知识图谱入门到实战:推荐系统实战实现
Neo4j是基于属性图模型的开源图数据库,核心优势在于高效处理实体间的多跳关联查询,完美适配知识图谱的网状数据结构。属性图模型:数据由“节点(Node)”“关系(Relationship)”“属性(Property)”三部分组成。节点和关系都可携带键值对形式的属性(如用户节点的age属性、购买关系的time属性);无 schema 灵活性:无需预先定义固定表结构,可根据业务需求动态添加节点、关系和
知识图谱是破解“信息过载”“推荐同质化”的关键技术。它能把用户、商品、场景等分散的信息转化为结构化的关联知识,让推荐从“基于行为的相似推荐”升级为“基于语义理解的精准推荐”。
1. 知识图谱入门:核心概念简化理解
知识图谱的本质是“结构化的语义知识库”,核心目标是把碎片化信息转化为“实体-关系-实体”的清晰关联,让机器能像人一样理解事物间的联系。对于推荐系统来说,就是把“用户喜欢商品A”“商品A属于3C品类”“用户常在通勤时购物”这类信息织成一张网,为精准推荐提供支撑。下图是一张简单的知识图谱
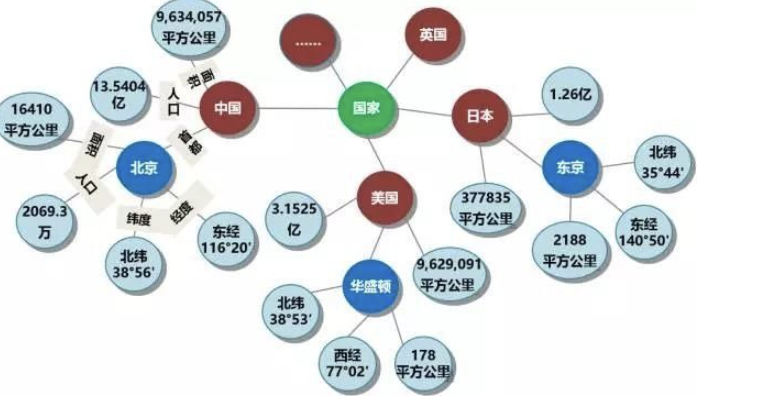
1.1. 核心组成:实体、关系、三元组
这是知识图谱的基础单位,对应推荐系统的核心要素:
- 实体:可独立存在的事物,比如“用户张三”“iPhone 15”“3C数码品类”“通勤场景”,是推荐系统中最核心的业务对象;
- 关系:连接实体的关联,比如“用户张三-购买-iPhone 15”“iPhone 15-属于-3C数码品类”“用户张三-常用场景-通勤”;
- 三元组:知识的最小表达单元,格式为“(实体1, 关系, 实体2)”或“(实体, 属性, 属性值)”,比如“(iPhone 15, 价格, 5999元)”“(用户张三, 年龄, 28岁)”。
1.2. 核心价值:为什么推荐系统需要知识图谱?
传统推荐系统多依赖用户行为(点击、收藏、购买)做协同过滤,但存在明显缺陷:冷启动差(新用户/新商品无行为数据)、推荐同质化(只推相似商品)、无法理解深层需求(比如用户买“羽毛球拍”可能是为了“健身”,而非单纯喜欢球拍)。
知识图谱能解决这些问题:通过实体间的关联推理,实现“需求挖掘”(买球拍→推荐健身装备)、“冷启动支持”(新商品关联已有品类→推荐给该品类偏好用户)、“场景化推荐”(通勤场景→推荐便携商品)。
1.3. 关键架构:从数据到知识的转化流程
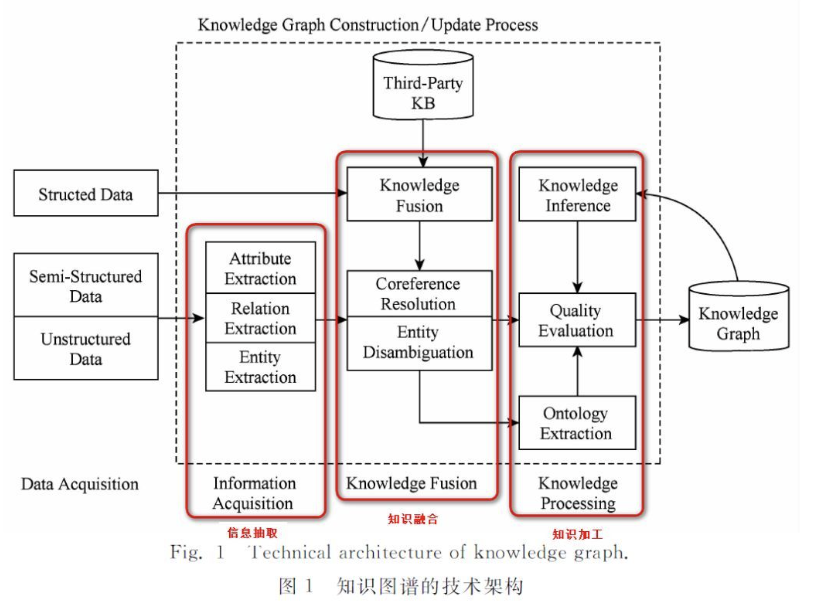
知识图谱的构建是“从原始数据到可用知识”的迭代过程,核心分为3步,适配推荐系统的业务数据特点:
- 信息抽取:从推荐系统的多源数据中提取实体、关系、属性。比如从用户订单表(结构化数据)提取“用户-购买-商品”,从商品评论(非结构化数据)提取“用户-偏好-商品材质”,从商品详情页(半结构化数据)提取“商品-属性-尺寸”;
- 知识融合:消除歧义、整合冗余。比如“张三”和“Zhang San”是同一用户,“手机”和“移动电话”是同一商品类别,需要合并为同一实体;
- 知识加工:完善知识体系。比如构建“商品-品类-一级类目”的层级关系(iPhone 15→手机→3C数码),通过推理补充缺失关系(用户喜欢3C数码→可能喜欢智能穿戴)。
1.3.1. 信息抽取:从异构数据中提取核心要素
信息抽取是知识图谱构建的第一步,目标是从非结构化、半结构化等异构数据源中,自动提取实体、关系、属性等结构化信息,核心解决“如何从海量数据中筛选有效信息单元”的问题。其关键技术包括三大类:
1.3.1.1. 实体抽取(命名实体识别NER)
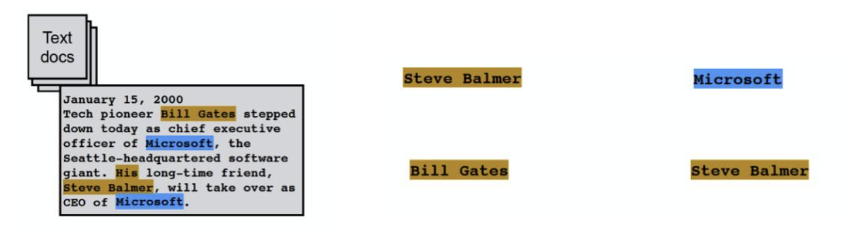
核心是从文本中自动识别命名实体(如推荐系统中的“用户张三”“iPhone 15”),是信息抽取的基础。早期采用人工定义类别+CRF等算法实现,但难以适配互联网动态内容,目前主流转向开放域实体识别:无需预设领域语料,通过“已知实例建模→迭代生成标注语料”或“基于搜索日志语义特征+聚类”等思路,自动发现实体并分类。
1.3.1.2. 关系抽取
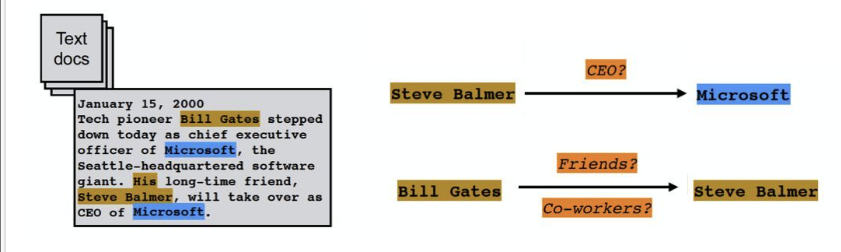
实体抽取得到的是离散实体,关系抽取需进一步提取实体间的关联(如“用户-购买-商品”),才能形成网状结构。技术演进从早期人工制定语法规则,逐步发展到统计机器学习、半监督/无监督学习,当前更倾向于结合开放域与封闭域方法,提升复杂场景的适配能力。
1.3.1.3. 属性抽取
目标是采集实体的属性信息(如“iPhone 15-价格-5999元”“用户张三-年龄-28岁”)。核心思路包括:将属性视为特殊关系转化为关系抽取问题;基于规则从结构化数据中提取;利用百科类半结构化数据训练模型,再应用于非结构化文本;通过数据挖掘定位属性名与属性值的关系模式。
1.3.2. 知识融合:整合碎片信息,消除歧义冗余
信息抽取得到的是分散的“拼图碎片”,存在歧义(同名实体)、冗余(同一实体不同称呼)、逻辑混乱等问题,知识融合需通过“实体链接”和“知识合并”解决这些问题,形成规整的知识单元。
1.3.2.1. 实体链接
将文本中抽取的实体指称项,链接到知识库中正确的实体。流程为:抽取实体指称项→实体消歧(解决同名异义,如“苹果”可能是水果或品牌)与共指消解(解决异名同义,如“张三”与“Zhang San”)→链接到正确实体。当前主流采用集成实体链接思路,利用实体共现关系提升链接准确性。
1.3.2.2. 知识合并
主要处理两类需求:一是合并外部知识库,需解决数据层(实体、属性冲突)和模式层(本体融合)的冗余问题;二是合并关系数据库(RDB2RDF),将结构化数据转化为RDF三元组(如“(用户1, 订单号, 001)”),融入知识图谱。
1.3.3. 知识加工:构建结构化知识体系
经过信息抽取和融合,得到的是基础事实,需通过知识加工形成结构化、网络化的知识体系,核心包括本体构建、知识推理、质量评估三大环节。
1.3.3.1. 本体构建
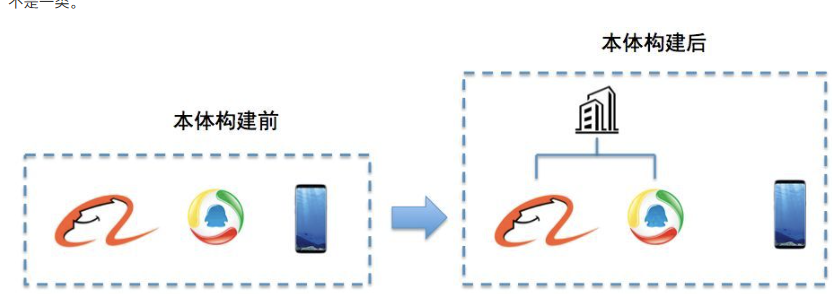
本体是公认的概念集合与框架(如“公司”“商品”“用户”),用于明确实体的层级关系。主流采用数据驱动的自动化构建:先计算实体并列相似度(如“阿里巴巴”与“腾讯”更相似),再抽取上下位关系(如“阿里巴巴-属于-公司”),最终生成本体(明确“公司”包含“阿里巴巴”“腾讯”,与“手机”非同类)。
1.3.3.2. 知识推理
