基于梯度下降的浅层神经网络分类数据—基本算法模型与数学公式准备
深度学习入门——基于梯度下降的浅层神经网络分类数据—基本算法模型与数学公式准备学习记录自:deeplearning.ai-andrewNG-master一、浅层神经网络的基本概念1.1 基本术语及运算一个简单的浅层神经网络如下图所示:其中x1、x2、x3所在的层次称为输入层,中间的4个单元组成隐藏层,最右边的一个单元组成输出层,如图所示,y ̂即为该神经网络的输出。上图展示了神经网络在传播时的计算
深度学习入门——基于梯度下降的浅层神经网络分类数据—基本算法模型与数学公式准备
学习记录自:deeplearning.ai-andrewNG-master
一、浅层神经网络的基本概念
1.1 基本术语及运算
一个简单的浅层神经网络如下图所示: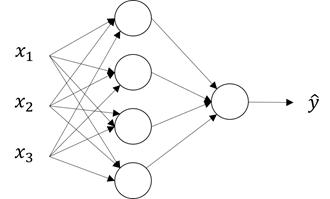
其中x1、x2、x3所在的层次称为输入层,中间的4个单元组成隐藏层,最右边的一个单元组成输出层,如图所示,y ̂即为该神经网络的输出。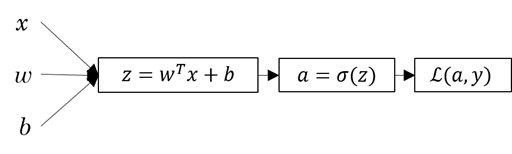
上图展示了神经网络在传播时的计算过程,其中以激活函数sigmoid为例,w和b为该神经网络的权重参数。
1.2常用的激活函数
激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。
这里我们针对常用的激活函数进行介绍,并给出激活函数的数学表达式及其导数。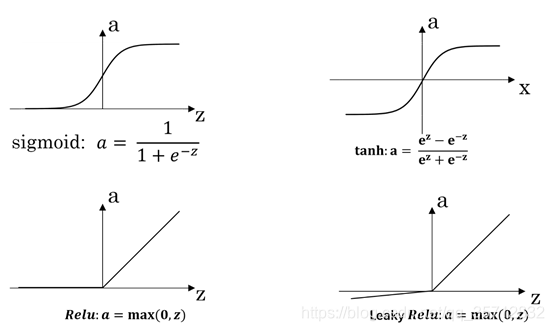
绝大多数情况下,我们一般选择Relu函数作为激活函数,除非实在特定情况下,如:处理二分分类问题时,会取选择sigmoid函数。在神经网络的传播过程中涉及优化问题,所以绝大多是情况会用到激活函数的导数,下面给出以上几个激活函数的导数。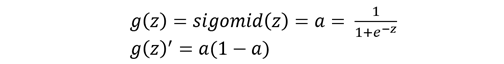
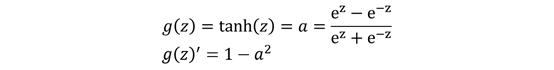
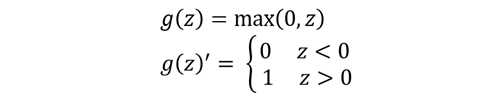
二、浅层神经网络中的传播与计算
2.1正向传播
正向传播主要计算本次传播的神经网络输出值与损失函数值,首先我们针对神经网络的输出进行讨论。
一个样本的输出值计算
下图中的神经网络里每个样本对应着特征x1、x2、x3,激活函数为sigmoid函数,样本的计算过程如图示。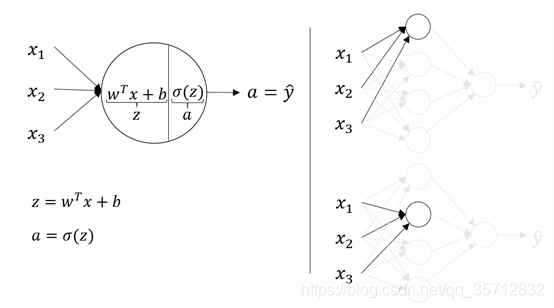
首先要逐个计算出隐藏层每个隐藏单元的输出值,然后再利用这些输出值计算输出层的激活函数值。
下图[]代表所在神经网络层次,下标表示该层次下的单元编号。
其中z为利用权重参数w、b计算得到的值,a为利用激活函数激活后的输出值。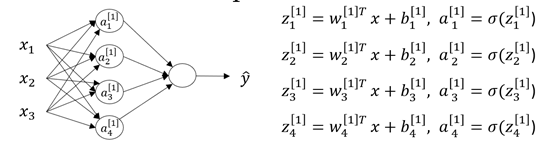
