利用python实现word文档的分割
摘要 本文介绍了使用Python实现Word文档按页分割的方法。该方法包括三个关键步骤:1)读取并分析文档XML结构,定位分页节点;2)为每个分页部分创建新文档;3)复制原文档的页面设置。相比传统方法,这种解决方案无需依赖商业软件,保留了原始格式,且支持批量处理。完整代码可通过文末链接获取。
一、缘起
最近工作中经常遇到这样一种情况,需要使用word的邮件合并功能批量生成一个多页的word文档,但生成的文档又需要单独拆分成一个单独的文档。 比如,邮件合并的常用场景,批量生成奖状。现在需要把这个多页文档的每一个页,单独分割出来,保存成多个新文档。
坚持能机器绝不手动的原则,尝试了VBA,奈何VBA不熟悉;又尝试了转换成pdf,然后利用wps自带的pdf分页,这个可以实现功能,但需要wps会员,并且输出为图片也不利于扩展。于是又想起老朋友 — python
二、尝试
之前使用过python-docx实现word里面的图片的批量排版,那再来用它试试吧!
思路: word文档分页,是靠分页符来实现分页,所以只需要按顺序读取整个文档,然后找到分页符,然后每个分页符位置拆分文档,就可以把内容拆开,再来一个for循环,把开的内容依次写入新的文档就大功告成了。
开始动手!
def split_docx_by_pages_basic(input_file, output_folder):
# 读取原始文档
doc = Document(input_file)
# 获取文件名
base_name = os.path.splitext(os.path.basename(input_file))[0]
# 获取文档中的所有段落
paragraphs = doc.paragraphs
page_count = 0
current_page_content = []
for i, paragraph in enumerate(paragraphs):
current_page_content.append(paragraph)
if paragraph.style.name == 'Page Break' or i == len(paragraphs) - 1:
# 创建新文档
new_doc = Document()
# 复制页面内容到新文档
for para in current_page_content:
new_para = new_doc.add_paragraph()
for run in para.runs:
new_run = new_para.add_run(run.text)
# 复制格式
new_run.bold = run.bold
new_run.italic = run.italic
new_run.underline = run.underline
new_run.font.name = run.font.name
new_run.font.size = run.font.size
# 保存新文档
output_file = os.path.join(output_folder, f"{base_name}_page_{page_count + 1}.docx")
new_doc.save(output_file)
print(f"已保存: {output_file}")
# 重置当前页面内容
current_page_content = []
page_count += 1
print(f"总计拆分为 {page_count} 个文档")
运行效果:
有点差强人意啊,不仅没有把文档分割,并且格式、页面面布局、印章等全乱了。
仔细查看了官方文档 python-docx以及其他资料,发现python-docx不直接支持页面操作,只能另辟蹊径了。
三、实现
黄天不负有心人,逛万999个博客后,终于发现 .docx文件的秘密了。原来 .docx文件它本质上是一个压缩的 ZIP 文件,内部包含 XML 文件,用于存储文档的文本、格式、图像等数据。把文件后缀名.docx改成.zip你就能看到他的真面目。
操作xml文件就简单多了,直接用最简单的正则匹配就好了。
1.读取文件、分析结构、找到分页节点
with zipfile.ZipFile(input_file, 'r') as zip_ref:
zip_ref.extractall(temp_dir)
print(" 1. 分析文档结构...")