针对知识图谱中缺失的关系或属性,通过推理补全。例如:由“A是B的配偶,B是C的主席,C坐落于D”推出“A生活在D”;由“老虎-科-猫科”“猫科-目-食肉目”推出“老虎-目-食肉目”。推理对象包括实体关系、属性值(由生日推年龄)、概念层次,算法分为基于逻辑、基于图、基于深度学习三类。
1.3.3.3. 质量评估
对知识的可信度量化,舍弃低置信度知识(如来源不可靠的“用户偏好”关系),保障知识库质量,为推荐系统的精准性提供基础。
1.3.4. 知识更新:动态维护知识图谱时效性
知识图谱需随业务数据动态更新,分为概念层(新增概念,如“智能穿戴”品类)和数据层(新增/更新实体、关系,如“新用户-购买-新商品”)更新,核心有两种落地方案:
1.3.4.1. 全面更新方案
以全量更新数据为输入,从零重建知识图谱。优势是逻辑简单,无需处理增量冲突;劣势是资源消耗大(需重新执行抽取、融合等全流程),适合数据量较小、更新频率低的场景(如月度全量商品数据更新)。落地方向:通过自动化脚本封装全流程,定时触发执行,执行后对比新旧图谱差异,人工校验核心实体关系后替换线上图谱。
1.3.4.2. 增量更新方案
仅以新增数据(如实时订单、新注册用户)为输入,向现有图谱添加知识。优势是资源消耗小,适配实时性需求(如电商大促实时更新购买关系);劣势是需处理新增数据与现有知识的冲突(如重复实体、矛盾属性)。落地方向:① 建立增量数据校验规则(如通过实体ID去重、属性值合理性校验);② 轻量级融合(新增实体链接到现有本体,不重构全图谱);③ 采用“规则+少量人工”审核冲突数据(如自动标记矛盾关系,人工确认后更新)。实际落地中,可结合两种方案:日常采用增量更新保障实时性,每月执行一次全面更新校准图谱质量。
- 信息抽取:从推荐系统的多源数据中提取实体、关系、属性。比如从用户订单表(结构化数据)提取“用户-购买-商品”,从商品评论(非结构化数据)提取“用户-偏好-商品材质”,从商品详情页(半结构化数据)提取“商品-属性-尺寸”;
- 知识融合:消除歧义、整合冗余。比如“张三”和“Zhang San”是同一用户,“手机”和“移动电话”是同一商品类别,需要合并为同一实体;
- 知识加工:完善知识体系。比如构建“商品-品类-一级类目”的层级关系(iPhone 15→手机→3C数码),通过推理补充缺失关系(用户喜欢3C数码→可能喜欢智能穿戴)。
1.3.5. 存储选择:图数据库vs关系数据库
推荐系统的知识图谱需要频繁查询“实体的多跳关联”(比如“用户→购买→商品→属于→品类→其他用户偏好”),图数据库(如Neo4j)在这类查询上比关系数据库高效数千倍。原因很简单:关系数据库用表存储,多表关联需复杂join;图数据库直接存储实体和关系,查询时只需“遍历路径”,天然适配网状结构。
2. 前置知识:Cypher查询语言与Neo4j框架核心解析
在进入实战前,需先掌握Neo4j框架的核心概念及Cypher查询语言的基础用法——这是后续数据建模、关系操作的核心工具。Neo4j作为主流图数据库,专为存储和查询网状关系数据设计;Cypher是Neo4j的专用查询语言,语法简洁直观,专注于“实体-关系”的操作逻辑。
2.1. Neo4j框架核心介绍
Neo4j是基于属性图模型的开源图数据库,核心优势在于高效处理实体间的多跳关联查询,完美适配知识图谱的网状数据结构。其核心特性如下:
- 属性图模型:数据由“节点(Node)”“关系(Relationship)”“属性(Property)”三部分组成。节点和关系都可携带键值对形式的属性(如用户节点的age属性、购买关系的time属性);
- 无 schema 灵活性:无需预先定义固定表结构,可根据业务需求动态添加节点、关系和属性,适配推荐系统中多变的实体关联场景;
- 高效关联查询:采用原生图存储引擎,关系通过指针直接关联,多跳查询(如用户→购买→商品→属于→品类)效率远超关系数据库的多表join;
- 支持事务:提供ACID事务支持,保障企业级应用的数据一致性(如推荐系统中用户购买行为的原子性记录)。
2.1.1. Neo4j核心类与Spring Data Neo4j集成类
在Java+SpringBoot环境中,通过Spring Data Neo4j(SDN)集成Neo4j,核心类负责实体映射、数据访问和会话管理,常用类如下:
|
核心类/接口 |
作用说明 |
实战常用场景 |
|
org.neo4j.ogm.annotation.Node |
实体类注解,标识该类映射Neo4j中的节点 |
定义UserNode、ProductNode等实体类 |
|
org.neo4j.ogm.annotation.Relationship |
实体类字段注解,定义节点间的关系(类型、方向) |
声明用户-购买-商品、商品-属于-品类等关系 |
|
org.neo4j.ogm.annotation.Id/@GeneratedValue |
标识节点唯一ID,GeneratedValue指定ID由Neo4j自动生成 |
为所有实体类定义唯一标识 |
|
org.neo4j.ogm.session.Session |
Neo4j会话对象,负责执行Cypher查询、提交事务 |
自定义复杂查询时获取会话执行Cypher |
|
org.springframework.data.neo4j.repository.Neo4jRepository |
数据访问层接口,继承后自动获得CRUD方法,支持自定义Cypher查询 |
定义UserRepository、ProductRepository等,实现数据增删改查 |
|
org.springframework.data.neo4j.repository.query.Query |
Repository接口方法注解,用于自定义Cypher查询语句 |
实现复杂关联查询(如查询用户偏好品类的商品) |
|
org.springframework.data.neo4j.repository.query.Param |
参数注解,将方法参数映射到Cypher查询中的占位符 |
传递动态参数(如userId、categoryId)到自定义查询 |
2.1.2. 核心类用法示例
以实体映射和Repository定义为例,展示核心类的基础用法:
// 1. 节点实体映射(核心注解使用)
@Data
@Node("User") // 映射Neo4j中的User节点
public class UserNode {
@Id
@GeneratedValue // 由Neo4j自动生成唯一ID
private Long id;
