(论文速读)Snuffy:高效全切片图像分类器
ECCV 2024提出的Snuffy是一种高效全切片图像(WSI)分类器,解决了当前数字病理学中多实例学习(MIL)方法计算成本高的问题。该架构采用稀疏Transformer的新型MIL-pooling方法,结合参数高效的持续预训练(AdaptFormer)和生物学启发的稀疏模式(类相关/随机全局注意力+对角注意力),在保持高性能的同时显著降低计算需求。理论证明其稀疏模式具有紧密的概率锐界和通用逼
论文题目:Snuffy: Efficient Whole Slide Image Classifier(高效全切片图像分类器)
会议:ECCV2024
摘要:数字病理学中基于多实例学习(MIL)的全切片图像(WSI)分类面临着巨大的计算挑战。目前的方法大多依赖于广泛的自监督学习(SSL)来获得令人满意的性能,需要很长的训练周期和大量的计算资源。同时,由于从自然图像到WSI的域转移,没有预训练会影响性能。我们介绍了Snuffy架构,这是一种基于稀疏变压器的新型MIL-pooling方法,它通过有限的预训练减轻了性能损失,并使连续少量样本学习预训练成为一种竞争选择。我们的稀疏模式是为病理学量身定制的,并且在理论上被证明是一个通用逼近器,具有迄今为止稀疏变压器层数上最紧密的概率锐界。我们证明了Snuffy在CAMELYON16和TCGA肺癌数据集上的有效性,实现了卓越的WSI和斑块级精度。
代码可在https://github.com/jafarinia/snuffy上获得。
Snuffy - 高效的全切片图像分类方法
引言
在数字病理学领域,全切片图像(Whole Slide Image, WSI)分类是癌症诊断和预后的关键技术。然而,WSI的巨大尺寸(通常约150,000×150,000像素)给深度学习模型的训练带来了巨大挑战。来自伊朗谢里夫理工大学的研究团队最近提出了一种名为Snuffy的新架构,在保持高性能的同时显著降低了计算需求。
当前技术面临的挑战
计算成本高昂
目前最先进的WSI分类方法严重依赖于大规模自监督学习(SSL)预训练:
- RNN-MIL和HIPT需要数十TB的训练数据
- DSMIL和DGMIL需要数月的预训练时间
- DTFD-MIL需要超过100GB的系统内存
- DGMIL的预训练时间达到惊人的1,612,920分钟(约3年)
这些要求使得许多临床和研究机构难以部署和开发深度学习技术。
