视觉OCC的三种典型模型对比分析:VoxFormer、SparseOcc与OccupancyDETR
0 引用
VoxFormer论文:
[2302.12251] VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
SparseOcc论文:
[2312.17118] Fully Sparse 3D Occupancy Prediction
OccupancyDETR论文:
[2309.08504] OccupancyDETR: Using DETR for Mixed Dense-sparse 3D Occupancy Prediction
1 摘要
自动驾驶感知系统正处于从二维(2D)图像空间向三维(3D)体积空间转型的关键时期。传统的3D目标检测(Bounding Box)虽然计算高效,但在描述不规则障碍物(如施工车辆伸出的支架、悬挂的植被或异形路障)时存在本质缺陷。为了解决这一问题,3D语义占据预测即OCC应运而生,它将物理世界体素化,对每一个体素进行“占据”与“语义”的分类,从而提供更精细的场景理解能力。
然而,3D占据预测面临着严峻的“维度诅咒”:3D空间的体素数量随分辨率呈立方级增长,而真实场景中超过90%的体素是空置的。如何在有限的计算资源下,高效、准确地重建3D场景,成为了当前学术界和工业界的核心议题。
本报告将深入剖析三种代表性的视觉3D占据预测模型:VoxFormer、SparseOcc 和 OccupancyDETR。这三种模型分别代表了三种截然不同的设计哲学:
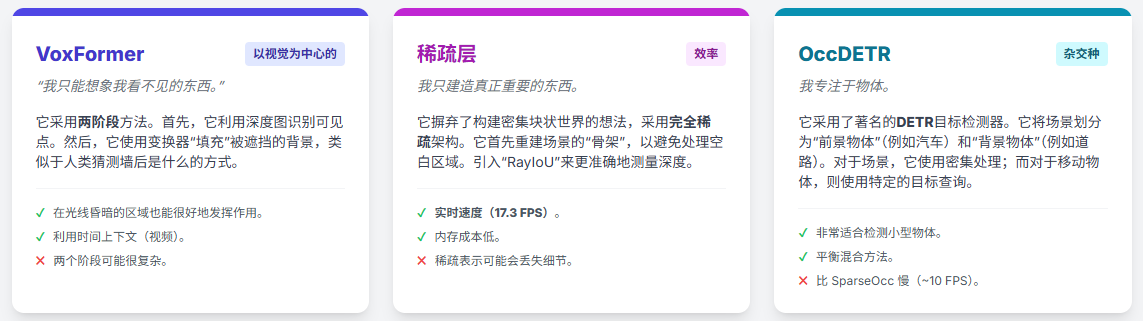
- VoxFormer 采用“先重建,后想象”的策略,利用显式深度估计构建稀疏查询,再通过掩码自编码器(MAE)补全场景。
- SparseOcc 提出“完全稀疏化”的范式,彻底摒弃稠密特征图,利用级联的稀疏解码器和Mask Transformer,并提出了针对性的RayIoU评价指标。
- OccupancyDETR 引入“前景-背景差异化处理”的混合思想,结合DETR目标检测与占据预测,对重点目标进行稠密处理,对背景进行稀疏处理。
2. 背景与挑战:从BEV到3D占据网络
2.1 感知范式的演进
在深入讨论具体模型之前,必须理解它们诞生的技术背景。自动驾驶视觉感知经历了几次重要的范式转移。早期的感知主要依赖于2D目标检测,这在图像平面上非常成熟,但缺乏深度信息,无法直接用于路径规划。随后的鸟瞰图(Bird's-Eye-View, BEV)感知通过将图像特征投影到地平面,解决了定位问题,成为了近年来量产车的主流方案。
