论文智能分析问答系统设计:结合SpringBoot、Neo4j、Spark和朴素贝叶斯分类器
SpringBoot是一个开源的Java基础框架,旨在简化新Spring应用的初始搭建以及开发过程。它使用“约定优于配置”的原则,提供了一系列默认配置,让开发者能够快速启动并运行Web应用程序。SpringBoot整合了如SpringMVC、SpringData、SpringSecurity等多种Spring模块,同时支持内嵌如Tomcat、Jetty或Undertow等服务器。在数据管理的多维世

简介:本文介绍了基于SpringBoot后端框架、Neo4j图形数据库和Spark大数据处理框架的论文智能分析问答系统。系统采用朴素贝叶斯分类器对用户提问进行文本分析,并提供学术研究辅助。通过集成这些技术,系统能够高效地处理关联数据,并构建知识图谱,以提供智能问答服务。文章还对项目的详细组件进行了分析,为Java Web开发和大数据处理的学习者提供了宝贵的参考。 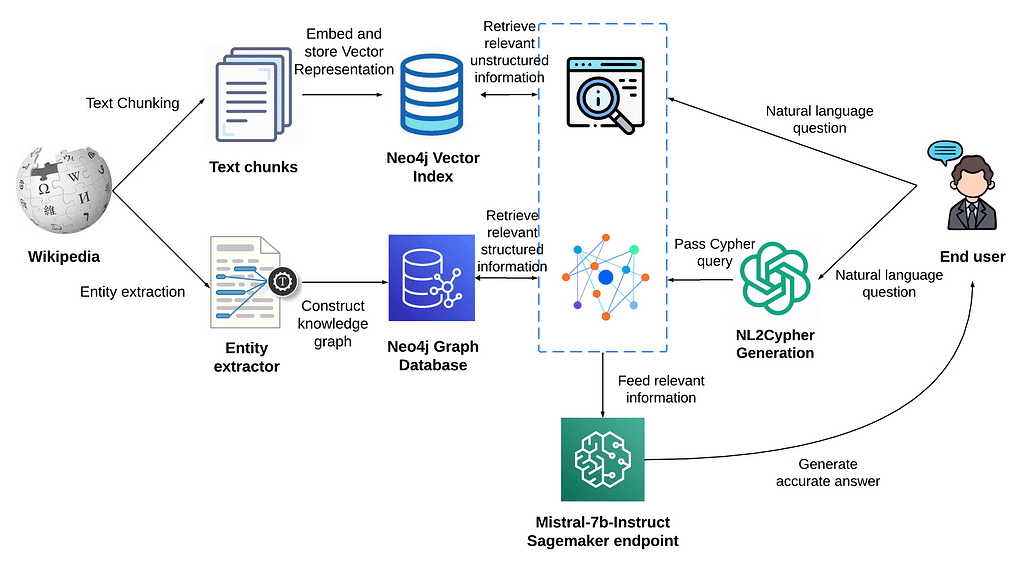
1. SpringBoot后端框架
1.1 简介SpringBoot
SpringBoot是一个开源的Java基础框架,旨在简化新Spring应用的初始搭建以及开发过程。它使用“约定优于配置”的原则,提供了一系列默认配置,让开发者能够快速启动并运行Web应用程序。SpringBoot整合了如SpringMVC、SpringData、SpringSecurity等多种Spring模块,同时支持内嵌如Tomcat、Jetty或Undertow等服务器。
1.2 SpringBoot的特性
- 独立运行 :SpringBoot应用无需外部依赖的Servlet容器,可以打包成一个独立的jar文件,通过java -jar运行。
- 自动配置 :SpringBoot根据添加的jar依赖,自动配置Spring和第三方库。
- 起步依赖 :简化构建配置,通过添加"starter"依赖来自动包含你需要的库。
1.3 SpringBoot在后端开发中的优势
SpringBoot使得开发者可以快速启动一个项目并专注业务逻辑的实现,而不必花费大量时间配置框架。它将大量的配置文件和模板工程化,极大的提高了开发效率,并且由于其轻量级的特性,也保证了应用的性能。
// 示例代码:一个简单的SpringBoot应用入口
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
在这个章节中,我们介绍了SpringBoot后端框架的基础知识,接下来将会深入探讨如何将SpringBoot与图形数据库Neo4j结合,实现高效的数据交互和管理。
2. 图形数据库Neo4j在智能系统中的应用
2.1 Neo4j图形数据库简介
2.1.1 图形数据库的基本概念
在数据管理的多维世界里,图形数据库作为一种特殊类型的数据库,它采用图形结构来存储数据。在图形数据库中,数据以节点(node)、关系(edge)和属性(property)的形式存在。节点表示实体或对象,关系表示实体之间的联系,属性则是节点或关系的附加信息。这种结构允许图形数据库在处理复杂的数据关系时表现出卓越的性能和灵活性,特别是在社交网络、推荐系统、生物信息学等领域。
图形数据库利用图论的概念,通过直观的图形表示,为数据建模带来了极大的便利。由于图结构天然适合表达实体之间的关系,因此在处理诸如“谁是某人的朋友的朋友?”这类查询时,图形数据库能够以极高的效率返回结果。
2.1.2 Neo4j的核心特性与优势
Neo4j是目前最流行的图形数据库之一,它提供了许多对开发者友好的特性,使得操作图形数据变得更为简单。Neo4j 的核心优势在于:
- 高性能: Neo4j 为图数据优化了存储和访问模式,使得关系追踪非常迅速。
- 事务完整性: 支持ACID事务,保证了数据的一致性和完整性。