@Property("userId") // 映射节点属性userId
private String userId;
// 关系定义:用户-购买-商品(出边)
@Relationship(type = "BUY", direction = Relationship.Direction.OUTGOING)
private List<ProductNode> boughtProducts;
}
// 2. Repository接口定义(继承Neo4jRepository,使用@Query自定义查询)
public interface UserRepository extends Neo4jRepository<UserNode, Long> {
// 自定义查询:根据用户ID查询关联的商品、品类(使用@Param映射参数)
@Query("MATCH (u:User{userId:$userId})-[r]->(n) RETURN u, r, n")
UserNode findUserWithRelations(@Param("userId") String userId);
}
// 3. 服务层中使用Repository和Session
@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
private final SessionFactory sessionFactory; // 用于获取Neo4j Session
// 示例1:使用Repository执行简单查询
public UserNode getUserById(String userId) {
return userRepository.findUserWithRelations(userId);
}
// 示例2:获取Session执行复杂Cypher查询
public List<ProductNode> getUserBoughtProducts(String userId) {
Session session = sessionFactory.openSession();
String cypher = "MATCH (u:User{userId:$userId})-[:BUY]->(p:Product) RETURN p";
return session.query(ProductNode.class, cypher, Collections.singletonMap("userId", userId))
.stream()
.map(map -> map.get("p"))
.collect(Collectors.toList());
}
}2.2. Cypher查询语言基础
Cypher语法设计借鉴了SQL和图形理论,核心是通过“模式匹配”定位节点和关系,完成查询、新增、修改、删除操作。推荐系统中常用的Cypher操作如下:
2.2.1. 核心语法要素
- 节点表示:用括号
(n:Label)表示节点,n是节点别名,Label是节点标签(如User、Product),可指定属性过滤(如(u:User{userId:'123'})); - 关系表示:用中括号
[:RELATION_TYPE]表示关系,RELATION_TYPE是关系类型(如BUY、BELONG_TO),方向用->或<-表示(如(u:User)-[:BUY]->(p:Product)); - 模式匹配:用MATCH关键字指定要匹配的“节点-关系”模式,是Cypher的核心;
- 结果返回:用RETURN关键字指定要返回的节点、关系或属性;
- 条件过滤:用WHERE关键字添加过滤条件(如属性匹配、关系存在性);
- 限制数量:用LIMIT关键字限制返回结果数量,适配推荐系统分页需求。
2.2.2. 推荐系统常用Cypher操作示例
结合推荐系统业务场景,展示高频Cypher操作:
-- 1. 匹配查询:查询用户123购买的所有商品(用户-购买-商品关系)
MATCH (u:User{userId:'123'})-[:BUY]->(p:Product)
RETURN p.productId, p.productName, p.price
LIMIT 10;
-- 2. 匹配查询:查询属于3C品类且适配通勤场景的商品(多关系关联)
MATCH (p:Product)-[:BELONG_TO]->(c:Category{categoryName:'3C数码'})
MATCH (p)-[:ADAPT_TO]->(s:Scene{sceneName:'通勤'})
RETURN p.productId, p.productName;
-- 3. 新增节点:新增用户节点(新用户注册场景)
CREATE (u:User{userId:'456', userName:'李四', age:28})
RETURN u;
-- 4. 新增关系:为用户456和商品789建立购买关系
MATCH (u:User{userId:'456'}), (p:Product{productId:'789'})
CREATE (u)-[:BUY{buyTime:'2024-05-01'}]->(p)
RETURN u, p;
-- 5. 更新属性:更新商品789的价格
MATCH (p:Product{productId:'789'})
SET p.price = 5499.00
RETURN p;
-- 6. 删除关系:删除用户456和商品789的购买关系
MATCH (u:User{userId:'456'})-[r:BUY]->(p:Product{productId:'789'})
DELETE r;
-- 7. 聚合查询:统计各品类的商品数量(用于推荐热门品类)
MATCH (p:Product)-[:BELONG_TO]->(c:Category)
RETURN c.categoryName, COUNT(p) AS productCount
ORDER BY productCount DESC
LIMIT 5;掌握上述Cypher基础操作和Neo4j核心类用法后,即可顺利开展推荐系统知识图谱的实战构建工作。
3. 实战:推荐系统知识图谱构建(Java+Neo4j)
本次实战以“电商推荐系统”为背景,构建“用户-商品-品类-场景”四核心实体的知识图谱,覆盖从环境搭建、数据建模、关系建立到新增数据维护的全流程。技术栈:Java+SpringBoot+Neo4j(图数据库),贴合企业级开发需求。
3.1.1. 环境准备:Docker部署Neo4j+SpringBoot集成