然而,BEV存在显著的“高度信息丢失”问题。在BEV视角下,一个悬挂在路面上方3米的限高杆和一个横卧在路面上的减速带可能映射为同样的特征。这种高度模糊性对于自动驾驶的安全至关重要。为了解决这一痛点,感知系统必须恢复Z轴信息,即从BEV图升级为3D体素网格。
2.2 维度诅咒与稀疏性难题
3D语义占据预测的核心任务是输入2D图像,输出一个尺寸为 H*W*Z的体素网格,每个网格包含语义标签。这一任务面临两大核心挑战:
- 第一是计算量的爆炸。如果我们将场景分辨率提高一倍,2D图像的像素数增加4倍,而3D体素的数量则增加8倍。构建一个高分辨率的稠密3D特征体需要消耗巨大的显存和算力,这在车载芯片上往往是不可接受的。
- 第二是场景的稀疏性。统计数据显示,在典型的自动驾驶场景数据集中(如Occ3D-nuScenes或SemanticKITTI)中,超过90%的3D空间是空的(空气)。如果网络对这90%的空区域进行同等强度的计算,将造成极大的资源浪费。
本文分析的三个模型,正是针对这“90%的浪费”提出了三种不同的解决方案。
3. VoxFormer:基于显式深度先验的场景补全
核心理念: “先见其实,后补其虚”。视觉特征只能对应可见的表面,不可见区域应当基于可见区域进行‘想象’。
VoxFormer 由NVIDIA和多所高校联合提出,其灵感来源于掩码自编码器(MAE)在计算机视觉中的成功。它认为,与其盲目地在真空中搜索特征,不如先利用深度估计确定哪里有物体,然后在这些确定的位置上进行特征提取,最后再利用Transformer的全局注意力机制去推断被遮挡的部分。
3.1 架构深度解析
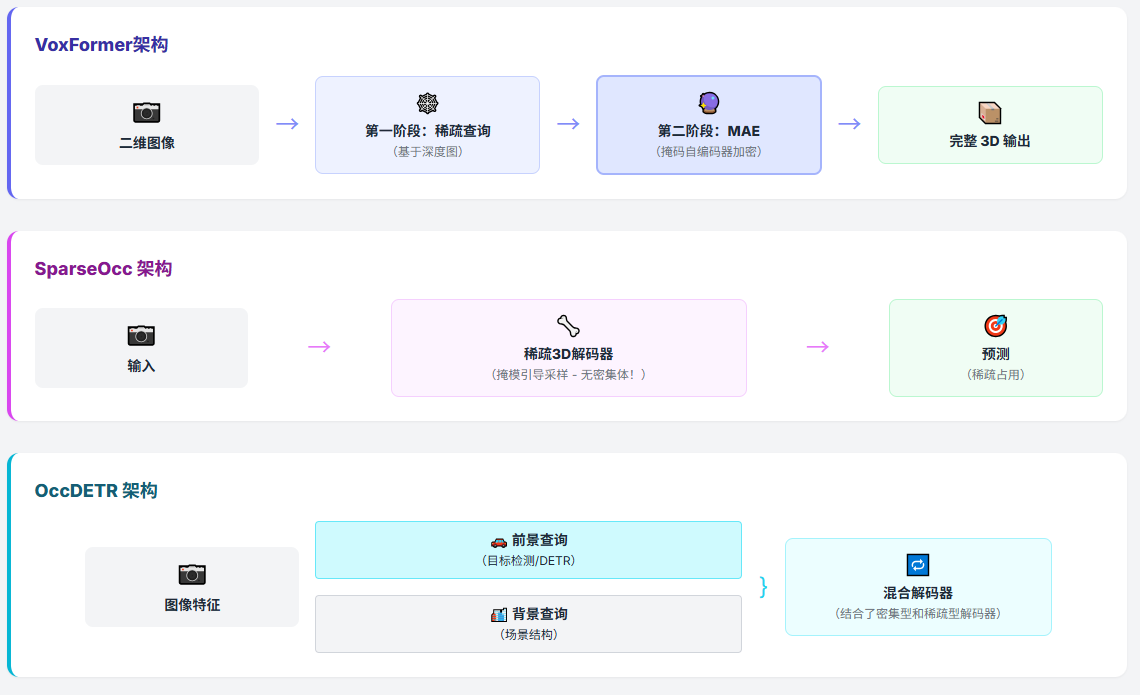
VoxFormer采用了严格的两阶段(Two-Stage)设计,这种设计在目标检测领域(如Faster R-CNN)非常经典,但在占据预测中被赋予了新的含义。
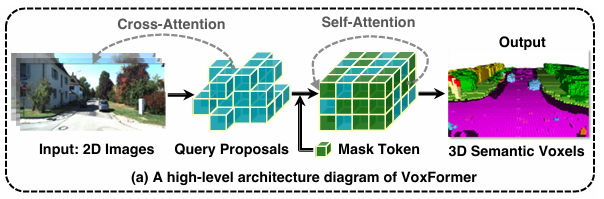
图3.1:VoxFormer 示意图 用于基于相机的语义场景完成,仅在给定 2D 图像的情况下预测完整的 3D 几何和语义。 在获得基于深度的体素查询建议后,VoxFormer 通过类似 MAE 的架构生成语义体素。
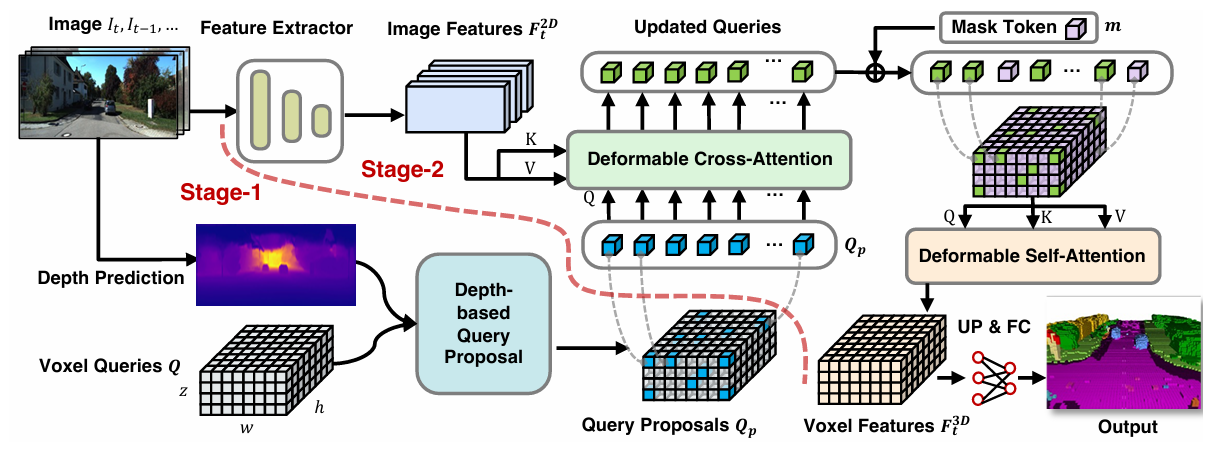
图3.2:VoxFormer的总体框架。 给定 RGB 图像,由 ResNet50 提取 2D 特征,并由现成的深度预测器估计深度。 校正后的估计深度启用了与类别无关的查询建议阶段:将选择位于占用位置的查询来与图像特征进行可变形交叉注意。 之后,将添加掩模标记以通过可变形自注意力来完成体素特征。 精炼后的体素特征将被上采样并投影到输出空间以进行每体素语义分割。 该框架支持单个或多个图像的输入。