- Cypher查询语言: 提供了一种声明式的图形查询语言,大大简化了数据检索和更新操作。
- 高可用性: Neo4j社区版和企业版都提供了高可用性解决方案,包括数据复制、故障转移等机制。
Neo4j的出现,为传统的数据库解决方案提供了另一种选择,特别是在需要高效处理大量复杂关系数据的场景中。它使得开发者可以专注于业务逻辑的实现,而无需担心底层数据结构和性能瓶颈。
2.2 Neo4j在后端数据管理中的角色
2.2.1 数据存储与查询优化
在后端数据管理中,Neo4j 提供了多种数据存储选项和查询优化策略。在存储方面,Neo4j 采用原生的图形存储机制,这意味着数据关系在存储层面上就得到了优化。由于数据的关联性是直接存储的,因此当查询复杂的关系时,Neo4j 能够在极短的时间内返回结果。
查询优化在Neo4j中也非常关键。图形查询语言Cypher是设计来专门处理图结构数据的,它支持模式匹配,可以让开发者以人类可读的方式编写复杂的查询。此外,Neo4j还支持索引和约束来优化查询性能,使得在处理大数据集时仍能保持高效的响应速度。
2.2.2 图形数据库与关系型数据库的对比
图形数据库和关系型数据库有着本质的区别,这些区别也导致了它们在处理不同类型的数据时各有优势。关系型数据库使用表格来存储数据,强调的是数据的结构化和规范化,适合处理静态的数据模型。相比之下,图形数据库更适合处理动态的、复杂的关系网络。
在性能方面,当数据模型中存在大量的连接关系时,图形数据库可以展现出更好的性能。例如,在社交网络分析、知识图谱构建等场景下,图形数据库可以更快地遍历和分析数据。而在事务密集型的应用中,如财务系统,关系型数据库通常表现更好。
2.3 实践:基于Neo4j的后端数据交互
2.3.1 RESTful API的设计与实现
在现代的Web应用中,RESTful API已成为服务端与客户端交互的标准方式。通过RESTful API,可以轻松地在Neo4j和前端应用之间传输数据。设计一个好的RESTful API需要考虑资源的表述、状态的转移以及无状态通信。这在Neo4j中通过利用Neo4j的HTTP API和Cypher查询语言来实现。
Neo4j的HTTP API为开发者提供了一套操作数据库的接口,允许开发者通过HTTP请求来创建、读取、更新和删除图中的数据。通过这种方式,任何支持HTTP请求的客户端都可以与Neo4j进行交互,这对于创建灵活的后端服务尤其有用。
2.3.2 Neo4j与SpringBoot的集成
SpringBoot作为一个广泛使用的后端开发框架,与Neo4j的集成非常自然。开发者可以通过Spring Data Neo4j模块,将Neo4j完全集成进SpringBoot应用中。这不仅简化了数据访问层的代码,还利用SpringBoot的自动配置、安全性和监控能力,使得整个应用开发过程更加高效。
集成Neo4j到SpringBoot应用中,通常涉及添加相应的依赖到项目中,并配置数据源连接。接下来,可以利用Spring Data的注解来定义实体类和它们之间的关系。此外,SpringBoot提供的自动配置功能可以进一步简化开发流程,例如自动配置事务管理、REST控制器等。
通过这些集成步骤,开发者可以创建出一个能够与Neo4j无缝交互的SpringBoot应用,同时保持应用的扩展性和维护性。
以上是第二章关于图形数据库Neo4j在智能系统中的应用的介绍。接下来的章节,我们将深入探讨Spark大数据处理技术以及朴素贝叶斯分类器在问答系统中的应用。这些章节将继续延续由浅入深的内容深度,包含丰富的操作步骤和详细代码解析,确保读者能够从理论到实践层面都有深刻的理解。
3. Spark大数据处理技术
3.1 Spark框架概述
3.1.1 Spark的核心组件介绍
Apache Spark是一个开源的大数据处理框架,它提供了一个快速且通用的数据处理引擎。Spark的核心组件包括:
- Spark Core:提供Spark的基本功能,包括任务调度、内存管理、错误恢复以及与存储系统交互的API等。
- Spark SQL:允许用户查询数据,无论是存储在Hive中的表格还是存储在HDFS中的文件。
- Spark Streaming:提供高吞吐量的数据流处理能力,用于实时分析。
- MLlib:机器学习库,包括各种机器学习算法和数据处理的工具。
- GraphX:用于图形计算的API和算法库,可以用来进行图的并行计算和图形算法的实现。
3.1.2 Spark与Hadoop的对比分析
Spark与Hadoop相比,在多个方面有显著优势:
- 运行速度:Spark基于内存计算,而Hadoop MapReduce是基于磁盘计算,因此Spark通常比Hadoop快100倍(在内存计算时)甚至更多。
- 算法支持:Spark支持更复杂的算法,如迭代算法和交互式算法,这对于机器学习和图处理等应用非常重要。
- 易用性:Spark的API设计得更加现代,易于使用,并且集成了Scala、Java、Python等多种语言。
然而,Hadoop在稳定性和成熟度方面仍有一定优势,尤其是在需要处理大量数据的场景中。此外,Hadoop的生态系统更为庞大,特别是在数据仓库、HDFS等方面。
3.2 Spark的数据处理能力
3.2.1 基于Spark的数据清洗
数据清洗是数据分析过程中重要的一步。在Spark中,数据清洗可以通过RDDs(弹性分布式数据集)来实现。下面是一个简单的例子:
// 加载数据
val rawDataset = sc.textFile("hdfs://path/to/input")
// 数据清洗:过滤掉不满足条件的数据行
val cleanDataset = rawDataset.filter(line => {
line.split(",").length == 4 && line.split(",")(2).matches("^[a-zA-Z]+$")
})
// 执行清洗操作
cleanDataset.collect().foreach(println)
在这个例子中,我们首先加载了数据集,然后使用 filter 函数过滤掉不符合条件的数据行。这里假设每行数据由逗号分隔,并且我们想要的数据行应该有4个字段,且第三个字段必须是字母字符。
3.2.2 Spark SQL与数据查询优化
Spark SQL提供了对结构化数据的处理能力,并可以执行SQL查询。对于数据查询优化,Spark SQL使用Catalyst优化器来优化查询计划,利用列式存储和编码技术提高性能。
SELECT customer_id, COUNT(*) AS num_orders
FROM orders
WHERE status = 'complete'
GROUP BY customer_id
ORDER BY num_orders DESC
在上面的SQL查询中,我们可能想要找出订单状态为“complete”的客户,并按照订单数量降序排列。为了优化这个查询,我们可以使用列式存储来减少对磁盘I/O的需求,并利用分区策略来提高并行处理能力。
3.3 实践:Spark在智能分析问答系统中的应用
3.3.1 数据流处理与实时分析
在构建智能分析问答系统时,实时分析用户查询和反馈是关键。Spark Streaming可以让开发者进行实时数据流处理。
import org.apache.spark.streaming._
// 创建一个StreamingContext,batch interval为1秒
val ssc = new StreamingContext(sc, Seconds(1))
// 从网络套接字读取数据流
val lines = ssc.socketTextStream("localhost", 9999)
// 计算每批次中数据的行数
