机器学习:PCA降维及其在人脸识别中的应用(含代码实现)
降维是指将高维数据通过某种方式映射到低维空间的过程,同时尽量保留原数据中的关键信息。在机器学习和数据挖掘中,尤其是图像处理、文本分析、生物信息等领域中,数据往往具有成百上千的特征维度,这些高维特征不仅计算开销大,还容易引发所谓的“维度灾难简单来说,降维的目的就是——用更少的特征,表示尽可能多的原始信息。先读取人脸数据并打标签。用PCA手动降维,提取主成分。用KNN基于降维特征训练模型并预测。输出准
一、前言
首先我们应该了解维度或者说维数的概念,在数学维度被定义为独立参数的数目,而在物理学中被定义为独立时空的数目。
例 “点是 0 维、直线是 1 维、平面是 2 维、体是 3 维”
- 点基于点是 0 维:在点上定位一个点,不需要参数
- 点基于直线是 1 维:在直线上定位一个点,需要 1 个参数
- 点基于平面是 2 维:在平面上定位一个点,需要 2 个参数
- 点基于体是 3 维:在体上定位一个点,需要 3 个参数
1. 什么是降维?
降维是指将高维数据通过某种方式映射到低维空间的过程,同时尽量保留原数据中的关键信息。在机器学习和数据挖掘中,尤其是图像处理、文本分析、生物信息等领域中,数据往往具有成百上千的特征维度,这些高维特征不仅计算开销大,还容易引发所谓的“维度灾难”。
简单来说,降维的目的就是——用更少的特征,表示尽可能多的原始信息。
2. 为什么要降维?
在实际应用中,尤其是图像识别任务中,降维有以下几个关键好处:
-
提高计算效率
图像数据非常庞大(比如一张112×92的人脸图像就有10304个像素点),直接处理会导致运算量剧增。降维后,大大减少了内存和计算资源的需求。 -
降低噪声干扰
高维数据中往往包含冗余信息或噪声,降维可以在一定程度上过滤掉这些干扰,提高模型泛化能力。 -
可视化与特征提取
在2D或3D空间中可视化原始数据几乎不可能,降维后可以更直观理解数据分布,便于发现潜在结构。 -
提升模型性能
维度越高,训练数据所需数量越多,否则模型容易过拟合。降维能有效减少过拟合风险,提升分类或识别准确率。
3. 人脸识别中的降维:为什么特别重要?
人脸图像本质上是一组灰度像素的组合,一张图像可能包含上万维特征,但真正有区分能力的信息(如眼睛、嘴巴、脸型等结构)可能只占很小一部分。
因此,在人脸识别任务中,我们不需要保留全部像素,而是提取出最“能代表一张脸”的低维特征:
-
比如:你并不需要看到一个人的完整照片,只要看到他的眉毛、鼻子和轮廓,就可以大致判断出他是谁。
-
PCA 就是这样的一种工具,它能自动找出最能区分不同人脸的方向,并压缩到更小的空间中。
4. PCA的数学原理
主成分分析(PCA, Principal Component Analysis)是一种经典的线性降维算法,它的核心思想是:
找到一个新的坐标系,使得原始数据在这些新坐标上的投影方差最大,从而保留尽可能多的数据信息。
核心步骤如下:
-
去中心化(zero-mean):减去每个特征的均值
-
计算协方差矩阵:观察各维度间的关系
-
特征值分解:提取协方差矩阵的主方向(特征向量)
-
选取前K个主成分:对应最大的K个特征值
-
数据投影到主成分空间:实现降维
简而言之,PCA就是一种把原始坐标系“旋转”到最能代表数据的方向的方法。
二、PCA基本原理
PCA(主成分分析)的目标,是将原始高维数据映射到一个新的坐标系中,使得投影后的数据具有最大的信息保留度。这一过程建立在线性代数与概率统计的基础之上,下面我们来逐步解构这个过程。
1. 向量空间与主成分的概念
我们可以把每一张图像(或者任何样本)看作一个向量:
一张 112×92 的人脸图像可以展开为一个 10304 维的向量,每一维表示一个像素灰度值。
主成分(Principal Components)就是这个点云数据中方差最大的方向。
-
第一个主成分方向(PC1):数据方差最大的方向;
-
第二个主成分方向(PC2):与PC1正交、次大方差方向;
-
以此类推……
简而言之,PCA 就是找到一组新坐标轴,使得数据在这些轴上的“分散程度”(方差)尽可能大。
2. 协方差矩阵的构造
我们如何量化“数据在某个方向上分布得有多分散”呢?答案是——协方差矩阵。
协方差的定义:
对于两个变量 xxx 和 yyy,它们的协方差为:
Cov(x,y)=1n∑i=1n(xi−xˉ)(yi−yˉ)\text{Cov}(x, y) = \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})(y_i - \bar{y})Cov(x,y)=n1i=1∑n(xi−xˉ)(yi−yˉ)