相关知识:上采样用于增加数据或特征图的空间分辨率,常见于图像超分辨率、语义分割等任务,旨在恢复细节信息或匹配不同尺度的网络层输出。
3.1.1 第一阶段:基于深度的稀疏查询生成
绝大多数占据网络(如MonoScene)会初始化一个稠密的、空的体素查询网格。VoxFormer认为这很低效。它首先引入了一个显式的深度估计模块。
深度估计与反投影: 模型使用一个轻量级的深度估计网络(论文中使用了MobileStereoNet作为深度骨干 )从输入图像中预测逐像素的深度图。有了深度图,就可以结合相机内参,将2D像素点反投影到3D空间,形成一个“伪激光雷达”(Pseudo-LiDAR)点云。
体素化与修正: 这些点云被体素化,形成一个初步的占据网格。然而,单目/双目深度估计通常伴随着噪声,尤其是在物体边缘和远距离处。因此,VoxFormer引入了一个轻量级的3D占据预测头,对这个初步网格进行“修正”。这一步仅仅作为分出占用/空闲的二分类任务。
稀疏查询选择: 经过修正后,模型只选择那些被预测为“占据”的体素位置作为Voxel Queries(体素查询)。这一步极大地减少了查询的数量,因为大部分空体素在这里就被剔除了。
3.1.2 第二阶段:稀疏到稠密的MAE补全
获得了代表可见表面的稀疏查询后,接下来的任务是赋予它们语义,并推断不可见区域。
可见区域特征增强: 被选中的稀疏查询通过可变形交叉注意力(Deformable Cross-Attention)机制与2D图像特征进行交互。由于查询点已经具备了大概的3D坐标,它们可以精准地投影回图像平面,提取对应的语义特征。这里的“可变形”机制意味着每个查询点只关注图像上投影点周围的几个采样点,而不是全图,进一步节省了计算量。
掩码标记(Mask Tokens)的引入: 这部分是VoxFormer的灵魂所在。那些在第一阶段未被选中的体素(即被遮挡的内部、背面或未探测到的区域),并不会被完全丢弃,而是被替换为一个可学习的Mask Token 。模型需要根据上下文(可见查询)来填空(Mask Token)。
自注意力机制(Self-Attention): 一个强大的Transformer自注意力模块被用来处理所有的体素,包括携带图像特征的可见查询和Mask Token。在这个过程中,信息发生流动:
-
可见查询将纹理、形状特征传递给周围的Mask Token。例如,如果可见查询识别出了汽车的前保险杠和挡风玻璃,自注意力机制会根据学习到的先验知识告诉后方的Mask Token:“你们应该组成汽车的后半部分”。这种“想象”能力使得VoxFormer能够生成完整的3D几何结构,而不仅仅是表面壳体。