val lineCounts = lines.count()
lineCounts.print()
// 开始计算流数据
ssc.start()
// 等待计算结束
ssc.awaitTermination()
在这个例子中,我们创建了一个StreamingContext,并通过网络套接字读取数据流。然后,我们计算每一批次的数据行数,并打印出来。
3.3.2 Spark与SpringBoot集成的实践案例
将Spark集成到SpringBoot项目中,可以通过RESTful API接收数据,并使用Spark进行处理。
@RestController
public class SparkController {
@Autowired
private JavaSparkContext sc;
@RequestMapping(value = "/processData", method = RequestMethod.POST)
public String processData(@RequestBody String data) {
// 创建RDD
JavaRDD<String> rdd = sc.parallelize(Collections.singletonList(data));
// 数据处理逻辑...
return "Processed data: " + result;
}
}
在这个简单的RESTful API例子中,我们创建了一个控制器来处理POST请求,接收的数据被转换为一个RDD进行处理。这可以作为数据流处理和实时分析的一个集成点。需要注意的是,实际的处理逻辑需要根据具体的业务需求来编写。
总结以上内容,Spark框架提供了一个全面的大数据处理解决方案,从基础的数据处理到复杂的机器学习算法,都有着良好的支持。在实际应用中,结合Spark与SpringBoot等后端框架,可以创建出高性能且可扩展的智能分析问答系统。
4. 朴素贝叶斯分类器在问答系统中的应用
4.1 朴素贝叶斯分类器原理
4.1.1 概率模型与贝叶斯定理基础
贝叶斯分类器是一类基于贝叶斯定理的简单概率分类器。在讨论朴素贝叶斯之前,理解贝叶斯定理是至关重要的。贝叶斯定理在概率论中描述了在已知一些条件下,某事件的概率。公式形式为:
[ P(A|B) = \frac{P(B|A) \cdot P(A)}{P(B)} ]
其中,(P(A|B)) 是在B事件发生的条件下A事件发生的后验概率,(P(B|A)) 是在A事件发生的条件下B事件发生的条件概率,(P(A)) 和 (P(B)) 分别是A事件和B事件的边缘概率。
4.1.2 朴素贝叶斯算法的数学解释
朴素贝叶斯算法在基于特征条件独立的假设下,使用贝叶斯定理来预测分类标签。假设我们有一个特征向量 (X = (x_1, x_2, ..., x_n)) 和一个标签 (Y),朴素贝叶斯的目标是计算 (P(Y|X))。根据贝叶斯定理,我们可以重写这个条件概率:
[ P(Y|X) = \frac{P(X|Y) \cdot P(Y)}{P(X)} ]
由于 (P(X)) 是常数,所以在分类时可以忽略它。朴素贝叶斯的“朴素”之处在于它假设所有特征 (x_i) 相互独立,所以 (P(X|Y)) 可以表示为:
[ P(X|Y) = P(x_1|Y) \cdot P(x_2|Y) \cdot ... \cdot P(x_n|Y) ]
这样就可以简化计算过程。
4.2 朴素贝叶斯在文本分类中的应用
4.2.1 文本预处理与特征提取
在将朴素贝叶斯应用于文本分类之前,首先需要进行文本预处理。这通常包括分词、去除停用词、词干提取和词形还原等步骤。预处理后,文本将被转换为特征向量。常见的方法是使用词袋模型或TF-IDF模型来提取特征。
4.2.2 模型训练与评估方法
朴素贝叶斯分类器的训练过程主要是计算每个类别的先验概率 (P(Y)) 和每个特征给定类别下的条件概率 (P(x_i|Y))。一旦模型训练完成,就可以用交叉验证等方法进行评估,并调整模型参数以优化性能。