领域迁移问题
另一方面,缺乏预训练或预训练不足会导致性能下降,因为从自然图像数据集(如ImageNet-1K)到病理图像存在显著的领域差异。例如,论文中展示的CLAM和KAT在没有充分预训练的情况下AUC仅为0.576-0.825。
Snuffy的核心创新

1. 参数高效的持续预训练
Snuffy的第一个创新是采用参数高效微调(PEFT)方法,特别是AdaptFormer:
预训练流程:
ImageNet-1K预训练模型
↓ (冻结原始权重)
+ Adapter层(可训练)
↓ (MAE/DINO自监督学习)
病理学领域适配模型
关键优势:
- 只训练少量新增参数(Adapter)
- 利用ImageNet预训练的强大特征
- 在病理数据集上进行域适配
- 将预训练时间减少一个数量级
实验结果显示,Snuffy DINO Adapter仅需1,536个可训练参数和23.7分钟训练时间,即可在CAMELYON16数据集上达到0.936的AUC,而完整的DGMIL需要111.66百万参数和1,612,920分钟。
2. 生物学启发的稀疏Transformer架构
Snuffy MIL-pooling架构包含两个互补组件:
Max-pooling组件
识别最具判别性的patch,为Attention-pooling提供"类相关全局注意力"。
Attention-pooling组件
这是Snuffy的核心创新——Snuffy稀疏模式,由三种注意力机制组成:
-
类相关全局注意力(Λ_top)
- 从Max-pooling识别的top-k个最重要patch
- 这些patch与所有其他patch进行全局交互
- 类比:病理学家关注的关键可疑区域
-
随机全局注意力(Λ_r^l)
- 每层随机选择的patch子集
- 捕获组织微环境信息
- 类比:病理学家会查看周围组织上下文
-
对角注意力(k)
- 每个patch关注自身
- 保证原始嵌入信息不丢失
生物学动机:这一设计受到病理学家诊断行为的启发。病理学家在癌症检测时常依赖于识别"非相关组织出现在其他组织中"这一关键生物标志物,即使组织本身不显示明显的恶性特征。
3. 理论保证:通用逼近能力
论文不仅提出了新架构,还提供了严格的理论证明。定理2证明:
如果λ_r = O(n),其中n是patch数量,则Snuffy稀疏模式作为通用逼近器所需的层数L集中在n log 2/λ_r附近。