3.2 性能与局限性分析
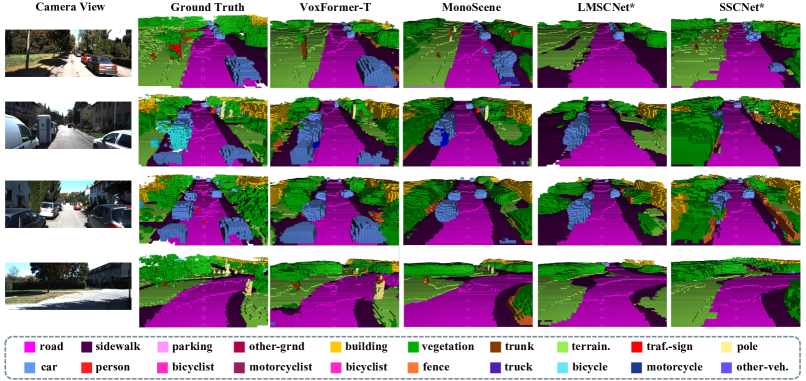
图3.3:VoxFormer和其他方法的定性结果。 VoxFormer 更好地捕捉大规模自动驾驶场景中的场景布局。 同时,VoxFormer在完成树干、杆子等小物体方面也表现出了令人满意的性能。
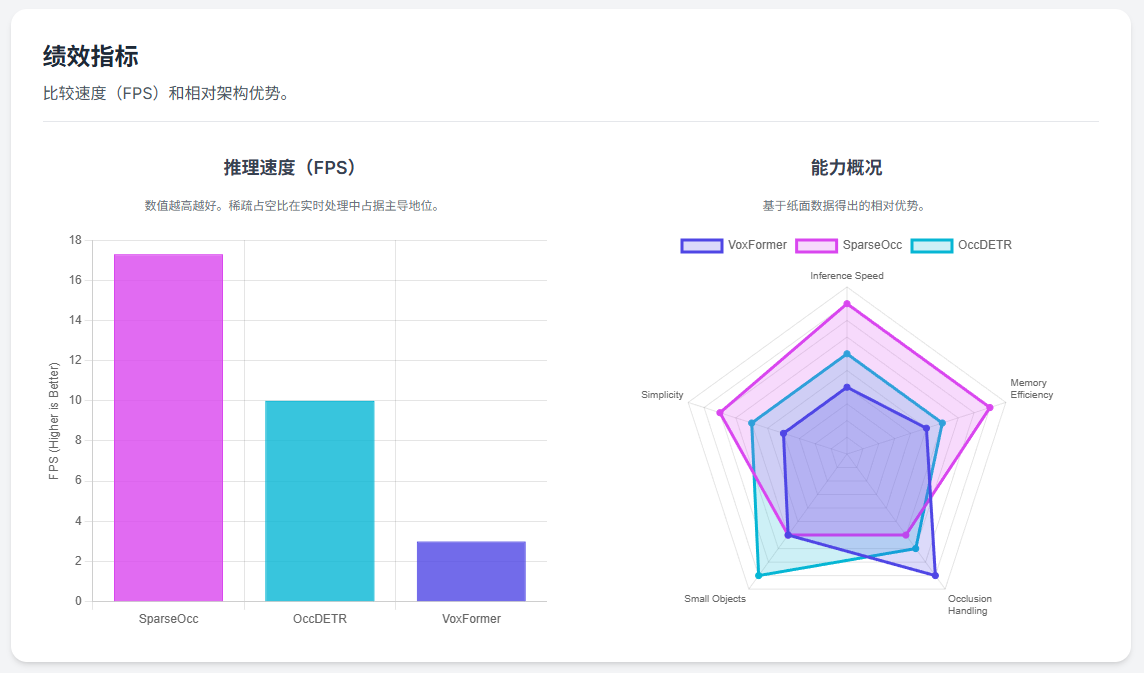
几何补全能力的优势: 实验数据显示,在SemanticKITTI数据集上,VoxFormer在几何补全(IoU)指标上表现优异,相对基线模型MonoScene提升了约20% 。这主要归功于第一阶段的显式深度注入。深度网络提供了强几何约束,使得模型在物体轮廓的刻画上远比纯隐式学习的方法准确。
短距离感知的统治力: 在近距离范围(0-12.8米和12.8-25.6米),VoxFormer的表现尤为出色,大幅超越对手。这是因为深度估计在近距离时的精度最高,提供的查询建议质量最好。对于自动驾驶而言,近距离感知直接关联到避障安全。
对深度先验的依赖(局限性): VoxFormer的阿喀琉斯之踵在于其对第一阶段深度估计的依赖。如果深度网络在某些场景下失效(例如夜间、无纹理墙面或远距离),第一阶段无法生成正确的查询点,第二阶段的补全也就成了无源之水。这种级联误差在远距离感知中表现得尤为明显,因为深度估计的误差随距离平方增加。
训练复杂性: 由于包含两个阶段,且涉及深度监督和占据监督,VoxFormer的训练流程相对繁琐。尽管其推理显存优化到了16GB以下,便于在消费级显卡上部署,但多阶段的pipeline在端到端优化方面不如单阶段模型直观。
4. SparseOcc:完全稀疏化的架构革命
核心理念: “拒绝浪费”。既然90%的空间是空的,那么网络内部的任何一个环节都不应该出现稠密的3D张量。从输入到输出,必须贯彻“完全稀疏”的设计原则。
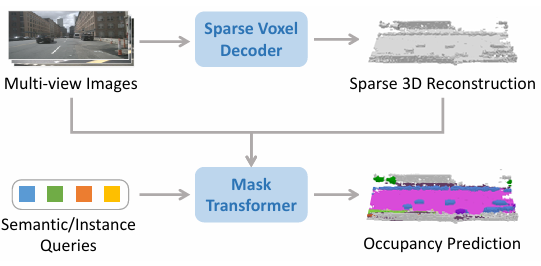
图4.1:SparseOcc 通过稀疏体素解码器从仅相机输入重建稀疏 3D 表示,然后通过一组稀疏查询估计每个片段的掩码和标签。
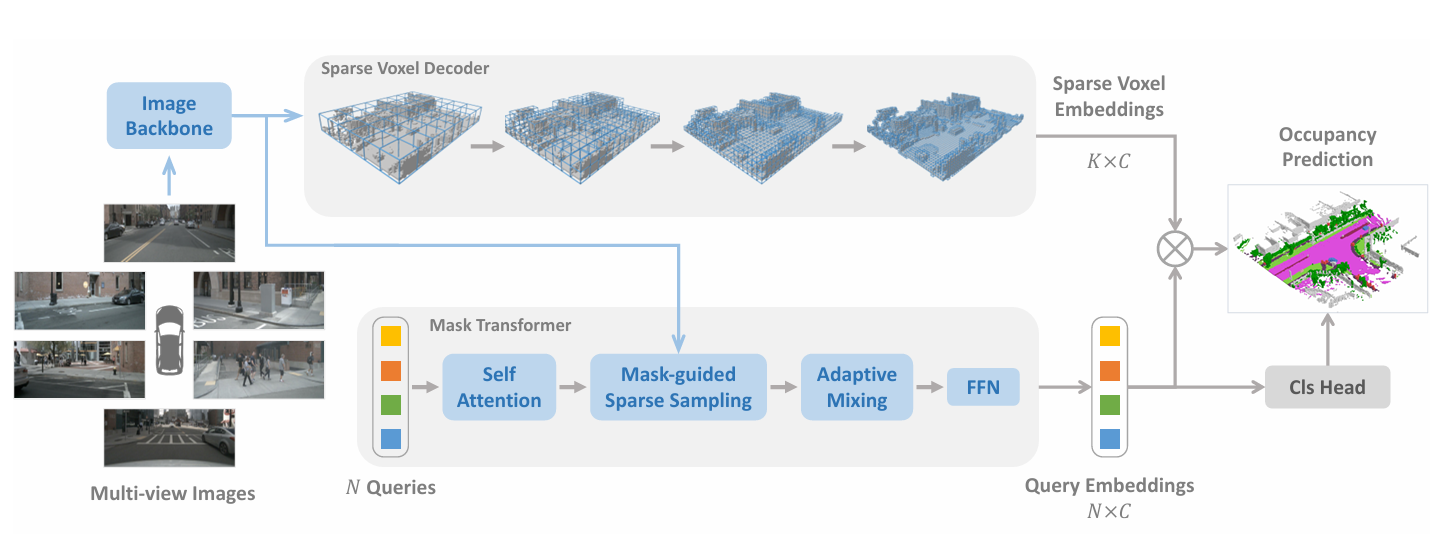
图4.2:SparseOcc 是一个完全稀疏的架构,因为它既不依赖于密集的 3D 特征,也不具有稀疏到密集和全局注意力操作。 稀疏体素解码器重建场景的稀疏几何形状,由 K 体素 (K≪W×H×D) 组成。 然后,掩码转换器使用 N 稀疏查询来预测每个片段的掩码和标签。 通过用实例查询替换语义查询,SparseOcc 可以轻松扩展到全景占用。