4.3 实践:问答系统中的分类器实现
4.3.1 构建问答系统的分类流程
在问答系统中,分类器通常用于将用户的查询归类到特定的问题类别。例如,一个智能客服系统可能会根据用户的提问来确定问题的意图,以便给出正确的回复。构建分类流程的步骤包括:
- 收集和标注数据集。
- 预处理文本数据并提取特征。
- 训练朴素贝叶斯分类器。
- 测试分类器性能并进行优化。
4.3.2 分类器在问答系统中的性能优化
分类器的性能可以通过多种方式优化。例如,通过调整特征提取方法、使用不同的平滑技术(如拉普拉斯平滑)来避免概率为零的情况,或者结合其他算法(如集成学习方法)来提高分类准确性。优化的具体方法取决于问题的复杂度和数据集的特点。
代码示例:使用朴素贝叶斯进行文本分类
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# 示例数据集
data = ["I need to reset my password", "How to change my email", "I forgot my username"]
labels = ["reset_password", "change_email", "forgot_username"]
# 文本向量化
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(data)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.25, random_state=42)
# 初始化朴素贝叶斯模型并训练
model = MultinomialNB()
model.fit(X_train, y_train)
# 进行预测
predictions = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy}")
在这个代码示例中,我们首先创建了一个简单的数据集和标签列表。然后使用 CountVectorizer 对文本数据进行向量化处理,接着划分训练集和测试集。使用 MultinomialNB 模型进行训练和预测,并最终计算模型的准确率。
参数说明与逻辑分析
CountVectorizer: 用于将文本数据转换为向量,这里使用的是词袋模型。train_test_split: 划分数据集为训练集和测试集。MultinomialNB: 多项式朴素贝叶斯模型,适用于离散特征数据。accuracy_score: 用于计算准确率,是模型性能评估的常用指标。
朴素贝叶斯分类器在问答系统中的应用是一个复杂的过程,但通过适当的预处理、特征提取和参数调优,可以显著提高分类的准确性和效率。
5. 论文智能分析问答系统构建与优化
5.1 系统需求分析与设计
在构建智能分析问答系统时,首先要对系统需求进行彻底的分析与设计。这包括理解潜在用户的需求、功能框架的搭建以及技术选型。
5.1.1 系统功能框架与技术选型
在确定系统需求后,我们需要设计一个功能强大的框架。它将支持如下核心功能:
- 用户输入理解
- 文本处理和分析
- 知识检索和查询
- 回答生成和优化
- 用户反馈和系统学习
为了实现这些功能,技术选型至关重要。我们可能会选择SpringBoot来构建我们的后端服务,因为它提供了快速开发、维护和扩展的能力。同时,对于知识图谱的构建和语义理解,我们会使用Neo4j数据库和Apache Spark进行大数据处理。
5.1.2 系统的用户体验与交互设计
用户体验(UX)是智能问答系统成功的关键因素之一。因此,我们还需要将用户体验纳入我们的设计考虑中。良好的交互设计应该简洁明了,易于用户操作,同时也要能够引导用户提出更高质量的问题。这涉及到界面设计的简洁性、反馈的及时性以及交互流程的直观性。
