【知识图谱】知识抽取与挖掘(Ⅱ)
一、面向文本的知识抽取1、DeepDive关系抽取实战(1)预备知识KBC系统2、开放域关系抽取(1)信息抽取(IE)概述IE的发展趋势主要系统传统IE和OpenIE互相补充:可以按当前知识库的规范数据,链接更多网络数据。OpenIE所得到的三元组可以用扩充知识库。(2)信息抽取(IE)系统发展① 第一代OpenIE系统TextRunner抽取特征:NER、P...
一、面向文本的知识抽取
1、DeepDive关系抽取实战
2、开放域关系抽取
(1)信息抽取(IE)概述
IE的发展趋势
主要系统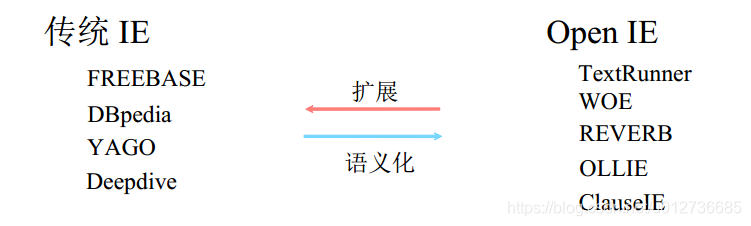
传统IE和OpenIE互相补充:
- 可以按当前知识库的规范数据,链接更多网络数据。
- OpenIE所得到的三元组可以用扩充知识库。
(2)信息抽取(IE)系统发展
① 第一代OpenIE系统
TextRunner
- 抽取特征:NER、POS、Dependency Parsing
- 学习模型:Navie Bayes、CRF
WOE
- 将核心语法路径也作为一个关系(涉及依存句法分析技术)
示例
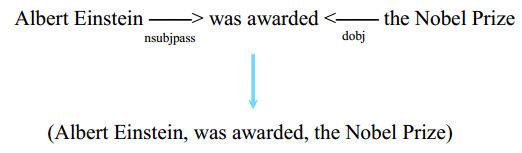
面临的挑战
- 关系不一致、不准确(例如:从句)
E.g.Peter thought that John began his career as a scientist- True:
(John, began, his career as a scientist) - False:
(Peter, began, his career as a scientist)
- True:
- 提取的关系不包含有效信息(例如:多元关系)
E.g.Al-Qaeda claimed responsibility for the 9/11 attacks- True:
(AI-Qaeda, claimed responsibility, for the 9/11 attacks) - False:
(Al-Qaeda, claimed, responsibility)
- True:
② 第二代OpenIE系统:更深入研究句子的语法特性
Reverb
- 基于动词的关系抽取:围绕动词词组抽取以下关系
V | VP | VW * P V = verb particle? adv? W = (noun | adj | adv | pron | det) P = (prep | particle | inf.marker)
OLLIE
- 增加抽取名词和形容词中包含的语义信息;
示例:
Microsoft co-founder Bill Gates spoke at ...
OLLIE可以抽取(Bill Gates, be co-founder of, Microsoft),Reverb不可以 - 把 Reverb 中抽取的关系作为种子,来学习更多的模板。
ClauseIE
- 基于子句的抽取
- 将句子拆分成各个从句,定义从句类型
- 用语法规则和句法依赖判断从句类型(Decision Tree)
- 过程:
抽取从句集合->识别从句类型->抽取关系
③ 更多进展
模型
- 联合训练:训练一个统一模型,同时抽取实体和关系
- 模板匹配方法与深度学习方法相结合
- 矩阵因式分解 等所有好用的分类器
源数据
- 结构化的知识库:可以依赖知识库进行更好的链接和特征抽取
(3)OpenIE的应用
