利用PCA-PCR主成分回归分析预测模型,适用于光谱等回归分析建模
利用PCA-PCR的主成分回归分析预测模型,特别适用于光谱等回归分析建模
光谱分析这玩意儿搞建模的都知道有多酸爽——动辄上千个波长点,数据维度高得能让人头皮发麻。上个月在实验室倒腾近红外光谱数据时,师兄甩过来一句"试试主成分回归呗",结果一上手发现这组合拳确实有门道。
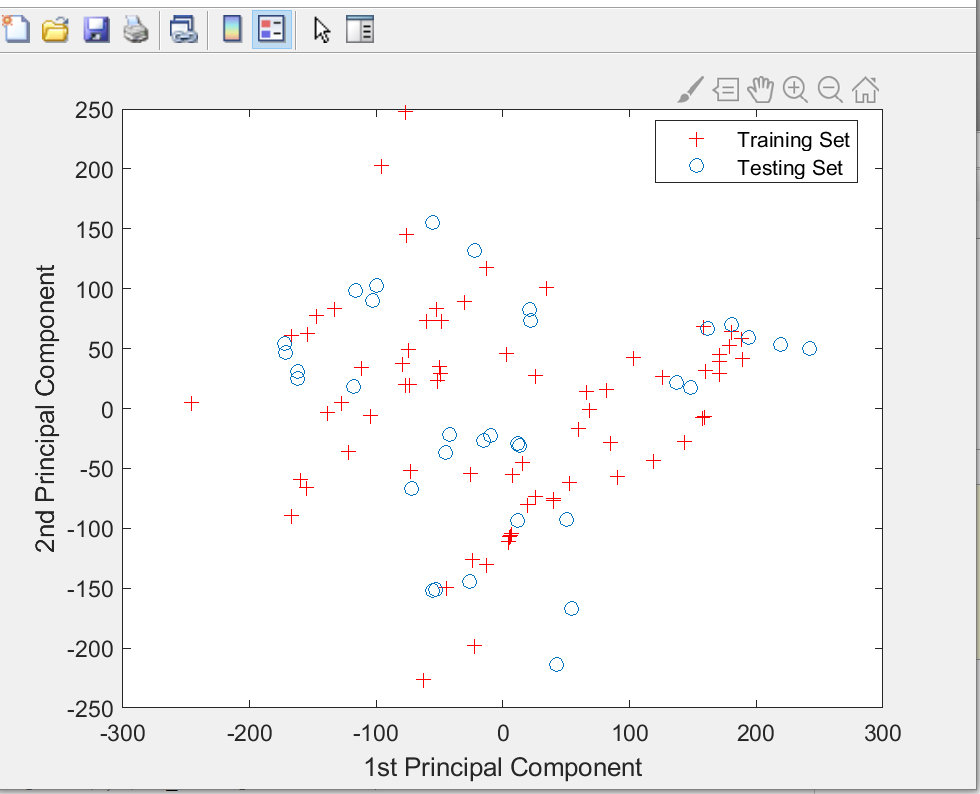
先扔个真实场景:我们实验室用近红外测了200个葡萄酒样本,每个样本在1000个波长点有吸光度数据,要预测酒精度含量。看着那200x1000的数据矩阵,常规线性回归直接扑街——变量数比样本还多,这不明摆着要过拟合么。
这时候就该主成分回归(PCR)登场了。核心思路其实挺聪明:先用PCA把光谱数据里的水分挤掉,留下真正有用的信息浓缩成几个主成分,再用这些浓缩精华去做回归。就像把一部长篇小说压缩成千字大纲,关键剧情一点没丢。
上代码实操一波,这里用Python的sklearn演示:
from sklearn.decomposition import PCA
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_val_score
import numpy as np