把以上数据向量化后,我们得到了单个样本正向传播时的神经网络输出值计算公式如下: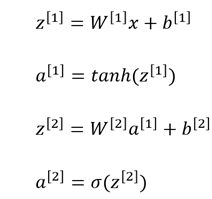
其中,上标[]表示所处的神经网络层次。
多个样本实现向量化
构造浅层神经网络,要做的对每个样本进行训练,所以在正向传播时,要对每个样本都进行输出计算,下面给出多个样本实现向量化之后的计算公式。
首先对样本输入值X进行向量化: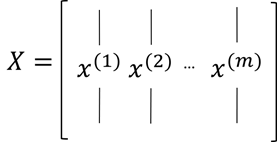
利用X计算得到神经网络第一层得输出值,并将输出值也向量化: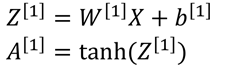
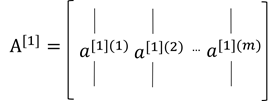
最后计算神经网络第二层得输出值: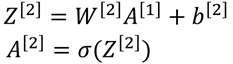
以上即为正向传播时的神经网络输出值的计算。
损失函数的计算
损失函数是对样本的标签值(y)和神经网络输出值(y ̂)的差异的描述,以下是其数学表达式: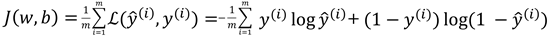
基于正向传播计算得到的输出值y ̂,即A^([2]),可以对损失函数进行求解。
2.2反向传播
反向传播主要计算的是损失函数对各个参数的偏导数,在优化损失函数和参数更新时,需要用到这些偏导数,所以极其重要。因为反向传播的理论推导比较困难,这里我们简单说明以下,并给出各个量的计算公式,并将其向量化。
构建的浅层神经网络的计算图如下图所示:
基于计算图我们给出单个样本在反向传播时各偏导数的计算公式: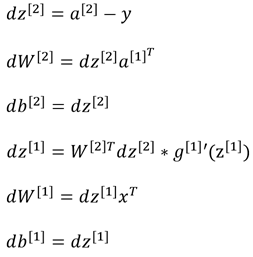
基于正向传播计算得到的数据结果,将其向量化,推导出多个样本在反向传播时各偏导数的计算公式: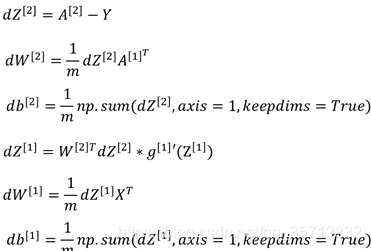
三、浅层神经网络的参数设定
3.1随机化参数
对于浅层神经网络里的权重参数,往往随机初始化的,考虑到为了使数值激活后,让激活函数值不要停留在平缓部分,在随机初始化时,往往让参数w和b较小。另外初始化的参数维度和神经网络的输入输出层的单元个数也是紧密相关的。
3.2 梯度下降与参数的更新
梯度的下降依赖于反向传播时计算得到的偏导数,因为损失函数为凸函数的原因,所以梯度下降总能使损失函数极小化,所以只用给定参数更新时的更新率即可完成梯度的下降与损失函数的优化。
这里对损失函数总能极小化作简单说明: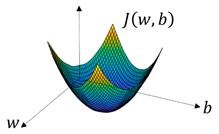
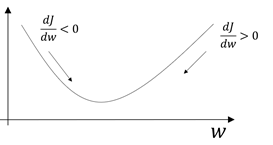
图示为损失函数与w,b的关系,因为是凹函数(优化问题中的凸函数定义与数学中不同),无论dJ/dw取值为正还是负,该函数总能下降到极小值附近。
关于参数的更新规则,下面给出它的更新公式:
θ= θ- α*dθ
其中,α为学习率。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)