Neo4j是开源图数据库,支持Cypher查询语言(专门用于图数据操作),用Docker部署可快速搭建环境,SpringBoot通过专用依赖实现集成。
3.1.1.1. Docker部署Neo4j
创建docker-compose.yml文件,配置Neo4j服务(包含必要插件APOC,用于复杂数据操作):
version: '3.8'
services:
neo4j:
image: neo4j
container_name: neo4j-recommend
restart: always
ports:
- "7474:7474" # 网页管理端端口
- "7687:7687" # 程序连接端口(Bolt协议)
volumes:
- ./neo4j/data:/data # 数据持久化
- ./neo4j/plugins:/plugins # 插件目录
environment:
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_apoc_import_file_use__neo4j__config=true
- NEO4JLABS_PLUGINS=["apoc"] # 启用APOC插件
- NEO4J_dbms_security_procedures_unrestricted=apoc.*
- NEO4J_dbms_memory_heap_max__size=2G # 调整堆内存,避免数据量大时卡顿执行命令启动服务:docker-compose up -d,启动后访问http://localhost:7474,初始用户名/密码:neo4j/neo4j,首次登录需修改密码(实战中记为xxx)。
3.1.1.2. SpringBoot集成Neo4j
在SpringBoot项目中添加依赖(pom.xml),核心依赖为spring-boot-starter-data-neo4j:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
<!-- 工具类依赖,用于字符串处理等 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>配置Neo4j连接信息(application.yml):
spring:
neo4j:
uri: neo4j://localhost:7687 # Bolt协议连接地址
authentication:
username: neo4j
password: xxx # 修改后的Neo4j密码3.1.2. 数据建模:定义推荐系统核心实体与关系
结合推荐系统业务,核心实体包括:用户(User)、商品(Product)、品类(Category)、场景(Scene)。用Spring Data Neo4j的注解定义实体类,映射Neo4j的节点和关系。
核心注解说明:
- @Node:标识类为Neo4j中的节点实体(如@Node("User")表示该类对应User节点);
- @Id + @GeneratedValue:定义节点唯一ID,由Neo4j自动生成;
- @Property:映射节点属性(如@Property("userName")表示该字段对应节点的userName属性);
- @Relationship:定义节点间的关系,type指定关系名称,direction指定关系方向(OUTGOING表示“从当前节点指向目标节点”)。
3.1.2.1. 实体类定义
import lombok.Data;
import org.neo4j.ogm.annotation.*;
import java.util.List;
// 1. 用户实体
@Data
@Node("User")
public class UserNode {
@Id
@GeneratedValue
private Long id; // Neo4j自动生成的唯一ID
@Property("userId")
private String userId; // 业务系统中的用户ID(如UUID)
@Property("userName")
private String userName; // 用户名
@Property("age")
private Integer age; // 年龄(用于个性化推荐)
// 关系1:用户-购买-商品(出边,从用户指向商品)
@Relationship(type = "BUY", direction = Relationship.Direction.OUTGOING)
private List<ProductNode> boughtProducts;
// 关系2:用户-偏好-品类(出边,从用户指向品类)
@Relationship(type = "PREFER", direction = Relationship.Direction.OUTGOING)
private List<CategoryNode> preferredCategories;
// 关系3:用户-常用场景-场景(出边,从用户指向场景)
@Relationship(type = "FREQUENT_SCENE", direction = Relationship.Direction.OUTGOING)
private List<SceneNode> frequentScenes;
}
// 2. 商品实体
@Data
@Node("Product")
public class ProductNode {
@Id
@GeneratedValue
private Long id;
@Property("productId")
private String productId; // 业务系统商品ID
@Property("productName")
private String productName; // 商品名称
@Property("price")
private Double price; // 价格
@Property("stock")
private Integer stock; // 库存
// 关系1:商品-属于-品类(出边,从商品指向品类)
@Relationship(type = "BELONG_TO", direction = Relationship.Direction.OUTGOING)
private CategoryNode category;
// 关系2:商品-适配场景-场景(出边,从商品指向场景)