X = np.loadtxt('wine_spectra.csv')
y = np.loadtxt('alcohol_content.csv')
# 管道式操作:先标准化->PCA->线性回归
pcr_model = make_pipeline(
StandardScaler(),
PCA(n_components=6),
LinearRegression()
)
# 交叉验证看效果
scores = cross_val_score(pcr_model, X, y,
scoring='neg_root_mean_squared_error',
cv=5)
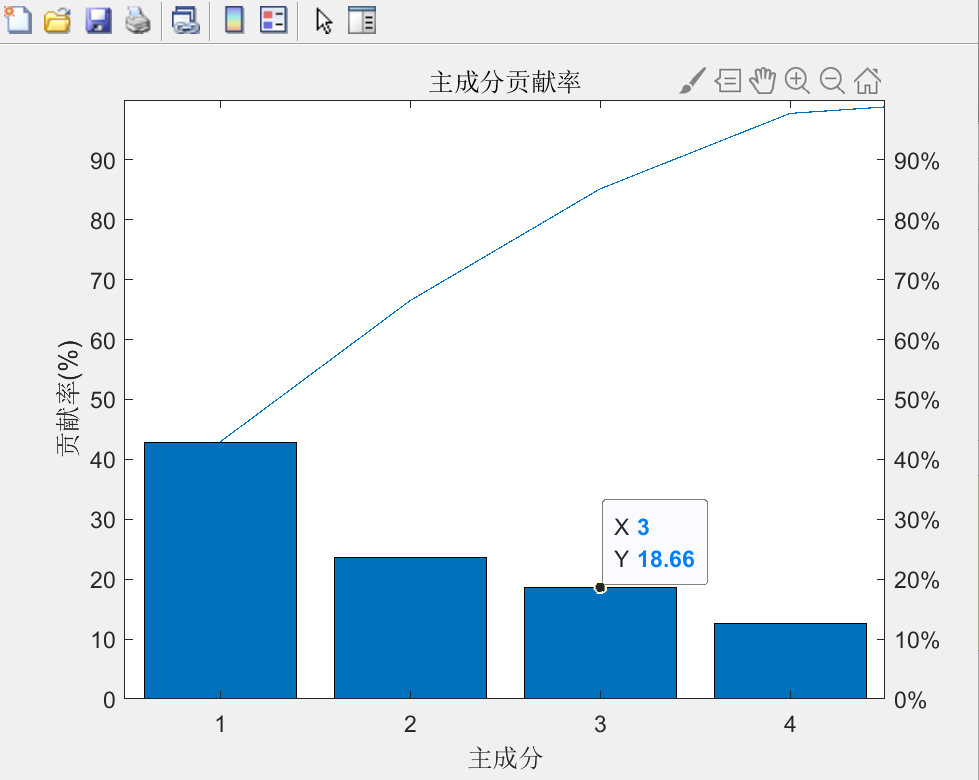
print(f'RMSE: {-scores.mean():.2f} ± {scores.std():.2f}')关键点在这PCA的组件数选多少。有人喜欢看碎石图,但实操中更常用累计方差解释率。比如下面这段代码能帮你可视化选择:
import matplotlib.pyplot as plt
pca = PCA().fit(X)
plt.plot(np.cumsum(pca.explained_variance_ratio_))
plt.axhline(0.85, color='r', linestyle='--')
plt.xlabel('主成分数量')