5.2 知识图谱与语义理解
构建智能问答系统中,知识图谱的构建和语义理解技术是核心技术。
5.2.1 知识图谱构建与应用
知识图谱是由实体、概念、事件和它们之间的关系组成的网络。在问答系统中,它可用于存储和管理大量的结构化知识。构建知识图谱的第一步是确定领域知识和关键实体,然后收集和整合数据源。
知识图谱的构建可以通过以下步骤进行:
- 实体识别:从文本中识别出关键实体。
- 关系抽取:确定实体之间的关系。
- 知识融合:整合来自不同来源的数据。
- 知识存储:将构建的知识图谱存储在Neo4j等图数据库中。
5.2.2 语义理解和自然语言处理技术
语义理解是指计算机理解和处理人类语言含义的能力。这包括对句子结构的分析、意图识别和回答生成。在问答系统中,自然语言处理(NLP)技术被广泛应用,如:
- 分词(Tokenization)
- 词性标注(Part-of-Speech Tagging)
- 命名实体识别(Named Entity Recognition)
- 依存解析(Dependency Parsing)
5.3 文本分析与问答处理流程
处理问答系统中的文本是整个系统的基础。
5.3.1 问答系统中的文本分析技术
文本分析包括对用户输入文本的预处理、特征提取和意图识别。预处理可能包含去除停用词、词干提取和词形还原等。特征提取可能利用TF-IDF(Term Frequency-Inverse Document Frequency)或词袋模型(Bag of Words)。
5.3.2 问答系统的核心算法实现
核心算法通常包括意图识别和回答检索。意图识别可以通过机器学习模型实现,例如朴素贝叶斯分类器或者深度学习模型。回答检索则依赖于对知识图谱的有效查询和相关性评分。
5.4 项目结构与文件解析
良好的项目结构和文件解析策略对系统的可维护性和扩展性至关重要。
5.4.1 项目模块划分与代码组织
为了代码的可维护性,我们需要将系统拆分为不同的模块,如:
- 用户界面(UI)
- API层
- 业务逻辑层(Service)
- 数据访问层(DAO)
- 模型和工具类(Model/Util)
5.4.2 文件解析与数据导入导出策略
文件解析模块负责解析用户输入的文件和从其他系统导入数据。同时,系统也需要能够导出查询结果或分析报告。在处理文件时,需要考虑到不同文件格式(如.txt, .json, .csv)的支持,以及编码、字符集等细节问题。
例如,如果我们要处理CSV文件,可以使用如下代码片段:
import csv
def read_csv(file_path):
with open(file_path, newline='', encoding='utf-8') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row) # 输出每一行的数据
# 示例用法
read_csv('input.csv')
在导出数据时,我们可以使用类似的方法,将处理好的数据写入到新的CSV文件中。
以上是第五章节“论文智能分析问答系统构建与优化”的详细内容。每个部分都提供了具体的技术和策略,以确保系统的高效和准确。希望这个章节能够为您的开发过程提供有价值的参考。
简介:本文介绍了基于SpringBoot后端框架、Neo4j图形数据库和Spark大数据处理框架的论文智能分析问答系统。系统采用朴素贝叶斯分类器对用户提问进行文本分析,并提供学术研究辅助。通过集成这些技术,系统能够高效地处理关联数据,并构建知识图谱,以提供智能问答服务。文章还对项目的详细组件进行了分析,为Java Web开发和大数据处理的学习者提供了宝贵的参考。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 23
23 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)