直接回答问题:回答不同用户提出的不同领域形如 (A1, ?, A2) 的问题
作为其他NLP任务的特征
- 文本理解
- 相似度比较
二、知识挖掘
1、实体消歧与链接
实体消歧可以通过实体链接的方式完成
(1)实体链接
实体链接:给定一篇文本中的实体指称(mention),确定这些指称在给定知识库中的目标实体 (entity)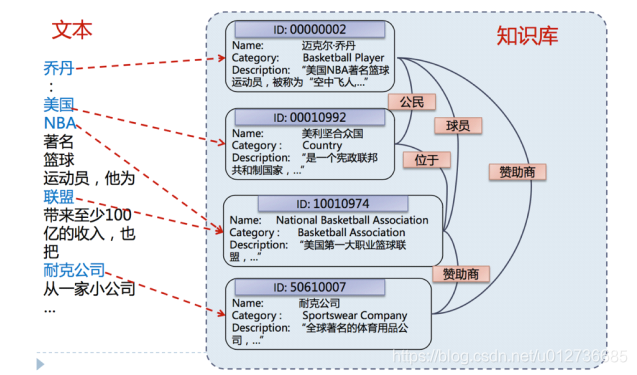
实体链接基本流程: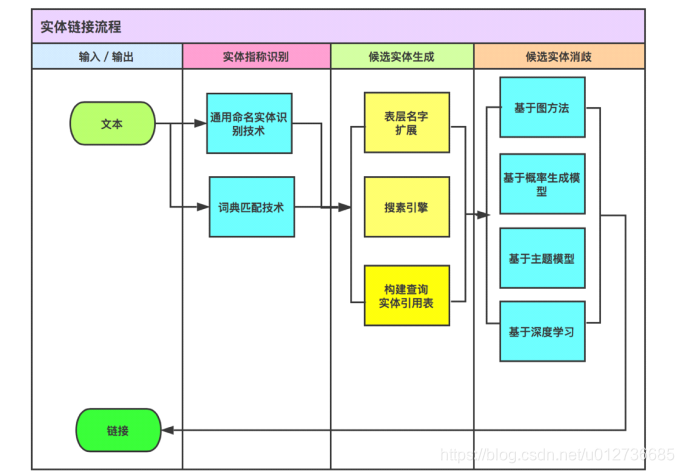
- 实体引用表: 从 mention 到 entity ID 的映射表。
- 示例:
将乔丹与ID为2的实体的映射就是实体引用表中的一个示例。 - 作用:查找出某一实体在知识库中对应的别名、简称、和同义词等。(可能存在错误)
实体的链接主要工作:
- 候选实体的生成(图中蓝色的即为候选实体)
- 候选实体的消歧(如区分出UCB的乔丹和篮球之神乔丹)。
(2)基于 entity-mention 模型:生成概率模型
简述:基于百科型知识库,适用于长、短文本场景。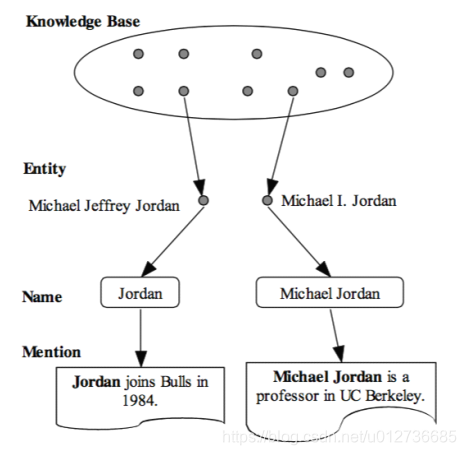
该模型的流程如上图所示,其过程如下:假设有两个句子,其中的实体分别为 Jordan(左) 和 Michael Jordan(右),即模型中的 Mention。问题:要判断这两个 Jordan 指的到底是 篮球大神 还是 ML大神 ? 这个问题可以用公式表述为:
e = a r g max e P ( m , e ) P ( m ) e=arg\max_{e}\frac{P(m,e)}{P(m)} e=argemaxP(m)P(m,e)
等价于: e = a r g max e P ( m , e ) = a r g max e P ( e ) P ( s ∣ e ) P ( c ∣ e ) e=arg\max_{e}P(m,e)=arg\max_{e}P(e)P(s|e)P(c|e) e=argemaxP(m,e)=argemaxP(e)P(s∣e)P(c∣e)
- 其中, e e e 为entity(目标实体), s s s 为name, c c c 为mention。
- P ( e ) P(e) P(e) 表示该目标实体的先验概率(实体流行度),
- P ( s ∣ e ) P(s|e) P(s∣e) 来自前面流程图中的实体引用表,它表示s作为目标实体e的毛文本出现的概率,s表示name。
- P ( c ∣ e ) P(c|e) P(c∣e) 表示的是翻译概率,由目标实体可以生成该mention的概率。
这样可以将上述例子描述为:给定一个 m m m 求生成 e e e 的概率,此处即为给定一个文本“Jordan joins Bulls in 1984.”,其中提及为 “Jordan”,通过计算由 Jordan 生成 Michael Jeffrey Jordan 的概率和 Michael I. Jordan 的概率,概率大的为最终的结果。即,根据 mention 所处的句子和上下文来判断该 mention 是某一实体的概率。
(3)构建实体关联图与标签传播算法消歧
简述:基于百科型知识库,适用于长文本场景。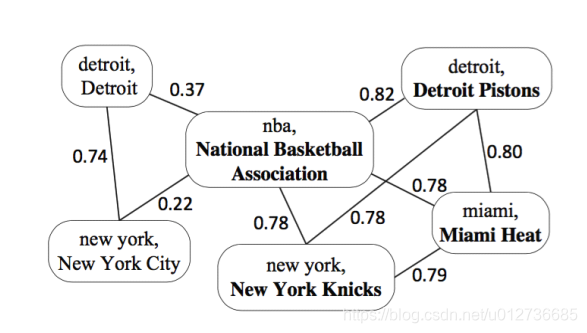
实体关联图由三个部分组成:
- 每个顶点 V i = < m i , e i > V_i=<m_i,e_i> Vi=<mi,ei>由