4.1 架构深度解析
SparseOcc的架构设计极其精简且激进,它摒弃了所有稠密的3D卷积或3D Transformer操作,取而代之的是稀疏体素解码器(Sparse Voxel Decoder)和掩码Transformer(Mask Transformer)。
4.1.1 稀疏体素解码器:由粗到精的剪枝艺术
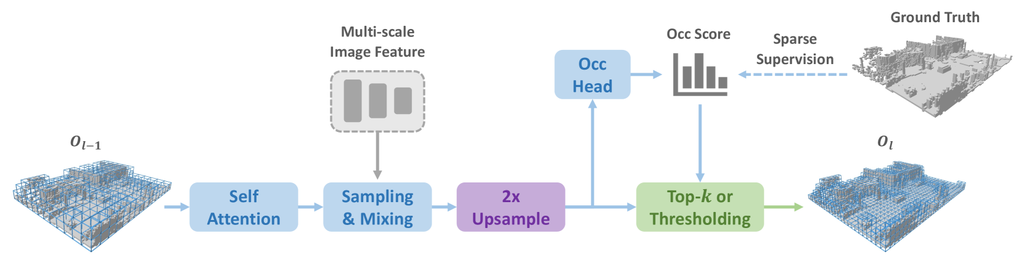
图4.3:稀疏体素解码器采用三层从粗到细的管道。 在每一层中,利用类似 Transformer 的架构来进行 3D-2D 交互。 在每一层的末尾,体素分辨率被上采样 2× 倍,并估计体素占用的概率。
为了避免处理空体素,SparseOcc采用了一种由粗到精(Coarse-to-Fine)的级联策略。
初始层(Coarse Level):网络首先在非常低的分辨率下生成一组稀疏的体素Token。由于分辨率极低,即便处理所有体素,计算量也微乎其微。
占据预测与剪枝(Pruning):在每一层,网络都会利用当前分辨率的体素特征预测一个“占据分数”。
Top-k 策略: 系统根据占据分数排序,只保留分数最高的 k个体素。
阈值策略: 或者设定一个阈值,低于该分数的体素直接丢弃。
上采样(Upsampling):
- 被保留下来的“存活”体素会被分裂(上采样)成下一级分辨率的体素(例如1个粗体素分裂为8个细体素)。这些新体素作为下一层的输入,重复“特征交互-预测-剪枝”的过程。
- 通过这种层层递进的筛选,SparseOcc 实际上是在动态地构建一棵稀疏八叉树(Sparse Octree),只有包含物体表面的分支会被展开,空区域在极早的阶段就被截断了。
4.1.2 Mask Transformer:稀疏空间中的语义赋予
当几何结构(即哪些位置有东西)被稀疏体素解码器确定后,Mask Transformer负责填补语义(即这是什么东西)。
不同于在稠密图上做分割,SparseOcc借鉴了Mask2Former的思想,使用一组稀疏查询(Sparse Queries)来代表场景中的语义成分。
4.2 评价指标的革命:RayIoU
SparseOcc论文不仅提出了新模型,还犀利地指出了当前占据预测领域的一个重大隐患:mIoU指标的缺陷。
4.2.1 mIoU的“厚表面”作弊问题

