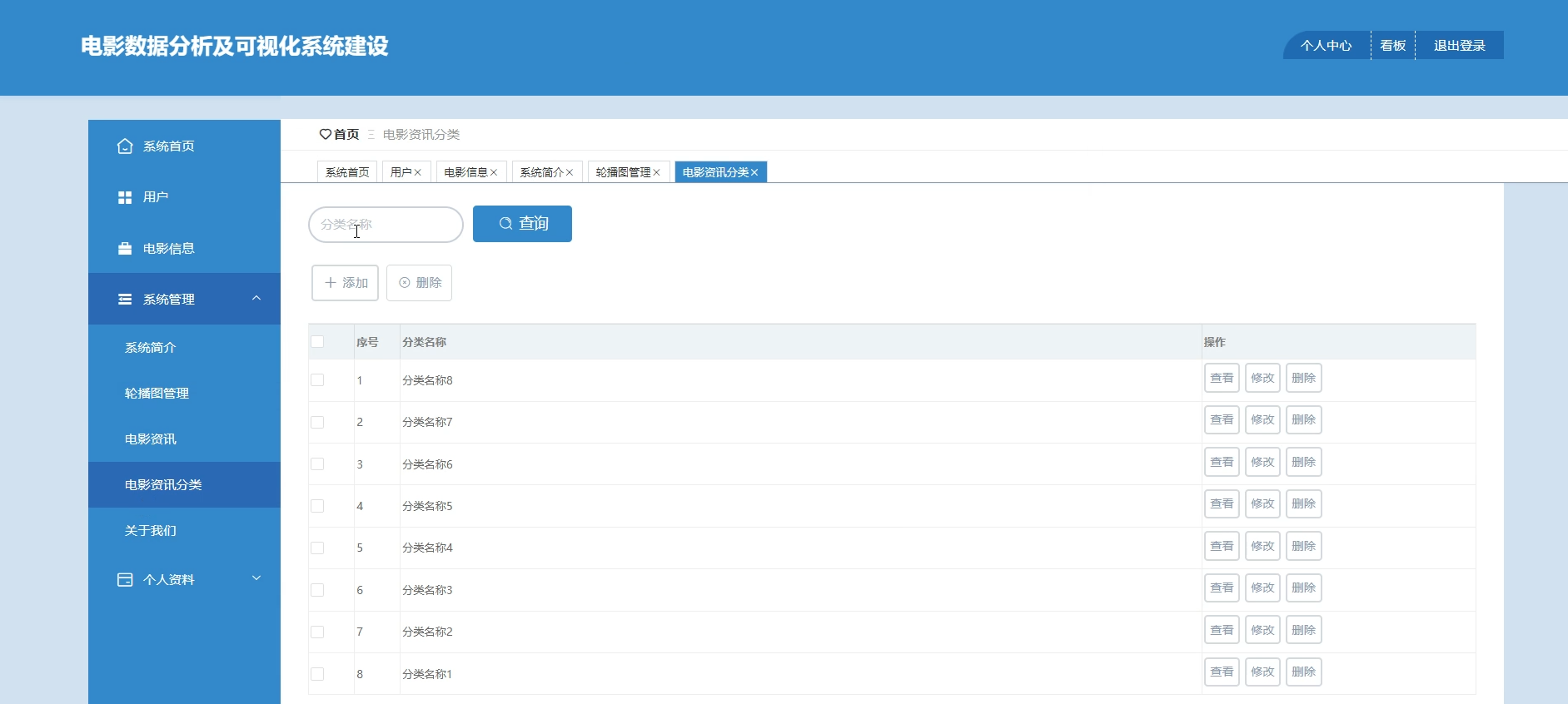
管理员:用户管理、电影信息管理、系统管理、电影资讯分类
5、电影数据分析系统成果展示
5.1演示视频
26届大数据毕业设计选题推荐| (基于django豆瓣电影数据分析及可视化系统 猫眼电影电视剧分析 票房预测系统 电影推荐系统)
5.2演示图片
1、用户端页面:
☀️登录注册☀️
☀️查看电影信息☀️
☀️电影资讯☀️
☀️我的收藏☀️
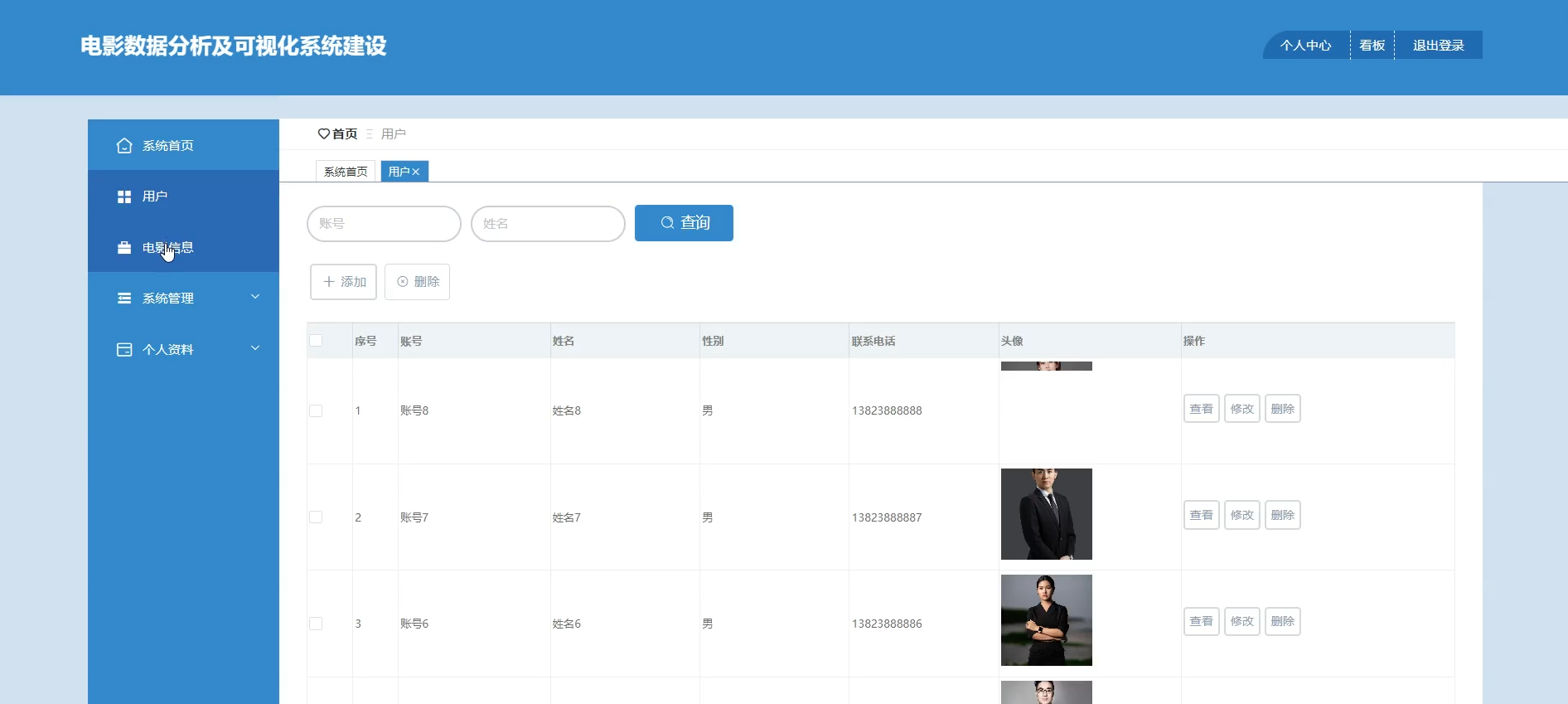
2、管理员端页面:
☀️用户管理☀️
☀️电影信息管理☀️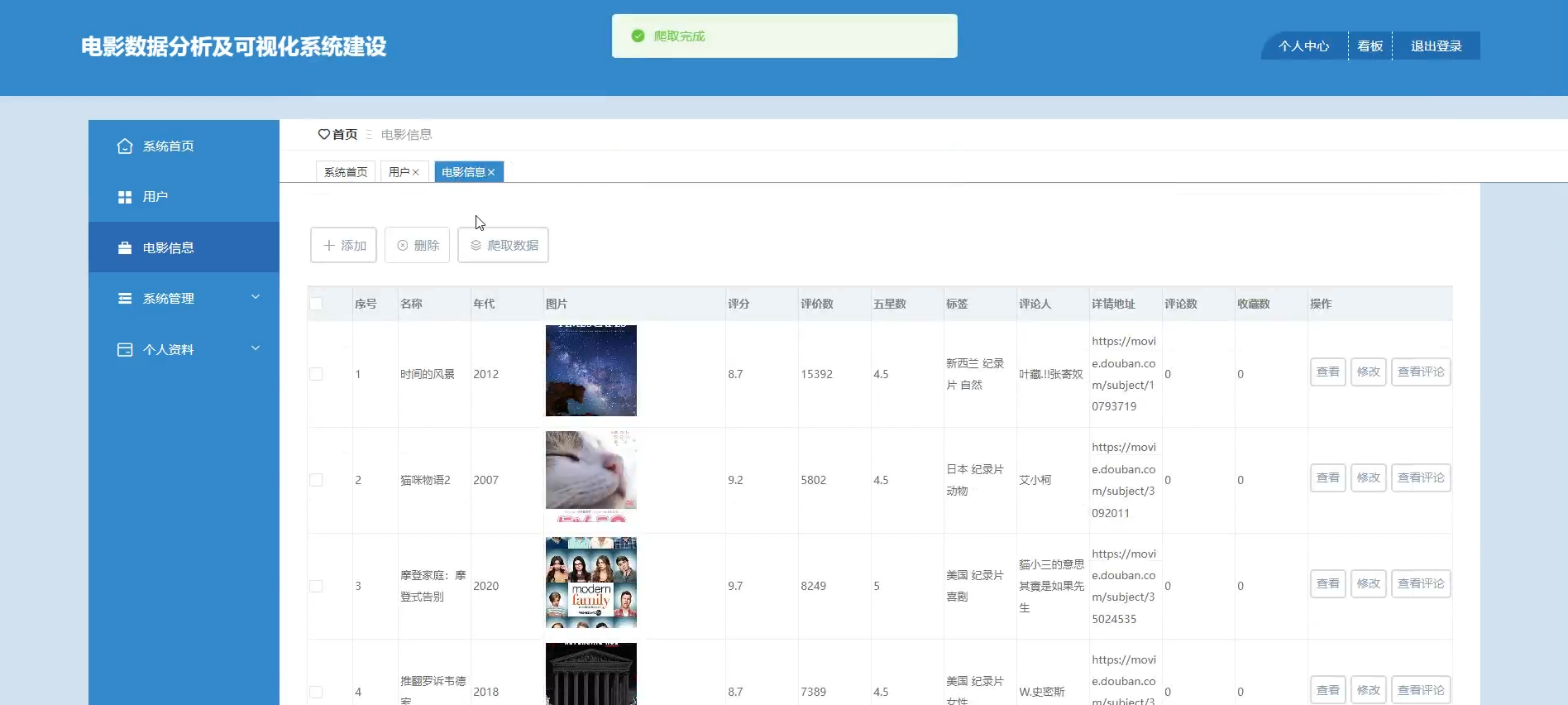
☀️电影资讯分类管理☀️
☀️数据可视化☀️

微信小程序智慧物业系统-代码展示
1.数据爬虫【代码如下(示例):】
class MovieSpider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive',
'Referer': 'https://movie.douban.com/'
}
# 用户代理池
self.user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:89.0) Gecko/20100101 Firefox/89.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15'
]
self.session = requests.Session()
self.movie_queue = Queue()
# 数据库配置
self.db_config = {
'host': 'localhost',
'database': 'movie_analysis',
'user': 'root',
'password': 'your_password'
}
def get_random_headers(self):
"""获取随机请求头"""
headers = self.headers.copy()
headers['User-Agent'] = random.choice(self.user_agents)
return headers
def get_movie_list(self, start=0, limit=20, sort='U'):
"""
获取豆瓣电影列表
start: 起始位置
limit: 每页数量
sort: 排序方式 U=按热度 T=按时间 S=按评价
"""
url = 'https://movie.douban.com/j/search_subjects'
params = {
'type': 'movie',
'tag': '热门',
'sort': sort,
'page_limit': limit,
'page_start': start
}
try:
response = self.session.get(url, params=params, headers=self.get_random_headers())
if response.status_code == 200:
data = response.json()
return data.get('subjects', [])
else:
logger.error(f"获取电影列表失败,状态码: {response.status_code}")
return []
except Exception as e:
logger.error(f"获取电影列表异常: {e}")
return []
def get_movie_detail(self, movie_id):
"""获取电影详细信息"""
url = f'https://movie.douban.com/subject/{movie_id}/'
try:
time.sleep(random.uniform(1, 3)) # 随机延时
response = self.session.get(url, headers=self.get_random_headers())
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
movie_info = self.parse_movie_detail(soup, movie_id)
return movie_info
else:
logger.error(f"获取电影详情失败,状态码: {response.status_code}, 电影ID: {movie_id}")
return None
except Exception as e:
logger.error(f"获取电影详情异常: {e}, 电影ID: {movie_id}")
return None
def parse_movie_detail(self, soup, movie_id):
"""解析电影详细信息"""
movie_info = {'id': movie_id}
try:
# 电影标题
title_element = soup.find('span', property='v:itemreviewed')
movie_info['title'] = title_element.text.strip() if title_element else ''
# 评分
rating_element = soup.find('strong', class_='ll rating_num')
movie_info['rating'] = float(rating_element.text.strip()) if rating_element and rating_element.text.strip() != '' else 0
# 评价人数
rating_people = soup.find('a', class_='rating_people')
if rating_people:
people_text = rating_people.text.strip()
people_num = re.findall(r'\d+', people_text)
movie_info['rating_people'] = int(people_num[0]) if people_num else 0
else:
movie_info['rating_people'] = 0
# 电影信息
info_element = soup.find('div', id='info')
if info_element:
info_text = info_element.get_text()
2.数据清洗【代码如下(示例):】
class MovieDataCleaner:
def __init__(self, db_config):
self.db_config = db_config
self.connection = None
# 初始化停用词
self.stop_words = self.load_stop_words()
# 评分映射字典
self.rating_mapping = {
'力荐': 5, '推荐': 4, '还行': 3, '较差': 2, '很差': 1,
'五星': 5, '四星': 4, '三星': 3, '二星': 2, '一星': 1
}
# 国家名称标准化映射
self.country_mapping = {
'美国': '美国', 'USA': '美国', 'United States': '美国',
'中国大陆': '中国', '中国': '中国', 'China': '中国',
'香港': '中国香港', 'Hong Kong': '中国香港',
'台湾': '中国台湾', 'Taiwan': '中国台湾',
'日本': '日本', 'Japan': '日本',
'韩国': '韩国', '南韩': '韩国', 'South Korea': '韩国',
'英国': '英国', 'UK': '英国', 'United Kingdom': '英国',
'法国': '法国', 'France': '法国',
'德国': '德国', 'Germany': '德国',
'意大利': '意大利', 'Italy': '意大利',
'西班牙': '西班牙', 'Spain': '西班牙',
'俄罗斯': '俄罗斯', 'Russia': '俄罗斯'
}
def load_stop_words(self):
"""加载停用词表"""
stop_words = {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '一', '一个', '上', '也', '很', '到', '说', '要', '去', '你', '会', '着', '没有', '看', '好', '自己', '这', '来', '么', '个', '还', '可以', '这个', '现在', '什么', '知道', '那', '能', '但是', '只是', '这样', '我们', '没', '可能', '如果', '觉得', '应该', '感觉', '真的', '那个', '就是', '有点', '不是', '比较', '或者', '以后', '时候', '因为', '所以', '虽然', '但是', '然后', '不过', '还是', '已经', '开始', '完全', '非常', '特别', '确实', '可是', '而且', '另外', '当然', '不错', '太', '挺', '蛮', '相当', '还好', '一般', '普通', '平常', '正常', '简单', '复杂', '容易', '困难', '重要', '主要', '关键', '基本', '大概', '可能', '或许', '也许', '大概', '估计', '应该', '肯定', '绝对', '完全', '彻底', '根本', '从来', '一直', '总是', '经常', '有时', '偶尔', '很少', '几乎', '差不多', '基本上'
}
return stop_words
def connect_database(self):