@Relationship(type = "ADAPT_TO", direction = Relationship.Direction.OUTGOING)
private List<SceneNode> adaptScenes;
}
// 3. 品类实体(支持层级:一级品类→二级品类→商品)
@Data
@Node("Category")
public class CategoryNode {
@Id
@GeneratedValue
private Long id;
@Property("categoryId")
private String categoryId; // 品类ID
@Property("categoryName")
private String categoryName; // 品类名称(如3C数码、手机、智能穿戴)
@Property("level")
private Integer level; // 品类层级(1:一级,2:二级)
// 关系1:品类-包含-子品类(出边,父品类指向子品类)
@Relationship(type = "CONTAIN", direction = Relationship.Direction.OUTGOING)
private List<CategoryNode> subCategories;
// 关系2:品类-属于-父品类(入边,子品类指向父品类)
@Relationship(type = "BELONG_TO", direction = Relationship.Direction.INCOMING)
private CategoryNode parentCategory;
}
// 4. 场景实体
@Data
@Node("Scene")
public class SceneNode {
@Id
@GeneratedValue
private Long id;
@Property("sceneId")
private String sceneId; // 场景ID
@Property("sceneName")
private String sceneName; // 场景名称(如通勤、居家、健身、送礼)
@Property("description")
private String description; // 场景描述(用于推荐匹配)
}3.1.2.2. 数据赋值逻辑:从业务系统同步数据
推荐系统的知识图谱数据多来自现有业务系统(如用户中心、商品中心、订单系统),数据赋值核心是“业务数据→实体属性”的映射,需注意数据清洗和一致性校验:
- 用户数据:从用户中心获取userId、userName、age,从订单系统统计“购买的商品”,从用户行为日志(点击、收藏)分析“偏好的品类”,从场景埋点数据(如登录时间、地点)提取“常用场景”;
- 商品数据:从商品中心获取productId、productName、price、stock,手动标注或通过算法识别“所属品类”和“适配场景”(如“便携充电宝”适配“通勤场景”);
- 品类数据:从商品中心的品类表获取categoryId、categoryName、level,构建层级关系(如“3C数码”包含“手机”,“手机”包含“智能手机”);
- 场景数据:结合业务需求预定义场景(通勤、居家等),或从用户评论、行为日志中提取新增场景(如“露营”)。
3.1.3. 关系建立:构建实体间的关联网络
关系是知识图谱的核心,推荐系统的关键关系包括“用户-购买-商品”“商品-属于-品类”“用户-偏好-品类”等。下面通过“数据同步服务”实现关系的批量建立,同时提供“单条数据新增”的接口。
3.1.3.1. 数据访问层:Repository接口
继承Neo4jRepository,获得默认的增删改查方法,同时支持自定义Cypher查询(推荐系统常用的关联查询):
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
// 用户Repository
public interface UserRepository extends Neo4jRepository<UserNode, Long> {
// 自定义查询:根据用户ID查询用户及关联的商品、品类、场景
@Query("MATCH (u:User{userId:$userId})-[r]->(n) RETURN u, r, n")
UserNode findUserWithRelations(@Param("userId") String userId);
// 推荐系统核心查询:查询偏好某品类的所有用户(用于品类推荐)
@Query("MATCH (u:User)-[:PREFER]->(c:Category{categoryId:$categoryId}) RETURN u")
List<UserNode> findUsersByPreferredCategory(@Param("categoryId") String categoryId);
}
// 商品Repository
public interface ProductRepository extends Neo4jRepository<ProductNode, Long> {
// 推荐系统核心查询:查询属于某品类且适配某场景的商品(场景化推荐)
@Query("MATCH (p:Product)-[:BELONG_TO]->(c:Category{categoryId:$categoryId}) " +
"MATCH (p)-[:ADAPT_TO]->(s:Scene{sceneId:$sceneId}) RETURN p")
List<ProductNode> findProductsByCategoryAndScene(
@Param("categoryId") String categoryId,
@Param("sceneId") String sceneId);
}
// 品类Repository
public interface CategoryRepository extends Neo4jRepository<CategoryNode, Long> {
// 查询某品类的所有子品类(用于层级推荐)
@Query("MATCH (c:Category{categoryId:$categoryId})-[:CONTAIN]->(subC:Category) RETURN subC")