图4.4:当前指标造成的深度惩罚不一致的图示。 考虑这样一个场景:我们面前有一堵墙,其真实距离为 d,厚度为 dv。 当预测的厚度为 dp≫dv 时,我们会遇到沿深度不一致的惩罚。 具体来说,如果预测的墙 dv 比地面真实值(总距离 d+dv)远,则其 IoU 将为零。 相反,如果预测的墙壁 dv 比真实情况更近(总距离 d−dv),则 IoU 保持在 0.5。 发生这种情况是因为表面后面的所有体素都充满了重复的预测。
目前的占据预测真值(Ground Truth)通常来自于LiDAR点云的体素化。由于LiDAR只能扫描到物体表面,真值中的物体往往是空心的(只有一层壳)。
问题: 如果一个模型预测出的墙体很厚(例如5个体素厚),传统的mIoU指标并不会严厉惩罚这种行为,因为真值中墙体内部是“未观测(Unknown)”区域,通常在评估时被忽略。
作弊激励: 模型发现,预测一个“胖”物体比预测一个“瘦”物体更容易得分。因为“胖”物体能覆盖住真值的薄壳,容忍度更高。但这在实际应用中是灾难性的——机器人会认为墙比实际更厚,导致可通行空间被误判。
4.2.2 RayIoU:回归物理本质
为了解决这个问题,SparseOcc提出了RayIoU(射线交并比)。这个指标模拟了光线的物理传播过程:
- 从相机光心发射一条射线。
- 计算射线在预测体素网格中首次碰撞到的体素(First Hit)。
- 检查这个碰撞点的深度(距离)和语义类别是否与真值一致。
RayIoU的杀伤力:
- 如果模型预测了“厚表面”,射线会在错误的深度提前碰撞,导致深度误差,从而被判定为错误。
- 如果模型在物体前方预测了“幽灵体素”(Ghost Voxel),射线也会提前终止,被判定为错误。
- RayIoU 强迫模型输出几何精准、表面轻薄的预测结果,这对于视觉SLAM和精细规划至关重要。
4.3 性能与效率

图4.5:语义占用预测的可视化比较。 尽管丢弃了超过 90% 的体素,我们的 SparseOcc 仍能有效地对场景的几何形状进行建模并捕获细粒度的细节(例如。,底行中黄色标记的交通锥)。
得益于完全稀疏的设计,SparseOcc在保持高性能的同时,推理速度达到了惊人的 17.3 FPS(在Tesla A100上)。相比之下,基于稠密特征的BEVFormer或MonoScene通常只有2-3 FPS。在Occ3D-nuScenes数据集上,SparseOcc以34.0的RayIoU刷新了SOTA,证明了“稀疏”并不意味着“信息丢失”,反而是“去伪存真”。
5. OccupancyDETR:以物体为中心的混合策略
核心理念: “抓大放小,重点突出”。人类视觉在观察场景时,会聚焦于前景物体(如车、人),而对背景(路、树)仅做余光处理。占据网络也应如此:用最强的算力处理前景,用最省的算力处理背景。