mention-entity对构成; - 每个顶点得分 :代表实体指称 m i m_i mi 的目标实体为 e i e_i ei 概率可能性大小;
- 每条边的权重:代表语义关系计算值,表明顶点 V i V_i Vi 和 V j V_j Vj 的关联程度。
基于实体关联图消歧具体过程如下:
- 1、顶点的得分的初始化
- 若顶点 V V V 实体不存在歧义,则顶点得分设置为 1,如图中最左边的两个结点,即加粗表示;
- 若顶点中
mention和entity满足 p ( e ∣ m ) > = 0.95 \mathrm{p}(e|m)>=0.95 p(e∣m)>=0.95,则顶点得分也设置为 1。 - 其余顶点的得分设置为 p ( e ∣ m ) \mathrm{p}(e|m) p(e∣m)。
- 2、边的权重的初始化:基于深度语义关系模型
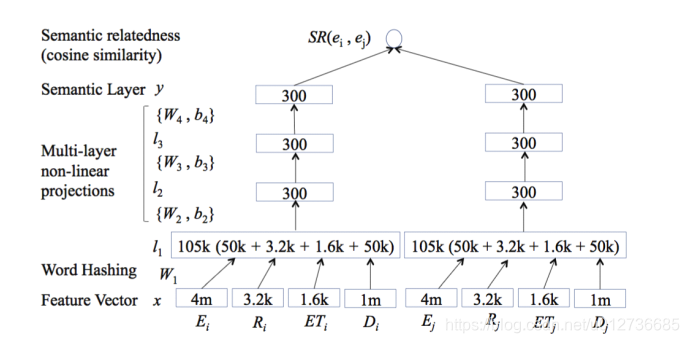
- 此处可以使用Wikipedia作为知识库,由于Wikipedia既包含结构化数据有包括非结构化数据,很适合作为训练数据来训练。
- 符号定义:
E: entity,R: relation,ET: entity type,D: word. - 过程:首先通过 Word Hashing 将上述变量转换为特征向量(类似于embedding?),接着做多层非线性投影(如使用 s i g m o i d sigmoid sigmoid 等函数)得到语义层 y y y;最后计算语义的相似度(如计算余弦相似度)作为两个实体之间的权重。
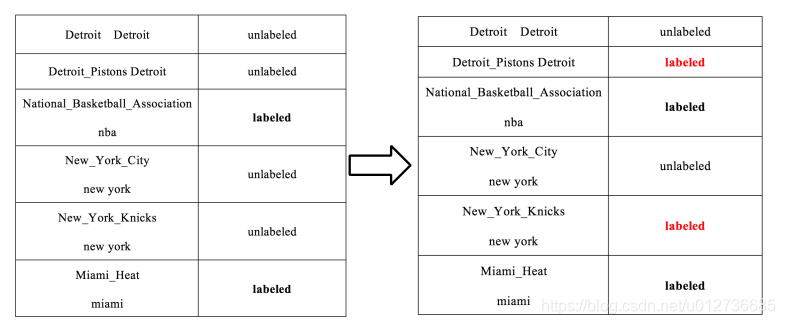
- 3、基于图的标签传播算法
- 步骤:(1)构造相似矩阵;(2)迭代传播直到收敛算法结束。
- 若某些
mention没有多个候选实体,则可认为它是labeled;- 例如:图中
nba可认为是labeled,而new york有两个候选实体所以认为是unlabeled;
- 例如:图中
- 将
labeled数据(一般多个)的影响向外传播,形成了一种协同传播,相当于构建了一个相似矩阵;
对图进行regulation,直到每一个标签都稳定了,起到协同消歧的作用。
(4)基于实体关联图和动态PageRank算法消歧
简述:基于百科型知识库,适用于长文本场景。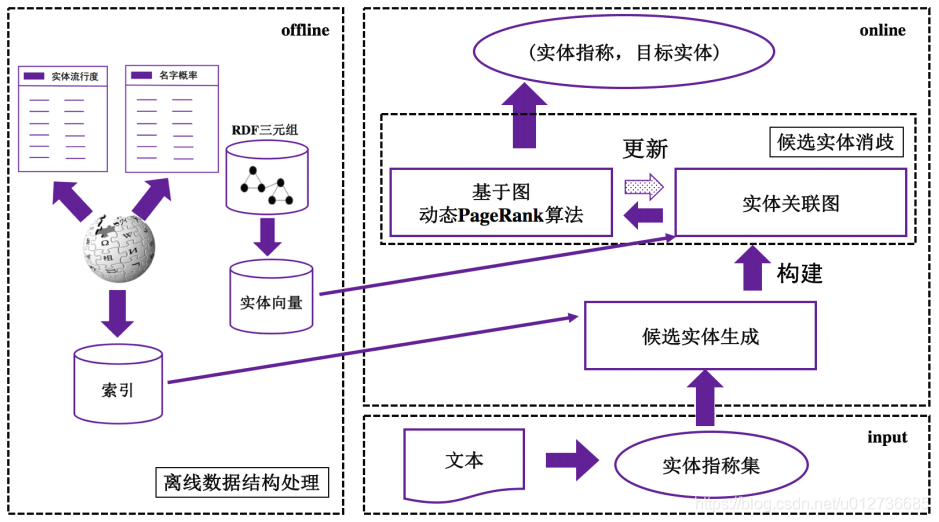
基本流程:
- 基于RDF三元组的数据库,离线将RDF三元组转换成实体向量(eg:woed2vec、知识图谱表示学习等方法);
- 根据实体向量计算相似度,并构建实体关联图;
- 使用基于图的动态PageRank算法更新图。
候选实体语义相似度计算:
- 基本思想:先将
RDF转换成vector,接着计算vector之间的相似度。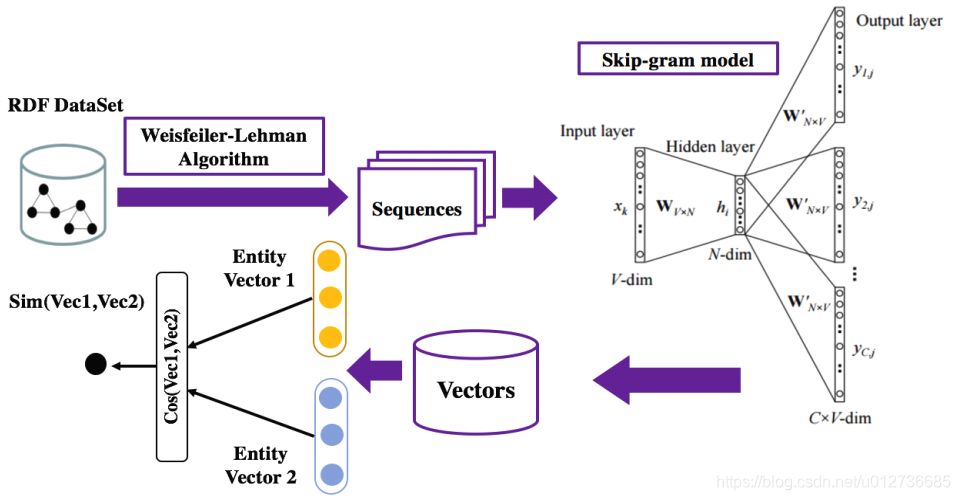
- Weisfeiler-Lehman Algorithm:将RDF图转换成子图,再将子图转换成序列;
- Skip-gram model:词向量。The Skip-gram model architecture usually tries to achieve the reverse of what the CBOW model does. It tries to predict the source context words (surrounding words) given a target word (the center word);