# 读取并分析document.xml
doc_xml_path = os.path.join(temp_dir, 'word', 'document.xml')
with open(doc_xml_path, 'r', encoding='utf-8') as f:
xml_content = f.read()
body = root.find('w:body', namespaces)
# 获取所有段落
paragraphs = body.findall('w:p', namespaces)
print(f" 找到 {len(paragraphs)} 个段落/元素")
# 检测分页符
page_breaks = []
for i, para in enumerate(paragraphs):
# 检查分页符
br_elements = para.findall('.//w:br', namespaces)
for br in br_elements:
br_type = br.get(QName(namespaces['w'], 'type'))
if br_type == 'page':
page_breaks.append(i)
# 检查分节符
p_pr = para.find('w:pPr', namespaces)
if p_pr is not None:
sect_pr = p_pr.find('w:sectPr', namespaces)
if sect_pr is not None:
# 分节符作为分页点
page_breaks.append(i)
# 确定拆分点
if page_breaks:
print(f" 检测到 {len(page_breaks)} 个分页/分节符")
split_points = [0] + [pos + 1 for pos in page_breaks] + [len(paragraphs)]
2.每个部分创建文档、复制文档结构
for part_num in range(len(split_points) - 1):
start_idx = split_points[part_num]
end_idx = split_points[part_num + 1]
if start_idx >= end_idx:
continue
print(f" 创建第 {part_num + 1}/{len(split_points) - 1} 部分...")
# 创建临时目录
part_temp_dir = os.path.join(temp_dir, f'part_{part_num}')
os.makedirs(part_temp_dir, exist_ok=True)
# 完整复制文档结构
copy_docx_structure_complete(temp_dir, part_temp_dir)
# 创建当前部分的document.xml
create_part_document_xml_complete(
temp_dir, part_temp_dir,