更精确地:
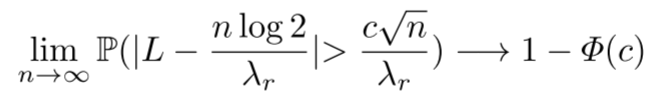
意义:
- 这是迄今为止稀疏Transformer层数要求的最紧概率界
- 只需要O(n log 2/λ_r)层,而不是之前研究建议的Ω̃(n)层
- 为Snuffy的高效性提供了理论支撑
实验结果:全面超越现有方法
CAMELYON16数据集:新的SOTA
CAMELYON16是病理学领域的标准benchmark,被称为"大海捞针"数据集,因为肿瘤区域往往很小且分散。
Exhaustive Snuffy家族的表现:
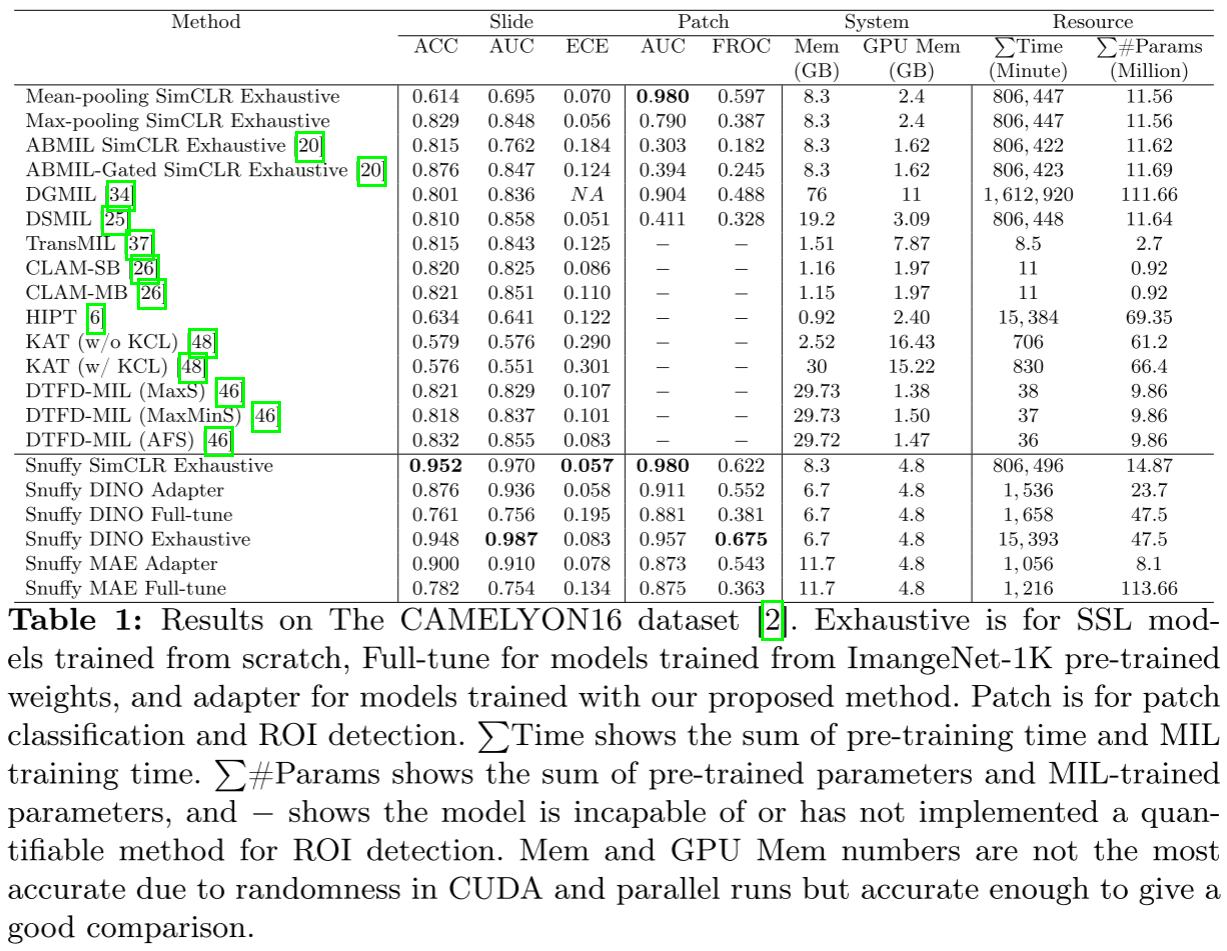
| 模型 | WSI AUC | WSI ACC | Patch AUC | FROC | 训练时间(分钟) |
|---|---|---|---|---|---|
| Snuffy DINO Exhaustive | 0.987 | 0.948 | 0.957 | 0.675 | 15,393 |
| Snuffy SimCLR Exhaustive | 0.970 | 0.952 | 0.980 | 0.622 | 806 |
| DGMIL (最佳基线) | 0.836 | 0.801 | 0.904 | 0.488 | 1,612,920 |
| DTFD-MIL AFS | 0.855 | 0.832 | - | - | 38 |
Efficient Snuffy家族的表现(PEFT微调):
| 模型 | WSI AUC | 训练时间(分钟) | 可训练参数(M) |
|---|---|---|---|
| Snuffy DINO Adapter | 0.936 | 23.7 | 1.54 |
| Snuffy MAE Adapter | 0.910 | 8.1 | 1.06 |
关键发现:
- 性能优越:Snuffy DINO Exhaustive的WSI AUC (0.987)和FROC (0.675)创造了新的SOTA
- 效率惊人:Snuffy DINO Adapter用1.54M参数和23.7分钟达到0.936 AUC,而DGMIL需要111.66M参数和1,612,920分钟
- 资源友好:Snuffy只需8.3-11.7GB内存,而DTFD-MIL需要29.7GB,KAT需要30GB