List<CategoryNode> findSubCategories(@Param("categoryId") String categoryId);
}
// 场景Repository
public interface SceneRepository extends Neo4jRepository<SceneNode, Long> {
// 根据场景名称查询场景(用于用户场景匹配)
SceneNode findBySceneName(String sceneName);
}3.1.3.2. 服务层:实现关系建立与数据同步
服务层核心职责:从业务系统同步数据,构建实体间的关系,提供批量同步和单条新增接口。以“用户-购买-商品”关系建立为例:
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
@Service
@RequiredArgsConstructor
public class KnowledgeGraphSyncService {
private final UserRepository userRepository;
private final ProductRepository productRepository;
private final OrderFeignClient orderFeignClient; // 调用订单系统Feign接口
// 批量同步用户-购买-商品关系
public void syncUserBuyProductRelations() {
// 1. 从订单系统获取所有订单数据(userId + productId列表)
List<OrderDTO> orderList = orderFeignClient.getAllOrders();
// 2. 按userId分组,获取每个用户购买的商品ID列表
Map<String, List<String>> userProductMap = orderList.stream()
.collect(Collectors.groupingBy(
OrderDTO::getUserId,
Collectors.mapping(OrderDTO::getProductId, Collectors.toList())
));
// 3. 构建关系:查询用户和商品实体,建立BUY关系
userProductMap.forEach((userId, productIds) -> {
// 3.1 查询用户实体(若不存在则创建)
UserNode userNode = userRepository.findUserWithRelations(userId);
if (userNode == null) {
userNode = createUserNodeFromUserCenter(userId); // 从用户中心获取数据创建用户节点
}
// 3.2 查询商品实体列表
List<ProductNode> productNodes = productIds.stream()
.map(productId -> productRepository.findByProductId(productId)) // 需自定义findByProductId方法
.filter(Objects::nonNull)
.collect(Collectors.toList());
// 3.3 建立用户-购买-商品关系
userNode.setBoughtProducts(productNodes);
userRepository.save(userNode); // 保存用户节点,自动同步关系
});
}
// 单条新增商品-属于-品类关系(适用于新商品上架场景)
public void addProductBelongToCategory(String productId, String categoryId) {
// 1. 查询商品和品类实体
ProductNode productNode = productRepository.findByProductId(productId);
CategoryNode categoryNode = categoryRepository.findByCategoryId(categoryId);
// 2. 校验实体存在性
if (productNode == null || categoryNode == null) {
throw new RuntimeException("商品或品类不存在");
}
// 3. 建立关系并保存
productNode.setCategory(categoryNode);
productRepository.save(productNode);
}
// 辅助方法:从用户中心创建用户节点
private UserNode createUserNodeFromUserCenter(String userId) {
UserDTO userDTO = userFeignClient.getUserById(userId); // 调用用户中心接口
UserNode userNode = new UserNode();
userNode.setUserId(userId);
userNode.setUserName(userDTO.getUserName());
userNode.setAge(userDTO.getAge());
return userRepository.save(userNode);
}
}3.1.4. 聚类存储:优化推荐系统查询效率
当知识图谱数据量较大(如百万级用户、千万级商品)时,需要通过“聚类存储”优化查询效率,核心思路是“按业务维度分区”,让推荐系统的查询只聚焦于相关数据:
3.1.4.1. 按品类聚类
将同一品类的商品、关联用户、适配场景存储在同一“分区”(Neo4j通过标签和属性索引实现)。比如给3C数码品类的商品添加标签“3C”,查询时通过标签过滤,减少数据扫描范围:
// 给商品添加品类标签(在ProductNode中新增label字段)
@Property("label")
private String label; // 如"3C"、"服饰"
// 新增商品时设置标签
productNode.setLabel(categoryNode.getCategoryName());
productRepository.save(productNode);