paragraphs[start_idx:end_idx],
namespaces
)
3.复制页面设置
def copy_page_settings(source_doc, target_doc):
"""复制页面设置"""
try:
if source_doc.sections and target_doc.sections:
source_sec = source_doc.sections[0]
target_sec = target_doc.sections[0]
# 页边距
target_sec.top_margin = source_sec.top_margin
target_sec.bottom_margin = source_sec.bottom_margin
target_sec.left_margin = source_sec.left_margin
target_sec.right_margin = source_sec.right_margin
# 页面大小
target_sec.page_width = source_sec.page_width
target_sec.page_height = source_sec.page_height
except Exception as e:
print(f" 复制页面设置失败: {e}")
4.复制段落及其所有格式
def copy_paragraph_with_all_format(source_para, target_doc):
"""复制段落及其所有格式"""
try:
# 创建新段落
new_para = target_doc.add_paragraph()
# 复制段落格式
source_pf = source_para.paragraph_format
target_pf = new_para.paragraph_format
# 段前段后间距
target_pf.space_before = source_pf.space_before if source_pf.space_before is not None else Pt(0)
target_pf.space_after = source_pf.space_after if source_pf.space_after is not None else Pt(0)
# 缩进
for attr in ['left_indent', 'right_indent', 'first_line_indent']:
if hasattr(source_pf, attr):
value = getattr(source_pf, attr)
if value is not None:
setattr(target_pf, attr, value)
# 行间距
if hasattr(source_pf, 'line_spacing_rule'):
target_pf.line_spacing_rule = source_pf.line_spacing_rule