- 校准性好:ECE为0.057-0.083,表明模型的预测置信度与实际准确率高度一致,这对临床应用至关重要
TCGA肺癌数据集
在包含1042个WSI(530个LUAD和512个LUSC)的TCGA肺癌数据集上:
- ACC: 0.947(超越所有基线,第二名DGMIL为0.920)
- AUC: 0.972(与KAT w/ KCL的0.971相当,优于HIPT的0.952)
经典MIL数据集
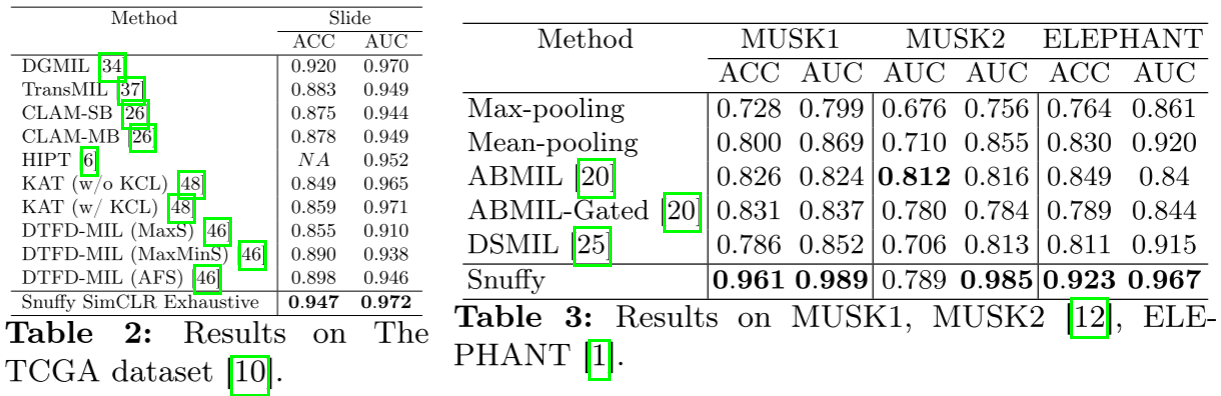
为验证架构的通用性,论文在三个经典MIL数据集上进行了测试:
| 数据集 | Snuffy ACC | Snuffy AUC | 最佳基线ACC | 最佳基线AUC |
|---|---|---|---|---|
| MUSK1 | 0.961 | 0.989 | 0.831 (ABMIL-Gated) | 0.869 (Mean-pooling) |
| MUSK2 | 0.789 | 0.985 | 0.812 (ABMIL) | 0.855 (Mean-pooling) |
| ELEPHANT | 0.923 | 0.967 | 0.849 (ABMIL) | 0.920 (Mean-pooling) |
这证明了Snuffy作为通用MIL-pooling架构的有效性。
消融实验:验证设计选择
深度影响
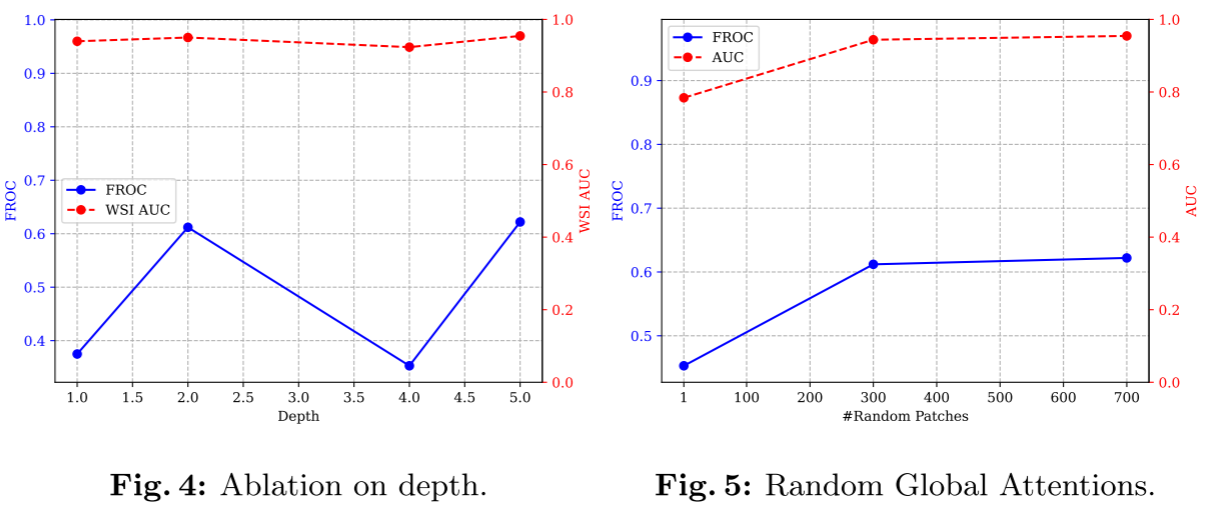
| 层数 | FROC | WSI AUC |
|---|---|---|
| 1 | 0.613 | 0.971 |
| 2 | 0.622 | 0.970 |
| 4 | 0.625 | 0.975 |
| 5 | 0.643 | 0.978 |
随着深度增加,性能略有提升,与理论预测一致。有趣的是,即使单层也表现良好(FROC 0.613),这缩小了理论要求与实践之间的差距。
随机全局注意力数量
| λ_r | FROC | AUC |
|---|---|---|
| 1 | 0.537 | 0.909 |
| 300 | 0.648 | 0.972 |
| 700 | 0.622 | 0.970 |
性能随λ_r增加而提升,但超过1000后收益递减,符合理论洞察。
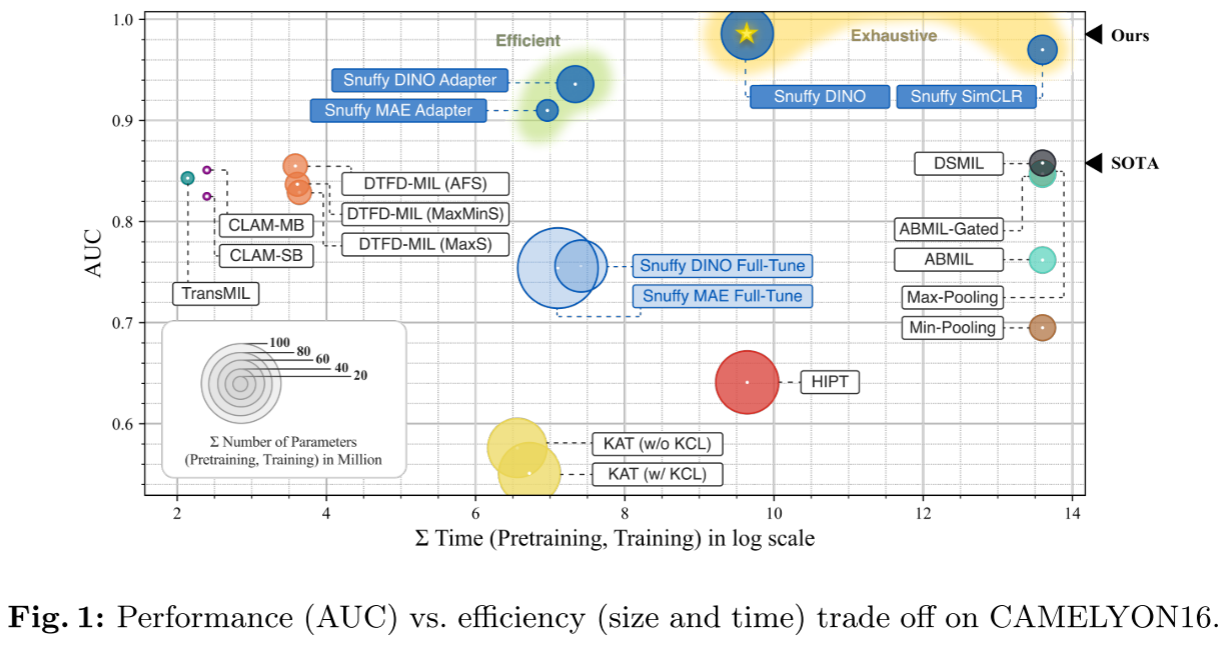
效率vs性能权衡分析