-
正值:说明变量正相关;
-
负值:说明变量负相关;
-
0:说明变量无相关性。
协方差矩阵(多维变量):
如果数据集是 n×dn \times dn×d 的矩阵(n个样本,d维特征),则其协方差矩阵是一个 d×dd \times dd×d 的对称矩阵,表示各个维度间的两两关系。
C=1nX⊤X\mathbf{C} = \frac{1}{n} X^\top XC=n1X⊤X
(此处 XXX 已经是中心化后的矩阵,即每一列减去了其均值)
3. 特征值与特征向量提取
我们要找到数据“最有信息的方向”,也就是协方差矩阵的主方向。这个主方向,其实就是协方差矩阵的特征向量。
-
特征向量(Eigenvector):表示方向
-
特征值(Eigenvalue):表示该方向上的方差大小
通过对协方差矩阵做特征分解,我们可以获得:
C⋅vi=λi⋅vi\mathbf{C} \cdot \mathbf{v}_i = \lambda_i \cdot \mathbf{v}_iC⋅vi=λi⋅vi
其中:
-
λi\lambda_iλi:特征值(越大越重要)
-
vi\mathbf{v}_ivi:对应的特征向量(主成分方向)

4. 主成分选择与降维映射
我们获得了所有特征向量(坐标轴方向)后,接下来的操作非常直观:
Step 1:按特征值大小排序
特征值越大,表示该方向的信息越多。所以我们保留前 KKK 个特征值所对应的特征向量。
Step 2:构建投影矩阵 WWW
设 W∈Rd×KW \in \mathbb{R}^{d \times K}W∈Rd×K 是保留的特征向量列矩阵,那么新的低维特征 ZZZ 可以通过投影得到:
Z=X⋅WZ = X \cdot WZ=X⋅W
- 这就是我们说的“把原始数据投影到主成分空间”,实现从 ddd 维到 KKK 维的降维。
图像识别中的举例说明
假设我们有一组 10304 维的人脸图像(112×92),我们通过 PCA 将其降到 50 维,结果如下:
-
原始维度:10304
-
主成分保留:前50个特征方向(累积保留了90%以上信息)
-
新数据:每张图变成 50 维向量,极大加快识别速度
三、PCA实现步骤(以图像为例)
PCA(主成分分析)是一种经典的无监督降维方法,尤其适用于图像数据这种高维输入。下面,我们以人脸图像为例,逐步解释 PCA 的完整流程,并穿插代码逻辑,让原理与实践相结合。
1. 数据中心化:减去均值,使均值为0
PCA 本质上是一种基于协方差的线性变换,而协方差计算的前提是数据必须是中心化的。
中心化步骤:
mean_vals = np.mean(X, axis=0) # 每个像素点的均值
std_vals = np.std(X, axis=0) # 每个像素点的标准差
standardized_X = (X - mean_vals) / std_vals # 标准化数据
中心化后的数据以原点为中心,使得不同样本在同一空间中更公平地比较。
2. 计算协方差矩阵
协方差矩阵反映了不同特征(像素点)之间的线性关系。其计算公式如下:
C=1n−1XTX\mathbf{C} = \frac{1}{n - 1} \mathbf{X}^{T} \mathbf{X}C=n−11XTX
在代码中:
# rowvar=False 表示每列是一个特征,行是样本
cov_matrix = np.cov(standardized_X, rowvar=False)
如果数据维度非常大(如图像),协方差矩阵的维度将是 D × D,即非常大,因此有时也会用奇异值分解(SVD)近似求解。
3. 特征值分解:获取特征值和特征向量
协方差矩阵的特征向量表示数据在各个方向上的主轴,特征值表示在该方向上的方差(也就是数据“能量”)。
# 使用 eigh 保证特征值有序,且协方差矩阵是对称的
eig_vals, eig_vecs = np.linalg.eigh(cov_matrix)
-
特征向量:表示主成分方向
-
特征值:衡量主成分的重要性
4. 选择主成分
PCA 要保留尽可能多的信息的同时降低维度,常用的方法是选择前 k 个特征值对应的主成分。
# 4. 将特征值从大到小排序,选择最大的n_components个主成分
sorted_indices = np.argsort(eig_vals)[::-1]
selected_indices = sorted_indices[:n_components]
# 5. 选取对应的特征向量作为主成分
pcs = eig_vecs[:, selected_indices]
6. 降维映射与重构:从高维映射到低维