if hasattr(source_pf, 'line_spacing') and source_pf.line_spacing is not None:
target_pf.line_spacing = source_pf.line_spacing
# 对齐
if source_para.alignment:
new_para.alignment = source_para.alignment
# 复制运行
for run in source_para.runs:
new_run = new_para.add_run(run.text)
# 基本格式
new_run.bold = run.bold
new_run.italic = run.italic
new_run.underline = run.underline
# 字体
if run.font.name:
new_run.font.name = run.font.name
if run.font.size:
new_run.font.size = run.font.size
# 颜色
if run.font.color and run.font.color.rgb:
new_run.font.color.rgb = run.font.color.rgb
except Exception as e:
print(f" 复制段落失败: {e}")
target_doc.add_paragraph(source_para.text)
5.将目录压缩为docx文件
def create_zip_from_dir(source_dir, output_path):
"""将目录压缩为docx文件"""
with zipfile.ZipFile(output_path, 'w', zipfile.ZIP_DEFLATED) as zipf:
for root, dirs, files in os.walk(source_dir):
for file in files:
file_path = os.path.join(root, file)
arcname = os.path.relpath(file_path, source_dir)
zipf.write(file_path, arcname)
四、效果
完美拆分成四个文档了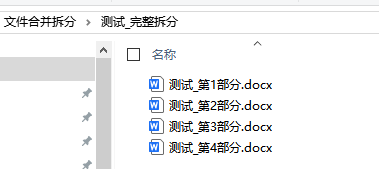
验证每个文档的内容、格式等是否变化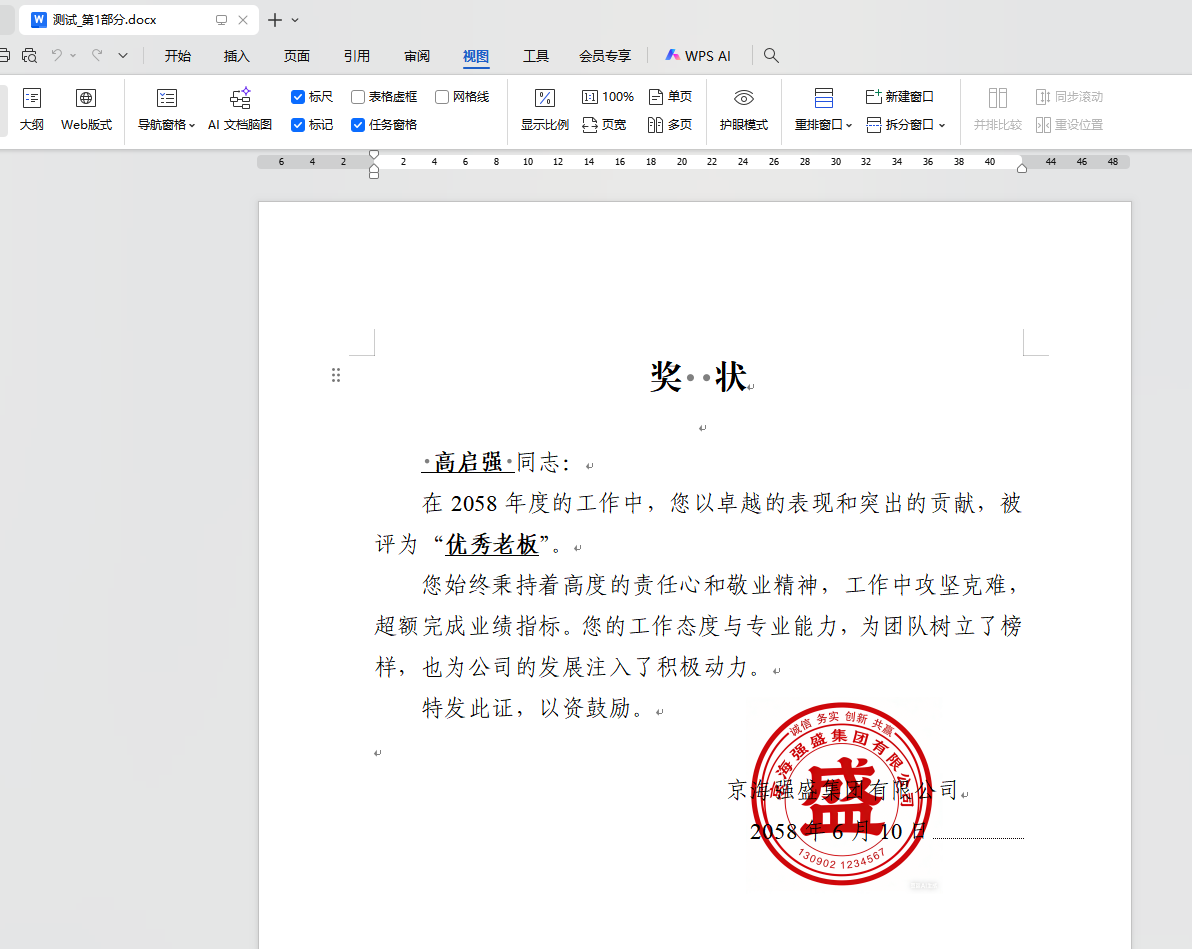
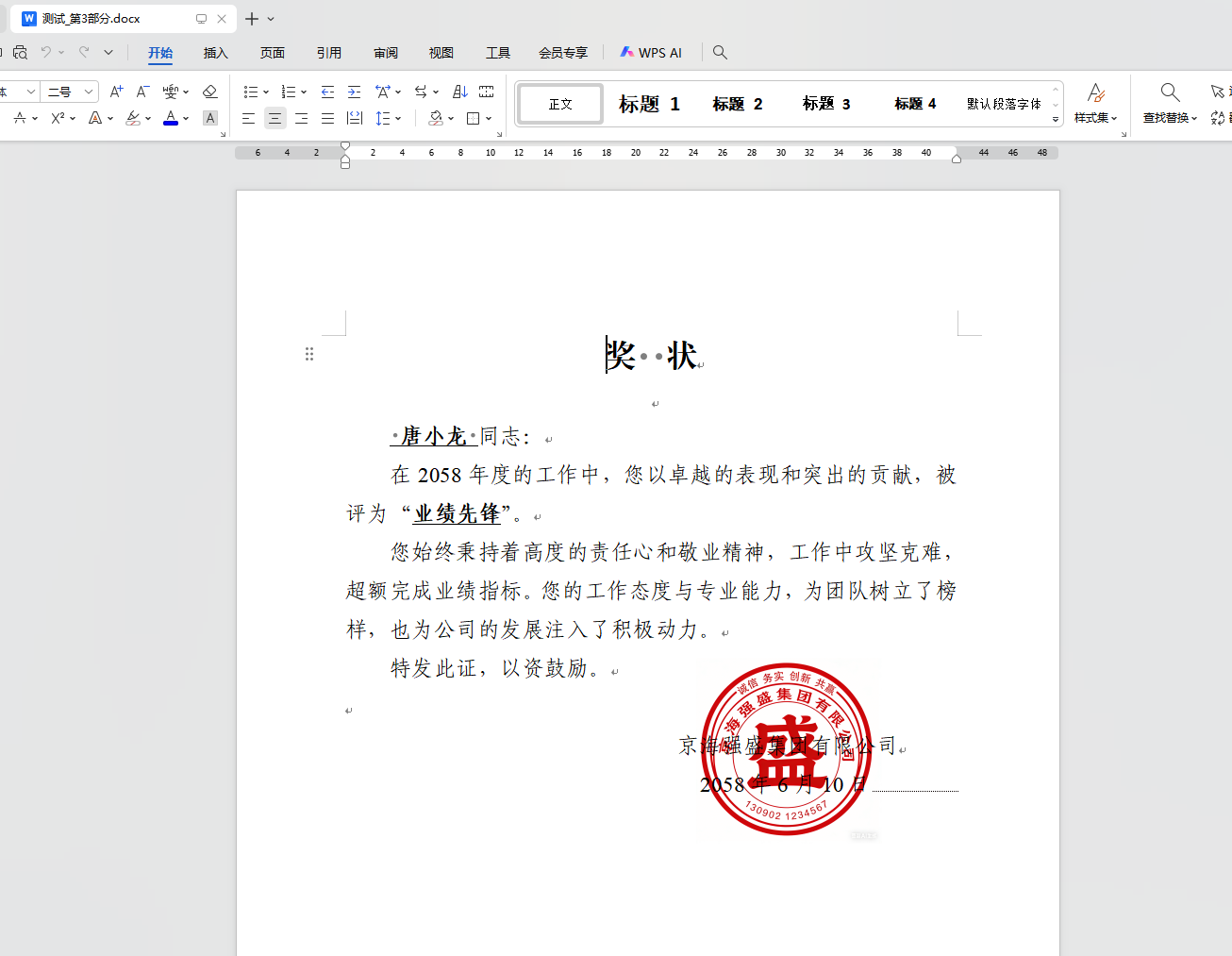
效果基本达标!
五、改进
此方法虽实现功能,但过程相对啰嗦,解析xml全靠正则,没啥技术含量,代码量稍大。后续可以尝试先把word转化成pdf文件,然后分割pdf,分割后在把pdf转成word。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)