OccupancyDETR 并没有像SparseOcc那样追求极致的纯粹稀疏,也没有像VoxFormer那样依赖深度图。它选择了一条折中且实用的路线:将成熟的2D目标检测技术引入到3D占据预测中。

图5.1:受人类高级视觉处理启发的 3D 语义占用感知概念图。前景定义: 汽车、卡车、行人、骑行者等动态或高风险障碍物被定义为前景。
5.1 架构深度解析
该模型的核心逻辑是将世界二分为前景(Foreground)和背景(Background)。
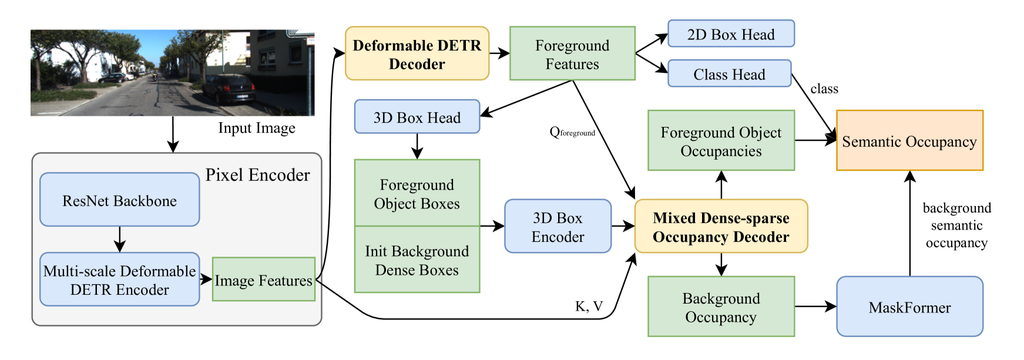
图5.2:OccupancyDETR的系统图。 箭头表示数据在系统内的流动方式。
5.1.1 目标检测模块:DETR的引入
DETR简介:DETR是一种端到端形式的目标检测模型,在本模型中用于直接输出这些物体在图像上的2D边界框以及潜在的3D边界框。
空间先验(Spatial Priors): 这些检测框不再仅仅是输出结果,它们变成了占据预测的“锚点”。模型不再需要在茫茫的3D空间中盲目搜索汽车,而是根据DETR的提示,直接去检测框划定的范围内细化3D结构。
早停匹配预训练(Early Matching Pre-training):
针对DETR类模型训练收敛慢的通病,OccupancyDETR提出了一种预训练策略。它利用预设的ROI(感兴趣区域)与真值进行早期匹配,强行加速了Query的学习过程。这使得模型在训练初期就能快速锁定物体区域,而不必在随机游走中浪费时间。
5.1.2 混合稠密-稀疏解码器(Mixed Dense-Sparse Decoder)
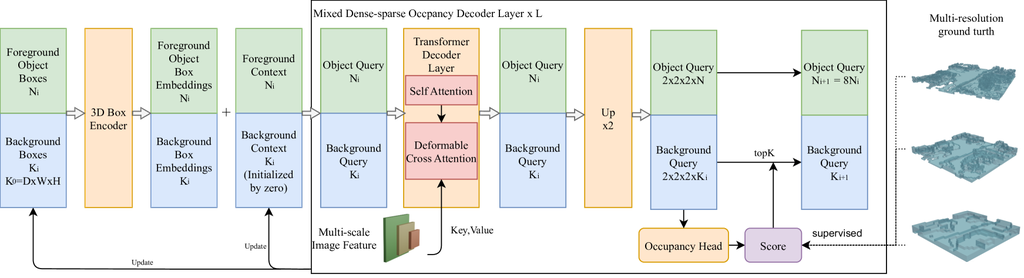
图5.3:混合稠密-稀疏占用解码器的详细架构
混合密集-稀疏占用解码器采用一种策略,其中密集占用解码器用于前景对象,而类似于SparseOcc的稀疏占用解码器用于背景对象。 该策略确保在前景对象的占用解码期间保留全部信息,同时避免在背景占用解码期间对未占用体素(约占整个网格的 90%)进行计算。 这导致资源利用率降低。
如图5.3所示,混合稠密-稀疏3D占用解码器由L层占用解码器层组成。 每层依次在 3D 查询中执行自注意力,然后执行具有多尺度图像特征的可变形交叉注意力。 设背景对象查询的初始形状为(D0,W0,H0),前景对象的数量为N0。 每层都执行上采样,其中输出按 ×2 上采样,3D 查询框被细分为排列在 (2,2,2) 中的 8 个较小的 3D 框。 上采样后,所有前景物体 3D 查询框都被保留,而对于背景物体,根据从占用头获得的分数仅保留前 K 个 3D 查询框(其中 K 是根据数据集和分辨率设置的参数)。 预先计算各种分辨率的地面实况占用网格,以监督占用头。 每一层之后,查询的数量和 3D 框的大小都会发生变化,构成一个从粗到细的过程。