- 计算余弦相似度。
构建实体关联图:
-
实体关联图的组成(四个部分):
- 实体指称节点
- 候选实体节点
- 候选实体节点顶点值:代表该候选实体是实体指称的目标实体概率大小
- 候选实体节点边权值:代表两个候选实体间的转化概率大小
-
构建过程:
- 各候选实体节点值:初始化均相等,之后每一轮更新为上一轮PageRank得分。
- 候选实体节点边权值:
- 计算两个实体之间相似度大小(cos函数):
S M ( e a i , e b j ) = c o s ( v ( e a i ) , v ( e b j ) ) SM(e^i_a,e^j_b)=cos(v(e^i_a),v(e^j_b)) SM(eai,ebj)=cos(v(eai),v(ebj)) - 计算两个候选实体之间转换概率:
E T P ( e a i , e b j ) = S M ( e a i , e b j ) ∑ k η ( v , v i ) S M ( e a i , k ) ETP(e^i_a,e^j_b)=\frac{SM(e^i_a,e^j_b)}{\sum_{kη}(v,v_i)SM(e^i_a,k)} ETP(eai,ebj)=∑kη(v,vi)SM(eai,k)SM(eai,ebj)
- 计算两个实体之间相似度大小(cos函数):
更新实体关联图: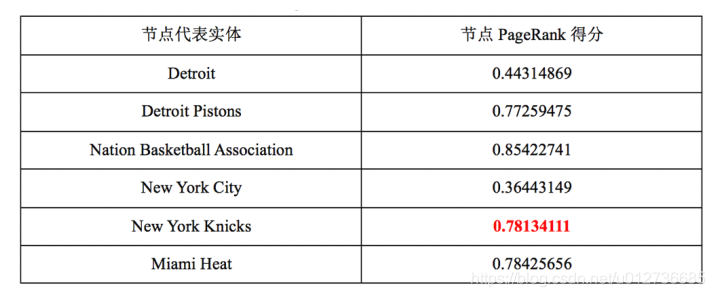
过程:首先根据PageRank算法计算未消歧实体指称实体的得分,取得分最高的未消歧实体。而后删除其他候选实体及相关的边,更新图中的边权值。
其流程如下图所示: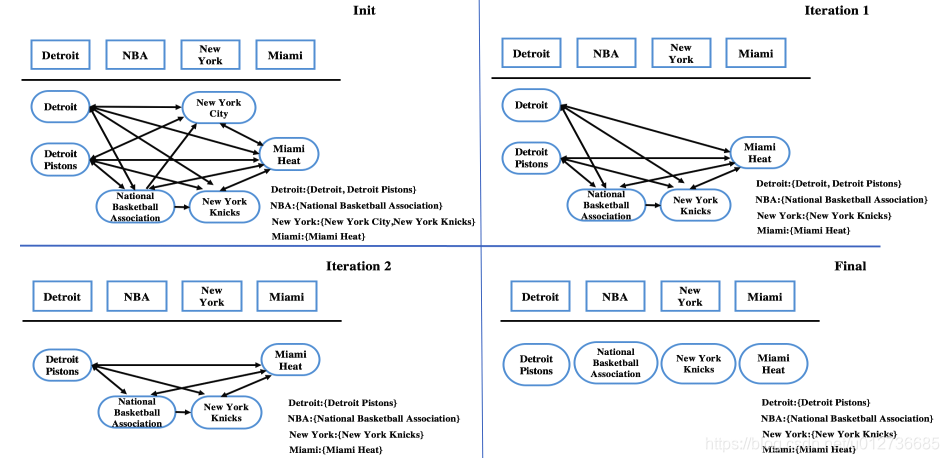
(5)小结
- 知识库的变更:从百科知识库发展到特定领域知识库;
- 实体链接的载体:从长文本到短文本,甚至到列表和表格数据;
- 候选实体生成追求同义词、简称、各种缩写等的准备和高效从Mention到实体候选的查找;
- 实体消歧则考虑相似度计算的细化和聚合,以及基于图计算协同消歧;
2、知识规则挖掘
(1)主要方法
- 基于归纳逻辑编程 (Inductive Logic Programming, ILP)的方法
- 使用精化算子 (refinement operators)
- 基于统计关系学习 (Statistical Relational Learning, SRL)的方法
- 主要对贝叶斯网络进行扩展
- 基于关联规则挖掘 (Association Rule Mining,ARM)的方法
- 构建事务表
- 挖掘规则
- 将规则转换为OWL公理
- 构建本体
(2)关联规则挖掘(ARM)
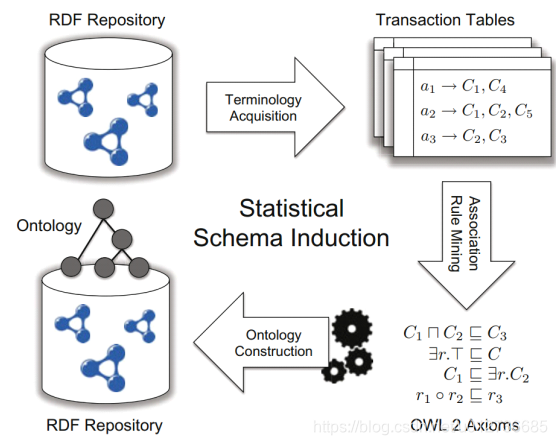
① OWL2公理 =》关联规则
| 公理(Axiom) | 规则(rules) |
|---|---|
| C ∈ D \mathrm{C}\in\mathrm{D} C∈D | { C } ⇒ { D } \{\mathrm{C}\}\Rightarrow\{\mathrm{D}\} {C}⇒{D} |
规则 { C } ⇒ { D } \{\mathrm{C}\}\Rightarrow\{\mathrm{D}\} {C}⇒{D} 意味着:概念 C 的实例同时属于概念 D,规则的置信度越高,则公理 C ∈ D \mathrm{C}\in\mathrm{D} C∈D 的可能性越大。