"""连接数据库"""
try:
self.connection = mysql.connector.connect(**self.db_config)
logger.info("数据库连接成功")
except Error as e:
logger.error(f"数据库连接失败: {e}")
raise
def close_database(self):
"""关闭数据库连接"""
if self.connection and self.connection.is_connected():
self.connection.close()
logger.info("数据库连接已关闭")
def load_data_from_db(self, table_name, limit=None):
"""从数据库加载数据"""
try:
query = f"SELECT * FROM {table_name}"
if limit:
query += f" LIMIT {limit}"
df = pd.read_sql(query, self.connection)
logger.info(f"从表 {table_name} 加载了 {len(df)} 条数据")
return df
except Exception as e:
logger.error(f"加载数据失败: {e}")
return pd.DataFrame()
def clean_movie_title(self, title):
"""清洗电影标题"""
if pd.isna(title) or title == '':
return ''
# 去除多余空格和特殊字符
title = re.sub(r'\s+', ' ', str(title).strip())
# 去除常见的多余信息
patterns_to_remove = [
r'\(.*?\)', # 去除括号内容
r'【.*?】', # 去除中文方括号内容
r'\[.*?\]', # 去除英文方括号内容
r'第\d+季', # 去除季数信息
r'Season\s*\d+', # 去除英文季数
r'S\d+E\d+', # 去除剧集编号
]
clean_title = title
for pattern in patterns_to_remove:
clean_title = re.sub(pattern, '', clean_title, flags=re.IGNORECASE)
# 最终清理
clean_title = re.sub(r'\s+', ' ', clean_title.strip())
return clean_title
def clean_rating(self, rating):
"""清洗评分数据"""
if pd.isna(rating):
return 0.0
微信小程序智慧物业系统-结语(文末获取源码)
💕💕
java精彩实战毕设项目案例
小程序精彩项目案例
Python精彩项目案例
💟💟如果大家有任何疑虑,或者对这个系统感兴趣,欢迎点赞收藏、留言交流啦!
💟💟欢迎在下方位置详细交流。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 27
27 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)