降维的实质是将数据从原始空间投影到主成分方向组成的新坐标系中:
Z=Xcentered⋅WZ = X_{\text{centered}} \cdot WZ=Xcentered⋅W
其中 WWW 为选出的主成分矩阵,ZZZ 为降维后的数据。
降维映射代码:
# 6. 将标准化数据投影到主成分空间,实现降维
X_reduced = np.dot(standardized_X, pcs)
7. 图像重构
可以将降维数据逆变换回高维空间,观察信息保留程度:
Xreconstructed=Z⋅WT+meanX_{\text{reconstructed}} = Z \cdot W^{T} + \text{mean}Xreconstructed=Z⋅WT+mean
代码实现:
X_reconstructed = np.dot(reduced_X, principal_components.T) + mean_vals
PCA 通过找到数据“方差最大”的方向,对图像进行压缩与特征提取,使我们在丢失尽可能少信息的前提下,大幅降低计算复杂度。
四、代码分析
1. 导入相关库
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import matplotlib
-
os:文件和路径操作。
-
cv2:OpenCV,用于图像读取和处理。
-
numpy:科学计算。
-
matplotlib.pyplot:绘图。
-
sklearn.model_selection.train_test_split:划分训练集和测试集。
-
sklearn.metrics.accuracy_score:计算分类准确率。
-
sklearn.preprocessing.StandardScaler:数据标准化。
-
sklearn.neighbors.KNeighborsClassifier:K最近邻分类器。
-
matplotlib:为了配置字体。
2. 设置中文字体支持(防止绘图中文乱码)
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 设置黑体字体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
这两行确保绘图时能显示中文标题和标签,且负号不会变成方块。
3. 加载人脸数据集(ORL_Faces)
def load_faces(path='ORL_Faces'):
images = []
labels = []
for i in range(1, 41): # 40个人
for j in range(1, 11): # 每个人10张照片
img_path = os.path.join(path, f"s{i}", f"{j}.pgm")
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) # 以灰度读图
if img is not None:
images.append(img)
labels.append(i)
else:
print(f"无法读取图像:{img_path}")
return np.array(images), np.array(labels)
-
读取文件夹中每个人的10张灰度图像。
-
返回二维数组
images(shape: 样本数 × 图像高 × 图像宽)和对应标签labels。
4. 手动实现 PCA 降维
def manual_pca(X, n_components):
mean_vals = np.mean(X, axis=0)
std_vals = np.std(X, axis=0)
standardized_X = (X - mean_vals) / std_vals # 标准化(零均值,单位方差)
cov_matrix = np.cov(standardized_X, rowvar=False) # 协方差矩阵
eig_vals, eig_vecs = np.linalg.eigh(cov_matrix) # 求特征值和特征向量
sorted_indices = np.argsort(eig_vals)[::-1] # 按特征值从大到小排序
selected_indices = sorted_indices[:n_components] # 选前n个主成分
pcs = eig_vecs[:, selected_indices] # 主成分特征向量矩阵
X_reduced = np.dot(standardized_X, pcs) # 投影到主成分空间