plt.ylabel('累计解释方差')通常掐在85%解释率的位置,但别太死板。有次做药物光谱分析时,发现第7主成分突然对预测指标特别敏感,这时候就得人为干预多留几个成分。
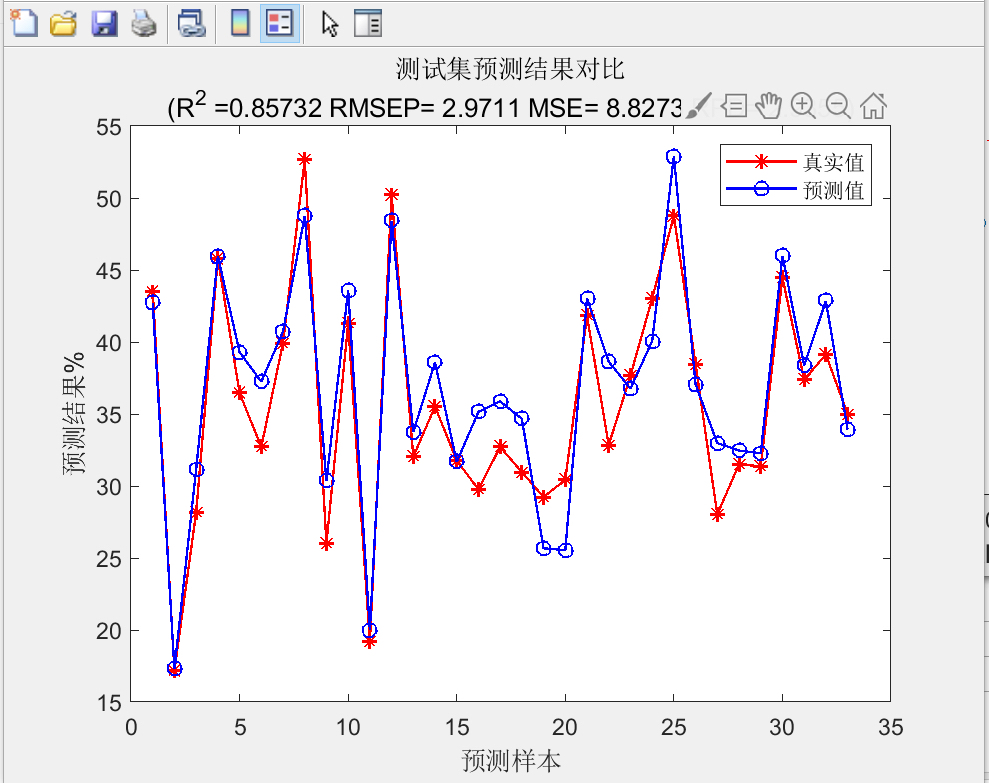
主成分回归最大的优势在于破除了多重共线性这个魔咒。光谱波长点之间高度相关,就像一群连体婴儿,普通回归根本分不清谁在干活。PCA把这些相关性打散重组,生成的正交主成分个个都是独立打工人。
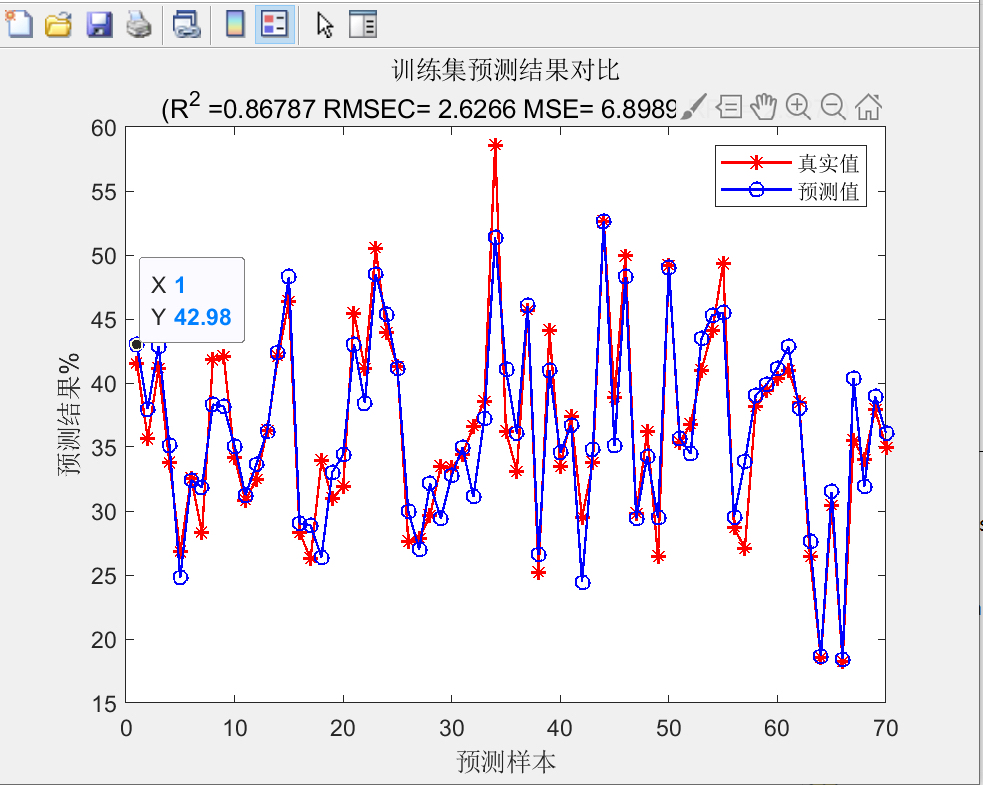
不过要注意标准化这个前置动作。PCA对量纲敏感得很,不做标准化的话,高方差特征会霸占主成分。曾经有萌新直接怼原始数据进去,结果前三个主成分全被某个异常波峰带偏,模型预测惨不忍睹。
最后来个效果对比才直观。拿同一组数据跑普通多元线性回归(MLR)和PCR,交叉验证的RMSE能差出两三个点。更狠的是当有新样本加入时,PCR模型的稳定性明显更好——毕竟那些噪声成分早就被PCA过滤掉了。
说到底,PCR就是给高维数据做了个智能压缩。既保留了关键信息,又避免了维度灾难。下次遇到光谱、色谱这些高维回归问题,不妨先让PCA打个头阵,没准儿就打开新世界了。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)