// 推荐系统查询:只查询3C品类的商品
@Query("MATCH (p:Product{label:'3C'})-[:ADAPT_TO]->(s:Scene{sceneId:$sceneId}) RETURN p")
List<ProductNode> find3CProductsByScene(@Param("sceneId") String sceneId);3.1.4.2. 创建索引:加速核心查询
对推荐系统高频查询的属性创建索引(如userId、productId、categoryId),Neo4j会自动优化查询计划:
// 在Repository接口中通过@Index注解创建索引
@Node("User")
public class UserNode {
@Id
@GeneratedValue
private Long id;
@Property("userId")
@Index(unique = true) // 唯一索引,加速用户ID查询
private String userId;
// 其他属性...
}
// 商品ID创建索引
@Node("Product")
public class ProductNode {
@Property("productId")
@Index(unique = true)
private String productId;
// 其他属性...
}3.1.5. 新增数据:关系变化与维护策略
推荐系统是动态的(新用户注册、新商品上架、用户行为更新),新增数据时需处理好“关系的新增、更新、删除”,避免知识图谱过时或出现冗余关系:
3.1.5.1. 新增用户:冷启动关系构建
新用户无行为数据时,通过“用户属性-品类匹配”构建初始关系(冷启动策略):比如新用户年龄25岁,系统统计25岁用户偏好的TOP3品类,自动建立“用户-偏好-品类”关系:
// 新用户冷启动关系构建
public void initNewUserRelations(String userId) {
UserNode userNode = createUserNodeFromUserCenter(userId);
Integer age = userNode.getAge();
// 查询同年龄段用户偏好的TOP3品类
List<CategoryNode> hotCategories = userRepository.findHotCategoriesByAge(age);
// 建立初始偏好关系
userNode.setPreferredCategories(hotCategories);
userRepository.save(userNode);
}3.1.5.2. 新增商品:关联关系自动补全
新商品上架时,根据商品名称和属性自动匹配品类和场景,建立“商品-属于-品类”“商品-适配-场景”关系:
// 新商品关联关系自动补全
public void autoCompleteNewProductRelations(String productId) {
ProductNode productNode = productRepository.findByProductId(productId);
String productName = productNode.getProductName();
// 1. 自动匹配品类(通过商品名称关键词匹配)
CategoryNode categoryNode = categoryRepository.findCategoryByKeyword(productName);
if (categoryNode != null) {
productNode.setCategory(categoryNode);
}
// 2. 自动匹配场景(如含“便携”关键词适配“通勤场景”)
List<SceneNode> sceneNodes = new ArrayList<>();
if (productName.contains("便携")) {
SceneNode commuteScene = sceneRepository.findBySceneName("通勤");
sceneNodes.add(commuteScene);
}
productNode.setAdaptScenes(sceneNodes);
productRepository.save(productNode);
}3.1.5.3. 关系更新:用户行为变化同步
当用户行为变化时(如取消收藏、新增购买),同步更新知识图谱关系:比如用户取消购买某商品,删除“用户-购买-商品”关系:
// 取消购买关系
public void cancelUserBuyProduct(String userId, String productId) {
UserNode userNode = userRepository.findUserWithRelations(userId);
if (userNode == null) {
throw new RuntimeException("用户不存在");
}
// 过滤掉要取消的商品
List<ProductNode> updatedProducts = userNode.getBoughtProducts().stream()
.filter(product -> !product.getProductId().equals(productId))
.collect(Collectors.toList());
userNode.setBoughtProducts(updatedProducts);
userRepository.save(userNode);
}3.1.5.4. 关系清理:冗余数据定期删除
定期清理无效关系(如商品下架后,删除“用户-购买-下架商品”关系),避免影响推荐准确性:
// 清理下架商品的关联关系
public void cleanOfflineProductRelations() {
// 查询所有下架商品(stock=0)
List<ProductNode> offlineProducts = productRepository.findProductsByStock(0);
// 删除用户-购买-下架商品关系
offlineProducts.forEach(product -> {
@Query("MATCH (u:User)-[r:BUY]->(p:Product{productId:$productId}) DELETE r")