支持度: 指某频繁项集在整个数据集中的比例。假设数据集有 10 条记录,包含{‘鸡蛋’, ‘面包’}的有 5 条记录,那么{‘鸡蛋’, ‘面包’}的支持度就是 5/10 = 0.5。
置信度: 是针对某个关联规则定义的。有关联规则如{‘鸡蛋’, ‘面包’} -> {‘牛奶’},它的置信度计算公式为 { ‘ 鸡 蛋 ’ , ‘ 面 包 ’ , ‘ 牛 奶 ’ } 的 支 持 度 { ‘ 鸡 蛋 ’ , ‘ 面 包 ’ } 的 支 持 度 \frac{\{‘鸡蛋’, ‘面包’, ‘牛奶’\}的支持度}{\{‘鸡蛋’, ‘面包’\}的支持度} {‘鸡蛋’,‘面包’}的支持度{‘鸡蛋’,‘面包’,‘牛奶’}的支持度。假设{‘鸡蛋’, ‘面包’, ‘牛奶’}的支持度为 0.45,{‘鸡蛋’, ‘面包’}的支持度为 0.5,则{‘鸡蛋’, ‘面包’} -> {‘牛奶’}的置信度为 0.45 / 0.5 = 0.9。
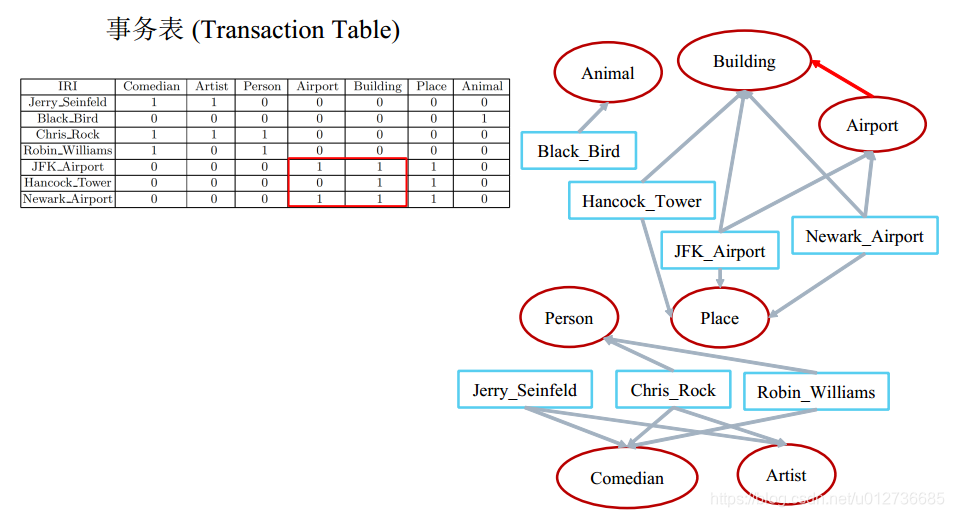
support(Airport, Building)=2
support(Airport)=2
confidence(Airport=>Building)=1
Airport ∈ \in ∈ Building
==》结果:可以推出Airport属于Building。
(3)统计关系学习(SRL)
输入:(实际上就是一个KG)
- 实体集合 { e i } \{e_i\} {ei}
- 关系集合 { r k } \{r_k\} {rk}
- 已知三元组集合 { ( e i , r k , e j ) } \{(e_i,r_k,e_j)\} {(ei,rk,ej)}
目标:根据已知三元组对未知三元组成立的可能性进行预测,可用于知识图谱补全。
ps:若 e i , e j e_i,e_j ei,ej 之间没有申明关系 r k r_k rk,而计算出来的 P ( e i , r k , e j ) \mathrm{P}(e_i, r_k, e_j) P(ei,rk,ej)很高(如 P = 1 P=1 P=1),则认为可以补全这条关系。
① 基于图的方法
基本思想:将连接两个实体的路径作为特征来预测其间可能存在的关系。
示例:下面的图谱中的边是一个有向的图,为了使图中可以形成路径,在图中定义了一些逆关系(如 I s A − 1 IsA^{−1} IsA−1)。在这个图中我们希望可以通过其他的三元组推出 Charlotte 也是一个 Writer。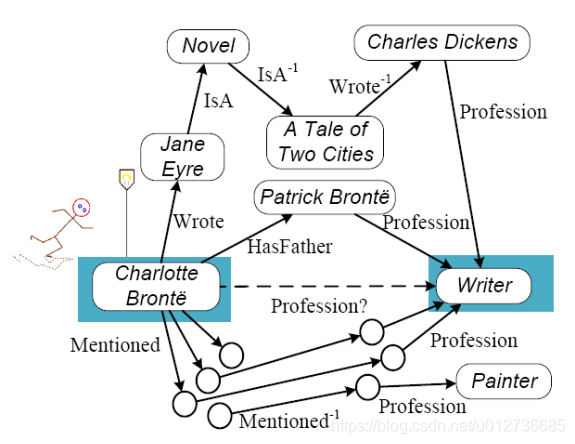
通用关系学习框架如下: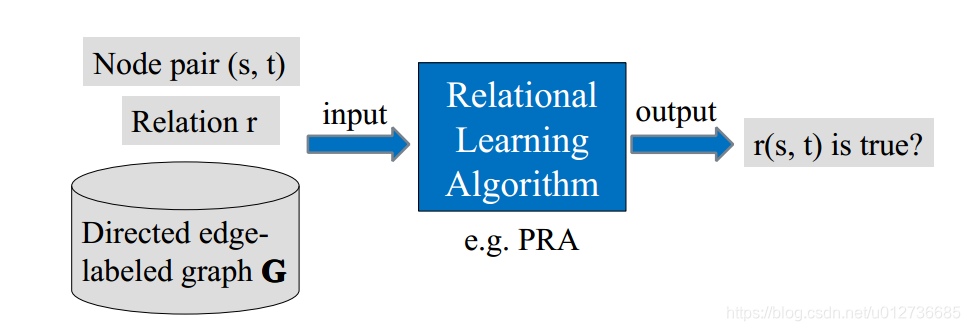
② 路径排序算法(Path Ranking Algorithm)
在基于图的方法中采用了的Relational Learning Algorithm是路径排序算法(Path Ranking Algorithm)。
相关定义:
-
定义 G = ( N , E , R ) G=(N,E,R) G=(N,E,R):
- N: nodes (instances or concepts)
- E: edges
- R: edge types,note: r − 1 r^{-1} r−1——reverse of edge type r r r
-
接着定义Path type π : ⟨ r 1 , r 2 , . . . , r n ⟩ \pi:\langle r_1, r_2,..., r_n \rangle π:⟨r1,r2,...,rn⟩