return X_reduced, pcs, mean_vals, std_vals
-
对数据做标准化处理。
-
计算协方差矩阵及其特征值和特征向量。
-
选出最重要的几个特征向量作为主成分。
-
把数据映射到主成分空间,完成降维。
5. 可视化特征脸
def visualize_eigenfaces(components, h, w, num=12):
plt.figure(figsize=(15, 6))
for i in range(min(num, components.shape[1])):
face = components[:, i].reshape(h, w)
plt.subplot(3, 4, i + 1)
plt.imshow(face, cmap='gray')
plt.title(f"特征脸 {i+1}")
plt.axis('off')
plt.tight_layout()
plt.show()
-
将PCA特征向量(特征脸)按图像形式展示。
-
默认展示12张“特征脸”。
6. 显示原图与重建图对比
def show_reconstructed_faces(original, reconstructed, h, w, num=10):
plt.figure(figsize=(15, 4))
for i in range(num):
plt.subplot(2, num, i + 1)
plt.imshow(original[i].reshape((h, w)), cmap='gray')
plt.title("原图", fontsize=9)
plt.axis('off')
plt.subplot(2, num, i + 1 + num)
plt.imshow(reconstructed[i].reshape((h, w)), cmap='gray')
plt.title("PCA重建", fontsize=9)
plt.axis('off')
plt.tight_layout()
plt.show()
-
比较原始图像和用降维后数据逆变换重建的图像。
-
便于观察PCA降维对图像信息的保留情况。
7. 预测结果可视化
def plot_predictions(y_true, y_pred):
plt.figure(figsize=(12, 5))
plt.plot(y_true, 'o-', label='真实标签')
plt.plot(y_pred, 'x-', label='预测标签')
plt.title("KNN + PCA 人脸识别预测对比")
plt.xlabel("样本索引")
plt.ylabel("标签")
plt.legend()
plt.grid(True)
plt.show()
- 用折线图展示每个测试样本的真实标签和预测标签,直观对比。
8. 主程序逻辑
def main():
faces, labels = load_faces('ORL_Faces')
n_samples, h, w = faces.shape
X = faces.reshape((n_samples, -1)) # 转成二维数据,样本数 × 像素数
# 划分训练集和测试集,25%测试
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.25, random_state=42)
# 标准化处理
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)
# PCA降维到100维
n_components = 100
X_train_pca, pcs, mean_vals, std_vals = manual_pca(X_train, n_components)
# 测试集也做同样降维
X_test_pca = (X_test - mean_vals) / std_vals
X_test_pca = np.dot(X_test_pca, pcs)
# KNN训练和预测
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_pca, y_train)
y_pred = knn.predict(X_test_pca)
# 输出准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"\nKNN分类准确率:{accuracy:.2%}")
# 可视化特征脸
visualize_eigenfaces(pcs, h, w, num=12)