void deleteUserBuyOfflineProduct(@Param("productId") String productId);
deleteUserBuyOfflineProduct(product.getProductId());
});
}3.1.6. 推荐系统应用:基于知识图谱的查询示例
结合前面的知识图谱,实现3个推荐系统核心场景的查询,展示知识图谱的价值:
3.1.6.1. 场景化推荐:查询用户常用场景适配的商品
// 给用户推荐常用场景适配的商品
public List<ProductNode> recommendProductsByUserScene(String userId) {
UserNode userNode = userRepository.findUserWithRelations(userId);
if (userNode == null) {
throw new RuntimeException("用户不存在");
}
// 1. 获取用户常用场景
List<SceneNode> frequentScenes = userNode.getFrequentScenes();
if (frequentScenes.isEmpty()) {
return Collections.emptyList();
}
// 2. 查询每个场景适配的商品(去重)
return frequentScenes.stream()
.flatMap(scene -> productRepository.findProductsByScene(scene.getSceneId()).stream())
.distinct()
.collect(Collectors.toList());
}3.1.6.2. 品类推荐:查询用户偏好品类的子品类商品
// 推荐用户偏好品类的子品类商品
public List<ProductNode> recommendProductsByPreferredCategory(String userId) {
UserNode userNode = userRepository.findUserWithRelations(userId);
if (userNode == null) {
throw new RuntimeException("用户不存在");
}
// 1. 获取用户偏好的品类
List<CategoryNode> preferredCategories = userNode.getPreferredCategories();
if (preferredCategories.isEmpty()) {
return Collections.emptyList();
}
// 2. 查询每个偏好品类的子品类
List<CategoryNode> subCategories = preferredCategories.stream()
.flatMap(category -> categoryRepository.findSubCategories(category.getCategoryId()).stream())
.collect(Collectors.toList());
// 3. 查询子品类下的商品
return subCategories.stream()
.flatMap(subCategory -> productRepository.findProductsByCategory(subCategory.getCategoryId()).stream())
.distinct()
.collect(Collectors.toList());
}3.1.6.3. 冷启动推荐:给新商品推荐潜在用户
// 新商品冷启动:推荐潜在用户
public List<UserNode> recommendPotentialUsersForNewProduct(String productId) {
ProductNode productNode = productRepository.findByProductId(productId);
if (productNode == null) {
throw new RuntimeException("商品不存在");
}
// 1. 获取商品所属品类
CategoryNode categoryNode = productNode.getCategory();
// 2. 查询偏好该品类的用户(潜在用户)
return userRepository.findUsersByPreferredCategory(categoryNode.getCategoryId());
}4. 总结:知识图谱在推荐系统中的落地要点
作为Java工程师,在推荐系统中落地知识图谱,核心是“业务驱动数据建模”和“高效维护关系网络”:
- 建模优先:围绕推荐场景确定核心实体和关系,避免过度设计(比如初期无需引入“品牌”“商家”等实体,聚焦用户-商品-品类-场景即可);
- 效率为王:通过索引、聚类存储优化查询性能,适配推荐系统的低延迟要求;
- 动态维护:建立数据同步机制,确保新增数据的关系及时更新,定期清理无效关系;
- 价值落地:从冷启动、场景化推荐等痛点场景切入,逐步扩大知识图谱的应用范围。
后续可进一步探索“知识推理”在推荐中的应用(如通过“用户喜欢A商品→A商品属于B品类→B品类包含C商品→推荐C商品”),让推荐更具智能化和精准度。
四、参考资料
使用 Spring Boot + Neo4j 实现知识图谱功能开发-阿里云开发者社区
https://zhuanlan.zhihu.com/p/1932781213434774802
1. 通俗易懂解释知识图谱(Knowledge Graph) - hyc339408769 - 博客园、
深入解析:Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络! - yjbjingcha - 博客园
https://www.51cto.com/article/794359.html
https://juejin.cn/post/7411047482651574287
https://juejin.cn/post/7442137496489000986?from=search-suggest

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)