- eg:
<HasFather, Profrssion>
- eg:
实体对概念计算:
在前面给出的图中,我们可以通过如 <HasFather, Profession> 的一些路径将 Charlotte 和 Writer 进行关联起来。我们可以将在图中已经定义的节点、边和边的类型作为上下文来表示实体对 (Charlotte Bonte, Writer),同时可以抽取出一些特征供后面学习。
对于这个实体对的概率可以通过如下公式计算:
s c o r e ( s , t ) = ∑ π ∈ Q P ( s → t ; π ) θ π score(s,t)=\sum_{\pi\in{Q}}P(s\to t;\pi)\theta_{\pi} score(s,t)=π∈Q∑P(s→t;π)θπ
- Q Q Q:是所有起始为 s s s 终点为 t t t 的路径集合(限制路径的最大长度为 n n n)
- θ π \theta_{\pi} θπ:通过训练得到的路径权重
路径概率的计算:
P ( s → t ; π ) = ∑ P ( s → z ; π ′ ) P ( z → t ; r ) P(s\to{t};\pi)=\sum P(s\to{z};\pi')P(z\to{t};r) P(s→t;π)=∑P(s→z;π′)P(z→t;r)
- P P P:将 s s s 到 t t t 的路径细化成 s s s 到 z z z 和 z z z 到 t t t 两条路径,其中 z z z 到 t t t 是存在关系 r r r 的单跳路径;
- 具体使用动态规划的方法求解
训练权重的计算(离线计算):
- 可以将路径作为特征,进行逻辑回归来求得权重。
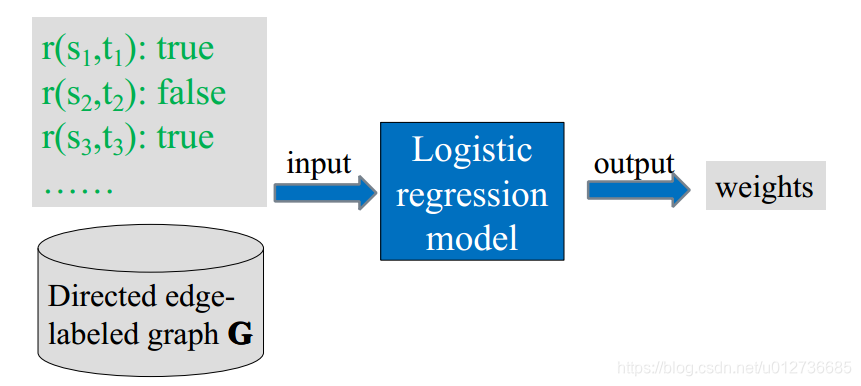
最后通过计算出来的 P P P 的大小判断出 (Charlotte Bonte, Writer) 是成立的。
3、知识图谱表示学习
(1)知识图谱表示学习的意义
在自然语言处理中我们可以通过 word embedding、sentence embedding甚至是document embedding等嵌入表示的方式来建立一个低维的统一的语义空间,使得语义可以计算。
在知识图谱中也类似,具体应用为:
-
实体预测与推理
给定一个实体和一个关系来预测另外一个实体。- eg:若给定一个电影实体《卧虎藏龙》和一个关系“观影人群”,来预测另外一个实体是什么。
-
关系推理
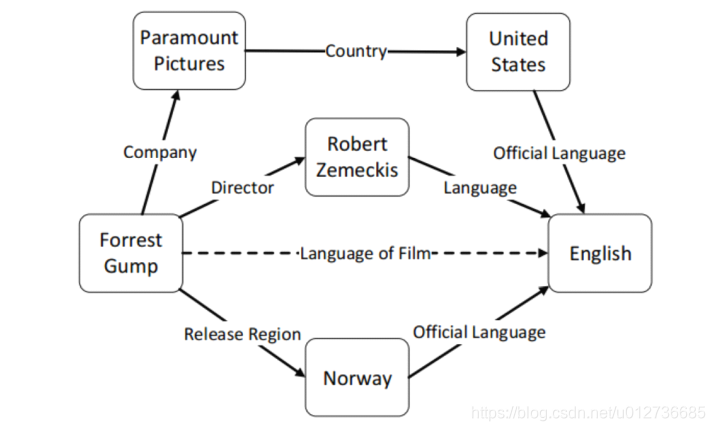
-
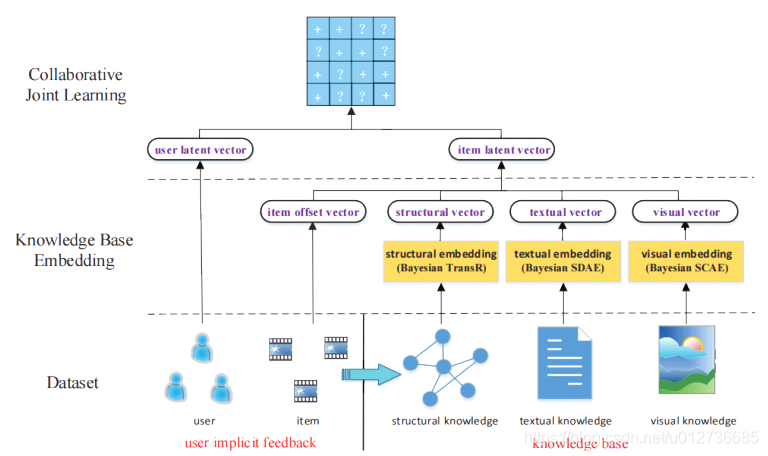
推荐系统
(2)TransE
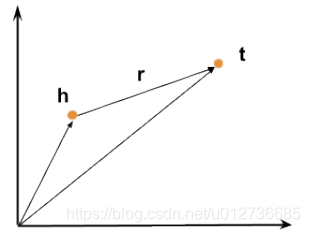
基本思想:TransE(Translation Embedding)是基于实体和关系的分布式向量表示,将三元组(head,relation,tail)看成向量 h h h 通过 r r r 翻译到 t t t 的过程,通过不断的调整向量 h 、 r 和 t h、r 和 t h、r和t,使 h + r h+r h+r 尽可能与 t t t 相等。
- 示例:如给出三元组
Capital of(Beijing, China)和Capital of(Pairs, France),则可以得出如下向量表示:Beijing−China=Pairs−France=Capital of
TransE的优化目标:
- 势能函数: f ( h , r , t ) = ∣ ∣ h + r − t ∣ ∣ 2 f(h,r,t)=||h+r-t||_2 f(h,r,t)=∣∣h+r−t∣∣2
f ( B e i j i n g , C a p i t a l − o f , C h i n a ) < f ( S h a n g h a i , C a p i t a l − o f , C h i n a ) f(Beijing,Capital−of,China)<f(Shanghai,Capital−of,China) f(Beijing,Capital−of,China)<f(Shanghai,Capital−of,China) - 目标函数:最小化整体势能。即使知识库中定义的势能比不在知识库中的三元组的势能低。
min ∑ ( h , r , t ) ∈ Δ ∑ ( h ′ , r ′ , t ′ ) ∈ Δ ′ [ γ + f ( h , r , t ) − f ( h ′ , r ′ , t ′ ) ] + \min\sum_{(h,r,t)\in\Delta}\sum_{(h',r',t')\in\Delta'}[\gamma+f(h,r,t)-f(h',r',t')]_+ min(h,r,t)∈Δ∑(h′,r′,t′)∈Δ′∑[γ+f(h,r,t)−f(h′,r′,t′)]+
其中, [ x ] + = max ( 0 , x ) [x]_+=\max(0,x) [x]+=max(0,x)
TransE的缺陷:
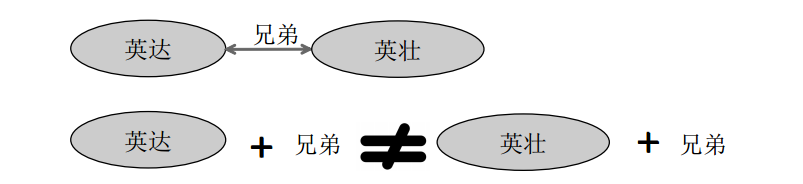
- 无法处理一对多、多对一和多对多问题。
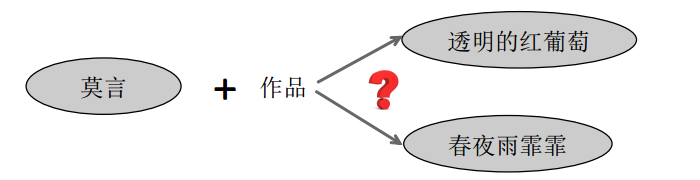
- 关系的性质。
(3)TransE改进
① 实体语义空间投影
TransH:将头尾实体映射到一个超平面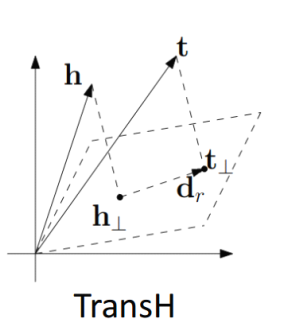
TransR:通过矩阵变换,将头、尾实体映射到一个新的语义空间,使得这个空间的关系尽量保持一对一。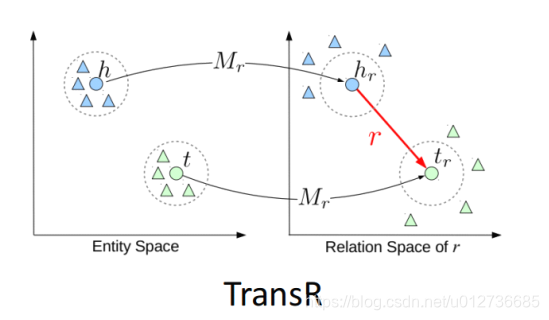
② 属性表示:分而治之
对于知识图谱的边既可以是属性(data type property)也可以是关系(object property)。对于属性来说,很容易产生一对多(如喜好)和多对一(性别),若将关系和属性的表示会出现困难。
分而治之:将对属性的学习和对关系的学习做了一个区分,同时基于属性的学习可以推进对关系的学习。
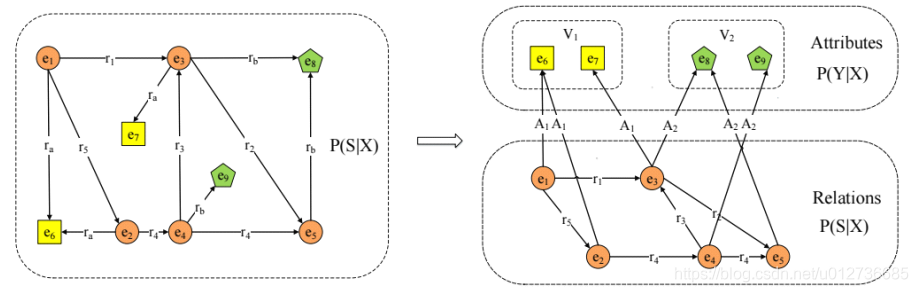
(4)路径的表示学习
PRA vs. TransE: 两种方法存在互补性
- PRA:可解释性强;能够从数据中挖掘出推理规则;难以处理稀疏关系;路径特征提取效率不高。
- TransE:能够表示数据中蕴含的潜在特征;参数较少,计算效率较高;模型简单,难以处理多对一、一对多、多对多的复杂关系可解释性不强。
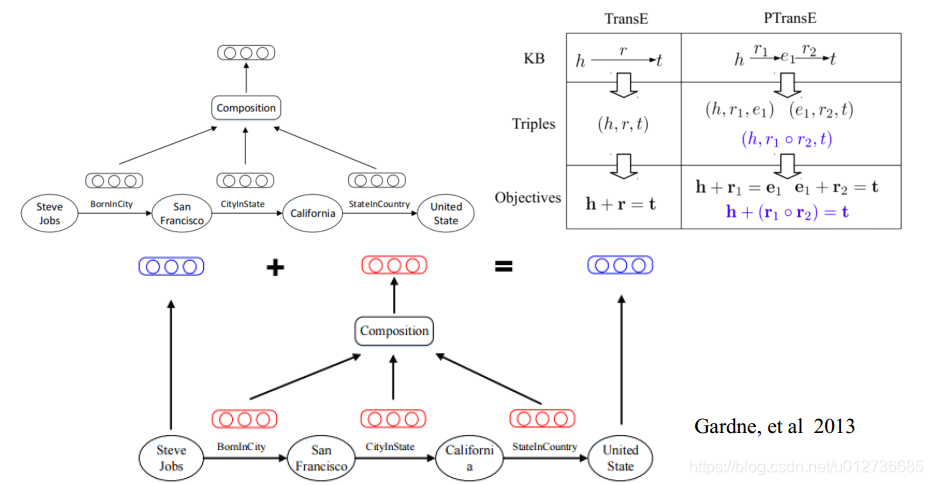
评价指标:
- 三元组分类任务:accuracy
- 链接预测任务:hits10
(5)加入规则的表示学习
学习推理的规则:推理的规则似然最大化。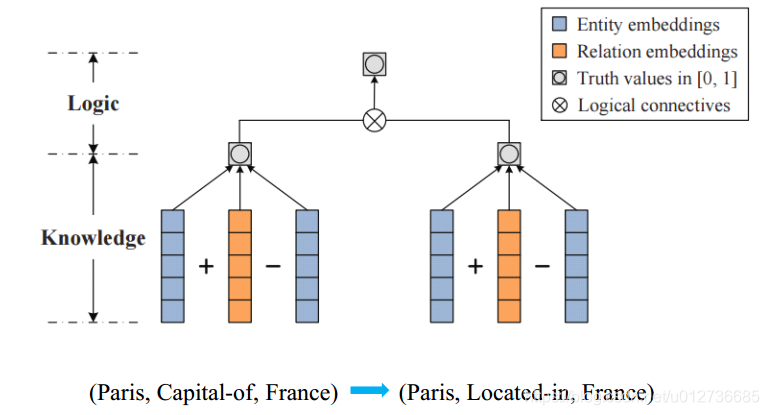
(6)多模态的表示学习
助力Zero-Shot和长尾链接预测:
- 对于在KG中出现很少,甚至没有出现过,而在长文本中出现较多的长尾数据来做实体链接预测。
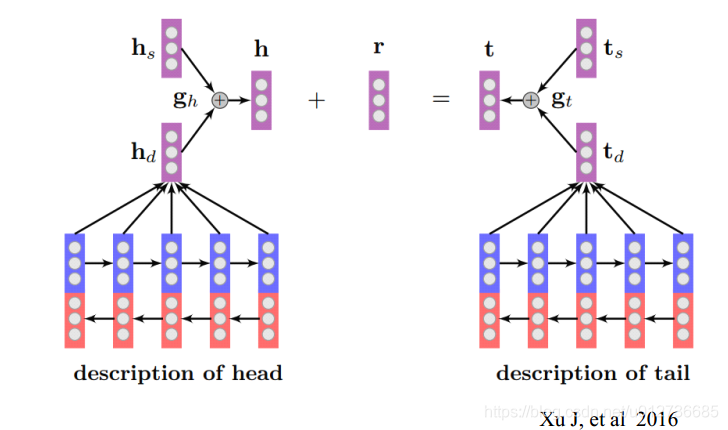
- h s h_s hs:KG中结构的学习
- h d h_d hd:在文本中的描述的学习,这里使用了Bi-LSTM模型
(7)基于知识图谱结构的表示学习
考虑哪些数据可以用来描述实体:
- Neighbor Context:实体周围的实体;
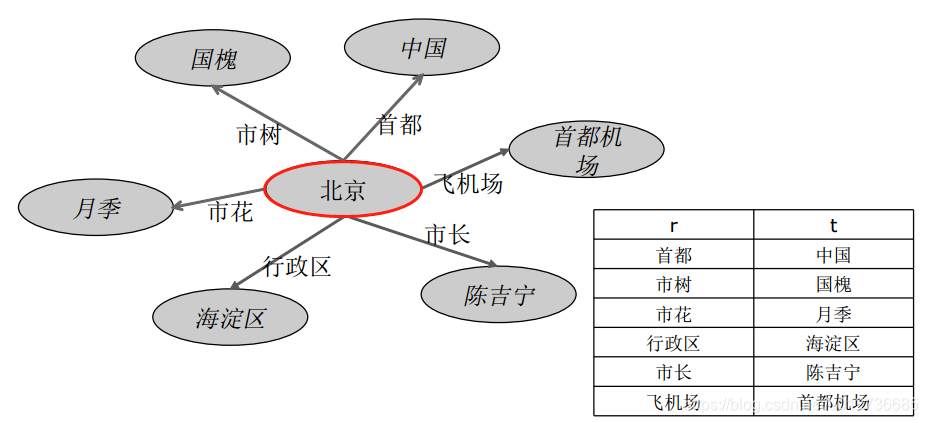
- Path Context:从一个实体到这个实体的联通路径;
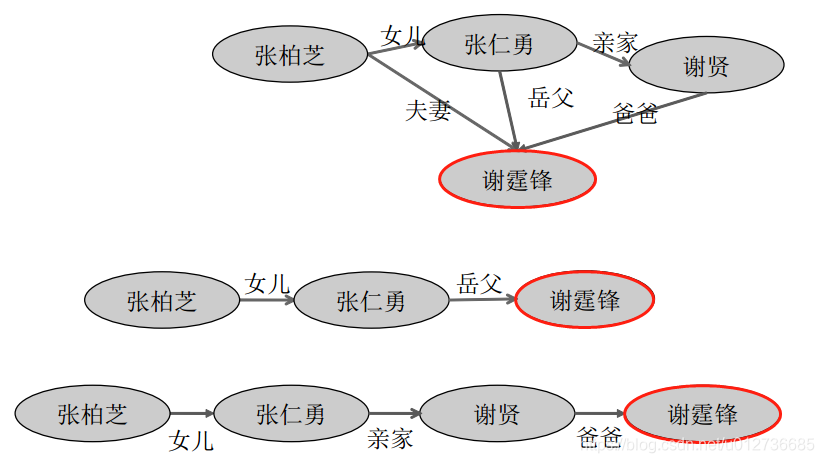
Triple Context = Triple + Path Context + Neighbor Context
- 势能函数
- 希望三元组在Triple Context概率最大
f ( h , r , t ) = P ( ( h , r , t ) ∣ C ( h , r , t ) ; Θ ) f ( h , r , t ) = P ( ( h , r , t ) ∣ C ( h , r , t ) ; Θ ) f(h,r,t)=P((h,r,t)|C(h,r,t);\Theta) f(h,r,t)=P((h,r,t)∣C(h,r,t);Θ) f(h,r,t)=P((h,r,t)∣C(h,r,t);Θ)f(h,r,t)=P((h,r,t)∣C(h,r,t);Θ) - 假设不同的Context都是相互独立的企且独立用来描述三元组的某一部分
f ( h , r , t ) = P ( h ∣ C ( h , r , t ) ; Θ ) = P ( t ∣ C ( h , r , t ) , h ; Θ ) = P ( r ∣ C ( h , r , t ) , h , t ; Θ ) \begin{aligned}f(h,r,t)&=P(h|C(h,r,t);\Theta) \\ &=P(t|C(h,r,t),h;\Theta) \\ &=P(r|C(h,r,t),h,t;\Theta)\end{aligned} f(h,r,t)=P(h∣C(h,r,t);Θ)=P(t∣C(h,r,t),h;Θ)=P(r∣C(h,r,t),h,t;Θ)
f ( h , r , t ) ≈ P ( h ∣ C N ( h ) ; Θ ) ⋅ P ( t ∣ C P ( h , t ) , h ; Θ ) ⋅ P ( r ∣ h , t ; Θ ) f(h,r,t)\approx P(h|C_N(h);\Theta) \cdot P(t|C_P(h,t),h;\Theta) \cdot P(r|h,t;\Theta) f(h,r,t)≈P(h∣CN(h);Θ)⋅P(t∣CP(h,t),h;Θ)⋅P(r∣h,t;Θ)
- 目标函数
P ( K ∣ Θ ) = Π ( h , r , t ) ∈ K f ( h , r , t ) P(\mathcal{K}|\Theta) = \Pi_{(h,r,t)\in \mathcal{K}}f(h,r,t) P(K∣Θ)=Π(h,r,t)∈Kf(h,r,t)
总结与挑战
- 融合更多本体特征的知识图谱表示学习算法研发
- 知识图谱表示学习与本体推理之间的等价性分析
- 知识图谱学习与网络表示学习之间的异同
- 神经符号系统

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)