论文提供了一个非常直观的可视化(Figure 1),展示了不同方法在性能(AUC)和效率(训练时间)之间的权衡:
效率梯队:
- Ours区域(Snuffy家族):高AUC (0.91-0.99) + 短训练时间
- SOTA区域(DSMIL, ABMIL-Gated等):中等AUC (0.76-0.86) + 中等时间
- MOTA区域(DGMIL, HIPT):高AUC但需要极长训练时间
Snuffy成功地将"高性能"和"高效率"这两个通常相互矛盾的目标结合在一起。
可视化:ROI检测能力
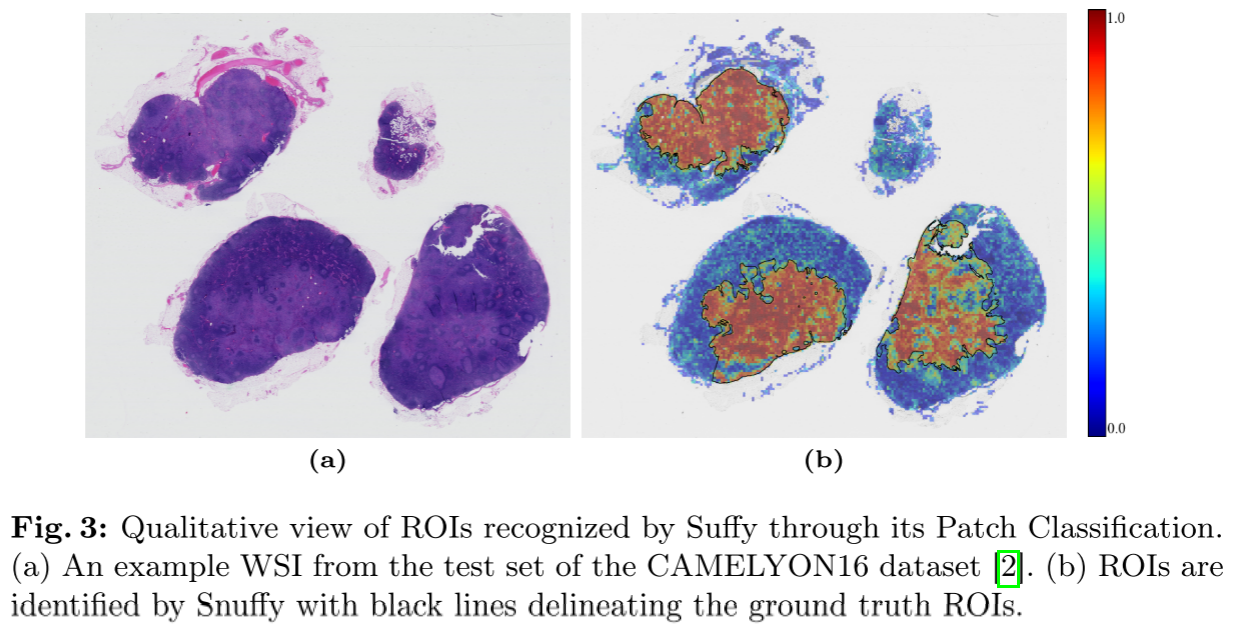
论文展示了Snuffy在CAMELYON16测试集上的定性ROI检测结果。通过patch分类得分的热图,可以清晰地看到:
- 肿瘤区域(红色/橙色)被准确识别
- 与ground truth标注(黑色轮廓)高度吻合
- 背景和正常组织(蓝色)被正确排除
这验证了Snuffy不仅在全局WSI分类上表现优异,在局部ROI检测上也非常精确。
方法论亮点
1. 两个Snuffy家族的互补性
Efficient Snuffy:
- 适用场景:资源受限环境、快速原型开发
- 优势:极低的计算成本(23.7分钟,1.54M参数)
- 性能:仍然达到competitive水平(AUC 0.936)
Exhaustive Snuffy:
- 适用场景:追求最佳性能的研究和临床应用
- 优势:新的SOTA性能(AUC 0.987, FROC 0.675)
- 成本:相对合理的训练时间(15,393分钟 vs DGMIL的1,612,920分钟)
2. Adapter vs Full-tune
实验发现,使用Adapter微调优于全参数微调:
| 方法 | WSI AUC | ECE |
|---|---|---|
| Snuffy DINO Adapter | 0.936 | 0.058 |
| Snuffy DINO Full-tune | 0.756 | 0.195 |
| Snuffy MAE Adapter | 0.910 | 0.078 |
| Snuffy MAE Full-tune | 0.754 | 0.134 |
Full-tune在病理数据上容易过拟合,而Adapter通过参数约束实现了更好的泛化。
3. SSL方法选择
DINO略优于MAE和SimCLR:
- DINO Exhaustive: AUC 0.987