前景:稠密上采样(Dense Upsampling)
对于被DETR检测到的物体框内部区域,模型采用稠密解码。
- 理由: 汽车、行人等物体结构复杂,且体积相对较小(相对于整个场景)。在这些局部区域内进行稠密计算,算力消耗是可控的,同时能保证还原出后视镜、轮胎等精细结构。
背景:稀疏上采样(Sparse Upsampling)
对于检测框以外的区域(道路、建筑物、植被),模型采用类似SparseOcc的稀疏解码策略。
- 理由: 背景物体通常体积巨大且结构简单(如平坦的路面)。对这些区域进行稀疏处理,可以大幅降低显存占用,避免在空旷的街道上方浪费算力。
5.1.3 MaskFormer背景分类
对于背景区域的语义赋予,OccupancyDETR使用了MaskFormer。由于背景类别往往没有清晰的实例边界(一片森林算一棵树还是多棵树?),MaskFormer通过预测二值掩码(Binary Mask)和类别向量的方式,比逐像素分类能生成更连贯的语义区域 。
5.2 性能与适用场景分析
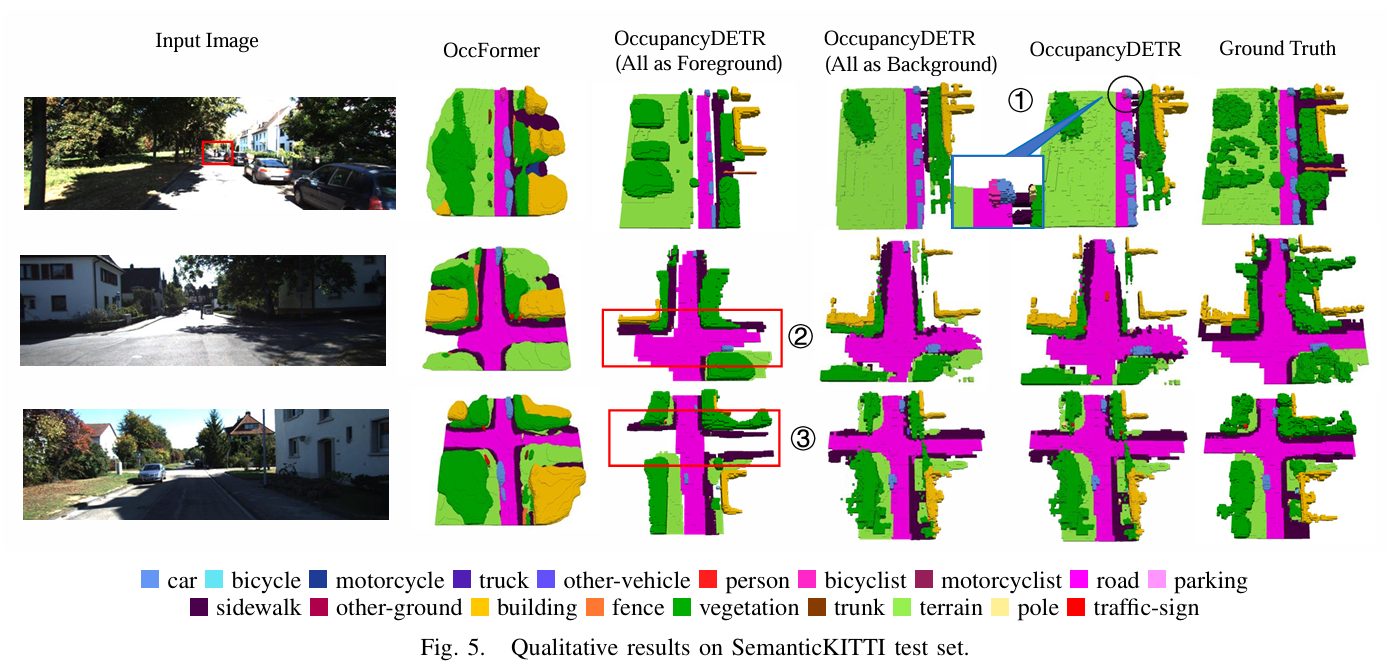
图5.4:SemanticKITTI 测试集的定性结果。
小目标检测的王者:
由于引入了专门的目标检测头(Object Detection Head),OccupancyDETR在小物体(Small Objects)的占据预测上具有天然优势。在纯占据网络中,远处的锥桶或行人可能因为体素化而被平滑掉,但在OccupancyDETR中,只要DETR检测到了它,它就会被作为前景进行稠密重建。实验显示其在SemanticKITTI上对小目标的响应优于纯稀疏方法 。
场景理解的连贯性挑战:
这种人为割裂前景和背景的做法也带来了一些挑战。例如,一辆车停在路面上,车是前景,路是背景。如果两个分支的解码不一致,可能会出现“车轮悬空”或“车陷地里”的几何伪影。混合解码器的融合层需要精心设计以处理这种边界处的特征对齐问题。
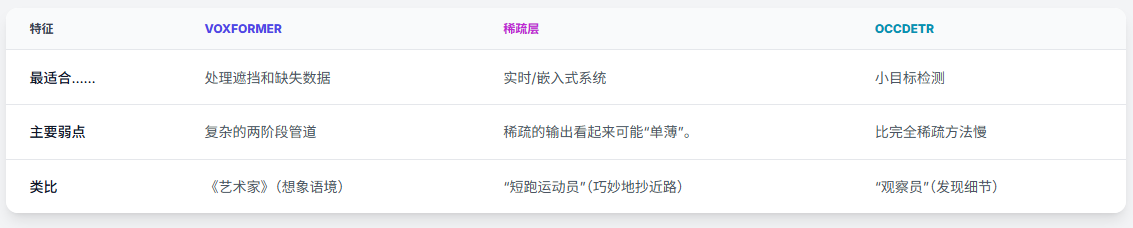
6. 三种以视觉为中心的OCC方法对比分析
6.1 模型概括
6.2 性能对比
6.3 适用场景

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 40
40 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)