# 可视化预测对比
plot_predictions(y_test, y_pred)
# 用PCA逆变换重建测试图像
X_test_reconstructed = np.dot(X_test_pca, pcs.T) * std_vals + mean_vals
show_reconstructed_faces(X_test, X_test_reconstructed, h, w, num=10)
9. 完整代码
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import matplotlib
# 设置中文字体(适配Windows系统)
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
matplotlib.rcParams['axes.unicode_minus'] = False # 正常显示负号
# 加载图像数据集
def load_faces(path='ORL_Faces'):
images = []
labels = []
for i in range(1, 41):
for j in range(1, 11):
img_path = os.path.join(path, f"s{i}", f"{j}.pgm")
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
if img is not None:
images.append(img)
labels.append(i)
else:
print(f"无法读取图像:{img_path}")
return np.array(images), np.array(labels)
# 手动PCA实现
def manual_pca(X, n_components):
# 1. 对数据进行标准化(零均值,单位方差)
mean_vals = np.mean(X, axis=0) # 每个像素点的均值
std_vals = np.std(X, axis=0) # 每个像素点的标准差
standardized_X = (X - mean_vals) / std_vals # 标准化数据
# 2. 计算协方差矩阵
# rowvar=False 表示每列是一个特征,行是样本
cov_matrix = np.cov(standardized_X, rowvar=False)
# 3. 求协方差矩阵的特征值和特征向量
# 使用 eigh 保证特征值有序,且协方差矩阵是对称的
eig_vals, eig_vecs = np.linalg.eigh(cov_matrix)
# 4. 将特征值从大到小排序,选择最大的n_components个主成分
sorted_indices = np.argsort(eig_vals)[::-1]
selected_indices = sorted_indices[:n_components]
# 5. 选取对应的特征向量作为主成分
pcs = eig_vecs[:, selected_indices]
# 6. 将标准化数据投影到主成分空间,实现降维
X_reduced = np.dot(standardized_X, pcs)
# 返回降维数据及用于标准化的参数
return X_reduced, pcs, mean_vals, std_vals
# 特征脸可视化
def visualize_eigenfaces(components, h, w, num=12):
plt.figure(figsize=(15, 6))
for i in range(min(num, components.shape[1])):
face = components[:, i].reshape(h, w)
plt.subplot(3, 4, i + 1)
plt.imshow(face, cmap='gray')
plt.title(f"特征脸 {i+1}")
plt.axis('off')
plt.tight_layout()
plt.show()
# 显示重建图像与原图对比
def show_reconstructed_faces(original, reconstructed, h, w, num=10):
plt.figure(figsize=(15, 4))
for i in range(num):
plt.subplot(2, num, i + 1)
plt.imshow(original[i].reshape((h, w)), cmap='gray')