- SimCLR Exhaustive: AUC 0.970
- MAE Adapter: AUC 0.910
但SimCLR在patch-level指标上表现最好(Patch AUC 0.980)。
为什么现有方法表现不佳?
论文提供了深入的分析:
HIPT的问题
- 依赖两次顺序降维(通过DINO预训练)
- 错误累积严重影响最终分类器
- 对数据饥渴的ViT而言,CAMELYON16的有限数据不足
DGMIL的ROI检测问题
- 依赖聚类生成伪标签
- 预设聚类数可能不准确
- 导致patch标注噪声
Mean-pooling的矛盾表现
- Patch AUC高(0.980)但WSI AUC低(0.695)
- 原因:使用instance-level MIL
- CAMELYON16肿瘤区域<10%,正常patch主导决策
- 导致高假阴性率
局限性与未来工作
论文诚实地指出了当前的局限:
- 理论与实践的差距:理论要求O(n log 2/λ_r)层,但单层实际表现很好
- SOTA仍需exhaustive训练:Efficient家族性能略低于Exhaustive
- 内存需求:理论保证需要较多层数,增加内存需求(虽然单层实际表现良好)
未来方向:
- 探索专为病理学定制的PEFT方法
- 开发更少资源密集的MIL-pooling方法
- 缩小稀疏Transformer的理论与实践差距
结论
Snuffy代表了WSI分类领域的重要进展,成功平衡了性能和效率:
关键贡献:
- ✅ 将预训练时间减少一个数量级(PEFT方法)
- ✅ 创新的生物学启发稀疏Transformer架构
- ✅ 最严格的理论保证(O(n log 2/λ_r)层界)
- ✅ 新的SOTA:WSI分类AUC 0.987,ROI检测FROC 0.675
- ✅ 通用性:在多个数据集上验证有效
实用价值:
- 降低了临床和研究机构的部署门槛
- 提供了两个家族满足不同需求
- 优秀的校准性能(ECE低)适合临床应用
对于病理学AI研究者和临床应用开发者来说,Snuffy提供了一个强大而实用的工具,使高性能WSI分类变得更加accessible。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 19
19 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)