plt.title("原图", fontsize=9)
plt.axis('off')
plt.subplot(2, num, i + 1 + num)
plt.imshow(reconstructed[i].reshape((h, w)), cmap='gray')
plt.title("PCA重建", fontsize=9)
plt.axis('off')
plt.tight_layout()
plt.show()
# 预测结果可视化
def plot_predictions(y_true, y_pred):
plt.figure(figsize=(12, 5))
plt.plot(y_true, 'o-', label='真实标签')
plt.plot(y_pred, 'x-', label='预测标签')
plt.title("KNN + PCA 人脸识别预测对比")
plt.xlabel("样本索引")
plt.ylabel("标签")
plt.legend()
plt.grid(True)
plt.show()
# 主程序入口
def main():
faces, labels = load_faces('ORL_Faces')
n_samples, h, w = faces.shape
X = faces.reshape((n_samples, -1))
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.25, random_state=42)
scaler = StandardScaler()
X_train_std = scaler.fit_transform(X_train)
X_test_std = scaler.transform(X_test)
n_components = 100
X_train_pca, pcs, mean_vals, std_vals = manual_pca(X_train, n_components)
X_test_pca = (X_test - mean_vals) / std_vals
X_test_pca = np.dot(X_test_pca, pcs)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train_pca, y_train)
y_pred = knn.predict(X_test_pca)
accuracy = accuracy_score(y_test, y_pred)
print(f"\nKNN分类准确率:{accuracy:.2%}")
# 可视化特征脸
visualize_eigenfaces(pcs, h, w, num=12)
# 可视化预测对比
plot_predictions(y_test, y_pred)
# 重建图像(逆变换)
X_test_reconstructed = np.dot(X_test_pca, pcs.T) * std_vals + mean_vals
show_reconstructed_faces(X_test, X_test_reconstructed, h, w, num=10)
if __name__ == "__main__":
main()
10. 运行结果

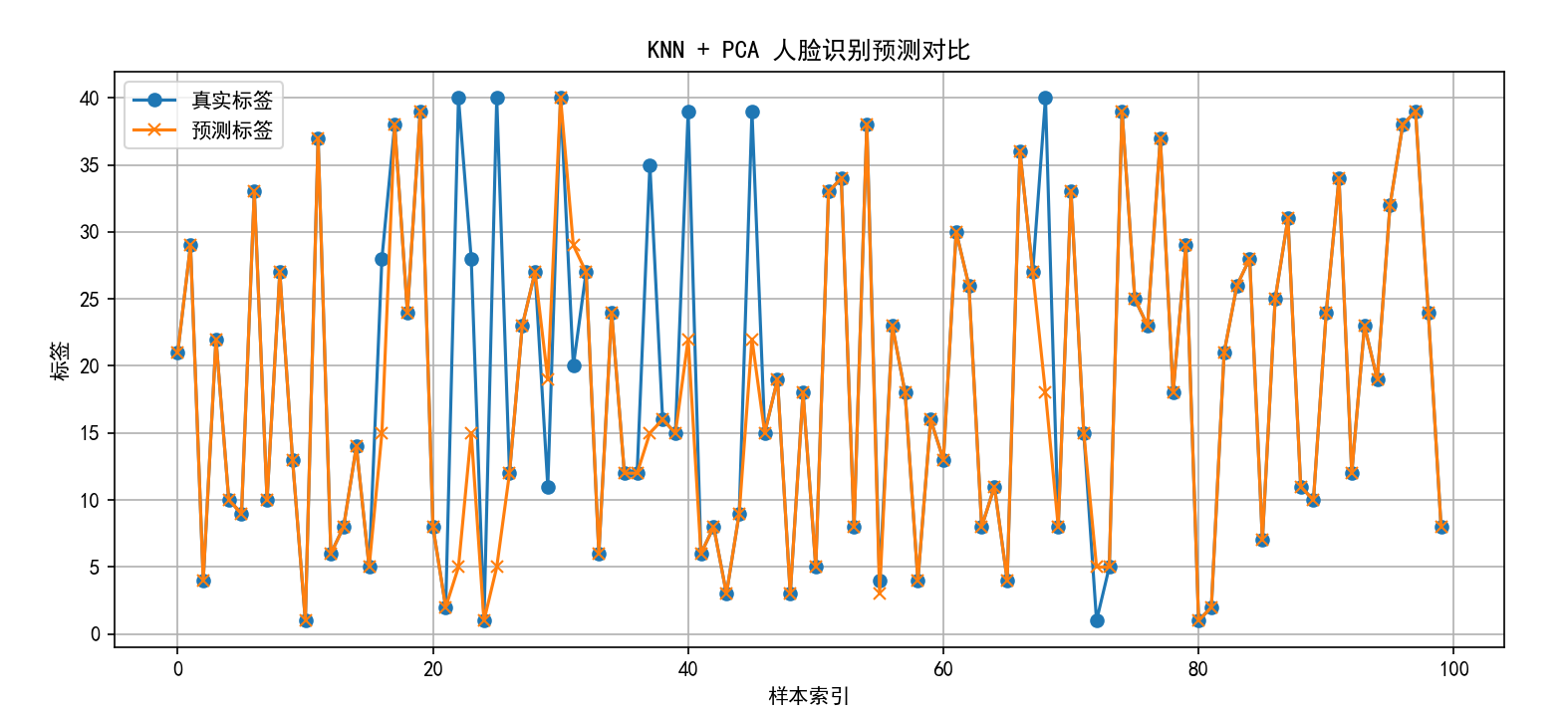

11. 总结
-
先读取人脸数据并打标签。
-
用PCA手动降维,提取主成分。
-
用KNN基于降维特征训练模型并预测。
-
输出准确率。
-
画出特征脸、预测结果对比图,以及重建后的人脸图像对比,方便观察降维效果和识别效果。
五、实验总结与收获
本次实验基于ORL人脸数据集,使用手动实现的PCA对人脸图像进行降维处理,并结合KNN分类器完成识别任务。通过数据预处理、PCA降维、特征脸可视化以及图像重建等环节,系统地验证了PCA在高维图像数据处理中的有效性和实用性。
-
数据标准化使得各像素维度处于同一尺度,有助于后续协方差矩阵的准确计算。
-
PCA降维提取了图像数据的主成分,有效降低了数据维度,去除冗余信息,同时保留了大部分图像特征。
-
特征脸可视化直观展示了主成分对应的“人脸特征”,加深了对PCA物理意义的理解。
-
分类准确率较高,表明降维后的特征依然具备良好的区分性,PCA结合KNN在人脸识别中表现良好。
-
重建图像展示了降维带来的信息损失情况,进一步说明了主成分的重要性。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)